目标检测任务是指给定一张图片,网络预测出图片中所包括的所有物体类别和对应的边界框

以我们提供的猫 cat 小数据集为例,带大家 15 分钟轻松上手 MMYOLO 目标检测。整个流程包含如下步骤:
本文以 YOLOv5-s 为例,其余 YOLO 系列算法的猫 cat 小数据集 demo 配置请查看对应的算法配置文件夹下。
假设你已经提前安装好了 Conda,接下来安装 PyTorch
conda create -n mmyolo python=3.8 -y
conda activate mmyolo
# 如果你有 GPU
conda install pytorch torchvision -c pytorch
# 如果你是 CPU
# conda install pytorch torchvision cpuonly -c pytorch安装 MMYOLO 和依赖库
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
pip install -U openmim
mim install -r requirements/mminstall.txt
# Install albumentations
mim install -r requirements/albu.txt
# Install MMYOLO
mim install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。温馨提醒:由于本仓库采用的是 OpenMMLab 2.0,请最好新建一个 conda 虚拟环境,防止和 OpenMMLab 1.0 已经安装的仓库冲突。
详细环境配置操作请查看 安装和验证
Cat 数据集是一个包括 144 张图片的单类别数据集(本 cat 数据集由 @RangeKing 提供原始图片,由 @PeterH0323 进行数据清洗), 包括了训练所需的标注信息。 样例图片如下所示:

你只需执行如下命令即可下载并且直接用起来
python tools/misc/download_dataset.py --dataset-name cat --save-dir ./data/cat --unzip --delete数据集组织格式如下所示:

data 位于 mmyolo 工程目录下, data/cat/annotations 中存放的是 COCO 格式的标注,data/cat/images 中存放的是所有图片
以 YOLOv5 算法为例,考虑到用户显存和内存有限,我们需要修改一些默认训练参数来让大家愉快的跑起来,核心需要修改的参数如下
- YOLOv5 是 Anchor-Based 类算法,不同的数据集需要自适应计算合适的 Anchor
- 默认配置是 8 卡,每张卡 batch size 为 16,现将其改成单卡,每张卡 batch size 为 12
- 默认训练 epoch 是 300,将其改成 40 epoch
- 由于数据集太小,我们选择固定 backbone 网络权重
- 原则上 batch size 改变后,学习率也需要进行线性缩放,但是实测发现不需要
具体操作为在 configs/yolov5 文件夹下新建 yolov5_s-v61_fast_1xb12-40e_cat.py 配置文件(为了方便大家直接使用,我们已经提供了该配置),并把以下内容复制配置文件中。
# 基于该配置进行继承并重写部分配置
_base_ = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
data_root = './data/cat/' # 数据集根路径
class_name = ('cat', ) # 数据集类别名称
num_classes = len(class_name) # 数据集类别数
# metainfo 必须要传给后面的 dataloader 配置,否则无效
# palette 是可视化时候对应类别的显示颜色
# palette 长度必须大于或等于 classes 长度
metainfo = dict(classes=class_name, palette=[(20, 220, 60)])
# 基于 tools/analysis_tools/optimize_anchors.py 自适应计算的 anchor
anchors = [
[(68, 69), (154, 91), (143, 162)], # P3/8
[(242, 160), (189, 287), (391, 207)], # P4/16
[(353, 337), (539, 341), (443, 432)] # P5/32
]
# 最大训练 40 epoch
max_epochs = 40
# bs 为 12
train_batch_size_per_gpu = 12
# dataloader 加载进程数
train_num_workers = 4
# 加载 COCO 预训练权重
load_from = 'https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth' # noqa
model = dict(
# 固定整个 backbone 权重,不进行训练
backbone=dict(frozen_stages=4),
bbox_head=dict(
head_module=dict(num_classes=num_classes),
prior_generator=dict(base_sizes=anchors)
))
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
# 数据集标注文件 json 路径
ann_file='annotations/trainval.json',
# 数据集前缀
data_prefix=dict(img='images/')))
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
_base_.optim_wrapper.optimizer.batch_size_per_gpu = train_batch_size_per_gpu
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
default_hooks = dict(
# 每隔 10 个 epoch 保存一次权重,并且最多保存 2 个权重
# 模型评估时候自动保存最佳模型
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'),
# warmup_mim_iter 参数非常关键,因为 cat 数据集非常小,默认的最小 warmup_mim_iter 是 1000,导致训练过程学习率偏小
param_scheduler=dict(max_epochs=max_epochs, warmup_mim_iter=10),
# 日志打印间隔为 5
logger=dict(type='LoggerHook', interval=5))
# 评估间隔为 10
train_cfg = dict(max_epochs=max_epochs, val_interval=10)以上配置从 yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py 中继承,并根据 cat 数据的特点更新了 data_root、metainfo、train_dataloader、val_dataloader、num_classes 等配置。
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py运行以上训练命令 work_dirs/yolov5_s-v61_fast_1xb12-40e_cat 文件夹会被自动生成,权重文件以及此次的训练配置文件将会保存在此文件夹中。 在 1660 低端显卡上,整个训练过程大概需要 8 分钟。

在 test.json 上性能如下所示:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.631
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.909
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.747
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.631
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.627
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.703
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.703
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.703
上述性能是通过 COCO API 打印,其中 -1 表示不存在对于尺度的物体。根据 COCO 定义的规则,Cat 数据集里面全部是大物体,不存在小和中等规模物体。
在训练过程中会打印如下两个关键警告:
- You are using
YOLOv5Headwith num_classes == 1. The loss_cls will be 0. This is a normal phenomenon. - The model and loaded state dict do not match exactly
这两个警告都不会对性能有任何影响。第一个警告是说明由于当前训练的类别数是 1,根据 YOLOv5 算法的社区, 分类分支的 loss 始终是 0,这是正常现象。第二个警告是因为目前是采用微调模式进行训练,我们加载了 COCO 80 个类的预训练权重, 这会导致最后的 Head 模块卷积通道数不对应,从而导致这部分权重无法加载,这也是正常现象。
如果训练中途停止,可以在训练命令最后加上 --resume ,程序会自动从 work_dirs 中加载最新的权重文件恢复训练。
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py --resume上述配置大概需要 3.0G 显存,如果你的显存不够,可以考虑开启混合精度训练
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py --ampMMYOLO 目前支持本地、TensorBoard 以及 WandB 等多种后端可视化,默认是采用本地可视化方式,你可以切换为 WandB 等实时可视化训练过程中各类指标。
WandB 官网注册并在 https://wandb.ai/settings 获取到 WandB 的 API Keys。
pip install wandb
# 运行了 wandb login 后输入上文中获取到的 API Keys ,便登录成功。
wandb login在 configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py 配置文件最后添加 WandB 配置
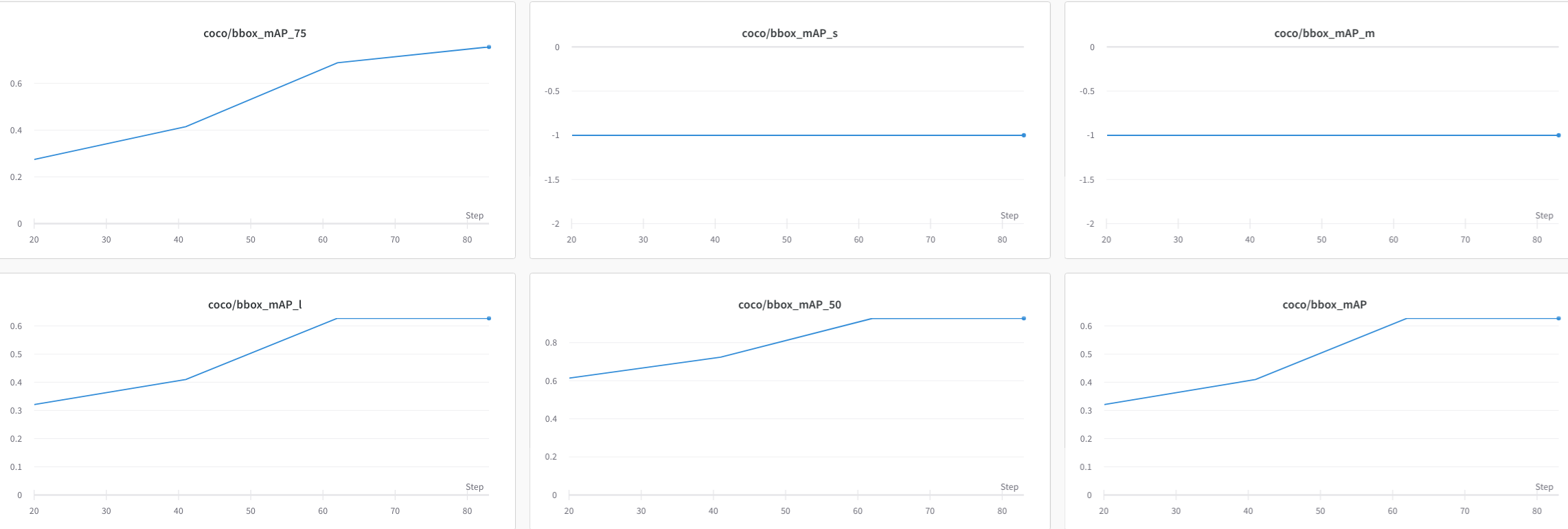
visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])重新运行训练命令便可以在命令行中提示的网页链接中看到 loss、学习率和 coco/bbox_mAP 等数据可视化了。
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py
安装 Tensorboard 依赖
pip install tensorboard同上述在配置文件 configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py配置的最后添加 tensorboard 配置
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='TensorboardVisBackend')])重新运行训练命令后,Tensorboard 文件会生成在可视化文件夹 work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/{timestamp}/vis_data 下,
运行下面的命令便可以在网页链接使用 Tensorboard 查看 loss、学习率和 coco/bbox_mAP 等可视化数据了:
tensorboard --logdir=work_dirs/yolov5_s-v61_fast_1xb12-40e_catpython tools/test.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--show-dir show_results运行以上测试命令, 你不仅可以得到模型训练部分所打印的 AP 性能,还可以将推理结果图片自动保存至 work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/{timestamp}/show_results 文件夹中。下面为其中一张结果图片,左图为实际标注,右图为模型推理结果。

如果你使用了 WandbVisBackend 或者 TensorboardVisBackend,则还可以在浏览器窗口可视化模型推理结果。
MMYOLO 中提供了特征图相关可视化脚本,用于分析当前模型训练效果。 详细使用流程请参考 特征图可视化
由于 test_pipeline 直接可视化会存在偏差,故将需要 configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py 中 test_pipeline
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]修改为如下配置:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 删除 YOLOv5KeepRatioResize, 将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor')) # 删除 pad_param
]我们选择 data/cat/images/IMG_20221020_112705.jpg 图片作为例子,可视化 YOLOv5 backbone 和 neck 层的输出特征图。
1. 可视化 YOLOv5 backbone 输出的 3 个通道
python demo/featmap_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layers backbone \
--channel-reduction squeeze_mean
结果会保存到当前路径的 output 文件夹下。上图中绘制的 3 个输出特征图对应大中小输出特征图。由于本次训练的 backbone 实际上没有参与训练,从上图可以看到,大物体 cat 是在小特征图进行预测,这符合目标检测分层检测思想。
2. 可视化 YOLOv5 neck 输出的 3 个通道
python demo/featmap_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layers neck \
--channel-reduction squeeze_mean
从上图可以看出,由于 neck 是参与训练的,并且由于我们重新设置了 anchor, 强行让 3 个输出特征图都拟合同一个尺度的物体,导致 neck 输出的 3 个图类似,破坏了 backbone 原先的预训练分布。同时也可以看出 40 epoch 训练上述数据集是不够的,特征图效果不佳。
3. Grad-Based CAM 可视化
基于上述特征图可视化效果,我们可以分析特征层 bbox 级别的 Grad CAM。
安装 grad-cam 依赖:
pip install "grad-cam"(a) 查看 neck 输出的最小输出特征图的 Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[2]
(b) 查看 neck 输出的中等输出特征图的 Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[1]
(c) 查看 neck 输出的最大输出特征图的 Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[0]
此处我们将通过 MMYOLO 的 EasyDeploy 来演示模型的转换部署和基本推理。
首先需要在当前 MMYOLO 的虚拟环境中按照 EasyDeploy 的 基本文档 对照自己的设备安装好所需的各个库。
pip install onnx onnxruntime
pip install onnx-simplifier # 如果需要使用 simplify 功能需要安装
pip install tensorrt # 如果有 GPU 环境并且需要输出 TensorRT 模型需要继续执行完成安装后就可以用以下命令对已经训练好的针对 cat 数据集的模型一键转换部署,当前设备的 ONNX 版本为 1.13.0,TensorRT 版本为 8.5.3.1,故可保持 --opset 为 11,其余各项参数的具体含义和参数值需要对照使用的 config 文件进行调整。此处我们先导出 CPU 版本的 ONNX 模型,--backend 为 ONNXRUNTIME。
python projects/easydeploy/tools/export_onnx.py \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
--img-size 640 640 \
--batch 1 \
--device cpu \
--simplify \
--opset 11 \
--backend ONNXRUNTIME \
--pre-topk 1000 \
--keep-topk 100 \
--iou-threshold 0.65 \
--score-threshold 0.25成功运行后就可以在 work-dir 下得到转换后的 ONNX 模型,默认使用 end2end.onnx 命名。
接下来我们使用此 end2end.onnx 模型来进行一个基本的图片推理:
python projects/easydeploy/tools/image-demo.py \
data/cat/images/IMG_20210728_205117.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.onnx \
--device cpu成功完成推理后会在默认的 MMYOLO 根目录下的 output 文件夹生成推理结果图,如果想直观看到结果而不需要保存,可以在上述命令结尾加上 --show ,为了方便展示,下图是生成结果的截取部分。

我们继续转换对应 TensorRT 的 engine 文件,因为 TensorRT 需要对应当前环境以及部署使用的版本进行,所以一定要确认导出参数,这里我们导出对应 TensorRT8 版本的文件,--backend 为 2。
python projects/easydeploy/tools/export.py \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
--img-size 640 640 \
--batch 1 \
--device cuda:0 \
--simplify \
--opset 11 \
--backend 2 \
--pre-topk 1000 \
--keep-topk 100 \
--iou-threshold 0.65 \
--score-threshold 0.25成功执行后得到的 end2end.onnx 就是对应 TensorRT8 部署需要的 ONNX 文件,我们使用这个文件完成 TensorRT engine 的转换。
python projects/easydeploy/tools/build_engine.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.onnx \
--img-size 640 640 \
--device cuda:0成功执行后会在 work-dir 下生成 end2end.engine 文件:
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat
├── 202302XX_XXXXXX
│ ├── 202302XX_XXXXXX.log
│ └── vis_data
│ ├── 202302XX_XXXXXX.json
│ ├── config.py
│ └── scalars.json
├── best_coco
│ └── bbox_mAP_epoch_40.pth
├── end2end.engine
├── end2end.onnx
├── epoch_30.pth
├── epoch_40.pth
├── last_checkpoint
└── yolov5_s-v61_fast_1xb12-40e_cat.py
我们继续使用 image-demo.py 进行图片推理:
python projects/easydeploy/tools/image-demo.py \
data/cat/images/IMG_20210728_205312.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.engine \
--device cuda:0此处依旧选择在 output 下保存推理结果而非直接显示结果,同样为了方便展示,下图是生成结果的截取部分。

这样我们就完成了将训练完成的模型进行转换部署并且检查推理结果的工作。至此本教程结束。
以上完整内容可以查看 15_minutes_object_detection.ipynb。 如果你在训练或者测试过程中碰到问题,请先查看 常见错误排除步骤,如果依然无法解决欢迎提 issue。