What is the receptive field (in number of pixels of the original image) of three stacked 3x3 conv filters with stride 1x1? Write your answer in the “3x3” format exactly.
It is a 7x7 conv filters.
The input to a conv layer is a 100x100x3 image. The filter size is 5x5 with a 5x5 stride and 'VALID' padding, and there are 128 filters. What is the output volume? Write your answer in the “100x100x3” format exactly.
Flatten: 5 (height) * 5 (width) * 3 (depth) = 125 dimensional
Im2Col: X_col = 125 * 400 (number of filters can fit in the image)
W_row = 128 * 125
W @ X [128 * 400]
Reshape to 20x20x128
So, the output should be 20x20x128
A “residual block” is the foundational unit of the ResNet convolutional architecture. The diagram below shows how it works. Explain why this innovation allowed successful training of deeper-than-ever networks.
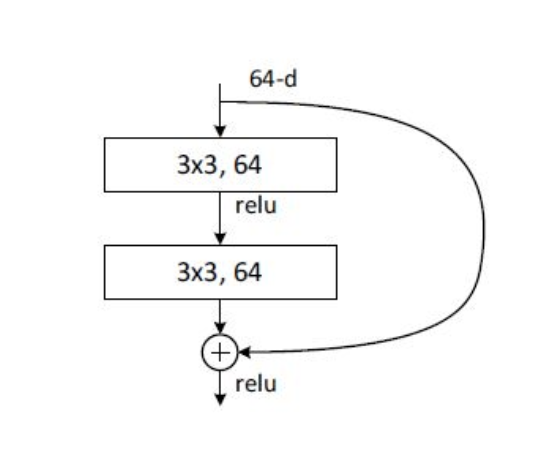
I think there have 2 major problems that before residual block comes out.
When choose ReLU as the activation function, there have one drawback that: because the outputs of this function are zero for input values that are below zero, the neurons of the network can be very fragile during training and can even “die”. Which means during the weight updates the weights are adjusted in such a way that for certain neurons the inputs are always below zero. And those neurons are always zero and do not contribute to the training process.
When we have a deep networks, the gradient tends to vanish. This is because the weights are small numbers, and each time the input goes through a layer, it will get small via multiply the weights. And this can let the signal become very small numbers in the later layers. Also this will cause the gradient become even smaller, even doesn't have any affect in the weights update, which known as Vanishing Gradient Problem.
With the residual block, the later layers can always get the input before and get more information to learn.
What purpose do 1x1 convolutions serve in the InceptionNet block?
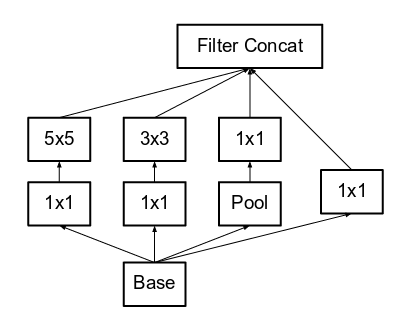
The 1x1 convolutions is used to reduce the number of channels in the inputs. Because
The 1×1 filter can be used to create a linear projection of a stack of feature maps.
The projection created by a 1×1 can act like channel-wise pooling and be used for dimensionality reduction.
The projection created by a 1×1 can also be used directly or be used to increase the number of feature maps in a model.
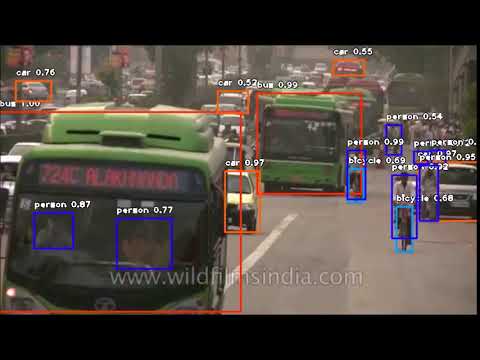
For a project, you have to detect all cars in images coming from a webcam, in real time. The resolution is reasonable (let's say 1080p). The framerate is 5 frames per second. You have access to a GPU on the detection computer. How would you go about doing this? It's more than acceptable to use existing software. Feel free to research on the internet.
For the ML model in this project, I think we can directly use the OpenCV's deep learning (dnn) module. By using it we can utilize the pre-trained networks with popular deep learning frameworks, such as: GoogleLeNet, ResNet, AlexNet, etc. And because it is pre-trained model, we can save many times on training the model.
Or if we'd like to train our own model, we can use the following labeled data for vehicle and non-vehicle to train the classifier. Such as:
- Vehicle: https://s3.amazonaws.com/udacity-sdc/Vehicle_Tracking/vehicles.zip
- Non=vehicle: https://s3.amazonaws.com/udacity-sdc/Vehicle_Tracking/non-vehicles.zip
But, if we can get the labeled images that captured from the webcam that will be the best.
With these data, then we should extract these features for training, such as:
Use a different color spaces (like HSV) that can be a better way to understanding the image without get effect by the color
See the compare between image:
and
Which can see a lot of different, especially the line on the road.
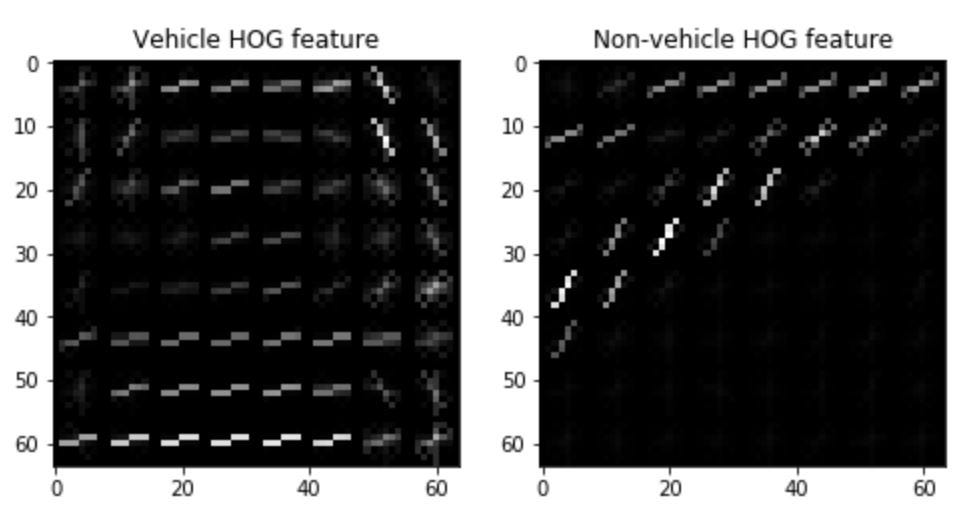
Use the HOG (Histogram of Oriented Gradients) of the image as the feature to train. With this we can even reduce the noise in the images, see:
We know that there have 3 primary object detection methods can be used:
- Faster R-CNNs (Girshick et al., 2015)
- You Only Look Once (YOLO) (Redmon and Farhadi, 2015)
- Single Shot Detectors (SSDs) (Liu et al., 2015)
The Faster R-CNNs can be used in our case that even it quite slow, it still can support about 7 FPS and we only have 5 FPS eend to be handled. YOLO is much faster that can support 40-90 FPS on a Titan X GPU. However YOLO's accuracy is not that good (newer version is better). SSDs are balance between the two. So we can use SSDs algorithm to detect object.
If we want to use ResNet or VGG in our pipeline, the problem is that these network architectures can be very large, which might be (200-500MB)
If we have a resource constrained devices, we can use MobileNets (Howard et al., 2017). This is also developed by Google researchers, and it's designed for resource constrained devices like phone. The main different between traditional CNN and MobileNets are the usage of depthwise separable convolution, which split convolution into two stages:
- A 3×3 depthwise convolution.
- Followed by a 1×1 pointwise convolution.
And this allow us to reduce the number of parameters in our network.
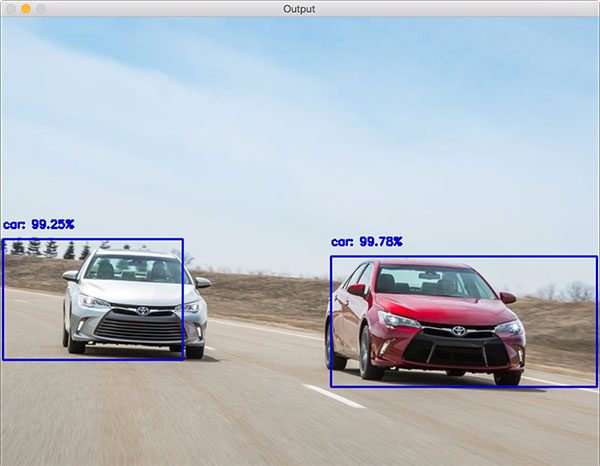
Then we can use the specific deep neural network (dnn) module in OpenCV that combined Image classification network and [Object detection](Object detection) to build our object detector. And it should be able to get the car from our webcam image:
Then next steps for us just connect the webcam feed with the Object Detector then we should get such data. I think with GPU accelrate we can easily handle 5 FPS feeds.
Most of the webcam will never been moved. So maybe we can get the image of the road without any cars as the ground truth. And only use the differences between current frame and the ground truth for dectection. This might save many of the computation.