diff --git a/.github/workflows/deploy.yaml b/.github/workflows/deploy.yaml
index ff743368a7..808b5a7a24 100644
--- a/.github/workflows/deploy.yaml
+++ b/.github/workflows/deploy.yaml
@@ -61,7 +61,7 @@ jobs:
- name : prepare
run: sh ./prepare.sh
- # if 'both', set each file 'community' and 'enterprise' seperately.
+ # if 'both', set each file 'community' and 'enterprise' separately.
- name: Update database_edition.yml
run: |
import yaml
diff --git a/community_versions.json b/community_versions.json
index 60d6371445..8027398493 100644
--- a/community_versions.json
+++ b/community_versions.json
@@ -1 +1 @@
-[{"version": "3.5.0", "title": "3.5.0", "aliases": []}, {"version": "3.4.1", "title": "3.4.1", "aliases": []}, {"version": "3.3.0", "title": "3.3.0", "aliases": []}, {"version": "3.2.1", "title": "3.2.1", "aliases": []}, {"version": "3.1.3", "title": "3.1.3", "aliases": []}, {"version": "3.0.2", "title": "3.0.2", "aliases": []}, {"version": "2.6.2", "title": "2.6.2", "aliases": []}, {"version": "master", "title": "master", "aliases": []}]
+[{"version": "3.5.0", "title": "3.5.0", "aliases": []},{"version": "3.4.2", "title": "3.4.2", "aliases": []},{"version": "3.4.1", "title": "3.4.1", "aliases": []}, {"version": "3.4.0", "title": "3.4.0", "aliases": []}, {"version": "3.3.0", "title": "3.3.0", "aliases": []}, {"version": "3.2.1", "title": "3.2.1", "aliases": []}, {"version": "3.1.3", "title": "3.1.3", "aliases": []}, {"version": "3.0.2", "title": "3.0.2", "aliases": []}, {"version": "2.6.2", "title": "2.6.2", "aliases": []}, {"version": "master", "title": "master", "aliases": []}]
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
index a9d13eb60b..469d86287c 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
@@ -110,7 +110,7 @@ Storage 服务是由 nebula-storaged 进程提供的,用户可以根据场景
{{nebula.name}}使用强类型 Schema。
-对于点或边的属性信息,{{nebula.name}}会将属性信息编码后按顺序存储。由于属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)。同时为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息。
+对于点或边的属性信息,{{nebula.name}}会将属性信息编码后按顺序存储。由于定长属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)。同时为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息。
## 数据分片
diff --git a/docs-2.0/14.client/6.nebula-go-client.md b/docs-2.0/14.client/6.nebula-go-client.md
index b070c70c9c..c8cae1fb2c 100644
--- a/docs-2.0/14.client/6.nebula-go-client.md
+++ b/docs-2.0/14.client/6.nebula-go-client.md
@@ -40,11 +40,11 @@ NebulaGraph GO 客户端提供 Connection Pool 和 Session Pool 两种使用方
- Session Pool
- 详细示例请参见 [session_pool_example.go](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/session_pool_example/session_pool_example.go)。
+ 详细示例请参见 [session_pool_example.go](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/examples/session_pool_example/session_pool_example.go)。
使用限制请参见 [Usage example](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/README.md#usage-example)。
- Connection Pool
- 详细示例请参见 [graph_client_basic_example](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/basic_example/graph_client_basic_example.go) 和 [graph_client_goroutines_example](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/gorountines_example/graph_client_goroutines_example.go)。
+ 详细示例请参见 [graph_client_basic_example](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/examples/basic_example/graph_client_basic_example.go) 和 [graph_client_goroutines_example](https://github.com/vesoft-inc/nebula-go/blob/{{go.branch}}/examples/gorountines_example/graph_client_goroutines_example.go)。
diff --git a/docs-2.0/2.quick-start/1.quick-start-overview.md b/docs-2.0/2.quick-start/1.quick-start-overview.md
index 78e0295a6d..ef9a3a2ab7 100644
--- a/docs-2.0/2.quick-start/1.quick-start-overview.md
+++ b/docs-2.0/2.quick-start/1.quick-start-overview.md
@@ -1,97 +1,316 @@
-# 使用 Docker Desktop 一键部署
+# 基于 Docker 快速部署
-按照以下步骤可以快速在 Docker Desktop 中部署{{nebula.name}}。
+{{nebula.name}} 提供了基于 Docker 的快速部署方式,可以在几分钟内完成部署。
-1. 安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
+=== "使用 Docker Desktop"
- !!! caution
+ 按照以下步骤可以快速在 Docker Desktop 中部署{{nebula.name}}。
- 如果在 Windows 端安装 Docker Desktop 需[安装 WSL 2](https://docs.docker.com/desktop/install/windows-install/)。
+ 1. 安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
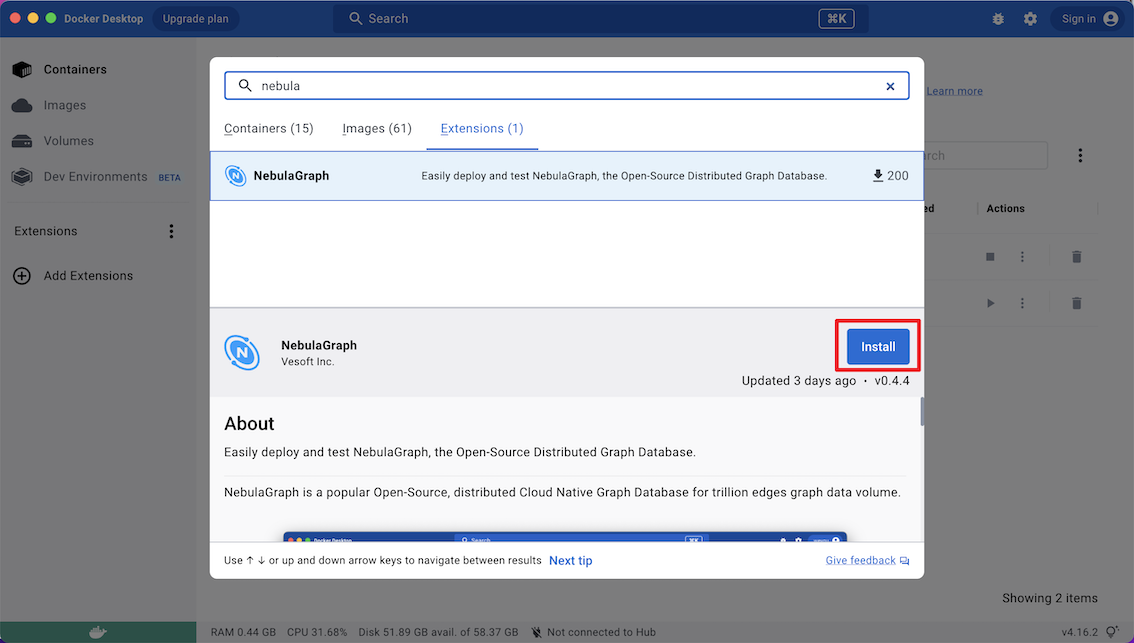
-2. 在仪表盘中单击`Extensions`或`Add Extensions`打开Extensions Marketplace 搜索{{nebula.name}} ,也可以点击 [{{nebula.name}}](https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext) 在 Docker Desktop 打开。
-3. 导航到{{nebula.name}}的扩展市场。
-4. 点击`Install`下载{{nebula.name}}。
+ !!! caution
- 
+ 如果在 Windows 端安装 Docker Desktop 需[安装 WSL 2](https://docs.docker.com/desktop/install/windows-install/)。
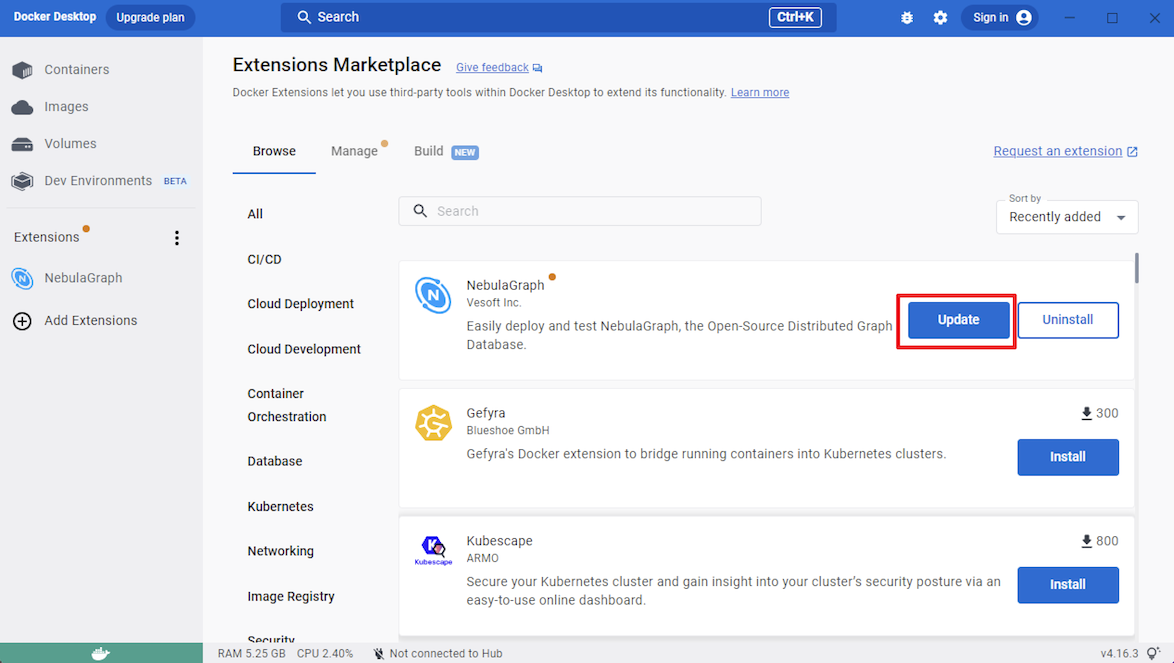
-5. 在有更新的时候,可以点击`Update`更新到最新版本。
+ 2. 在仪表盘中单击`Extensions`或`Add Extensions`打开Extensions Marketplace 搜索{{nebula.name}} ,也可以点击 [{{nebula.name}}](https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext) 在 Docker Desktop 打开。
+ 3. 导航到{{nebula.name}}的扩展市场。
+ 4. 点击`Install`下载{{nebula.name}}。
- 
+ 
-视频介绍
+ 5. 在有更新的时候,可以点击`Update`更新到最新版本。
-
+ 
-## 视频
+ 视频介绍
-用户也可以观看视频快速了解{{nebula.name}}的相关概念和操作。
+
+
-### {{nebula.name}} Academy 系列课程
+=== "使用 Docker Compose"
- * [第一课:图的概念](https://www.bilibili.com/video/BV1CK411f7Fw)(03 分 45 秒)
+ 使用 Docker Compose 可以基于准备好的配置文件快速部署{{nebula.name}}服务,仅建议在测试{{nebula.name}}功能时使用该方式。
-
+ ## 前提条件
- * [第二课:图的结构](https://www.bilibili.com/video/BV1CK411f7Fw)(02 分 24 秒)
+ - 主机上安装如下应用程序。
-
+ | 应用程序 | 推荐版本 | 官方安装参考 |
+ |:---|:---|:---|
+ |Docker|最新版本|[Install Docker Engine](https://docs.docker.com/engine/install/) |
+ |Docker Compose|最新版本|[Install Docker Compose](https://docs.docker.com/compose/install/)|
+ |Git|最新版本|[Download Git](https://git-scm.com/download/)|
- 请访问 [Bilibili 空间](https://space.bilibili.com/472621355),查看更多视频。
+ - 如果使用非 root 用户部署{{nebula.name}},请授权该用户 Docker 相关的权限。详细信息,请参见 [Manage Docker as a non-root user](https://docs.docker.com/engine/install/linux-postinstall/#manage-docker-as-a-non-root-user)。
-### 热点视频
+ - 启动主机上的 Docker 服务。
-
+ ## 部署{{nebula.name}}
+ 1. 通过 Git 克隆`nebula-docker-compose`仓库的`{{dockercompose.release}}`分支到主机。
-* [Foesa 小学姐课堂——{{nebula.name}}那些磨人的概念](https://www.bilibili.com/video/BV1Q5411K7Gg)(04 分 20 秒)
+ !!! danger
-
+ `master`分支包含最新的未测试代码。请**不要**在生产环境使用此版本。
-* [Foesa 小学姐课堂——`path`的三种类型](https://www.bilibili.com/video/BV1Uf4y1t72L)(03 分 09 秒)
-
+ ```bash
+ $ git clone -b {{dockercompose.branch}} https://github.com/vesoft-inc/nebula-docker-compose.git
+ ```
-* [Foesa 小学姐课堂——悬挂边](https://www.bilibili.com/video/BV1GR4y1F7ko) (02 分 27 秒)
+ !!! Note
-
+ Docker Compose 的`x.y`版本对齐内核的`x.y`版本,对于内核`z`版本,Docker Compose 不会发布对应的`z`版本,但是会拉取`z`版本的内核镜像。
- * [Foesa 小学姐课堂——自环](https://www.bilibili.com/video/BV1E5411S7t2)(02 分 53 秒)
+ 2. 切换至目录`nebula-docker-compose`。
-
+ ```bash
+ $ cd nebula-docker-compose/
+ ```
- * [Nebula Explore Demo Show](https://www.bilibili.com/video/BV1VL4y1V7C2)(02 分 53 秒)
+ 3. 执行如下命令启动{{nebula.name}}服务。
-
+ !!! note
-
diff --git a/docs-2.0/20.appendix/0.FAQ.md b/docs-2.0/20.appendix/0.FAQ.md
index a66731734b..18f4419cf6 100644
--- a/docs-2.0/20.appendix/0.FAQ.md
+++ b/docs-2.0/20.appendix/0.FAQ.md
@@ -29,7 +29,7 @@
{{nebula.name}} {{ nebula.release }} 与 历史版本 (包括{{nebula.name}} 1.x 和 2.x) 的数据格式、客户端通信协议均**双向不兼容**。
使用**老版本**客户端连接**新版本**服务端,会导致服务进程**退出**。
- 数据格式升级参见[升级{{nebula.name}}历史版本至当前版本](../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md)。
+ 数据格式升级参见[升级{{nebula.name}}历史版本至当前版本](../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm.md)。
客户端与工具均需要[下载对应版本](../20.appendix/6.eco-tool-version.md)。
{{ comm.comm_end }}
@@ -40,7 +40,7 @@
{{nebula.name}} {{ nebula.release }} 与 历史版本 (包括{{nebula.name}} 1.x 和 2.x) 的数据格式、客户端通信协议均**双向不兼容**。
使用**老版本**客户端连接**新版本**服务端,会导致服务进程**退出**。
- 数据格式升级参见[升级{{nebula.name}}历史版本至当前版本](../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md)。
+ 数据格式升级参见[升级{{nebula.name}}历史版本至当前版本](../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md)。
客户端与工具均需要[下载对应版本](../20.appendix/6.eco-tool-version.md)。
{{ent.ent_end}}
@@ -53,15 +53,25 @@
## 关于执行报错
-### 如何处理错误信息 `SemanticError: Missing yield clause.`
+### 如何处理错误信息`-1005:GraphMemoryExceeded: (-2600)`
+
+这个错误是由 Memory Tracker 发出的,它在观察到内存使用超过了设定阈值时发出警报。这个机制可以帮助避免服务进程被系统的 OOM(Out of Memory)killer 终止。解决步骤:
+
+1. 检查内存使用情况:首先,你需要查看命令执行过程中的内存用量。如果内存使用量确实很高,那么这个错误可能是预期中的情况。
+
+2. 检查 Memory Tracker 的配置:如果内存使用量并不高,检查 Memory Tracker 的相关配置。这包括`memory_tracker_untracked_reserved_memory_mb`(未被跟踪的预留内存量,单位为 MB),`memory_tracker_limit_ratio`(内存限制比例),以及`memory_purge_enabled`(是否启用内存清理)。关于 Memory Tracker 的配置,参见 [memory tracker 配置](../5.configurations-and-logs/1.configurations/4.storage-config.md#memory_tracker)。
+
+3. 优化配置:根据实际情况,调整这些配置。例如,如果可用内存限制过低,可以调高`memory_tracker_limit_ratio`的值。
+
+### 如何处理错误信息`SemanticError: Missing yield clause`
从{{nebula.name}} 3.0.0 开始,查询语句`LOOKUP`、`GO`、`FETCH`必须用`YIELD`子句指定输出结果。详情请参见[YIELD](../3.ngql-guide/8.clauses-and-options/yield.md)。
-### 如何处理错误信息 `Host not enough!`
+### 如何处理错误信息`Host not enough!`
从 3.0.0 版本开始,在配置文件中添加的 Storage 节点无法直接读写,配置文件的作用仅仅是将 Storage 节点注册至 Meta 服务中。必须使用`ADD HOSTS`命令后,才能正常读写 Storage 节点。详情参见[管理 Storage 主机](../4.deployment-and-installation/manage-storage-host.md)。
-### 如何处理错误信息 `To get the property of the vertex in 'v.age', should use the format 'var.tag.prop'`
+### 如何处理错误信息`To get the property of the vertex in 'v.age', should use the format 'var.tag.prop'`
从 3.0.0 版本开始,`pattern`支持同时匹配多个 Tag,所以返回属性时,需要额外指定 Tag 名称。即从`RETURN 变量名.属性名`改为`RETURN 变量名.Tag名.属性名`。
@@ -77,7 +87,7 @@
-->
-### 如何处理错误信息 `Storage Error E_RPC_FAILURE`
+### 如何处理错误信息`Storage Error E_RPC_FAILURE`
报错原因通常为 Graph 服务向 Storage 服务请求了过多的数据,导致 Storage 服务超时。请尝试以下解决方案:
@@ -87,7 +97,7 @@
* 为 Storage 服务器提供性能更好的 SSD 或者内存。
* 重试请求。
-### 如何处理错误信息 `The leader has changed. Try again later`
+### 如何处理错误信息`The leader has changed. Try again later`
已知问题,通常需要重试 1-N 次 (N==partition 数量)。原因为 meta client 更新 leader 缓存需要 1-2 个心跳或者通过错误触发强制更新。
@@ -515,37 +525,7 @@ dmp 文件是错误报告文件,详细记录了进程退出的信息,可以
如果修改过配置文件中预设的端口,请找出实际使用的端口并在防火墙中开放它们。
-周边工具各自使用不同的端口。以下是{{nebula.name}}内核及周边工具使用的默认端口信息:
-
-| 序号 | 所属产品/服务 | 类型 | 默认端口 | 说明 |
-| :--- | :--------------------- | :--- | :---------------------------- | :----------------------------------------------------------- |
-| 1 | {{nebula.name}} | TCP | 9669 | Graph 服务的 RPC 守护进程监听端口(通常用于客户端连接Graph服务)。 |
-| 2 | {{nebula.name}} | TCP | 19669 | Graph 服务的 HTTP 端口。 |
-| 3 | {{nebula.name}} | TCP | 19670 | Graph 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
-| 4 | {{nebula.name}} | TCP | 9559 | Meta 服务的 RPC 守护进程监听端口。(通常由 Graph 服务和 Storage 服务发起请求,用于获取和更新图数据库的元数据信息。 |
-| 5 | {{nebula.name}} | TCP | 9560 | Meta 服务之间的 Raft 通信端口。 |
-| 6 | {{nebula.name}} | TCP | 19559 | Meta 服务的 HTTP 端口。 |
-| 7 | {{nebula.name}} | TCP | 19560 | Meta 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
-| 8 | {{nebula.name}} | TCP | 9777 | Storage 服务中,Drainer 服务占用端口(仅在企业版集群中暴露)。 |
-| 9 | {{nebula.name}} | TCP | 9778 | Storage 服务中,Admin 服务占用端口。 |
-| 10 | {{nebula.name}} | TCP | 9779 | Storage 服务的 RPC 守护进程监听端口。(通常由 Graph 服务发起请求,用于执行数据存储相关的操作,例如读取、写入或删除数据。) |
-| 11 | {{nebula.name}} | TCP | 9780 | Storage 服务之间的 Raft 通信端口。 |
-| 12 | {{nebula.name}} | TCP | 19779 | Storage 服务的 HTTP 端口。 |
-| 13 | {{nebula.name}} | TCP | 19780 | Storage 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
-| 14 | {{nebula.name}} | TCP | 8888 | 备份和恢复功能的 Agent 服务端口。Agent 是集群中每台机器的一个守护进程,用于启停{{nebula.name}}服务和上传、下载备份文件。 |
-| 15 | {{nebula.name}} | TCP | 9789、9790、9788 | 全文索引中 Raft Listener 的端口,从 Storage 服务读取数据,然后将它们写入 Elasticsearch 集群。
也是集群间数据同步中 Storage Listener 的端口。用于同步主集群的 Storage 数据。端口 9790、9788 由端口 9789 加一减一后自动生成。 |
-| 16 | {{nebula.name}} | TCP | 9200 | {{nebula.name}}使用该端口与 Elasticsearch 进行 HTTP 通信,以执行全文搜索查询和管理全文索引。 |
-| 17 | {{nebula.name}} | TCP | 9569、9570、9568| 集群间数据同步功能中 Meta Listener 的端口,用于同步主集群的 Meta 数据。端口 9570、9568 由端口 9569 加一减一后自动生成。 |
-| 18 | {{nebula.name}} | TCP | 9889、9890、9888 | 集群间数据同步功能中 Drainer 服务端口。用于同步 Storage、Meta 数据给从集群。端口 9890、9888 由端口 9889 加一减一后自动生成。|
-| 19 | NebulaGraph Studio | TCP | 7001 | Studio 提供 Web 服务占用端口。 |
-| 20 | {{dashboard_ent.name}} | TCP | 8090 | Nebula HTTP Gateway 依赖服务端口。为集群服务提供 HTTP 接口,执行 nGQL 语句与{{nebula.name}}数据库进行交互。 |
-| 21 | {{dashboard_ent.name}} | TCP | 9200 | Nebula Stats Exporter 依赖服务端口。收集集群的性能指标,包括服务 IP 地址、版本和监控指标(例如查询数量、查询延迟、心跳延迟 等)。 |
-| 22 | {{dashboard_ent.name}} | TCP | 9100 | Node Exporter 依赖服务端口。收集集群中机器的资源信息,包括 CPU、内存、负载、磁盘和流量。 |
-| 23 | {{dashboard_ent.name}} | TCP | 9091 | Prometheus 服务的端口。存储监控数据的时间序列数据库。 |
-| 24 | NebulaGraph Dashboard | TCP | 7003 | Dashboard 社区版 提供 Web 服务占用端口。 |
-| 25 | {{dashboard_ent.name}} | TCP | 7005 | {{dashboard_ent.name}}提供 Web 服务占用端口。 |
-| 26 | {{dashboard_ent.name}} | TCP | 9093 | Alertmanager 服务的端口。接收 Prometheus 告警,发送告警通知给{{dashboard_ent.name}}。 |
-| 27 | {{explorer.name}} | TCP | 7002 | {{explorer.name}}提供的 Web 服务占用端口。 |
+更多端口信息,参见[公司产品端口全集](port-guide.md)。
### 如何测试端口是否已开放?
diff --git a/docs-2.0/20.appendix/6.eco-tool-version.md b/docs-2.0/20.appendix/6.eco-tool-version.md
index 83e3745b03..555646197f 100644
--- a/docs-2.0/20.appendix/6.eco-tool-version.md
+++ b/docs-2.0/20.appendix/6.eco-tool-version.md
@@ -166,7 +166,7 @@ NebulaGraph Console 是{{nebula.name}}的原生 CLI 客户端。如何使用请
{{comm.comm_begin}}
## NebulaGraph Docker Compose
-Docker Compose 可以快速部署{{nebula.name}}集群。如何使用请参见 [Docker Compose 部署 NebulaGraph](../4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose.md)。
+Docker Compose 可以快速部署{{nebula.name}}集群。如何使用请参见 [Docker Compose 部署 NebulaGraph](../2.quick-start/1.quick-start-overview.md)。
|{{nebula.name}}版本|Docker Compose 版本|
|:---|:---|
diff --git a/docs-2.0/20.appendix/learning-path.md b/docs-2.0/20.appendix/learning-path.md
index a07ec981bb..770ddd726a 100644
--- a/docs-2.0/20.appendix/learning-path.md
+++ b/docs-2.0/20.appendix/learning-path.md
@@ -97,7 +97,7 @@
| 文档 |
| ------------------------------------------------------------ |
- | [升级{{nebula.name}}](https://docs.nebula-graph.com.cn/{{nebula.release}}/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest/) |
+ | [升级{{nebula.name}}](https://docs.nebula-graph.com.cn/{{nebula.release}}/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm/) |
### 3.3 配置Nebula
@@ -262,7 +262,7 @@
|[图数据库在安全风控场景的应用 @BOSS 直聘](https://www.bilibili.com/video/BV1Rh41117G9)|
|[更多文档](https://nebula-graph.com.cn/posts/) 、[视频](https://space.bilibili.com/472621355/channel/series) |
## 6. 常见问题
-
+
| 文档 |
| ------------------------------------------------------------ |
| [常见问题 FAQ](https://docs.nebula-graph.com.cn/{{nebula.release}}/20.appendix/0.FAQ/#faq) |
@@ -302,4 +302,4 @@
- 有关{{nebula.name}}语言的概述,参见[开源分布式图数库论文](https://arxiv.org/pdf/2206.07278.pdf)中的 2.8 节。
-{{comm.comm_end}}
\ No newline at end of file
+{{comm.comm_end}}
diff --git a/docs-2.0/20.appendix/port-guide.md b/docs-2.0/20.appendix/port-guide.md
new file mode 100644
index 0000000000..c54b10a8d4
--- /dev/null
+++ b/docs-2.0/20.appendix/port-guide.md
@@ -0,0 +1,34 @@
+# 产品端口全集
+
+以下是{{nebula.name}}内核及周边工具使用的默认端口信息:
+
+| 序号 | 所属产品/服务 | 类型 | 默认端口 | 说明 |
+| :--- | :--------------------- | :--- | :---------------------------- | :----------------------------------------------------------- |
+| 1 | {{nebula.name}} | TCP | 9669 | Graph 服务的 RPC 守护进程监听端口(通常用于客户端连接Graph服务)。 |
+| 2 | {{nebula.name}} | TCP | 19669 | Graph 服务的 HTTP 端口。 |
+| 3 | {{nebula.name}} | TCP | 19670 | Graph 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
+| 4 | {{nebula.name}} | TCP | 9559 | Meta 服务的 RPC 守护进程监听端口。(通常由 Graph 服务和 Storage 服务发起请求,用于获取和更新图数据库的元数据信息。 |
+| 5 | {{nebula.name}} | TCP | 9560 | Meta 服务之间的 Raft 通信端口。 |
+| 6 | {{nebula.name}} | TCP | 19559 | Meta 服务的 HTTP 端口。 |
+| 7 | {{nebula.name}} | TCP | 19560 | Meta 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
+| 8 | {{nebula.name}} | TCP | 9777 | Storage 服务中,Drainer 服务占用端口(仅在企业版集群中暴露)。 |
+| 9 | {{nebula.name}} | TCP | 9778 | Storage 服务中,Admin 服务占用端口。 |
+| 10 | {{nebula.name}} | TCP | 9779 | Storage 服务的 RPC 守护进程监听端口。(通常由 Graph 服务发起请求,用于执行数据存储相关的操作,例如读取、写入或删除数据。) |
+| 11 | {{nebula.name}} | TCP | 9780 | Storage 服务之间的 Raft 通信端口。 |
+| 12 | {{nebula.name}} | TCP | 19779 | Storage 服务的 HTTP 端口。 |
+| 13 | {{nebula.name}} | TCP | 19780 | Storage 服务的 HTTP/2 端口。(3.x 后已弃用该端口) |
+| 14 | {{nebula.name}} | TCP | 8888 | 备份和恢复功能的 Agent 服务端口。Agent 是集群中每台机器的一个守护进程,用于启停{{nebula.name}}服务和上传、下载备份文件。 |
+| 15 | {{nebula.name}} | TCP | 9789、9790、9788 | 全文索引中 Raft Listener 的端口,从 Storage 服务读取数据,然后将它们写入 Elasticsearch 集群。
也是集群间数据同步中 Storage Listener 的端口。用于同步主集群的 Storage 数据。端口 9790、9788 由端口 9789 加一减一后自动生成。 |
+| 16 | {{nebula.name}} | TCP | 9200 | {{nebula.name}}使用该端口与 Elasticsearch 进行 HTTP 通信,以执行全文搜索查询和管理全文索引。 |
+| 17 | {{nebula.name}} | TCP | 9569、9570、9568| 集群间数据同步功能中 Meta Listener 的端口,用于同步主集群的 Meta 数据。端口 9570、9568 由端口 9569 加一减一后自动生成。 |
+| 18 | {{nebula.name}} | TCP | 9889、9890、9888 | 集群间数据同步功能中 Drainer 服务端口。用于同步 Storage、Meta 数据给从集群。端口 9890、9888 由端口 9889 加一减一后自动生成。|
+| 19 | NebulaGraph Studio | TCP | 7001 | Studio 提供 Web 服务占用端口。 |
+| 20 | {{dashboard_ent.name}} | TCP | 8090 | Nebula HTTP Gateway 依赖服务端口。为集群服务提供 HTTP 接口,执行 nGQL 语句与{{nebula.name}}数据库进行交互。 |
+| 21 | {{dashboard_ent.name}} | TCP | 9200 | Nebula Stats Exporter 依赖服务端口。收集集群的性能指标,包括服务 IP 地址、版本和监控指标(例如查询数量、查询延迟、心跳延迟 等)。 |
+| 22 | {{dashboard_ent.name}} | TCP | 9100 | Node Exporter 依赖服务端口。收集集群中机器的资源信息,包括 CPU、内存、负载、磁盘和流量。 |
+| 23 | {{dashboard_ent.name}} | TCP | 9091 | Prometheus 服务的端口。存储监控数据的时间序列数据库。 |
+| 24 | NebulaGraph Dashboard | TCP | 7003 | Dashboard 社区版 提供 Web 服务占用端口。 |
+| 25 | {{dashboard_ent.name}} | TCP | 7005 | {{dashboard_ent.name}}提供 Web 服务占用端口。 |
+| 26 | {{dashboard_ent.name}} | TCP | 9093 | Alertmanager 服务的端口。接收 Prometheus 告警,发送告警通知给{{dashboard_ent.name}}。 |
+| 27 | {{explorer.name}} | TCP | 7002 | {{explorer.name}}提供的 Web 服务占用端口。 |
+| 28 | License Manager | TCP | 9119 | License Manager (LM) 服务的端口。LM 服务用于管理 License(仅在企业版集群中使用)。|
diff --git a/docs-2.0/20.appendix/release-notes/explorer-release-note.md b/docs-2.0/20.appendix/release-notes/explorer-release-note.md
index 80562e4473..2d565dbd21 100644
--- a/docs-2.0/20.appendix/release-notes/explorer-release-note.md
+++ b/docs-2.0/20.appendix/release-notes/explorer-release-note.md
@@ -1,5 +1,13 @@
# {{explorer.name}}版本更新说明
+## v3.5.1
+
+- 缺陷修复
+
+ - 修复错误链接。
+ - 修复错误文案。
+ - 移除弃用的工具组件。
+
## v3.5.0
- 功能
diff --git a/docs-2.0/3.ngql-guide/17.query-tuning-statements/2.kill-session.md b/docs-2.0/3.ngql-guide/17.query-tuning-statements/2.kill-session.md
index 58558983e7..d9c3395d41 100644
--- a/docs-2.0/3.ngql-guide/17.query-tuning-statements/2.kill-session.md
+++ b/docs-2.0/3.ngql-guide/17.query-tuning-statements/2.kill-session.md
@@ -34,7 +34,7 @@
`KILL SESSION`语句支持管道操作,即将`SHOW SESSIONS`语句与`KILL SESSION`语句结合使用,以终止多个会话。
- `[WHERE ]`:
- - 可选项,使用`WHERE`子句过滤会话;``指滤过表达式,例如`WHERE $-.CreateTime < datetime("2022-12-14T18:00:00")`。如果不加改选项,则关闭所有当前会话。
+ - 可选项,使用`WHERE`子句过滤会话;``指滤过表达式,例如`WHERE $-.CreateTime < datetime("2022-12-14T18:00:00")`。如果不加该选项,则关闭所有当前会话。
- `WHERE`子句中支持的过滤项有:`SessionId`、`UserName`、`SpaceName`、`CreateTime`、`UpdateTime`、`GraphAddr`、`Timezone`、`ClientIp`。可以执行 [SHOW SESSIONS 命令](../../3.ngql-guide/7.general-query-statements/6.show/17.show-sessions.md)查看这些过滤项的含义。
- `{SESSION|SESSIONS}`:支持`SESSION`和`SESSIONS`的写法。
diff --git a/docs-2.0/3.ngql-guide/7.general-query-statements/3.go.md b/docs-2.0/3.ngql-guide/7.general-query-statements/3.go.md
index 349b8425c9..c47098e75f 100644
--- a/docs-2.0/3.ngql-guide/7.general-query-statements/3.go.md
+++ b/docs-2.0/3.ngql-guide/7.general-query-statements/3.go.md
@@ -1,6 +1,6 @@
# GO
-`GO`从给定起始点开始遍历图。`GO`语句采用的路径类型是[`walk`](../../1.introduction/2.1.path.md),即遍历时点和边都可以重复。
+`GO`语句是{{nebula.name}}图数据库中用于从给定起始点开始遍历图的语句。`GO`语句采用的路径类型是[`walk`](../../1.introduction/2.1.path.md),即遍历时点和边都可以重复。
## openCypher 兼容性
@@ -29,15 +29,15 @@ YIELD [DISTINCT]
[AS ] [, [AS ] ...]
```
-- ` {STEP|STEPS}`:指定跳数。如果没有指定跳数,默认值`N`为`1`。如果`N`为`0`,{{nebula.name}} 不会检索任何边。
+- ` {STEP|STEPS}`:指定跳数。如果没有指定跳数,默认值`N`为`1`。如果`N`为`0`,{{nebula.name}}不会检索任何边。
- `M TO N {STEP|STEPS}`:遍历`M~N`跳的边。如果`M`为`0`,输出结果和`M`为`1`相同,即`GO 0 TO 2`和`GO 1 TO 2`是相同的。
-- ``:用逗号分隔的点 ID 列表,或特殊的引用符`$-.id`。详情参见[管道符](../5.operators/4.pipe.md)。
+- ``:用逗号分隔的点 ID 列表。
- ``:遍历的 Edge type 列表。
-- `REVERSELY | BIDIRECT`:默认情况下检索的是``的出边(正向),`REVERSELY`表示反向,即检索入边;`BIDIRECT` 为双向,即检索正向和反向,通过返回 `._type` 字段判断方向,其正数为正向,负数为反向。
+- `REVERSELY | BIDIRECT`:默认情况下检索的是``的出边(正向),`REVERSELY`表示反向,即检索入边;`BIDIRECT` 为双向,即检索正向和反向。可通过`YIELD`返回`._type`字段判断方向,其正数为正向,负数为反向。
- `WHERE `:指定遍历的过滤条件。用户可以在起始点、目的点和边使用`WHERE`子句,还可以结合`AND`、`OR`、`NOT`、`XOR`一起使用。详情参见 [WHERE](../8.clauses-and-options/where.md)。
@@ -46,7 +46,7 @@ YIELD [DISTINCT]
- 遍历多个 Edge type 时,`WHERE`子句有一些限制。例如不支持`WHERE edge1.prop1 > edge2.prop2`。
- GO 语句执行时先遍历所有的点,然后再根据过滤器条件进行过滤。
-- `YIELD [DISTINCT] `:定义需要返回的输出。` `建议使用 [Schema 相关函数](../6.functions-and-expressions/4.schema.md),当前支持`src(edge)`、`dst(edge)`、`type(edge)`等,暂不支持嵌套函数。详情参见 [YIELD](../8.clauses-and-options/yield.md)。
+- `YIELD [DISTINCT] `:定义需要返回的输出。` `建议使用 [Schema 相关函数](../6.functions-and-expressions/4.schema.md)指定返回信息,当前支持`src(edge)`、`dst(edge)`、`type(edge)`等,暂不支持嵌套函数。详情参见 [YIELD](../8.clauses-and-options/yield.md)。
- `SAMPLE `:用于在结果集中取样。详情参见 [SAMPLE](../8.clauses-and-options/sample.md)。
@@ -62,7 +62,18 @@ YIELD [DISTINCT]
- `LIMIT [,] ]`:限制输出结果的行数。详情参见 [LIMIT](../8.clauses-and-options/limit.md)。
-## 示例
+
+## 使用说明
+
+- GO 语句中的`WHERE`和`YIELD`子句通常结合属性引用符(`$^`和`$$`)或函数`properties($^)`和`properties($$)`指定点的属性;使用函数`properties(edge)`指定边的属性。用法参见[属性引用符](../4.variable-and-composite-queries/3.property-reference.md)和 [Schema 相关函数](../6.functions-and-expressions/4.schema.md)。
+- GO 复合语句中如需引用子查询的结果,需要为该结果设置别名,并使用管道符`|`传递给下一个子查询,同时在下一个子查询中使用`$-`引用该结果的别名。详情参见[管道符](../5.operators/4.pipe.md)。
+- 当查询属性没有值时,返回结果显示`NULL`。
+
+## 场景及示例
+
+### 查询起始点的直接邻居点
+
+场景:查询某个点的直接相邻点,例如查询一个人所属队伍。
```ngql
# 返回 player102 所属队伍。
@@ -75,6 +86,10 @@ nebula> GO FROM "player102" OVER serve YIELD dst(edge);
+-----------+
```
+### 查询指定跳数内的点
+
+场景:查询一个点在指定跳数内的所有点,例如查询一个人两跳内的朋友。
+
```ngql
# 返回距离 player102 两跳的朋友。
nebula> GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
@@ -90,7 +105,34 @@ nebula> GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
```
```ngql
-# 添加过滤条件。
+# 查询 player100 1~2 跳内的朋友。
+nebula> GO 1 TO 2 STEPS FROM "player100" OVER follow \
+ YIELD dst(edge) AS destination;
++-------------+
+| destination |
++-------------+
+| "player101" |
+| "player125" |
+...
+
+# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
+nebula> MATCH (v) -[e:follow*1..2]->(v2) \
+ WHERE id(v) == "player100" \
+ RETURN id(v2) AS destination;
++-------------+
+| destination |
++-------------+
+| "player100" |
+| "player102" |
+...
+```
+
+### 添加过滤条件
+
+场景:查询满足特定条件的点和边,例如查询起始点和目的点之间具有特定属性的边。
+
+```ngql
+# 使用 WHERE 添加过滤条件。
nebula> GO FROM "player100", "player102" OVER serve \
WHERE properties(edge).start_year > 1995 \
YIELD DISTINCT properties($$).name AS team_name, properties(edge).start_year AS start_year, properties($^).name AS player_name;
@@ -104,8 +146,13 @@ nebula> GO FROM "player100", "player102" OVER serve \
+-----------------+------------+---------------------+
```
+### 查询多个 Edge type
+
+场景:查询起始点关联的多个边类型可以通过设置多个Edge Type实现,也可以通过设置`*`关联所有的边类型。
+
+
```ngql
-# 遍历多个 Edge type。属性没有值时,会显示`NULL`。
+# 遍历多个 Edge type。
nebula> GO FROM "player100" OVER follow, serve \
YIELD properties(edge).degree, properties(edge).start_year;
+-------------------------+-----------------------------+
@@ -117,8 +164,10 @@ nebula> GO FROM "player100" OVER follow, serve \
+-------------------------+-----------------------------+
```
+### 查询入边方向的点
+
```ngql
-# 返回 player100 入方向的邻居点。
+# 返回关注 player100 的邻居点。
nebula> GO FROM "player100" OVER follow REVERSELY \
YIELD src(edge) AS destination;
+-------------+
@@ -139,6 +188,10 @@ nebula> MATCH (v)<-[e:follow]- (v2) WHERE id(v) == 'player100' \
...
```
+### 子查询作为起始点
+
+场景:使用子查询的结果作为图遍历的起始点。
+
```ngql
# 查询 player100 的朋友和朋友所属队伍。
nebula> GO FROM "player100" OVER follow REVERSELY \
@@ -167,28 +220,9 @@ nebula> MATCH (v)<-[e:follow]- (v2)-[e2:serve]->(v3) \
...
```
-```ngql
-# 查询 player100 1~2 跳内的朋友。
-nebula> GO 1 TO 2 STEPS FROM "player100" OVER follow \
- YIELD dst(edge) AS destination;
-+-------------+
-| destination |
-+-------------+
-| "player101" |
-| "player125" |
-...
+### 使用 GROUP BY 分组
-# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
-nebula> MATCH (v) -[e:follow*1..2]->(v2) \
- WHERE id(v) == "player100" \
- RETURN id(v2) AS destination;
-+-------------+
-| destination |
-+-------------+
-| "player100" |
-| "player102" |
-...
-```
+场景:使用`GROUP BY`分组,然后使用`YIELD`返回分组后的结果。
```ngql
# 根据年龄分组。
@@ -199,12 +233,14 @@ nebula> GO 2 STEPS FROM "player100" OVER follow \
+-------------+----------------------------+----------+
| dst | src | age |
+-------------+----------------------------+----------+
-| "player125" | ["player101"] | [41] |
-| "player100" | ["player125", "player101"] | [42, 42] |
-| "player102" | ["player101"] | [33] |
+| "player125" | {"player101"} | [41] |
+| "player100" | {"player125", "player101"} | [42, 42] |
+| "player102" | {"player101"} | [33] |
+-------------+----------------------------+----------+
```
+### 使用 ORDER BY 和 LIMIT 排序和限制输出结果
+
```ngql
# 分组并限制输出结果的行数。
nebula> $a = GO FROM "player100" OVER follow YIELD src(edge) AS src, dst(edge) AS dst; \
@@ -219,6 +255,9 @@ nebula> $a = GO FROM "player100" OVER follow YIELD src(edge) AS src, dst(edge) A
+-------------+-------------+-------------+-------------+
```
+### 其他用法
+
+
```ngql
# 在多个边上通过 IS NOT EMPTY 进行判断。
nebula> GO FROM "player100" OVER follow WHERE properties($$).name IS NOT EMPTY YIELD dst(edge);
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/_upgrade-nebula-from-300-to-latest.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/_upgrade-nebula-from-300-to-latest.md
deleted file mode 100644
index 273bc4b072..0000000000
--- a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/_upgrade-nebula-from-300-to-latest.md
+++ /dev/null
@@ -1,57 +0,0 @@
-# 升级{{nebula.name}} v3.x 至 v{{nebula.release}}
-
-{{nebula.name}} v3.x 升级至 v{{nebula.release}},只需要使用 v{{nebula.release}}的 RPM/DEB 包进行升级操作即可,或者[编译 v{{nebula.release}}](../2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md) 之后重新安装。
-
-
-!!! caution
-
- 在升级部署了全文索引的{{nebula.name}}前,需要手动删除 Elasticsearch (ES) 中的全文索引。在升级后需要重新使用`SIGN IN`语句登录 ES 并重新创建全文索引。用户可通过 cURL 命令手动删除 ES 中全文索引。命令为`curl -XDELETE -u : ':/'`,例如`curl -XDELETE -u elastic:elastic 'http://192.168.8.223:9200/nebula_index_2534'`。如果 ES 没有设置用户名及密码,则无需指定`-u`选项。
-
-
-## RPM/DEB 包升级步骤
-
-1. 下载 [RPM/DEB 包](https://www.nebula-graph.com.cn/download)。
-
-2. 停止所有{{nebula.name}}服务。详情请参见[管理{{nebula.name}}服务](../../2.quick-start/3.quick-start-on-premise/5.start-stop-service.md)。建议更新前备份配置文件。
-
- !!! caution
-
- 如果用户需要保留无 Tag 的点,在集群内所有 Graph 服务的配置文件(`nebula-graphd.conf`)中新增`--graph_use_vertex_key=true`;在所有 Storage 服务的配置文件(`nebula-storaged.conf`)中新增`--use_vertex_key=true`。
-
-3. 执行如下命令升级:
-
- - RPM 包
-
- ```bash
- $ sudo rpm -Uvh
- ```
-
- 若安装时指定路径,那么升级时也需要指定路径
-
- ```bash
- $ sudo rpm -Uvh --prefix=
- ```
-
- - DEB 包
-
- ```bash
- $ sudo dpkg -i
- ```
-
-4. 在每台服务器上启动所需的服务。详情请参见[管理{{nebula.name}}服务](../../2.quick-start/3.quick-start-on-premise/5.start-stop-service.md#_1)。
-
-## 编译新版本源码升级步骤
-
-1. 备份旧版本的配置文件。配置文件保存在{{nebula.name}}安装路径的`etc`目录内。
-
-2. 更新仓库并编译源码。详情请参见[使用源码安装{{nebula.name}}](../2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md)。
-
- !!! note
-
- 编译时注意设置安装路径,和旧版本的安装路径保持一致。
-
-## Docker Compose 部署
-
-!!! caution
-
- Docker Compose 部署的{{nebula.name}}建议重新部署新版本后导入数据。
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm.md
similarity index 100%
rename from docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
rename to docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm.md
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md
similarity index 99%
rename from docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
rename to docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md
index 5358dbd9e5..2eeddbd19f 100644
--- a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
+++ b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md
@@ -8,7 +8,7 @@
!!! note
- 如果您的{{nebula.name}}版本低于 3.0.0,请先升级到 3.1.0 再升级到 {{nebula.release}}。具体操作请参见[升级{{nebula.name}} 2.x 至 3.1.0](https://docs.nebula-graph.com.cn/3.1.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest/)。
+ 如果您的{{nebula.name}}版本低于 3.0.0,请先升级到 3.1.0 再升级到 {{nebula.release}}。具体操作请参见[升级{{nebula.name}} 2.x 至 3.1.0](https://docs.nebula-graph.com.cn/3.1.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm/)。
- 执行升级操作的集群 IP 地址必须与原集群相同。
diff --git a/docs-2.0/4.deployment-and-installation/6.deploy-text-based-index/1.text-based-index-restrictions.md b/docs-2.0/4.deployment-and-installation/6.deploy-text-based-index/1.text-based-index-restrictions.md
index 65b1dd78c8..0422bf0802 100644
--- a/docs-2.0/4.deployment-and-installation/6.deploy-text-based-index/1.text-based-index-restrictions.md
+++ b/docs-2.0/4.deployment-and-installation/6.deploy-text-based-index/1.text-based-index-restrictions.md
@@ -1,6 +1,5 @@
# 全文索引限制
-{{ent.ent_begin}}
!!! caution
- 本文介绍全文索引的限制,请在使用全文索引前仔细阅读。
@@ -12,6 +11,8 @@
- 全文索引名称只能包含数字、小写字母、下划线。
+- 不同图空间内的全文索引名称不能重复。
+
- 查询默认返回 10 条数据。可以使用`LIMIT`子句返回更多数据,最多可以返回 10000 条。可以修改 ElasticSearch 的参数调整最大返回条数。
- 如果 Tag/Edge type 上存在全文索引,无法删除或修改 Tag/Edge type。
@@ -32,41 +33,4 @@
- 从写入{{nebula.name}},到写入 listener,再到写入 Elasticsearch 并创建索引可能需要一段时间。如果访问全文索引时返回未找到索引,可检查索引任务的状态。
-- 使用 K8s 方式部署的{{nebula.name}}集群不支持自动部署全文索引,但支持手动部署。
-
-{{ent.ent_end}}
-
-
-{{comm.comm_begin}}
-!!! caution
-
- 本文介绍全文索引的限制,请在使用全文索引前仔细阅读。
-
-全文索引有如下 14 条限制:
-
-- 全文索引当前仅支持`LOOKUP`语句。
-
-- 全文索引名称只能包含数字、小写字母、下划线。
-
-- 如果 Tag/Edge type 上存在全文索引,无法删除或修改 Tag/Edge type。
-
-- 属性的类型必须为`STRING`或`FIXED_STRING`。
-
-- 全文索引不支持多个 Tag/Edge type 的搜索。
-
-- 不支持排序全文搜索的返回结果,而是按照数据插入的顺序返回。
-
-- 全文索引不支持搜索属性值为`NULL`的属性。
-
-- 不支持修改 Elasticsearch 中的索引,只能删除重建。
-
-- 不支持管道符。
-
-- `WHERE`子句只能用单个条件进行全文搜索。
-
-- 确保同时启动了 Elasticsearch 集群和 NebulaGraph,否则可能导致 Elasticsearch 集群写入的数据不完整。
-
-- 从写入 NebulaGraph,到写入 listener,再到写入 Elasticsearch 并创建索引可能需要一段时间。如果访问全文索引时返回未找到索引,可等待索引生效(但是,该等待时间未知,也无返回码检查)。
-
-- 使用 K8s 方式部署的 NebulaGraph 集群不支持全文索引。
-{{comm.comm_end}}
\ No newline at end of file
+- 使用 K8s 方式部署的{{nebula.name}}集群不支持自动部署全文索引,但支持手动部署。
\ No newline at end of file
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
index d81af04bd9..a72e910a00 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
@@ -77,10 +77,8 @@ Graph 服务提供了两份初始配置文件`nebula-graphd.conf.default`和`neb
| `ws_http_port` | `19669` | HTTP 服务的端口。 |不支持|
|`heartbeat_interval_secs` | `10` | 默认心跳间隔。请确保所有服务的`heartbeat_interval_secs`取值相同,否则会导致系统无法正常工作。单位:秒。 |支持|
|`storage_client_timeout_ms`|-| Graph 服务与 Storage 服务的 RPC 连接超时时间。初始配置文件中未设置该参数,使用需手动添加。默认值为`60000`毫秒。|不支持|
-{{ ent.ent_begin }}
-|`enable_record_slow_query`|`true`|是否启用慢查询记录。|不支持|
-|`slow_query_limit`|`100`|慢查询记录的最大条数。|不支持|
-{{ ent.ent_end }}
+|`enable_record_slow_query`|`true`|是否启用慢查询记录。注:企业版功能。|不支持|
+|`slow_query_limit`|`100`|慢查询记录的最大条数。注:企业版功能。|不支持|
|`slow_query_threshold_us`|`200000`|定义超过多长时间的查询为慢查询。单位:微秒。|不支持|
|`ws_meta_http_port`|`19559`|HTTP 协议监听 Meta 服务的端口,需要和 Meta 服务配置文件中的`ws_http_port`保持一致。|不支持|
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
index b155343308..85031fd638 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
@@ -199,7 +199,7 @@ rocksdb options 配置的格式为`{"":""}`,多个
| `negative_pool_capacity` | `50` | 消极缓存池的大小。 单位:兆字节。 |
| `negative_item_ttl` | `300` | 消极缓存条目的有效时间。单位:秒。 | -->
-## Black box 配置
+## black box 配置
!!! enterpriseonly
@@ -217,9 +217,11 @@ rocksdb options 配置的格式为`{"":""}`,多个
## memory tracker 配置
+有关 Memory Tracker 的详细信息,请参见[图数据库 NebulaGraph 的内存管理实践之 Memory Tracker](https://discuss.nebula-graph.com.cn/t/topic/13128)。
+
| 名称 | 预设值 | 说明 |是否支持运行时动态修改|
| :------------------- | :------------------------ | :------------------------------------------ |:----------------------- |
-|`memory_tracker_limit_ratio` |`0.8` |取值可设置为:`(0, 1]`、`2`、`3`。
`(0, 1]`:可用内存的百分比,当可用内存低于该值时,{{nebula.name}}会停止接受查询。
计算公式:可用内存/(总内存 - 保留内存)。
**注意**:对于混合部署的集群,需要根据实际情况**调小**该参数。例如,当预期 Graphd 只占用 50% 的内存时,该参数的值可设置为小于`0.5`。
`2`:动态自适应模式(Dynamic Self Adaptive),MemoryTracker 会根据系统当前的可用内存,动态调整可用内存。
**注意**:此功能为实验性功能,由于动态自适应不能做到实时监控操作系统内存使用情况,在一些大内存分配的场景,还是会存在 OOM 可能。
`3`:关掉 MemoryTracker,MemoryTracker 将只记录内存使用情况,即使超过限额,也不会干预执行。|支持|
+|`memory_tracker_limit_ratio` |`0.8` |取值可设置为:`(0, 1]`、`2`、`3`。
`(0, 1]`:可用内存的百分比,当可用内存低于该值时,{{nebula.name}}会停止接受查询。
计算公式:可用内存/(总内存 - 保留内存)。
**注意**:对于混合部署的集群,需要根据实际情况**调小**该参数。例如,当预期 Graphd 只占用 50% 的内存时,该参数的值可设置为小于`0.5`。
`2`:动态自适应模式(Dynamic Self Adaptive),Memory Tracker 会根据系统当前的可用内存,动态调整可用内存。
**注意**:此功能为实验性功能,由于动态自适应不能做到实时监控操作系统内存使用情况,在一些大内存分配的场景,还是会存在 OOM 可能。
`3`:关掉 Memory Tracker,Memory Tracker 将只记录内存使用情况,即使超过限额,也不会干预执行。|支持|
|`memory_tracker_untracked_reserved_memory_mb` |`50`|保留内存的大小,单位:MB。|支持|
|`memory_tracker_detail_log` |`false` | 是否定期生成较详细的内存跟踪日志。当值为`true`时,会定期生成内存跟踪日志。|支持|
|`memory_tracker_detail_log_interval_ms` |`60000`|内存跟踪日志的生成时间间隔,单位:毫秒。仅当`memory_tracker_detail_log`为`true`时,该参数生效。|支持|
diff --git a/docs-2.0/9.about-license/2.license-management-suite/3.license-manager.md b/docs-2.0/9.about-license/2.license-management-suite/3.license-manager.md
index 53dc07e2b7..764fb944d2 100644
--- a/docs-2.0/9.about-license/2.license-management-suite/3.license-manager.md
+++ b/docs-2.0/9.about-license/2.license-management-suite/3.license-manager.md
@@ -185,7 +185,7 @@ LM 启动后,可在 LM 的安装路径下通过 LM CLI 工具查看 License
| 字段 | 说明 |
| :--- | :--- |
| `LMID` | LM 的 ID。获取 License Key 时,需要绑定该 LMID。|
- | `LicenseStatus` | License 的状态。包括:
`Normal`:可正常使用 License。
`NotExist`:License Key 不存在。
`Invalid`:License Key 无效。
`Syncing`:正在从 [LC](2.license-center.md) 同步 License 信息。
`Expiring`:License 即将过期。
`Expired`:License 已过期。|
+ | `LicenseStatus` | License 的状态。包括:
`Normal`:可正常使用 License。
`NotExist`:License Key 不存在。
`Invalid`:License Key 无效。
`Expiring`:License 即将过期。
`Expired`:License 已过期。|
| `LicenseKey` | 一个包含授权信息的加密字符串,是用户获得悦数图数据库及附属软件功能授权的唯一凭证。 |
| `Type` | 购买的资源类型。目前支持购买`NODE`(节点)和`CPU`类型资源。|
| `Query Node` | 购买的查询节点的数量 |
diff --git a/docs-2.0/README.md b/docs-2.0/README.md
index 97a49408e1..93527d9c3a 100644
--- a/docs-2.0/README.md
+++ b/docs-2.0/README.md
@@ -29,16 +29,35 @@ NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库
* [生态工具](20.appendix/6.eco-tool-version.md)
* [Academy 课程](https://academic.nebula-graph.io/intro/)
+## 最新发布
+
+{{comm.comm_begin}}
+- [{{nebula.name}} {{nebula.release}}](20.appendix/release-notes/nebula-comm-release-note.md)
+- [Studio](20.appendix/release-notes/studio-release-note.md)
+- [Dashboard](20.appendix/release-notes/dashboard-comm-release-note.md)
+{{comm.comm_end}}
+
+{{ent.ent_begin}}
+- [{{nebula.name}} {{nebula.release}}](20.appendix/release-notes/nebula-ent-release-note.md)
+- [{{dashboard_ent.name}}](20.appendix/release-notes/dashboard-ent-release-note.md)
+- [{{explorer.name}}](20.appendix/release-notes/explorer-release-note.md)
+{{ent.ent_end}}
+
+
## 其他资料
- [学习路径](https://academic.nebula-graph.io/?lang=ZH_CN)
-{{ comm.comm_begin }}
+ {{ comm.comm_begin }}
- [引用 NebulaGraph](https://arxiv.org/abs/2206.07278)
-{{ comm.comm_end }}
- [论坛](https://discuss.nebula-graph.com.cn/)
- [主页](https://nebula-graph.com.cn/)
- [系列视频](https://space.bilibili.com/472621355)
- [英文文档](https://docs.nebula-graph.io/)
+ {{ comm.comm_end }}
+ {{ ent.ent_begin }}
+- [主页](https://yueshu.com.cn/)
+ {{ ent.ent_end }}
+
## 图例说明
diff --git a/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md b/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
index f6bb539127..3dfd41ca4b 100644
--- a/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
+++ b/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
@@ -10,7 +10,8 @@
|{{nebula.name}}|{{br_ent.name}}|Agent |
|:---|:---|:---|
-|3.5.x|3.5.0、3.4.1、3.4.0|3.4.0|
+|3.5.x|3.5.1|3.4.0|
+|3.4.1|3.4.1、3.4.0|3.4.0|
## 安装{{br_ent.name}}
diff --git a/docs-2.0/graph-computing/nebula-algorithm.md b/docs-2.0/graph-computing/nebula-algorithm.md
index 2a374f19be..99b6fce32a 100644
--- a/docs-2.0/graph-computing/nebula-algorithm.md
+++ b/docs-2.0/graph-computing/nebula-algorithm.md
@@ -29,9 +29,7 @@ NebulaGraph Algorithm 版本和{{nebula.name}}内核的版本对应关系如下
## 使用限制
-- 对于非整数的 String 类型数据,推荐使用调用算法接口的方式,可以使用 SparkSQL 的`dense_rank`函数进行编码,将 String 类型转换为 Long 类型。
-
-- 图计算会输出点的数据集,算法结果会以DataFrame形式作为点的属性存储。用户可以根据业务需求,自行对算法结果做进一步操作,例如统计、筛选。
+图计算会输出点的数据集,算法结果会以DataFrame形式作为点的属性存储。用户可以根据业务需求,自行对算法结果做进一步操作,例如统计、筛选。
!!! compatibility
@@ -239,6 +237,7 @@ NebulaGraph Algorithm 实现图计算的流程如下:
pagerank: {
maxIter: 10
resetProb: 0.15
+ encodeId:false # 如果点 ID 是字符串类型,请配置为 true。
}
# Louvain 参数
@@ -246,6 +245,7 @@ NebulaGraph Algorithm 实现图计算的流程如下:
maxIter: 20
internalIter: 10
tol: 0.5
+ encodeId:false # 如果点 ID 是字符串类型,请配置为 true。
}
# ...
diff --git a/docs-2.0/nebula-cloud/1.what-is-cloud.md b/docs-2.0/nebula-cloud/1.what-is-cloud.md
index c568cdb3fd..547589b2d0 100644
--- a/docs-2.0/nebula-cloud/1.what-is-cloud.md
+++ b/docs-2.0/nebula-cloud/1.what-is-cloud.md
@@ -2,6 +2,10 @@
{{cloud.name}}(公有云)是一套集成了{{nebula.name}}和数据服务的云上服务,支持一键部署{{nebula.name}}和相关可视化产品。用户可以在几分钟内创建一个图数据库,并快速扩展计算、存储等资源。
+!!! note
+
+ Cloud 当前支持的内核版本是 {{cloud.aliyunRelease}},暂不支持 {{nebula.release}}。
+
-
- {{nebula.name}}:{{nebula.release}}。
## 前提条件
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
index 57b1d5c57a..3f91db7b93 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
@@ -79,7 +79,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
开始导入数据之前,用户需要确认以下信息:
-- 已经[安装部署 {{nebula.name}} {{nebula.release}}](../../4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md) 并获取如下信息:
+- 已经[安装部署{{nebula.name}} {{nebula.release}}](../../4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md) 并获取如下信息:
- Graph 服务和 Meta 服务的的 IP 地址和端口。
@@ -91,7 +91,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
- Schema 的信息,包括 Tag 和 Edge type 的名称、属性等。
-- 已经[编译 Exchange](../ex-ug-compile.md),或者直接[下载](https://repo1.maven.org/maven2/com/vesoft/nebula-exchange/)编译完成的。jar 文件。本示例中使用 Exchange {{exchange.release}}。
+- 已经[编译 Exchange](../ex-ug-compile.md),或者直接[下载](https://repo1.maven.org/maven2/com/vesoft/nebula-exchange/)编译完成的 jar 文件。本示例中使用 Exchange {{exchange.release}}。
- 已经安装 Spark。
@@ -192,10 +192,10 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
#{{nebula.name}}相关配置
nebula: {
address:{
- graph:["127.0.0.1:9669"]
+ graph:["192.168.8.XXX:9669"]
#任意一个 Meta 服务的地址。
#如果您的{{nebula.name}}在虚拟网络中,如k8s,请配置 Leader Meta的地址。
- meta:["127.0.0.1:9559"]
+ meta:["192.168.8.XXX:9559"]
}
user: root
pswd: nebula
@@ -209,7 +209,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
# SST 文件在 HDFS 的存储路径
remote:"/sst"
- # HDFS 的 NameNode 地址
+ # HDFS 的 NameNode 地址,例如 "hdfs://:"。
hdfs.namenode: "hdfs://*.*.*.*:9000"
}
@@ -299,7 +299,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
}
# 指定 CSV 文件的路径。
- # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://ip:port/xx/xx.csv"。
+ # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://:port/xx/xx.csv"。
path: "hdfs://*.*.*.*:9000/dataset/vertex_team.csv"
# 如果 CSV 文件没有表头,使用 [_c0, _c1, _c2, ..., _cn] 表示其表头,并将列指示为属性值的源。
@@ -351,7 +351,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
}
# 指定 CSV 文件的路径。
- # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://ip:port/xx/xx.csv"。
+ # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://:port/xx/xx.csv"。
path: "hdfs://*.*.*.*:9000/dataset/edge_follow.csv"
# 如果 CSV 文件没有表头,使用 [_c0, _c1, _c2, ..., _cn] 表示其表头,并将列指示为属性值的源。
@@ -406,7 +406,7 @@ SST 文件是一个内部包含了任意长度的有序键值对集合的文件
}
# 指定 CSV 文件的路径。
- # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://ip:port/xx/xx.csv"。
+ # 文件存储在 HDFS 上,用双引号括起路径,以 hdfs://开头,例如"hdfs://:port/xx/xx.csv"。
path: "hdfs://*.*.*.*:9000/dataset/edge_serve.csv"
# 如果 CSV 文件没有表头,使用 [_c0, _c1, _c2, ..., _cn] 表示其表头,并将列指示为属性值的源。
diff --git a/docs-2.0/nebula-explorer/db-management/11.import-data.md b/docs-2.0/nebula-explorer/db-management/11.import-data.md
index e29c579fe4..0510149e0c 100644
--- a/docs-2.0/nebula-explorer/db-management/11.import-data.md
+++ b/docs-2.0/nebula-explorer/db-management/11.import-data.md
@@ -8,7 +8,7 @@
- CSV 文件符合 Schema 要求。
-- 账号拥有 GOD、ADMIN 或 DBA 权限。详情参见 [{{nebula.name}}内置角色](../../7.data-security/1.authentication/3.role-list.md)。
+- 账号拥有 GOD、ADMIN、DBA 或 USER 权限。详情参见 [{{nebula.name}}内置角色](../../7.data-security/1.authentication/3.role-list.md)。
## 入口
diff --git a/docs-2.0/nebula-importer/use-importer.md b/docs-2.0/nebula-importer/use-importer.md
index fa39199d75..60d54e387f 100644
--- a/docs-2.0/nebula-importer/use-importer.md
+++ b/docs-2.0/nebula-importer/use-importer.md
@@ -28,19 +28,21 @@ NebulaGraph Importer(简称 Importer)是一款{{nebula.name}}的 CSV 文件
- [RPM/DEB 包安装](../4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md)
{{comm.comm_begin}}
- - [Docker Compose 部署](../4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose.md)
+ - [Docker Compose 部署](../2.quick-start/1.quick-start-overview.md)
- [源码编译安装](../4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md)
{{comm.comm_end}}
-- {{nebula.name}} 中已创建 Schema,包括图空间、Tag 和 Edge type,或者通过参数`manager.hooks.before.statements`设置。
+- {{nebula.name}}中已创建 Schema,包括图空间、Tag 和 Edge type,或者通过参数`manager.hooks.before.statements`设置。
## 操作步骤
-准备好待导入的 CSV 文件并配置 yaml 文件,即可使用本工具向{{nebula.name}}批量导入数据。
+### 创建 CSV 文件
+
+准备好待导入的 CSV 文件并配置 YAML 文件,即可使用本工具向{{nebula.name}}批量导入数据。
!!! note
- yaml 配置文件说明请参见下文的配置文件说明。
+ YAML 配置文件说明请参见下文的[配置文件说明](#_8)。
### 下载二进制包运行
@@ -49,10 +51,10 @@ NebulaGraph Importer(简称 Importer)是一款{{nebula.name}}的 CSV 文件
!!! note
使用 RPM/DEB 包安装的文件路径为`/usr/bin/nebula-importer`。
-2. 启动服务。
+2. 在`nebula-importer`的安装目录下,执行以下命令导入数据。
```bash
- $ ./ --config
+ $ ./ --config
```
### 源码编译运行
@@ -81,7 +83,7 @@ NebulaGraph Importer(简称 Importer)是一款{{nebula.name}}的 CSV 文件
$ make build
```
-4. 启动服务。
+4. 开始导入数据。
```bash
$ ./bin/nebula-importer --config
@@ -92,25 +94,37 @@ NebulaGraph Importer(简称 Importer)是一款{{nebula.name}}的 CSV 文件
使用 Docker 可以不必在本地安装 Go 语言环境,只需要拉取 NebulaGraph Importer 的[镜像](https://hub.docker.com/r/vesoft/nebula-importer),并将本地配置文件和 CSV 数据文件挂载到容器中。命令如下:
```bash
-$ docker pull vesoft/nebula-importer
+$ docker pull vesoft/nebula-importer:
$ docker run --rm -ti \
--network=host \
-v : \
-v : \
- vesoft/nebula-importer:
+ vesoft/nebula-importer: \
--config
```
-- ``:yaml 配置文件的绝对路径。
-- ``:数据文件的绝对路径。如果文件不在本地,请忽略该参数。
-- ``:Importer 的版本号,请填写`v3`。
+- ``:填写 YAML 配置文件的绝对路径。
+- ``:填写 CSV 数据文件的绝对路径。如果文件不在本地,请忽略该参数。
+- ``:填写 Importer 的版本号,请填写`v4`。
!!! note
建议使用相对路径。如果使用本地绝对路径,请检查路径映射到 Docker 中的路径。
+例如:
+
+```bash
+$ docker pull vesoft/nebula-importer:v4
+$ docker run --rm -ti \
+ --network=host \
+ -v /home/user/config.yaml:/home/user/config.yaml \
+ -v /home/user/data:/home/user/data \
+ vesoft/nebula-importer:v4 \
+ --config /home/user/config.yaml
+```
+
## 配置文件说明
-NebulaGraph Importer 的[Github](https://github.com/vesoft-inc/nebula-ng-tools/tree/{{importer.branch}}/importer/examples)内提供多种示例配置文件。配置文件用来描述待导入文件信息、{{nebula.name}}服务器信息等。下文将分类介绍配置文件内的字段。
+NebulaGraph Importer 的 [Github](https://github.com/vesoft-inc/nebula-importer/tree/{{importer.branch}}/examples) 内提供多种示例配置文件。配置文件用来描述待导入文件信息、{{nebula.name}}服务器信息等。下文将分类介绍配置文件内的字段。
!!! note
@@ -160,20 +174,16 @@ manager:
statsInterval: 10s
hooks:
before:
- - statements:
- - UPDATE CONFIGS storage:wal_ttl=3600;
- - UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = true };
- statements:
- |
- DROP SPACE IF EXISTS basic_int_examples;
- CREATE SPACE IF NOT EXISTS basic_int_examples(partition_num=5, replica_factor=1, vid_type=int);
- USE basic_int_examples;
+ DROP SPACE IF EXISTS basic_string_examples;
+ CREATE SPACE IF NOT EXISTS basic_string_examples(partition_num=5, replica_factor=1, vid_type=int);
+ USE basic_string_examples;
wait: 10s
after:
- statements:
- |
- UPDATE CONFIGS storage:wal_ttl=86400;
- UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = false };
+ SHOW SPACES;
```
|参数|默认值|是否必须|说明|
@@ -199,14 +209,14 @@ log:
level: INFO
console: true
files:
- - logs/nebula-importer.log
+ - logs/nebula-importer.log
```
|参数|默认值|是否必须|说明|
|:---|:---|:---|:---|
|`log.level`|`INFO`|否|日志级别。可选值为`DEBUG`、`INFO`、`WARN`、`ERROR`、`PANIC`、`FATAL`。|
|`log.console`|`true`|否|存储日志时是否将日志同步打印到 Console。|
-|`log.files`|-|否|日志文件路径。|
+|`log.files`|-|否|日志文件路径。需手动创建日志文件目录。|
### Source 配置
diff --git a/docs-2.0/nebula-operator/1.introduction-to-nebula-operator.md b/docs-2.0/nebula-operator/1.introduction-to-nebula-operator.md
index 2dbcd7bd93..81f8c84f7e 100644
--- a/docs-2.0/nebula-operator/1.introduction-to-nebula-operator.md
+++ b/docs-2.0/nebula-operator/1.introduction-to-nebula-operator.md
@@ -42,12 +42,13 @@ NebulaGraph Operator 已具备的功能如下:
NebulaGraph Operator 不支持 v1.x 版本的 NebulaGraph,其与{{nebula.name}}版本的对应关系如下:
-|{{nebula.name}}版本 |NebulaGraph Operator 版本 |
-| ------------------- | ---------------- |
-| 3.0.0 ~ 3.4.1 |1.3.0、1.4.0 ~ 1.4.2|
-| 3.0.0 ~ 3.3.x |1.0.0、1.1.0、1.2.0|
-| 2.5.x ~ 2.6.x |0.9.0|
-| 2.5.x |0.8.0|
+| {{nebula.name}}版本 | NebulaGraph Operator 版本 |
+| ------------------- | ------------------------- |
+| 3.5.x | 1.5.0 |
+| 3.0.0 ~ 3.4.1 | 1.3.0、1.4.0 ~ 1.4.2 |
+| 3.0.0 ~ 3.3.x | 1.0.0、1.1.0、1.2.0 |
+| 2.5.x ~ 2.6.x | 0.9.0 |
+| 2.5.x | 0.8.0 |
!!! Compatibility "历史版本兼容性"
diff --git a/docs-2.0/nebula-operator/10.backup-restore-using-operator.md b/docs-2.0/nebula-operator/10.backup-restore-using-operator.md
index a2d6619f69..4c953fc4f0 100644
--- a/docs-2.0/nebula-operator/10.backup-restore-using-operator.md
+++ b/docs-2.0/nebula-operator/10.backup-restore-using-operator.md
@@ -8,7 +8,7 @@
## 原理介绍
-[{{br_ent.name}}](../backup-and-restore/nebula-br-ent/1.br-ent-overview.md)工具是{{nebula.name}}企业版数据备份和恢复的命令行工具。NebulaGraph Operator 基于{{br_ent.name}}工具来实现 Kubernetes 上的{{nebula.name}}集群数据的备份和恢复。
+[{{br_ent.name}}](../backup-and-restore/nebula-br-ent/1.br-ent-overview.md)工具是{{nebula.name}}企业版数据备份和恢复的命令行工具。NebulaGraph Operator 使用{{br_ent.name}}工具来实现 Kubernetes 上的{{nebula.name}}集群数据的备份和恢复。
备份数据时,NebulaGraph Operator 会创建一个 Job,然后将{{nebula.name}}集群中的数据备份到指定的存储服务上。
@@ -44,8 +44,22 @@
- NebulaGraph Operator 支持全量备份和增量备份。
- 数据备份过程中,指定图空间中的 DDL 和 DML 语句将会阻塞,我们建议在业务低峰期进行操作,例如凌晨 2 点至 5 点。
- 执行增量备份的集群和指定的上一次备份的集群需为同一个,并且和指定的上一次备份的(存储桶)路径需相同。
-- 确保每次增量备份距离上一次备份的时间小于一个`wal_ttl`的时间。
+- 确保每次增量备份距离上一次备份的时间小于一个[`wal_ttl`](../5.configurations-and-logs/1.configurations/4.storage-config.md#raft)的时间。
- 不支持备份指定图空间数据。
+- 执行备份 Job 前,需要创建一个 Secret,用于存储拉取私有仓库中{{br_ent.name}}镜像所需的凭证。
+
+ ```
+ kubectl - create secret docker-registry \
+ --docker-server=REGISTRY_SERVER \
+ --docker-username=REGISTRY_USERNAME \
+ --docker-password=REGISTRY_PASSWORD \
+ ```
+
+ - ``:存放该 Secret 的命名空间。确保该命名空间与备份 Job 的命名空间相同。
+ - ``:Secret 的名称。
+ - `REGISTRY_SERVER`:指定拉取镜像的私有仓库服务器地址,例如`reg.example-inc.com`。
+ - `REGISTRY_USERNAME`:镜像仓库用户名。
+ - `REGISTRY_PASSWORD`:镜像仓库密码。
### 全量备份
@@ -60,24 +74,26 @@ metadata:
name: nebula-full-backup
spec:
parallelism: 1
- ttlSecondsAfterFinished: 60
+ ttlSecondsAfterFinished: 600
template:
spec:
restartPolicy: OnFailure
+ imagePullSecrets:
+ - name: br-ent-secret # 拉取私有仓库中{{br_ent.name}}镜像所需的凭证的 Secret 的名称。
containers:
- - image: vesoft/br-ent:v{{br_ent.release}}
+ - image: reg.vesoft-inc.com/cloud-dev/br-ent:v{{br_ent.release}}}
imagePullPolicy: Always
name: backup
command:
- /bin/sh
- -ecx
- - exec /usr/local/bin/nebula-br backup full
- - --meta $META_ADDRESS:9559
- - --storage s3://$BUCKET
- - --s3.access_key $ACCESS_KEY
- - --s3.secret_key $SECRET_KEY
- - --s3.region $REGION
- - --s3.endpoint https://s3.$REGION.amazonaws.com
+ - 'exec /usr/local/bin/br-ent backup full
+ --meta nebula-metad-0.nebula-metad-headless..svc.cluster.local:9559 # 指定 Meta 服务的地址,将 替换为集群所在的命名空间。
+ --storage s3://BUCKET # 指定备份数据的存储位置。
+ --s3.access_key ACCESS_KEY # 指定访问存储服务的 AccessKey。
+ --s3.secret_key SECRET_KEY # 指定访问存储服务的 SecretKey。
+ --s3.region REGION # 指定存储服务所在的地理区域。
+ --s3.endpoint https://s3.REGION.amazonaws.com' # 指定存储服务的访问地址。
```
### 增量备份
@@ -91,25 +107,26 @@ metadata:
name: nebula-incr-backup
spec:
parallelism: 1
- ttlSecondsAfterFinished: 60
+ ttlSecondsAfterFinished: 600
template:
spec:
restartPolicy: OnFailure
+ imagePullSecrets:
+ - name: br-ent-secret
containers:
- - image: vesoft/br-ent:v{{br_ent.release}}
+ - image: reg.vesoft-inc.com/cloud-dev/br-ent:v{{br_ent.release}}
imagePullPolicy: Always
name: backup
command:
- /bin/sh
- -ecx
- - exec /usr/local/bin/nebula-br backup incr
- - --meta $META_ADDRESS:9559
- - --base $BACKUP_NAME
- - --storage s3://$BUCKET
- - --s3.access_key $ACCESS_KEY
- - --s3.secret_key $SECRET_KEY
- - --s3.region $REGION
- - --s3.endpoint https://s3.$REGION.amazonaws.com
+ - 'exec /usr/local/bin/br-ent backup incr
+ --meta nebula-metad-0.nebula-metad-headless..svc.cluster.local:9559 # 指定 Meta 服务的地址,将 替换为集群所在的命名空间。
+ --storage s3://BUCKET # 指定备份数据的存储位置。
+ --s3.access_key ACCESS_KEY # 指定访问存储服务的 AccessKey。
+ --s3.secret_key SECRET_KEY # 指定访问存储服务的 SecretKey。
+ --s3.region REGION # 指定存储服务所在的地理区域。
+ --s3.endpoint https://s3.REGION.amazonaws.com' # 指定存储服务的访问地址。
```
### 参数说明
@@ -221,7 +238,22 @@ kubectl apply -f .yaml
执行以下命令查看 NebulaRestore 对象的状态。
```bash
-kubectl get rt -w
+kubectl get rt -n
+
+# 输出示例:
+NAME STATUS STARTED COMPLETED AGE
+restore1 Complete 67m 59m 67m
+```
+
+在恢复任务完成后,会创建一个新的 NebulaGraph 集群。执行以下命令查看新集群的状态:
+
+```bash
+kubectl get nc -n
+
+# 输出示例:
+NAME GRAPHD-DESIRED GRAPHD-READY METAD-DESIRED METAD-READY STORAGED-DESIRED STORAGED-READY AGE
+nebula 1 1 1 1 3 3 2d3h
+ngxvsm 1 1 1 1 3 3 92m # 新集群
```
diff --git a/docs-2.0/nebula-operator/2.deploy-nebula-operator.md b/docs-2.0/nebula-operator/2.deploy-nebula-operator.md
index 93c79aa201..0901217743 100644
--- a/docs-2.0/nebula-operator/2.deploy-nebula-operator.md
+++ b/docs-2.0/nebula-operator/2.deploy-nebula-operator.md
@@ -86,7 +86,7 @@ image:
image: vesoft/nebula-operator:{{operator.tag}}
imagePullPolicy: Always
kubeRBACProxy:
- image: gcr.io/kubebuilder/kube-rbac-proxy:v0.13.0
+ image: bitnami/kube-rbac-proxy:0.14.2
imagePullPolicy: Always
kubeScheduler:
image: registry.k8s.io/kube-scheduler:v1.24.11
@@ -287,7 +287,7 @@ helm install nebula-operator nebula-operator/nebula-operator --namespace=:指定 Secret 的名称。
+ - ``:指定 Secret 的名称。
- DOCKER_REGISTRY_SERVE:指定拉取镜像的私有仓库服务器地址,例如`reg.example-inc.com`
- DOCKER_USE:镜像仓库用户名。
- DOCKER_PASSWORD:镜像仓库密码。
diff --git a/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.1create-cluster-with-kubectl.md b/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.1create-cluster-with-kubectl.md
index 200456931a..13579b896e 100644
--- a/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.1create-cluster-with-kubectl.md
+++ b/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.1create-cluster-with-kubectl.md
@@ -22,6 +22,7 @@
kubectl create namespace nebula
```
+ {{ent.ent_begin}}
2. 创建 Secret,用于拉取私有仓库中{{nebula.name}}镜像。
```bash
@@ -31,12 +32,12 @@
--docker-password=DOCKER_PASSWORD
```
- - :存放该 Secret 的命名空间。
+ - ``:存放该 Secret 的命名空间。
- ``:指定 Secret 的名称。
- DOCKER_REGISTRY_SERVE:指定拉取镜像的私有仓库服务器地址,例如`reg.example-inc.com`。
- DOCKER_USE:镜像仓库用户名。
- DOCKER_PASSWORD:镜像仓库密码。
-
+ {{ent.ent_end}}
3. 创建集群配置文件。
@@ -46,9 +47,10 @@
{{ent.ent_begin}}
联系销售人员获取完整配置示例。必须自定义修改以下参数,其他参数可按需修改。
- - `spec.metad.licenseManagerURL`
- - `spec..image`
- - `spec.imagePullSecrets`
+
+ - `spec.metad.licenseManagerURL`
+ - `spec..image`
+ - `spec.imagePullSecrets`
{{ent.ent_end}}
示例配置的参数描述如下:
@@ -72,6 +74,7 @@
| `spec.storaged.dataVolumeClaims.resources.requests.storage` | - | Storaged 服务的数据盘存储大小,可指定多块数据盘存储数据。当指定多块数据盘时,路径为:`/usr/local/nebula/data1`、`/usr/local/nebula/data2`等。 |
| `spec.storaged.dataVolumeClaims.resources.storageClassName` | - | Storaged 服务的数据盘存储配置。使用示例配置时需要将其替换为事先创建的存储类名称,参见 [Storage Classes](https://kubernetes.io/docs/concepts/storage/storage-classes/) 查看创建存储类详情。 |
| `spec.storaged.logVolumeClaim.storageClassName`|-|Storaged 服务的日志盘存储配置。使用示例配置时需要将其替换为事先创建的存储类名称,参见 [Storage Classes](https://kubernetes.io/docs/concepts/storage/storage-classes/) 查看创建存储类详情。 |
+ |`spec.agent`|`{}`| Agent 服务的配置。用于备份和恢复及日志清理功能,如果不自定义该配置,将使用默认配置。|
| `spec.reference.name` | - | 依赖的控制器名称。 |
| `spec.schedulerName` | - | 调度器名称。 |
| `spec.imagePullPolicy` | {{nebula.name}}镜像的拉取策略。关于拉取策略详情,请参考 [Image pull policy](https://kubernetes.io/docs/concepts/containers/images/#image-pull-policy)。 | 镜像拉取策略。 |
@@ -95,7 +98,7 @@
{{ ent.ent_end }}
-2. 创建{{nebula.name}}集群。
+4. 创建{{nebula.name}}集群。
```bash
kubectl create -f apps_v1alpha1_nebulacluster.yaml
@@ -108,7 +111,7 @@
```
-3. 查看{{nebula.name}}集群状态。
+5. 查看{{nebula.name}}集群状态。
```bash
kubectl get nebulaclusters nebula
diff --git a/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.2create-cluster-with-helm.md b/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.2create-cluster-with-helm.md
index afe9824157..c190ad951a 100644
--- a/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.2create-cluster-with-helm.md
+++ b/docs-2.0/nebula-operator/3.deploy-nebula-graph-cluster/3.2create-cluster-with-helm.md
@@ -55,9 +55,9 @@
- DOCKER_USE:镜像仓库用户名。
- DOCKER_PASSWORD:镜像仓库密码。
- {{ent.ent_end}}}
+ {{ent.ent_end}}
-6. 创建{{nebula.name}}集群。
+1. 创建{{nebula.name}}集群。
```bash
helm install "${NEBULA_CLUSTER_NAME}" nebula-operator/nebula-cluster \
@@ -189,4 +189,5 @@ helm uninstall nebula --namespace=nebula
| `nebula.storaged.readinessProbe` | `{}` | 为 Storaged pod 设置就绪探针以检测容器的状态。 |
| `nebula.storaged.sidecarContainers` | `{}` | 为 Storaged pod 设置 Sidecar Containers。 |
| `nebula.storaged.sidecarVolumes` | `{}` | 为 Storaged Pod 设置 Sidecar Volumes。 |
+|`nebula.agent`|`{}`| Agent 服务的配置。用于备份和恢复及日志清理功能,如果不自定义该配置,将使用默认配置。|
| `imagePullSecrets` | `[]` | 拉取私有仓库镜像的 Secret。 |
diff --git a/docs-2.0/nebula-operator/7.operator-faq.md b/docs-2.0/nebula-operator/7.operator-faq.md
index 8937470b61..2454f09fa2 100644
--- a/docs-2.0/nebula-operator/7.operator-faq.md
+++ b/docs-2.0/nebula-operator/7.operator-faq.md
@@ -47,7 +47,7 @@ cd /usr/local/nebula/logs
image: vesoft/nebula-operator:{{operator.tag}}
imagePullPolicy: Always
kubeRBACProxy:
- image: gcr.io/kubebuilder/kube-rbac-proxy:v0.13.0
+ image: bitnami/kube-rbac-proxy:0.14.2
imagePullPolicy: Always
kubeScheduler:
image: registry.k8s.io/kube-scheduler:v1.24.11
diff --git a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md
index 876ad58c53..4a70ddf0d7 100644
--- a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md
+++ b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md
@@ -28,14 +28,14 @@ $ cd /usr/local/nebula/logs
为了方便日志的采集和管理,每个{{nebula.name}}服务都会部署一个 sidecar 容器,负责收集该服务容器产生的日志,并将其发送到指定的日志磁盘中。sidecar 容器使用 [logrotate](https://linux.die.net/man/8/logrotate) 工具自动清理和归档日志。
-在集群实例的 YAML 配置文件中,可以通过`spec.logRotate`字段配置日志轮转以自动对日志进行清理和归档。默认情况下,日志轮转功能是关闭的。开启日志轮转功能示例如下:
+在集群实例的 YAML 配置文件中,通过`spec.logRotate`字段开启日志轮转功能,同时在`spec..config`下设置`timestamp_in_logfile_name`值为`false`以自动对各服务日志进行清理和归档。默认情况下,日志轮转功能是关闭的。为{{nebula.name}}各个服务都开启日志轮转功能示例如下:
```yaml
...
spec:
graphd:
config:
- # 是否在日志文件名中包含时间戳,true 表示包含,false 表示不包含。
+ # 是否在日志文件名中包含时间戳,需设置为 false 以实现日志轮转。默认值为 true。
"timestamp_in_logfile_name": "false"
metad:
config:
diff --git a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md
index ca61dc3ca5..e731f9ecb3 100644
--- a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md
+++ b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md
@@ -57,7 +57,7 @@ sslCerts:
```yaml
sslCerts:
- # 用于决定客户端在建立 TLS 连接时,是否验证服务器端的证书链和主机名。默认值为`true`。
+ # 用于决定客户端在建立 TLS 连接时,是否验证服务器端的证书链和主机名。
insecureSkipVerify: false
```
diff --git a/docs-2.0/stylesheets/pdf.css b/docs-2.0/stylesheets/pdf.css
new file mode 100644
index 0000000000..9250b2dab3
--- /dev/null
+++ b/docs-2.0/stylesheets/pdf.css
@@ -0,0 +1,3 @@
+* {
+ font-family: Verdana, Geneva, Tahoma, sans-serif !important;
+}
\ No newline at end of file
diff --git a/mkdocs.yml b/mkdocs.yml
index 8734f729ed..8d9d91c832 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -75,7 +75,8 @@ markdown_extensions:
- pymdownx.caret
- pymdownx.tilde
- pymdownx.superfences
- - pymdownx.tabbed
+ - pymdownx.tabbed:
+ alternate_style: true
# Plugins
plugins:
@@ -103,7 +104,7 @@ plugins:
- 9.about-license/5.manage-license.md
- 9.about-license/2.license-management-suite/1.suite-overview.md
- 9.about-license/2.license-management-suite/2.license-center.md
- # exclude.ent.begin
+ # exclude.ent.begin (hide the ent-docs below when releasing comm)
- 9.about-license/*
- 3.ngql-guide/6.functions-and-expressions/17.ES-function.md
- 4.deployment-and-installation/deploy-license.md
@@ -125,7 +126,7 @@ plugins:
- 20.appendix/release-notes/nebula-ent-release-note.md
- 20.appendix/release-notes/dashboard-ent-release-note.md
- 20.appendix/release-notes/explorer-release-note.md
- - 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
+ - 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md
- 2.quick-start/2.quick-start-on-cloud/1.create-instance-on-cloud.md
- 2.quick-start/2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md
- 2.quick-start/2.quick-start-on-cloud/3.how-to-query-on-cloud.md
@@ -136,10 +137,9 @@ plugins:
- nebula-cloud/nebula-cloud-on-alibabacloud/2.use-cloud-services.md
- nebula-cloud/nebula-cloud-on-alibabacloud/3.delete-service-instance.md
- nebula-cloud/nebula-cloud-on-alibabacloud/4.scaling-services.md
- - 4.deployment-and-installation/3.upgrade-nebula-graph/_upgrade-nebula-from-300-to-latest.md
- 3.ngql-guide/6.functions-and-expressions/9.user-defined-functions.md
# exclude.ent.end
- # exclude.comm.begin
+ # exclude.comm.begin (hide the comm-doc when releasing ent)
- nebula-dashboard/1.what-is-dashboard.md
- nebula-dashboard/2.deploy-dashboard.md
- nebula-dashboard/3.connect-dashboard.md
@@ -149,7 +149,7 @@ plugins:
- 2.quick-start/1.quick-start-overview.md
- 2.quick-start/2.start-free-trial-on-cloud.md
- backup-and-restore/nebula-br/*
- - 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
+ - 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm.md
- nebula-studio/*
- nebula-dashboard/
- 20.appendix/release-notes/nebula-comm-release-note.md
@@ -158,11 +158,9 @@ plugins:
- 4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md
- 15.contribution/how-to-contribute.md
- 4.deployment-and-installation/standalone-deployment.md
- - 4.deployment-and-installation/3.upgrade-nebula-graph/_upgrade-nebula-from-300-to-latest.md
- 8.service-tuning/enable_autofdo_for_nebulagraph.md
- 20.appendix/history.md
- 20.appendix/mind-map.md
- - 4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose.md
- 3.ngql-guide/6.functions-and-expressions/9.user-defined-functions.md
# exclude.comm.end
@@ -183,6 +181,8 @@ plugins:
# nav.ent.begin
cover_logo: 'https://docs-cdn.nebula-graph.com.cn/figures/yueshu_favicon_230515.png'
# nav.ent.end
+ pdf_stylesheets:
+ - stylesheets/pdf.css
# nav.ent.begin
output_path: pdf/yueshu-cn.pdf
@@ -243,9 +243,9 @@ extra:
release: 3.7.0
tag: v3.7.0
explorer:
- release: 3.5.0
+ release: 3.5.1
branch: release-3.5
- tag: v3.5.0
+ tag: v3.5.1
# nav.ent.begin
name: 悦数图探索
# nav.ent.end
@@ -314,8 +314,8 @@ extra:
branch: release-3.5
tag: v3.5.0
br_ent:
- release: 3.5.0
- tag: v3.5.0
+ release: 3.5.1
+ tag: v3.5.1
# nav.ent.begin
name: Backup&Restore
# nav.ent.end
@@ -349,8 +349,8 @@ extra:
release: 1.5.0
tag: v1.5.0
branch: release-1.5
- upgrade_from: 3.0.0
- upgrade_to: 3.4.1
+ upgrade_from: 3.5.0
+ upgrade_to: 3.5.x
exporter:
release: 3.3.0
branch: release-3.3
@@ -570,18 +570,16 @@ nav:
- 安装部署:
- 准备资源: 4.deployment-and-installation/1.resource-preparations.md
- - 安装软件包:
+ - 单机安装:
- 使用 RPM/DEB 包安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md
- 使用 TAR 包安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/4.install-nebula-graph-from-tar.md
- - 使用 RPM/DEB 包部署多机集群: 4.deployment-and-installation/2.compile-and-install-nebula-graph/deploy-nebula-graph-cluster.md
- - 使用生态工具安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/6.deploy-nebula-graph-with-peripherals.md
+ - 多机安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/deploy-nebula-graph-cluster.md
+ - 使用生态工具安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/6.deploy-nebula-graph-with-peripherals.md
- 管理服务: 4.deployment-and-installation/manage-service.md
- 连接服务: 4.deployment-and-installation/connect-to-nebula-graph.md
- 管理 Storage 主机: 4.deployment-and-installation/manage-storage-host.md
# - 管理逻辑机架(Zone): 4.deployment-and-installation/5.zone.md
- - 升级版本:
- # - 升级 v3.x 至 v3.4(社区版): 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md
- - 升级悦数图数据库至 v3.5(企业版): 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
+ - 升级版本: 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent.md
- 卸载悦数图数据库: 4.deployment-and-installation/4.uninstall-nebula-graph.md
- 配置与日志:
@@ -803,22 +801,21 @@ nav:
- 回收 PV: nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md
- 均衡扩容后的 Storage 数据: nebula-operator/8.custom-cluster-configurations/8.3.balance-data-when-scaling-storage.md
- 管理集群日志: nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md
- - 启用 TLS 加密: nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md
- - 升级悦数图数据库: nebula-operator/9.upgrade-nebula-cluster.md
- - 配置滚动更新策略: nebula-operator/11.rolling-update-strategy.md
+ - 配置滚动更新策略: nebula-operator/11.rolling-update-strategy.md
+# - 升级悦数图数据库: nebula-operator/9.upgrade-nebula-cluster.md
- 备份与恢复: nebula-operator/10.backup-restore-using-operator.md
- 故障自愈: nebula-operator/5.operator-failover.md
- 常见问题: nebula-operator/7.operator-faq.md
- 性能测试: nebula-bench.md
-
+ - 常见问题 FAQ: 20.appendix/0.FAQ.md
- 附录:
- Release Note:
- 悦数图数据库: 20.appendix/release-notes/nebula-ent-release-note.md
- 悦数运维监控: 20.appendix/release-notes/dashboard-ent-release-note.md
- 悦数图探索: 20.appendix/release-notes/explorer-release-note.md
- 学习路径: 20.appendix/learning-path.md
- - 常见问题 FAQ: 20.appendix/0.FAQ.md
+ - 产品端口全集: 20.appendix/port-guide.md
- 生态工具概览: 20.appendix/6.eco-tool-version.md
- 错误码: 20.appendix/error-code.md
@@ -844,7 +841,7 @@ nav:
- Graph 服务: 1.introduction/3.nebula-graph-architecture/3.graph-service.md
- Storage 服务: 1.introduction/3.nebula-graph-architecture/4.storage-service.md
- 快速入门:
- - 使用 Docker Desktop: 2.quick-start/1.quick-start-overview.md
+ - 基于 Docker: 2.quick-start/1.quick-start-overview.md
- 从云开始(免费试用): 2.quick-start/2.start-free-trial-on-cloud.md
- 本地部署:
- 步骤 1:安装 NebulaGraph: 2.quick-start/3.quick-start-on-premise/2.install-nebula-graph.md
@@ -1004,23 +1001,22 @@ nav:
- 安装部署:
- 准备资源: 4.deployment-and-installation/1.resource-preparations.md
- - 编译与安装:
- - 使用源码安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md
+ - 编译安装:
+ - 编译源码: 4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md
+# - 使用 Docker 编译:
+ - 本地单机安装:
- 使用 RPM/DEB 包安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md
- - 使用 tar.gz 文件安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/4.install-nebula-graph-from-tar.md
- - 使用 Docker Compose 部署: 4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose.md
- - 使用 RPM/DEB 包部署多机集群: 4.deployment-and-installation/2.compile-and-install-nebula-graph/deploy-nebula-graph-cluster.md
- - 使用生态工具安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/6.deploy-nebula-graph-with-peripherals.md
- - 安装存算合并版 NebulaGraph: 4.deployment-and-installation/standalone-deployment.md
+ - 使用 TAR 包安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/4.install-nebula-graph-from-tar.md
+ - 安装存算合并版服务: 4.deployment-and-installation/standalone-deployment.md
+ - 本地多机安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/deploy-nebula-graph-cluster.md
+ - 使用 Docker Compose 安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose.md
+ - 使用生态工具安装: 4.deployment-and-installation/2.compile-and-install-nebula-graph/6.deploy-nebula-graph-with-peripherals.md
- 管理服务: 4.deployment-and-installation/manage-service.md
- 连接服务: 4.deployment-and-installation/connect-to-nebula-graph.md
- 管理 Storage 主机: 4.deployment-and-installation/manage-storage-host.md
# - 管理逻辑机架(Zone): 4.deployment-and-installation/5.zone.md
-
- - 升级版本:
- - 升级 NebulaGraph 至 v3.5(社区版): 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
- # - 升级 v3.x 至 v3.4(社区版): 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md
- - 卸载 NebulaGraph: 4.deployment-and-installation/4.uninstall-nebula-graph.md
+ - 升级版本: 4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-comm.md
+ - 卸载: 4.deployment-and-installation/4.uninstall-nebula-graph.md
- 配置与日志:
- 配置:
@@ -1146,14 +1142,13 @@ nav:
- 自定义 NebulaGraph 集群的配置参数: nebula-operator/8.custom-cluster-configurations/8.1.custom-conf-parameter.md
- 回收 PV: nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md
- 管理集群日志: nebula-operator/8.custom-cluster-configurations/8.4.manage-running-logs.md
- - 启用 TLS 加密: nebula-operator/8.custom-cluster-configurations/8.5.enable-ssl.md
- - 升级 NebulaGraph: nebula-operator/9.upgrade-nebula-cluster.md
- - 配置滚动更新策略: nebula-operator/11.rolling-update-strategy.md
+ - 配置滚动更新策略: nebula-operator/11.rolling-update-strategy.md
+# - 升级 NebulaGraph: nebula-operator/9.upgrade-nebula-cluster.md
- 故障自愈: nebula-operator/5.operator-failover.md
- 常见问题: nebula-operator/7.operator-faq.md
- 图计算:
- - 算法简介: graph-computing/algorithm-description.md
+# - 算法简介: graph-computing/algorithm-description.md
- NebulaGraph Algorithm: graph-computing/nebula-algorithm.md
- NebulaGraph Spark Connector: nebula-spark-connector.md
@@ -1161,21 +1156,23 @@ nav:
- NebulaGraph Flink Connector: nebula-flink-connector.md
- NebulaGraph Bench: nebula-bench.md
+
+ - 常见问题: 20.appendix/0.FAQ.md
+
- 附录:
- Release Note:
- NebulaGraph 社区版: 20.appendix/release-notes/nebula-comm-release-note.md
- NebulaGraph Studio: 20.appendix/release-notes/studio-release-note.md
- NebulaGraph Dashboard 社区版: 20.appendix/release-notes/dashboard-comm-release-note.md
- 学习路径: 20.appendix/learning-path.md
- - 常见问题 FAQ: 20.appendix/0.FAQ.md
- 生态工具概览: 20.appendix/6.eco-tool-version.md
- 导入工具选择: 20.appendix/write-tools.md
+ - 产品端口全集: 20.appendix/port-guide.md
- 社区参与: 15.contribution/how-to-contribute.md
- 年表: 20.appendix/history.md
- 思维导图: 20.appendix/mind-map.md
- 错误码: 20.appendix/error-code.md
# nav.pdf.begin
- - PDF: https://docs-cdn.nebula-graph.com.cn/pdf/master/NebulaGraph-CN.pdf
+ - PDF: ./pdf/NebulaGraph-CN.pdf
# nav.pdf.end
# nav.comm.end
-