Any system that reproduces sound needs to do so with a certain quality. Such quality can be quantified through conducting experimental evaluations with human evaluations. These are often called "listening tests" or "subjective evaluations". The output of such an evaluation is often in the form of an Mean Opinion Score (MOS). For some applications standardized tests exists, such as MUSHRA for intermediate quality audio codecs. One can carry out such tests oneself using tools like webMUSHRA, or the tests can be performed as a service by professional laboratories such as FORCE Senselab. For an extensive treaty on the topic see the book Sensory Evaluation of Sound.
This repository is mostly a collection of notes on existing works. It was built up as part of research into prior art, for a project to build new audio quality estimation methods using Machine Learning. Some outcomes of this project can be found in:
- Efficient data collection pipeline for machine learning of audio quality. AES Show Spring 2021
- Predicting Audio Quality for different assessor types using machine learning. AES Show Spring 2021
It is also possible to estimate sound quality using computer programs, using algorithms that model the human perception. These can be used to compliment, or in some cases replace, subjective evaluations. Such methods are often referred to as "objective metrics". These have been developed since at least the early 1990, and have increased performance and complexity over time. Approaches range from simple calculations using well-known influential factors, to near black-box models learned using artificial neural networks.
This page gives an overview some of the metrics that are available.
A wide range of metrics exists.
The reference is the audio before being processed by the system under test. It may also be called "original", "unprocessed" or similar.
In some usecases or test setups the reference is easily available. For example when comparing audio codecs, the codec is usually ran on a set of reference material, and this reference can be used during evaluation. Metrics making use of the reference is normally called "full reference". When a reference is used, it is possible for to directly model the changes that the system makes to the audio.
In others cases the reference is not available, like online estimation of telephone speech quality. In that case the metric of use must be "reference-free" or "no reference" type. It is sometimes also called a "non-intrusive" or "single-ended" method. The changes the system makes is not directly observable.
Some metrics may target specific application areas, and others be of more general nature
- Speech transmission. Telephony, Voice over IP (VoIP), Tele-conferencing
- Wireless sound transmission. Bluetooth devices etc.
- Sound reproduction. Speakers and headphones, concert halls
- Hearing aids, assistive technology.
- Audio Codec development
- Speech Enchancement and Speech Denoising
- Audio Source Separation algorithms
- Speech and Music Synthesis
Some categories of outputs are in common usage
- Speech Intelligibility. How well and how easily can speech be understood
- Speech Quality. How good does the speech sound
- Audio Quality. How good does the audio sound. Implies wider range of audio than just speech, typically music
The output can designed to an estimate of Mean Opinion Score (MOS) or other quality scale. Or it can be a dimensionless distance metric whos relationship to subjective ratings must be determined separately.
Most metrics are monoaural, estimating the quality of a single channel of audio. A few metrics are specialized to cover binaural and spatial audio.
With deep-learning methods, the objective to optimize for is specified using a loss function. When building neural networks that should produce perceptually good audio, the ideal is to incorporate into the loss function. This normally requires the function to be differentiable.
| Method | Purpose | Open Implementations | Definition |
|---|---|---|---|
| PSQM | Speech Quality | ITU-T P.861 | |
| SI-SDR | Audio Quality | torchaudio | [Paper]((https://ieeexplore.ieee.org/document/8683855) |
| STOI | Speech Intelligibility | pystoi,torchaudio | Paper |
| PESQ | Speech Quality | torchaudio | ITU-T P.862 |
| PEAQ | Audio Quality | GstPEAQ | ITU-R BS.1387-1 |
| POLQA | Speech Quality | ITU-T P.863 | |
| VISQOL | Audio/Speech Quality | visqol | Paper |
| Frechet Audio Distance | Audio Quality | frechet_audio_distance | Paper |
| DNSMOS | Speech Quality | DNSMOS | Paper |
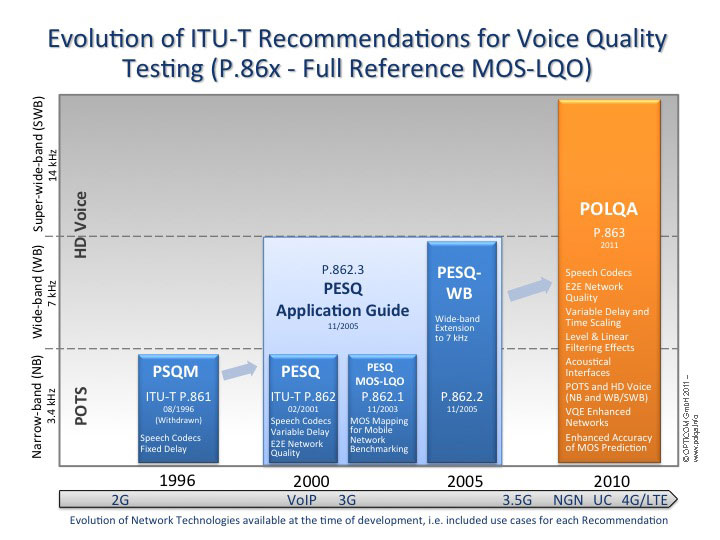
Perceptual Speech Quality Measure. wikipedia
Voice quality of voice-band (300 – 3400 Hz) speech codecs.
ITU-T Recommendation P.861 in 1996. Withdraw. Superseeded by PESQ in 2001.
Cannot account for packet loss, delay variance (jitter) or non-sequential packets.
Perceptual Evaluation of Speech Quality. wikipedia
ITU-T standardized in 2001. https://www.itu.int/rec/T-REC-P.862

Superseeded by POLQA in 2011.
Implemented in pytorch-audio / TorchAudio. Can be used as a loss function
Standard provides a reference implementation in C. Only to be used for evaluations, probhibits commercial usage.
https://github.com/ludlows/python-pesq Python module. Copied original reference C code.
https://github.com/vBaiCai/python-pesq another Python package. Marked as Work In Progress
PESQ was not intended to compare speech before and after noise reduction. Its stated aims were to quantify degradation due to codecs and transmission channel errors. It was originally tested on speech with environmental noise (i.e., clean original vs. noisy signal) and was found to correlate well in that case. However, PESQ was found not to correlate with subjective MOS on a number of other tasks (see the standard), and thus should not be blindly used unless tested first. Yaakov J Stein @ research.net
The POLQA perceptual measurement algorithm is a joint development of OPTICOM, SwissQual and TNO, protected by copyrights and patents and available under license from OPTICOM as software for various platforms.
Latest version is POLQA v3 (2018)

Available as PolqaOem64 by the standards group. Requires a license.
Used by WebRTC https://github.com/webrtc-uwp/webrtc/tree/master/modules/audio_processing/test/py_quality_assessment
Virtual Speech Quality Objective Listener
Originally designed for Speech, but extended to Audio later (VISQOLAudio). Latest version, VISQOLv3 combines the two variations into one method with a mode switch.
VISQOLv3 website. Paper: ViSQOL v3: An Open Source Production Ready Objective Speech and Audio Metric.
google/visqol. Official open-source implementation VISQOLv3. Commandline tool written in C++. Cross-platform. Provides a command-line tool, and also a C++ API, and Python bindings.
An earlier MATLAB implementation of ViSQOLAudio available is at. http://www.mee.tcd.ie/~sigmedia/Resources/ViSQOLAudio https://sites.google.com/a/tcd.ie/sigmedia/visqolaudio
Note: Password protected, must be requested via email.

Based on similarity of spectrograms Designed to be particularly sensitive to VoIP degradation
Using a distance metric called the Neurogram Similarity Index Measure or NSIM Inspired by Structural Similarity Index (SSIM) In this work, spectrograms are treated as images to compare similarity.
Paper compares quality predictions with PESQ and POLQA for common problems in VoIP: clock drift, associated time warping, and playout delays. The results indicate that ViSQOL and POLQA significantly outperform PESQ, with ViSQOL competing well with POLQA.
(On speech enhancement algorithms) However, these metrics have difficulty with modern communications networks. Modern codecs can produce high-quality speech without preserving the input waveform. Quality measures based on waveform similarity do not work for these codecs. Comparing signals in the spectral domain avoids this problem and can produce results that agree with human judgement
ViSQOLAudio: An objective audio quality metric for low bitrate codecs https://research.google/pubs/pub43991/
Moidification of ViSQOL, with Voice Activity Detection removed and wider range of frequency bands. Bark scale.
- AAC-HE and AAC-LC codecs at four bit rates and examples of MP3 and OPUS codecs
- PEAQ, POLQA, and VISQOLAudio
- compared against the subjective listener test results carried out with headphones to evaluate their suitability for measuring audio quality for low bit rate codecs
A key component is Neurogram Similarity Index Measure (NSIM), originally proposed in Speech intelligibility prediction using a Neurogram Similarity Index Measure (Hines, 2012).
Signal to Distortion Ratio (SDR). From the MATLAB toolbox BSS_eval Designed to evaluate (blind) source separation algorithms. Authors now suggest to use PEASS instead. Only of historical interest. Should at the very least use SI-SDR.
Scale-Invariant Signal-to-Distortion Ratio (SI-SDR). Slightly modified definition of SDR, proposed in SDR – Half-baked or Well Done?.
Corrected version of 'SDR' method from BSS_eval.
Speech Intelligibility Index
Only reliable for "simple degradations" (additive noise)
ANIQUE+: A new American national standard for non-intrusive estimation of narrowband speech quality
Claims to be significantly better than ITU-T P.563
Abbreviated FAD
Paper: Fréchet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms. Published in December, 2018
Official implementation Blogpost announcement
Proposed a learned metric for measuring the quality of audio generated by neural networks. Especially for music enhancement and music generation.
Proposes to use a "standard" training set of studio-grade music recordings. Can in that way be used reference-free to evaluate new material. Designed for system evaluation: operates over whole evaluation set of recordings, not per recording.
- Audio converted to log- Mel spectrograms
- Using 1 second windows with 0.5 second overlap
- Calculates audio embeddings using a pretrained neural network (VGGish)
- Estimates multivariate Gaussians on embeddings on entire evaluation and reference datasets
- Computes the Fréchet distance between the Gaussians
Metric eveloped by introducing a wide variety of artificial distortions onto a large dataset of music. Magnatagatune dataset. 600 hours of music samples at 16 kHz.
Included distortions: Low pass, High pass, Reverberation, Pops, Gaussian Noise, Quantization, Speed up/slow down, Pitch down, Griffin-Lim (phase) distortions, Mel encoding
Humans rated 69,000 5-second audio clips, 95 hours total. For fitting model.
Evaluations was done on a 25 minute subset. 300 samples a 5 seconds FAD correlates more closely with human perception than SDR, cosine distance, or magnitude L2 distance. FAD had a correlation coefficient of 0.52, and others 0.39, -0.15 and -0.01 respectively.
NOTE: weak baselines metrics used in comparison. Many audio quality metrics that are expected to do better than SDR.
Based on magnitude mel-filtered spectrograms. Ignores phase
Short-time Objective Intelligibility measure.
Proposed in A short-time objective intelligibility measure for time-frequency weighted noisy speech
Intelligibility measure which is highly correlated with the intelligibility of degraded speech signals, e.g., due to additive noise, single/multi-channel noise reduction, binary masking and vocoded speech as in CI simulations. The STOI-measure is intrusive, i.e., a function of the clean and degraded speech signals.
STOI may be a good alternative to the speech intelligibility index (SII) or the speech transmission index (STI), when you are interested in the effect of nonlinear processing to noisy speech, e.g., noise reduction, binary masking algorithms, on speech intelligibility.
- Method is based on spectrograms.
- 15, 1/3 octave bands. Covering from 150-4500 Hz.
- 25 ms frames.
- 400 ms windows.
- Compares two spectrograms, using correlation cofficient. ? more details
- Outputs a time-frequency score.
- Overall score is then the average of these.
Paper authors provide a MATLAB reference implementation http://www.ceestaal.nl/code/
https://github.com/mpariente/pystoi Pure Python implementation. Python 3 compatible. Available on PIP. Has tests against the MATLAB reference.
Single-ended method for objective speech quality assessment in narrow-band telephony applications https://www.itu.int/rec/T-REC-P.563/en
Perceptual Evaluation methods for Audio Source Separation Website
Provides both perceptually motivated objective measures, as well as some tools for subjective evalutions (MUSHRA).
Paper: Subjective and objective quality assessment of audio source separation
Implementation in MATLAB. http://bass-db.gforge.inria.fr/peass/PEASS-Software.html Licensed as GNU GPLv3
Frequency-weighted segmental SNR
Has been used for binaural speech intelligibility in Estimation of binaural intelligibility using the frequency-weighted segmental SNR of stereo channel signals.
pysepm Python package. Implements many Speech Quality and Speech Intelligibilty metrics. Including Log-likelihood Ratio. STOI and PESQ metrics by wrapping pystoi and pypesq
DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality metric to evaluate Noise Suppressors DNSMOS P.835: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors
DPAM = Deep Perceptual Audio Metric.
Paper: A Differentiable Perceptual Audio Metric Learned from Just Noticeable Differences. 2020
- Uses deep neural network that operates on raw audio waveform
- Trained on algorithmically generated degradations. Using perturbations such as noise, reverb, and compression artifacts
- Uses active learning process with human evaluators designed to identify just-noticeable difference (JND) level
- Human evaluators have to answer "are these two clips identical?"
- In Python. Based on PyTorch
- Pre-trained neural network.
- Can output a vector representation of audio. Enables fine-tuning custom metrics
- Differentiable. Can be used as a loss in neural network
- MIT licensed
Improvement upon DPAM, by the same authors. Inherits most properties of DPAM.
Paper. CDPAM: Contrastive learning for perceptual audio similarity The primary improvement (over DPAM) is to combine contrastive learning and multi-dimensional representations to build robust models from limited data.
PErception MOdel-based Quality estimation
PEMO-Q - A New Method for Objective Audio Quality Assessment Using a Model of Auditory Perception claims to be better than PEAQ.
Expansion of the speech quality measure qC.
Evaluation Of Audio Quality
Based on ITU-R recommendation BS.1387 (PEAQ), and very similar to it.
https://github.com/godock/eaqual
AMBIQUAL - a full reference objective quality metric for ambisonic spatial audio https://ieeexplore.ieee.org/document/8463408