Kar Ng 2022-05
- 1 SUMMARY
- 2 R PACKAGES
- 3 INTRODUCTION
- 4 DATA PREPARATION
- 5 DATA CLEANING AND MANIPULATION
- 6 EDA
- 7 CLUSTERING
- 8 CONCLUSION
- 9 REFERENCE

This project is trying to cluster a big credit card dataset that has 17 variables and 9000 rows of data. Prior to clustering, the dataset was cleaned, featured-selected using R-squared for multicollinearity assessment, and transformed via standardisation.
Principal component analysis (PCA) was used for exploratory data analysis (EDA) and found that the amount of transaction for cash in advance, credit limit, magnitude of payments paid back to the credit card company, magnitude of purchases made, and the percentage of full payment made by credit card users are important variables (or known as features) to look at in this analysis. Other variables can be important supportive information such as preference of making minimum payments and purchase frequency in oneoff-nature or installment-nature.
5 different machine learning clustering algorithms are performed, which are Clustering for Large Application (CLARA), Hierarchical K-means Clustering Hybrid (HKmeans), Fuzzy clustering, Model-based Clustering, Density-Based Spatial Clustering for Application with Noise (DBSCAN). Analysis outcome shows that VEV model suggested by model-based clustering is the best clustering model that is able to detect 8 distinct group of credit card users, which is also the largest amount suggested compared to other algorithms. These groups are:
Cluster 1: Less active user that prefer cash-in-advance.
Cluster 2: Less active user that prefer to use credit card to make
purchases, especially installment purchases.
Cluster 3: Revolvers who prefer to make expensive purchases.
Cluster 4: Less active users who prefer to make full repayment back to
credit card company.
Cluster 5: Active card users who make expensive purchases and make
repayment in big amount sometime they prefer full payment, sometime they
pay minimum payments.
Cluster 6: Max payers who prefer to pay money owe in full with zero
tenure.
Cluster 7: Less active revolvers, they spend small amount of money to
purchase cheaper products.
Cluster 8: Max Payer but this users group is more active in making
purchases than cluster 6.
Highlight
Following R packages are loaded for this project.
set.seed(123)
library(tidyverse)
library(kableExtra)
library(skimr)
library(factoextra)
library(hopkins)
library(clValid)
library(NbClust)
library(mclust)
library(cowplot)
library(dbscan)
library(fpc)
library(corrplot)
library(FactoMineR)
library(ggiraphExtra) # for radar
library(GGally) # for ggparcoord
library(caret) # findCorrelation
library(ggrepel)This project will use various type of clustering techniques to develop customer segmentation to define marketing strategy.
Dataset used in this project is called “Credit Card Dataset for Clustering” by Arjun Bhasin. It is a public dataset from Kaggle.com.
The dataset has 17 behavioral information of 9000 active credit card holders.
Following codes import the dataset and specify the first column as row’s name. Having the first column as row name is a requirement to perform clustering.
cc <- read.csv("cc_dataset.csv",
header = T,
row.names = 1) # specificy column 1 as row name Randomly sample the first 10 rows of the dataset.
sample_n(cc, 10) %>%
kbl() %>%
kable_material_dark()| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C12536 | 1417.9792 | 1.000000 | 0.00 | 0.00 | 0.00 | 97.10606 | 0.000000 | 0.000000 | 0.000000 | 0.285714 | 4 | 0 | 1500 | 201.4252 | 233.5456 | 0.000000 | 7 |
| C12584 | 147.4186 | 0.181818 | 1074.00 | 1074.00 | 0.00 | 0.00000 | 0.083333 | 0.083333 | 0.000000 | 0.000000 | 0 | 2 | 5500 | 0.0000 | NA | 0.000000 | 12 |
| C18954 | 220.9437 | 1.000000 | 1833.34 | 0.00 | 1833.34 | 0.00000 | 0.916667 | 0.000000 | 0.916667 | 0.000000 | 0 | 11 | 1000 | 1652.7554 | 176.8253 | 0.818182 | 12 |
| C13073 | 1820.2166 | 1.000000 | 4877.66 | 2341.16 | 2536.50 | 0.00000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0 | 154 | 4500 | 1297.9945 | 408.2934 | 0.166667 | 12 |
| C11902 | 5941.2712 | 1.000000 | 279.36 | 0.00 | 279.36 | 905.98283 | 0.666667 | 0.000000 | 0.666667 | 0.083333 | 2 | 16 | 6000 | 3140.4024 | 2949.0011 | 0.000000 | 12 |
| C13466 | 820.1633 | 1.000000 | 680.14 | 0.00 | 680.14 | 0.00000 | 0.750000 | 0.000000 | 0.666667 | 0.000000 | 0 | 18 | 1200 | 1178.2472 | 219.8759 | 0.000000 | 12 |
| C14894 | 3755.1840 | 1.000000 | 3211.86 | 1420.58 | 1791.28 | 0.00000 | 1.000000 | 0.750000 | 0.833333 | 0.000000 | 0 | 22 | 11000 | 3198.2619 | 960.8566 | 0.000000 | 12 |
| C16933 | 156.7233 | 1.000000 | 1776.76 | 0.00 | 1776.76 | 0.00000 | 1.000000 | 0.000000 | 0.916667 | 0.000000 | 0 | 22 | 9600 | 1339.3031 | 185.2810 | 0.916667 | 12 |
| C12835 | 3057.5537 | 1.000000 | 0.00 | 0.00 | 0.00 | 2037.64807 | 0.000000 | 0.000000 | 0.000000 | 0.250000 | 3 | 0 | 12500 | 7265.9761 | 847.1706 | 0.000000 | 12 |
| C15251 | 1852.6464 | 1.000000 | 2600.00 | 2200.00 | 400.00 | 3481.13268 | 0.333333 | 0.166667 | 0.083333 | 0.083333 | 8 | 4 | 6000 | 1362.4258 | 727.4295 | 0.100000 | 12 |
The name of all variables are:
names(cc)## [1] "BALANCE" "BALANCE_FREQUENCY"
## [3] "PURCHASES" "ONEOFF_PURCHASES"
## [5] "INSTALLMENTS_PURCHASES" "CASH_ADVANCE"
## [7] "PURCHASES_FREQUENCY" "ONEOFF_PURCHASES_FREQUENCY"
## [9] "PURCHASES_INSTALLMENTS_FREQUENCY" "CASH_ADVANCE_FREQUENCY"
## [11] "CASH_ADVANCE_TRX" "PURCHASES_TRX"
## [13] "CREDIT_LIMIT" "PAYMENTS"
## [15] "MINIMUM_PAYMENTS" "PRC_FULL_PAYMENT"
## [17] "TENURE"
Following is the data description extracted from the relevant Kaggle webpage.
Variables <- c("CUSTID", "BALANCE", "BALANCEFREQUENCY", "PURCHASES", "ONEOFFPURCHASES",
"INSTALLMENTSPURCHASES", "CASHADVANCE", "PURCHASESFREQUENCY", "ONEOFFPURCHASESFREQUENCY", "PURCHASESINSTALLMENTSFREQUENCY", "CASHADVANCEFREQUENCY", "CASHADVANCETRX", "PURCHASESTRX", "CREDITLIMIT", "PAYMENTS", "MINIMUM_PAYMENTS", "PRCFULLPAYMENT", "TENURE")
Description <- c("Identification of Credit Card holder (Categorical)",
"Balance amount left in their account to make purchases",
"How frequently the Balance is updated, score between 0 and 1 (1 = frequently updated, 0 = not frequently updated)",
"Amount of purchases made from account",
"Maximum purchase amount done in one-go",
"Amount of purchase done in installment",
"Cash in advance given by the user",
"How frequently the Purchases are being made, score between 0 and 1 (1 = frequently purchased, 0 = not frequently purchased)",
"How frequently Purchases are happening in one-go (1 = frequently purchased, 0 = not frequently purchased)",
"How frequently purchases in installments are being done (1 = frequently done, 0 = not frequently done)",
"How frequently the cash in advance being paid",
"Number of Transactions made with Cash in Advanced",
"Number of purchase transactions made",
"Limit of Credit Card for user",
"Amount of Payment done by user",
"Minimum amount of payments made by user",
"Percent of full payment paid by user",
"Tenure of credit card service for user")
data.frame(Variables, Description) %>%
kbl() %>%
kable_material_dark()| Variables | Description |
|---|---|
| CUSTID | Identification of Credit Card holder (Categorical) |
| BALANCE | Balance amount left in their account to make purchases |
| BALANCEFREQUENCY | How frequently the Balance is updated, score between 0 and 1 (1 = frequently updated, 0 = not frequently updated) |
| PURCHASES | Amount of purchases made from account |
| ONEOFFPURCHASES | Maximum purchase amount done in one-go |
| INSTALLMENTSPURCHASES | Amount of purchase done in installment |
| CASHADVANCE | Cash in advance given by the user |
| PURCHASESFREQUENCY | How frequently the Purchases are being made, score between 0 and 1 (1 = frequently purchased, 0 = not frequently purchased) |
| ONEOFFPURCHASESFREQUENCY | How frequently Purchases are happening in one-go (1 = frequently purchased, 0 = not frequently purchased) |
| PURCHASESINSTALLMENTSFREQUENCY | How frequently purchases in installments are being done (1 = frequently done, 0 = not frequently done) |
| CASHADVANCEFREQUENCY | How frequently the cash in advance being paid |
| CASHADVANCETRX | Number of Transactions made with Cash in Advanced |
| PURCHASESTRX | Number of purchase transactions made |
| CREDITLIMIT | Limit of Credit Card for user |
| PAYMENTS | Amount of Payment done by user |
| MINIMUM_PAYMENTS | Minimum amount of payments made by user |
| PRCFULLPAYMENT | Percent of full payment paid by user |
| TENURE | Tenure of credit card service for user |
Data Size and type
The dataset has 8950 rows and 17 variables. Following summary displays data type of each column and their initial values.
glimpse(cc)## Rows: 8,950
## Columns: 17
## $ BALANCE <dbl> 40.90075, 3202.46742, 2495.14886, 166~
## $ BALANCE_FREQUENCY <dbl> 0.818182, 0.909091, 1.000000, 0.63636~
## $ PURCHASES <dbl> 95.40, 0.00, 773.17, 1499.00, 16.00, ~
## $ ONEOFF_PURCHASES <dbl> 0.00, 0.00, 773.17, 1499.00, 16.00, 0~
## $ INSTALLMENTS_PURCHASES <dbl> 95.40, 0.00, 0.00, 0.00, 0.00, 1333.2~
## $ CASH_ADVANCE <dbl> 0.0000, 6442.9455, 0.0000, 205.7880, ~
## $ PURCHASES_FREQUENCY <dbl> 0.166667, 0.000000, 1.000000, 0.08333~
## $ ONEOFF_PURCHASES_FREQUENCY <dbl> 0.000000, 0.000000, 1.000000, 0.08333~
## $ PURCHASES_INSTALLMENTS_FREQUENCY <dbl> 0.083333, 0.000000, 0.000000, 0.00000~
## $ CASH_ADVANCE_FREQUENCY <dbl> 0.000000, 0.250000, 0.000000, 0.08333~
## $ CASH_ADVANCE_TRX <int> 0, 4, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0~
## $ PURCHASES_TRX <int> 2, 0, 12, 1, 1, 8, 64, 12, 5, 3, 12, ~
## $ CREDIT_LIMIT <dbl> 1000, 7000, 7500, 7500, 1200, 1800, 1~
## $ PAYMENTS <dbl> 201.8021, 4103.0326, 622.0667, 0.0000~
## $ MINIMUM_PAYMENTS <dbl> 139.50979, 1072.34022, 627.28479, NA,~
## $ PRC_FULL_PAYMENT <dbl> 0.000000, 0.222222, 0.000000, 0.00000~
## $ TENURE <int> 12, 12, 12, 12, 12, 12, 12, 12, 12, 1~
The “dbl” and “ind” are data type allocated by R to particular columns that have these characteristics. The “dbl” stands for “double”, it is used for numerical variables that have decimal places. The “int” stands for integer, it is used for numerical variables that have integer values.
From the above summary, I can see that all variables are numeric with either “dbl” and “int”.
Purchases
I found that the variable “PURCHASES” is the sum of “ONEOFF_PURCHASES” and “INSTALLMENTS_PURCHASES”. This finding may not be important in this analysis. Feature selection will be carried out in next section.
Following codes select 10 rows among the dataset, and the temporary new variable “MY_PURCHASES” (only in this section) proves my finding, which has the same values as the “PURCHASES”.
cc %>%
top_n(10, BALANCE) %>%
dplyr::select(ONEOFF_PURCHASES, INSTALLMENTS_PURCHASES, PURCHASES) %>%
mutate(MY_PURCHASES = ONEOFF_PURCHASES + INSTALLMENTS_PURCHASES) %>%
kbl() %>%
kable_material_dark()| ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | PURCHASES | MY_PURCHASES | |
|---|---|---|---|---|
| C10144 | 9449.07 | 12560.85 | 22009.92 | 22009.92 |
| C10544 | 529.30 | 0.00 | 529.30 | 529.30 |
| C10609 | 7564.81 | 258.93 | 7823.74 | 7823.74 |
| C10914 | 0.00 | 0.00 | 0.00 | 0.00 |
| C12434 | 0.00 | 1168.75 | 1168.75 | 1168.75 |
| C14256 | 3657.30 | 1630.98 | 5288.28 | 5288.28 |
| C14836 | 717.24 | 0.00 | 717.24 | 717.24 |
| C15429 | 105.30 | 579.44 | 684.74 | 684.74 |
| C15642 | 0.00 | 1770.57 | 1770.57 | 1770.57 |
| C16812 | 3582.45 | 1442.23 | 5024.68 | 5024.68 |
Missing values check
By examining the variables “n_missing” and “complete_rate” in following tables, there is:
- 1 missing value in the variable “CREDIT_LIMIT”
- 313 missing values in the “MINIMUM_PAYMENTS”
skim_without_charts(cc) | Name | cc |
| Number of rows | 8950 |
| Number of columns | 17 |
| \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ | |
| Column type frequency: | |
| numeric | 17 |
| \_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 |
|---|---|---|---|---|---|---|---|---|---|
| BALANCE | 0 | 1.00 | 1564.47 | 2081.53 | 0.00 | 128.28 | 873.39 | 2054.14 | 19043.14 |
| BALANCE_FREQUENCY | 0 | 1.00 | 0.88 | 0.24 | 0.00 | 0.89 | 1.00 | 1.00 | 1.00 |
| PURCHASES | 0 | 1.00 | 1003.20 | 2136.63 | 0.00 | 39.63 | 361.28 | 1110.13 | 49039.57 |
| ONEOFF_PURCHASES | 0 | 1.00 | 592.44 | 1659.89 | 0.00 | 0.00 | 38.00 | 577.41 | 40761.25 |
| INSTALLMENTS_PURCHASES | 0 | 1.00 | 411.07 | 904.34 | 0.00 | 0.00 | 89.00 | 468.64 | 22500.00 |
| CASH_ADVANCE | 0 | 1.00 | 978.87 | 2097.16 | 0.00 | 0.00 | 0.00 | 1113.82 | 47137.21 |
| PURCHASES_FREQUENCY | 0 | 1.00 | 0.49 | 0.40 | 0.00 | 0.08 | 0.50 | 0.92 | 1.00 |
| ONEOFF_PURCHASES_FREQUENCY | 0 | 1.00 | 0.20 | 0.30 | 0.00 | 0.00 | 0.08 | 0.30 | 1.00 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0 | 1.00 | 0.36 | 0.40 | 0.00 | 0.00 | 0.17 | 0.75 | 1.00 |
| CASH_ADVANCE_FREQUENCY | 0 | 1.00 | 0.14 | 0.20 | 0.00 | 0.00 | 0.00 | 0.22 | 1.50 |
| CASH_ADVANCE_TRX | 0 | 1.00 | 3.25 | 6.82 | 0.00 | 0.00 | 0.00 | 4.00 | 123.00 |
| PURCHASES_TRX | 0 | 1.00 | 14.71 | 24.86 | 0.00 | 1.00 | 7.00 | 17.00 | 358.00 |
| CREDIT_LIMIT | 1 | 1.00 | 4494.45 | 3638.82 | 50.00 | 1600.00 | 3000.00 | 6500.00 | 30000.00 |
| PAYMENTS | 0 | 1.00 | 1733.14 | 2895.06 | 0.00 | 383.28 | 856.90 | 1901.13 | 50721.48 |
| MINIMUM_PAYMENTS | 313 | 0.97 | 864.21 | 2372.45 | 0.02 | 169.12 | 312.34 | 825.49 | 76406.21 |
| PRC_FULL_PAYMENT | 0 | 1.00 | 0.15 | 0.29 | 0.00 | 0.00 | 0.00 | 0.14 | 1.00 |
| TENURE | 0 | 1.00 | 11.52 | 1.34 | 6.00 | 12.00 | 12.00 | 12.00 | 12.00 |
Alternatively, following code performs the missing-value check.
colSums(is.na(cc)) %>%
kbl(col.names = "Numbers of Missing Values") %>%
kable_material_dark(full_width = F)| Numbers of Missing Values | |
|---|---|
| BALANCE | 0 |
| BALANCE_FREQUENCY | 0 |
| PURCHASES | 0 |
| ONEOFF_PURCHASES | 0 |
| INSTALLMENTS_PURCHASES | 0 |
| CASH_ADVANCE | 0 |
| PURCHASES_FREQUENCY | 0 |
| ONEOFF_PURCHASES_FREQUENCY | 0 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0 |
| CASH_ADVANCE_FREQUENCY | 0 |
| CASH_ADVANCE_TRX | 0 |
| PURCHASES_TRX | 0 |
| CREDIT_LIMIT | 1 |
| PAYMENTS | 0 |
| MINIMUM_PAYMENTS | 313 |
| PRC_FULL_PAYMENT | 0 |
| TENURE | 0 |
There are 8950 rows of data and I will still have 96.5% of data remain after removal of these missing values and therefore I will simply remove these missing values for the simplicity of this project.
Typically, missing value can be handled by either removal, replaced with mean, median, or using imputation algorithm such as KNN or bagging algorithm. These techniques are usually performed when there are too many missing values in important variables. For example, when missing values of a variable is higher than 5% but less than 60%.
Summary
Visualising the statistical distribution of each variable:
summary(cc) %>% kbl() %>% kable_material_dark()| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min. : 0.0 | Min. :0.0000 | Min. : 0.00 | Min. : 0.0 | Min. : 0.0 | Min. : 0.0 | Min. :0.00000 | Min. :0.00000 | Min. :0.0000 | Min. :0.0000 | Min. : 0.000 | Min. : 0.00 | Min. : 50 | Min. : 0.0 | Min. : 0.02 | Min. :0.0000 | Min. : 6.00 | |
| 1st Qu.: 128.3 | 1st Qu.:0.8889 | 1st Qu.: 39.63 | 1st Qu.: 0.0 | 1st Qu.: 0.0 | 1st Qu.: 0.0 | 1st Qu.:0.08333 | 1st Qu.:0.00000 | 1st Qu.:0.0000 | 1st Qu.:0.0000 | 1st Qu.: 0.000 | 1st Qu.: 1.00 | 1st Qu.: 1600 | 1st Qu.: 383.3 | 1st Qu.: 169.12 | 1st Qu.:0.0000 | 1st Qu.:12.00 | |
| Median : 873.4 | Median :1.0000 | Median : 361.28 | Median : 38.0 | Median : 89.0 | Median : 0.0 | Median :0.50000 | Median :0.08333 | Median :0.1667 | Median :0.0000 | Median : 0.000 | Median : 7.00 | Median : 3000 | Median : 856.9 | Median : 312.34 | Median :0.0000 | Median :12.00 | |
| Mean : 1564.5 | Mean :0.8773 | Mean : 1003.20 | Mean : 592.4 | Mean : 411.1 | Mean : 978.9 | Mean :0.49035 | Mean :0.20246 | Mean :0.3644 | Mean :0.1351 | Mean : 3.249 | Mean : 14.71 | Mean : 4494 | Mean : 1733.1 | Mean : 864.21 | Mean :0.1537 | Mean :11.52 | |
| 3rd Qu.: 2054.1 | 3rd Qu.:1.0000 | 3rd Qu.: 1110.13 | 3rd Qu.: 577.4 | 3rd Qu.: 468.6 | 3rd Qu.: 1113.8 | 3rd Qu.:0.91667 | 3rd Qu.:0.30000 | 3rd Qu.:0.7500 | 3rd Qu.:0.2222 | 3rd Qu.: 4.000 | 3rd Qu.: 17.00 | 3rd Qu.: 6500 | 3rd Qu.: 1901.1 | 3rd Qu.: 825.49 | 3rd Qu.:0.1429 | 3rd Qu.:12.00 | |
| Max. :19043.1 | Max. :1.0000 | Max. :49039.57 | Max. :40761.2 | Max. :22500.0 | Max. :47137.2 | Max. :1.00000 | Max. :1.00000 | Max. :1.0000 | Max. :1.5000 | Max. :123.000 | Max. :358.00 | Max. :30000 | Max. :50721.5 | Max. :76406.21 | Max. :1.0000 | Max. :12.00 | |
| NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA’s :1 | NA | NA’s :313 | NA | NA |
The name of all variables are in capital form and which would be difficult to read for readers and also myself.
colnames(cc) %>%
kbl(col.names = "Variables") %>%
kable_material_dark()| Variables |
|---|
| BALANCE |
| BALANCE_FREQUENCY |
| PURCHASES |
| ONEOFF_PURCHASES |
| INSTALLMENTS_PURCHASES |
| CASH_ADVANCE |
| PURCHASES_FREQUENCY |
| ONEOFF_PURCHASES_FREQUENCY |
| PURCHASES_INSTALLMENTS_FREQUENCY |
| CASH_ADVANCE_FREQUENCY |
| CASH_ADVANCE_TRX |
| PURCHASES_TRX |
| CREDIT_LIMIT |
| PAYMENTS |
| MINIMUM_PAYMENTS |
| PRC_FULL_PAYMENT |
| TENURE |
Following code transforms all the names into reader-friendly form.
cc <- cc %>%
rename_all(str_to_sentence)Checking again the name of each variable.
colnames(cc) %>%
kbl(col.names = "Variables") %>%
kable_material_dark()| Variables |
|---|
| Balance |
| Balance_frequency |
| Purchases |
| Oneoff_purchases |
| Installments_purchases |
| Cash_advance |
| Purchases_frequency |
| Oneoff_purchases_frequency |
| Purchases_installments_frequency |
| Cash_advance_frequency |
| Cash_advance_trx |
| Purchases_trx |
| Credit_limit |
| Payments |
| Minimum_payments |
| Prc_full_payment |
| Tenure |
Following code removes all the missing values in the dataset (314 rows among 8950 rows).
cc <- cc %>%
na.omit()Now, the number of rows have been reduced to 8636 from 8950.
nrow(cc)## [1] 8636
During Exploratory Data Analysis (EDA), trends in the dataset will be explored and the data would be transformed if required.
A histogram is plotted to investigate the distribution of the data.
# data frame
df5.1 <- cc %>%
pivot_longer(c(1:17),
names_to = "my.variable",
values_to = "my.value")
# graphs
ggplot(df5.1, aes(x = my.value, fill = my.variable)) +
geom_histogram(color = "black") +
facet_wrap(~my.variable, scale = "free") +
theme_minimal() +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45),
plot.title = element_text(face = "bold", hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5, face = "bold")) +
labs(title = "Variable Distribution Analysis",
subtitle = "by Histogram")
Many columns that is skewed and having large values. Usually, one would log these variables, however, since I will transform them using standardisation in later section, I will not log-transform them.
Following plot shows the relationship between variables. Correlated variables means redundancy and I will be removing variables from any variable pairs that have a correlation value greater than a certain threshold. I will be using 0.8 as the cut-off point.
Graphically:
cor_cc <- cor(cc, method = "spearman")
corrplot(cor_cc, type = "lower",
method = "number",
tl.cex = 0.6,
tl.col = "purple",
number.cex = 0.6,
pch = 20)
Construct a correlation table to look at relevant correlation statistics:
cor_cc %>%
round(2) %>%
as.data.frame() %>%
kbl() %>%
kable_material_dark()| Balance | Balance_frequency | Purchases | Oneoff_purchases | Installments_purchases | Cash_advance | Purchases_frequency | Oneoff_purchases_frequency | Purchases_installments_frequency | Cash_advance_frequency | Cash_advance_trx | Purchases_trx | Credit_limit | Payments | Minimum_payments | Prc_full_payment | Tenure | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Balance | 1.00 | 0.51 | -0.01 | 0.13 | -0.10 | 0.57 | -0.16 | 0.10 | -0.16 | 0.54 | 0.55 | -0.06 | 0.38 | 0.42 | 0.90 | -0.53 | 0.06 |
| Balance_frequency | 0.51 | 1.00 | 0.13 | 0.12 | 0.12 | 0.13 | 0.20 | 0.14 | 0.15 | 0.17 | 0.17 | 0.19 | 0.10 | 0.16 | 0.50 | -0.22 | 0.23 |
| Purchases | -0.01 | 0.13 | 1.00 | 0.75 | 0.71 | -0.39 | 0.79 | 0.69 | 0.61 | -0.40 | -0.39 | 0.89 | 0.26 | 0.40 | -0.01 | 0.23 | 0.13 |
| Oneoff_purchases | 0.13 | 0.12 | 0.75 | 1.00 | 0.21 | -0.19 | 0.43 | 0.95 | 0.13 | -0.19 | -0.18 | 0.60 | 0.31 | 0.37 | 0.07 | 0.04 | 0.10 |
| Installments_purchases | -0.10 | 0.12 | 0.71 | 0.21 | 1.00 | -0.36 | 0.79 | 0.19 | 0.92 | -0.37 | -0.36 | 0.78 | 0.13 | 0.23 | -0.05 | 0.27 | 0.12 |
| Cash_advance | 0.57 | 0.13 | -0.39 | -0.19 | -0.36 | 1.00 | -0.45 | -0.19 | -0.38 | 0.94 | 0.95 | -0.41 | 0.16 | 0.27 | 0.48 | -0.28 | -0.12 |
| Purchases_frequency | -0.16 | 0.20 | 0.79 | 0.43 | 0.79 | -0.45 | 1.00 | 0.47 | 0.85 | -0.46 | -0.45 | 0.92 | 0.11 | 0.16 | -0.10 | 0.29 | 0.09 |
| Oneoff_purchases_frequency | 0.10 | 0.14 | 0.69 | 0.95 | 0.19 | -0.19 | 0.47 | 1.00 | 0.12 | -0.18 | -0.18 | 0.61 | 0.28 | 0.32 | 0.05 | 0.06 | 0.08 |
| Purchases_installments_frequency | -0.16 | 0.15 | 0.61 | 0.13 | 0.92 | -0.38 | 0.85 | 0.12 | 1.00 | -0.38 | -0.38 | 0.78 | 0.05 | 0.11 | -0.09 | 0.26 | 0.11 |
| Cash_advance_frequency | 0.54 | 0.17 | -0.40 | -0.19 | -0.37 | 0.94 | -0.46 | -0.18 | -0.38 | 1.00 | 0.98 | -0.41 | 0.09 | 0.20 | 0.46 | -0.30 | -0.13 |
| Cash_advance_trx | 0.55 | 0.17 | -0.39 | -0.18 | -0.36 | 0.95 | -0.45 | -0.18 | -0.38 | 0.98 | 1.00 | -0.40 | 0.10 | 0.22 | 0.47 | -0.30 | -0.10 |
| Purchases_trx | -0.06 | 0.19 | 0.89 | 0.60 | 0.78 | -0.41 | 0.92 | 0.61 | 0.78 | -0.41 | -0.40 | 1.00 | 0.19 | 0.28 | -0.03 | 0.25 | 0.16 |
| Credit_limit | 0.38 | 0.10 | 0.26 | 0.31 | 0.13 | 0.16 | 0.11 | 0.28 | 0.05 | 0.09 | 0.10 | 0.19 | 1.00 | 0.47 | 0.26 | 0.02 | 0.17 |
| Payments | 0.42 | 0.16 | 0.40 | 0.37 | 0.23 | 0.27 | 0.16 | 0.32 | 0.11 | 0.20 | 0.22 | 0.28 | 0.47 | 1.00 | 0.37 | 0.16 | 0.20 |
| Minimum_payments | 0.90 | 0.50 | -0.01 | 0.07 | -0.05 | 0.48 | -0.10 | 0.05 | -0.09 | 0.46 | 0.47 | -0.03 | 0.26 | 0.37 | 1.00 | -0.48 | 0.14 |
| Prc_full_payment | -0.53 | -0.22 | 0.23 | 0.04 | 0.27 | -0.28 | 0.29 | 0.06 | 0.26 | -0.30 | -0.30 | 0.25 | 0.02 | 0.16 | -0.48 | 1.00 | 0.01 |
| Tenure | 0.06 | 0.23 | 0.13 | 0.10 | 0.12 | -0.12 | 0.09 | 0.08 | 0.11 | -0.13 | -0.10 | 0.16 | 0.17 | 0.20 | 0.14 | 0.01 | 1.00 |
Following are highly correlated variables with a correlation level of higher than 80%, and I will be removing these redundant variables from the dataset.
correlated_vars <- caret::findCorrelation(x = cor_cc,
names = T, # display detect variable names
cutoff = 0.80)
correlated_vars %>%
kbl(col.names = "Redundant Variables") %>%
kable_styling(full_width = FALSE)| Redundant Variables |
|---|
| Purchases_trx |
| Purchases_frequency |
| Cash_advance |
| Cash_advance_frequency |
| Installments_purchases |
| Balance |
| Oneoff_purchases |
Update the dataset by removing correlated variables.
cc <- cc %>%
select(-one_of(correlated_vars))
names(cc) %>%
kbl(col.names = "Active Variables") %>%
kable_styling(full_width = FALSE)| Active Variables |
|---|
| Balance_frequency |
| Purchases |
| Oneoff_purchases_frequency |
| Purchases_installments_frequency |
| Cash_advance_trx |
| Credit_limit |
| Payments |
| Minimum_payments |
| Prc_full_payment |
| Tenure |
Now, the total number of variables from the dataset has been reduced from 17 to only 10. The 7 highly correlated variables have been removed.
In this section, I will use principal component analysis (PCA) to explore the data.
This first step (generally recommended) is to scale the data by standardisation so that variables with different units can be scaled down to a value between -1 to 1. This transformation will make all variables with various scales become comparable.
cc.scale <- scale(cc)Showing the first 6 rows of the data:
head(cc.scale) %>% kbl() %>% kable_material_dark()| Balance_frequency | Purchases | Oneoff_purchases_frequency | Purchases_installments_frequency | Cash_advance_trx | Credit_limit | Payments | Minimum_payments | Prc_full_payment | Tenure | |
|---|---|---|---|---|---|---|---|---|---|---|
| C10001 | -0.3700254 | -0.4291590 | -0.6862398 | -0.7171374 | -0.4794091 | -0.9625197 | -0.5439104 | -0.3054899 | -0.5376958 | 0.3551601 |
| C10002 | 0.0676750 | -0.4731808 | -0.6862398 | -0.9264679 | 0.0992522 | 0.6771649 | 0.7968061 | 0.0876836 | 0.2123677 | 0.3551601 |
| C10003 | 0.5053754 | -0.1164058 | 2.6464980 | -0.9264679 | -0.4794091 | 0.8138052 | -0.3994801 | -0.0999003 | -0.5376958 | 0.3551601 |
| C10005 | 0.5053754 | -0.4657977 | -0.4085128 | -0.9264679 | -0.4794091 | -0.9078636 | -0.3801428 | -0.2611154 | -0.5376958 | 0.3551601 |
| C10006 | 0.5053754 | 0.1420539 | -0.6862398 | 0.5388507 | -0.4794091 | -0.7438951 | -0.1321118 | 0.6503258 | -0.5376958 | 0.3551601 |
| C10007 | 0.5053754 | 2.7989266 | 2.6464980 | 1.5855083 | -0.4794091 | 2.4534898 | 1.5704929 | -0.2808094 | 2.8375934 | 0.3551601 |
Applying PCA algorithm, and the Scree Plot implies that the first two components explain about 40.2% of variation and they will be used to construct the axes of PCA factor map.
res.pca <- PCA(cc.scale, graph = F)
fviz_screeplot(res.pca, addlabels = T, ylim = c(0, 30), barfill = "orange", barcolor = "black") +
labs(title = "Scree Plot") +
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
The goal of PCA is to identify direction in the dataset where the first two dimensions explain the most variation.
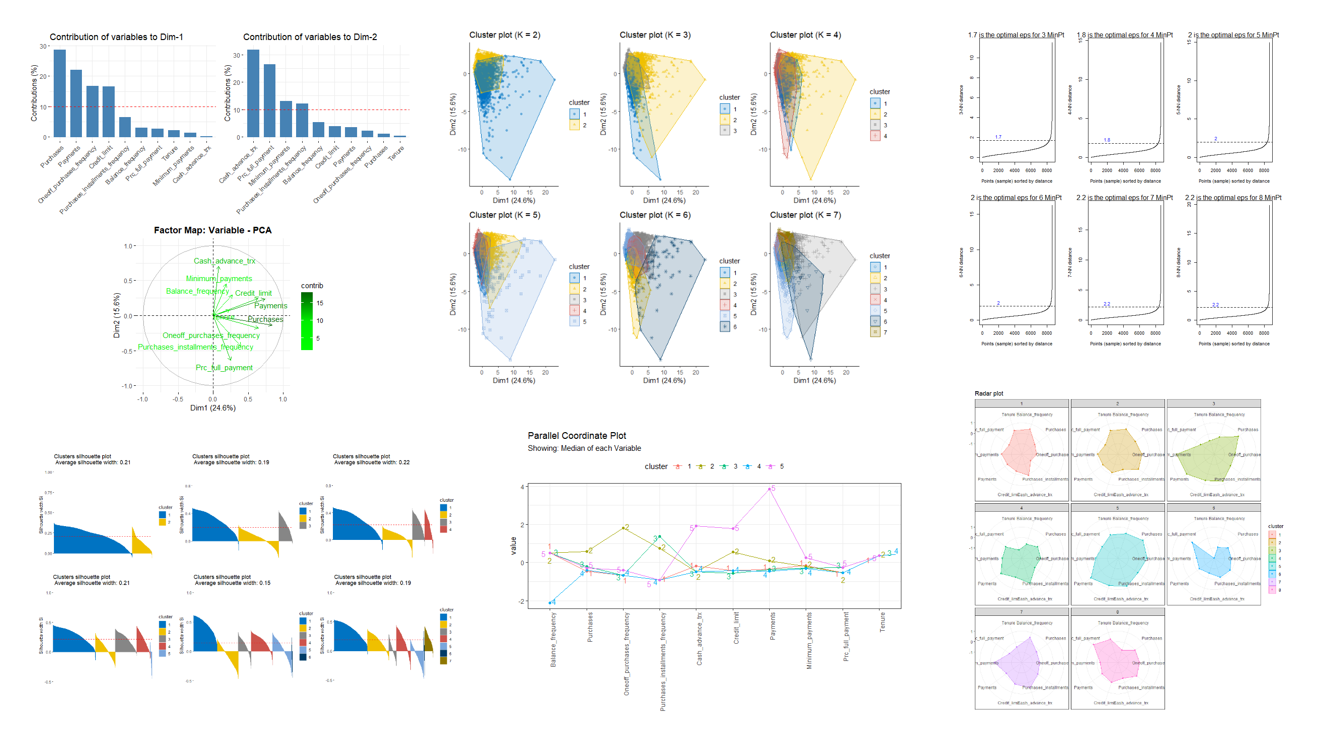
pca1 <- fviz_contrib(res.pca, choice = "var", axes = 1, top = 10)
pca2 <- fviz_contrib(res.pca, choice = "var", axes = 2, top = 10)
pca3 <- fviz_pca_var(res.pca, repel = T,
col.var = "contrib",
gradient.cols = c("green", "green2", "darkgreen")) +
labs(title = "Factor Map: Variable - PCA") +
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
pg <- plot_grid(pca1, pca2)
plot_grid(pg, pca3, cols = 1)
The important variables in the datasets that explain many of the variation are purchases, cash_advance_trx, payments, and credit limit.
These variables are the closest variables to the circumference of the correlation circle which indicating that they have a high cosine-square level and are well represented by the first two principal components (Dim1 and Dim2). These variables also have high contribution level compared to other variables, which means they are important variables in contributing to the factor map.
PCA also reveals correlation trends among the variables in the dataset. Positively correlated variables are grouped together, for examples:
- “Purchases” and “Oneoff_purchases_frequency”
- “Credit_limit” and “Payments”
- “Cash_advance_trx” and “Minimum_payments”
- “Minimum_payments” and “Prc_full_payment” (Negative correlation)
It is possible that, during clustering, which is another branch of unsupervised learning, these variables can be important and help forming distinctive groups. PCA detection of these important variables quickly generate some insights, such as:
-
Would there be a group of credit card holders who love using credit cards and have made numerous purchases, or vice versa?
-
Would there be a group of credit card holders who love paying minimum payment instead of paying full amount of balance that they owe, or vice versa?
-
Would there be a group of credit card holders who use a lot of cash advance from the credit card company?
These will be investigated in the next section, clustering, by several type of clustering algorithms.
The dataset must meet several conditions prior to be clustered,
- Having observation as row and variable as variable
- No missing values in the dataset
- Standardising the data (generally recommended) to make variables comparable. This step will transform the values in all variables to a scale that have 0 mean and 1 standard deviation.
All these steps have been met.
There are different type of clustering methods such as partitioning clustering which include “k-means clustering”, “PAM”, and “CLARA”, or hierarchical clustering which include the famous “AGNES” and “DIANA”.
Partitioning and hierarchical clustering methods are alternative to each other, and although automation with selection statistics are available to choose the best algorithm for the dataset but I will not perform it here as the data size is too large to handle within a reasonable time frame. However, proper steps of clustering will be performed along with several advanced clustering techniques.
A big issue with clustering techniques is that it will always return clusters even if there is no any cluster in the dataset. Therefore, clustering tendency assessment is an important step to test whether the dataset can be clustered.
Hopkins Statistics is a statistical method that using probability to test for spatial randomness of the data. The null hypothesis is that the credit card dataset is uniformly distributed, indicating no meaningful cluster.
- If the value of hopkins statistic is low (0 - 3), it indicates regularly-spaced data or being indecisive (clustered or random).
- If the value is around zero, it indicates random data
- If the value is around 0.7 to 1, it is a significant evidence that the data might be clusterable.
set.seed(123)
hopkins(cc.scale, m = nrow(cc.scale)-1)## [1] 0.9999995
The Hopkins Statistics is close to 1, and base on this value I can reject the null hypothesis and conclude that the credit card dataset is significantly a clusterable data.
Following is the same test from other R package and should yield similar result. The Hopkins statistic is also closed to 1 and I can conclude that the dataset is significantly clusterable.
set.seed(123)
get_clust_tendency(cc.scale, n = 100, graph = F)## $hopkins_stat
## [1] 0.9663011
##
## $plot
## NULL
I have picked CLARA as the clustering algorithm to perform for this dataset because this dataset has more than thousand of observations (Alboukadel Kassambara 2017). CLARA stands for “Clustering Large Application”, which is an extension of PAM (Partitioning Around Medoid), and PAM is a robust alternative to the K-mean clustering because it is less sensitive to outlier.
As the name of CLARA suggests, I apply CALARA because this dataset is a large dataset and CLARA can help to reduce computation time and RAM storage issue by a sampling approach. I did not pick hierarchical clustering (AGNES and DIANA) for this project because of the same reason, CLARA is designed for large application.
Following perform 6 CLARA algorithms for 6 different number of K for exploration purposes.
res.clara2 <- eclust(cc.scale,
FUNcluster = "clara",
k = 2,
graph = F)
res.clara3 <- eclust(cc.scale,
FUNcluster = "clara",
k = 3,
graph = F)
res.clara4 <- eclust(cc.scale,
FUNcluster = "clara",
k = 4,
graph = F)
res.clara5 <- eclust(cc.scale,
FUNcluster = "clara",
k = 5,
graph = F)
res.clara6 <- eclust(cc.scale,
FUNcluster = "clara",
k = 6,
graph = F)
res.clara7 <- eclust(cc.scale,
FUNcluster = "clara",
k = 7,
graph = F)
f1 <- fviz_cluster(res.clara2, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 2)")
f2 <- fviz_cluster(res.clara3, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 3)")
f3 <- fviz_cluster(res.clara4, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 4)")
f4 <- fviz_cluster(res.clara5, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 5)")
f5 <- fviz_cluster(res.clara6, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 6)")
f6 <- fviz_cluster(res.clara7, show.clust.cent = F, geom = "point", alpha = 0.5, palette = "jco") +
theme_classic() + labs(title = "Cluster plot (K = 7)")
plot_grid(f1, f2, f3, f4, f5, f6,
ncol = 3,
nrow = 2)
From the above visualisation, I can see how the data partitions change (or added) when K is increased. Following shows the silhouette width of each observation in each k.
The line in the middle of the graph is the overall average silhouette width of each k, the higher silhouette width, the better the quality of a clustering or an observation.
In following plots, it can be interpreted this way (Alboukadel Kassambara 2017):
- Observations with a large Silhouette value are very well clustered
- Observations with a small silhouette value means they lies between two clusters
- Observations with a negative Silhouette are probably assgined to the wrong cluster. However, negative values may be unavoidable.
f7 <- fviz_silhouette(res.clara2, palette = "jco")## cluster size ave.sil.width
## 1 1 6897 0.23
## 2 2 1739 0.14
f8 <- fviz_silhouette(res.clara3, palette = "jco")## cluster size ave.sil.width
## 1 1 3978 0.31
## 2 2 3462 0.04
## 3 3 1196 0.25
f9 <- fviz_silhouette(res.clara4, palette = "jco")## cluster size ave.sil.width
## 1 1 4267 0.30
## 2 2 2574 0.07
## 3 3 1065 0.27
## 4 4 730 0.23
f10 <- fviz_silhouette(res.clara5, palette = "jco")## cluster size ave.sil.width
## 1 1 3699 0.29
## 2 2 1737 0.06
## 3 3 1868 0.22
## 4 4 1176 0.22
## 5 5 156 -0.13
f11 <- fviz_silhouette(res.clara6, palette = "jco")## cluster size ave.sil.width
## 1 1 2054 0.45
## 2 2 1842 -0.09
## 3 3 1118 0.10
## 4 4 1881 0.18
## 5 5 1660 0.04
## 6 6 81 -0.09
f12 <- fviz_silhouette(res.clara7, palette = "jco")## cluster size ave.sil.width
## 1 1 2896 0.37
## 2 2 1885 0.18
## 3 3 638 0.02
## 4 4 1254 0.17
## 5 5 1141 -0.10
## 6 6 95 0.03
## 7 7 727 0.22
plot_grid(f7, f8, f9, f10, f11, f12,
ncol = 3,
nrow = 2)
Above graph can be used as a reference when interpreting a result from a suggested optimal K.
Instead of choosing the clustering manually, there are methods to suggest the best K. Now I will use two typical methods among other popular methods to find the optimal number of clusters (specified by “k”). All methods should recommend the same or highly similar number of optimal k. In general, the optimal k is specified by the analyst of the project, and it can be hard task. There is also no definite answer to say what k is the best, it is subjective and relying on the selection of the distance matrix and the parameters used for clustering the data (Alboukadel Kassambara 2017).
Elbow Method:
Following shows the result of Elbow method. In Elbow method, clustering algorithm is computed for different number of clusters (k). For each k, the total within sum of square (WSS) is calculated. Total WSS can be understood as total within-cluster variation, and we want it to be minimised.
For each unit of K addition, the WSS is decreased, however the best K is located when the reduction rate of total WSS starts to slow down significantly. It is known as the location of a bend (knee), the location is generally considered as an indicator of appropriate k.
Therefore, in following Total WSS graph, the optimal K can be either 5 or 6.
fviz_nbclust(cc.scale, FUNcluster = clara, method = "wss")
Silhouette Method
This method uses average silhouette width to determine the optimal number of k. Average silhouette width is the y-axis in following graph, and which can be understood as an averaged “similarity” value of each point within a cluster.
In each cluster, we wish observation points within a cluster are similar to each other and by that way, they would have high silhouette width. An average silhouette width is the combination of silhouette value of each points in a cluster. Therefore, a high average silhouette width also means good clustering.
The silhouette method of this section suggests 4 as the optimal number of K for clustering because this k has the highest average silhouette width.
fviz_nbclust(cc.scale, FUNcluster = clara, method = "silhouette")
Analysing the result
Therefore, what is the best K?
- Elbow method suggests 5 and 6, and
- Average Silhouette width method suggests 4 and 5 (Average silhouette width of 5 is not too far from 4 actually)
Therefore, I will be taking 5 as the optimal number of cluster for CLARA because it is the value suggested by two methods.
Following code chunk adds the clustering results to the scaled original data.
# set up dataframe
clara_k6 <- cbind(as.data.frame(cc.scale),
cluster = res.clara5$clustering) %>% # merge scaled data with clusters
mutate(cluster = as.factor(cluster)) %>%
relocate(cluster, .before = Balance_frequency)
# plot
ggRadar(clara_k6, aes(group = cluster),
size = 1,
use.label = F,
rescale = F) +
# Use scaled data to plot Radar, do not normalise btw 1-0 by rescale = T.
# scaled data better show subtle trends
theme_bw() +
labs(title = "Radar plot") +
facet_wrap(~cluster) +
theme(legend.position = "none",
axis.text.x = element_text(size = 7),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())  Following show
the median of each variable in each cluster. I plot them to aid
interpretation of Radar plot above if required.
Following show
the median of each variable in each cluster. I plot them to aid
interpretation of Radar plot above if required.
set.seed(123)
clara_k6_median <- clara_k6 %>%
as.data.frame() %>%
group_by(cluster) %>%
summarise_all(median)
ggparcoord(clara_k6_median,
column = c(2:11),
groupColumn = "cluster",
scale = "globalminmax",
showPoints = T) +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "top") +
labs(title = "Parallel Coordinate Plot",
subtitle = "Showing: Median of each Variable") +
geom_text_repel(aes(label = cluster), box.padding = 0.1)
Five groups of credit card users have been identified:
Cluster 1: Infrequent User, the credit card users in this cluster do not like to use credit card that much, they do use occasionally, however they are less active compared to users in other clusters.
Cluster 2: One-off Purchasers, credit card users in this group prefer to use credit card for one-off purchase and less prefer to use it to make installment purchase.
Cluster 3: Installment Purchasers, credit card users in this group love to use credit card to make installment purchases.
Cluster 4: Max Payers, users from this group have zero level “Balance_frequency” which is a variable detecting their activities with the credit card company. Users in this group also has a high level of percentage of full-payment. They prefer to pay money they owe in full. It may explains why they have low level of “Balance frequency”.
Cluster 5: Active Revolvers, users from this group are characterised by very high level of credit card activities in term of dollars scale. The variables “Purchases” and “Payments” were in dollars unit. Users in this group spend bigger amount of money in their purchases, they have also the highest level of cash in advance transaction, they make repayment back in big amount, and they have a low level of full payment (percentage). It seems like they do not like to pay back in full.
In this section, I will perform hkmeans, which is a method that combining K-means clustering and hierarchical clustering. It is a technique that can improve k-means results.
The biggest limitation of K-means clustering is that the final result is subjected to the initial random selection of centroids. However, in hkmeans, the selection of initial centroids is not based on randomisation but the result of hierarchical clustering from the hk-mean algorithm. These centroids can be understood as optimiased centroids. Therefore, in hierarchical k-means clustering, the hierarchial clustering is being performed first, then followed by the k-means clustering.
Hierarchical K-Means Clustering algorithms :
-
Step 1: Compute hierarchical clustering with the optimal K obtained from previous section (e.g., based on “WSS” of K-means). In this step, distance matrix between each pair of observation is computed and based on that, a linkage function is selected to group similar objects into hierarchical cluster tree. Each observation are considered a cluster on its on, then the forming of clustering move upward and form bigger cluster, and this step continues until the root is reached. Finally, the tree is cut into pre-specified K (which is 7 in this case).
-
Step 2: Compute the center (i.e. mean) of each cluster. Therefore, there are 7 new center here in each of the 7 clusters.
-
Step 3: Compute K-means clustering on the original standardised credit card dataset by using the set of cluster centers computed in step 2 as the initial cluster centers. Then, according to the algorithm of K-means clustering, each observations will be assigned to the closest centroid based on distance matrix (eg. euclidean). For each k-clusters, a new mean is being updated again by calculating the new mean value of all data points in the cluster. Finally, all observations are being re-allocated to these new means. The allocation of observations and the calculation of new means are iterated until the total within sum of square (WSS) is minimised.
Optimal K Search
Following silhouette method suggests 2 as the optimal K.
fviz_nbclust(cc.scale,
FUNcluster = kmeans,
method = "silhouette") Following
kmean-wss Elbow method also suggests the same, The rate of WSS reduction
become slower in second K.
Following
kmean-wss Elbow method also suggests the same, The rate of WSS reduction
become slower in second K.
fviz_nbclust(cc.scale, FUNcluster = kmeans, method = "wss")
From above result of WSS and silhouette analysis, I will use 2 as the optimal number of K for clustering.
Following code completes the hkmeans algorithm.
# Create hierarchical k-means clustering
res.hk <- hkmeans(cc.scale,
k = 2,
hc.metric = "manhattan",
hc.method = "average", # Single or Average linkage function is recommended as they are less sensitive to the skewness caused by outliers in this credit card dataset.
km.algorithm = "Hartigan-Wong")The “res.hk” object contains following results.
# Items created from the object
names(res.hk)## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault" "data"
## [11] "hclust"
These 7 clusters have following size:
res.hk$size## [1] 6926 1710
Graphical presentation of the 6 clusters:
hk.cluster <- fviz_cluster(res.hk,
palette = "jco",
geom = "point",
alpha = 0.5)
hk.cluster +
theme_classic() +
theme(plot.title = element_text(hjust = 0.5, face = "bold"),
plot.subtitle = element_text(hjust = 0.5)) +
labs(title = "Hierarchical K-means Clustering Results",
subtitle = "Hartigan-Wong algorithm + Euclidean + ward.D2 + K = 6") Plotting Radar
plot to see how distinctive each of the 2 clusters.
Plotting Radar
plot to see how distinctive each of the 2 clusters.
hk_df <- cbind(as.data.frame(cc.scale),
cluster = res.hk$cluster) %>%
mutate(cluster = as.factor(cluster)) %>%
relocate(cluster, .before = Balance_frequency)
ggRadar(hk_df, aes(group = cluster),
size = 1,
rescale = F,
use.label = F) +
theme_bw() +
labs(title = "Radar plot") +
facet_wrap(~cluster) 
Two clusters identified from the entire dataset have following sample size:
table(res.hk$cluster)##
## 1 2
## 6926 1710
set.seed(123)
hk_df_median <- hk_df %>%
as.data.frame() %>%
group_by(cluster) %>%
summarise_all(median)
ggparcoord(hk_df_median,
column = c(2:11),
groupColumn = "cluster",
scale = "globalminmax",
showPoints = T) +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "top") +
labs(title = "Parallel Coordinate Plot",
subtitle = "Showing: Median of each Variable") +
geom_text_repel(aes(label = cluster), box.padding = 0.1)
Insights:
Cluster 1: Less-active user. Most of the credit card users from this cluster use their credit card in an very infrequency manner.
Cluster 2: Active-user. These credit card users are actively using their credit card to make purchases. One off purchases is more popular than installment purchases.
This section performs an alternative to k-mean clustering. In K-mean clustering or PAM, observations are assigned to exactly 1 cluster. However, in fuzzy clustering, each observation has a probability of belong to each cluster. Points that close to the center of a cluster will have a higher probability than points that further away. It is a technique usually used for marketing in determining preference and shopping patterns of customers in a more realistic way.
Computing fuzzy algorithm:
res.fanny <- fanny(cc.scale, k = 2,
metric = "euclidean",
stand = FALSE,
memb.exp = 1.05)Showing the member coefficient
head(res.fanny$membership, 10)## [,1] [,2]
## C10001 0.999999914 8.648864e-08
## C10002 0.999820051 1.799489e-04
## C10003 0.093730995 9.062690e-01
## C10005 0.999999984 1.638830e-08
## C10006 0.761181762 2.388182e-01
## C10007 0.000172510 9.998275e-01
## C10008 0.001644969 9.983550e-01
## C10009 0.999634366 3.656337e-04
## C10010 0.971929245 2.807076e-02
## C10011 0.002505073 9.974949e-01
Following code show the cluster that each observation belongs to (extracting the first 10 observations).
head(res.fanny$clustering, 10)## C10001 C10002 C10003 C10005 C10006 C10007 C10008 C10009 C10010 C10011
## 1 1 2 1 1 2 2 1 1 2
Visualising the clusters:
fviz_cluster(res.fanny, geom = "point", repel = T,
palette = "jco")
Silhouette width (Si) is a type of interval cluster validation, with a range from 1 to -1. If an observation has a Si of closer than 1 then the point is well clustered, whereas if a point is close to -1 than it indicates that the point is poorly clustered and assigning this point to other cluster may improve the results. It can be understood that if a point has negative Si, it means that they are not in the correct cluster (Alboukadel Kassambara 2017).
fviz_silhouette(res.fanny, palette = "jco")## cluster size ave.sil.width
## 1 1 4678 0.36
## 2 2 3958 -0.03

According to the above silhouette plot that is available for Fuzzy algorithm, there are a lot of noises in figure 2 and 3, and generally all 7 clusters have a relatively low silhouette level which is a statistic used to measure clustering quality. Therefore, results from following graph is recommended to be digested with caution.
# Radar plot
fuz_df <- cbind(as.data.frame(cc.scale),
cluster = res.fanny$clustering) %>% # merge scaled data with clusters
mutate(cluster = as.factor(cluster)) %>%
relocate(cluster, .before = Balance_frequency)
ggRadar(fuz_df, aes(group = cluster),
size = 1,
use.label = T,
rescale = F) +
# Use scaled data to plot Radar, do not normalise btw 1-0 by rescale = T.
# scaled data better show subtle trends
theme_bw() +
labs(title = "Radar plot") +
facet_wrap(~ cluster)
set.seed(123)
fuz_df_median <- fuz_df %>%
as.data.frame() %>%
group_by(cluster) %>%
summarise_all(median)
ggparcoord(fuz_df_median,
column = c(2:11),
groupColumn = "cluster",
scale = "globalminmax",
showPoints = T) +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "top") +
labs(title = "Parallel Coordinate Plot",
subtitle = "Showing: Median of each Variable") +
geom_text_repel(aes(label = cluster), box.padding = 0.1)
Fuzzy clustering with 2 clusters have the similar characteristics as Hierarchical K-means clustering, which is having 2 clusters that group users into a group of less-active user and a group of active users. Some differences appear are:
Cluster 1: The preference of using cash in advance is more obvious than the cluster 1 in HKmeans in previous section.
Cluster 2: Fuzzy clustering indicates that installment-purchases is more popular than one-off purchases. However, though both are falling the same category of “purchases”. Important similarity is still preserved, users in this group is also prefer to make full repayment, and less prefer for minimum payments.
Model-based clustering also computes probabilities for each observation. However, this model-based clustering will suggest us the best k.
Algorithm used in this model-based clustering is called Expectation-Maximization algorithm (EM). In this algorithm, data are considered as coming from a mixture of two or more clusters, and all clusters may have a mixture of density.
The algorithm starts by hierarchical model-based clustering, and cut the dendrogram for different number of k. In each k, each cluster is centered at the means with increase density for points near the mean.
The geometric features (volume, shape, and orientation) of each cluster will then be determined. After this step, the similarity of volume, shape and orientation between clusters of that k will be determine using a standard parameterasation.
Fitting the model-based clustering:
res.mc <- Mclust(cc.scale)The best model is determined using the Bayesian Information Criterion or BIC. A large BIC indicates good model, and the model with highest BIC will be selected.
The model-based clustering selected a model with 8 clusters (k), the optimal selected model name is VEV, it means clusters have varying volume, equal shape, and varying orientation on the coordinate axes.
summary(res.mc)## ----------------------------------------------------
## Gaussian finite mixture model fitted by EM algorithm
## ----------------------------------------------------
##
## Mclust VEV (ellipsoidal, equal shape) model with 7 components:
##
## log-likelihood n df BIC ICL
## -23317.69 8636 407 -50324.3 -50792.31
##
## Clustering table:
## 1 2 3 4 5 6 7
## 2267 1312 385 1071 357 1356 1888
Visualising the outcome of cluster-based modeling:
mc1 <- fviz_mclust(res.mc,
what = "classification",
geom = "point",
alpha = 0.1)
mc2 <- fviz_mclust(res.mc, what = "BIC")
mc3 <- fviz_mclust(res.mc, what = "uncertainty") + labs(subtitle = "Larger symbols indicate the more uncertain observations.")## Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
## "none")` instead.
pg1 <- plot_grid(mc1, mc2)
plot_grid(pg1, mc3,
nrow = 2) Visualising the
clustering result using Radar plot:
Visualising the
clustering result using Radar plot:
# df
mc_df <- cbind(as.data.frame(cc.scale),
cluster = res.mc$classification) %>% # merge scaled data with clusters
mutate(cluster = as.factor(cluster)) %>%
relocate(cluster, .before = Balance_frequency)
# Radar plot
ggRadar(mc_df, aes(group = cluster),
size = 1,
use.label = T,
rescale = F) +
# Use scaled data to plot Radar, do not normalise btw 1-0 by rescale = T.
# scaled data better show subtle trends
theme_bw() +
labs(title = "Radar plot") +
facet_wrap(~cluster) +
theme(plot.margin = unit(c(0.1, 0.1, 0.1, 0.1), "mm"))
Alternatively, a parallel coordinate plot may help:
set.seed(111)
mc_df_median <- mc_df %>%
as.data.frame() %>%
group_by(cluster) %>%
summarise_all(median)
ggparcoord(mc_df_median,
column = c(2:11),
groupColumn = "cluster",
scale = "globalminmax",
showPoints = T) +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "top") +
labs(title = "Parallel Coordinate Plot",
subtitle = "Showing: Median of each Variable") +
geom_text_repel(aes(label = cluster), box.padding = 0.1) 
Model-based clustering identified 4 groups of cluster with following characterisation:
Based on the median of each cluster:
Cluster 1: Less active user. They don’t like to use credit card that much, but slightly more prefer to use cash-in-advance.
Cluster 2: Less active user. They don’t like to use credit card that much, but slightly more prefer to use credit card to make purchases, especially installment purchases.
Cluster 3: Revolvers, they prefer to make minimum payment back to credit card company, they prefer to make expensive purchases and therefore they have higher credit limit and make bigger payment back to credit card company, but they don’t like to make full-payment back.
Cluster 4: Less active user, but they prefer to make full payment and they very low tenure.
Cluster 5: Active card users, they buy expensive products and make big payment back to credit card company. Sometime they prefer full payment, sometime they pay minimum payments.
Cluster 6: Max Payers, but they are less active with zero level of tenure.
Cluster 7: Revolvers, they less active revolvers who prefer to make minimum payment. They spend small money for purchases on cheaper products.
Cluster 8: Max Payer, but they are active with high level of tenure.
DBSCAN stands for Density-Based Spatial Clustering for Application with Noise. It is a method that we can easily detect and extract outliers, and cluster the observations based on their main members. To compute DBSCAN algorithm, we need to specify epsilon (eps) and minimum points (MinPts).
-
For best “MinPts”, it goes with the rules that it should be large if the dataset is large, however it must be chosen at least 3. I will work with different value of MinPts to see their effects on cluster configurations.
-
For best “eps”, it can also be tried out with different values, however, I will go with the KNN method. This method will compute the K-nearest neighbor distances in a matrix of points (Alboukadel Kassambara 2017). The k specified in this case is not the optimal number of clustering but the number of k-nearest neighbor, and which corresponds to MinPts. I will plot the relevant graph and look at the “knee” (where a sharp change is about to happen), and where is the optimal value of epsilon (eps).
In my DBSCAN algorithm, I will be trying out different MinPt parameter from 3 to 8. Therefore, I computed different KNN distance plot below for respective MinPt to search for the best epsilon (eps) for each of them.
set.seed(123)
par(mfrow = c(2,3))
#
dbscan::kNNdistplot(cc.scale, k = 3) # K = MinPt, K here is KNN'K
abline(h = 1.7, lty = 2)
text(x = 2000, y = 2.1, "1.7", col = "blue")
mtext("1.7 is the optimal eps for 3 MinPt ")
dbscan::kNNdistplot(cc.scale, k = 4) # K = MinPt, K here is KNN'K
abline(h = 1.8, lty = 2)
text(x = 2000, y = 2.3, "1.8", col = "blue")
mtext("1.8 is the optimal eps for 4 MinPt ")
dbscan::kNNdistplot(cc.scale, k = 5) # K = MinPt, K here is KNN'K
abline(h = 2, lty = 2)
text(x = 2000, y = 2.5, "2", col = "blue")
mtext("2 is the optimal eps for 5 MinPt ")
#
dbscan::kNNdistplot(cc.scale, k = 6) # K = MinPt, K here is KNN'K
abline(h = 2, lty = 2)
text(x = 2000, y = 2.5, "2", col = "blue")
mtext("2 is the optimal eps for 6 MinPt ")
dbscan::kNNdistplot(cc.scale, k = 7) # K = MinPt, K here is KNN'K
abline(h = 2.2, lty = 2)
text(x = 2000, y = 2.8, "2.2", col = "blue")
mtext("2.2 is the optimal eps for 7 MinPt ")
dbscan::kNNdistplot(cc.scale, k = 8) # K = MinPt, K here is KNN'K
abline(h = 2.2, lty = 2)
text(x = 2000, y = 2.8, "2.2", col = "blue")
mtext("2.2 is the optimal eps for 8 MinPt ")
Applying above result and now start to compute DBSCAN algorithm for 6 different MinPts.
set.seed(123)
dbsscan.res.eps1 <- fpc::dbscan(cc.scale,
eps = 1.7,
MinPts = 3)
dbsscan.res.eps2 <- fpc::dbscan(cc.scale,
eps = 1.8,
MinPts = 4)
dbsscan.res.eps3 <- fpc::dbscan(cc.scale,
eps = 2,
MinPts = 5)
dbsscan.res.eps4 <- fpc::dbscan(cc.scale,
eps = 2,
MinPts = 6)
dbsscan.res.eps5 <- fpc::dbscan(cc.scale,
eps = 2.2,
MinPts = 7)
dbsscan.res.eps6 <- fpc::dbscan(cc.scale,
eps = 2.2,
MinPts = 8)
g1 <- fviz_cluster(dbsscan.res.eps1,
data = cc.scale,
stand = F) + labs(title = "MinPts = 3 with eps at 1.7")
g2 <- fviz_cluster(dbsscan.res.eps2,
data = cc.scale,
stand = F) + labs(title = "MinPts = 4 with eps at 1.8")
g3 <- fviz_cluster(dbsscan.res.eps3,
data = cc.scale,
stand = F) + labs(title = "MinPts = 5 with eps at 2")
g4 <- fviz_cluster(dbsscan.res.eps4,
data = cc.scale,
stand = F) + labs(title = "MinPts = 6 with eps at 2")
g5 <- fviz_cluster(dbsscan.res.eps5,
data = cc.scale,
stand = F) + labs(title = "MinPts = 7 with eps at 2.2")
g6 <- fviz_cluster(dbsscan.res.eps6,
data = cc.scale,
stand = F) + labs(title = "MinPts = 8 with eps at 2.2")
plot_grid(g1, g2, g3, g4, g5, g6,
nrow = 3,
ncol = 2)
From the result above, it is observed that DBSCAN algorithm may not suitable for this dataset. DBSCAN clustering works will when different distinct clusters in the dataset have similar density of points, however, all data points are too close to each other and form a high, big dense area and which may have failed the DBSCAN algorithm.
Comparing the results from CLARA, H-Kmeans, Fuzzy, model-based, and DBSCAN clustering. The VEV model from model-based clustering is able to detect 8 k, which is the largest amount of distinct clusters compared to other clustering algorithms.
Cluster 1: Less active user that prefer cash-in-advance.
Cluster 2: Less active user that prefer to use credit card to make
purchases, especially installment purchases.
Cluster 3: Revolvers who prefer to make expensive purchases.
Cluster 4: Less active users who prefer to make full repayment back to
credit card company.
Cluster 5: Active card users who make expensive purchases and make
repayment in big amount, sometime they prefer full payment, sometime
they pay minimum-payments.
Cluster 6: Max payers who prefer to pay money owe in full with zero
tenure.
Cluster 7: Less active revolvers, they spend small amount of money to
purchase cheaper products.
Cluster 8: Max Payer but this users group is more active in making
purchases than cluster 6.
If smaller amount of clusters is interested, the next best algorithm will be CLARA which suggests 5 groups of different credit card users, followed by 2 groups suggested by HKmeans and Fuzzy.
Thank you for Reading
Arjun Bhasin 2018, Credit card Dataset for Clustering, viewed 10 May 2022, https://www.kaggle.com/datasets/arjunbhasin2013/ccdata
Alboukadel Kassambara 2017, Practical Guide to Cluster Analysis in R, Multivariate Analysis 1, Edition 1, sthda.com
Clustering and dimensionality reduction techniques on the Berlin Airbnb data and the problem of mixed data (n.d.),viewed 15 May 2022 https://rstudio-pubs-static.s3.amazonaws.com/579984_6b9efbf84ee24f00985c29e24265d2ba.html
Jenny Listman 2019, Customer Segmentation / K Means Clustering, viewed 14 May 2022, https://www.kaggle.com/code/jennylistman/customer-segmentation-k-means-clustering
Matt.0 2019, 10 Tips for Choosing the Optimal Number of Clusters, viewed 12 May 2022, https://towardsdatascience.com/10-tips-for-choosing-the-optimal-number-of-clusters-277e93d72d92