MIT JOS 2016
[TODO] move branch graph to master
[TODO] move all readme to master
- 前面lab的知识
- git的知识
- mit lab3
测分make grade
提交make clean && make handin
我的改动git diff finish_lab3~3 finish_lab3~1
这个lab的任务是提供一个用户保护的运行环境,需要增强JOS内核,建立一个数据结构来跟踪记录用户环境
创建单用户的用户环境,把运行程序镜像载入,并运行
你的内核还要能够相应 用户环境里程序的 系统调用 以及 异常
注:在这个lab里 术语environment(环境)和process(进程)是可互换的,都是指一个可以运行程序的地方,这里用environment(环境)是为了 区分 JOS environments and UNIX processes provide different interfaces。
和上一个lab一样先获取lab3的代码,再合并上lab2完成的代码,我的过程如下
> git checkout -b lab3 origin/lab3
> git checkout -b finish_lab3
> git merge finish_lab2 --no-commit
> vim GNUmakefile
> vim kern/monitor.c
> vim kern/pmap.c
> vim lib/printfmt.c
> rm README.md
> git rm README.md
> git add .
> git commit -m "manual merge finish_lab2 to lab3"
> git diff lab3 finish_lab3 --stat
conf/env.mk | 2 +-
kern/kdebug.c | 5 +++++
kern/monitor.c | 15 ++++++++++++++-
kern/pmap.c | 128 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++------------------------------
lib/printfmt.c | 8 +++-----
5 files changed, 121 insertions(+), 37 deletions(-)lab3 的新文件.....
| folder | file | description |
|---|---|---|
| inc/ | env.h | Public definitions for user-mode environments |
| trap.h | Public definitions for trap handling | |
| syscall.h | Public definitions for system calls from user environments to the kernel | |
| lib.h | Public definitions for the user-mode support library | |
| kern/ | env.h | |
| env.c | Kernel code implementing user-mode environments | |
| trap.h | Kernel-private trap handling definitions | |
| trap.c | Trap handling code | |
| trapentry.S | Assembly-language trap handler entry-points | |
| syscall.h | Kernel-private definitions for system call handling | |
| syscall.c | System call implementation code | |
| lib/ | Makefrag | Makefile fragment to build user-mode library, obj/lib/libjos.a |
| entry.S | Assembly-language entry-point for user environments | |
| libmain.c | User-mode library setup code called from entry.S | |
| syscall.c | User-mode system call stub functions | |
| console.c | User-mode implementations of putchar and getchar, providing console I/O | |
| exit.c | User-mode implementation of exit | |
| panic.c | User-mode implementation of panic | |
| user/ | Various test programs to check kernel lab 3 code |
或者 你可以通过输入git diff finish_lab2 --stat查看
make grade 为本lab的测试,但通过测试并不说明你的代码就完全正确,可能有未测试到的错误,影响未来的lab :-)
也就是说如果你的代码出错了,也可能是lab1,lab2的残留错误:-)
作者推荐了两种debug方法,gdb或者inline汇编
阅读inc/env.h,可以看到Env结构体,内核要用该结构体来跟踪 用户环境 [嗨呀 感觉中文翻译得僵硬得一逼]
其中struct Trapframe可以在inc/trap.h中找到
这个lab 只需要一个用户环境,但下一个lab需要多个用户环境,所以你需要设计的是能支持多用户环境的
接下来看到kern/env.c
struct Env *envs = NULL; // 所有的 environments
struct Env *curenv = NULL; // 当前的 current env
static struct Env *env_free_list; // 空闲的 environment list
内核用这三个来控制用户环境
内核运行开始时,envs指向一个 Env数组(该数组一一对应所有的environment ) 和之前Page的思想类似
在jos里,作者设计的是最多同时运行NENV个environment,虽然实际测试的运行数量远小于这个值...也就是说 初始化时NENV是数组的个数....
Environment State
struct Env {
struct Trapframe env_tf; // Saved registers
struct Env * env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t * env_pgdir; // Kernel virtual address of page dir
};变量说明
env_tf:
这个结构体用于保存寄存器,当environment不处于运行泰德时候,也就是内核切换environment时用的。
env_link:
用于`env_free_list`,指向下一个空闲environment
env_id:
内核用该值储存一个唯一标识 比如(i.e., using this particular slot in the envs array). 在一个用户environment终止后,内核可用重申请同一个Env结构用于不同的environment,尽管是重用,但新的environment会有不同的env_id.
env_parent_id:
内核用该值存创建该environment的environment 这样environment就可以形成一个树,可以用于做安全判断environment是否被允许对某物做某事.
env_type:
用于区分`ENV_TYPE_USER`(大多数)和`ENV_TYPE_IDLE`,在未来的lab里会用
env_status:
ENV_FREE: 非活跃 在`env_free_list`中
ENV_RUNNABLE: 活跃 已准备好 等待run
ENV_RUNNING: 活跃 当前正在 run
ENV_NOT_RUNNABLE: 活跃 但未准备好 比如在等待另一给environment的 interprocess communication (IPC)
env_pgdir:
保存kernel virtual address of this environment's page directory.
env_cr3:
保存对应的environment's page directory的物理地址
Like a Unix process, a JOS environment couples the concepts of "thread" and "address space". The thread is defined primarily by the saved registers (the env_tf field), and the address space is defined by the page directory and page tables pointed to by env_pgdir and env_cr3. To run an environment, the kernel must set up the CPU with both the saved registers and the appropriate address space.
Env和xv6里的proc类似.都保存用户态的寄存器in a Trapframe structure. In JOS, 个人环境 没有它们自己的内核栈 as processes do in xv6. There can be only JOS environment active in the kernel at a time, so JOS needs only a single kernel stack.
lab2 里我么在mem_init()中给pages[]数组申请了空间,类似的现在你需要在mem_init()中给envs[]申请空间
- 修改
kern/pmap.c中的mem_init()申请并映射envs数组. 需要NENV个Env大小,同时envs需要user read-only,让用户是只读的,最终让check_kern_pgdir()执行正确.
看inc/memlayout.h看到UENVS这一块大小为PTSIZE
所以新增两段代码为(在对应提示的位置)
envs = (struct Env * ) boot_alloc(NENV * sizeof (struct Env ));
boot_map_region(kern_pgdir,UENVS , PTSIZE , PADDR(envs) , PTE_U);
运行make qemu-nox可以看到
check_kern_pgdir() succeeded!
check_page_installed_pgdir() succeeded!
kernel panic at kern/env.c:460: env_run not yet implemented
注意这里就要提到lab2 实现的page_init了,请看我的lab2的文档中关于page_init的第四部分申请的修改,当时就是因为有已经申请使用的被误认为未使用除了错,而改为了PGNUM(PADDR(boot_alloc(0))),这里我们又申请了新的envs的数组,它依旧能正确运行,而不需要再次修改:-)
因为我们尚无文件系统,我们要运行的程序都是嵌入在kernel内部的,作为elf镜像嵌入,见上方的文件夹说明,我们将要运行的源程序都在user/里,编译后的在obj/user/里,这里编译用的是-b 而不会生成.o类型,然后还有魔法名字例如_binary_obj_user_hello_start,_binary_obj_user_hello_end,:-) 总之大自意思是编译过程很神奇就是了,它和普通的执行程序不同:-)。
你可以在kern/init.c的i386_init()中看到运行这些用户程序:-) 目测是#if defined这个宏里,但是建立用户环境的功能并没实现,刚刚只是申请了一一对应的数组,把仅内核读写的位置映射到了用户只读的位置。
在kern/env.c中实现以下函数
env_init() 初始化envs并且把它们加入env_free_list. 并调用env_init_percpu()(它配置段硬件 分段为权限0(内核)权限3(用户)),参照pages_init()实现如下
void
env_init(void)
{
// Set up envs array
int i;
for (i = 0 ; i < NENV ; i++ ) {
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
// Per-CPU part of the initialization
env_init_percpu();
}env_setup_vm() 申请一个页目录 for a new environment 并初始化这个新的environment的地址空间的内核部分
并不会写,然后看到代码上的注释讲初始化,申请,设置e->env_pgdir,返回值,已有的代码申请了页,设置了e->env_pgdir,但env_pgdir是个指针,看用法是个数组,所以我们要把env_pgdir指向页,注释中还提示kern/pmap.h中的函数有帮助,实现如下
e->env_pgdir = page2kva(p);
p->pp_ref++ ;
for(i = PDX(UTOP) ; i < NPDENTRIES ; i++ )
e->env_pgdir[i]=kern_pgdir[i];这里建立一个独自的pgdir,但只拷贝UTOP以上,但因为之前也没写过UTOP以下,故可以用memmove(e->env_pgdir, kern_pgdir, PGSIZE);代替[inc/string.h没有memcpy...],目前看来 把kern_pgdir复制了一份放到e->env_pgdir并设置UVPT在PD中的对应位置的PDE,所以以后va转换 怎么用这个PD了?
region_alloc(struct Env *e, void *va, size_t len)
申请len字节的物理地址地址空间,并把它映射到虚拟地址va上,不要 初始化为0或其它操作,页需要能被用户写,如果任何步骤出错panic,注释提示注意页对齐
回想lab2 我们有把物理地址和虚拟地址的映射的函数,也有把虚拟地址和Page做映射的函数,Page更好操作,实现思路为
- 计算va起始和末尾
- for(起始->末尾){
- 申请页//不要做任何初始化操作
-
申请失败则panic - 把该页和for的va映射 注意权限位
- }
实现如下[这里我们传入page_insert的是e->env_pgdir而不再是kern_pgdir]
uintptr_t va_start = (uintptr_t)ROUNDDOWN(va ,PGSIZE);
uintptr_t va_end = (uintptr_t)ROUNDUP (va + len,PGSIZE);
uintptr_t i ;
for ( i = va_start ; i < va_end ; i += PGSIZE) {
struct Page * pg = page_alloc(0); // Does not zero or otherwise initialize the mapped pages in any way
if (!pg)
panic("region_alloc failed!");
page_insert(e->env_pgdir, pg, (void *)i , PTE_W | PTE_U);
}这个函数功能,在环境e下的va地址开始申请了len的空间
load_icode(struct Env *e, uint8_t *binary, size_t size)
用来解析ELF二进制文件的,和boot loader已经完成了的很像,把文件内容装载进新的用户环境.
看注释,该函数只会在内核初始化时,第一个用户模式环境开始前,调用,
该函数把ELF文件装载到适当的用户环境中,从适当的虚拟地址位置开始执行,清零程序头部标记的段(但不清.bss等的),可以参考boot/main.c (该部分是从磁盘读取的)
我们只需要load ph->p_type == ELF_PROG_LOAD的,
- 每个段的虚拟地址
ph->p_va - 内存大小
ph->p_memsz字节 - 文件大小
ph->p_filesz字节 - 需要把
binary + ph->p_offset拷贝到ph->p_va,其余的内存需要被清零 - 对于用户可写
- ELF 段不必页对齐,可以假设没有两个段会使用同一个虚拟页面
- 建议函数
region_alloc - Loading the segments is much simpler if you can move data directly into the virtual addresses stored in the ELF binary. So which page directory should be in force during this function?
- 在程序入口还需要干些事,看下方的
env_run和env_pop_tf
直接看boot/main.c中的bootmain()函数,其中readseg为读磁盘,之后为获得ph,把ph~eph读入内存,执行,那我们的实现思路为
- 读取binary 判断是否为ELF
- 切换cr3 这也就看出了我们上面
e->env_pgdir的作用,这样内核的kern_pgdir不在变,要执行一个程序的时候装载该程序的e->env_pgdir即可,因为该e->env_pgdir拷贝自kern_pgdir由加上了自己的使用的pde,又因为上面的假设 虚拟页不会重复,我们申请内存时用的page_alloc这个依然是kernel统一管理,所以那么不同的程序之间也就不会冲突,这样不同程序的切换就改变cr3即可 - for(ph~eph){
-
注意判断是否为`ELF_PROG_LOAD` -
通过`region_alloc`来申请va以及memsz -
清零所有 -
复制程序 filesz - }
- 复原cr3 为
kern_pgdir
实现如下
struct Elf * elf = (struct Elf *) binary;
struct Proghdr *ph, *eph;
// is this a valid ELF?
if (elf->e_magic != ELF_MAGIC)
panic("load_icode failed! invalid ELF!");
ph = (struct Proghdr *) ((uint8_t *) elf + elf->e_phoff);
eph = ph + elf->e_phnum;
lcr3(PADDR(e->env_pgdir));
for (; ph < eph; ph++){
if (ph->p_type == ELF_PROG_LOAD) {
region_alloc(e, (void *)ph->p_va, ph->p_memsz);
memset((void *)ph->p_va, 0, ph->p_memsz);
memmove((void *)ph->p_va, binary + ph->p_offset, ph->p_filesz);
}
}
lcr3(PADDR(kern_pgdir));
// entry point
// Now map one page for the program's initial stack
// at virtual address USTACKTOP - PGSIZE.
region_alloc(e, (void *) (USTACKTOP - PGSIZE), PGSIZE);这个函数的功能在环境e下,拷贝并解析了binary指向的ELF程序,并不懂第三个参数size要干嘛,这里的entry point要怎么搞
env_create()
用env_alloc申请 environment并 调用load_icode来装载ELF binary到申请的environment中.
又是说只会在kernel初始化的时候执行一次,并且new environment的parent id设为0
看env_alloc
// Allocates and initializes a new environment.
// On success, the new environment is stored in *newenv_store.
//
// Returns 0 on success, < 0 on failure. Errors include:
// -E_NO_FREE_ENV if all NENVS environments are allocated
// -E_NO_MEM on memory exhaustion
//
int
env_alloc(struct Env **newenv_store, envid_t parent_id)实现代码为
void
env_create(uint8_t *binary, size_t size, enum EnvType type)
{
struct Env *e;
int ret = env_alloc(&e, 0);
if(ret == -E_NO_FREE_ENV )
panic("env_create failed! all NENVS environments are allocated");
if(ret == -E_NO_MEM )
panic("env_create failed! memory exhaustion");
e->env_type = type;
load_icode(e, binary, size);
}env_run(struct Env *e) 在用户态运行给的e.文档说panic的%e对输出错误有帮助 demo如下
r = -E_NO_MEM;
panic("env_alloc: %e", r);.....然后我把上一个函数的错误处理改了
if(ret < 0)
panic("env_create: %e", ret);看注释
- 如果有正在运行的程序并且不是它自己,则把当前运行的程序设为RUNNABLE (
curenv,env_status) - 设置当前正在运行的为e (
curenv,env_status) - 更新
e->env_runs的计次 - 和上面一样用
lcr3()切换cr3 - 用
env_pop_tf()重新加载环境寄存器 - 检查之前的函数
e->env_tf的值是否正确
实现如下
if (curenv == e)
return ;
if(curenv && curenv->env_status == ENV_RUNNING)
curenv->env_status = ENV_RUNNABLE;
curenv = e;
e->env_status = ENV_RUNNING;
e->env_runs++;
lcr3(PADDR(e->env_pgdir));
env_pop_tf(&e->env_tf);然后make 告诉我This function does not return......然后改成
if (curenv != e){
if(curenv && curenv->env_status == ENV_RUNNING)
curenv->env_status = ENV_RUNNABLE;
curenv = e;
e->env_status = ENV_RUNNING;
e->env_runs++;
lcr3(PADDR(e->env_pgdir));
env_pop_tf(&e->env_tf);
}然而依然不对...
把env_pop_tf(&e->env_tf);移到if外来就对了 但感觉逻辑很奇怪_(:з」∠)_
load_icode的entry
boot/main.c执行的是((void (*)(void)) (ELFHDR->e_entry))();
要设置的e中的env_tf的只有tf_eip了
所以entry point的设置为e->env_tf.tf_eip = elf->e_entry;
Note: 就算你实现了这部分,你仍然无法正常执行用户程序,因为你还没有配置IDT(中断 描述 表), 因此用户程序无法返回内核态. 因此任何需要内核帮助的用户程序会fail 引发三重 fault. 因此 你完成这部分会看到类似[........] new env [........] ,继续往后
这里我make qemu-nox
[00000000] new env 000013ff
kernel panic at kern/env.c:502: PADDR called with invalid kva 00000000
对应的语句为lcr3(PADDR(e->env_pgdir));
........... 然后错误是因为它运行的是envs[0]而我的env_init的free_list是倒着连的......所以把 它按照free->0->1->2...的方式连 :-) 真的无语 改为如下
void
env_init(void)
{
// Set up envs array
int i;
for (i = NENV - 1 ; i >=0 ; --i ) {
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
// Per-CPU part of the initialization
env_init_percpu();
}这样make qemu-nox就可以看到 类似如下的无限循环了
[00000000] new env 00002000
至此 我们实现了程序装入 运行 切换
确保你知道执行顺序
start (kern/entry.S)i386_init (kern/init.c)cons_initmem_initenv_inittrap_init (still incomplete at this point)env_createenv_runenv_pop_tf
/*
Once you are done you should compile your kernel and run it under QEMU. If all goes well, your system should enter user space and execute the hello binary until it makes a system call with the int instruction. At that point there will be trouble, since JOS has not set up the hardware to allow any kind of transition from user space into the kernel. When the CPU discovers that it is not set up to handle this system call interrupt, it will generate a general protection exception, find that it can't handle that, generate a double fault exception, find that it can't handle that either, and finally give up with what's known as a "triple fault". Usually, you would then see the CPU reset and the system reboot. While this is important for legacy applications (see this blog post for an explanation of why), it's a pain for kernel development, so with the 6.828 patched QEMU you'll instead see a register dump and a "Triple fault." message.
We'll address this problem shortly, but for now we can use the debugger to check that we're entering user mode. Use make qemu-gdb and set a GDB breakpoint at env_pop_tf, which should be the last function you hit before actually entering user mode. Single step through this function using si; the processor should enter user mode after the iret instruction. You should then see the first instruction in the user environment's executable, which is the cmpl instruction at the label start in lib/entry.S. Now set a breakpoint at the static inline int32_t syscall(...) located in lib/syscall.c. If you cannot execute as far as the syscall() function, then something is wrong with address space setup or program loading code; go back and fix it before continuing. Another thing need to be noticed is that there are actually 2 functions named syscall, make sure you set the breakpoint at the right one.
*/terminal 1> make qemu-nox-gdb
terminal 2> make gdb
(gdb) b env_pop_tf
(gdb) c
Continuing.
The target architecture is assumed to be i386
0xf01031c5 <env_pop_tf>: push %ebp
Breakpoint 1, env_pop_tf (tf=0xf01c0000) at kern/env.c:460
460 {
(gdb) si
0xf01031c6 <env_pop_tf+1>: mov %esp,%ebp
0xf01031c6 460 {
(gdb) si
0xf01031c8 <env_pop_tf+3>: sub $0x18,%esp
0xf01031c8 460 {
(gdb) si
0xf01031cb <env_pop_tf+6>: mov 0x8(%ebp),%esp
461 __asm __volatile("movl %0,%%esp\n"
(gdb) si
0xf01031ce <env_pop_tf+9>: popa
0xf01031ce 461 __asm __volatile("movl %0,%%esp\n"
(gdb) b syscall
Breakpoint 2 at 0xf0103c6e: file {standard input}, line 91.
(gdb) si
0xf01031cf <env_pop_tf+10>: pop %es
0xf01031cf in env_pop_tf (tf=???) at kern/env.c:461
461 __asm __volatile("movl %0,%%esp\n"
(gdb) si
0xf01031d0 <env_pop_tf+11>: pop %ds
0xf01031d0 461 __asm __volatile("movl %0,%%esp\n"
(gdb) si
0xf01031d1 <env_pop_tf+12>: add $0x8,%esp
0xf01031d1 461 __asm __volatile("movl %0,%%esp\n"
(gdb) si
0xf01031d4 <env_pop_tf+15>: iret
0xf01031d4 461 __asm __volatile("movl %0,%%esp\n"
(gdb) si
0x800020: cmp $0xeebfe000,%esp
0x00800020 in ?? ()
(gdb) si
0x800026: jne 0x80002c现在 int $0x30 (sysenter) 用户的系统调用是一个死循环,一旦从内核态进入用户态就回不来了,现在要实现基本的 exception和系统调用的处理,以致内核能从用户态代码拿回处理器控制权
- Read Chapter 9, Exceptions and Interrupts in the 80386 Programmer's Manual (or Chapter 5 of the IA-32 Developer's Manual), if you haven't already.[:-) sjtu的图都是没做备份的 这里我放的mit的链接]
~~如果能认真看完文档 还有什么上课的必要呢 :-) ~~
Exceptions 和 interrupts 都是protected control transfers,都是让处理器从 用户态(CPL=3) 转为 内核态(CPL=0) 同时也不会给用户态代码任何干扰内核运行的机会,在intel的术语中interrupt通常为处理器外部异步事件引起的 保护控制传输,比如外部I/O活动,作为对比exception为同步事件引起的 保护控制传输,例如除0,访问无效内存
为了确保这些 保护控制传输 能真正的起到保护作用,因此设计的是当 exception或interrupt发生时,并不是任意的进入内核,而是处理器要确保内核能控制才会进入,用了以下两个方法:
- The Interrupt Descriptor Table
也就是上面提到的未设置的IDT,该表让processer确定 内核能对特定的中断 有特定的入口点 而不会继续执行错误的代码,x86允许256个不同的 interrupt/exception 入口点 也就是interrupt vector (也就是0~255的整数),数值由中断类型决定,CPU用interrupt vector的值作为index在IDT中找值放入eip,也就是指向内核处理该错误的到函数入口,加载到代码段(CS)寄存器中的值,其中第0-1位包括要运行异常处理程序的权限级别。 (在JOS中,所有异常都在内核模式下处理,权限级别为0)
简单的说就是 不同的错误(interrupt/exception)会发出不同的值(0~255)然后cpu再根据该值 在IDT中找处理函数入口,所以我们的任务要去配置IDT表 以及实现对应的处理函数
- The Task State Segment.
在中断前 需要保存当前程序的寄存器等 在处理完后回重新赋值这些寄存器 所以保存的位置需要不被用户修改 否则在重载时可能造成危害
因此x86在 处理interrupt/trap时 模式从用户转换到内核时,它还会转换到一个内核内存里的栈(一个叫做TSS(task state segment )的结构体),处理器把SS, ESP, EFLAGS, CS, EIP, and an optional error code push到这个栈上,然后它再从IDT的配置 设置CS和EIP的值,再根据新的栈设置esp和ss
虽然 TSS很大并有很多用途,但对于lab对于jos我们只用它来定义处理器在从用户模式 转换到内核模式时,应切换的堆栈,因为x86上JOS在kernel态的权限级别为0,在进入内核模式时,处理器用TSS的ESP0 和SS0两个字段来定义内核栈 ,JOS不使用其它的TSS字段
x86 能生成的所有同步exceptions 的值(interrupt vector) 在0~31,比如page fault 会触发14号,>31的部分是给软件中断使用的,可以由int 指令生成 或外部异步硬件产生
这个section 我们要处理0-31的,下一个section我们要处理软件中断vector 48 (0x30),lab 4 要处理外部硬件中断 如时钟中断
然后文档决定把上面讲的都连在一起,用一个example来说明,如果用户程序 执行 除0
-
处理器根据TSS的SS0 和ESP0字段切换栈(这两个字段在JOS会分别设为
GD_KD和KSTACKTOP) -
处理器按照以下格式push exception参数到 内核栈上
+--------------------+ KSTACKTOP | 0x00000 | old SS | " - 4 | old ESP | " - 8 | old EFLAGS | " - 12 | 0x00000 | old CS | " - 16 | old EIP | " - 20 <---- ESP +--------------------+
-
因为我们要处理 除0 错误,对应 interrupt vector的值为0,在x86中 处理器去读配置的IDT表配置的0号的入口 然后设置CS:EIP指向该入口
-
然后该处理函数处理 比如终止用户程序之类的事
对于明确的错误 比如上面的除0 ,处理器还会把 错误号push上去 也就是interrupt vector
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20
| error code | " - 24 <---- ESP
+--------------------r
处理器在 内核态和用户态 都可以处理 exceptions和interrupts.但只有从用户态转换到内核态时 在push old 寄存器前,处理器会自动转换栈,并根据IDT配置调用适当的exception处理程序。如果发生 interrupt/exception时 已经在内核态( CS寄存器的低两位为0), 那么CPT只会push 更多的值在同一个内核栈上,这种情况下,内核可以优雅的处理 内核自己引发的 嵌套exceptions.这种能力是实现保护的重要途径 我们将在后面的section的系统调用中看到.
如果说 发生exceptions或interrupts时本身就在内核态,那么也就不需要储存old SS和EIP,以不push error code 的为例,内核栈长这样
+--------------------+ <---- old ESP
| old EFLAGS | " - 4
| 0x00000 | old CS | " - 8
| old EIP | " - 12
+--------------------+
一个重要需要注意的是,内核处理嵌套exceptions的有限能力,若已经在内核态并接受到一个exception,而且还不能push它old state到内核栈上(比如栈空间不够了),那么这样处理无法恢复,因此它会简单的reset它自己,我们不应让这样的情况发生(想想微软蓝屏:-) )
上面讲了这么多前人设计的结果,下面终于要在该设计思想和模拟硬件上搞事情了。
上面讲完了,你也就知道IDT是个啥了,我们将要设置 IDT的031,一会还要设置system call interrupt,在未来的lab会设置3247(device IRQ)
阅读inc/trap.h和kern/trap.h, inc/trap.h定义了 一些interrupt vector的常量宏和两个数据结构PushRegs和Trapframe,kern/trap.h则定义的是两个全局变量extern struct Gatedesc idt[];和extern struct Pseudodesc idt_pd;以及一堆函数的申明
关于Gatedesc和Pseudodesc这两个结构体的定义可以在inc/mmu.h中找到
文档说 0~31 有些是保留定义的,但在lab里并不会由processer产生,它们的处理函数怎么写也无所谓,写你认为最简洁的处理,,,,简而言之就是只写你实现了的处理函数,整个流程如下所画
IDT trapentry.S trap.c
+----------------+
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
| | // do stuff {
| | call trap // handle the exception/interrupt
| | // ... }
+----------------+
| &handler2 |--------> handler2:
| | // do stuff
| | call trap
| | // ...
+----------------+
.
.
.
+----------------+
| &handlerX |--------> handlerX:
| | // do stuff
| | call trap
| | // ...
+----------------+
每一个 exception/interrupt 需要在trapentry.S有它自己的handler, trap_init()函数要做的是把 IDT中填上这些handler函数的地址,每一个handler需要建立一个struct Trapframe 在//do stuff的位置,然后 调用trap.c中的trap函数,然后trap再处理具体的exception/interrupt或者分发给再具体的处理函数
编辑trapentry.S和trap.c实现上面描述的. 在trapentry.S中的宏TRAPHANDLER和TRAPHANDLER_NOEC对你会有帮助.你需要用inc/trap.h中定义的宏 在trapentry.S定义入口函数, 你还需要提供TRAPHANDLER 宏引用的_alltraps. 你还需要编辑trap_init()初始化idt 来指向每一个 trapentry.S中拟定已的entry point; SETGATE宏会有帮助.
你的_alltraps应该满足:
- 按照Trapframe 的结构push值
- 装载
GD_KD到 %ds和 %es - pushl %esp 传递一个指向 Trapframe 的指针作为 trap()的参数
- call trap (can trap ever return?)
考虑使用pushal 指令 它和struct Trapframe很契合,通过google到pusha的工作 看到了pusha契合的是PushRegs结构 也就是PushRegs注释中所写的
用user/下的代码测试你写的处理程序,它们会引发一些 exceptions 比如 用户/除零,你需要能够 make grade通过 divzero, softint, and badsegment tests at this point.
先看宏TRAPHANDLER(name, num)注释说你需要在c中定义一个类似void NAME();然后把NAME作为参数传给这个函数,num为错误号,TRAPHANDLER_NOEC 是NO ERROR CODE的版本 :-) 多pushl了一个$0,注释说保持结构一样,对照上方的 图,可以看到没有push的会少一个push,这两个宏实际是函数模板,这里我们用这两个宏来实现上面图中trapentry.S的handlerX的部分,关于哪个vector会push 错误号 可以参考这里
在根据trap.h里定义的,实现为
/*
* Lab 3: Your code here for generating entry points for the different traps.
*/
TRAPHANDLER_NOEC( ENTRY_DIVIDE , T_DIVIDE ) /* 0 divide error*/
TRAPHANDLER_NOEC( ENTRY_DEBUG , T_DEBUG ) /* 1 debug exception*/
TRAPHANDLER_NOEC( ENTRY_NMI , T_NMI ) /* 2 non-maskable interrupt*/
TRAPHANDLER_NOEC( ENTRY_BRKPT , T_BRKPT ) /* 3 breakpoint*/
TRAPHANDLER_NOEC( ENTRY_OFLOW , T_OFLOW ) /* 4 overflow*/
TRAPHANDLER_NOEC( ENTRY_BOUND , T_BOUND ) /* 5 bounds check*/
TRAPHANDLER_NOEC( ENTRY_ILLOP , T_ILLOP ) /* 6 illegal opcode*/
TRAPHANDLER_NOEC( ENTRY_DEVICE , T_DEVICE ) /* 7 device not available*/
TRAPHANDLER ( ENTRY_DBLFLT , T_DBLFLT ) /* 8 double fault*/
/*TRAPHANDLER_NOEC( ENTRY_COPROC , T_COPROC )*/ /* 9 reserved (not generated by recent processors)*/
TRAPHANDLER ( ENTRY_TSS , T_TSS ) /* 10 invalid task switch segment*/
TRAPHANDLER ( ENTRY_SEGNP , T_SEGNP ) /* 11 segment not present*/
TRAPHANDLER ( ENTRY_STACK , T_STACK ) /* 12 stack exception*/
TRAPHANDLER ( ENTRY_GPFLT , T_GPFLT ) /* 13 general protection fault*/
TRAPHANDLER ( ENTRY_PGFLT , T_PGFLT ) /* 14 page fault*/
/*TRAPHANDLER_NOEC( ENTRY_RES , T_RES )*/ /* 15 reserved*/
TRAPHANDLER_NOEC( ENTRY_FPERR , T_FPERR ) /* 16 floating point error*/
TRAPHANDLER_NOEC( ENTRY_ALIGN , T_ALIGN ) /* 17 aligment check*/
TRAPHANDLER_NOEC( ENTRY_MCHK , T_MCHK ) /* 18 machine check*/
TRAPHANDLER_NOEC( ENTRY_SIMDERR , T_SIMDERR) /* 19 SIMD floating point error*/这样 我们 完成了handlerX中 具有每个特性的东西,
下面在_alltraps中实现它们共性的东西——按照Trapframe结构铺数据 【还需要在c中定义函数名哦!】
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));below注释以下的是硬件push的,tf_trapno是我们刚刚 用TRAPHANDLER模板实现的,那我们现在还剩下的就是把 顶部5个push,设置ds和es,再把最后的栈顶地址 作为结构体首部地址压栈 调用trap(也就是上面写的应该满足),实现如下
/*
* Lab 3: Your code here for _alltraps
*/
_alltraps:
pushw $0
pushw %ds
pushw $0
pushw %es
pushal
movw $GD_KD,%ds
movw $GD_KD,%es
pushl %esp
call trap
...然后我试了试movw这样并不可行,然后换成了:-) 或者直接movw $0x10
pushw $GD_KD
popw %ds
pushw $GD_KD
popw %es接下来 开始实现trap函数trap_init 要用宏 SETGATE(gate, istrap, sel, off, dpl)在inc/mmu.h中
首先声明前面汇编中的函数名
extern void ENTRY_DIVIDE ();/* 0 divide error*/
extern void ENTRY_DEBUG ();/* 1 debug exception*/
extern void ENTRY_NMI ();/* 2 non-maskable interrupt*/
extern void ENTRY_BRKPT ();/* 3 breakpoint*/
extern void ENTRY_OFLOW ();/* 4 overflow*/
extern void ENTRY_BOUND ();/* 5 bounds check*/
extern void ENTRY_ILLOP ();/* 6 illegal opcode*/
extern void ENTRY_DEVICE ();/* 7 device not available*/
extern void ENTRY_DBLFLT ();/* 8 double fault*/
//extern void ENTRY_COPROC ();/* 9 reserved (not generated by recent processors)*/
extern void ENTRY_TSS ();/* 10 invalid task switch segment*/
extern void ENTRY_SEGNP ();/* 11 segment not present*/
extern void ENTRY_STACK ();/* 12 stack exception*/
extern void ENTRY_GPFLT ();/* 13 general protection fault*/
extern void ENTRY_PGFLT ();/* 14 page fault*/
//extern void ENTRY_RES ();/* 15 reserved*/
extern void ENTRY_FPERR ();/* 16 floating point error*/
extern void ENTRY_ALIGN ();/* 17 aligment check*/
extern void ENTRY_MCHK ();/* 18 machine check*/
extern void ENTRY_SIMDERR();/* 19 SIMD floating point error*/然后配置IDT表 要注意的是根据文档INTO,INT 3,BOUND,INT n是允许软件中断 dpl需要设置为3
SETGATE(idt[T_DIVIDE ],0,GD_KT,ENTRY_DIVIDE ,0);
SETGATE(idt[T_DEBUG ],0,GD_KT,ENTRY_DEBUG ,0);
SETGATE(idt[T_NMI ],0,GD_KT,ENTRY_NMI ,0);
SETGATE(idt[T_BRKPT ],0,GD_KT,ENTRY_BRKPT ,3);
SETGATE(idt[T_OFLOW ],0,GD_KT,ENTRY_OFLOW ,3);
SETGATE(idt[T_BOUND ],0,GD_KT,ENTRY_BOUND ,3);
SETGATE(idt[T_ILLOP ],0,GD_KT,ENTRY_ILLOP ,0);
SETGATE(idt[T_DEVICE ],0,GD_KT,ENTRY_DEVICE ,0);
SETGATE(idt[T_DBLFLT ],0,GD_KT,ENTRY_DBLFLT ,0);
//SETGATE(idt[T_COPROC ],0,GD_KT,ENTRY_COPROC ,0);
SETGATE(idt[T_TSS ],0,GD_KT,ENTRY_TSS ,0);
SETGATE(idt[T_SEGNP ],0,GD_KT,ENTRY_SEGNP ,0);
SETGATE(idt[T_STACK ],0,GD_KT,ENTRY_STACK ,0);
SETGATE(idt[T_GPFLT ],0,GD_KT,ENTRY_GPFLT ,0);
SETGATE(idt[T_PGFLT ],0,GD_KT,ENTRY_PGFLT ,0);
//SETGATE(idt[T_RES ],0,GD_KT,ENTRY_RES ,0);
SETGATE(idt[T_FPERR ],0,GD_KT,ENTRY_FPERR ,0);
SETGATE(idt[T_ALIGN ],0,GD_KT,ENTRY_ALIGN ,0);
SETGATE(idt[T_MCHK ],0,GD_KT,ENTRY_MCHK ,0);
SETGATE(idt[T_SIMDERR],0,GD_KT,ENTRY_SIMDERR,0);至此 若用户除零中断发生->硬件检测并push需要push的值->硬件根据我们在trap_init()中SETGATE配的IDT表找到我们的处理函数入口-> 该处理函数是由trapentry.S中TRAPHANDLER模板实现,并调用_alltraps->_alltraps在之前push的基础上再push上Trapframe结构体相复合的数据 放置其头部地址(指针)->调用trap(已经由作者实现)->调用trap_dispatch(需要我们补充)这里divzero ,softint以及badsegment都只是print_trapframe+env_destroy
执行make grade 根据检测代码 他检测到了应有的print_trapframe打出的,Part A 30分已经到手
为什么每一个exception/interrupt需要一个独立的处理函数,因为有的处理器不会push错误号,如果用同一个处理函数则无法区分错误类型。
你有任何办法让user/softint 的行为如代码所写也就是产生int $14,评测程序期望它会产生 a general protection fault (trap 13),但 softint的c代码写的int $14.,为什么需要产生$13?如果内核允许softint的int $14 指令来调用 内核的页缺失(14)会怎样?
把c代码改一改:-), 来看上面的SETGATE的dpl注释 也就是说 上面我们设置了入口的所有错误号 都是由系统级别产生,比如除0,是用户代码在除0,但是产生int 0 是由系统级别(硬件?)产生的,用户不能自己使用int 0,所以如果要让 softint(程序int,软件int),那就把对应的权限位dpl 设为3即SETGATE(idt[T_PGFLT ],0,GD_KT,ENTRY_PGFLT ,3);(!!!但并不一应该这样做)
// - dpl: Descriptor Privilege Level -
// the privilege level required for software to invoke
// this interrupt/trap gate explicitly using an int instruction.以上
错误发生->硬件int->硬件根据IDTR寄存器的前部分得到IDT的地址->硬件根据IDT找函数入口->硬件push->硬件进入函数入口->处理函数push->trap()
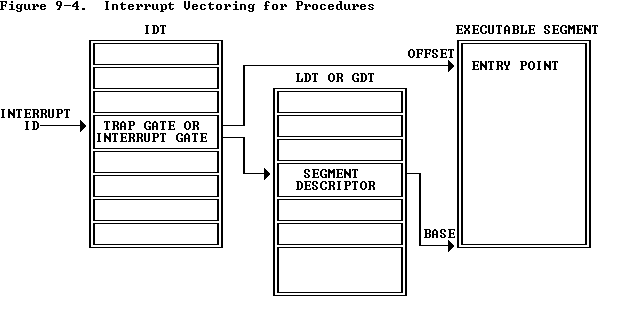
现在有基本处理机制了(就是把用户程序给结束掉:-) ),现在你需要实现更强大的exception的处理机制
The page fault exception, interrupt vector 14 (T_PGFLT), 是一个至关重要的一个中断:-)(前面的lab只实现了页的工作相关函数,测试都是用硬编码测试没有中断机制). 当处理器产生了一个page fault,,它会保存引发错误的线性/虚拟地址到CR2. 作者已经在trap.c中的page_fault_handler()实现了部分(kernel态的page fault没有处理),我们之后需要完全实现它.
刚刚错误的传输途径 IDT->_alltraps->trap->trap_dispatch,
编辑trap_dispatch()来分发页错误到page_fault_handler() 然后需要通过make grade的faultread, faultreadkernel, faultwrite, and faultwritekernel tests.测试,你可以用make run-x或make run-x-nox来运行特殊的用户程序 ,比如make run-faultread-nox.
You will further refine the kernel's page fault handling below, as you implement system calls.
实现如下 值得注意的是page_fault_handler 是无返回的 它会销毁当前的用户程序 所以 这里有没有break是一样的
static void
trap_dispatch(struct Trapframe *tf)
{
// Handle processor exceptions.
// LAB 3: Your code here.
switch(tf->tf_trapno){
case T_DIVIDE:
cprintf("trap T_DIVIDE:divide error\n");
break ;
case T_GPFLT:
cprintf("trap T_DIVIDE:general protection fault\n");
break ;
case T_PGFLT:
page_fault_handler(tf);
break;
default:
cprintf("trap no=%d\n",tf->tf_trapno);
break ;
}用户程序通过使用系统调用来 让内核帮它们完成它们自己权限所不能完成的事情,当用户程序调用系统调用时 处理器进入内核态,处理器+内核合作一起保存用户态的状态,内核再执行对应的系统调用的代码,完成后再返回用户态。但用户如何调用系统调用的内容和过程因系统而异。
在JOS里我们使用sysenter指令,你需要在kern/init.c中配置MSRs,来允许用户调用系统调用
程序会用寄存器传递系统调用号和系统调用参数,系统调用号放在%eax中,参数依次放在%edx,%ecx,%ebx, %edi中,内核执行完后返回值放在%eax中,在lib/syscall.c的syscall()函数中已经写好了汇编的系统调用函数的一部分,你也许需要修改这个函数,如处理返回值或消除冗余的寄存器保存但不要修改sysenter指令
If our instruction can alter the condition code register, we have to add "cc" to the list of clobbered registers.
If our instruction modifies memory in an unpredictable fashion, add "memory" to the list of clobbered registers. This will cause GCC to not keep memory values cached in registers across the assembler instruction. We also have to add the volatile keyword if the memory affected is not listed in the inputs or outputs of the asm.
使用 sysenter 和 sysexit 指令实现系统调用,sysenter/sysexit 指令设计得比int/iret快. 它们用寄存器而不是用栈,并把对segmentation寄存器的使用做了规定.这些指令具体细节可以在in Volume 2B of the Intel reference manuals中找到.或者这里
最简单的方式对 这两个函数的支持是在kern/trapentry.S中加上sysenter_handler 来帮助保存必须的寄存器. (Trapframe结构体很好的提示了哪些需要保存,并且你需要确定保存了正确的用户环境 返回地址 和 栈指针). 因此 和上面call trap不同,push syscall要的参数再直接调用syscall ,一旦syscall返回,重设置所有保存了的并执行sysexit指令.
你还需要在kern/init.c添加设置必要的 model specific registers (MSRs)的代码. 查看这里的enable_sep_cpu(),在inc/x86.h中你可以找到一个wrmsr的实现.最后lib/syscall.c 需要修改以支持用 sysenter来系统调用. 下面是sysenter指令的寄存器 设计结构,用户请求需要按照该格式:
eax - syscall number
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
esi - return pc
ebp - return esp
esp - trashed by sysenter
GCC's 内联汇编不支持直接把值放入ebp,所以你可以用push+pop来放入ebp (以及esi和其它寄存器). 返回地址放入esi可以用类似如下指令leal after_sysenter_label, %%esi
Note,这种只支持4个参数,如果你想支持5个需要自己搞.最后你需要实现kern/syscall.c中的syscall(),确保 系统调用号是无效的时候syscall()返回-E_INVAL. 你需要阅读并理解lib/syscall.c (尤其是内联汇编代码) inc/syscall.h的代码会有帮助. 在下一个lab,我们开启异步interrupts时 你还需要再看你的代码,特别的在返回用户程序时你需要重新启用interrupt,sysexit并不会自动启用.
资料说
中断门
- 清除了EFLAGS中的IF(interrupt flag)位,因此它成为服务硬件中断的理想选择(中断门和陷阱门唯一区别is that an interrupt gate will disable further processor handling of hardware interrupts, making it especially suitable to service hardware interrupts)
- 更多用于硬件
陷阱门
- 更多用于软件
任务门
- a task gate will cause the currently active task-state segment to be switched, using the hardware task switch mechanism to effectively hand over use of the processor to another program, thread or process. 用来程序切换
- 与上两个的描述符不同i,t
这里也就是需要重新启用的原因
先整理一下system call要干嘛
- 从
inc/trap.h的T_SYSCALL可以看到 syscall的错误号是48,不属于硬件产生的,它是用户行为 是用户可调用的(或者通过上面描述的可以知道) - 从
inc/syscall.h可以看到syscall目前有7种号,其名字可以看出它们的功能 - 从
kern/syscall.c可以看到对应上面7种号的函数 部分已经实现
也就是说[值得注意的是 这里有两个syscall函数 一个是用户可见的一个是用户不可见的]
- 用户调用
lib/syscall.c里的具体函数,全部都同意调用syscall函数(lib/syscall.c)发起调用 - syscall push参数并使用sysenter
- sysenter 以不同于int 的方式进入内核态
When SYSENTER is called, CS is set to the value in IA32_SYSENTER_CS. SS is set to IA32_SYSENTER_CS + 8. EIP is loaded from IA32_SYSENTER_EIP and ESP is loaded from IA32_SYSENTER_ESP. The CPU is now in ring 0, with EFLAGS.IF=0, EFLAGS.VM=0, EFLAGS.RF=0. -
sysenter 会产生 int 48? 通过[这种方法](http://wiki.osdev.org/SYSENTER#Introduction)找到`sysenter_handler`处理后调用syscall -
调用`kern/syscall.c`的syscall -
syscall根据号分发到 不同的具体函数 -
返回`kern/syscall.c`的syscall
× sysexit 会
- sysexit
When SYSEXIT is called, CS is set to IA32_SYSENTER_CS+16. EIP is set to EDX. SS is set to IA32_SYSENTER_CS+24, and ESP is set to ECX.Notes: ECX and EDX are not automatically saved as the return address and Stack Pointer. These need to be saved in Ring 3. - 返回syscall(lib/syscall.c)
所以我们要做的事有
- 实现syscall(lib/syscall.c) 的的push, sysenter,返回值处理 ,sysexit
- 设置MSRs 启用sysenter/sysexit
- 实现
sysenter_handler对传来的调用(这里提示用struct Trapframe) 然后根据syscall(kern/syscall.c)的参数push - 写IDT 把
sysenter_handler配置到 48(sysenter/T_SYSCALL)的位置 - 实现
kern/syscall.c的syscall的分发
那就从最简单无脑的开始:-),kern/syscall.c路由分发嘛 对照这inc/syscall.h 实现如下
// Dispatches to the correct kernel function, passing the arguments.
int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
// Call the function corresponding to the 'syscallno' parameter.
// Return any appropriate return value.
switch(syscallno){
case SYS_cputs:
sys_cputs((char *)a1,(size_t)a2);
return 0;
case SYS_cgetc:
return sys_cgetc();
case SYS_getenvid:
return sys_getenvid();
case SYS_env_destroy:
return sys_env_destroy((envid_t) a1);
case SYS_map_kernel_page:
return sys_map_kernel_page((void*) a1, (void*) a2);
case SYS_sbrk:
return sys_sbrk((uint32_t)a1);
case NSYSCALLS:
default:
return -E_INVAL;
}
}然后实现kern/trapentry.S里的sysenter_handler,然后目前理解的是
- 前面是通过idt找到入口,按照Trapframe补充结构剩余参数,调用
_alltraps(修改es/ds切换到内核态) 调用内核代码trap(Trapframe * tf) 处理, - 这里 我们通过新的方法写MSRs 而不是idt,找到sysenter的处理入口,按照syscall的参数格式push参数,调用syscall,
值得注意的有
- 参数按照上面 描述的arg的顺序进行push,而它的值来源是 "lib/syscall.c"中嵌入汇编的
"a" (num),"d" (a1),"c" (a2),"b" (a3),"D" (a4)定义的 - 不需要再像trap那样 设置es和ds 这里由sysenter指令 转换
- call以后的并不能写到
lib/syscall.c的内联汇编中[也许是我写法不对?]
sysenter_handler:
pushl %edi
pushl %ebx
pushl %ecx
pushl %edx
pushl %eax
call syscall
movl %ebp, %ecx
movl %esi, %edx
sysexit实现了sysenter_handler这里我们采取 写MSRs来让处理器能找到函数入口,参照这里和这里
在kern/trap.c中加上 声明和 MSRs的设置
extern void sysenter_handler();
wrmsr(0x174, GD_KT, 0); /* SYSENTER_CS_MSR */
wrmsr(0x175, KSTACKTOP, 0); /* SYSENTER_ESP_MSR */
wrmsr(0x176, sysenter_handler, 0);/* SYSENTER_EIP_MSR */最后来实现一下lib/syscall.c中的syscall
根据上面图的结构eax,edx, ecx, ebx, edi已经由 volatile对应实现,还需要设置esi和ebp分别为返回的指令地址和返回的esp,提示有leal after_sysenter_label, %%esi
新增的代码实现如下
"leal after_sysenter_label%=, %%esi\n\t"
"movl %%esp,%%ebp\n\t"
"sysenter\n\t"
"after_sysenter_label%=: \n\t"然后make grade发现wrmsr的实现并没有,mit给的链接里能找到,把它加入到inc/x86.h中
/* If your binutils don't accept this: upgrade! */
#define rdmsr(msr,val1,val2) \
__asm__ __volatile__("rdmsr" \
: "=a" (val1), "=d" (val2) \
: "c" (msr))
#define wrmsr(msr,val1,val2) \
__asm__ __volatile__("wrmsr" \
: /* no outputs */ \
: "c" (msr), "a" (val1), "d" (val2))至此make grade可以通过testbss,看代码也就是 用户调用cprintf了
然后发现mit的使用sysenter实际是mit的challenge,,,,其实很多sjtu要求必做的都是mit的challenge :-)
那不用sysenter,用IDT+int的方法呢,对于内核要做的调用 和上面一样,不同的是 怎样触发和接受处理中断
在trap_dispatch中加上
case T_SYSCALL:
tf->tf_regs.reg_eax = syscall(
tf->tf_regs.reg_eax,
tf->tf_regs.reg_edx,
tf->tf_regs.reg_ecx,
tf->tf_regs.reg_ebx,
tf->tf_regs.reg_edi,
tf->tf_regs.reg_esi);
return ;在trap_init加上 注意权限位是3
extern void ENTRY_SYSCALL();/* 48 system call*/
SETGATE(idt[T_SYSCALL],0,GD_KT,ENTRY_SYSCALL,3);用户程序 starts running at the top of lib/entry.S. 在一些配置后 代码调用在lib/libmain.c中的libmain(). 你需要修改libmain()初始化全局指针thisenv指向当前用户环境的Env. (提示Part A lib/entry.S已经定义了 envs 指向UENVS个.) 提示看inc/env.h并使用sys_getenvid.
libmain()然后调用umain(),也就是 每一个函数的主函数,user/hello在主函数结束后 它尝试访问thisenv->env_id. 之前你没有实现,这里会报错. 现在应该正确了,如果还报错请检查 它的是否是用户可读(back in Part A in pmap.c; this is the first time we've actually used the UENVS area).
在libmain()添加代码 让user/hello能输出 "i am environment 00001000". user/hello 然后尝试sys_env_destroy()来退出 (see lib/libmain.c and lib/exit.c). 因为现在只有一个用户环境 因此内核应该 报告销毁了唯一用户环境 并进入内核monitor. 你需要make grade 通过 hello 测试.
sys_getenvid() 可以得到当前env_id,通过kern/env.c中envid2env()函数中的方式,实现如下
thisenv = &envs[ENVX(sys_getenvid())];你需要写sbrk() 可以通过man sbrk看到描述, 它可以扩展程序的heap. 也就是动态申请内存. 实际上malloc在heap上申请就用的该系统调用.int sys_sbrk(uint32_t increment); 增加单签程序的increment字节大小数据空间. 成功的话sbrk()返回当前程序的断点. NOTE: 和标准的sbrk()行为有些区别.
对于实现你只需要申请多个页并把它们插入到页表的正确的位置, growing the heap higher. load_icode()的行为may act as a hint. 你也许需要修改Env的结构来记录当前程序的断点,并根据sbrk()来更新,在你完成后 你需要通过make grade的sbrktest测试.
理清顺序,用户程序调某个需要动态申请内存的函数->该函数调用给用户的sbrk(lib/syscall.c的sys_sbrk())->该sys_sbrk()通过我们上面写好的syscall的途径进入到kern/syscall.c的sys_sbrk()->sys_sbrk()去调kern的分配内存region_alloc((struct Env *e, void *va, size_t len)
根据inc/memlayout.h中USTACKTOP等描述 看到STACK的增长是向地址小的增长,再看已有的几个 有load_icode为程序内分配 虚拟地址的 和 为栈分配第一次栈空间的,那我们sbrk只为栈heap服务
所以我们在inc/env.h的Env结构中加上 以下 来记录heap底部
uintptr_t env_heap_bottom;在kern/env.c中load_icode申请了USTACKTOP位置的PGSIZE大小后初始化
region_alloc(e, (void *) (USTACKTOP - PGSIZE), PGSIZE);
e->env_heap_bottom = (uintptr_t)ROUNDDOWN(USTACKTOP - PGSIZE,PGSIZE);最后在kern/syscall.c中实现sbrk
static int
sys_sbrk(uint32_t inc)
{
region_alloc(curenv, (void *) (curenv->env_heap_bottom - inc), inc);
return curenv->env_heap_bottom = (uintptr_t)ROUNDDOWN(curenv->env_heap_bottom - inc,PGSIZE);
}除了以上代码还需要 把region_alloc的static去掉并在kern/env.h中加上声明
至此make grade通过了sbrktest
断点异常 也就是int 3(T_BRKPT),是允许调试程序向用户代码中临时"插入/取代"的断点指令,在jos中我们将轻微的滥用该指令,将它转化为任何用户程序都可以用来调用内核monitor的 原始伪系统....这种方法也有它的合理性,比如你可以直接把jos kernel看成一个原始调试器, 比如用户模式下lib/panic.c中的panic在输出panic信息后会while(1){int 3}
编辑trap_dispatch()让 断点异常能调用kernel monitor.你现在需要通过make grade 的breakpoint测试,在这之后你需要 修改 JOS kernel monitor以支持GDB-style 调试命令c, si and x. c 告诉GDB 从刚刚的位置继续执行, si 意味 一条一条指令执行, and x 表示打印内存. 你需要理解EFLAGS寄存器的位的含义.你的si需要调用debuginfo_eip() 输出当前eip的信息,and x 需要输出连续4字节的数据 .
先看kern/monitor.c的monitor(struct Trapframe *tf)接受参数tf,那在trap_dispatch中加上
case T_BRKPT:
cprintf("trap T_BRKPT:breakpoint\n");
monitor(tf);
return ;注意这里用的是return 而不是break ,我这里设计的逻辑 是
- 接受到int 3 打开monitor
- 用户如果 输入c/si则 退出monitor 返回用户程序继续执行 而不是把程序 destroy掉
关于eflags可以在wiki或者 inc/mmu.h的注释中看到
用户代码 int 3->陷入内核trap->通过trap_dispatch调用monitor->等待输入,首先我们在kern/monitor.c和kern/monitor.h中和其他指令一样 加上三个指令
int mon_c(int argc, char **argv, struct Trapframe *tf);
int mon_si(int argc, char **argv, struct Trapframe *tf);
int mon_x(int argc, char **argv, struct Trapframe *tf);and
{ "c", "GDB-style instruction continue.", mon_c },
{ "si", "GDB-style instruction stepi.", mon_si },
{ "x", "GDB-style instruction examine.", mon_x },接下来 当输入c时 我们只需要继续执行即可 那么让 monitor返回即可 观察到if (runcmd(buf, tf) < 0) break;也就是返回值为负即可,需要注意 在无用户程序运行时 也会接受这三个指令 ,而它们的区别在与tf是否为NULL(:-)终于知道lab1的tf有啥用了)
实现如下
//continue
int
mon_c(int argc, char **argv, struct Trapframe *tf){
if(tf)//GDB-mode
return -1;
cprintf("not support continue in non-gdb mode\n");
return 0;
}然后是stepi 根据wiki把Trap flag置为1即可
//stepi
int
mon_si(int argc, char **argv, struct Trapframe *tf){
if(tf){//GDB-mode
tf->tf_eflags |= FL_TF;
struct Eipdebuginfo info;
debuginfo_eip((uintptr_t)tf->tf_eip, &info);
cprintf("tf_eip=%08x\n%s:%u %.*s+%u\n",
tf->tf_eip,info.eip_file, info.eip_line, info.eip_fn_namelen, info.eip_fn_name, tf->tf_eip - (uint32_t)info.eip_fn_addr);
return -1;
}
cprintf("not support stepi in non-gdb mode\n");
return 0;
}有趣的是我运行make run-breakpoint-nox得到trap no=1也就是我前面trap_dispatch中做的未处理int的报告 然后在inc/trap.h中找到该号对应T_DEBUGdebug exception,可以看到第一次T_BRKPT是由用户int 3 指令引起,而通过FL_TF设置后程序运行则由处理器产生T_DEBUG,于是再在trap_dispatch中加上
case T_DEBUG:
cprintf("trap T_DEBUG:debug exception\n");
monitor(tf);
return ;又发现在si以后c也每次都是T_DEBUG说明 它不会自己清除FL_TF位 所以再修改为
//continue
int
mon_c(int argc, char **argv, struct Trapframe *tf){
if(tf){//GDB-mode
tf->tf_eflags &= ~FL_TF;
return -1;
}
cprintf("not support continue in non-gdb mode\n");
return 0;
}然后 是mon_x接受一个地址 实现如下 [TODO 如果在这时请求的是一个无效地址会崩么]
//examine
int
mon_x(int argc, char **argv, struct Trapframe *tf){
if(tf){//GDB-mode
if (argc != 2) {
cprintf("Please enter the address");
return 0;
}
uintptr_t examine_address = (uintptr_t)strtol(argv[1], NULL, 16);
uint32_t examine_value;
__asm __volatile("movl (%0), %0" : "=r" (examine_value) : "r" (examine_address));
cprintf("%d\n", examine_value);
return 0;
}
cprintf("not support stepi in non-gdb mode\n");
return 0;
}make grade得到70/90 目测这里测了一下如文档一样x,si,x,c
我的这里没有spawn???[TODO]
The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to SETGATE from trap_init). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?
如何初始化 记得权限给用户可发出即3,和上面的为什么int 14触发了int 13一个道理。
What do you think is the point of these mechanisms, particularly in light of what the user/softint test program does?
因为 如果用户乱触发一些 有可能对kernel造成危险的 应该被进制,比如页错误会让内核难以/无法管理页,但int 3 kern只是对相应的用户环境里进行暂停 不会对kernel或其它用户环境破坏 所以可以被用户去触发
内存保护是 操作系统的一个重要的功能,确保一个程序的bug不会破坏操作系统和其它程序.操作系统总是依赖于硬件的支持来实现内存保护. 操作系统记录了哪些虚拟地址是有效的,哪些是无效的. 当一个程序尝试访问无效的地址或者它没有权限的地址, 处理器在这个引发fault的程序的指令位置停止然后trap进into the kernel with information about the attempted operation. 如果fault可以修复,则内核可以修复它 让程序继续运行,如果不能修复则 不会执行该指令及以后的指令.
一个修复的例子,考虑自动增加的stack. 在很多系统中 内核初始化只申请了一个stack页, 如果一个程序访问的超过了页大小,内核需要申请新的页让程序继续 通过这样内核只申请这个程序真实需要的stack内存, 但在程序看来 它一直有很大内存.
系统调用 给内存保护带来了一个有趣的问题.大多数系统调用接口允许用户传递指向内核传递了一个指针,这些指针指向用户的用来读或者写的buffer,然后内核使用这些指针工作,有两个问题
内核里的页错误相对于用户的页错误是有更大的潜在危险。如果内核页错误 管理它自己的数据结构 那会引起内核bug, and the fault handler should panic the kernel (and hence the whole system). 但是当内核 使用这些用户给的指针 应该只属于用户的行为错误 不应产生内核bug。
内核有更多的内存读写权限.用户传来的指针也可能指向一个 内核才有权限的地址 内核需要能分辨 它对用户的权限是否满足要求(可能是private 数据 或者 破坏内存的完整性)
根据上面两个原因 都应该 小心的处理用户程序.
你可以用审查所有从用户传给内核的指针的方法 来 解决了这两个问题 检查它是否是用户可访问 以及它是否已经分配 .
如果本身内核的页错误,那内核应该panic并终止
修改kern/trap.c 使之若在kernel mode 发生页错误 则panic,提示通过 tf_cs的低位检测当前处于什么模式
阅读kern/pmap.c中的user_mem_assert()函数并实现user_mem_check()函数.
修改kern/syscall.c以至能健全的检查系统调用的参数.
运行user/buggyhello 用户环境应当被销毁 但内核不应panic. 你应该看到:
[00001000] user_mem_check assertion failure for va 00000001 [00001000] free env 00001000 Destroyed the only environment - nothing more to do!
最后修改kern/kdebug.c中的debuginfo_eip 让它调用user_mem_check on usd, stabs, and stabstr. If you now run user/breakpoint, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into lib/libmain.c before the kernel panics with a page fault. What causes this page fault? You don't need to fix it, but you should understand why it happens.
Note 你刚刚实现的机制对malicious user applications 也试用(such as user/evilhello)
一步一步,先kern/trap.c的page_fault_handler加上 是否是内核态的检测
if ((tf->tf_cs & 0x3) == 0)
panic("kernel page fault");然后看user_mem_assert 发现它是对user_mem_check的一个封装,如果user_mem_check出错 user_mem_assert就直接destroy用户环境了
user_mem_check说 va 和len都没有页对齐 你应该检查它覆盖的所有部分,权限应满足perm | PTE_P 地址应小于ULIM,如果出错设置user_mem_check_addr的值为第一个出错的虚拟地址,正确返回0,失败返回-E_FAULT
回顾pte_t * pgdir_walk(pde_t *pgdir, const void *va, int create)函数 传入 (页目录,虚拟地址,是否新建) 返回 页表项,实现如下
int
user_mem_check(struct Env *env, const void *va, size_t len, int perm)
{
uintptr_t va_start = (uintptr_t) va;
uintptr_t va_end = (uintptr_t) va + len ;
uintptr_t va_iterator;
perm |= PTE_P;
for (va_iterator = va_start; va_iterator < va_end; va_iterator = ROUNDDOWN(va_iteratoridx+PGSIZE, PGSIZE)) {
if (va_iterator >= ULIM) {
user_mem_check_addr = va_iterator;
return -E_FAULT;
}
pte_t * pte = pgdir_walk (env->env_pgdir, (void*)va_iterator, 0);
if ( pte == NULL || (*pte & perm) != perm) {
user_mem_check_addr = va_iterator;
return -E_FAULT;
}
}
return 0;
}然后开始 使kern/syscall.c中的函数健全,sys_cputs中
user_mem_assert(curenv, (void*)s, len, PTE_U);最后修改kern/kdebug.c函数 搜索3找到 LAB 3的注释加上对usd,stabs,stabstr的地址的检测,注意大小的sizeof 要用对 不要用成sizeof(指针),实现如下
if (user_mem_check(curenv, usd, sizeof(struct UserStabData), PTE_U) < 0)
return -1;and
if (user_mem_check(curenv, stabs , stab_end -stabs , PTE_U) < 0)
return -1;
if (user_mem_check(curenv, stabstr, stabstr_end-stabstr, PTE_U) < 0)
return -1;至此make grade已经85/90 只有evilhello2没有通过
需要通过evilhello的测试点,和上面同样的原因,已经通过,这个evilhello.c的注释里有mua ha ha!蛇精病吧
Modern OSes (such as Linux and Windows) often provide some interfaces which allows user application to access kernel memory or physical memory. Many malicious user applications could take advantage of these features to attack the kernel. [:-) 一脸茫然 比如我之前听说的 rowhammer也是有关???]
在JOS中 有一种简单的系统调用叫做sys_map_kernel_page 用户程序可以用这个函数把内核页 映射到用户空间(userspace)
evilhello2.c 希望执行一些evil()函数里的特权操作. ring0_call()把函数指针作为参数. 它调用提供的函数指针在ring0 privilege(kernel) 然后返回到 ring3(user). 这有一些办法来实现它. 你需要按照下面注释中的指令来进入ring0.
sgdt 是一个x86架构中的非特权指令. 它把保存GDT描述符保存到一个提供的地址. 在映射 page contains GDT into user space之后, 我们可以在GDT中设置一个调用门. 调用们(Call gate)是x86架构中一种跨特权控制转换机制.在设置了 call gate以后. 程序可以使用lcall (far call) 指令来调用segment specified in callgate entry (For example, kernel code segment). 地啊用了以后, lret指令可以用来返回到原来的 segment中.更多的Callgate请参考intel手册.
完成ring0_call() 你应当看到在page fault后出现IN RING0!!! . (the function evil() is called twice, one in ring0 and one in ring3).
To make your life easier 666666666666, mmu.h 提供了一些工具宏和数据结构(SETCALLGATE, SEG, struct Pseudodesc, struct Gatedesc ...) 你可以使用它们来管理GDT.
Note: 如果你覆盖了GDT中的一些 entry. 请在返回ring3前恢复它们,否则你的系统可能并不能正确运行.
考虑实现步骤
- sgdt 来知道gdt的地址
- 知道了地址,用
sys_map_kernel_page来吧gdt映射到用户可编辑!? - 用SETCALLGATE和前面设置IDT类似的来设置GDT(位置i) 指向我们新设计一个函数F入口
- 内联汇编根据F的参数压栈
- lcall 位置i
- F(){执行evil 并 lret}
- 恢复 覆盖掉的GDT
这里没有找到lcall的和gdt关系的文档,虽然本身文档上说After setting up the call gate. Applications may use lcall (far call) instruction to call into the segment specified in callgate entry (For example, kernel code segment). 也用 设置gdt[? >> 3] + lcall ?,$0成功调用了[TODO 具体的文档]
kern/env.c可以看到gdt只有0x0~0x28 虽然理论上 如果 gdt 有开更大的空间,那么gdt[0x30 >> 3]+lcall $0x30,$0这样也可以,但这里我们作为用户攻击内核,默认不能对内核代码修改,因此 这里选用的GD_EVIL只能是0x0~0x28的8的倍数,然而前面三个为内核服务,我们就算进攻也需要内核支持,所以真实取值只有0x18,0x20,0x28 (通过grep -r "GD_" * | grep define指令可以查看)【讲道理都不是很理想,可以实验在gdt初始化时多申请数组大小,再去写那个位置也能成功】
实现如下
char user_gdt[PGSIZE*2];
struct Segdesc *gdte_ptr,gdte_backup;
static void (*ring0_call_func)(void) = NULL;
static void
call_fun_wrapper()
{
ring0_call_func();
*gdte_ptr = gdte_backup;
asm volatile("leave");
asm volatile("lret");
}and
// Invoke a given function pointer with ring0 privilege, then return to ring3
void ring0_call(void (*fun_ptr)(void)) {
// 1.
struct Pseudodesc gdtd;
sgdt(&gdtd);
// 2.
int r;
if((r = sys_map_kernel_page((void* )gdtd.pd_base, (void* )user_gdt)) < 0){
cprintf("ring0_call: sys_map_kernel_page failed, %e\n", r);
return ;
}
ring0_call_func = fun_ptr;// DONT MOVE THIS BEFORE SYS_MAP_KERNEL_PAGE
// 3.
struct Segdesc *gdt = (struct Segdesc*)((uint32_t)(PGNUM(user_gdt) << PTXSHIFT) + PGOFF(gdtd.pd_base));
//cprintf("(user_gdt,gdt) = (%08x,%08x)\n", (uint32_t)user_gdt,(uint32_t)gdt);
int GD_EVIL = GD_UD; // 0x8 * n 0x18(GD_UT) 0x20(GD_UD) 0x28(GD_TSS0)
gdte_backup = *(gdte_ptr = &gdt[GD_EVIL >> 3]);
SETCALLGATE(*((struct Gatedesc *)gdte_ptr), GD_KT, call_fun_wrapper, 3);
// 4. 5. 6. 7.
asm volatile ("lcall %0, $0" : : "i"(GD_EVIL));至此make grade拿分90/90
先写感受
首先 感谢网上的部分代码以及攻略,在有些部分给予我帮助,虽然都有较多同样的错误:-) 你告诉我不是抄来抄去的我不信,所以要查是不是抄的其实很简单,就那么多错误的地方都犯得一样,或者那么多不按文档自己改写的代码 格式都一样?,(在此膜一下tcbbd大佬 感觉他是个人完成的代码,而且他没写代码攻略写了整个的设计的理解,感觉受益很多),关于网上代码/攻略我发现的普遍错误,已经在文档中用"值得注意的是"提到了,也许我的实现还有些不完善/错误的地方,如果你有发现,希望能帮我指出,开个issue或者pull request,:-)
这个mit的文档写得很是用心,然而读mit给的外部链接,看具体的手册可以有更具体的认识,虽然有些还是需要自己去google一波才能弄清。sjtu把网页fork一份但里面的图都裂了=.=没图说个..。能搜到的大多中文文档只讲应该这样,而没有怎么设计的,为什么,从哪来。码完的感受是——coding is easy and boring。感觉 缺少的是中文文档,我以为要是有同样详尽的中文文档,教会普通高中生jos lab毫无难度啊,难的是英文和耐心_(:з」∠)_。
从第一个lab到这个lab 我更期望能锻炼学习者的是
- 读英文文档 搜英文资料的能力
- git grep vim等linux 工具的使用
- 已有代码阅读能力
而os个人感觉像个附赠品
然后内容
- 在前面lab的页管理,虚拟地址管理函数实现的基础上,做了 用户环境的管理函数(该部分知识依赖就一个用户环境状态转换图)
- IDT 怎么工作 也是一张图的知识量
- sysenter/sysexit 需要文档(应该也可以按照上面走IDT的方法实现(未尝试))
- 再上面的基础上 做了更多支持,并做了内存相关保护
- 一个evilhello2 还是比较有趣:-)
- panic source code
- iret
- Interrupt vector table
- IDT
- How does the kernel know if the CPU is in user mode or kenel mode?
- Where is the mode bit?
- PUSHA
- X86 Assembly/Other Instructions
- X86 Registers
- How are the segment registers (fs, gs, cs, ss, ds, es) used in Linux?
- LInux 描述符GDT, IDT & LDT结构定义
- The difference between Call Gate, Interrupt Gate, Trap Gate?
- ARM GCC Inline Assembler Cookbook
- GCC-Inline-Assembly-HOWTO
- Labels in GCC inline assembly
- eflags
- Trap flag
- far call
- Call gate