简体中文 | English
这部分将介绍如何使用Labelme和PaddleLabel标注工具完成目标检测相关单模型的数据标注。 点击上述链接,参考⾸⻚⽂档即可安装数据标注⼯具并查看详细使⽤流程。

Labelme 是一个 python 语言编写,带有图形界面的图像标注软件。可用于图像分类,目标检测,图像分割等任务,在目标检测的标注任务中,标签存储为 JSON 文件。
为避免环境冲突,建议在 conda 环境下安装。
conda create -n labelme python=3.10
conda activate labelme
pip install pyqt5
pip install labelme- 创建数据集根目录,如
hemlet。 - 在
hemlet中创建images目录(必须为images目录),并将待标注图片存储在images目录下,如下图所示:
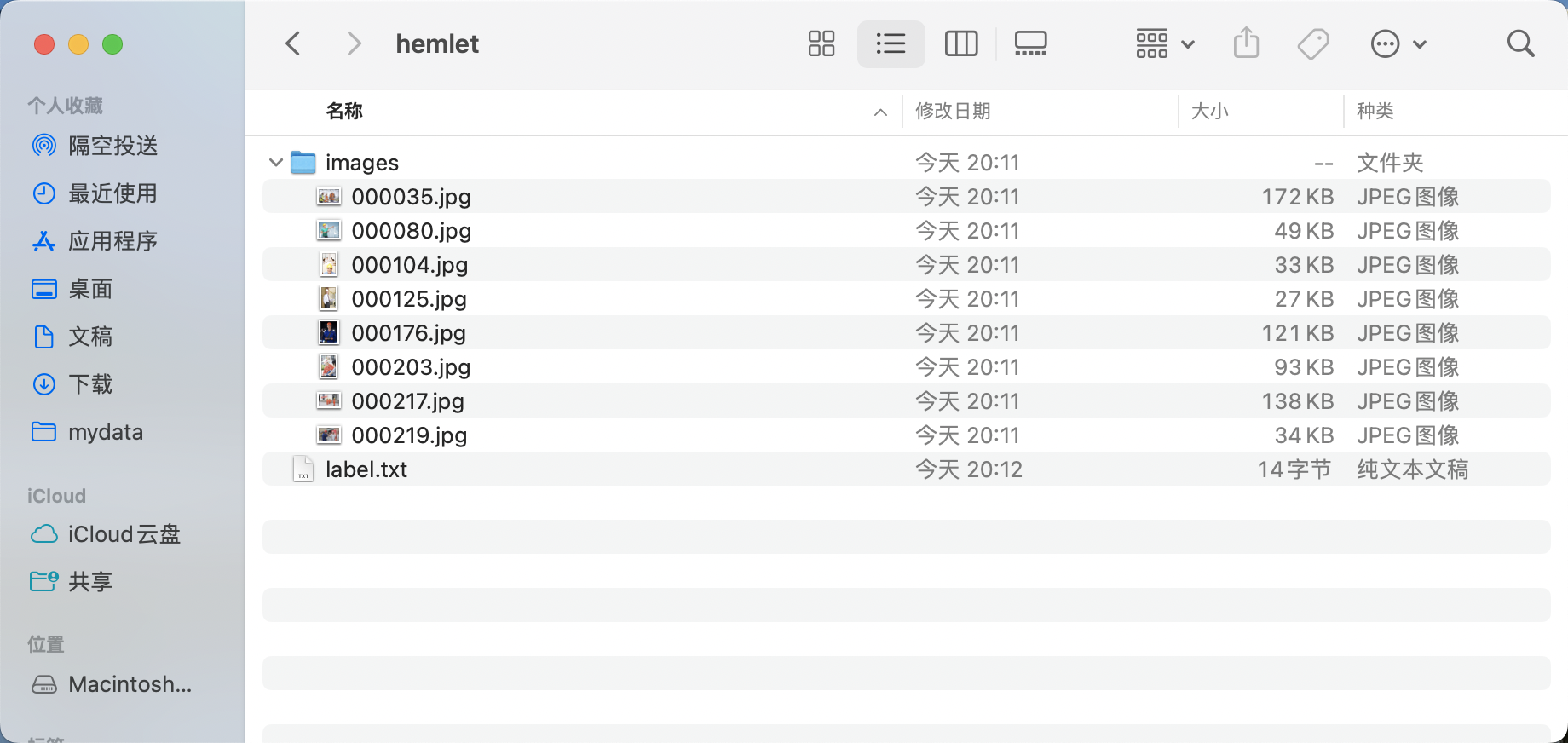
- 在
hemlet文件夹中创建待标注数据集的类别标签文件label.txt,并在label.txt中按行写入待标注数据集的类别。安全帽检测数据集的label.txt为例,如下图所示:

终端进入到待标注数据集根目录,并启动 Labelme 标注工具:
cd path/to/hemlet
labelme images --labels label.txt --nodata --autosave --output annotationsflags为图像创建分类标签,传入标签路径。nodata停止将图像数据存储到JSON文件。autosave自动存储。ouput标签文件存储路径。
- 启动
Labelme后如图所示:
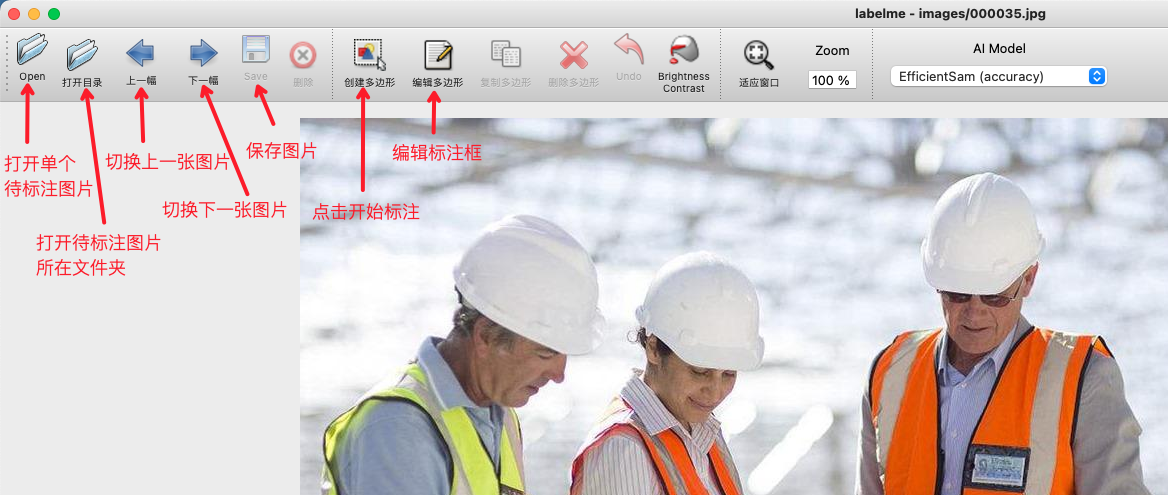
- 点击"编辑"选择标注类型
- 选择创建矩形框
- 在图片上拖动十字框选目标区域

- 再次点击选择目标框类别
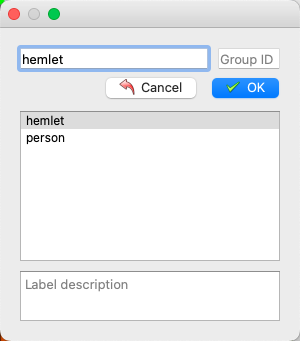
- 标注好后点击存储。(若在启动
Labelme时未指定output字段,会在第一次存储时提示选择存储路径,若指定autosave字段使用自动保存,则无需点击存储按钮)。
- 然后点击
Next Image进行下一张图片的标注。

- 最终标注好的标签文件如图所示:
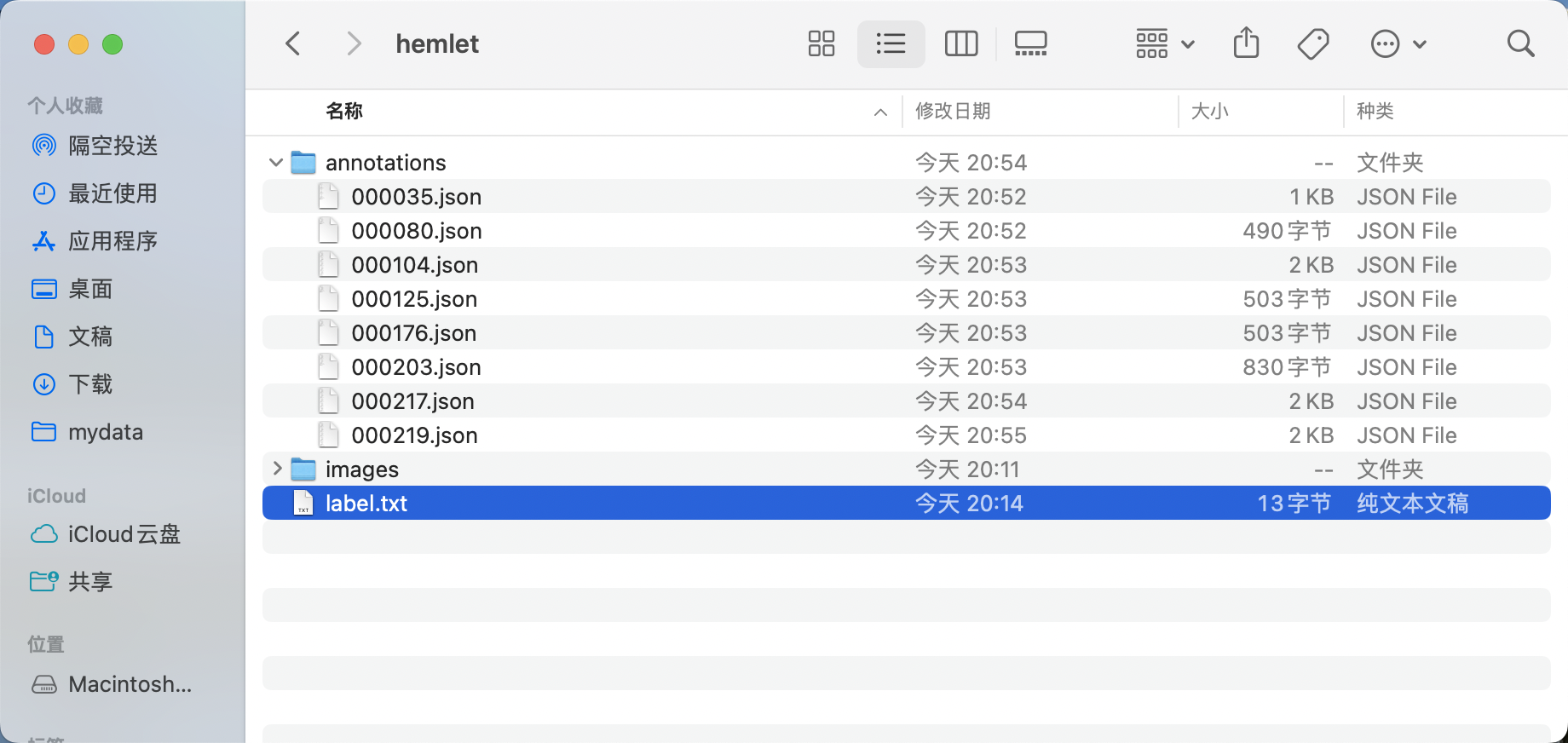
-
调整目录得到安全帽检测标准
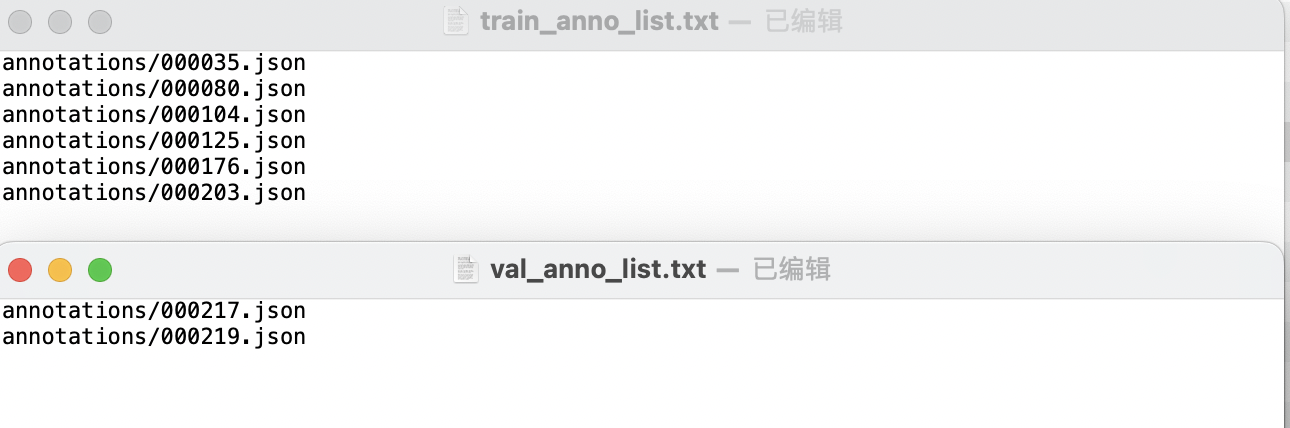
Labelme格式数据集- 在数据集根目录创建
train_anno_list.txt和val_anno_list.txt两个文本文件,并将annotations目录下的全部json文件路径按一定比例分别写入train_anno_list.txt和val_anno_list.txt,也可全部写入到train_anno_list.txt同时创建一个空的val_anno_list.txt文件,使用数据划分功能进行重新划分。train_anno_list.txt和val_anno_list.txt的具体填写格式如图所示:
- 经过整理得到的最终目录结构如下:
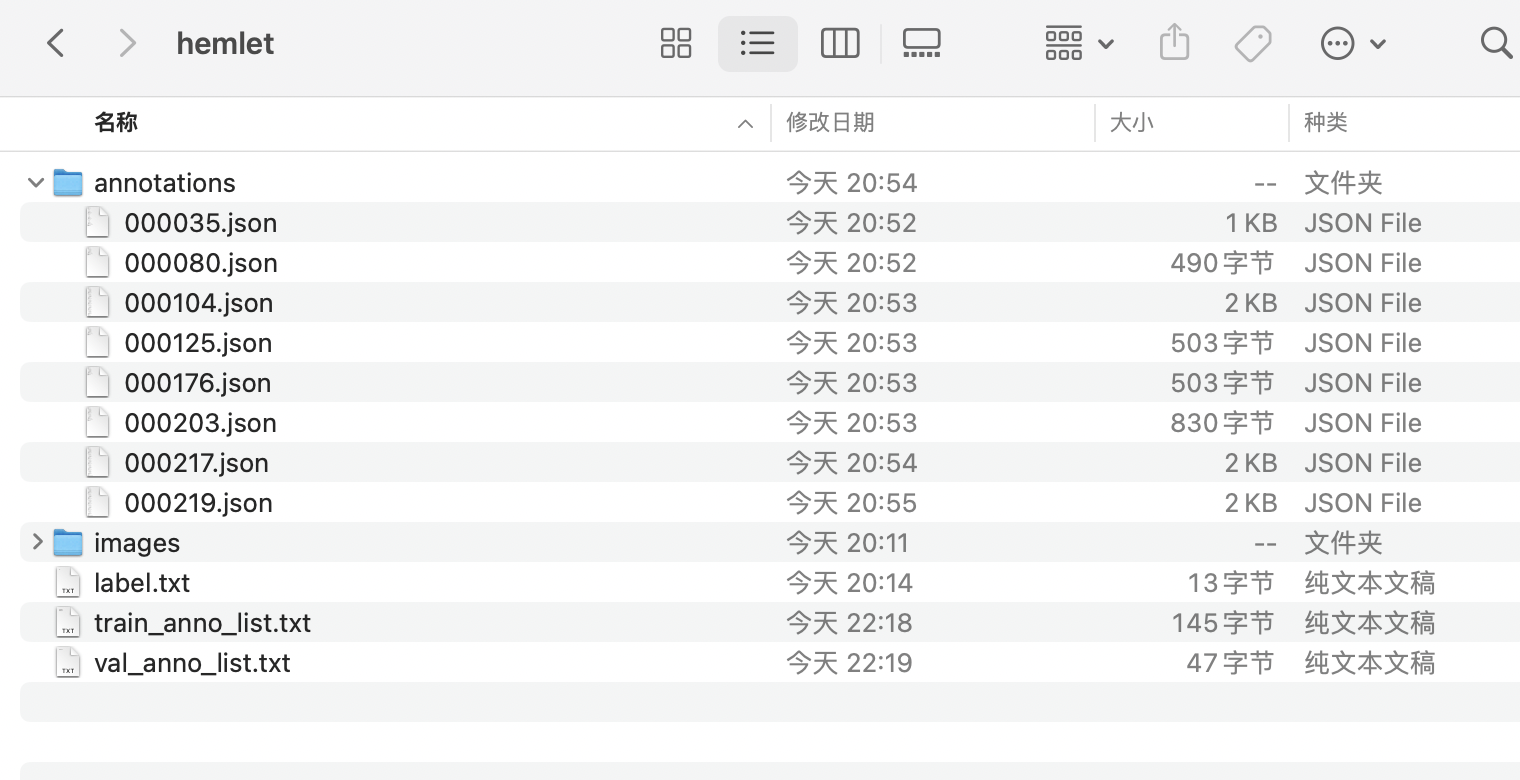
- 在数据集根目录创建
使用Labelme标注完成后,需要将数据格式转换为coco格式。下面给出了按照上述教程使用Lableme标注完成的数据和进行数据格式转换的代码示例:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_labelme_examples.tar -P ./dataset
tar -xf ./dataset/det_labelme_examples.tar -C ./dataset/
python main.py -c paddlex/configs/object_detection/PicoDet-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe- 为避免环境冲突,建议创建一个干净的
conda环境:
conda create -n paddlelabel python=3.11
conda activate paddlelabel- 同样可以通过
pip一键安装
pip install --upgrade paddlelabel
pip install a2wsgi uvicorn==0.18.1
pip install connexion==2.14.1
pip install Flask==2.2.2
pip install Werkzeug==2.2.2- 安装成功后,可以在终端使用如下指令之一启动 :
paddlelabel # 启动paddlelabel
pdlabel # 缩写,和paddlelabel完全相同PaddleLabel 启动后会自动在浏览器中打开网页,接下来可以根据任务开始标注流程了。
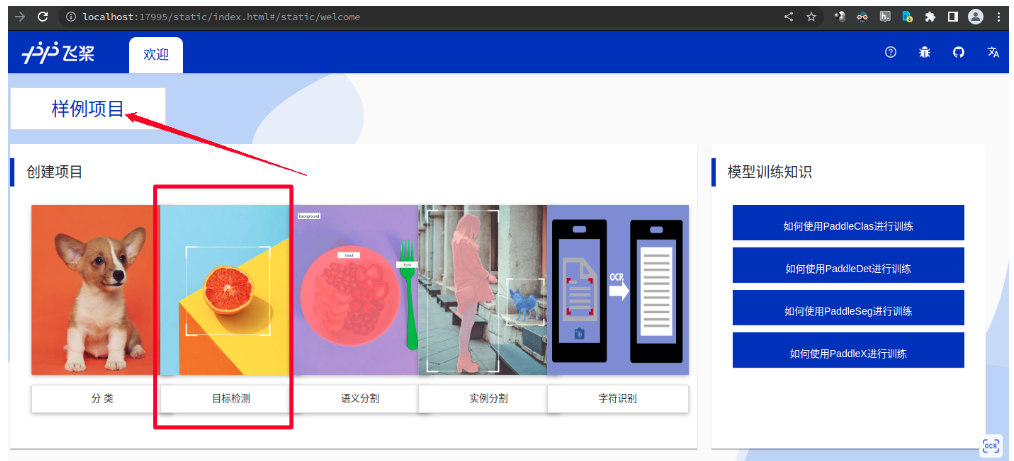
- 打开自动弹出的网页,点击样例项目,点击目标检测
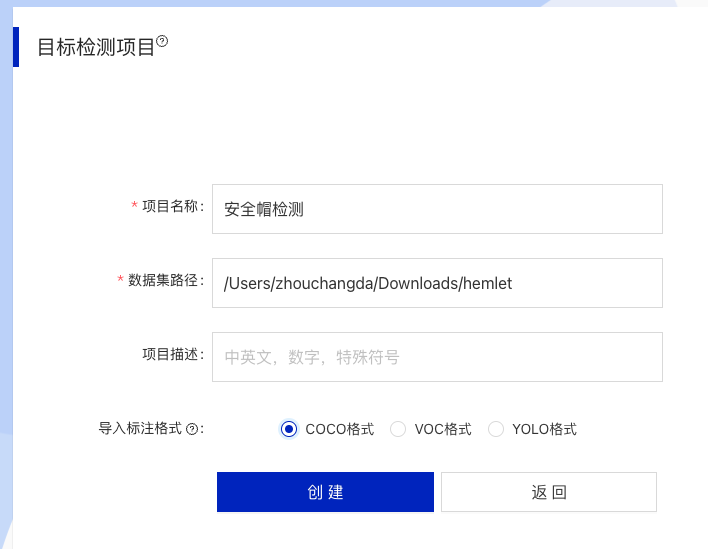
- 填写项目名称,数据集路径,注意路径是本地机器上的 绝对路径。完成后点击创建。
- 首先定义需要标注的类别,以版面分析为例,提供10个类别,每个类别有唯一对应的id,点击添加类别,创建所需的类别名
- 开始标注
- 首先选择需要标注的标签
- 点击左侧的矩形选择按钮
- 在图片中框选需要区域,注意按语义进行分区,如出现多栏情况请分别标注多个框
- 完成标注后,右下角会出现标注结果,可以检查标注是否正确
- 全部完成之后点击项目总览

- 导出标注文件
- 在项目总览中按需求划分数据集,然后点击导出数据集
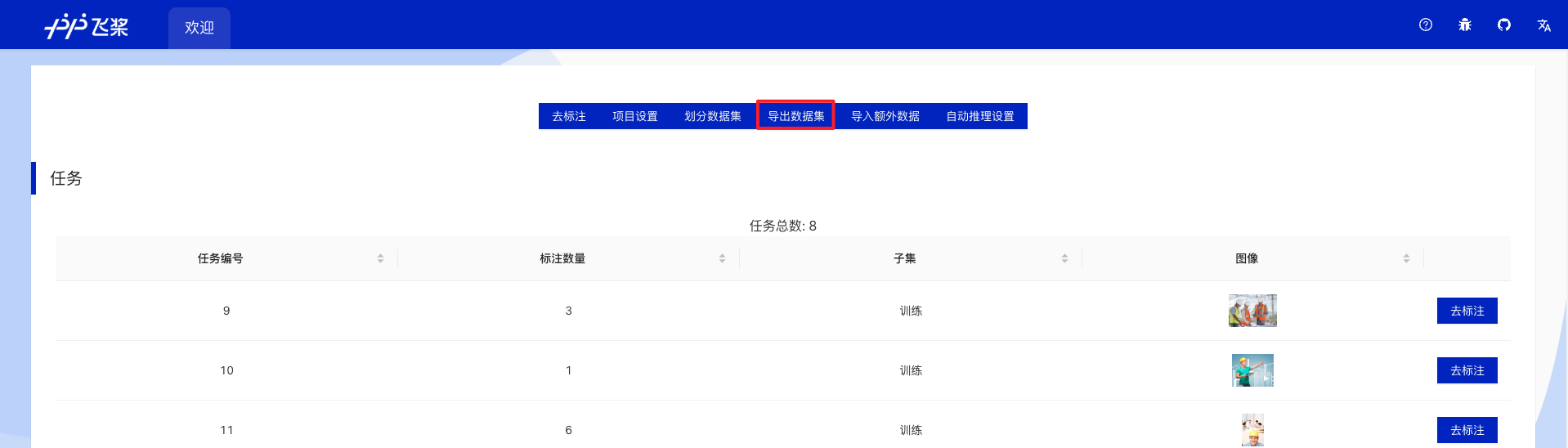
- 填写导出路径和导出格式,导出路径依然是一个绝对路径,导出格式请选择
coco
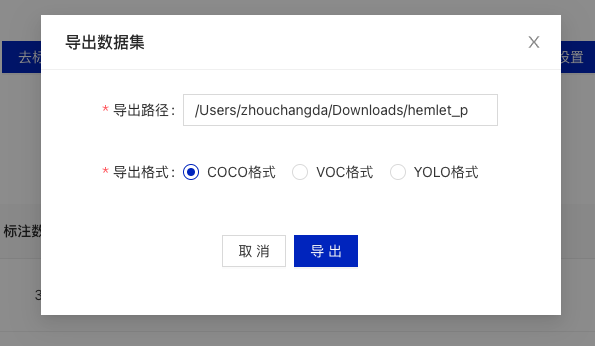
- 导出成功后,在指定的路径下就可以获得标注文件。

- 调整目录得到安全帽检测标准
coco格式数据集- 并将三个
json文件以及image目录进行重命名,对应关系如下:
- 并将三个
| 源文件(目录)名 | 重命名后文件(目录)名 |
|---|---|
train.json |
instance_train.json |
val.json |
instance_train.json |
test.json |
instance_test.json |
image |
images |
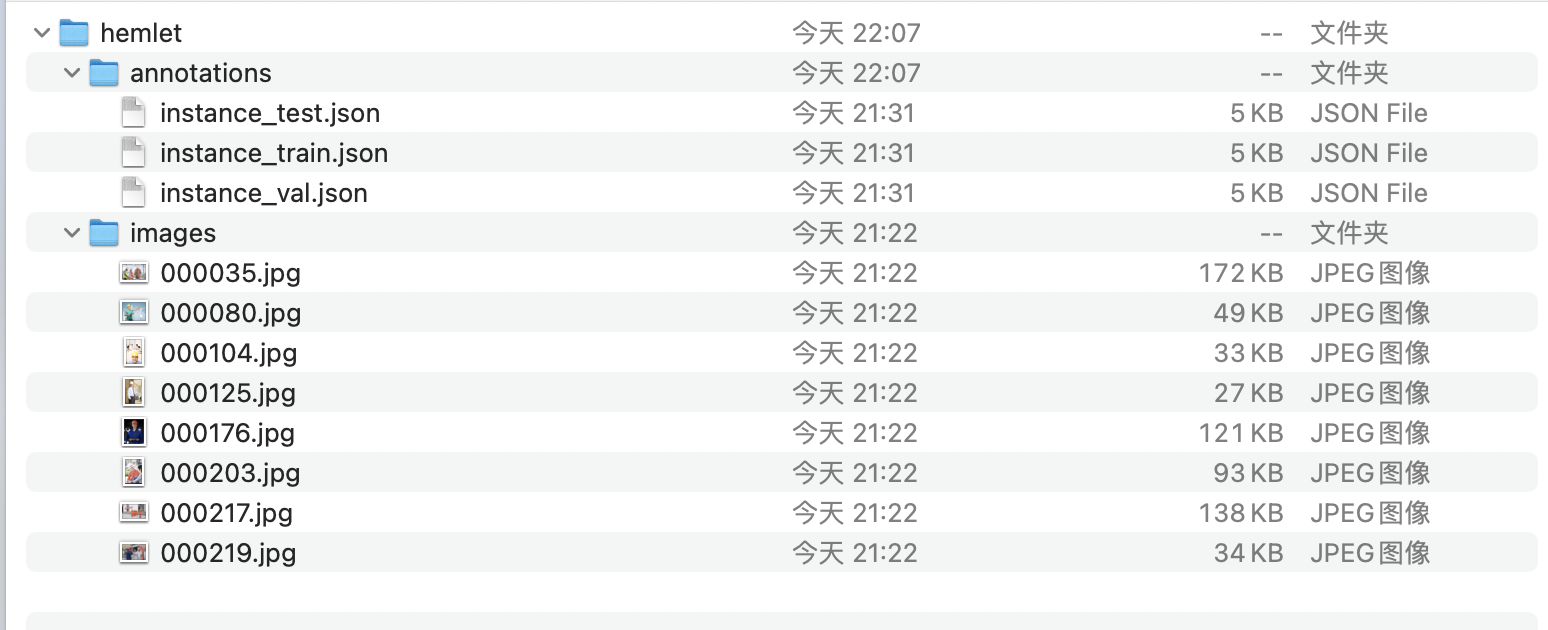
- 在数据集根目录创建
annotations目录,并将json文件全部移动到annotations目录下,得到最后的数据集目录如下:
- 将
hemlet目录打包压缩为.tar或.zip格式压缩包即可得到安全帽检测标准coco格式数据集
PaddleX 针对目标检测任务定义的数据集,名称是 COCODetDataset,组织结构和标注格式如下:
dataset_dir # 数据集根目录,目录名称可以改变
├── annotations # 标注文件的保存目录,目录名称不可改变
│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式
│ └── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式
└── images # 图像的保存目录,目录名称不可改变标注文件采用 COCO 格式。请大家参考上述规范准备数据,此外可以参考示例数据集 。