AWS の資格試験でよく出てくる DR(ディザスタ・リカバリ)戦略についてまとめ、どういう要件の時にどの戦略を取るべきかを把握できるようにします。
主に AWS の公式ブログに書かれている内容を元に自分なりにまとめていった資料となります。
内容は濃すぎずなんとなくわかる程度に書いたものなのでもっと詳しく知りたい方は参考情報のリンクから AWS の公式ブログを確認してください。
DR とは ディザスタ・リカバリ の略で 災害復旧の戦略 についてのことを指します。
災害復旧方法はどういう戦略をとるかは 企業の状況やサービスの特性 によって決まるのでいくつかのパターンを把握しておきどの戦略で行くべきかを判断できるようになっておくことが大切でしょう。
DR 戦略を決めるうえで知らなくてはいけない考え方といくつかの用語があるのでしっかりと押さえておきます。

出典:目標復旧時間 (RTO) と目標復旧時点 (RPO) - 信頼性の柱
そもそも障害が発生したら ビジネス継続性計画(BCP) を元に いつまで(RTO) に いつの時点(RPO) に戻さないといけないのかを考える必要があります。いつまで(RTO) に いつの時点(RPO) によってシステムの構成を アクティブ/アクティブ にするべきなのかそれとも アクティブ/パッシブ にするべきなのかも変わってきます。
ビジネス継続性計画(BCP)、いつまでに(RTO)、いつの時点(RPO)、アクティブ/アクティブ、アクティブ/パッシブ の言葉について押さえておきます。
災害や障害などが起こった時に ビジネスを継続させるための計画のこと を指します。
サービスに障害が発生し 復旧するまでに許容される時間のこと を指します。
例:障害が発生したら 30分(RTO) で復旧しないといけない
サービスに障害が発生してから いつまでのデータを復旧するかのこと を指します。
例:障害が発生してから 5分前のデータ時点(RPO) まで戻さないといけない
同じ構成のシステムを複数用意(冗長化) しそれぞれのシステムでリクエストをさばきます。
いずれかのシステムに障害が発生した場合は障害のあったシステムへのリクエストが遮断され動いているシステムのみで動作させる方法です。
システムが多重化されているため、信頼性も高い構成となっています。
同じ構成あるいは本番環境よりも劣った環境を用意しておき待機 させておきます。リクエストは本番環境のみでさばき、障害が発生した場合は待機させておいたシステムを稼働させ、こちらでリクエストをさばく方法です。
この時、本番環境相当のものを待機させておくことを ホットスタンバイ と言い、本番環境よりも劣った環境を待機させておくことを ウォームスタンバイ という。
RTO(目標復旧時間)とRPO(目標復旧時点)は BCP(ビジネス継続性計画)を決める上でとても重要なものです。
これらは ビジネスが使用不可能な状態になったとき社内外のお客様にどういう影響を与える のか見極め考えるのが良いでしょう。
これらの目標は基本的には 組織が決めるもの になります。
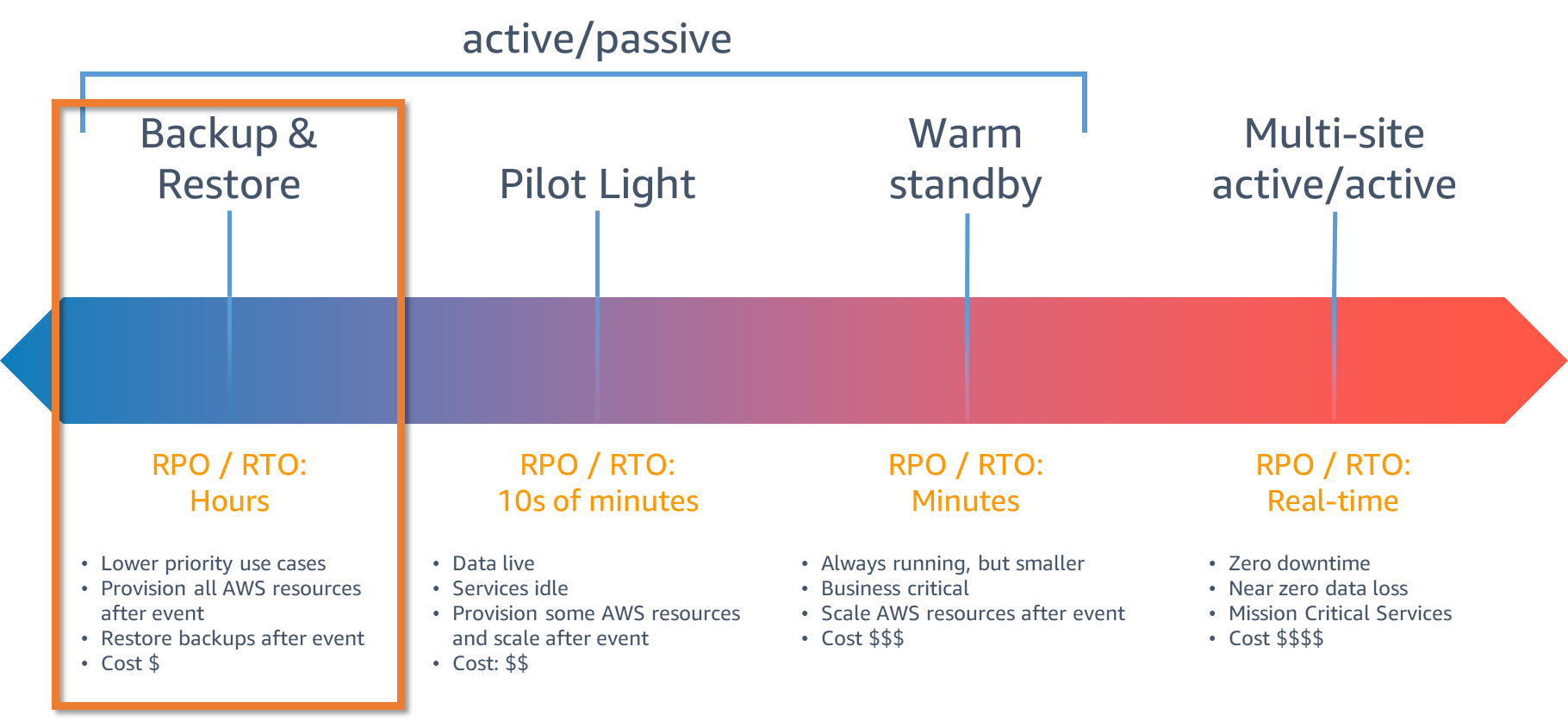
DR 戦略には4つのパターンがあります。復旧時間が早ければ早い程、コストがかかりますが、復旧時間に制限がなく遅くても問題ない場合はコストもかからないようになっていきます。
| DR 戦略 | 復旧時間 | 復旧時点 | 可用性 | コスト | 構成 | 適用範囲 |
|---|---|---|---|---|---|---|
| マルチサイト | ⏱ | ⏱ | ⬆️⬆️⬆️⬆️ | 💸💸💸💸 | アクティブ/アクティブ | リージョンの災害 |
| ウォームスタンバイ | ⏱⏱ | ⏱⏱ | ⬆️⬆️⬆️ | 💸💸💸 | アクティブ/パッシブ | リージョンの災害 |
| パイロットライト | ⏱⏱⏱ | ⏱⏱⏱ | ⬆️⬆️ | 💸💸 | アクティブ/パッシブ | リージョンの災害 |
| バックアップと復元 | ⏱⏱⏱⏱ | ⏱⏱⏱⏱ | ⬆️ | 💸 | アクティブ/パッシブ | 1つの物理センターの中断や喪失 |
AWS のブログに書かれていた記事をもとにまとめていきます。
RTO(目標復旧時間)とRPO(目標復旧時点)を元に考えていくことになります。
それぞれの戦略によってコストや復旧時間やデータのロス時間などが異なるため「コストと複雑度」、「データの消失とサービスの中断」を軸に図に表してみるとわかりやすいと思います。
~RTO(目標復旧時間)ベースで見る~
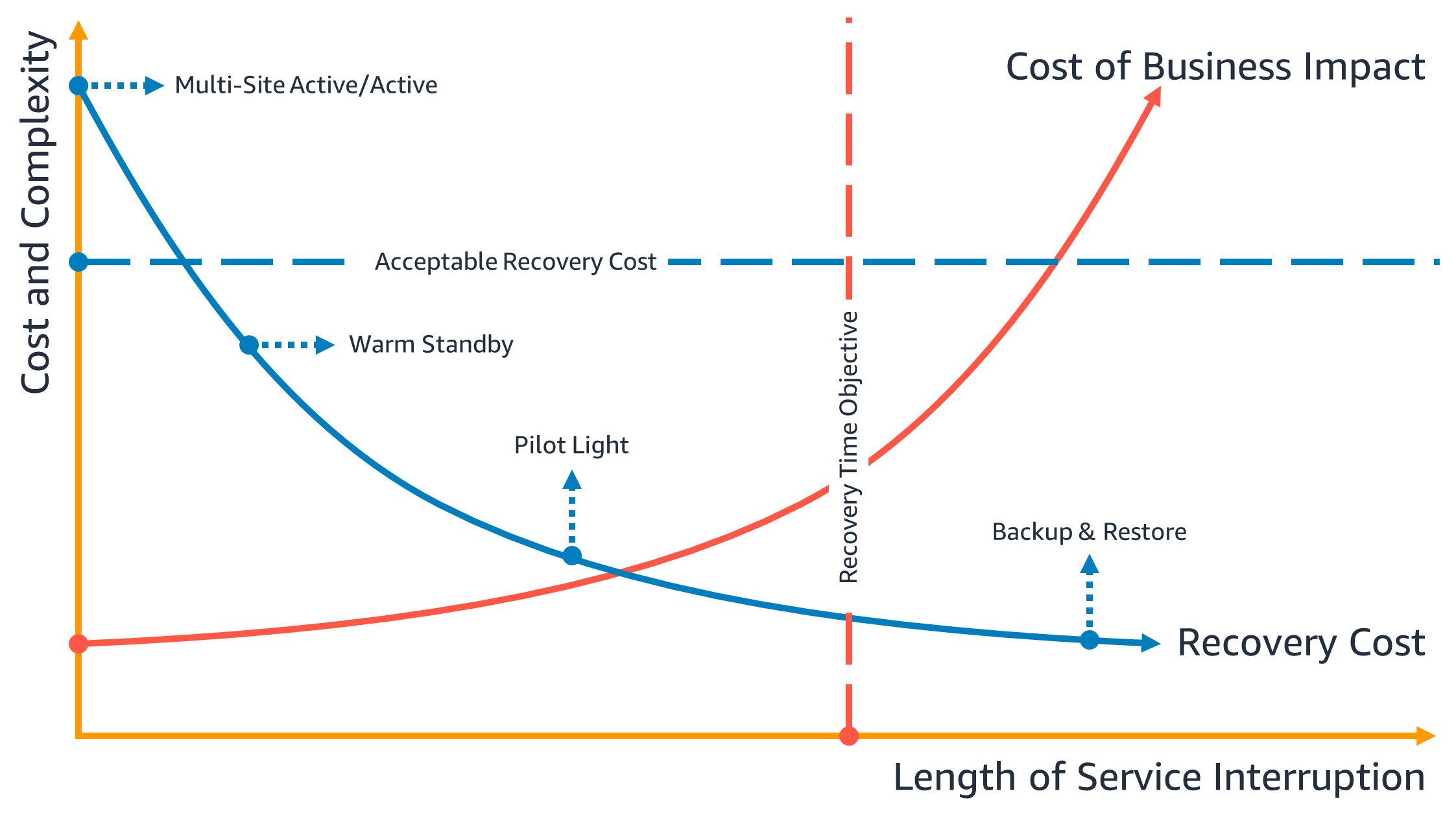
出典:ビジネス継続性計画 (BCP) - AWS でのワークロードの災害対策: クラウド内での復旧 図 4 - 目標復旧時間
~RPO(目標復旧時点)ベースで見る~
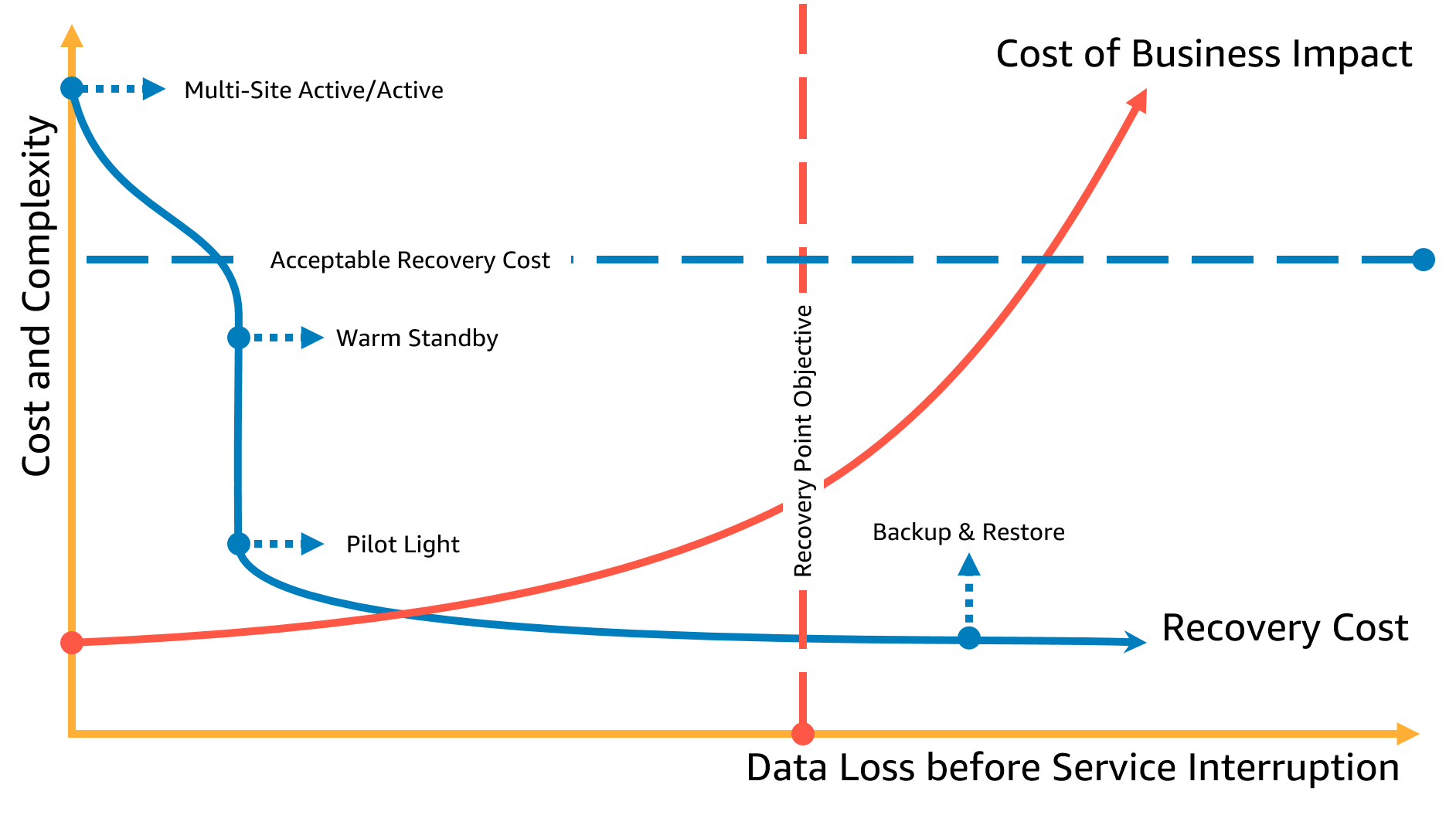
出典:ビジネス継続性計画 (BCP) - AWS でのワークロードの災害対策: クラウド内での復旧 図 5 - 目標復旧時点
それぞれのDR戦略について見ていきます。
最短の復旧時間(RTO)、最小のデータ損失(RPO) で障害から復旧するための DR 戦略です。
| 復旧時間 | 復旧時点 | 可用性 | コスト | 構成 | 適用範囲 |
|---|---|---|---|---|---|
| ⏱ | ⏱ | ⬆️⬆️⬆️⬆️ | 💸💸💸💸 | アクティブ/アクティブ | リージョンの災害 |

出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート IV: マルチサイトアクティブ/アクティブ - 図 1.DR戦略 | Amazon Web Services ブログ
構成としては以下のようなものを指す。

別々のリージョンに同じ構成のシステムを用意(アクティブ/アクティブな構成)し、どちらかのリージョンで障害が発生しても、片方のリージョンのみにリクエストが飛ぶようになるのでユーザーから見ると障害があったかどうかわからない状態になる。
この構成で重要なことは 障害が発生してから復旧までの時間はほぼなし で データの損失もない 状態で稼働できることである。
ただし別のリージョンに全く同じリソースを稼働し続けさせるため、コストは高く なる。
AWS の公式ブログにかかれている「マルチサイト」については こちら を参照
数分の復旧時間(RTO)、限りなく最小のデータの損失(RPO) で障害から復旧するための DR 戦略です。
| 復旧時間 | 復旧時点 | 可用性 | コスト | 構成 | 適用範囲 |
|---|---|---|---|---|---|
| ⏱⏱ | ⏱⏱ | ⬆️⬆️⬆️ | 💸💸💸 | アクティブ/パッシブ | リージョンの災害 |

出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ 図 1.DR戦略 | Amazon Web Services ブログ
構成としては以下のようなものを指す。

別のリージョンに本番相当よりかはサーバーのインスタンス数が少ないシステムを用意(アクティブ/パッシブな構成)しておき、障害が発生した時は本番環境から待機させておいたリージョンへリクエストが飛ぶようにします。
待機させておくシステムは本番レベルのトラフィックを処理できる程のものでなく、サーバーの台数は本番相当よりかは少ない状態で待機させておくことが多いです。
ちなみにこの時、待機させておくシステムが本番相当のものであった場合は ホットスタンバイ と呼ばれています。
この構成で重要なことは 障害が発生してから復旧までの時間は数分で済み、 データの損失も限りなくない状態 で稼働できることです。
本番相当のリソースを用意するわけではないので コストはマルチサイトに比べると安く なりますが 本番相当のリクエストを必ずしも処理できるものではない です。
AWS の公式ブログにかかれている「ウォームスタンバイ」については こちら を参照
数10分の復旧時間(RTO)、限りなく最小のデータの損失(RPO) で障害から復旧するための DR 戦略です。
| 復旧時間 | 復旧時点 | 可用性 | コスト | 構成 | 適用範囲 |
|---|---|---|---|---|---|
| ⏱⏱⏱ | ⏱⏱ | ⬆️⬆️ | 💸💸 | アクティブ/パッシブ | リージョンの災害 |
出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ 図 1.DR戦略 | Amazon Web Services ブログ
構成としては以下のようなものを指す。

出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ 図 2.パイロットライトDR戦略 | Amazon Web Services ブログ
~そもそもパイロットライトとは~
AWS の AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ のブログにこんな事が書かれています。
家庭用の炉のパイロットライトは、それ自体は家の中に熱を供給しません。パイロットライトは炉を素早く点火する手段を提供し、炉が熱を供給します。
つまりパイロットライトの戦略はシステムを素早く起動できる状態を保っておき、待機させておくことを指します。
~AWSにおけるパイロットライト戦略とは~
ウォームスタンバイと同じような形で別のリージョンにアクティブ/パッシブな構成を待機させておきます。
ただしこの時、ウォームスタンバイとの違いはサーバーのインスタンスを立ち上げておかず、障害が発生した時に待機させておいたリージョンでサーバーを起動させリクエストが飛ぶようにします。
ウォームスタンバイよりサーバーを起動させる工程が含まれるため、障害復旧に時間がかかります。
この構成で重要なことは 障害が発生してから復旧までの時間は数10分で済み、 データの損失も限りなくない状態 で稼働できることです。 ウォームスタンバイと違ってサーバーは用意しておかないので コストはウォームスタンバイに比べると安く なります。
AWS の公式ブログにかかれている「パイロットライト」については こちら を参照
1時間以上の復旧時間(RTO)、最大のデータ損失(RPO) で障害から復旧するための DR 戦略です。
| 復旧時間 | 復旧時点 | 可用性 | コスト | 構成 | 適用範囲 |
|---|---|---|---|---|---|
| ⏱⏱⏱⏱ | ⏱⏱⏱⏱ | ⬆️ | 💸 | アクティブ/パッシブ | 1つの物理センターの中断や喪失 |
出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速なリカバリによるバックアップと復元 図1. DR戦略 | Amazon Web Services ブログ
構成としては以下のようなものを指す。
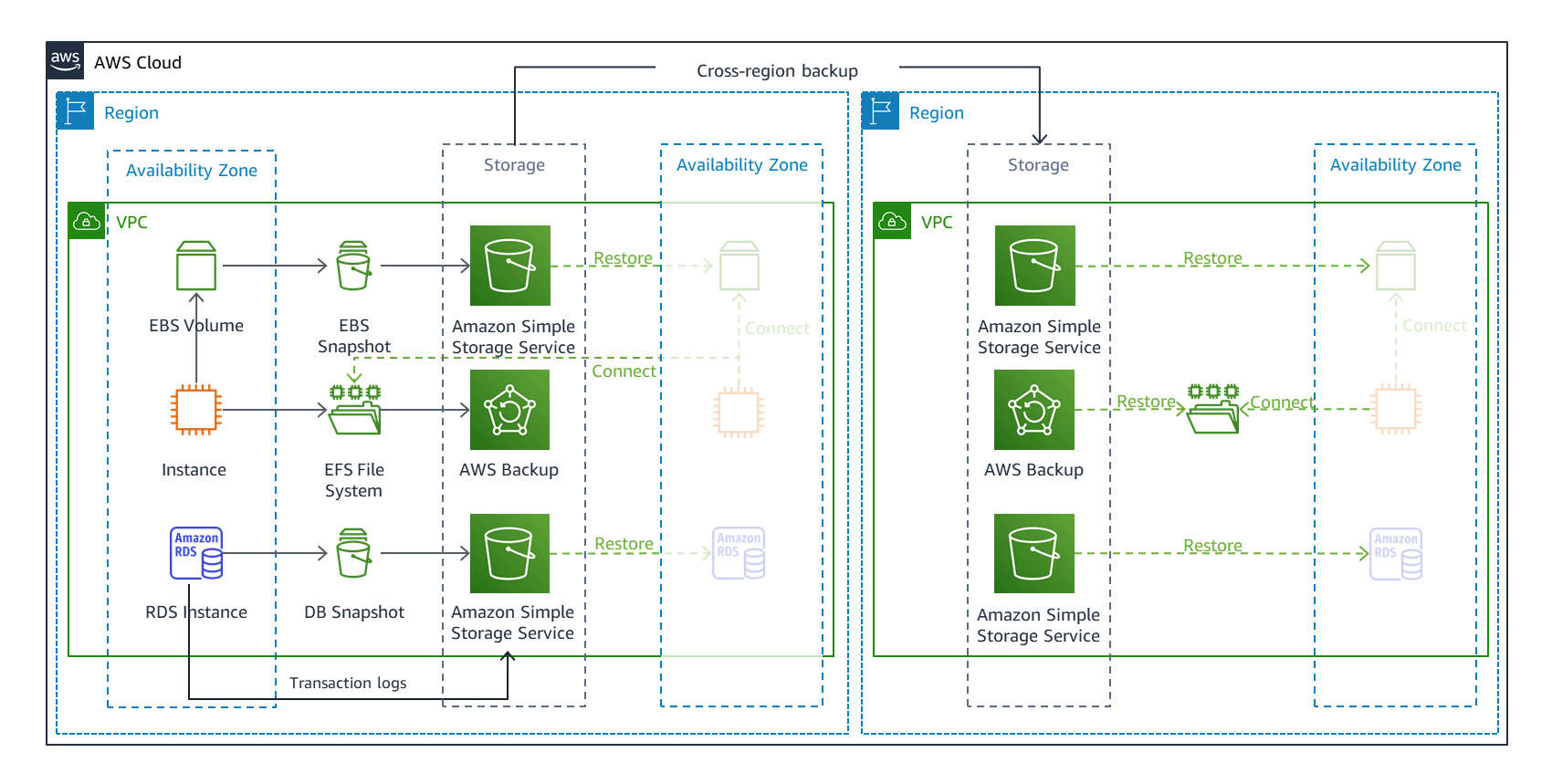
出典:AWS のディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速なリカバリによるバックアップと復元 図2. バックアップと復元のDR戦略 | Amazon Web Services ブログ
バックアップ用のファイルを保存しそれを別のリージョンにコピーしておきます。障害が発生した時は、コピーされたバックアップ用のファイルを使ってシステムを復元します。
システムの復元後は復元したシステムのあるリージョンにリクエストを向けることで復旧を行います。
この構成で重要なことは 障害が発生してから復旧までの時間は1時間以上かかり、データの損失もバックアップを取った時間に依存する ことです。
他の DR 戦略と違ってバックアップファイルのみを保存しておくだけなので コストがすごく安く なりますが反面、バックアップファイルからシステムを構築させるため、復旧までの時間がすごくかかります。
AWS の公式ブログにかかれている「バックアップと復元」については こちら を参照
DR 戦略の種類とどういったものかはわかったがそれぞれの DR 戦略を設計する際にどういうことをすればよいのかこちらにまとめます。
あくまでこれは設計例でシステム構成などによっても変わってくるのでなんとなくこんな事が必要ぐらいの感覚で書いておく。
マルチサイトで運用する場合はデータは複数のリージョンで同じものを使う必要があるため、グローバルなサービスを使用して設計することになります。
- Amazon Route53 で 位置情報ルーティングポリシー、レイテンシールーティングポリシー を設定する
- Amazon DynamoDB で DynamoDB グローバルテーブル を使用する
- Amazon Aurora で Aurora グローバルデータベース を使用する
- Amazon ElastiCache for Redis で Global Datastore を使用する
- AWS Global Accelerator を ルーティングとフェイルオーバー で使用する
待機させておくため、データに関してはクロスリージョンレプリケーションさせリージョン間で同じデータになるようにします。またインスタンス数やタスク数を増やすことも必要なのでインフラは IaC 化し簡単にスケールアップできるようにしておくことになります。
どのタイミングでスケールアップするか判断できるようにしないといけないため、災害イベントが検出できるようにしておくことになります。
- Amazon Aurora や Amazon DynamoDB テーブル などを クロスリージョンレプリケーション する
- Amazon CloudWatch Alarms と Amazon EventBridge を連携して 災害イベント を検出させる
- AWS Health と Amazon EventBridge を連携して 災害イベント を検出させる
- CloudFormation, AWS Cloud Development Kit(AWS CDK) を使用して Infrastructure as Code(IaC) を使用する
- AWS CLI や AWS SDK を使用 して Amazon EC2 のインスタンス数や Amazon ECS のタスク数をスケールアップする
- Amazon Route53 で ヘルスチェックの設定 をする
- AWS Global Accelerator を フェイルオーバー で使用する
基本的にはウォームスタンバイと同じになるので特に説明はないです。
- Amazon Aurora や Amazon DynamoDB テーブル などを クロスリージョンレプリケーション する
- Amazon CloudWatch Alarms と Amazon EventBridge を連携して 災害イベント を検出させる
- AWS Health と Amazon EventBridge を連携して 災害イベント を検出させる
- CloudFormation, AWS Cloud Development Kit(AWS CDK) を使用して Infrastructure as Code(IaC) を使用する
- AWS CLI や AWS SDK を使用 して Amazon EC2 のインスタンス数や Amazon ECS のタスク数をスケールアップする
- Amazon Route53 で ヘルスチェックの設定 をする
- AWS Global Accelerator を フェイルオーバー で使用する
データはポイントインタイムリカバリなどを使用して特定時点のバックアップファイルを保存しておき、それらのファイルを使ってシステムを作成することになります。
バックアップの手順を自動化させておけば RTO は短くなるため、バックアップを自動化しておくことは有用です。
システムが障害が起きたかどうかを判断するために通知の仕組みをしっかりと作りこむことになりそうです。
- Amazon DynamoDB で ポイントインタイムリカバリ を設定する
- Amazon RDS で 特定の時点への DB instance の復元 を使用する
- Amazon S3 で バケットのバージョニング を設定する
- AWS Backup を使用して別のリージョンに バックアップファイル(EBS ボリューム、RDS DBインスタンス、DynamoDB テーブルなど) をコピーする
- Amazon CloudWatch Alarms と Amazon EventBridge を連携して 災害イベント を検出させる
- AWS Health と Amazon EventBridge を連携して 災害イベント を検出させる
- CloudFormation, AWS Cloud Development Kit(AWS CDK) を使用して Infrastructure as Code(IaC) を使用する
- Amazon EC2 Image Builder を使用して ゴールデン AMI を作成し 別のリージョン にコピーする
- Amazon EventBridge を使用して AWS Lambda や AWS Step Functions を使用して自動化する
参考資料は災害復旧の 考え方の資料 と How の資料 があります。
まずは考え方の資料から見ることをおすすめします。