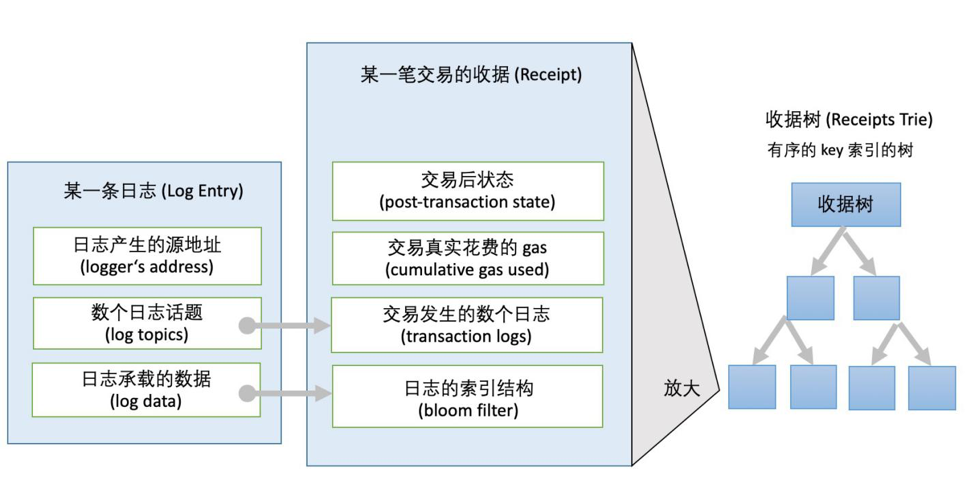
// core/types/log.go
type Log struct {
// 1、通用核心结构
// 发出日志事件的合约地址
Address common.Address `json:"address" gencodec:"required"`
// 最多可以有 4 个主题(topic)。每个主题正好是 32 个字节
// Solidity 将一个主题用作事件的签名
// 注意:如 string 和 bytes 可能超过 32 个字节
// 如果它们被索引,Solidity 将存储 KECCAK256的哈希值,而不是实际数据。
Topics []common.Hash `json:"topics" gencodec:"required"`
// data是事件的有效负载(payload), 可以是任意数量的字节
// 通过 ABI-encoded 编码
// 事件的所有“非索引参数”都存储为数据。
Data []byte `json:"data" gencodec:"required"`
// 2、节点代码层面所用的衍生结构
// 交易所在的区块号
BlockNumber uint64 `json:"blockNumber"`
// log所在的交易哈希
TxHash common.Hash `json:"transactionHash" gencodec:"required"`
// 交易在区块中的索引
TxIndex uint `json:"transactionIndex"`
// 包含这个log的交易被包含在的区块哈希
BlockHash common.Hash `json:"blockHash"`
// log在区块中的索引
Index uint `json:"logIndex"`
// 判断是否包含此log的区块被reorg以至于Log reverted
Removed bool `json:"removed"`
}
日志原语的 gas 费用取决于该条log拥有多少topics、记录了多少data:
日志操作便宜的原因是日志数据并没有真正存储在区块链中(只存储了索引topics的logsBloom)。Log是在交易执行过程中产生的,理论上,日志可以根据需要即时重新计算,因为重跑一遍这个交易还是得到一样的值(确定性状态机),所以以太坊只需要记录用于索引Log的值即可,data字段并不需要存储进区块链。

// core/types/bloom9.go
// 2048 bit bloom filter.
type Bloom [BloomByteLength]byte布隆过滤器于1970 年由布隆提出,是一个长度为2048位的位( bit) 数组

本质上,布隆过滤器是一种概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
- 优点:相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少
- 缺点:返回的结果是概率性的,而不是确切性的,且删除困难(易影响到其他值)
工作原理:
- 通过K个哈希函数计算该数据,返回K个计算出的hash值
- 这些K个hash值映射到对应的K个二进制的数组下标
- 将K个下标对应的二进制数据改成1
参考:Redis 支持 setbit 和 getbit 操作,具有纯内存、性能高等特点,天然可以作为布隆过滤器来使用
// core/bloom_indexer.go
// BloomIndexer对象主要构建了对bloom filter分section的bit索引结构
// 实现了core.ChainIndexer(用来给区块链创建索引的功能)的方法
type BloomIndexer struct {
size uint64 // section大小
db ethdb.Database // levelDB物理数据库实例
gen *bloombits.Generator // generator生成一个rotated bloom filter用于分批过滤
section uint64 // 当前正在处理的section number
head common.Hash // 最后一次处理的区块的header hash
}如果我们要映射值到布隆过滤器中(如"baidu"),我们需要使用多个不同的哈希函数生成多个哈希值然后映射至bloom filter的对应bit(多个哈希函数,产生多个哈希值,而产生的多个映射生成的),并对每个生成的哈希值指向的 bit 位置 。

值得注意的是,这里只能说明"baidu"可能存在,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
在这种情况下,布隆过滤器对于确定某一元素是否在列表中不是很有用。要找出答案,我们必须实际查询列表。但是,如果待查询值的映射上,某个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说该这个值一定不存在