如何尝试走迷宫呢?遇到障碍物就从头 “回溯” 继续探索,这就是回溯算法的形象解释。
更抽象的,可以将回溯算法理解为深度遍历一颗树,每个叶子结点都是一种方案的终态,而对某条路线的判断可能在访问到叶子结点之前就结束。
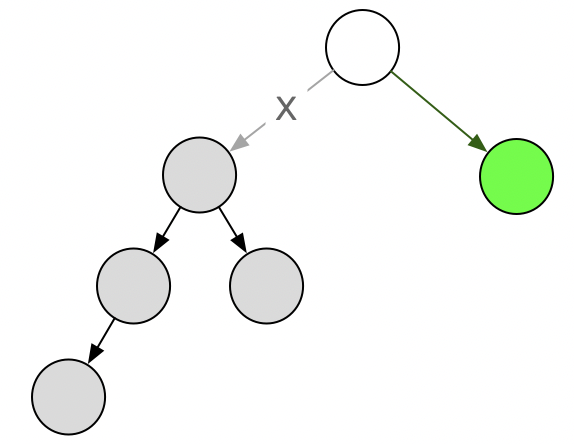
相比动态规划,回溯可以解决的问题更复杂,尤其是针对具有后效性的问题。
动态规划之所以无法处理有后效性问题,原因是其 dp(i)=F(dp(j)) 其中 0<=j<i 导致的,因为 i 通过 i-1 推导,如果 i-1 的某种选择会对 i 的选择产生影响,那么这个推导就是无效的。
而回溯,由于每条分支判断是相互独立的,互不影响,所以即便前面的选择具有后效性,这个后效性也可以在这条选择线路持续影响下去,而不影响其他分支。
所以回溯是一种适用性更广的算法,但相对的,其代价(时间复杂度)也更高,所以只有当没有更优算法时,才应当考虑回溯算法。
经过上述思考,回溯算法的实现思路就清晰了:递归或迭代。由于两者可以相互转换,而递归理解成本较低,因此我更倾向于递归方式解决问题。
这里必须提到一点,即工作与算法竞赛思维的区别:由于递归调用堆栈深度较大,整体性能不如迭代好,且迭代写法不如递归自然,所以做算法题时,为了提升那么一点儿性能,以及不经意间流露自己的实力,可能大家更倾向用迭代方式解决问题。
但工作中,大部分是性能不敏感场景,可维护性反而是更重要的,所以工程代码建议用更易理解的递归方式解决问题,把堆栈调用交给计算机去做。
其实算法代码追求更简短,能写成一行的绝不换行也是同样的道理,希望大家能在不同环境里自由切换习惯,而不要拘泥于一种风格。
用递归解决回溯的套路不止一种,我介绍一下自己常用的 TS 语言方法:
function func(params: any[], results: any[] = []) {
// 消耗 params 生成 currentResult
const { currentResult, restParams } = doSomething(params);
// 如果 params 还有剩余,则递归消耗,直到 params 耗尽为止
if (restParams.length > 0) func(restParams, results.concat(currentResult));
}这里 params 就类似迷宫后面的路线,而 results 记录了已走的最佳路线,当 params 路线消耗完了,就走出了迷宫,否则终止,让其它递归继续走。
所以回溯逻辑其实挺好写的,难在如何判断这道题应该用回溯做,以及如何优化算法复杂度。
先从两道入门题讲起,分别是电话号码的字母组合与复原 IP 地址。
电话号码的字母组合是一道中等题,题目如下:
给定一个仅包含数字
2-9的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
电话号码数字对应的字母其实是个映射表,比如 2 映射 a,b,c,3 映射 d,e,f,那么 2,3 能表示的字母组合就有 3x3=9 种,而要打印出比如 ad、ae 这种组合,肯定要用穷举法,穷举法也是回溯的一种,只不过每一种可能性都要而已,而复杂点儿的回溯可能并不是每条路径都符合要求。
所以这道题就好做了,只要构造出所有可能的组合就行。
接下来我们看一道类似,但有一定分支合法判断的题目,复原 IP 地址。
复原 IP 地址是一道中等题,题目如下:
给定一个只包含数字的字符串,用以表示一个 IP 地址,返回所有可能从 s 获得的 有效 IP 地址 。你可以按任何顺序返回答案。
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
例如:"0.1.2.201" 和 "192.168.1.1" 是 有效 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效 IP 地址。
首先肯定一个一个字符读取,问题就在于,一个字符串可能表示多种可能的 IP,比如 25525511135 可以表示为 255.255.11.135 或 255.255.111.35,原因在于,11.135 和 111.35 都是合法的表示,所以我们必须用回溯法解决问题,只是回溯过程中,会根据读取数据动态判定增加哪些新分支,以及哪些分支是非法的。
比如读取到 [1,1,1,3,5] 时,由于 11 和 111 都是合法的,因为这个位置的数字只要在 0~255 之间即可,而 1113 超过这个范围,所以被忽略,所以从这个场景中分叉出两条路:
- 当前项:
11,余项135。 - 当前项:
111,余项35。
之后再递归,直到非法情况终止,比如以及满了 4 项但还有剩余数字,或者不满足 IP 范围等。
可见,只要梳理清楚合法与非法的情况,直到如何动态生成新的递归判断,这道题就不难。
这道题输入很直白,直接给出来了,其实不是每道题的输入都这么容易想,我们看下一道全排列。
全排列是一道中等题,题目如下:
给定一个不含重复数字的数组
nums,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
与还原 IP 地址类似,我们也是消耗给的输入,比如 123,我们可以先消耗 1,余下 23 继续组合。但与 IP 复原不同的是,第一个数字可以是 1 2 3 中的任意一个,所以其实在生成当前项时有所不同:当前项可以从所有余项里挑选,然后再递归即可。
比如 123 的第一次可以挑选 1 或 2 或 3,对于 1 的情况,还剩 23,那么下次可以挑选 2 或 3,当只剩一项时,就不用挑了。
全排列的输入虽然不如还原 IP 地址的输入直白,但好歹是基于给出的字符串推导而出的,那么再复杂点的题目,输入可能会拆解为多个,这需要你灵活思考,比如括号生成题目。
括号生成是一道中等题,题目如下:
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例: 输入:
n = 3输出:["((()))","(()())","(())()","()(())","()()()"]
这道题基本思路与上一题很像,而且由于题目问的是所有可能性,而不是最优解,所以无法用动规,所以我们考虑回溯算法。
上一道 IP 题目的输入是已知字符串,而这道题的输入就要你动动脑经了。这道题的输入是字符串吗?显然不是,因为输入是括号数量,那么只有一个括号数量就够了吗?不够,因为题目要求有效括号,那什么是有效括号?闭合的才是,所以我们想到用左右括号数量表示这个数字,即输入是 n,那么转化为 open=n, close=n。
有了输入,如何消耗输入呢?我们每一步都可以用一个左括号 open 或一个右括号 close,但第一个必须是 open,且当前已消耗 close 数量必须小于已消耗 open 数量时,才可以加上 close,因为一个 close 左边必须有个 open 形成合法闭合。
所以这道题就迎刃而解了。回顾来看,回溯的入参要能灵活思考,而这个思考取决于你的经验,比如遇到括号问题,下意识就直到拆解为左右括号。所以算法之间是相通的,适当的知识迁移可以事半功倍。
好了,在此我们先打住,其实不是所有题目都可以用回溯解决,但有些题目看上去只是回溯题目的变种,但其实不然。我们回到上一道全排列题,与之比较像的是 下一个排列,这道题看上去好像是基于全排列衍生的,但却无法用回溯算法解决,我们看看这道题。
下一个排列是一道中等题,题目如下:
实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须 原地 修改,只允许使用额外常数空间。
比如:
输入:nums = [1,2,3]
输出:[1,3,2]
输入:nums = [3,2,1]
输出:[1,2,3]
如果你在想,能否借鉴全排列的思想,在全排列过程中自然推导出下一个排列,那大概率是想不通的,因为从整体推导到局部的效率太低,这道题直接给出一个局部值,我们必须用相对 “局部的方法” 快速推导出下一个值,所以这道题无法用回溯算法解决。
� 对于 3,2,1 的例子,由于已经是最大排列了,所以下个排列只能是初始化的 1,2,3 升序,这个是特例。除此之外,都有下一个更大排列,以 1,2,3 为例,更大的是 1,3,2 而不是 2,1,3。
我们再观察长一点的例子,比如 3,2,1,4,5,6,可以发现,无论前面如何降序,只要最后几个是升序的,只要把最后两个扭转即可:3,2,1,4,6,5。
如果是 3,2,1,4,5,6,9,8,7 呢?显然 9,8,7 任意相邻交换都会让数字变得更小,不符合要求,我们还是要交换 5,6 .. 不 6,9,因为 65x 比 596 要大更多。到这里我们得到几个规律:
- 尽可能交换后面的数。交换
5,6会比交换6,9更大,因为6,9更靠后,位数更小。 - 我们将
3,2,1,4,5,6,9,8,7分为两段,分别是前段3,2,1,4,5,6和后段9,8,7,我们要让前段尽可能大的数和后段尽可能小的数交换,同时还要保证,后段尽可能小的数比前段尽可能大的数还要 大。
为了满足第二点,我们必须从后向前查找,如果是升序就跳过,直到找到一个数字 j 比 j-1 小,那么前段作为交换的就是第 j 项,后段要找一个最小的数与之交换,由于搜索的算法导致后段一定是降序的,因此从后向前找到第一个比 j 大的项交换即可。
最后我们发现,交换后也不一定是完美下一项,因为后段是降序的,而我们已经把前面一个尽可能最小的 “大” 位改大了,后面一定要升序才满足下一个排列,因此要把后段进行升序排列。
因为后段已经满足降序了,因此采用双指针交换法相互对调即可变成升序,这一步千万不要用快排,会导致整体时间复杂度提高 O(nlogn)。
最后由于只扫描了一次 + 反转后段一次,所以算法复杂度是 O(n)。
从这道题可以发现,不要轻视看似变种的题目,从全排列到下一个排列,可能要完全换一个思路,而不是对回溯进行优化。
我们继续回到回溯问题,回溯最经典的问题就是 N 皇后,也是难度最大的题目,与之类似的还有解决数独问题,不过都类似,我们这次还是以 N 皇后作为代表来理解。
N 皇后问题是一道困难题,题目如下:
n 皇后问题 研究的是如何将
n个皇后放置在n×n的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数
n,返回所有不同的n皇后问题 的解决方案。每一种解法包含一个不同的
n皇后问题 的棋子放置方案,该方案中'Q'和'.'分别代表了皇后和空位。
皇后的攻击范围非常广,包括横、纵、斜,所以当 n<4 时是无解的,而神奇的时,n>=4 时都有解,比如下面两个图:
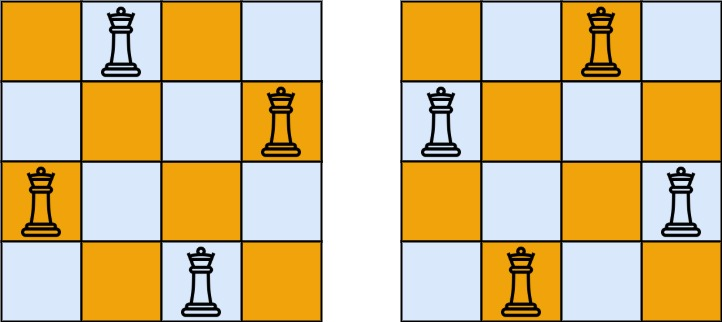
这道题显然具有 “强烈的” 后效性,因为皇后攻击范围是由其位置决定的,换而言之,一个皇后位置确定后,其他皇后的可能摆放位置会发生变化,因此只能用回溯算法。
那么如何识别合法与非法位置呢?核心就是根据横、纵、斜三种攻击方式,建立四个数组,分别存储哪些行、列、撇、捺位置是不能放置的,然后将所有合法位置都作为下一次递归的可能位置,直到皇后放完,或者无位置可放为止。
容易想到的就是四个数组,分别存储被占用的下标,这样的话,只是递归中条件判断分支复杂一些,其它其实并无难度。
这道题的空间复杂度进阶算法是,利用二进制方式,使用 4 个数字 代替四个下标数组,每个数组转化为二进制时,1 的位置代表被占用,0 的位置代表未占用,通过位运算,可以更快速、低成本的进行位置占用,与判断当前位置是否被占用。
这里只提一个例子,就可以感受到二进制魅力:
由于按照行看,一行只能放一个皇后,所以每次都从下一行看起,因此行限制就不用看了(至少下一行不可能和前面的行冲突),所以我们只要记录列、撇、捺三个位置即可。
不同之处在于,我们采用二进制的数字,只要三个数字即可表示列、撇、捺。二进制位中的 1 表示被占用,0 表示不被占用。
比如列、撇、捺分别是变量 x,y,z,对应二进制可能是:
000000100100000001100
“非” 逻辑是任意为 1 就是 1,因此 “非” 逻辑可以将所有 1 合并,即 x | y | z 即 0011101。
然后将这个结果取反,用非逻辑,即 ~(x | y | z),结果是 1100010,那这里所有的 1 就表示可放的位置,我们记这个变量为 p,通过 p & -p 不断拿最后一位 1 得到安放位置,即可调用递归了。
从这道题可以发现,N 皇后难度不在于回溯算法,而在于如何利用二进制写出高效的回溯算法。所以回溯算法考察的比较综合,因为算法本身很模式化,而且相对比较 “笨拙”,所以需要将更多重心放在优化效率上。
回溯算法本质上是利用计算机高速计算能力,将所有可能都尝试一遍,唯一区别是相对暴力解法,可能在某个分支提前终止(枝剪),所以其实是一个较为笨重的算法,当题目确实具有后效性,且无法用贪心或者类似下一排列这种巧妙解法时,才应该采用。
最后我们要总结对比一下回溯与动态规划算法,其实动态规划算法的暴力递归过程就与回溯相当,只是动态规划可以利用缓存,存储之前的结果,避免重复子问题的重复计算,而回溯因为面临的问题具有后效性,不存在重复子问题,所以无法利用缓存加速,所以回溯算法高复杂度是无法避免的。
回溯算法被称为 “通用解题方法”,因为可以解决许多大规模计算问题,是利用计算机运算能力的很好实践。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)