What is the purpose of the activation function in a multi-layer perceptron?
The purpose of an activation function is to add some kind of non-linear property to the neural network. It is responsible for transforming the summed weighted input from the node into the activation of the node or output for that input.
How many hidden layers in a multi-layer perceptron are needed to represent any function? Briefly explain your answer.
Because MLPs are universal approximators. So with one hidden layer, it can approximate any function that we require.
From book Deep Learning: Goodfellow, Bengio, Courville (Cambridge, MA; MIT Press, 2017), Chapter 6.4.1, it has:
Specifically, the universal approximation theorem (Horniket al., 1989; Cybenko, 1989) states that a feedforward network with a linear outputlayer and at least one hidden layer with any “squashing” activation function (suchas the logistic sigmoid activation function) can approximate any Borel measurablefunction from one finite-dimensional space to another with any desired nonzeroamount of error, provided that the network is given enough hidden units. The derivatives of the feedforward network can also approximate the derivatives of the function arbitrarily well (Hornik et al., 1990).
List two reasons to prefer the ReLU activation function over the sigmoid activation function.
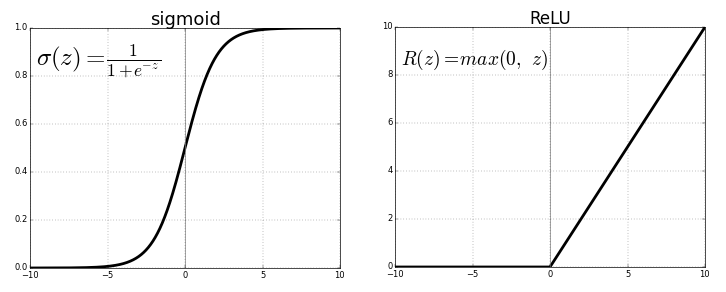
2 drawbacks for Sigmoid function are:
The activation of the neurons saturate either at the tail of 0 or 1. The derivative of the sigmoid function gets very small at that area. In this case, the near-zero derivative would make the gradient of the loss function very small, which prevents the update of the weights and thus the entire learning process.
the outputs of the function are not zero-centered. Usually, this makes the training of the neural network more difficult and unstable.
2 advantages for ReLU function are:
In practice, it was shown that ReLU accelerates the convergence of gradient descent towards the global minimum of the loss function in comparison to other activation functions.
While other activation functions (tanh and sigmoid) involve very computationally expensive operations such as exponentials etc., ReLU, on the other hand, can be easily implemented by simply thresholding a vector of values at zero.
What do you hope to get out of this class? What are some problems that you hope to apply deep learning to?
I'd like to know:
How to collection the data in first place, if I'd like to working on something new? Seem like it's quite expensive to collect data and do the cleanup.
How Machine Learning or Deep Learing works in real projects? How to get the data back from end user and re-training the model? What's the release cadence is a good one for release ML or DL models? What's the problems that might meet when release the models and how to prepare for those problems.