开门见山。
最近在搭建基于 Hadoop 3.3.6 的高可用集群时,遇到了虽然守护进程能正常启动,但是提交 WordCount 示例程序后作业没有办法启动执行的情况(刚开始就挂了),查看日志发现主要是以下两种情况:
-
提示
/bin/java文件不存在。bash: /bin/java: No such file or directory -
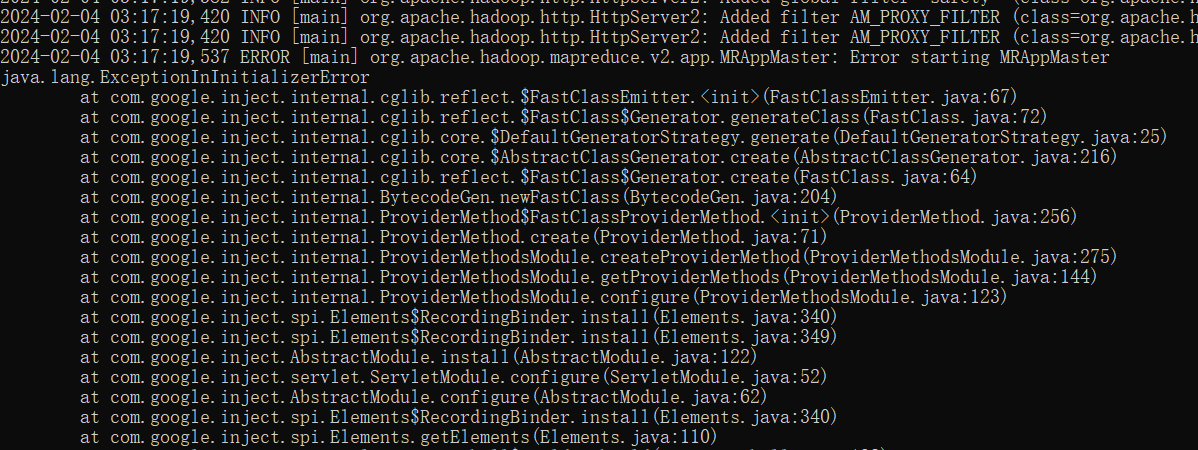
启动
MRAppMaster失败,原因是其抛出了java.lang.reflect.InaccessibleObjectException异常。java.lang.reflect.InaccessibleObjectException: Unable to make ... accessible: module java.base does not "opens java.lang" to unnamed module @...
这里简单写一下二者的解决方法。

字面上看是 Bash 找不到可执行文件 /bin/java ,但细想一下,无论是在 hadoop-env.sh 还是 yarn-env.sh 亦或者 yarn-site.xml 的 yarn.nodemanager.env-whitelist 配置中,我全都加上了 JAVA_HOME 的相关环境变量配置,我在任何地方都没有写过 /bin/java 这个路径,就有点令人匪夷所思了。
但在看了 NodeManager 执行作业时生成的默认容器启动脚本 launch_container.sh 后就能发现其末尾写着这样的语句(这个脚本的位置可以参考下方):
echo "Launching container"
exec /bin/bash -c "$JAVA_HOME/bin/java ... -Xmx1024m org.apache.hadoop.mapreduce.v2.app.MRAppMaster ...显而易见,这里因为 $JAVA_HOME 环境变量没有传递进脚本,导致 bash 实际执行的是 /bin/java。
怎么解决这个问题?最粗暴的方式是直接给 Java 创建一个软链 /bin/java (网上很多复制粘贴的帖子给出的方法),这样做虽然能跑,但其实没触及根本的问题。
还有一种方法是直接在 Hadoop安装目录/libexec/hadoop-config.sh 中导出一个 JAVA_HOME 环境变量。(网上的帖子里还有修改这里某个条件判断语句的解决方案,但是在 Hadoop 新版中这部分代码已经重构了)
我真的好想找出问题的根源哇!(╯▔皿▔)╯ 回去检查配置文件,我也没看出什么问题,该配置的都配置了。
到底还是偶然看到的 StackOverflow 的一位老哥点明了我(链接):
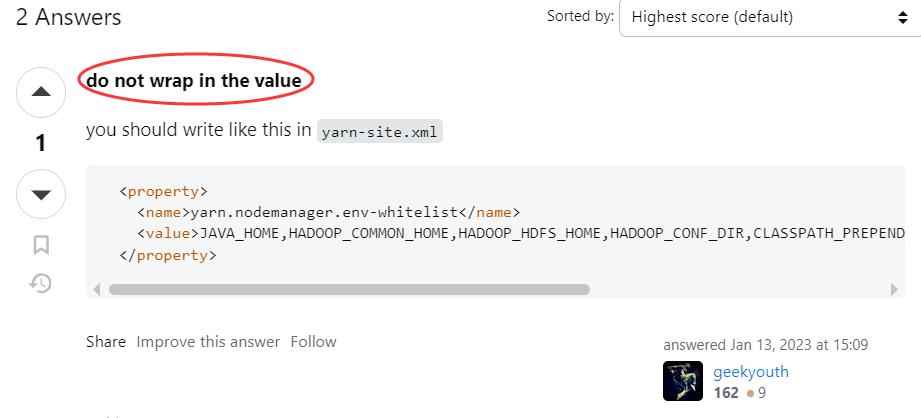
“不要在属性值中换行”
回去检查了一下我的 yarn-site.xml 配置,发现 VSCode 格式化工具帮我格式化成了这个样子:
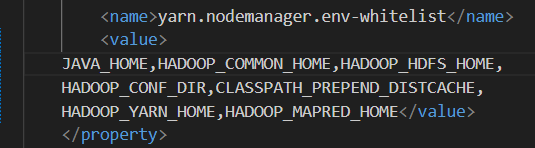
去掉开头的换行符,改成 <value>JAVA_HOME, ...</value> 就能把这个问题给解决了...原来是值中出现额外字符而导致的,哭笑不得。

这个异常贴到网上倒是能找到很多类似的解决方案,即加上 Java 选项 --add-opens java.base/java.lang=ALL-UNNAMED ,但大多是围绕 ResourceManager, NodeManager 启动时的情况。
问题就在于这里 MRAppMaster 的启动参数位于 launch_container.sh 中,因而我需要找到办法在脚本的这一句中加入 Java 选项:
exec /bin/bash -c "$JAVA_HOME/bin/java ... -Xmx1024m org.apache.hadoop.mapreduce.v2.app.MRAppMaster ...在官方文档里按 java opts 这种关键词查了半天没找着,转变思路用 MRAppMaster 搜索,还真就给我找着了。在 mapred-site.xml 配置中有这样一个属性(文档链接):
| 属性名 | 默认值 | 说明 |
|---|---|---|
| yarn.app.mapreduce.am.command-opts | -Xmx1024m | Java opts for the MR App Master processes.... |
正好就是 MRAppMaster 进程启动时的 Java 选项,在 mapred-site.xml 中加入如下属性配置即可:
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<!--保留了 -Xmx1024 -->
<value>--add-opens java.base/java.lang=ALL-UNNAMED -Xmx1024m</value>
<description>MR App Master 进程的 Java 参数</description>
</property>首先执行一个作业(Job),然后在集群某台机器中找到其对应的 Application:
# 找到 Job 对应的 Application
yarn application -list -appStates=ALL返回内容大概是这样:
Total number of applications (application-types: [], states: [NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED] and tags: []):2
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1707118501768_0002 word count MAPREDUCE root default FINISHED SUCCEEDED 100% http://shworker1:19888/jobhistory/job/job_1707118501768_0002
找到 applicationId 后,查询这个应用在哪台机器上执行:
yarn application -status application_1707118501768_0002返回内容大概是这样:
Application Report :
Application-Id : application_1707118501768_0002
Application-Name : word count
Application-Type : MAPREDUCE
User : root
Queue : default
Application Priority : 0
Start-Time : 1707120843501
Finish-Time : 1707120865825
Progress : 100%
State : FINISHED
Final-State : SUCCEEDED
Tracking-URL : http://shworker1:19888/jobhistory/job/job_1707118501768_0002
RPC Port : 42097
AM Host : shworker1
Aggregate Resource Allocation : 52071 MB-seconds, 35 vcore-seconds
Aggregate Resource Preempted : 0 MB-seconds, 0 vcore-seconds
Log Aggregation Status : DISABLED
Diagnostics :
Unmanaged Application : false
Application Node Label Expression : <Not set>
AM container Node Label Expression : <DEFAULT_PARTITION>
TimeoutType : LIFETIME ExpiryTime : UNLIMITED RemainingTime : -1seconds
其中 AM Host 即为应用执行所在主机,这里是 shworker1。
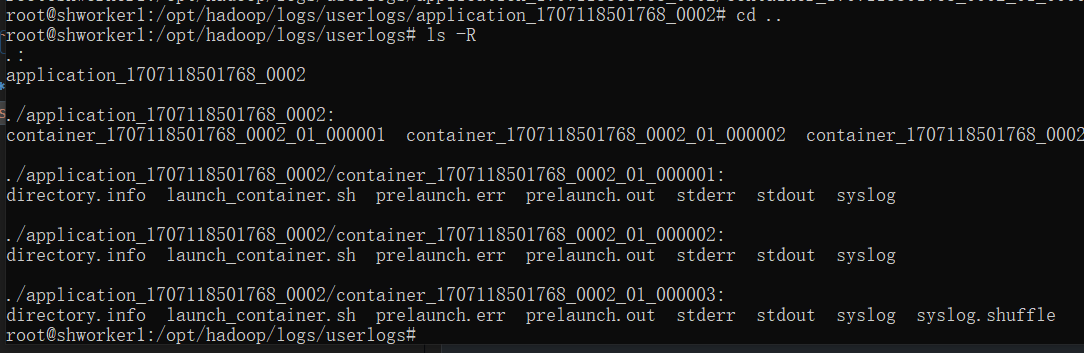
在主机 shworker1 上进入Hadoop的日志目录,这个日志目录默认是 ${HADOOP_HOME}/logs 。其中会有一个子目录 userlogs,在这个目录内你就能找到 application_1707118501768_0002 的 Container 日志了: