이 문서는 케라스를 활용하여 ConvNets 을 앙상블 하는 방법에 대하여 설명합니다. 2018년 8월을 기준으로, 동작하지 않는 코드 부분을 동작하도록 조금 변형했기 때문에 원문의 코드와 일치하지 않을 수 있습니다. 본문 역시 그대로 번역한 것이 아닌 필요한 설명과 합쳐서 다시 쓴 글이기 때문에 원문과 다를 수 있습니다. 원문에서 나온 코드들을 이해를 돕기 위해 jupyter notebook 파일을 첨부합니다.
- 케라스
- Neural Networks layer
- CNN
- Ensemble

"통계 및 기계 학습에서 앙상블 기법은 단일 구성 학습 알고리즘만으로 얻을 수 있는 것보다 더 나은 예측 성능을 얻기 위해 여러 학습 알고리즘을 사용합니다. 일반적으로 무한한 통계 역학의 앙상블과 달리 기계 학습 앙상블은 여러 모델의 구체적인 유한 집합이지만, 대체로 그러한 모델들 사이에 훨씬 더 유연한 구조가 존재할 수 있습니다." [1]
앙상블을 사용하는 이유는 주로 그것이 만들어지는 모형의 가설 공간(hypothesis)내에 포함되지 않는 다른 가설을 찾는 것입니다. 경험적으로, 앙상블은 모델 사이의 다양성이 클 때, 더 좋은 결과를 도출하는 경향이 있습니다.[2]
여러 큰 규모의 머신러닝 경쟁대회의 결과를 보면, 상위권의 결과는 단일 모델보다는 앙상블 모델로 만들어졌을 가능성이 높습니다. 예를 들어, ILSVRC2015의 단일 모델 아키텍처의 최고 등수는 13위였습니다. 1-12위는 앙상블 구조들이 차지했습니다.
여러 신경 네트워크를 앙상블로 사용하는 방법에 대한 튜토리얼이나 문서를 보지 못했기 때문에 제가 사용하는 방식을 공유하기로 하였습니다.
저는 케라스의 API를 사용하여, 비교적 잘 알려진 논문의 3가지 작은 CNNs(ResNet50, Inception 등) 모델을 새로 만들 것입니다. CIFAR-10 학습 데이터 세트를 활용하여 각 모델을 각각 학습할 것입니다.[3] 그런 다음 각 모델을 테스트 세트를 사용하여 평가할 것입니다. 그 후 3가지 모델 모두를 앙상블하여 평가할 것입니다. 앙상블은 앙상블 내의 각각의 단일 모델보다 더 나은 성능을 낼 것으로 기대됩니다.
앙상블에는 여러 가지 방법이 있습니다; 스태킹 역시 그중 하나입니다. 보다 일반적인 방법 중 하나이며 다른 모든 앙상블 기술을 이론적으로 나타낼 수 있습니다. 스태킹은 다른 여러 학습 알고리즘의 예측을 결합하는 알고리즘을 학습하는 것과 관련이 있습니다. [1] 이 예제에서는 앙상블에서 각 모델의 결과값의 평균을 취하는 것과 관련된 가장 간단한 스태킹 중 하나를 사용하겠습니다. 평균을 취하는것은 매개 변수를 필요로 하지 않으므로 이 앙상블(모델 만)을 교육 할 필요가 없습니다.
첫 번째로 의존 라이브러리를 불러옵니다.
from keras.models import Model, Input
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, Dropout, Activation, Average
from keras.utils import to_categorical
from keras.losses import categorical_crossentropy
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras.optimizers import Adam
from keras.datasets import cifar10
import numpy as np저는 CIFAR-10 데이터 세트를 사용하고 있습니다. 이 데이터 세트를 활용하여 잘 동작하게끔 만들어진 아키텍쳐에 대한 문서를 쉽게 찾을수 있기 때문입니다. 인기있는 데이터 세트를 사용하면 이 예제를 쉽게 재현할 수 있습니다.
여기선 데이터 세트을 가져옵니다. 학습용 , 테스트용 데이터 세트는 모두 정규화 됩니다. 학습 레이블의 벡터는 one-hot-matrix로 변환됩니다. 테스트 레이블은 학습중에 쓰일일이 없기 때문에 변환이 필요없습니다.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train / 255.
x_test = x_test / 255.
y_train = to_categorical(y_train, num_classes=10)데이터 세트는 10개의 클래스를 가진 60,000개의 32x32 RGB 이미지들로 구성되어 있습니다. 학습/검증을 위해 50,000개의 이미지를, 테스트를 위해 10,000개의 이미를 사용합니다.
print('x_train shape: {} | y_train shape: {}\nx_test shape : {} | y_test shape : {}'.format(x_train.shape, y_train.shape,x_test.shape, y_test.shape))x_train shape: (50000, 32, 32, 3) | y_train shape: (50000, 10)
x_test shape : (10000, 32, 32, 3) | y_test shape : (10000, 1)
세개의 모델에서 같은 형태의 데이터를 사용할 것이므로, 모든 모델에서 사용할 단일 입력 레이어를 정의하는것이 좋습니다.
input_shape = x_train[0,:,:,:].shape
model_input = Input(shape=input_shape)제가 학습시킬 첫번째 모델은 ConvPool-CNN-C입니다. [4] 링크된 논문의 4페이지에 이 모델에 대하여 설명되어 있습니다.
이 모델은 매우 간단합니다. 여러 가지 컨볼루션 계층 뒤에 풀링 계층이 오는 공통 패턴을 특징으로합니다. 이 모델에서 몇몇 사람들에게 익숙하지 않은 유일한 부분은 최종 계층입니다. 완전히 연결된(fully-connected) 여러 개의 레이어를 사용하는 대신 전역 평균 풀링 계층(global average pooling layer)이 사용됩니다.
다음은 글로벌 풀링 계층의 작동 방식에 대한 간략한 개요입니다. 마지막 컨볼루션 계층 Conv2D (10, (1,1))은 10 개의 출력 클래스에 해당하는 10 개의 특성 맵을 출력합니다. 그런 다음 GlobalAveragePooling2D ()레이어는 이러한 10 개의 특성 맵의 공간 평균을 계산합니다. 즉, 출력은 길이가 10 인 벡터입니다. 그 후 소프트맥스 활성화가 해당 벡터에 적용됩니다. 보시다시피 이 방법은 모델 상단에서 FC 레이어를 사용하는 것과 비슷합니다. 전역 풀링 계층과 그 이점에 대한 자세한 내용은 Network in Network 문서를 참조하십시오. [5]
주목해야 할 중요한 점은 이 레이어의 출력은 먼저 GlobalAveragePooling2D ()를 거쳐야하기 때문에 마지막 Conv2D (10, (1,1)) 레이어의 출력에 활성화 기능이 적용되지 않는다는 것입니다.
def conv_pool_cnn(model_input):
x = Conv2D(96, kernel_size=(3, 3), activation='relu', padding = 'same')(model_input)
x = Conv2D(96, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(96, (3, 3), activation='relu', padding = 'same')(x)
x = MaxPooling2D(pool_size=(3, 3), strides = 2)(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = MaxPooling2D(pool_size=(3, 3), strides = 2)(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (1, 1), activation='relu')(x)
x = Conv2D(10, (1, 1))(x)
x = GlobalAveragePooling2D()(x)
x = Activation(activation='softmax')(x)
model = Model(model_input, x, name='conv_pool_cnn')
return model모델을 인스턴스화 합니다.
conv_pool_cnn_model = conv_pool_cnn(model_input)단순화를 위하여 각 모델은 동일한 매개 변수를 사용하여 컴파일되고 학습됩니다. 32의 배치 사이즈로 (1 epoch당 1250번의 스텝) 20 epoch을 사용하면 3가지 모델 중 어떤 모델이라도 국소 최소치(local minimum)를 얻는 데는 충분할 것으로 보입니다. 훈련 데이터 세트에서 무작위로 선택된 20%의 데이터가 검증에 사용됩니다.
def compile_and_train(model, num_epochs):
model.compile(loss=categorical_crossentropy, optimizer=Adam(), metrics=['acc'])
filepath = 'weights/' + model.name + '.{epoch:02d}-{loss:.2f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=0, save_weights_only=True, save_best_only=True, mode='auto', period=1)
tensor_board = TensorBoard(log_dir='logs/', histogram_freq=0, batch_size=32)
history = model.fit(x=x_train, y=y_train, batch_size=32, epochs=num_epochs, verbose=1, callbacks=[checkpoint, tensor_board], validation_split=0.2)
return history테슬라 K80 GPU 를 사용할 경우, 각 모델은 1epoch당 1분정도의 시간이 소요됩니다. CPU를 사용한다면, 좀 더 많은 시간이 걸릴 수 있습니다.
_ = compile_and_train(conv_pool_cnn_model, num_epochs=20)이 모델은 약 79%의 유효성 검사 정확도를 달성합니다.
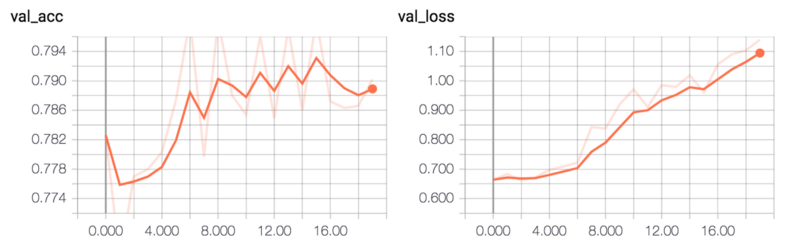
모델을 평가하는 가장 단순한 방법은 테스트 세트의 에러율을 계산하는 것입니다.
def evaluate_error(model):
pred = model.predict(x_test, batch_size = 32)
pred = np.argmax(pred, axis=1)
pred = np.expand_dims(pred, axis=1) # make same shape as y_test
error = np.sum(np.not_equal(pred, y_test)) / y_test.shape[0]
return error
evaluate_error(conv_pool_cnn_model)0.2414
다음 CNN 인 ALL_CNN_C는 첫 번째 모델과 동일한 논문에서 나온 것입니다. [4] 이 모델은 이전 모델과 매우 유사합니다. 실제로 유일한 차이점은 맥스 풀링 레이어 대신 2의 보폭을 가진 컨벌루션 레이어가 사용된다는 것입니다. Conv2D (10, (1, 1)) 레이어 바로 다음에 사용되는 활성화 기능이 없다는 점에 유의하십시오. 해당 레이어 바로 다음에서 ReLU 활성화가 사용되면 학습이 제대로 수행되지 않습니다.
def all_cnn(model_input):
x = Conv2D(96, kernel_size=(3, 3), activation='relu', padding = 'same')(model_input)
x = Conv2D(96, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(96, (3, 3), activation='relu', padding = 'same', strides = 2)(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same', strides = 2)(x)
x = Conv2D(192, (3, 3), activation='relu', padding = 'same')(x)
x = Conv2D(192, (1, 1), activation='relu')(x)
x = Conv2D(10, (1, 1))(x)
x = GlobalAveragePooling2D()(x)
x = Activation(activation='softmax')(x)
model = Model(model_input, x, name='all_cnn')
return model
all_cnn_model = all_cnn(model_input)
_ = compile_and_train(all_cnn_model, num_epochs=20)이 모델은 약 75%의 유효성 검사 정확도를 달성합니다.
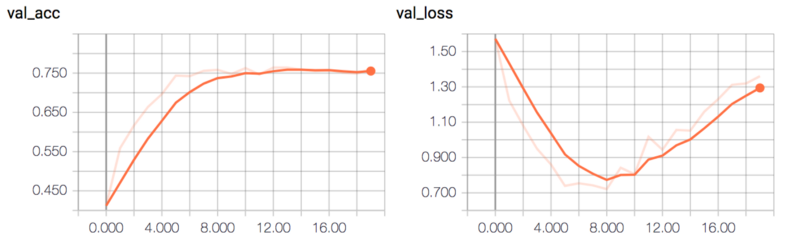
두 모델이 서로 매우 유사하기 때문에 에러율은 크게 다르지 않습니다.
0.26090000000000002
세 번째 CNN은 Network in Network CNN입니다. [5] 이것은 글로벌 풀링 레이어를 소개한 논문의 CNN입니다. 이전 두 모델보다 작으므로 훈련이 훨씬 빠릅니다. 최종 컨볼루션 레이어 후에 relu가 없습니다!
저는 MLP 컨볼루션 레이어 내에서 멀티 레이어 퍼셉트론을 사용하는 대신, 1x1 커널로 컨볼루션 레이어를 사용했습니다. 이 방법은 최적화 할 매개변수가 줄어들어 교육 속도가 빨라지고 더 나은 결과를 얻을 수 있습니다 (FC 레이어를 사용할 때 50 % 이상의 유효성 검사 정확도를 얻을 수 없습니다). 이 논문은 mlpconv 계층에 의해 적용되는 함수가 정상적인 회선 계층에서 계단식 교차 채널 파라메트릭 풀링과 동일하며 1x1 커널을 갖는 컨볼루션 계층과 동일하다는 것을 설명합니다. 아키텍쳐에 대한 저의 해석이 올바르지 않으면, 저에게 알려주세요.
def nin_cnn(model_input):
#mlpconv block 1
x = Conv2D(32, (5, 5), activation='relu',padding='valid')(model_input)
x = Conv2D(32, (1, 1), activation='relu')(x)
x = Conv2D(32, (1, 1), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Dropout(0.5)(x)
#mlpconv block2
x = Conv2D(64, (3, 3), activation='relu',padding='valid')(x)
x = Conv2D(64, (1, 1), activation='relu')(x)
x = Conv2D(64, (1, 1), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Dropout(0.5)(x)
#mlpconv block3
x = Conv2D(128, (3, 3), activation='relu',padding='valid')(x)
x = Conv2D(32, (1, 1), activation='relu')(x)
x = Conv2D(10, (1, 1))(x)
x = GlobalAveragePooling2D()(x)
x = Activation(activation='softmax')(x)
model = Model(model_input, x, name='nin_cnn')
return model
nin_cnn_model = nin_cnn(model_input)이 모델은 저의 머신에서 1epoch당 15초로 빠르게 학습됩니다.
_ = compile_and_train(nin_cnn_model, num_epochs=20)이 모델은 약 65%의 유효성 검사 정확도를 달성합니다.
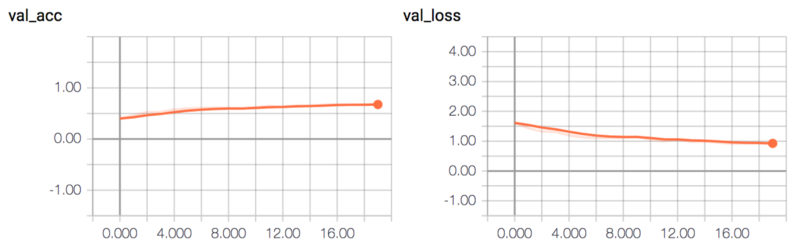
이 모델은 다른 두 모델보다 좀 더 간단하므로, 에러율이 조금 더 높습니다.
evaluate_error(nin_cnn_model)0.31640000000000001
이제 세 가지 모델 모두 앙상블로 결합됩니다.
여기서, 세가지 모델 모두가 다시 인스턴스화되고 가장 좋은 저장된 가중치가 로드됩니다.
conv_pool_cnn_model = conv_pool_cnn(model_input)
all_cnn_model = all_cnn(model_input)
nin_cnn_model = nin_cnn(model_input)
conv_pool_cnn_model.load_weights('weights/conv_pool_cnn.29-0.10.hdf5')
all_cnn_model.load_weights('weights/all_cnn.30-0.08.hdf5')
nin_cnn_model.load_weights('weights/nin_cnn.30-0.93.hdf5')
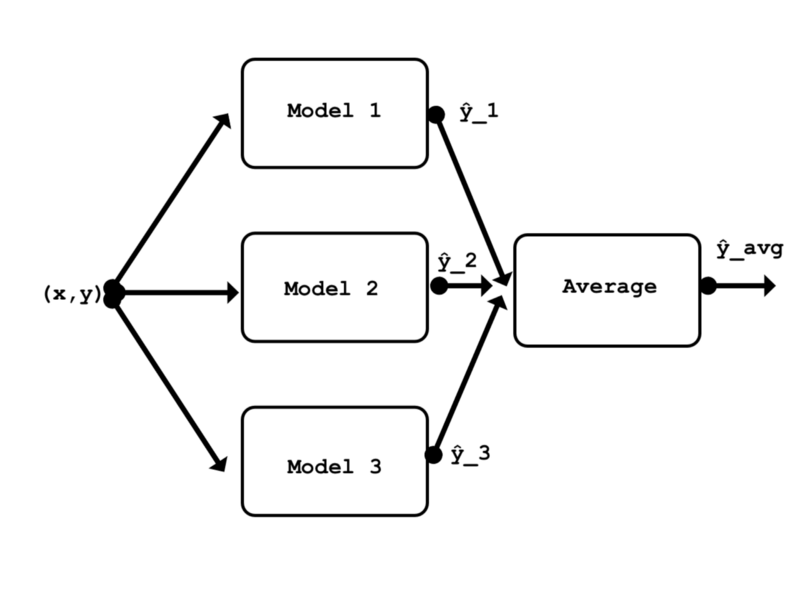
models = [conv_pool_cnn_model, all_cnn_model, nin_cnn_model]앙상블 모델의 정의는 매우 간단합니다. 이번의 모든 모델간에 공유되는 동일한 입력 레이어를 사용합니다. 가장 위의 레이어에서 앙상블은 세가지 모델의 결과를 Average() 병합 레이어를 사용하여 세 모델의 출력 평균을 계산합니다.
def ensemble(models, model_input):
outputs = [model.outputs[0] for model in models]
y = Average()(outputs)
model = Model(model_input, y, name='ensemble')
return model
ensemble_model = ensemble(models, model_input)예상대로 앙상블은 모든 단일 모델보다 에러율이 낮습니다.
evaluate_error(ensemble_model)0.2049
완벽을 기하기 위하여, 우리는 두가지 모델 조합으로 구성된 앙상블의 성능을 확인할 수 있습니다. 이 중 두 모델은 단일 모델보다 에러율이 낮습니다.
pair_A = [conv_pool_cnn_model, all_cnn_model]
pair_B = [conv_pool_cnn_model, nin_cnn_model]
pair_C = [all_cnn_model, nin_cnn_model]
pair_A_ensemble_model = ensemble(pair_A, model_input)
evaluate_error(pair_A_ensemble_model)0.21199999999999999
pair_B_ensemble_model = ensemble(pair_B, model_input)
evaluate_error(pair_B_ensemble_model)0.22819999999999999
pair_C_ensemble_model = ensemble(pair_C, model_input)
evaluate_error(pair_C_ensemble_model)0.2447
소개에서 언급한 내용을 다시 말하자면: 모든 모델은 각자의 약점을 가지고 있습니다. 앙상블을 사용하는 이유는 데이터에 대하여 다른 가설을 가지는 여러 모델을 쌓아 놓음으로써, 각각의 모델의 가설 공간(hypothesis)에 없는 더 좋은 가설을 찾을 수 있다는 것입니다.
매우 기본적인 앙상블을 사용하여도, 대부분의 경우 단일 모델을 사용했을 때보다 더 낮은 오류율을 얻을 수 있었습니다. 이것은 앙상블의 효과를 증명합니다.
물론, 기계 학습 작업을 위해 앙상블을 사용할 때 명심해야 할 몇 가지 실제적인 고려 사항이 있습니다. 앙상블은 여러 모델을 쌓기 때문에 각 모델에 대해 입력 데이터를 순방향 전파해야 함을 의미합니다. 이렇게하면 수행해야 할 계산량이 늘어나고 결과적으로 평가 (예측) 시간이 길어집니다. 연구나 Kaggle 대회에서 앙상블을 사용하여 평가 시간이 증가하는 것은 그다지 치명적이지 않습니다. 그러나 상용 제품을 설계 할 때는 매우 중요한 요소입니다. 또 다른 고려 사항은 상업용 제품에서 앙상블 사용함으로써 발생하는 최종 모델의 크기 증가입니다.
이 포스트의 쥬피터 노트북의 HTML 버전은 이곳에서 볼 수 있습니다.
쥬피터 노트북의 소스코드는 이곳에서 확인할 수 있습니다.
이 기사를 쓸 때, 몇가지 부분을 변경하여서 (대부분 말투와 오타입니다.) 쥬피터 노트북과 내용이 조금 다를 수 있습니다.
이 글은 2018 컨트리뷰톤에서
Contributue to Keras프로젝트로 진행했습니다.
Translator : 김설기 , mike2ox (Moonhyeok Song)
Translator Email : ksulki@gmail.com,firefinger07@gmail.com