Last updated: September 2020
Inspired by Model Cards for Model Reporting (Mitchell et al.) and Lessons from Archives (Jo & Gebru), we’re providing some accompanying information about the 1.3 billion parameter human feedback model we're releasing.
This model was developed by researchers at OpenAI to help us understand how large language models can be trained with human feedback, to optimize an objective that is better aligned with the goals of the task they are given. We focus on the task of abstractive summarization of English text. This model card details the 1.3 billion parameter Transformer model trained with human feedback (henceforth ‘the model’), as we are releasing both the weights and the evaluation code for this model. To train the model we use data collected primarily from external contractors.[1]
July 2020
Language model trained for abstractive summarization.
The 1.3 billion parameter model trained with human feedback. Many of the details here also apply to the 6.7 billion parameter model, whose weights we are not releasing at this time.
The primary intended users of the model are AI researchers. The primary use of the model is for summarizing text from the Reddit TL;DR dataset and CNN/DailyMail dataset, as this is where we have evaluated its performance. We also imagine that the model will be used by researchers to better understand the behaviors, capabilities, biases, and constraints of large-scale language models trained with human feedback.
While originally intended for research purposes, the model could be used for some practical applications of summarization, though we urge caution here (see below). In addition to summarizing text from the Reddit TL;DR dataset and CNN/DailyMail dataset, we expect that it may also be applied to summarize text in other domains, such as search results, product reviews, or longer documents. We expect performance of the model will be more variable in these domains than on the specific datasets it was tested on. The model could also be used for creative or entertainment purposes. It’s also possible that the model is used for non-summarization tasks, such as dialogue or machine translation; however, since our model has only been fine-tuned on the task of summarization, it’s likely that its performance on these tasks will be worse than existing models of the same size (e.g. GPT-2).
Because the model has not been evaluated in domains other than posts from Reddit and news articles from the CNN/DM dataset (see ‘Datasets’ section below), it should not be used in other domains until its performance in them has been evaluated. In the context of this research, there are at least four distinct sources of bias: the pretraining data, fine-tuning data, human feedback data, and the researchers themselves. There are not yet clear norms regarding transparency for human feedback data and associated biases, though we provide some coarse-grained statistics below. As techniques like those used in this paper become more widespread, human feedback and its associated biases will also grow in importance. Given these biases, we do not recommend that the model be deployed into systems that interact with humans unless the deployers first carry out a study of biases relevant to the intended use-case and context. Further, we do not recommend the model be used in a fully automated summarization system applied in safety-critical or other high-stakes contexts. Finally, since the model was fine-tuned solely on English summaries, usage for summarizing non-English text is out-of-scope.
The Reddit TL;DR human feedback dataset is a dataset of posts crawled from a subset of the forum reddit.com, along with summaries of these posts and human evaluations of these summaries. It currently consists of ~70k human evaluations, which are binary comparisons of summaries (both generated by machine learning models and written by humans) of Reddit posts. The motivation is to: (1) train a large summarization model that can generate summaries that are (2) in an English-language domain where good summaries cannot be simply derived from extracting the first 3 sentences of the text (such as the CNN/DailyMail dataset), and (3) provide the dataset to researchers to train and analyze the performance of their own summarization models. The collection of Reddit posts used in the dataset was mostly non-interventionist: we filtered data with explicit sexual content or mentions of suicide, and only collected data from subreddits with significant amounts of data that are comprehensible to a general audience. The collection of the human evaluations was interventionist: we explicitly defined what a ‘good’ summary was ourselves, and communicated this definition to our human labelers via a set of instructions. We also provided significant feedback at multiple stages of the data collection process (described in Appendix C of the paper).
The model was trained from three different sources of data. First, a pre-training step (the same used for training GPT-3) was performed where the model was trained to predict the next word in text from the Internet. This Internet data included: (1) a version of the CommonCrawl dataset, filtered based on similarity to high-quality reference corpora, (2) an expanded version of the Webtext dataset, (3) two Internet-based book corpora, and (4) English-language Wikipedia.
Next, the model was fine-tuned to generate summaries of text written by humans, on a dataset of posts from the online forum Reddit. This is based on the existing Reddit TL;DR dataset, developed by Völske et al in 2017, with additional scraping conducted to obtain more data and filtering to remove topics such as explicit sexuality and suicide. The distribution over topics (subreddits) used in this dataset is listed in Appendix A of the paper.
Finally, the model was further fine-tuned to optimize the score from a ‘reward model’ (another 1.3 billion parameter Transformer model) using reinforcement learning, which was in turn trained on data collected from external contractors. This data consists of binary comparisons between two candidate summaries (either generated by the model, or by baseline models, or written by humans) of Reddit posts. We are not releasing the dataset at this time.
Since the model is both pre-trained on vast quantities of data from the Internet, and fine-tuned on a dataset of Reddit posts, it is likely that the model can generate summaries that contain toxic content, or are biased against certain groups. We have not conducted an empirical investigation of the magnitude of these biases; for reference, some analysis of the bias of our pre-trained models is available in the GPT-3 paper.
The model can also generate summaries that are inaccurate or misleading. We show a summary of contractor ratings of the accuracy of the model’s summaries (in addition to quality along several other axes) below. Overall, our contractors provided an accuracy score of 4 or less out of 7 in 7% of summaries generated by the model. This number would likely increase if the model is used off-distribution. Thus, summaries from the model should not be assumed to be representative of the text that was summarized.
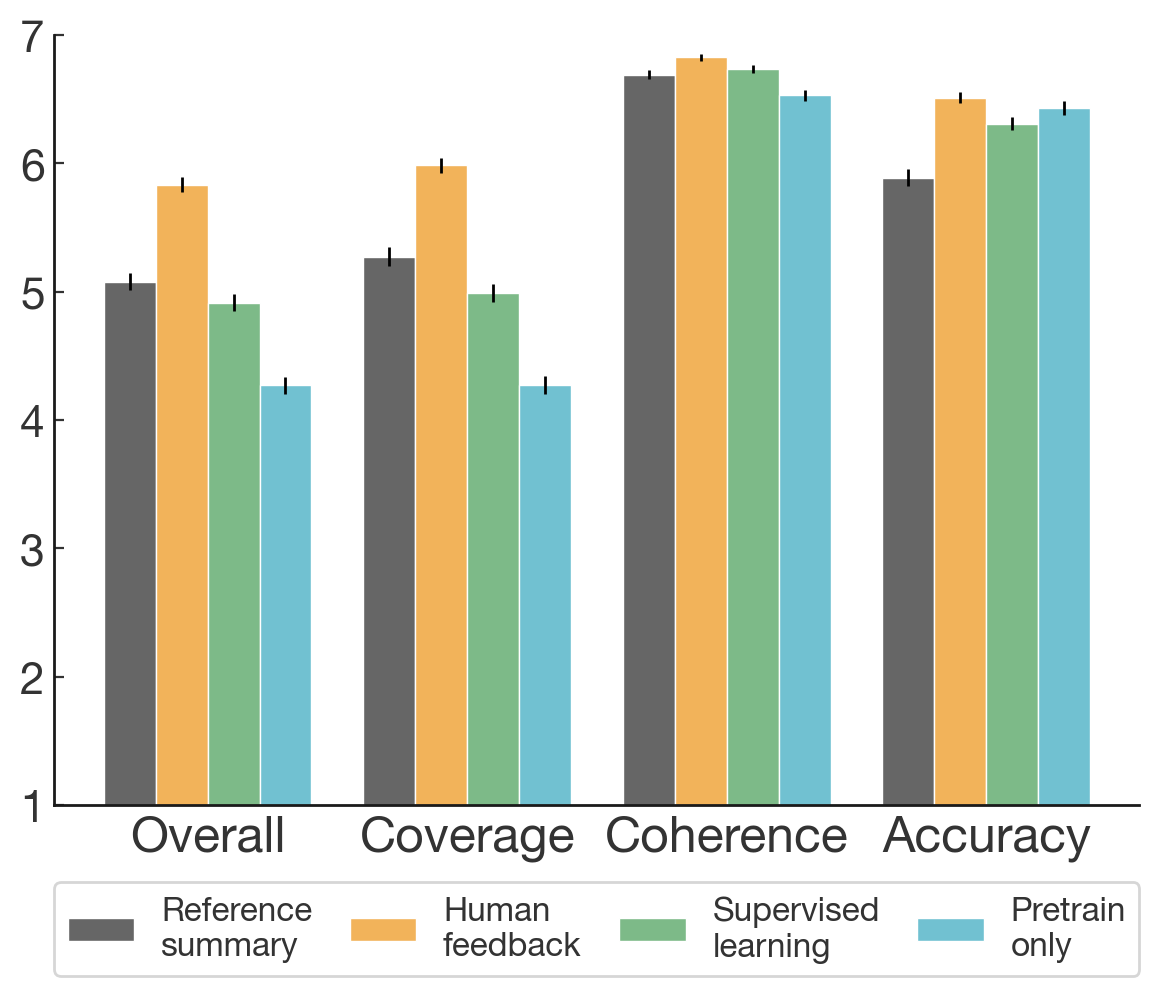
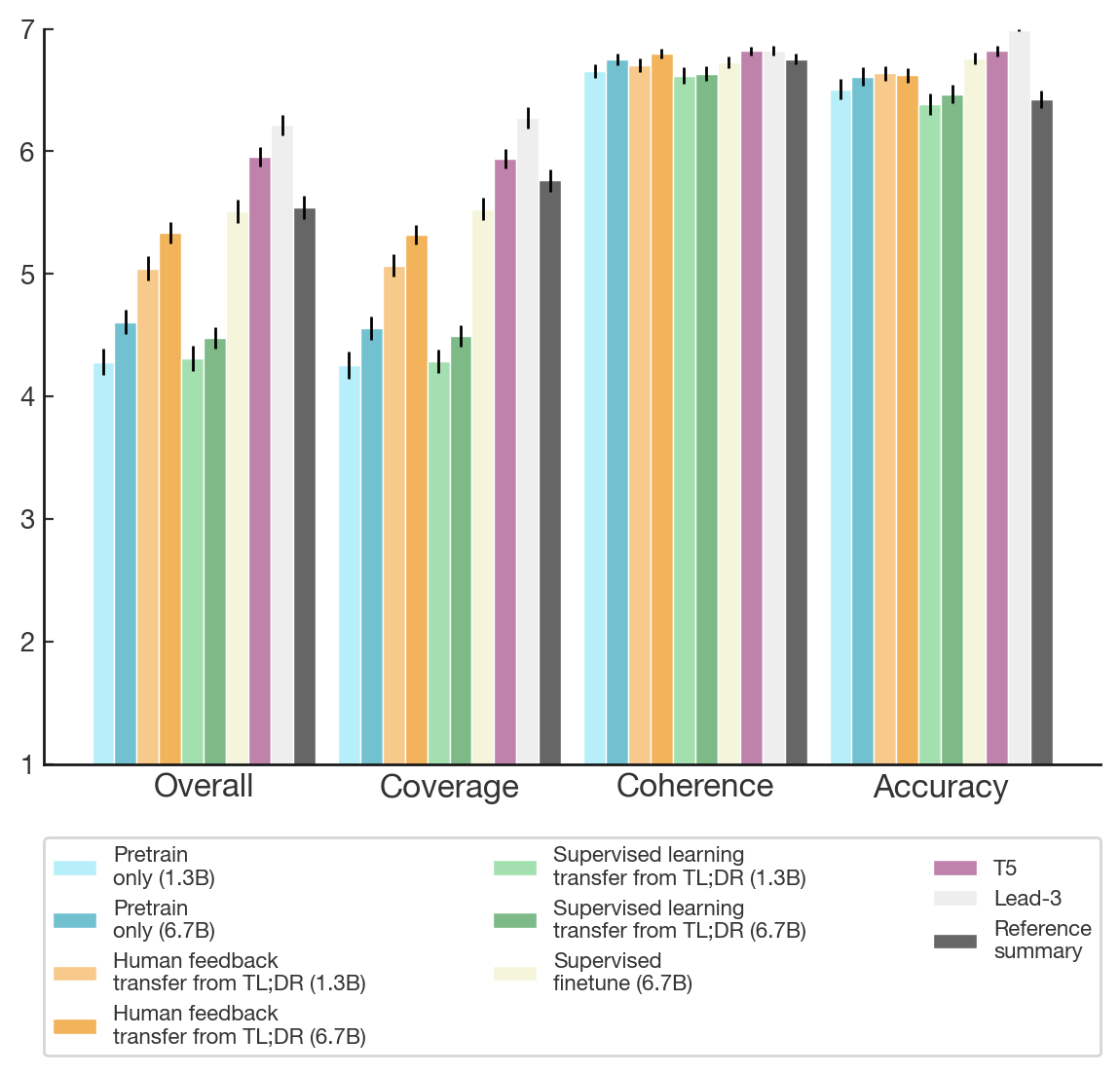
Contractor evaluations of various trained policies on the TL;DR dataset (left) and CNN/DailyMail (right). Scores are given out of 7 across various dimensions of quality. The model referred to in this report is the “Human feedback (1.3B)” and “Human feedback transfer from TL;DR (1.3B)”.
There are also some technical caveats to model usage: (1) the model can only generate summaries between 24 and 48 tokens (approximately 30 to 60 words), and (2) the model uses a specific padding scheme for the context (detailed in Appendix B of the paper); if a different padding scheme is used, performance will likely degrade.
Finally, in addition to what we highlighted in the “Out Of Scope Use Cases” section above, we don’t endorse applying the model to any commercial applications without further testing of the performance and bias in the specific domain. If, following such testing, the model is applied in a commercial context, we recommend that it be made abundantly clear to readers of the summaries that they were generated by an algorithm, not by a human.
The human feedback method used to train the model can be effective if the desired model behavior is known, and is easy to communicate to human labelers. However, this is not a method for determining what the desired model behavior should be. Deciding what makes a good summary may seem straightforward, but doing so involves making decisions based on a set of priorities and assumptions. Even when these are made explicit, judging quality for tasks with complex objectives, where different humans might disagree on the correct model behavior, will require significant care in project and method design, including selection, hiring and training of labelers. We do not endorse the use of human feedback methods to train models that can be used for harm, such as disseminating misinformation or generating abusive content, or can be unintentionally harmful due to factors such as bias or poor generalization.
The behaviors and biases of this model, like any model trained with human feedback, is influenced heavily by the labelers used to train it (see Appendix C of our paper for demographics information of our labelers, as well as instructions provided to them). It is also influenced ultimately by us, the people who made decisions about how labelers would be selected and trained, and by biases in the pretraining data. We recommend caution in determining the desired model behavior when applying our method to new domains.
While we do not have the capacity to respond to individual emails, we are interested in gathering feedback, especially relating to concerns about the methods we used and about model bias. The best way to provide feedback is to raise an issue on our GitHub repository.
[1] More information about the contractors we worked with, including the names of those who wished to be acknowledged can be found in the paper. See also the Method Recommendations section.