`.
+
+Running the following uploads the model that is saved in `preset_dir` to Hugging Face:
+
+
+```python
+hf_username = huggingface_hub.whoami()["name"]
+hf_uri = f"hf://{hf_username}/gpt2_imdb"
+keras_hub.upload_preset(hf_uri, preset_dir)
+
+```
+
+---
+## Load a User Uploaded Model
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset(
+ f"kaggle://{kaggle_username}/gpt2/keras/gpt2_imdb"
+)
+```
+
+We can also load the model uploaded to Hugging Face by calling `from_preset`.
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset(f"hf://{hf_username}/gpt2_imdb")
+```
+
+# Classifier Upload
+
+Uploading a classifier model is similar to Causal LM upload.
+To upload the fine-tuned model, first, the model should be saved to a local directory using `save_to_preset`
+API and then it can be uploaded via `keras_hub.upload_preset`.
+
+
+```python
+# Load the base model.
+classifier = keras_hub.models.Classifier.from_preset(
+ "bert_tiny_en_uncased", num_classes=2
+)
+
+# Fine-tune the classifier.
+classifier.fit(imdb_train)
+
+# Save the model to a local preset directory.
+preset_dir = "./bert_tiny_imdb"
+classifier.save_to_preset(preset_dir)
+
+# Upload to Kaggle.
+keras_hub.upload_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb", preset_dir
+)
+```
+ 100/100 ━━━━━━━━━━━━━━━━━━━━ 7s 31ms/step - loss: 0.6975 - sparse_categorical_accuracy: 0.5164
+
+
+
+```
+Upload successful: preprocessor.json (947B)
+Upload successful: tokenizer.json (461B)
+Upload successful: task.json (2KB)
+Upload successful: task.weights.h5 (50MB)
+Upload successful: model.weights.h5 (17MB)
+Upload successful: config.json (454B)
+Upload successful: metadata.json (140B)
+Upload successful: vocabulary.txt (226KB)
+
+Your model instance version has been created.
+```
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+classifier = keras_hub.models.Classifier.from_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb"
+)
+```
\ No newline at end of file
diff --git a/redirects/api/keras_nlp/layers/fnet_encoder/index.html b/redirects/api/keras_nlp/layers/fnet_encoder/index.html
index cf952224ad..3a5100b022 100644
--- a/redirects/api/keras_nlp/layers/fnet_encoder/index.html
+++ b/redirects/api/keras_nlp/layers/fnet_encoder/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/index.html b/redirects/api/keras_nlp/layers/index.html
index 939076da8d..6a18f1255f 100644
--- a/redirects/api/keras_nlp/layers/index.html
+++ b/redirects/api/keras_nlp/layers/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/mlm_head/index.html b/redirects/api/keras_nlp/layers/mlm_head/index.html
index e7b3d201be..62d08476e8 100644
--- a/redirects/api/keras_nlp/layers/mlm_head/index.html
+++ b/redirects/api/keras_nlp/layers/mlm_head/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/mlm_mask_generator/index.html b/redirects/api/keras_nlp/layers/mlm_mask_generator/index.html
index 15cbbf4724..e2d69ca00c 100644
--- a/redirects/api/keras_nlp/layers/mlm_mask_generator/index.html
+++ b/redirects/api/keras_nlp/layers/mlm_mask_generator/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/multi_segment_packer/index.html b/redirects/api/keras_nlp/layers/multi_segment_packer/index.html
index 46476327cb..e4f1342f53 100644
--- a/redirects/api/keras_nlp/layers/multi_segment_packer/index.html
+++ b/redirects/api/keras_nlp/layers/multi_segment_packer/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/position_embedding/index.html b/redirects/api/keras_nlp/layers/position_embedding/index.html
index facafa7c4b..b1289a7284 100644
--- a/redirects/api/keras_nlp/layers/position_embedding/index.html
+++ b/redirects/api/keras_nlp/layers/position_embedding/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/sine_position_encoding/index.html b/redirects/api/keras_nlp/layers/sine_position_encoding/index.html
index f741133224..f4ba245015 100644
--- a/redirects/api/keras_nlp/layers/sine_position_encoding/index.html
+++ b/redirects/api/keras_nlp/layers/sine_position_encoding/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/start_end_packer/index.html b/redirects/api/keras_nlp/layers/start_end_packer/index.html
index 310b463196..b061c27a8c 100644
--- a/redirects/api/keras_nlp/layers/start_end_packer/index.html
+++ b/redirects/api/keras_nlp/layers/start_end_packer/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/token_and_position_embedding/index.html b/redirects/api/keras_nlp/layers/token_and_position_embedding/index.html
index 6d3b71e9a4..e7ea6564eb 100644
--- a/redirects/api/keras_nlp/layers/token_and_position_embedding/index.html
+++ b/redirects/api/keras_nlp/layers/token_and_position_embedding/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/transformer_decoder/index.html b/redirects/api/keras_nlp/layers/transformer_decoder/index.html
index 463349ec84..c97613b370 100644
--- a/redirects/api/keras_nlp/layers/transformer_decoder/index.html
+++ b/redirects/api/keras_nlp/layers/transformer_decoder/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/api/keras_nlp/layers/transformer_encoder/index.html b/redirects/api/keras_nlp/layers/transformer_encoder/index.html
index 50ff134876..adc2424450 100644
--- a/redirects/api/keras_nlp/layers/transformer_encoder/index.html
+++ b/redirects/api/keras_nlp/layers/transformer_encoder/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/redirects/examples/nlp/gpt2_text_generation_with_kerasnlp/index.html b/redirects/examples/nlp/gpt2_text_generation_with_kerasnlp/index.html
index c057bb3ab4..17cdb19bdc 100644
--- a/redirects/examples/nlp/gpt2_text_generation_with_kerasnlp/index.html
+++ b/redirects/examples/nlp/gpt2_text_generation_with_kerasnlp/index.html
@@ -1,2 +1,2 @@
-
+
diff --git a/requirements.txt b/requirements.txt
index 4b40a0e06f..106f41e643 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -11,7 +11,8 @@ jupyter
pydot
boto3
tensorflow
-keras-tuner
keras-cv
-tf_keras
keras-nlp
+keras-tuner
+tf_keras
+keras-hub-nightly # TODO: update to keras-hub.
diff --git a/scripts/api_master.py b/scripts/api_master.py
index 49d2b32538..045013a5c6 100644
--- a/scripts/api_master.py
+++ b/scripts/api_master.py
@@ -1,5 +1,6 @@
from kt_api_master import KT_API_MASTER
from cv_api_master import CV_API_MASTER
+from hub_api_master import HUB_API_MASTER
from nlp_api_master import NLP_API_MASTER
API_MASTER = {
@@ -1824,5 +1825,6 @@
KT_API_MASTER,
CV_API_MASTER,
NLP_API_MASTER,
+ HUB_API_MASTER,
],
}
diff --git a/scripts/autogen.py b/scripts/autogen.py
index 50517df940..3c190d49aa 100644
--- a/scripts/autogen.py
+++ b/scripts/autogen.py
@@ -28,10 +28,10 @@
import render_tags
try:
- import keras_nlp
+ import keras_hub
except Exception as e:
- print(f"Could not import Keras NLP. Exception: {e}")
- keras_nlp = None
+ print(f"Could not import KerasHub. Exception: {e}")
+ keras_hub = None
try:
import keras_cv
@@ -39,6 +39,11 @@
print(f"Could not import Keras CV. Exception: {e}")
keras_cv = None
+try:
+ import keras_nlp
+except Exception as e:
+ print(f"Could not import Keras NLP. Exception: {e}")
+ keras_nlp = None
EXAMPLES_GH_LOCATION = Path("keras-team") / "keras-io" / "blob" / "master" / "examples"
GUIDES_GH_LOCATION = Path("keras-team") / "keras-io" / "blob" / "master" / "guides"
@@ -48,6 +53,7 @@
"keras_tuner": f"{KERAS_TEAM_GH}/keras-tuner/tree/v1.4.7/",
"keras_cv": f"{KERAS_TEAM_GH}/keras-cv/tree/v0.9.0/",
"keras_nlp": f"{KERAS_TEAM_GH}/keras-nlp/tree/v0.15.1/",
+ "keras_hub": f"{KERAS_TEAM_GH}/keras-hub/tree/v0.16.1.dev202409290341/",
"tf_keras": f"{KERAS_TEAM_GH}/tf-keras/tree/v2.17.0/",
}
USE_MULTIPROCESSING = False
@@ -543,6 +549,8 @@ def make_md_source_for_entry(self, entry, path_stack, title_stack):
template = render_tags.render_tags(template, keras_nlp)
if "keras_cv/" in path_stack and "models/" in path_stack:
template = render_tags.render_tags(template, keras_cv)
+ if "keras_hub/" in path_stack and "models/" in path_stack:
+ template = render_tags.render_tags(template, keras_hub)
source_path = Path(self.md_sources_dir) / Path(*path_stack)
if path.endswith("/"):
md_source_path = source_path / "index.md"
diff --git a/scripts/docstrings.py b/scripts/docstrings.py
index d33124a0eb..9a705f69cb 100644
--- a/scripts/docstrings.py
+++ b/scripts/docstrings.py
@@ -94,7 +94,7 @@ def render_from_object(self, object_, signature_override: str, element):
if docstring:
docstring = self.process_docstring(docstring)
subblocks.append(docstring)
- # Render preset table for KerasCV and KerasNLP
+ # Render preset table for KerasCV and KerasHub
if element.endswith("from_preset"):
table = render_tags.render_table(import_object(element.rsplit(".", 1)[0]))
if table is not None:
diff --git a/scripts/examples_master.py b/scripts/examples_master.py
index 6477e994a4..eb2e6d96c7 100644
--- a/scripts/examples_master.py
+++ b/scripts/examples_master.py
@@ -433,7 +433,7 @@
"subcategory": "Text classification",
},
{
- "path": "fnet_classification_with_keras_nlp",
+ "path": "fnet_classification_with_keras_hub",
"title": "Text Classification using FNet",
"subcategory": "Text classification",
"keras_3": True,
@@ -473,15 +473,15 @@
"keras_3": True,
},
{
- "path": "data_parallel_training_with_keras_nlp",
- "title": "Data Parallel Training with KerasNLP and tf.distribute",
+ "path": "data_parallel_training_with_keras_hub",
+ "title": "Data Parallel Training with KerasHub and tf.distribute",
"subcategory": "Text classification",
"keras_3": True,
},
# Machine translation
{
- "path": "neural_machine_translation_with_keras_nlp",
- "title": "English-to-Spanish translation with KerasNLP",
+ "path": "neural_machine_translation_with_keras_hub",
+ "title": "English-to-Spanish translation with KerasHub",
"subcategory": "Machine translation",
"keras_3": True,
},
@@ -525,8 +525,8 @@
},
# Text similarity search
{
- "path": "semantic_similarity_with_keras_nlp",
- "title": "Semantic Similarity with KerasNLP",
+ "path": "semantic_similarity_with_keras_hub",
+ "title": "Semantic Similarity with KerasHub",
"subcategory": "Text similarity search",
"keras_3": True,
},
@@ -807,15 +807,15 @@
},
# Text generation
{
- "path": "gpt2_text_generation_with_kerasnlp",
- "title": "GPT2 Text Generation with KerasNLP",
+ "path": "gpt2_text_generation_with_keras_hub",
+ "title": "GPT2 Text Generation with KerasHub",
"subcategory": "Text generation",
"highlight": True,
"keras_3": True,
},
{
"path": "text_generation_gpt",
- "title": "GPT text generation from scratch with KerasNLP",
+ "title": "GPT text generation from scratch with KerasHub",
"subcategory": "Text generation",
"keras_3": True,
},
diff --git a/scripts/guides_master.py b/scripts/guides_master.py
index 7505d000d4..4912a80149 100644
--- a/scripts/guides_master.py
+++ b/scripts/guides_master.py
@@ -54,6 +54,26 @@
],
}
+HUB_GUIDES_MASTER = {
+ "path": "keras_hub/",
+ "title": "KerasHub",
+ "toc": True,
+ "children": [
+ {
+ "path": "getting_started",
+ "title": "Getting Started with KerasHub",
+ },
+ {
+ "path": "transformer_pretraining",
+ "title": "Pretraining a Transformer from scratch with KerasHub",
+ },
+ {
+ "path": "upload",
+ "title": "Uploading Models with KerasHub",
+ },
+ ],
+}
+
KT_GUIDES_MASTER = {
"path": "keras_tuner/",
"title": "Hyperparameter Tuning",
@@ -202,5 +222,6 @@
KT_GUIDES_MASTER,
CV_GUIDES_MASTER,
NLP_GUIDES_MASTER,
+ HUB_GUIDES_MASTER,
],
}
diff --git a/scripts/hub_api_master.py b/scripts/hub_api_master.py
new file mode 100644
index 0000000000..18787ee0fd
--- /dev/null
+++ b/scripts/hub_api_master.py
@@ -0,0 +1,1426 @@
+BASE_CLASSES = {
+ "path": "base_classes/",
+ "title": "Models API",
+ "toc": True,
+ "children": [
+ {
+ "path": "backbone",
+ "title": "Backbone",
+ "generate": [
+ "keras_hub.models.Backbone",
+ "keras_hub.models.Backbone.from_preset",
+ "keras_hub.models.Backbone.token_embedding",
+ "keras_hub.models.Backbone.enable_lora",
+ "keras_hub.models.Backbone.save_lora_weights",
+ "keras_hub.models.Backbone.load_lora_weights",
+ "keras_hub.models.Backbone.save_to_preset",
+ ],
+ },
+ {
+ "path": "task",
+ "title": "Task",
+ "generate": [
+ "keras_hub.models.Task",
+ "keras_hub.models.Task.from_preset",
+ "keras_hub.models.Task.save_to_preset",
+ "keras_hub.models.Task.preprocessor",
+ "keras_hub.models.Task.backbone",
+ ],
+ },
+ {
+ "path": "preprocessor",
+ "title": "Preprocessor",
+ "generate": [
+ "keras_hub.models.Preprocessor",
+ "keras_hub.models.Preprocessor.from_preset",
+ "keras_hub.models.Preprocessor.save_to_preset",
+ "keras_hub.models.Preprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "causal_lm",
+ "title": "CausalLM",
+ "generate": [
+ "keras_hub.models.CausalLM",
+ "keras_hub.models.CausalLM.from_preset",
+ "keras_hub.models.CausalLM.compile",
+ "keras_hub.models.CausalLM.generate",
+ "keras_hub.models.CausalLM.save_to_preset",
+ "keras_hub.models.CausalLM.preprocessor",
+ "keras_hub.models.CausalLM.backbone",
+ ],
+ },
+ {
+ "path": "causal_lm_preprocessor",
+ "title": "CausalLMPreprocessor",
+ "generate": [
+ "keras_hub.models.CausalLMPreprocessor",
+ "keras_hub.models.CausalLMPreprocessor.from_preset",
+ "keras_hub.models.CausalLMPreprocessor.save_to_preset",
+ "keras_hub.models.CausalLMPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "seq_2_seq_lm",
+ "title": "Seq2SeqLM",
+ "generate": [
+ "keras_hub.models.Seq2SeqLM",
+ "keras_hub.models.Seq2SeqLM.from_preset",
+ "keras_hub.models.Seq2SeqLM.compile",
+ "keras_hub.models.Seq2SeqLM.generate",
+ "keras_hub.models.Seq2SeqLM.save_to_preset",
+ "keras_hub.models.Seq2SeqLM.preprocessor",
+ "keras_hub.models.Seq2SeqLM.backbone",
+ ],
+ },
+ {
+ "path": "seq_2_seq_lm_preprocessor",
+ "title": "Seq2SeqLMPreprocessor",
+ "generate": [
+ "keras_hub.models.Seq2SeqLMPreprocessor",
+ "keras_hub.models.Seq2SeqLMPreprocessor.from_preset",
+ "keras_hub.models.Seq2SeqLMPreprocessor.save_to_preset",
+ "keras_hub.models.Seq2SeqLMPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "text_classifier",
+ "title": "TextClassifier",
+ "generate": [
+ "keras_hub.models.TextClassifier",
+ "keras_hub.models.TextClassifier.from_preset",
+ "keras_hub.models.TextClassifier.compile",
+ "keras_hub.models.TextClassifier.save_to_preset",
+ "keras_hub.models.TextClassifier.preprocessor",
+ "keras_hub.models.TextClassifier.backbone",
+ ],
+ },
+ {
+ "path": "text_classifier_preprocessor",
+ "title": "TextClassifierPreprocessor",
+ "generate": [
+ "keras_hub.models.TextClassifierPreprocessor",
+ "keras_hub.models.TextClassifierPreprocessor.from_preset",
+ "keras_hub.models.TextClassifierPreprocessor.save_to_preset",
+ "keras_hub.models.TextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "masked_lm",
+ "title": "MaskedLM",
+ "generate": [
+ "keras_hub.models.MaskedLM",
+ "keras_hub.models.MaskedLM.from_preset",
+ "keras_hub.models.MaskedLM.compile",
+ "keras_hub.models.MaskedLM.save_to_preset",
+ "keras_hub.models.MaskedLM.preprocessor",
+ "keras_hub.models.MaskedLM.backbone",
+ ],
+ },
+ {
+ "path": "masked_lm_preprocessor",
+ "title": "MaskedLMPreprocessor",
+ "generate": [
+ "keras_hub.models.MaskedLMPreprocessor",
+ "keras_hub.models.MaskedLMPreprocessor.from_preset",
+ "keras_hub.models.MaskedLMPreprocessor.save_to_preset",
+ "keras_hub.models.MaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "upload_preset",
+ "title": "upload_preset",
+ "generate": ["keras_hub.upload_preset"],
+ },
+ ],
+}
+
+MODELS_MASTER = {
+ "path": "models/",
+ "title": "Pretrained Models",
+ "toc": True,
+ "children": [
+ {
+ "path": "albert/",
+ "title": "Albert",
+ "toc": True,
+ "children": [
+ {
+ "path": "albert_tokenizer",
+ "title": "AlbertTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.AlbertTokenizer",
+ "keras_hub.tokenizers.AlbertTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "albert_backbone",
+ "title": "AlbertBackbone model",
+ "generate": [
+ "keras_hub.models.AlbertBackbone",
+ "keras_hub.models.AlbertBackbone.from_preset",
+ "keras_hub.models.AlbertBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "albert_text_classifier",
+ "title": "AlbertTextClassifier model",
+ "generate": [
+ "keras_hub.models.AlbertTextClassifier",
+ "keras_hub.models.AlbertTextClassifier.from_preset",
+ "keras_hub.models.AlbertTextClassifier.backbone",
+ "keras_hub.models.AlbertTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "albert_text_classifier_preprocessor",
+ "title": "AlbertTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.AlbertTextClassifierPreprocessor",
+ "keras_hub.models.AlbertTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.AlbertTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "albert_masked_lm",
+ "title": "AlbertMaskedLM model",
+ "generate": [
+ "keras_hub.models.AlbertMaskedLM",
+ "keras_hub.models.AlbertMaskedLM.from_preset",
+ "keras_hub.models.AlbertMaskedLM.backbone",
+ "keras_hub.models.AlbertMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "albert_masked_lm_preprocessor",
+ "title": "AlbertMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.AlbertMaskedLMPreprocessor",
+ "keras_hub.models.AlbertMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.AlbertMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "bart/",
+ "title": "Bart",
+ "toc": True,
+ "children": [
+ {
+ "path": "bart_tokenizer",
+ "title": "BertTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.BertTokenizer",
+ "keras_hub.tokenizers.BertTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "bart_backbone",
+ "title": "BertBackbone model",
+ "generate": [
+ "keras_hub.models.BertBackbone",
+ "keras_hub.models.BertBackbone.from_preset",
+ "keras_hub.models.BertBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "bart_seq_2_seq_lm",
+ "title": "BartSeq2SeqLM model",
+ "generate": [
+ "keras_hub.models.BartSeq2SeqLM",
+ "keras_hub.models.BartSeq2SeqLM.from_preset",
+ "keras_hub.models.BartSeq2SeqLM.generate",
+ "keras_hub.models.BartSeq2SeqLM.backbone",
+ "keras_hub.models.BartSeq2SeqLM.preprocessor",
+ ],
+ },
+ {
+ "path": "bart_seq_2_seq_lm_preprocessor",
+ "title": "BartSeq2SeqLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.BartSeq2SeqLMPreprocessor",
+ "keras_hub.models.BartSeq2SeqLMPreprocessor.from_preset",
+ "keras_hub.models.BartSeq2SeqLMPreprocessor.generate_preprocess",
+ "keras_hub.models.BartSeq2SeqLMPreprocessor.generate_postprocess",
+ "keras_hub.models.BartSeq2SeqLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "bert/",
+ "title": "Bert",
+ "toc": True,
+ "children": [
+ {
+ "path": "bert_tokenizer",
+ "title": "BertTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.BertTokenizer",
+ "keras_hub.tokenizers.BertTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "bert_backbone",
+ "title": "BertBackbone model",
+ "generate": [
+ "keras_hub.models.BertBackbone",
+ "keras_hub.models.BertBackbone.from_preset",
+ "keras_hub.models.BertBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "bert_text_classifier",
+ "title": "BertTextClassifier model",
+ "generate": [
+ "keras_hub.models.BertTextClassifier",
+ "keras_hub.models.BertTextClassifier.from_preset",
+ "keras_hub.models.BertTextClassifier.backbone",
+ "keras_hub.models.BertTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "bert_text_classifier_preprocessor",
+ "title": "BertTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.BertTextClassifierPreprocessor",
+ "keras_hub.models.BertTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.BertTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "bert_masked_lm",
+ "title": "BertMaskedLM model",
+ "generate": [
+ "keras_hub.models.BertMaskedLM",
+ "keras_hub.models.BertMaskedLM.from_preset",
+ "keras_hub.models.BertMaskedLM.backbone",
+ "keras_hub.models.BertMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "bert_masked_lm_preprocessor",
+ "title": "BertMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.BertMaskedLMPreprocessor",
+ "keras_hub.models.BertMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.BertMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "bloom/",
+ "title": "Bloom",
+ "toc": True,
+ "children": [
+ {
+ "path": "bloom_tokenizer",
+ "title": "BloomTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.BloomTokenizer",
+ "keras_hub.tokenizers.BloomTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "bloom_backbone",
+ "title": "BloomBackbone model",
+ "generate": [
+ "keras_hub.models.BloomBackbone",
+ "keras_hub.models.BloomBackbone.from_preset",
+ "keras_hub.models.BloomBackbone.token_embedding",
+ "keras_hub.models.BloomBackbone.enable_lora",
+ ],
+ },
+ {
+ "path": "bloom_causal_lm",
+ "title": "BloomCausalLM model",
+ "generate": [
+ "keras_hub.models.BloomCausalLM",
+ "keras_hub.models.BloomCausalLM.from_preset",
+ "keras_hub.models.BloomCausalLM.generate",
+ "keras_hub.models.BloomCausalLM.backbone",
+ "keras_hub.models.BloomCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "bloom_causal_lm_preprocessor",
+ "title": "BloomCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.BloomCausalLMPreprocessor",
+ "keras_hub.models.BloomCausalLMPreprocessor.from_preset",
+ "keras_hub.models.BloomCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "deberta_v3/",
+ "title": "DebertaV3",
+ "toc": True,
+ "children": [
+ {
+ "path": "deberta_v3_tokenizer",
+ "title": "DebertaV3Tokenizer",
+ "generate": [
+ "keras_hub.tokenizers.DebertaV3Tokenizer",
+ "keras_hub.tokenizers.DebertaV3Tokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "deberta_v3_backbone",
+ "title": "DebertaV3Backbone model",
+ "generate": [
+ "keras_hub.models.DebertaV3Backbone",
+ "keras_hub.models.DebertaV3Backbone.from_preset",
+ "keras_hub.models.DebertaV3Backbone.token_embedding",
+ ],
+ },
+ {
+ "path": "deberta_v3_text_classifier",
+ "title": "DebertaV3TextClassifier model",
+ "generate": [
+ "keras_hub.models.DebertaV3TextClassifier",
+ "keras_hub.models.DebertaV3TextClassifier.from_preset",
+ "keras_hub.models.DebertaV3TextClassifier.backbone",
+ "keras_hub.models.DebertaV3TextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "deberta_v3_text_classifier_preprocessor",
+ "title": "DebertaV3TextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.DebertaV3TextClassifierPreprocessor",
+ "keras_hub.models.DebertaV3TextClassifierPreprocessor.from_preset",
+ "keras_hub.models.DebertaV3TextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "deberta_v3_masked_lm",
+ "title": "DebertaV3MaskedLM model",
+ "generate": [
+ "keras_hub.models.DebertaV3MaskedLM",
+ "keras_hub.models.DebertaV3MaskedLM.from_preset",
+ "keras_hub.models.DebertaV3MaskedLM.backbone",
+ "keras_hub.models.DebertaV3MaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "deberta_v3_masked_lm_preprocessor",
+ "title": "DebertaV3MaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.DebertaV3MaskedLMPreprocessor",
+ "keras_hub.models.DebertaV3MaskedLMPreprocessor.from_preset",
+ "keras_hub.models.DebertaV3MaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "distil_bert/",
+ "title": "DistilBert",
+ "toc": True,
+ "children": [
+ {
+ "path": "distil_bert_tokenizer",
+ "title": "DistilBertTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.DistilBertTokenizer",
+ "keras_hub.tokenizers.DistilBertTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "distil_bert_backbone",
+ "title": "DistilBertBackbone model",
+ "generate": [
+ "keras_hub.models.DistilBertBackbone",
+ "keras_hub.models.DistilBertBackbone.from_preset",
+ "keras_hub.models.DistilBertBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "distil_bert_text_classifier",
+ "title": "DistilBertTextClassifier model",
+ "generate": [
+ "keras_hub.models.DistilBertTextClassifier",
+ "keras_hub.models.DistilBertTextClassifier.from_preset",
+ "keras_hub.models.DistilBertTextClassifier.backbone",
+ "keras_hub.models.DistilBertTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "distil_bert_text_classifier_preprocessor",
+ "title": "DistilBertTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.DistilBertTextClassifierPreprocessor",
+ "keras_hub.models.DistilBertTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.DistilBertTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "distil_bert_masked_lm",
+ "title": "DistilBertMaskedLM model",
+ "generate": [
+ "keras_hub.models.DistilBertMaskedLM",
+ "keras_hub.models.DistilBertMaskedLM.from_preset",
+ "keras_hub.models.DistilBertMaskedLM.backbone",
+ "keras_hub.models.DistilBertMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "distil_bert_masked_lm_preprocessor",
+ "title": "DistilBertMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.DistilBertMaskedLMPreprocessor",
+ "keras_hub.models.DistilBertMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.DistilBertMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "gemma/",
+ "title": "Gemma",
+ "toc": True,
+ "children": [
+ {
+ "path": "gemma_tokenizer",
+ "title": "GemmaTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.GemmaTokenizer",
+ "keras_hub.tokenizers.GemmaTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "gemma_backbone",
+ "title": "GemmaBackbone model",
+ "generate": [
+ "keras_hub.models.GemmaBackbone",
+ "keras_hub.models.GemmaBackbone.from_preset",
+ "keras_hub.models.GemmaBackbone.token_embedding",
+ "keras_hub.models.GemmaBackbone.enable_lora",
+ "keras_hub.models.GemmaBackbone.get_layout_map",
+ ],
+ },
+ {
+ "path": "gemma_causal_lm",
+ "title": "GemmaCausalLM model",
+ "generate": [
+ "keras_hub.models.GemmaCausalLM",
+ "keras_hub.models.GemmaCausalLM.from_preset",
+ "keras_hub.models.GemmaCausalLM.generate",
+ "keras_hub.models.GemmaCausalLM.backbone",
+ "keras_hub.models.GemmaCausalLM.preprocessor",
+ "keras_hub.models.GemmaCausalLM.score",
+ ],
+ },
+ {
+ "path": "gemma_causal_lm_preprocessor",
+ "title": "GemmaCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.GemmaCausalLMPreprocessor",
+ "keras_hub.models.GemmaCausalLMPreprocessor.from_preset",
+ "keras_hub.models.GemmaCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "electra/",
+ "title": "Electra",
+ "toc": True,
+ "children": [
+ {
+ "path": "electra_tokenizer",
+ "title": "ElectraTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.ElectraTokenizer",
+ "keras_hub.tokenizers.ElectraTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "electra_backbone",
+ "title": "ElectraBackbone model",
+ "generate": [
+ "keras_hub.models.ElectraBackbone",
+ "keras_hub.models.ElectraBackbone.from_preset",
+ "keras_hub.models.ElectraBackbone.token_embedding",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "falcon/",
+ "title": "Falcon",
+ "toc": True,
+ "children": [
+ {
+ "path": "falcon_tokenizer",
+ "title": "FalconTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.FalconTokenizer",
+ "keras_hub.tokenizers.FalconTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "falcon_backbone",
+ "title": "FalconBackbone model",
+ "generate": [
+ "keras_hub.models.FalconBackbone",
+ "keras_hub.models.FalconBackbone.from_preset",
+ "keras_hub.models.FalconBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "falcon_causal_lm",
+ "title": "FalconCausalLM model",
+ "generate": [
+ "keras_hub.models.FalconCausalLM",
+ "keras_hub.models.FalconCausalLM.from_preset",
+ "keras_hub.models.FalconCausalLM.generate",
+ "keras_hub.models.FalconCausalLM.backbone",
+ "keras_hub.models.FalconCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "falcon_causal_lm_preprocessor",
+ "title": "FalconCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.FalconCausalLMPreprocessor",
+ "keras_hub.models.FalconCausalLMPreprocessor.from_preset",
+ "keras_hub.models.FalconCausalLMPreprocessor.generate_preprocess",
+ "keras_hub.models.FalconCausalLMPreprocessor.generate_postprocess",
+ "keras_hub.models.FalconCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "f_net/",
+ "title": "FNet",
+ "toc": True,
+ "children": [
+ {
+ "path": "f_net_tokenizer",
+ "title": "FNetTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.FNetTokenizer",
+ "keras_hub.tokenizers.FNetTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "f_net_backbone",
+ "title": "FNetBackbone model",
+ "generate": [
+ "keras_hub.models.FNetBackbone",
+ "keras_hub.models.FNetBackbone.from_preset",
+ "keras_hub.models.FNetBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "f_net_text_classifier",
+ "title": "FNetTextClassifier model",
+ "generate": [
+ "keras_hub.models.FNetTextClassifier",
+ "keras_hub.models.FNetTextClassifier.from_preset",
+ "keras_hub.models.FNetTextClassifier.backbone",
+ "keras_hub.models.FNetTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "f_net_text_classifier_preprocessor",
+ "title": "FNetTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.FNetTextClassifierPreprocessor",
+ "keras_hub.models.FNetTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.FNetTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "f_net_masked_lm",
+ "title": "FNetMaskedLM model",
+ "generate": [
+ "keras_hub.models.FNetMaskedLM",
+ "keras_hub.models.FNetMaskedLM.from_preset",
+ "keras_hub.models.FNetMaskedLM.backbone",
+ "keras_hub.models.FNetMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "f_net_masked_lm_preprocessor",
+ "title": "FNetMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.FNetMaskedLMPreprocessor",
+ "keras_hub.models.FNetMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.FNetMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "gpt2/",
+ "title": "GPT2",
+ "toc": True,
+ "children": [
+ {
+ "path": "gpt2_tokenizer",
+ "title": "GPT2Tokenizer",
+ "generate": [
+ "keras_hub.tokenizers.GPT2Tokenizer",
+ "keras_hub.tokenizers.GPT2Tokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "gpt2_backbone",
+ "title": "GPT2Backbone model",
+ "generate": [
+ "keras_hub.models.GPT2Backbone",
+ "keras_hub.models.GPT2Backbone.from_preset",
+ "keras_hub.models.GPT2Backbone.token_embedding",
+ ],
+ },
+ {
+ "path": "gpt2_causal_lm",
+ "title": "GPT2CausalLM model",
+ "generate": [
+ "keras_hub.models.GPT2CausalLM",
+ "keras_hub.models.GPT2CausalLM.from_preset",
+ "keras_hub.models.GPT2CausalLM.generate",
+ "keras_hub.models.GPT2CausalLM.backbone",
+ "keras_hub.models.GPT2CausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "gpt2_causal_lm_preprocessor",
+ "title": "GPT2CausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.GPT2CausalLMPreprocessor",
+ "keras_hub.models.GPT2CausalLMPreprocessor.from_preset",
+ "keras_hub.models.GPT2CausalLMPreprocessor.generate_preprocess",
+ "keras_hub.models.GPT2CausalLMPreprocessor.generate_postprocess",
+ "keras_hub.models.GPT2CausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "llama/",
+ "title": "Llama",
+ "toc": True,
+ "children": [
+ {
+ "path": "llama_tokenizer",
+ "title": "LlamaTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.LlamaTokenizer",
+ "keras_hub.tokenizers.LlamaTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "llama_backbone",
+ "title": "LlamaBackbone model",
+ "generate": [
+ "keras_hub.models.LlamaBackbone",
+ "keras_hub.models.LlamaBackbone.from_preset",
+ "keras_hub.models.LlamaBackbone.token_embedding",
+ "keras_hub.models.LlamaBackbone.enable_lora",
+ ],
+ },
+ {
+ "path": "llama_causal_lm",
+ "title": "LlamaCausalLM model",
+ "generate": [
+ "keras_hub.models.LlamaCausalLM",
+ "keras_hub.models.LlamaCausalLM.from_preset",
+ "keras_hub.models.LlamaCausalLM.generate",
+ "keras_hub.models.LlamaCausalLM.backbone",
+ "keras_hub.models.LlamaCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "llama_causal_lm_preprocessor",
+ "title": "LlamaCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.LlamaCausalLMPreprocessor",
+ "keras_hub.models.LlamaCausalLMPreprocessor.from_preset",
+ "keras_hub.models.LlamaCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "llama3/",
+ "title": "Llama3",
+ "toc": True,
+ "children": [
+ {
+ "path": "llama3_tokenizer",
+ "title": "Llama3Tokenizer",
+ "generate": [
+ "keras_hub.tokenizers.Llama3Tokenizer",
+ "keras_hub.tokenizers.Llama3Tokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "llama3_backbone",
+ "title": "Llama3Backbone model",
+ "generate": [
+ "keras_hub.models.Llama3Backbone",
+ "keras_hub.models.Llama3Backbone.from_preset",
+ "keras_hub.models.Llama3Backbone.token_embedding",
+ "keras_hub.models.Llama3Backbone.enable_lora",
+ ],
+ },
+ {
+ "path": "llama3_causal_lm",
+ "title": "Llama3CausalLM model",
+ "generate": [
+ "keras_hub.models.Llama3CausalLM",
+ "keras_hub.models.Llama3CausalLM.from_preset",
+ "keras_hub.models.Llama3CausalLM.generate",
+ "keras_hub.models.Llama3CausalLM.backbone",
+ "keras_hub.models.Llama3CausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "llama3_causal_lm_preprocessor",
+ "title": "Llama3CausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.Llama3CausalLMPreprocessor",
+ "keras_hub.models.Llama3CausalLMPreprocessor.from_preset",
+ "keras_hub.models.Llama3CausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "mistral/",
+ "title": "Mistral",
+ "toc": True,
+ "children": [
+ {
+ "path": "mistral_tokenizer",
+ "title": "MistralTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.MistralTokenizer",
+ "keras_hub.tokenizers.MistralTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "mistral_backbone",
+ "title": "MistralBackbone model",
+ "generate": [
+ "keras_hub.models.MistralBackbone",
+ "keras_hub.models.MistralBackbone.from_preset",
+ "keras_hub.models.MistralBackbone.token_embedding",
+ "keras_hub.models.MistralBackbone.enable_lora",
+ ],
+ },
+ {
+ "path": "mistral_causal_lm",
+ "title": "MistralCausalLM model",
+ "generate": [
+ "keras_hub.models.MistralCausalLM",
+ "keras_hub.models.MistralCausalLM.from_preset",
+ "keras_hub.models.MistralCausalLM.generate",
+ "keras_hub.models.MistralCausalLM.backbone",
+ "keras_hub.models.MistralCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "mistral_causal_lm_preprocessor",
+ "title": "MistralCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.MistralCausalLMPreprocessor",
+ "keras_hub.models.MistralCausalLMPreprocessor.from_preset",
+ "keras_hub.models.MistralCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "opt/",
+ "title": "OPT",
+ "toc": True,
+ "children": [
+ {
+ "path": "opt_tokenizer",
+ "title": "OPTTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.OPTTokenizer",
+ "keras_hub.tokenizers.OPTTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "opt_backbone",
+ "title": "OPTBackbone model",
+ "generate": [
+ "keras_hub.models.OPTBackbone",
+ "keras_hub.models.OPTBackbone.from_preset",
+ "keras_hub.models.OPTBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "opt_causal_lm",
+ "title": "OPTCausalLM model",
+ "generate": [
+ "keras_hub.models.OPTCausalLM",
+ "keras_hub.models.OPTCausalLM.from_preset",
+ "keras_hub.models.OPTCausalLM.generate",
+ "keras_hub.models.OPTCausalLM.backbone",
+ "keras_hub.models.OPTCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "opt_causal_lm_preprocessor",
+ "title": "OPTCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.OPTCausalLMPreprocessor",
+ "keras_hub.models.OPTCausalLMPreprocessor.from_preset",
+ "keras_hub.models.OPTCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "pali_gemma/",
+ "title": "PaliGemma",
+ "toc": True,
+ "children": [
+ {
+ "path": "pali_gemma_tokenizer",
+ "title": "PaliGemmaTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.PaliGemmaTokenizer",
+ "keras_hub.tokenizers.PaliGemmaTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "pali_gemma_backbone",
+ "title": "PaliGemmaBackbone model",
+ "generate": [
+ "keras_hub.models.PaliGemmaBackbone",
+ "keras_hub.models.PaliGemmaBackbone.from_preset",
+ "keras_hub.models.PaliGemmaBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "pali_gemma_causal_lm",
+ "title": "PaliGemmaCausalLM model",
+ "generate": [
+ "keras_hub.models.PaliGemmaCausalLM",
+ "keras_hub.models.PaliGemmaCausalLM.from_preset",
+ "keras_hub.models.PaliGemmaCausalLM.generate",
+ "keras_hub.models.PaliGemmaCausalLM.backbone",
+ "keras_hub.models.PaliGemmaCausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "pali_gemma_causal_lm_preprocessor",
+ "title": "PaliGemmaCausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.PaliGemmaCausalLMPreprocessor",
+ "keras_hub.models.PaliGemmaCausalLMPreprocessor.from_preset",
+ "keras_hub.models.PaliGemmaCausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "phi3/",
+ "title": "Phi3",
+ "toc": True,
+ "children": [
+ {
+ "path": "phi3_tokenizer",
+ "title": "Phi3Tokenizer",
+ "generate": [
+ "keras_hub.tokenizers.Phi3Tokenizer",
+ "keras_hub.tokenizers.Phi3Tokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "phi3_backbone",
+ "title": "Phi3Backbone model",
+ "generate": [
+ "keras_hub.models.Phi3Backbone",
+ "keras_hub.models.Phi3Backbone.from_preset",
+ "keras_hub.models.Phi3Backbone.token_embedding",
+ ],
+ },
+ {
+ "path": "phi3_causal_lm",
+ "title": "Phi3CausalLM model",
+ "generate": [
+ "keras_hub.models.Phi3CausalLM",
+ "keras_hub.models.Phi3CausalLM.from_preset",
+ "keras_hub.models.Phi3CausalLM.generate",
+ "keras_hub.models.Phi3CausalLM.backbone",
+ "keras_hub.models.Phi3CausalLM.preprocessor",
+ ],
+ },
+ {
+ "path": "phi3_causal_lm_preprocessor",
+ "title": "Phi3CausalLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.Phi3CausalLMPreprocessor",
+ "keras_hub.models.Phi3CausalLMPreprocessor.from_preset",
+ "keras_hub.models.Phi3CausalLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "resnet/",
+ "title": "ResNet",
+ "toc": True,
+ "children": [
+ {
+ "path": "resnet_image_converter",
+ "title": "ResNetImageConverter",
+ "generate": [
+ "keras_hub.layers.ResNetImageConverter",
+ "keras_hub.layers.ResNetImageConverter.from_preset",
+ ],
+ },
+ {
+ "path": "resnet_backbone",
+ "title": "ResNetBackbone model",
+ "generate": [
+ "keras_hub.models.ResNetBackbone",
+ "keras_hub.models.ResNetBackbone.from_preset",
+ "keras_hub.models.ResNetBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "resnet_image_classifier",
+ "title": "ResNetImageClassifier model",
+ "generate": [
+ "keras_hub.models.ResNetImageClassifier",
+ "keras_hub.models.ResNetImageClassifier.from_preset",
+ "keras_hub.models.ResNetImageClassifier.backbone",
+ "keras_hub.models.ResNetImageClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "resnet_image_classifier_preprocessor",
+ "title": "ResNetImageClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.ResNetImageClassifierPreprocessor",
+ "keras_hub.models.ResNetImageClassifierPreprocessor.from_preset",
+ "keras_hub.models.ResNetImageClassifierPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "roberta/",
+ "title": "Roberta",
+ "toc": True,
+ "children": [
+ {
+ "path": "roberta_tokenizer",
+ "title": "RobertaTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.RobertaTokenizer",
+ "keras_hub.tokenizers.RobertaTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "roberta_backbone",
+ "title": "RobertaBackbone model",
+ "generate": [
+ "keras_hub.models.RobertaBackbone",
+ "keras_hub.models.RobertaBackbone.from_preset",
+ "keras_hub.models.RobertaBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "roberta_text_classifier",
+ "title": "RobertaTextClassifier model",
+ "generate": [
+ "keras_hub.models.RobertaTextClassifier",
+ "keras_hub.models.RobertaTextClassifier.from_preset",
+ "keras_hub.models.RobertaTextClassifier.backbone",
+ "keras_hub.models.RobertaTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "roberta_text_classifier_preprocessor",
+ "title": "RobertaTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.RobertaTextClassifierPreprocessor",
+ "keras_hub.models.RobertaTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.RobertaTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "roberta_masked_lm",
+ "title": "RobertaMaskedLM model",
+ "generate": [
+ "keras_hub.models.RobertaMaskedLM",
+ "keras_hub.models.RobertaMaskedLM.from_preset",
+ "keras_hub.models.RobertaMaskedLM.backbone",
+ "keras_hub.models.RobertaMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "roberta_masked_lm_preprocessor",
+ "title": "RobertaMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.RobertaMaskedLMPreprocessor",
+ "keras_hub.models.RobertaMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.RobertaMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ {
+ "path": "xlm_roberta/",
+ "title": "XLMRoberta",
+ "toc": True,
+ "children": [
+ {
+ "path": "xlm_roberta_tokenizer",
+ "title": "XLMRobertaTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.XLMRobertaTokenizer",
+ "keras_hub.tokenizers.XLMRobertaTokenizer.from_preset",
+ ],
+ },
+ {
+ "path": "xlm_roberta_backbone",
+ "title": "XLMRobertaBackbone model",
+ "generate": [
+ "keras_hub.models.XLMRobertaBackbone",
+ "keras_hub.models.XLMRobertaBackbone.from_preset",
+ "keras_hub.models.XLMRobertaBackbone.token_embedding",
+ ],
+ },
+ {
+ "path": "xlm_roberta_text_classifier",
+ "title": "XLMRobertaTextClassifier model",
+ "generate": [
+ "keras_hub.models.XLMRobertaTextClassifier",
+ "keras_hub.models.XLMRobertaTextClassifier.from_preset",
+ "keras_hub.models.XLMRobertaTextClassifier.backbone",
+ "keras_hub.models.XLMRobertaTextClassifier.preprocessor",
+ ],
+ },
+ {
+ "path": "xlm_roberta_text_classifier_preprocessor",
+ "title": "XLMRobertaTextClassifierPreprocessor layer",
+ "generate": [
+ "keras_hub.models.XLMRobertaTextClassifierPreprocessor",
+ "keras_hub.models.XLMRobertaTextClassifierPreprocessor.from_preset",
+ "keras_hub.models.XLMRobertaTextClassifierPreprocessor.tokenizer",
+ ],
+ },
+ {
+ "path": "xlm_roberta_masked_lm",
+ "title": "XLMRobertaMaskedLM model",
+ "generate": [
+ "keras_hub.models.XLMRobertaMaskedLM",
+ "keras_hub.models.XLMRobertaMaskedLM.from_preset",
+ "keras_hub.models.XLMRobertaMaskedLM.backbone",
+ "keras_hub.models.XLMRobertaMaskedLM.preprocessor",
+ ],
+ },
+ {
+ "path": "xlm_roberta_masked_lm_preprocessor",
+ "title": "XLMRobertaMaskedLMPreprocessor layer",
+ "generate": [
+ "keras_hub.models.XLMRobertaMaskedLMPreprocessor",
+ "keras_hub.models.XLMRobertaMaskedLMPreprocessor.from_preset",
+ "keras_hub.models.XLMRobertaMaskedLMPreprocessor.tokenizer",
+ ],
+ },
+ ],
+ },
+ ],
+}
+
+SAMPLERS_MASTER = {
+ "path": "samplers/",
+ "title": "Samplers",
+ "toc": True,
+ "children": [
+ {
+ "path": "samplers",
+ "title": "Sampler base class",
+ "generate": [
+ "keras_hub.samplers.Sampler",
+ "keras_hub.samplers.Sampler.get_next_token",
+ ],
+ },
+ {
+ "path": "beam_sampler",
+ "title": "BeamSampler",
+ "generate": ["keras_hub.samplers.BeamSampler"],
+ },
+ {
+ "path": "contrastive_sampler",
+ "title": "ContrastiveSampler",
+ "generate": ["keras_hub.samplers.ContrastiveSampler"],
+ },
+ {
+ "path": "greedy_sampler",
+ "title": "GreedySampler",
+ "generate": ["keras_hub.samplers.GreedySampler"],
+ },
+ {
+ "path": "random_sampler",
+ "title": "RandomSampler",
+ "generate": ["keras_hub.samplers.RandomSampler"],
+ },
+ {
+ "path": "top_k_sampler",
+ "title": "TopKSampler",
+ "generate": ["keras_hub.samplers.TopKSampler"],
+ },
+ {
+ "path": "top_p_sampler",
+ "title": "TopPSampler",
+ "generate": ["keras_hub.samplers.TopPSampler"],
+ },
+ ],
+}
+
+TOKENIZERS_MASTER = {
+ "path": "tokenizers/",
+ "title": "Tokenizers",
+ "toc": True,
+ "children": [
+ {
+ "path": "tokenizer",
+ "title": "Tokenizer",
+ "generate": [
+ "keras_hub.tokenizers.Tokenizer",
+ "keras_hub.tokenizers.Tokenizer.from_preset",
+ "keras_hub.tokenizers.Tokenizer.save_to_preset",
+ ],
+ },
+ {
+ "path": "word_piece_tokenizer",
+ "title": "WordPieceTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.WordPieceTokenizer",
+ "keras_hub.tokenizers.WordPieceTokenizer.tokenize",
+ "keras_hub.tokenizers.WordPieceTokenizer.detokenize",
+ "keras_hub.tokenizers.WordPieceTokenizer.get_vocabulary",
+ "keras_hub.tokenizers.WordPieceTokenizer.vocabulary_size",
+ "keras_hub.tokenizers.WordPieceTokenizer.token_to_id",
+ "keras_hub.tokenizers.WordPieceTokenizer.id_to_token",
+ ],
+ },
+ {
+ "path": "sentence_piece_tokenizer",
+ "title": "SentencePieceTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.SentencePieceTokenizer",
+ "keras_hub.tokenizers.SentencePieceTokenizer.tokenize",
+ "keras_hub.tokenizers.SentencePieceTokenizer.detokenize",
+ "keras_hub.tokenizers.SentencePieceTokenizer.get_vocabulary",
+ "keras_hub.tokenizers.SentencePieceTokenizer.vocabulary_size",
+ "keras_hub.tokenizers.SentencePieceTokenizer.token_to_id",
+ "keras_hub.tokenizers.SentencePieceTokenizer.id_to_token",
+ ],
+ },
+ {
+ "path": "byte_pair_tokenizer",
+ "title": "BytePairTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.BytePairTokenizer",
+ "keras_hub.tokenizers.BytePairTokenizer.tokenize",
+ "keras_hub.tokenizers.BytePairTokenizer.detokenize",
+ "keras_hub.tokenizers.BytePairTokenizer.get_vocabulary",
+ "keras_hub.tokenizers.BytePairTokenizer.vocabulary_size",
+ "keras_hub.tokenizers.BytePairTokenizer.token_to_id",
+ "keras_hub.tokenizers.BytePairTokenizer.id_to_token",
+ ],
+ },
+ {
+ "path": "byte_tokenizer",
+ "title": "ByteTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.ByteTokenizer",
+ "keras_hub.tokenizers.ByteTokenizer.tokenize",
+ "keras_hub.tokenizers.ByteTokenizer.detokenize",
+ "keras_hub.tokenizers.ByteTokenizer.get_vocabulary",
+ "keras_hub.tokenizers.ByteTokenizer.vocabulary_size",
+ "keras_hub.tokenizers.ByteTokenizer.token_to_id",
+ "keras_hub.tokenizers.ByteTokenizer.id_to_token",
+ ],
+ },
+ {
+ "path": "unicode_codepoint_tokenizer",
+ "title": "UnicodeCodepointTokenizer",
+ "generate": [
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.tokenize",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.detokenize",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.get_vocabulary",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.vocabulary_size",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.token_to_id",
+ "keras_hub.tokenizers.UnicodeCodepointTokenizer.id_to_token",
+ ],
+ },
+ {
+ "path": "compute_word_piece_vocabulary",
+ "title": "compute_word_piece_vocabulary function",
+ "generate": ["keras_hub.tokenizers.compute_word_piece_vocabulary"],
+ },
+ {
+ "path": "compute_sentence_piece_proto",
+ "title": "compute_sentence_piece_proto function",
+ "generate": ["keras_hub.tokenizers.compute_sentence_piece_proto"],
+ },
+ ],
+}
+
+PREPROCESSING_LAYERS_MASTER = {
+ "path": "preprocessing_layers/",
+ "title": "Preprocessing Layers",
+ "toc": True,
+ "children": [
+ {
+ "path": "audio_converter",
+ "title": "AudioConverter layer",
+ "generate": ["keras_hub.layers.AudioConverter"],
+ },
+ {
+ "path": "image_converter",
+ "title": "ImageConverter layer",
+ "generate": ["keras_hub.layers.ImageConverter"],
+ },
+ {
+ "path": "resizing_image_converter",
+ "title": "ResizingImageConverter layer",
+ "generate": ["keras_hub.layers.ResizingImageConverter"],
+ },
+ {
+ "path": "start_end_packer",
+ "title": "StartEndPacker layer",
+ "generate": ["keras_hub.layers.StartEndPacker"],
+ },
+ {
+ "path": "multi_segment_packer",
+ "title": "MultiSegmentPacker layer",
+ "generate": ["keras_hub.layers.MultiSegmentPacker"],
+ },
+ {
+ "path": "random_swap",
+ "title": "RandomSwap layer",
+ "generate": ["keras_hub.layers.RandomSwap"],
+ },
+ {
+ "path": "random_deletion",
+ "title": "RandomDeletion layer",
+ "generate": ["keras_hub.layers.RandomDeletion"],
+ },
+ {
+ "path": "masked_lm_mask_generator",
+ "title": "MaskedLMMaskGenerator layer",
+ "generate": ["keras_hub.layers.MaskedLMMaskGenerator"],
+ },
+ ],
+}
+
+MODELING_LAYERS_MASTER = {
+ "path": "modeling_layers/",
+ "title": "Modeling Layers",
+ "toc": True,
+ "children": [
+ {
+ "path": "transformer_encoder",
+ "title": "TransformerEncoder layer",
+ "generate": [
+ "keras_hub.layers.TransformerEncoder",
+ "keras_hub.layers.TransformerEncoder.call",
+ ],
+ },
+ {
+ "path": "transformer_decoder",
+ "title": "TransformerDecoder layer",
+ "generate": [
+ "keras_hub.layers.TransformerDecoder",
+ "keras_hub.layers.TransformerDecoder.call",
+ ],
+ },
+ {
+ "path": "fnet_encoder",
+ "title": "FNetEncoder layer",
+ "generate": ["keras_hub.layers.FNetEncoder"],
+ },
+ {
+ "path": "position_embedding",
+ "title": "PositionEmbedding layer",
+ "generate": ["keras_hub.layers.PositionEmbedding"],
+ },
+ {
+ "path": "rotary_embedding",
+ "title": "RotaryEmbedding layer",
+ "generate": ["keras_hub.layers.RotaryEmbedding"],
+ },
+ {
+ "path": "sine_position_encoding",
+ "title": "SinePositionEncoding layer",
+ "generate": ["keras_hub.layers.SinePositionEncoding"],
+ },
+ {
+ "path": "reversible_embedding",
+ "title": "ReversibleEmbedding layer",
+ "generate": ["keras_hub.layers.ReversibleEmbedding"],
+ },
+ {
+ "path": "token_and_position_embedding",
+ "title": "TokenAndPositionEmbedding layer",
+ "generate": ["keras_hub.layers.TokenAndPositionEmbedding"],
+ },
+ {
+ "path": "alibi_bias",
+ "title": "AlibiBias layer",
+ "generate": ["keras_hub.layers.AlibiBias"],
+ },
+ {
+ "path": "masked_lm_head",
+ "title": "MaskedLMHead layer",
+ "generate": ["keras_hub.layers.MaskedLMHead"],
+ },
+ {
+ "path": "cached_multi_head_attention",
+ "title": "CachedMultiHeadAttention layer",
+ "generate": ["keras_hub.layers.CachedMultiHeadAttention"],
+ },
+ ],
+}
+
+
+METRICS_MASTER = {
+ "path": "metrics/",
+ "title": "Metrics",
+ "toc": True,
+ "children": [
+ {
+ "path": "perplexity",
+ "title": "Perplexity metric",
+ "generate": ["keras_hub.metrics.Perplexity"],
+ },
+ ],
+}
+
+HUB_API_MASTER = {
+ "path": "keras_hub/",
+ "title": "KerasHub",
+ "toc": True,
+ "children": [
+ MODELS_MASTER,
+ BASE_CLASSES,
+ TOKENIZERS_MASTER,
+ PREPROCESSING_LAYERS_MASTER,
+ MODELING_LAYERS_MASTER,
+ SAMPLERS_MASTER,
+ METRICS_MASTER,
+ ],
+}
diff --git a/scripts/master.py b/scripts/master.py
index 8425fe70bc..9db79961a6 100644
--- a/scripts/master.py
+++ b/scripts/master.py
@@ -42,11 +42,15 @@
"path": "keras_tuner/",
"title": "KerasTuner: Hyperparameter Tuning",
},
+ {
+ "path": "keras_hub/",
+ "title": "KerasHub: Pretrained Models",
+ },
{
"path": "keras_cv/",
"title": "KerasCV: Computer Vision Workflows",
},
- {
+ {
"path": "keras_nlp/",
"title": "KerasNLP: Natural Language Workflows",
},
diff --git a/scripts/render_tags.py b/scripts/render_tags.py
index cfa58c08e1..a8533a1dd3 100644
--- a/scripts/render_tags.py
+++ b/scripts/render_tags.py
@@ -1,4 +1,4 @@
-"""Custom rendering code for the /api/{keras_nlp|keras_cv}/models page.
+"""Custom rendering code for the /api/{keras_hub|keras_cv}/models page.
The model metadata is pulled from the library, each preset has a
metadata dictionary as follows:
@@ -55,17 +55,17 @@ def format_path(metadata):
def is_base_class(symbol):
- import keras_nlp
+ import keras_hub
return symbol in (
- keras_nlp.models.Backbone,
- keras_nlp.models.Tokenizer,
- keras_nlp.models.Preprocessor,
- keras_nlp.models.Task,
- keras_nlp.models.Classifier,
- keras_nlp.models.CausalLM,
- keras_nlp.models.MaskedLM,
- keras_nlp.models.Seq2SeqLM,
+ keras_hub.models.Backbone,
+ keras_hub.models.Tokenizer,
+ keras_hub.models.Preprocessor,
+ keras_hub.models.Task,
+ keras_hub.models.Classifier,
+ keras_hub.models.CausalLM,
+ keras_hub.models.MaskedLM,
+ keras_hub.models.Seq2SeqLM,
)
@@ -83,17 +83,12 @@ def render_backbone_table(symbols):
continue
presets = symbol.presets
# Only keep the ones with pretrained weights for KerasCV Backbones.
- if issubclass(symbol, keras_cv.models.Backbone):
- presets = symbol.presets_with_weights
for preset in presets:
if preset in added_presets:
continue
else:
added_presets.add(preset)
metadata = presets[preset]["metadata"]
- # KerasCV backbones docs' URL has a "backbones/" path.
- if issubclass(symbol, keras_cv.models.Backbone) and "path" in metadata:
- metadata["path"] = "backbones/" + metadata["path"]
table += (
f"{preset} | "
f"{format_path(metadata)} | "
@@ -106,59 +101,6 @@ def render_backbone_table(symbols):
return table
-def render_classifier_table(symbols):
- """Renders the markdown table for classifier presets as a string."""
-
- table = TABLE_HEADER
-
- # Classifier presets
- for name, symbol in symbols:
- if "Classifier" not in name:
- continue
- for preset in symbol.presets:
- backbone_cls = symbol.backbone_cls
- if backbone_cls is not None and preset not in backbone_cls.presets:
- metadata = symbol.presets[preset]["metadata"]
- table += (
- f"{preset} | "
- f"{format_path(metadata)} | "
- f"{format_param_count(metadata)} | "
- f"{metadata['description']} \n"
- )
- return table
-
-
-def render_task_table(symbols):
- """Renders the markdown table for Task presets as a string."""
- table = TABLE_HEADER
-
- for name, symbol in symbols:
- if not inspect.isclass(symbol):
- continue
- if not issubclass(symbol, keras_cv.models.Task):
- continue
- for preset in symbol.presets:
- # Do not print all backbone presets for a task
- if (
- preset
- in keras_cv.src.models.backbones.backbone_presets.backbone_presets
- ):
- continue
- if preset not in symbol.presets_with_weights:
- continue
- # Only render the ones with pretrained_weights for KerasCV.
- metadata = symbol.presets_with_weights[preset]["metadata"]
- # KerasCV tasks docs' URL has a "tasks/" path.
- metadata["path"] = "tasks/" + metadata["path"]
- table += (
- f"{preset} | "
- f"{format_path(metadata)} | "
- f"{format_param_count(metadata)} | "
- f"{metadata['description']} \n"
- )
- return table
-
-
def render_table(symbol):
table = TABLE_HEADER_PER_MODEL
if is_base_class(symbol) or len(symbol.presets) == 0:
@@ -182,18 +124,10 @@ def render_table(symbol):
def render_tags(template, lib):
- """Replaces all custom KerasNLP/KerasCV tags with rendered content."""
+ """Replaces all custom KerasHub/KerasCV tags with rendered content."""
symbols = lib.models.__dict__.items()
if "{{backbone_presets_table}}" in template:
template = template.replace(
"{{backbone_presets_table}}", render_backbone_table(symbols)
)
- if "{{classifier_presets_table}}" in template:
- template = template.replace(
- "{{classifier_presets_table}}", render_classifier_table(symbols)
- )
- if "{{task_presets_table}}" in template:
- template = template.replace(
- "{{task_presets_table}}", render_task_table(symbols)
- )
return template
diff --git a/templates/api/keras_hub/index.md b/templates/api/keras_hub/index.md
new file mode 100644
index 0000000000..faa0a651f0
--- /dev/null
+++ b/templates/api/keras_hub/index.md
@@ -0,0 +1,9 @@
+# KerasHub
+
+KerasHub is a toolbox of modular building blocks ranging from pretrained
+state-of-the-art models, to low-level Transformer Encoder layers. For an
+introduction to the library see the [KerasHub home page](/keras_hub). For a
+high-level introduction to the API see our
+[getting started guide](/guides/keras_hub/getting_started/).
+
+{{toc}}
diff --git a/templates/api/keras_hub/layers/index.md b/templates/api/keras_hub/layers/index.md
new file mode 100644
index 0000000000..9db5473315
--- /dev/null
+++ b/templates/api/keras_hub/layers/index.md
@@ -0,0 +1,8 @@
+# KerasHub Layers
+
+KerasHub layers are `keras.Layer` subclasses for NLP-specific use cases.
+
+These layers are building blocks for common NLP model architectures
+(e.g. Transformers).
+
+{{toc}}
diff --git a/templates/api/keras_hub/metrics/index.md b/templates/api/keras_hub/metrics/index.md
new file mode 100644
index 0000000000..b9b37b27f4
--- /dev/null
+++ b/templates/api/keras_hub/metrics/index.md
@@ -0,0 +1,5 @@
+# KerasHub Metrics
+
+KerasHub metrics are `keras.Metric` subclasses for NLP-specific use cases.
+
+{{toc}}
diff --git a/templates/api/keras_hub/models/bert/index.md b/templates/api/keras_hub/models/bert/index.md
new file mode 100644
index 0000000000..2871f5edad
--- /dev/null
+++ b/templates/api/keras_hub/models/bert/index.md
@@ -0,0 +1,9 @@
+# BERT
+
+Models, tokenizers, and preprocessing layers for BERT,
+as described in ["BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"](https://arxiv.org/abs/1810.04805).
+
+For a full list of available **presets**, see the
+[models page](/api/keras_hub/models).
+
+{{toc}}
diff --git a/templates/api/keras_hub/models/distil_bert/index.md b/templates/api/keras_hub/models/distil_bert/index.md
new file mode 100644
index 0000000000..095e6a3bb8
--- /dev/null
+++ b/templates/api/keras_hub/models/distil_bert/index.md
@@ -0,0 +1,9 @@
+# DistilBERT
+
+Models, tokenizers, and preprocessing layers for DistilBERT,
+as described in ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://arxiv.org/abs/1910.01108).
+
+For a full list of available **presets**, see the
+[models page](/api/keras_hub/models).
+
+{{toc}}
diff --git a/templates/api/keras_hub/models/index.md b/templates/api/keras_hub/models/index.md
new file mode 100644
index 0000000000..3982cc3832
--- /dev/null
+++ b/templates/api/keras_hub/models/index.md
@@ -0,0 +1,34 @@
+# KerasHub Models
+
+KerasHub contains end-to-end implementations of popular model architectures.
+These models can be created in two ways:
+
+- Through the `from_preset()` constructor, which instantiates an object with
+ a pre-trained configurations, vocabularies, and (optionally) weights.
+- Through custom configuration controlled by the user.
+
+Below, we list all presets available in the library. For more detailed usage,
+browse the docstring for a particular class. For an in depth introduction
+to our API, see the [getting started guide](/guides/keras_hub/getting_started/).
+
+## Presets
+
+The following preset names correspond to a config and weights for a pretrained
+model. Any task, preprocessor, backbone or tokenizer `from_preset()` can be used
+to create a model from the saved preset.
+
+```python
+backbone = keras_hub.models.Backbone.from_preset("bert_base_en")
+tokenizer = keras_hub.models.Tokenizer.from_preset("bert_base_en")
+classifier = keras_hub.models.TextClassifier.from_preset("bert_base_en", num_classes=2)
+preprocessor = keras_hub.models.TextClassifierPreprocessor.from_preset("bert_base_en")
+```
+
+{{backbone_presets_table}}
+
+**Note**: The links provided will lead to the model card or to the official README,
+if no model card has been provided by the author.
+
+## API Documentation
+
+{{toc}}
diff --git a/templates/api/keras_hub/models/roberta/index.md b/templates/api/keras_hub/models/roberta/index.md
new file mode 100644
index 0000000000..de765df2c0
--- /dev/null
+++ b/templates/api/keras_hub/models/roberta/index.md
@@ -0,0 +1,9 @@
+# RoBERTa
+
+Models, tokenizers, and preprocessing layers for RoBERTa,
+as described in ["RoBERTa: A Robustly Optimized BERT Pretraining Approach"](https://arxiv.org/abs/1907.11692).
+
+For a full list of available **presets**, see the
+[models page](/api/keras_hub/models).
+
+{{toc}}
diff --git a/templates/api/keras_hub/models/xlm_roberta/index.md b/templates/api/keras_hub/models/xlm_roberta/index.md
new file mode 100644
index 0000000000..e9cc86facc
--- /dev/null
+++ b/templates/api/keras_hub/models/xlm_roberta/index.md
@@ -0,0 +1,9 @@
+# XLM-RoBERTa
+
+Models, tokenizers, and preprocessing layers for XLM-Roberta,
+as described in ["Unsupervised Cross-lingual Representation Learning at Scale"](https://arxiv.org/abs/1911.02116).
+
+For a full list of available **presets**, see the
+[models page](/api/keras_hub/models).
+
+{{toc}}
diff --git a/templates/api/keras_hub/tokenizers/index.md b/templates/api/keras_hub/tokenizers/index.md
new file mode 100644
index 0000000000..44e037619b
--- /dev/null
+++ b/templates/api/keras_hub/tokenizers/index.md
@@ -0,0 +1,11 @@
+# KerasHub Tokenizers
+
+Tokenizers convert raw string input into integer input suitable for a Keras `Embedding` layer.
+They can also convert back from predicted integer sequences to raw string output.
+
+All tokenizers subclass `keras_hub.tokenizers.Tokenizer`, which in turn
+subclasses `keras.layers.Layer`. Tokenizers should generally be applied inside a
+[tf.data.Dataset.map](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map)
+for training, and can be included inside a `keras.Model` for inference.
+
+{{toc}}
diff --git a/templates/api/keras_hub/utils/index.md b/templates/api/keras_hub/utils/index.md
new file mode 100644
index 0000000000..b73489484c
--- /dev/null
+++ b/templates/api/keras_hub/utils/index.md
@@ -0,0 +1,6 @@
+# KerasHub Utils
+
+Standalone utilitiy methods for KerasHub, including functions for generating
+sequences of text with a model.
+
+{{toc}}
diff --git a/templates/getting_started/benchmarks.md b/templates/getting_started/benchmarks.md
index 0e1be1848b..0fcee3f563 100644
--- a/templates/getting_started/benchmarks.md
+++ b/templates/getting_started/benchmarks.md
@@ -21,7 +21,7 @@ selections.
We are not measuring the best possible performance achievable by each framework,
but the out-of-the-box performance of common user workflows. With this goal in
-mind, we leveraged pre-existing implementations from KerasCV and KerasNLP for
+mind, we leveraged pre-existing implementations from KerasCV and KerasHub for
the Keras versions of the models.
## Hardware
@@ -77,7 +77,7 @@ better.
| **Mistral
(generate)** | 1 | NA | 743.28 | **679.30** | 11,054.67* | **679.30** |
\* _LLM inference with the PyTorch backend is abnormally slow at this time
-because KerasNLP uses static sequence padding, unlike HuggingFace. This will be
+because KerasHub uses static sequence padding, unlike HuggingFace. This will be
addressed soon._
## Discussion
diff --git a/templates/getting_started/ecosystem.md b/templates/getting_started/ecosystem.md
index 6b2e6454e3..f24cc655fc 100644
--- a/templates/getting_started/ecosystem.md
+++ b/templates/getting_started/ecosystem.md
@@ -13,11 +13,11 @@ KerasTuner is an easy-to-use, scalable hyperparameter optimization framework tha
---
-## KerasNLP
+## KerasHub
-[KerasNLP Documentation](/keras_nlp/) - [KerasNLP GitHub repository](https://github.com/keras-team/keras-nlp)
+[KerasHub Documentation](/keras_hub/) - [KerasHub GitHub repository](https://github.com/keras-team/keras-hub)
-KerasNLP is a natural language processing library that supports users through
+KerasHub is a natural language processing library that supports users through
their entire development cycle. Our workflows are built from modular components
that have state-of-the-art preset weights and architectures when used
out-of-the-box and are easily customizable when more control is needed.
diff --git a/templates/getting_started/faq.md b/templates/getting_started/faq.md
index b948724cc1..d38f8e846e 100644
--- a/templates/getting_started/faq.md
+++ b/templates/getting_started/faq.md
@@ -748,7 +748,7 @@ intermediate_output = intermediate_layer_model(data)
### How can I use pre-trained models in Keras?
You could leverage the [models available in `keras.applications`](/api/applications/),
-or the models available in [KerasCV](/keras_cv/) and [KerasNLP](/keras_nlp/).
+or the models available in [KerasCV](/keras_cv/) and [KerasHub](/keras_hub/).
---
diff --git a/templates/getting_started/index.md b/templates/getting_started/index.md
index 0b6c03ff72..420dc2dfc4 100644
--- a/templates/getting_started/index.md
+++ b/templates/getting_started/index.md
@@ -40,13 +40,13 @@ To use Keras 3, you will also need to install a backend framework -- either JAX,
If you install TensorFlow 2.15, you should reinstall Keras 3 afterwards. The cause is that `tensorflow==2.15` will overwrite your Keras installation with `keras==2.15`.
This step is not necessary for TensorFlow versions 2.16 onwards as starting in TensorFlow 2.16, it will install Keras 3 by default.
-### Installing KerasCV and KerasNLP
+### Installing KerasCV and KerasHub
-KerasCV and KerasNLP can be installed via pip:
+KerasCV and KerasHub can be installed via pip:
```
pip install --upgrade keras-cv
-pip install --upgrade keras-nlp
+pip install --upgrade keras-hub
pip install --upgrade keras
```
diff --git a/templates/guides/keras_hub/getting_started.md b/templates/guides/keras_hub/getting_started.md
new file mode 100644
index 0000000000..51afbb54ac
--- /dev/null
+++ b/templates/guides/keras_hub/getting_started.md
@@ -0,0 +1,1065 @@
+# Getting Started with KerasHub
+
+**Author:** [Jonathan Bischof](https://github.com/jbischof)
+**Date created:** 2022/12/15
+**Last modified:** 2023/07/01
+**Description:** An introduction to the KerasHub API.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_hub/getting_started.ipynb) •
[**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_hub/getting_started.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_hub/getting_started.py)
+
+
+
+---
+## Introduction
+
+KerasHub is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed.
+
+This library is an extension of the core Keras API; all high-level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasHub.
+
+KerasHub uses Keras 3 to work with any of TensorFlow, Pytorch and Jax. In the
+guide below, we will use the `jax` backend for training our models, and
+[tf.data](https://www.tensorflow.org/guide/data) for efficiently running our
+input preprocessing. But feel free to mix things up! This guide runs in
+TensorFlow or PyTorch backends with zero changes, simply update the
+`KERAS_BACKEND` below.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide, we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+
[**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_hub/getting_started.py)
+
+
+
+---
+## Introduction
+
+KerasHub is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed.
+
+This library is an extension of the core Keras API; all high-level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasHub.
+
+KerasHub uses Keras 3 to work with any of TensorFlow, Pytorch and Jax. In the
+guide below, we will use the `jax` backend for training our models, and
+[tf.data](https://www.tensorflow.org/guide/data) for efficiently running our
+input preprocessing. But feel free to mix things up! This guide runs in
+TensorFlow or PyTorch backends with zero changes, simply update the
+`KERAS_BACKEND` below.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide, we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+ +
+
+```python
+!pip install -q --upgrade keras-hub
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+import keras_hub
+import keras
+
+# Use mixed precision to speed up all training in this guide.
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+
+
+```python
+!pip install -q --upgrade keras-hub
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+import keras_hub
+import keras
+
+# Use mixed precision to speed up all training in this guide.
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+```
+
+
+```
+
+---
+## API quickstart
+
+Our highest level API is `keras_hub.models`. These symbols cover the complete user
+journey of converting strings to tokens, tokens to dense features, and dense features to
+task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following
+modules:
+
+* **Tokenizer**: `keras_hub.models.XXTokenizer`
+ * **What it does**: Converts strings to sequences of token ids.
+ * **Why it's important**: The raw bytes of a string are too high dimensional to be useful
+ features so we first map them to a small number of tokens, for example `"The quick brown
+ fox"` to `["the", "qu", "##ick", "br", "##own", "fox"]`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Preprocessor**: `keras_hub.models.XXPreprocessor`
+ * **What it does**: Converts strings to a dictionary of preprocessed tensors consumed by
+ the backbone, starting with tokenization.
+ * **Why it's important**: Each model uses special tokens and extra tensors to understand
+ the input such as delimiting input segments and identifying padding tokens. Padding each
+ sequence to the same length improves computational efficiency.
+ * **Has a**: `XXTokenizer`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Backbone**: `keras_hub.models.XXBackbone`
+ * **What it does**: Converts preprocessed tensors to dense features. *Does not handle
+ strings; call the preprocessor first.*
+ * **Why it's important**: The backbone distills the input tokens into dense features that
+ can be used in downstream tasks. It is generally pretrained on a language modeling task
+ using massive amounts of unlabeled data. Transferring this information to a new task is a
+ major breakthrough in modern NLP.
+ * **Inherits from**: `keras.Model`.
+* **Task**: e.g., `keras_hub.models.XXClassifier`
+ * **What it does**: Converts strings to task-specific output (e.g., classification
+ probabilities).
+ * **Why it's important**: Task models combine string preprocessing and the backbone model
+ with task-specific `Layers` to solve a problem such as sentence classification, token
+ classification, or text generation. The additional `Layers` must be fine-tuned on labeled
+ data.
+ * **Has a**: `XXBackbone` and `XXPreprocessor`.
+ * **Inherits from**: `keras.Model`.
+
+Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):
+
+ +
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+
+---
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+
+
+```python
+!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+!tar -xf aclImdb_v1.tar.gz
+!# Remove unsupervised examples
+!rm -r aclImdb/train/unsup
+```
+
+```python
+BATCH_SIZE = 16
+imdb_train = keras.utils.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = keras.utils.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+```
+
+
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+
+---
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+
+
+```python
+!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+!tar -xf aclImdb_v1.tar.gz
+!# Remove unsupervised examples
+!rm -r aclImdb/train/unsup
+```
+
+```python
+BATCH_SIZE = 16
+imdb_train = keras.utils.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = keras.utils.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+```
+
+```
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+100 80.2M 100 80.2M 0 0 88.0M 0 --:--:-- --:--:-- --:--:-- 87.9M
+
+Found 25000 files belonging to 2 classes.
+Found 25000 files belonging to 2 classes.
+(, )
+
+```
+
+---
+## Inference with a pretrained classifier
+
+ +
+The highest level module in KerasHub is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_hub.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is
+[negative, positive] for binary classification.
+
+
+```python
+classifier = keras_hub.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-hub!"])
+```
+
+
+
+The highest level module in KerasHub is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_hub.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is
+[negative, positive] for binary classification.
+
+
+```python
+classifier = keras_hub.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-hub!"])
+```
+
+
+```
+ 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 689ms/step
+
+array([[-1.539, 1.543]], dtype=float16)
+
+```
+
+All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with
+preset preprocessing, architecture and weights. This means that we can pass raw strings
+in any format accepted by a `keras.Model` and get output specific to our task.
+
+This particular **preset** is a `"bert_tiny_uncased_en"` **backbone** fine-tuned on
+`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
+the `tiny` architecture for demo purposes, but larger models are recommended for SoTA
+performance. For all the task-specific presets available for `BertClassifier`, see
+our keras.io [models page](https://keras.io/api/keras_hub/models/).
+
+Let's evaluate our classifier on the IMDB dataset. You will note we don't need to
+call `keras.Model.compile` here. All **task** models like `BertClassifier` ship with
+compilation defaults, meaning we can just call `keras.Model.evaluate` directly. You
+can always call compile as normal to override these defaults (e.g. to add new metrics).
+
+The output below is [loss, accuracy],
+
+
+```python
+classifier.evaluate(imdb_test)
+```
+
+
+```
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - loss: 0.4610 - sparse_categorical_accuracy: 0.7882
+
+[0.4630218744277954, 0.783519983291626]
+
+```
+
+Our result is 78% accuracy without training anything. Not bad!
+
+---
+## Fine tuning a pretrained BERT backbone
+
+ +
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/).
+
+To train your classifier, use `keras.Model.fit` as with any other
+`keras.Model`. As with our inference example, we can rely on the compilation
+defaults for the **task** and skip `keras.Model.compile`. As preprocessing is
+included, we again pass the raw data.
+
+
+```python
+classifier = keras_hub.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+```
+
+
+
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/).
+
+To train your classifier, use `keras.Model.fit` as with any other
+`keras.Model`. As with our inference example, we can rely on the compilation
+defaults for the **task** and skip `keras.Model.compile`. As preprocessing is
+included, we again pass the raw data.
+
+
+```python
+classifier = keras_hub.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+```
+
+
+```
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 16s 9ms/step - loss: 0.5202 - sparse_categorical_accuracy: 0.7281 - val_loss: 0.3254 - val_sparse_categorical_accuracy: 0.8621
+
+
+
+```
+
+Here we see a significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
+training even though the IMDB dataset is much smaller than `sst2`.
+
+---
+## Fine tuning with user-controlled preprocessing
+ +
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** we can use `tf.data` for preprocessing while running on the
+Jax or PyTorch backend. The input dataset will automatically be converted to
+backend native tensor types during fit. In fact, given the efficiency of `tf.data`
+for running preprocessing, this is good practice on all backends.
+
+
+```python
+import tensorflow as tf
+
+preprocessor = keras_hub.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+# Apply the preprocessor to every sample of train and test data using `map()`.
+# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see
+# https://www.tensorflow.org/guide/data_performance for details.
+
+# Note: only call `cache()` if you training data fits in CPU memory!
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_hub.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased", preprocessor=None, num_classes=2
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+```
+
+
+
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** we can use `tf.data` for preprocessing while running on the
+Jax or PyTorch backend. The input dataset will automatically be converted to
+backend native tensor types during fit. In fact, given the efficiency of `tf.data`
+for running preprocessing, this is good practice on all backends.
+
+
+```python
+import tensorflow as tf
+
+preprocessor = keras_hub.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+# Apply the preprocessor to every sample of train and test data using `map()`.
+# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see
+# https://www.tensorflow.org/guide/data_performance for details.
+
+# Note: only call `cache()` if you training data fits in CPU memory!
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_hub.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased", preprocessor=None, num_classes=2
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - loss: 0.5194 - sparse_categorical_accuracy: 0.7272 - val_loss: 0.3032 - val_sparse_categorical_accuracy: 0.8728
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2871 - sparse_categorical_accuracy: 0.8805 - val_loss: 0.2809 - val_sparse_categorical_accuracy: 0.8818
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2134 - sparse_categorical_accuracy: 0.9178 - val_loss: 0.3043 - val_sparse_categorical_accuracy: 0.8790
+
+
+
+```
+
+After three epochs, our validation accuracy has only increased to 0.88. This is both a
+function of the small size of our dataset and our model. To exceed 90% accuracy, try
+larger **presets** such as `"bert_base_en_uncased"`. For all the **backbone** presets
+available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/).
+
+### Custom preprocessing
+
+In cases where custom preprocessing is required, we offer direct access to the
+`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`
+constructor to get the vocabulary matching pretraining.
+
+**Note:** `BertTokenizer` does not pad sequences by default, so the output is
+ragged (each sequence has varying length). The `MultiSegmentPacker` below
+handles padding these ragged sequences to dense tensor types (e.g. `tf.Tensor`
+or `torch.Tensor`).
+
+
+```python
+tokenizer = keras_hub.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
+tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
+
+# Write your own packer or use one of our `Layers`
+packer = keras_hub.layers.MultiSegmentPacker(
+ start_value=tokenizer.cls_token_id,
+ end_value=tokenizer.sep_token_id,
+ # Note: This cannot be longer than the preset's `sequence_length`, and there
+ # is no check for a custom preprocessor!
+ sequence_length=64,
+)
+
+
+# This function that takes a text sample `x` and its
+# corresponding label `y` as input and converts the
+# text into a format suitable for input into a BERT model.
+def preprocessor(x, y):
+ token_ids, segment_ids = packer(tokenizer(x))
+ x = {
+ "token_ids": token_ids,
+ "segment_ids": segment_ids,
+ "padding_mask": token_ids != 0,
+ }
+ return x, y
+
+
+imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+
+# Preprocessed example
+print(imdb_train_preprocessed.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': }, )
+
+```
+
+---
+## Fine tuning with a custom model
+
+
+For more advanced applications, an appropriate **task** `Model` may not be available. In
+this case, we provide direct access to the **backbone** `Model`, which has its own
+`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can
+be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).
+
+A **backbone** `Model` does not include automatic preprocessing but can be paired with a
+matching **preprocessor** using the same **preset** as shown in the previous workflow.
+
+In this workflow, we experiment with freezing our backbone model and adding two trainable
+transformer layers to adapt to the new input.
+
+**Note**: We can ignore the warning about gradients for the `pooled_dense` layer because
+we are using BERT's sequence output.
+
+
+```python
+preprocessor = keras_hub.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
+backbone = keras_hub.models.BertBackbone.from_preset("bert_tiny_en_uncased")
+
+imdb_train_preprocessed = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_preprocessed = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+backbone.trainable = False
+inputs = backbone.input
+sequence = backbone(inputs)["sequence_output"]
+for _ in range(2):
+ sequence = keras_hub.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=512,
+ dropout=0.1,
+ )(sequence)
+# Use [CLS] token output to classify
+outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
+
+model = keras.Model(inputs, outputs)
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(5e-5),
+ metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+model.summary()
+model.fit(
+ imdb_train_preprocessed,
+ validation_data=imdb_test_preprocessed,
+ epochs=3,
+)
+```
+
+
+Model: "functional_1"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
+┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
+│ padding_mask │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ segment_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ token_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ bert_backbone_3 │ [(None, 128), │ 4,385,… │ padding_mask[0][0], │
+│ (BertBackbone) │ (None, None, │ │ segment_ids[0][0], │
+│ │ 128)] │ │ token_ids[0][0] │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ transformer_encoder │ (None, None, 128) │ 198,272 │ bert_backbone_3[0][… │
+│ (TransformerEncode… │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │
+│ (TransformerEncode… │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ get_item_4 │ (None, 128) │ 0 │ transformer_encoder… │
+│ (GetItem) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ dense (Dense) │ (None, 2) │ 258 │ get_item_4[0][0] │
+└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
+
+
+
+
+
+ Total params: 4,782,722 (18.24 MB)
+
+
+
+
+
+ Trainable params: 396,802 (1.51 MB)
+
+
+
+
+
+ Non-trainable params: 4,385,920 (16.73 MB)
+
+
+
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 17s 10ms/step - loss: 0.6208 - sparse_categorical_accuracy: 0.6612 - val_loss: 0.6119 - val_sparse_categorical_accuracy: 0.6758
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.5324 - sparse_categorical_accuracy: 0.7347 - val_loss: 0.5484 - val_sparse_categorical_accuracy: 0.7320
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.4735 - sparse_categorical_accuracy: 0.7723 - val_loss: 0.4874 - val_sparse_categorical_accuracy: 0.7742
+
+
+
+```
+
+This model achieves reasonable accuracy despite having only 10% of the trainable parameters
+of our `BertClassifier` model. Each training step takes about 1/3 of the time---even
+accounting for cached preprocessing.
+
+---
+## Pretraining a backbone model
+ +
+Do you have access to large unlabeled datasets in your domain? Are they around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasHub library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e
+[Transformer pretraining](https://keras.io/guides/keras_hub/transformer_pretraining/#pretraining)
+for step-by-step details on how to replicate the original paper.
+
+### Preprocessing
+
+
+```python
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_hub.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_hub.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+```
+
+
+
+Do you have access to large unlabeled datasets in your domain? Are they around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasHub library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e
+[Transformer pretraining](https://keras.io/guides/keras_hub/transformer_pretraining/#pretraining)
+for step-by-step details on how to replicate the original paper.
+
+### Preprocessing
+
+
+```python
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_hub.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_hub.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': , 'mask_positions': }, , )
+
+```
+
+### Pretraining model
+
+
+```python
+# BERT backbone
+backbone = keras_hub.models.BertBackbone(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ num_layers=2,
+ num_heads=2,
+ hidden_dim=128,
+ intermediate_dim=512,
+)
+
+# Language modeling head
+mlm_head = keras_hub.layers.MaskedLMHead(
+ token_embedding=backbone.token_embedding,
+)
+
+inputs = {
+ "token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
+ "segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
+ "padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
+ "mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
+}
+
+# Encoded token sequence
+sequence = backbone(inputs)["sequence_output"]
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.summary()
+pretraining_model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
+ weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+
+# Pretrain on IMDB dataset
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=3, # Increase to 6 for higher accuracy
+)
+```
+
+
+Model: "functional_3"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
+┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
+│ mask_positions │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ padding_mask │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ segment_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ token_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ bert_backbone_4 │ [(None, 128), │ 4,385,… │ mask_positions[0][0… │
+│ (BertBackbone) │ (None, None, │ │ padding_mask[0][0], │
+│ │ 128)] │ │ segment_ids[0][0], │
+│ │ │ │ token_ids[0][0] │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ masked_lm_head │ (None, None, │ 3,954,… │ bert_backbone_4[0][… │
+│ (MaskedLMHead) │ 30522) │ │ mask_positions[0][0] │
+└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
+
+
+
+
+
+ Total params: 4,433,210 (16.91 MB)
+
+
+
+
+
+ Trainable params: 4,433,210 (16.91 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - loss: 5.7032 - sparse_categorical_accuracy: 0.0566 - val_loss: 5.0685 - val_sparse_categorical_accuracy: 0.1044
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 5.0701 - sparse_categorical_accuracy: 0.1096 - val_loss: 4.9363 - val_sparse_categorical_accuracy: 0.1239
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 4.9607 - sparse_categorical_accuracy: 0.1240 - val_loss: 4.7913 - val_sparse_categorical_accuracy: 0.1417
+
+
+
+```
+
+After pretraining save your `backbone` submodel to use in a new task!
+
+---
+## Build and train your own transformer from scratch
+
+
+Want to implement a novel transformer architecture? The KerasHub library offers all the
+low-level modules used to build SoTA architectures in our `models` API. This includes the
+`keras_hub.tokenizers` API which allows you to train your own subword tokenizer using
+`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.
+
+In this workflow, we train a custom tokenizer on the IMDB data and design a backbone with
+custom transformer architecture. For simplicity, we then train directly on the
+classification task. Interested in more details? We wrote an entire guide to pretraining
+and finetuning a custom transformer on
+[keras.io](https://keras.io/guides/keras_hub/transformer_pretraining/),
+
+### Train custom vocabulary from IMDB data
+
+
+```python
+vocab = keras_hub.tokenizers.compute_word_piece_vocabulary(
+ imdb_train.map(lambda x, y: x),
+ vocabulary_size=20_000,
+ lowercase=True,
+ strip_accents=True,
+ reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
+)
+tokenizer = keras_hub.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab,
+ lowercase=True,
+ strip_accents=True,
+ oov_token="[UNK]",
+)
+```
+
+### Preprocess data with a custom tokenizer
+
+
+```python
+packer = keras_hub.layers.StartEndPacker(
+ start_value=tokenizer.token_to_id("[START]"),
+ end_value=tokenizer.token_to_id("[END]"),
+ pad_value=tokenizer.token_to_id("[PAD]"),
+ sequence_length=512,
+)
+
+
+def preprocess(x, y):
+ token_ids = packer(tokenizer(x))
+ return token_ids, y
+
+
+imdb_preproc_train_ds = imdb_train.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+imdb_preproc_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+### Design a tiny transformer
+
+
+```python
+token_id_input = keras.Input(
+ shape=(None,),
+ dtype="int32",
+ name="token_ids",
+)
+outputs = keras_hub.layers.TokenAndPositionEmbedding(
+ vocabulary_size=len(vocab),
+ sequence_length=packer.sequence_length,
+ embedding_dim=64,
+)(token_id_input)
+outputs = keras_hub.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=128,
+ dropout=0.1,
+)(outputs)
+# Use "[START]" token to classify
+outputs = keras.layers.Dense(2)(outputs[:, 0, :])
+model = keras.Model(
+ inputs=token_id_input,
+ outputs=outputs,
+)
+
+model.summary()
+```
+
+
+Model: "functional_5"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃
+┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
+│ token_ids (InputLayer) │ (None, None) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ token_and_position_embedding │ (None, None, 64) │ 1,259,648 │
+│ (TokenAndPositionEmbedding) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_2 │ (None, None, 64) │ 33,472 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ get_item_6 (GetItem) │ (None, 64) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ dense_1 (Dense) │ (None, 2) │ 130 │
+└─────────────────────────────────┴───────────────────────────┴────────────┘
+
+
+
+
+
+ Total params: 1,293,250 (4.93 MB)
+
+
+
+
+
+ Trainable params: 1,293,250 (4.93 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+### Train the transformer directly on the classification objective
+
+
+```python
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(5e-5),
+ metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+model.fit(
+ imdb_preproc_train_ds,
+ validation_data=imdb_preproc_val_ds,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/step - loss: 0.7790 - sparse_categorical_accuracy: 0.5367 - val_loss: 0.4420 - val_sparse_categorical_accuracy: 0.8120
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.3654 - sparse_categorical_accuracy: 0.8443 - val_loss: 0.3046 - val_sparse_categorical_accuracy: 0.8752
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.2471 - sparse_categorical_accuracy: 0.9019 - val_loss: 0.3060 - val_sparse_categorical_accuracy: 0.8748
+
+
+
+```
+
+Excitingly, our custom classifier is similar to the performance of fine-tuning
+`"bert_tiny_en_uncased"`! To see the advantages of pretraining and exceed 90% accuracy we
+would need to use larger **presets** such as `"bert_base_en_uncased"`.
diff --git a/templates/guides/keras_hub/transformer_pretraining.md b/templates/guides/keras_hub/transformer_pretraining.md
new file mode 100644
index 0000000000..15e94ea486
--- /dev/null
+++ b/templates/guides/keras_hub/transformer_pretraining.md
@@ -0,0 +1,635 @@
+# Pretraining a Transformer from scratch with KerasHub
+
+**Author:** [Matthew Watson](https://github.com/mattdangerw/)
+**Date created:** 2022/04/18
+**Last modified:** 2023/07/15
+**Description:** Use KerasHub to train a Transformer model from scratch.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_hub/transformer_pretraining.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_hub/transformer_pretraining.py)
+
+
+
+KerasHub aims to make it easy to build state-of-the-art text processing models. In this
+guide, we will show how library components simplify pretraining and fine-tuning a
+Transformer model from scratch.
+
+This guide is broken into three parts:
+
+1. *Setup*, task definition, and establishing a baseline.
+2. *Pretraining* a Transformer model.
+3. *Fine-tuning* the Transformer model on our classification task.
+
+---
+## Setup
+
+The following guide uses Keras 3 to work in any of `tensorflow`, `jax` or
+`torch`. We select the `jax` backend below, which will give us a particularly
+fast train step below, but feel free to mix it up.
+
+
+```python
+!pip install -q --upgrade keras-hub
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+
+import keras_hub
+import tensorflow as tf
+import keras
+```
+
+```
+
+```
+
+Next up, we can download two datasets.
+
+- [SST-2](https://paperswithcode.com/sota/sentiment-analysis-on-sst-2-binary) a text
+classification dataset and our "end goal". This dataset is often used to benchmark
+language models.
+- [WikiText-103](https://paperswithcode.com/dataset/wikitext-103): A medium sized
+collection of featured articles from English Wikipedia, which we will use for
+pretraining.
+
+Finally, we will download a WordPiece vocabulary, to do sub-word tokenization later on in
+this guide.
+
+
+```python
+# Download pretraining data.
+keras.utils.get_file(
+ origin="https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip",
+ extract=True,
+)
+wiki_dir = os.path.expanduser("~/.keras/datasets/wikitext-103-raw/")
+
+# Download finetuning data.
+keras.utils.get_file(
+ origin="https://dl.fbaipublicfiles.com/glue/data/SST-2.zip",
+ extract=True,
+)
+sst_dir = os.path.expanduser("~/.keras/datasets/SST-2/")
+
+# Download vocabulary data.
+vocab_file = keras.utils.get_file(
+ origin="https://storage.googleapis.com/tensorflow/keras-hub/examples/bert/bert_vocab_uncased.txt",
+)
+```
+
+Next, we define some hyperparameters we will use during training.
+
+
+```python
+# Preprocessing params.
+PRETRAINING_BATCH_SIZE = 128
+FINETUNING_BATCH_SIZE = 32
+SEQ_LENGTH = 128
+MASK_RATE = 0.25
+PREDICTIONS_PER_SEQ = 32
+
+# Model params.
+NUM_LAYERS = 3
+MODEL_DIM = 256
+INTERMEDIATE_DIM = 512
+NUM_HEADS = 4
+DROPOUT = 0.1
+NORM_EPSILON = 1e-5
+
+# Training params.
+PRETRAINING_LEARNING_RATE = 5e-4
+PRETRAINING_EPOCHS = 8
+FINETUNING_LEARNING_RATE = 5e-5
+FINETUNING_EPOCHS = 3
+```
+
+### Load data
+
+We load our data with [tf.data](https://www.tensorflow.org/guide/data), which will allow
+us to define input pipelines for tokenizing and preprocessing text.
+
+
+```python
+# Load SST-2.
+sst_train_ds = tf.data.experimental.CsvDataset(
+ sst_dir + "train.tsv", [tf.string, tf.int32], header=True, field_delim="\t"
+).batch(FINETUNING_BATCH_SIZE)
+sst_val_ds = tf.data.experimental.CsvDataset(
+ sst_dir + "dev.tsv", [tf.string, tf.int32], header=True, field_delim="\t"
+).batch(FINETUNING_BATCH_SIZE)
+
+# Load wikitext-103 and filter out short lines.
+wiki_train_ds = (
+ tf.data.TextLineDataset(wiki_dir + "wiki.train.raw")
+ .filter(lambda x: tf.strings.length(x) > 100)
+ .batch(PRETRAINING_BATCH_SIZE)
+)
+wiki_val_ds = (
+ tf.data.TextLineDataset(wiki_dir + "wiki.valid.raw")
+ .filter(lambda x: tf.strings.length(x) > 100)
+ .batch(PRETRAINING_BATCH_SIZE)
+)
+
+# Take a peak at the sst-2 dataset.
+print(sst_train_ds.unbatch().batch(4).take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+You can see that our `SST-2` dataset contains relatively short snippets of movie review
+text. Our goal is to predict the sentiment of the snippet. A label of 1 indicates
+positive sentiment, and a label of 0 negative sentiment.
+
+### Establish a baseline
+
+As a first step, we will establish a baseline of good performance. We don't actually need
+KerasHub for this, we can just use core Keras layers.
+
+We will train a simple bag-of-words model, where we learn a positive or negative weight
+for each word in our vocabulary. A sample's score is simply the sum of the weights of all
+words that are present in the sample.
+
+
+```python
+# This layer will turn our input sentence into a list of 1s and 0s the same size
+# our vocabulary, indicating whether a word is present in absent.
+multi_hot_layer = keras.layers.TextVectorization(
+ max_tokens=4000, output_mode="multi_hot"
+)
+multi_hot_layer.adapt(sst_train_ds.map(lambda x, y: x))
+multi_hot_ds = sst_train_ds.map(lambda x, y: (multi_hot_layer(x), y))
+multi_hot_val_ds = sst_val_ds.map(lambda x, y: (multi_hot_layer(x), y))
+
+# We then learn a linear regression over that layer, and that's our entire
+# baseline model!
+
+inputs = keras.Input(shape=(4000,), dtype="int32")
+outputs = keras.layers.Dense(1, activation="sigmoid")(inputs)
+baseline_model = keras.Model(inputs, outputs)
+baseline_model.compile(loss="binary_crossentropy", metrics=["accuracy"])
+baseline_model.fit(multi_hot_ds, validation_data=multi_hot_val_ds, epochs=5)
+```
+
+
+```
+Epoch 1/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 2s 698us/step - accuracy: 0.6421 - loss: 0.6469 - val_accuracy: 0.7567 - val_loss: 0.5391
+Epoch 2/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 493us/step - accuracy: 0.7524 - loss: 0.5392 - val_accuracy: 0.7868 - val_loss: 0.4891
+Epoch 3/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 513us/step - accuracy: 0.7832 - loss: 0.4871 - val_accuracy: 0.7991 - val_loss: 0.4671
+Epoch 4/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 475us/step - accuracy: 0.7991 - loss: 0.4543 - val_accuracy: 0.8069 - val_loss: 0.4569
+Epoch 5/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 476us/step - accuracy: 0.8100 - loss: 0.4313 - val_accuracy: 0.8036 - val_loss: 0.4530
+
+
+
+```
+
+A bag-of-words approach can be a fast and surprisingly powerful, especially when input
+examples contain a large number of words. With shorter sequences, it can hit a
+performance ceiling.
+
+To do better, we would like to build a model that can evaluate words *in context*. Instead
+of evaluating each word in a void, we need to use the information contained in the
+*entire ordered sequence* of our input.
+
+This runs us into a problem. `SST-2` is very small dataset, and there's simply not enough
+example text to attempt to build a larger, more parameterized model that can learn on a
+sequence. We would quickly start to overfit and memorize our training set, without any
+increase in our ability to generalize to unseen examples.
+
+Enter **pretraining**, which will allow us to learn on a larger corpus, and transfer our
+knowledge to the `SST-2` task. And enter **KerasHub**, which will allow us to pretrain a
+particularly powerful model, the Transformer, with ease.
+
+---
+## Pretraining
+
+To beat our baseline, we will leverage the `WikiText103` dataset, an unlabeled
+collection of Wikipedia articles that is much bigger than `SST-2`.
+
+We are going to train a *transformer*, a highly expressive model which will learn
+to embed each word in our input as a low dimensional vector. Our wikipedia dataset has no
+labels, so we will use an unsupervised training objective called the *Masked Language
+Modeling* (MaskedLM) objective.
+
+Essentially, we will be playing a big game of "guess the missing word". For each input
+sample we will obscure 25% of our input data, and train our model to predict the parts we
+covered up.
+
+### Preprocess data for the MaskedLM task
+
+Our text preprocessing for the MaskedLM task will occur in two stages.
+
+1. Tokenize input text into integer sequences of token ids.
+2. Mask certain positions in our input to predict on.
+
+To tokenize, we can use a `keras_hub.tokenizers.Tokenizer` -- the KerasHub building block
+for transforming text into sequences of integer token ids.
+
+In particular, we will use `keras_hub.tokenizers.WordPieceTokenizer` which does
+*sub-word* tokenization. Sub-word tokenization is popular when training models on large
+text corpora. Essentially, it allows our model to learn from uncommon words, while not
+requiring a massive vocabulary of every word in our training set.
+
+The second thing we need to do is mask our input for the MaskedLM task. To do this, we can use
+`keras_hub.layers.MaskedLMMaskGenerator`, which will randomly select a set of tokens in each
+input and mask them out.
+
+The tokenizer and the masking layer can both be used inside a call to
+[tf.data.Dataset.map](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map).
+We can use `tf.data` to efficiently pre-compute each batch on the CPU, while our GPU or TPU
+works on training with the batch that came before. Because our masking layer will
+choose new words to mask each time, each epoch over our dataset will give us a totally
+new set of labels to train on.
+
+
+```python
+# Setting sequence_length will trim or pad the token outputs to shape
+# (batch_size, SEQ_LENGTH).
+tokenizer = keras_hub.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab_file,
+ sequence_length=SEQ_LENGTH,
+ lowercase=True,
+ strip_accents=True,
+)
+# Setting mask_selection_length will trim or pad the mask outputs to shape
+# (batch_size, PREDICTIONS_PER_SEQ).
+masker = keras_hub.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=MASK_RATE,
+ mask_selection_length=PREDICTIONS_PER_SEQ,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+)
+
+
+def preprocess(inputs):
+ inputs = tokenizer(inputs)
+ outputs = masker(inputs)
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": outputs["token_ids"],
+ "mask_positions": outputs["mask_positions"],
+ }
+ labels = outputs["mask_ids"]
+ weights = outputs["mask_weights"]
+ return features, labels, weights
+
+
+# We use prefetch() to pre-compute preprocessed batches on the fly on the CPU.
+pretrain_ds = wiki_train_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+pretrain_val_ds = wiki_val_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Preview a single input example.
+# The masks will change each time you run the cell.
+print(pretrain_val_ds.take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'mask_positions': }, , )
+
+```
+
+The above block sorts our dataset into a `(features, labels, weights)` tuple, which can be
+passed directly to `keras.Model.fit()`.
+
+We have two features:
+
+1. `"token_ids"`, where some tokens have been replaced with our mask token id.
+2. `"mask_positions"`, which keeps track of which tokens we masked out.
+
+Our labels are simply the ids we masked out.
+
+Because not all sequences will have the same number of masks, we also keep a
+`sample_weight` tensor, which removes padded labels from our loss function by giving them
+zero weight.
+
+### Create the Transformer encoder
+
+KerasHub provides all the building blocks to quickly build a Transformer encoder.
+
+We use `keras_hub.layers.TokenAndPositionEmbedding` to first embed our input token ids.
+This layer simultaneously learns two embeddings -- one for words in a sentence and another
+for integer positions in a sentence. The output embedding is simply the sum of the two.
+
+Then we can add a series of `keras_hub.layers.TransformerEncoder` layers. These are the
+bread and butter of the Transformer model, using an attention mechanism to attend to
+different parts of the input sentence, followed by a multi-layer perceptron block.
+
+The output of this model will be a encoded vector per input token id. Unlike the
+bag-of-words model we used as a baseline, this model will embed each token accounting for
+the context in which it appeared.
+
+
+```python
+inputs = keras.Input(shape=(SEQ_LENGTH,), dtype="int32")
+
+# Embed our tokens with a positional embedding.
+embedding_layer = keras_hub.layers.TokenAndPositionEmbedding(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ sequence_length=SEQ_LENGTH,
+ embedding_dim=MODEL_DIM,
+)
+outputs = embedding_layer(inputs)
+
+# Apply layer normalization and dropout to the embedding.
+outputs = keras.layers.LayerNormalization(epsilon=NORM_EPSILON)(outputs)
+outputs = keras.layers.Dropout(rate=DROPOUT)(outputs)
+
+# Add a number of encoder blocks
+for i in range(NUM_LAYERS):
+ outputs = keras_hub.layers.TransformerEncoder(
+ intermediate_dim=INTERMEDIATE_DIM,
+ num_heads=NUM_HEADS,
+ dropout=DROPOUT,
+ layer_norm_epsilon=NORM_EPSILON,
+ )(outputs)
+
+encoder_model = keras.Model(inputs, outputs)
+encoder_model.summary()
+```
+
+
+Model: "functional_3"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃
+┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
+│ input_layer_1 (InputLayer) │ (None, 128) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ token_and_position_embedding │ (None, 128, 256) │ 7,846,400 │
+│ (TokenAndPositionEmbedding) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ layer_normalization │ (None, 128, 256) │ 512 │
+│ (LayerNormalization) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ dropout (Dropout) │ (None, 128, 256) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_1 │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_2 │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+└─────────────────────────────────┴───────────────────────────┴────────────┘
+
+
+
+
+
+ Total params: 9,428,224 (287.73 MB)
+
+
+
+
+
+ Trainable params: 9,428,224 (287.73 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+### Pretrain the Transformer
+
+You can think of the `encoder_model` as it's own modular unit, it is the piece of our
+model that we are really interested in for our downstream task. However we still need to
+set up the encoder to train on the MaskedLM task; to do that we attach a
+`keras_hub.layers.MaskedLMHead`.
+
+This layer will take as one input the token encodings, and as another the positions we
+masked out in the original input. It will gather the token encodings we masked, and
+transform them back in predictions over our entire vocabulary.
+
+With that, we are ready to compile and run pretraining. If you are running this in a
+Colab, note that this will take about an hour. Training Transformer is famously compute
+intensive, so even this relatively small Transformer will take some time.
+
+
+```python
+# Create the pretraining model by attaching a masked language model head.
+inputs = {
+ "token_ids": keras.Input(shape=(SEQ_LENGTH,), dtype="int32", name="token_ids"),
+ "mask_positions": keras.Input(
+ shape=(PREDICTIONS_PER_SEQ,), dtype="int32", name="mask_positions"
+ ),
+}
+
+# Encode the tokens.
+encoded_tokens = encoder_model(inputs["token_ids"])
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = keras_hub.layers.MaskedLMHead(
+ token_embedding=embedding_layer.token_embedding,
+ activation="softmax",
+)(encoded_tokens, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.compile(
+ loss="sparse_categorical_crossentropy",
+ optimizer=keras.optimizers.AdamW(PRETRAINING_LEARNING_RATE),
+ weighted_metrics=["sparse_categorical_accuracy"],
+ jit_compile=True,
+)
+
+# Pretrain the model on our wiki text dataset.
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=PRETRAINING_EPOCHS,
+)
+
+# Save this base model for further finetuning.
+encoder_model.save("encoder_model.keras")
+```
+
+
+```
+Epoch 1/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 242s 41ms/step - loss: 5.4679 - sparse_categorical_accuracy: 0.1353 - val_loss: 3.4570 - val_sparse_categorical_accuracy: 0.3522
+Epoch 2/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 234s 40ms/step - loss: 3.6031 - sparse_categorical_accuracy: 0.3396 - val_loss: 3.0514 - val_sparse_categorical_accuracy: 0.4032
+Epoch 3/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 232s 40ms/step - loss: 3.2609 - sparse_categorical_accuracy: 0.3802 - val_loss: 2.8858 - val_sparse_categorical_accuracy: 0.4240
+Epoch 4/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 233s 40ms/step - loss: 3.1099 - sparse_categorical_accuracy: 0.3978 - val_loss: 2.7897 - val_sparse_categorical_accuracy: 0.4375
+Epoch 5/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 235s 40ms/step - loss: 3.0145 - sparse_categorical_accuracy: 0.4090 - val_loss: 2.7504 - val_sparse_categorical_accuracy: 0.4419
+Epoch 6/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 252s 43ms/step - loss: 2.9530 - sparse_categorical_accuracy: 0.4157 - val_loss: 2.6925 - val_sparse_categorical_accuracy: 0.4474
+Epoch 7/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 232s 40ms/step - loss: 2.9088 - sparse_categorical_accuracy: 0.4210 - val_loss: 2.6554 - val_sparse_categorical_accuracy: 0.4513
+Epoch 8/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 236s 40ms/step - loss: 2.8721 - sparse_categorical_accuracy: 0.4250 - val_loss: 2.6389 - val_sparse_categorical_accuracy: 0.4548
+
+```
+
+---
+## Fine-tuning
+
+After pretraining, we can now fine-tune our model on the `SST-2` dataset. We can
+leverage the ability of the encoder we build to predict on words in context to boost
+our performance on the downstream task.
+
+### Preprocess data for classification
+
+Preprocessing for fine-tuning is much simpler than for our pretraining MaskedLM task. We just
+tokenize our input sentences and we are ready for training!
+
+
+```python
+
+def preprocess(sentences, labels):
+ return tokenizer(sentences), labels
+
+
+# We use prefetch() to pre-compute preprocessed batches on the fly on our CPU.
+finetune_ds = sst_train_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+finetune_val_ds = sst_val_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Preview a single input example.
+print(finetune_val_ds.take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+### Fine-tune the Transformer
+
+To go from our encoded token output to a classification prediction, we need to attach
+another "head" to our Transformer model. We can afford to be simple here. We pool
+the encoded tokens together, and use a single dense layer to make a prediction.
+
+
+```python
+# Reload the encoder model from disk so we can restart fine-tuning from scratch.
+encoder_model = keras.models.load_model("encoder_model.keras", compile=False)
+
+# Take as input the tokenized input.
+inputs = keras.Input(shape=(SEQ_LENGTH,), dtype="int32")
+
+# Encode and pool the tokens.
+encoded_tokens = encoder_model(inputs)
+pooled_tokens = keras.layers.GlobalAveragePooling1D()(encoded_tokens[0])
+
+# Predict an output label.
+outputs = keras.layers.Dense(1, activation="sigmoid")(pooled_tokens)
+
+# Define and compile our fine-tuning model.
+finetuning_model = keras.Model(inputs, outputs)
+finetuning_model.compile(
+ loss="binary_crossentropy",
+ optimizer=keras.optimizers.AdamW(FINETUNING_LEARNING_RATE),
+ metrics=["accuracy"],
+)
+
+# Finetune the model for the SST-2 task.
+finetuning_model.fit(
+ finetune_ds,
+ validation_data=finetune_val_ds,
+ epochs=FINETUNING_EPOCHS,
+)
+```
+
+
+```
+Epoch 1/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 21s 9ms/step - accuracy: 0.7500 - loss: 0.4891 - val_accuracy: 0.8036 - val_loss: 0.4099
+Epoch 2/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 16s 8ms/step - accuracy: 0.8826 - loss: 0.2779 - val_accuracy: 0.8482 - val_loss: 0.3964
+Epoch 3/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 16s 8ms/step - accuracy: 0.9176 - loss: 0.2066 - val_accuracy: 0.8549 - val_loss: 0.4142
+
+
+
+```
+
+Pretraining was enough to boost our performance to 84%, and this is hardly the ceiling
+for Transformer models. You may have noticed during pretraining that our validation
+performance was still steadily increasing. Our model is still significantly undertrained.
+Training for more epochs, training a large Transformer, and training on more unlabeled
+text would all continue to boost performance significantly.
+
+One of the key goals of KerasHub is to provide a modular approach to NLP model building.
+We have shown one approach to building a Transformer here, but KerasHub supports an ever
+growing array of components for preprocessing text and building models. We hope it makes
+it easier to experiment on solutions to your natural language problems.
diff --git a/templates/guides/keras_hub/upload.md b/templates/guides/keras_hub/upload.md
new file mode 100644
index 0000000000..3817d354e9
--- /dev/null
+++ b/templates/guides/keras_hub/upload.md
@@ -0,0 +1,308 @@
+# Uploading Models with KerasHub
+
+**Author:** [Samaneh Saadat](https://github.com/SamanehSaadat/), [Matthew Watson](https://github.com/mattdangerw/)
+**Date created:** 2024/04/29
+**Last modified:** 2024/04/29
+**Description:** An introduction on how to upload a fine-tuned KerasHub model to model hubs.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_hub/upload.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_hub/upload.py)
+
+
+
+# Introduction
+
+Fine-tuning a machine learning model can yield impressive results for specific tasks.
+Uploading your fine-tuned model to a model hub allows you to share it with the broader community.
+By sharing your models, you'll enhance accessibility for other researchers and developers,
+making your contributions an integral part of the machine learning landscape.
+This can also streamline the integration of your model into real-world applications.
+
+This guide walks you through how to upload your fine-tuned models to popular model hubs such as
+[Kaggle Models](https://www.kaggle.com/models) and [Hugging Face Hub](https://huggingface.co/models).
+
+# Setup
+
+Let's start by installing and importing all the libraries we need. We use KerasHub for this guide.
+
+
+```python
+!pip install -q --upgrade keras-hub huggingface-hub kagglehub
+```
+
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax"
+
+import keras_hub
+
+```
+
+# Data
+
+We can use the IMDB reviews dataset for this guide. Let's load the dataset from `tensorflow_dataset`.
+
+
+```python
+import tensorflow_datasets as tfds
+
+imdb_train, imdb_test = tfds.load(
+ "imdb_reviews",
+ split=["train", "test"],
+ as_supervised=True,
+ batch_size=4,
+)
+```
+
+We only use a small subset of the training samples to make the guide run faster.
+However, if you need a higher quality model, consider using a larger number of training samples.
+
+
+```python
+imdb_train = imdb_train.take(100)
+```
+
+# Task Upload
+
+A `keras_hub.models.Task`, wraps a `keras_hub.models.Backbone` and a `keras_hub.models.Preprocessor` to create
+a model that can be directly used for training, fine-tuning, and prediction for a given text problem.
+In this section, we explain how to create a `Task`, fine-tune and upload it to a model hub.
+
+---
+## Load Model
+
+If you want to build a Causal LM based on a base model, simply call `keras_hub.models.CausalLM.from_preset`
+and pass a built-in preset identifier.
+
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset("gpt2_base_en")
+
+```
+
+
+```
+Downloading from https://www.kaggle.com/api/v1/models/keras/gpt2/keras/gpt2_base_en/2/download/task.json...
+
+Downloading from https://www.kaggle.com/api/v1/models/keras/gpt2/keras/gpt2_base_en/2/download/preprocessor.json...
+
+```
+
+---
+## Fine-tune Model
+
+After loading the model, you can call `.fit()` on the model to fine-tune it.
+Here, we fine-tune the model on the IMDB reviews which makes the model movie domain-specific.
+
+
+```python
+# Drop labels and keep the review text only for the Causal LM.
+imdb_train_reviews = imdb_train.map(lambda x, y: x)
+
+# Fine-tune the Causal LM.
+causal_lm.fit(imdb_train_reviews)
+```
+ 100/100 ━━━━━━━━━━━━━━━━━━━━ 151s 1s/step - loss: 1.0198 - sparse_categorical_accuracy: 0.3271
+
+---
+## Save the Model Locally
+
+To upload a model, you need to first save the model locally using `save_to_preset`.
+
+
+```python
+preset_dir = "./gpt2_imdb"
+causal_lm.save_to_preset(preset_dir)
+```
+
+Let's see the saved files.
+
+
+```python
+os.listdir(preset_dir)
+```
+
+
+
+
+
+```
+['preprocessor.json',
+ 'tokenizer.json',
+ 'task.json',
+ 'model.weights.h5',
+ 'config.json',
+ 'metadata.json',
+ 'assets']
+
+```
+
+### Load a Locally Saved Model
+
+A model that is saved to a local preset can be loaded using `from_preset`.
+What you save in, is what you get back out.
+
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset(preset_dir)
+```
+
+You can also load the `keras_hub.models.Backbone` and `keras_hub.models.Tokenizer` objects from this preset directory.
+Note that these objects are equivalent to `causal_lm.backbone` and `causal_lm.preprocessor.tokenizer` above.
+
+
+```python
+backbone = keras_hub.models.Backbone.from_preset(preset_dir)
+tokenizer = keras_hub.models.Tokenizer.from_preset(preset_dir)
+```
+
+---
+## Upload the Model to a Model Hub
+
+After saving a preset to a directory, this directory can be uploaded to a model hub such as Kaggle or Hugging Face directly from the KerasHub library.
+To upload the model to Kaggle, the URI must start with `kaggle://` and to upload to Hugging Face, it should start with `hf://`.
+
+### Upload to Kaggle
+
+To upload a model to Kaggle, first, we need to authenticate with Kaggle.
+This can in one of the following ways:
+1. Set environment variables `KAGGLE_USERNAME` and `KAGGLE_KEY`.
+2. Provide a local `~/.kaggle/kaggle.json`.
+3. Call `kagglehub.login()`.
+
+Let's make sure we are logged in before continuing.
+
+
+```python
+import kagglehub
+
+if "KAGGLE_USERNAME" not in os.environ or "KAGGLE_KEY" not in os.environ:
+ kagglehub.login()
+
+```
+
+To upload a model we can use `keras_hub.upload_preset(uri, preset_dir)` API where `uri` has the format of
+`kaggle:////Keras/` for uploading to Kaggle and `preset_dir` is the directory that the model is saved in.
+
+Running the following uploads the model that is saved in `preset_dir` to Kaggle:
+
+
+```python
+kaggle_username = kagglehub.whoami()["username"]
+kaggle_uri = f"kaggle://{kaggle_username}/gpt2/keras/gpt2_imdb"
+keras_hub.upload_preset(kaggle_uri, preset_dir)
+```
+
+
+```
+Upload successful: preprocessor.json (834B)
+Upload successful: tokenizer.json (322B)
+Upload successful: task.json (2KB)
+Upload successful: model.weights.h5 (475MB)
+Upload successful: config.json (431B)
+Upload successful: metadata.json (142B)
+Upload successful: merges.txt (446KB)
+Upload successful: vocabulary.json (1018KB)
+
+Your model instance version has been created.
+
+```
+
+### Upload to Hugging Face
+
+To upload a model to Hugging Face, first, we need to authenticate with Hugging Face.
+This can in one of the following ways:
+1. Set environment variables `HF_USERNAME` and `HF_TOKEN`.
+2. Call `huggingface_hub.notebook_login()`.
+
+Let's make sure we are logged in before coninuing.
+
+
+```python
+import huggingface_hub
+
+if "HF_USERNAME" not in os.environ or "HF_TOKEN" not in os.environ:
+ huggingface_hub.notebook_login()
+```
+
+`keras_hub.upload_preset(uri, preset_dir)` can be used to upload a model to Hugging Face if `uri` has the format of
+`kaggle:///`.
+
+Running the following uploads the model that is saved in `preset_dir` to Hugging Face:
+
+
+```python
+hf_username = huggingface_hub.whoami()["name"]
+hf_uri = f"hf://{hf_username}/gpt2_imdb"
+keras_hub.upload_preset(hf_uri, preset_dir)
+
+```
+
+---
+## Load a User Uploaded Model
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset(
+ f"kaggle://{kaggle_username}/gpt2/keras/gpt2_imdb"
+)
+```
+
+We can also load the model uploaded to Hugging Face by calling `from_preset`.
+
+```python
+causal_lm = keras_hub.models.CausalLM.from_preset(f"hf://{hf_username}/gpt2_imdb")
+```
+
+# Classifier Upload
+
+Uploading a classifier model is similar to Causal LM upload.
+To upload the fine-tuned model, first, the model should be saved to a local directory using `save_to_preset`
+API and then it can be uploaded via `keras_hub.upload_preset`.
+
+
+```python
+# Load the base model.
+classifier = keras_hub.models.Classifier.from_preset(
+ "bert_tiny_en_uncased", num_classes=2
+)
+
+# Fine-tune the classifier.
+classifier.fit(imdb_train)
+
+# Save the model to a local preset directory.
+preset_dir = "./bert_tiny_imdb"
+classifier.save_to_preset(preset_dir)
+
+# Upload to Kaggle.
+keras_hub.upload_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb", preset_dir
+)
+```
+ 100/100 ━━━━━━━━━━━━━━━━━━━━ 7s 31ms/step - loss: 0.6975 - sparse_categorical_accuracy: 0.5164
+
+
+
+```
+Upload successful: preprocessor.json (947B)
+Upload successful: tokenizer.json (461B)
+Upload successful: task.json (2KB)
+Upload successful: task.weights.h5 (50MB)
+Upload successful: model.weights.h5 (17MB)
+Upload successful: config.json (454B)
+Upload successful: metadata.json (140B)
+Upload successful: vocabulary.txt (226KB)
+
+Your model instance version has been created.
+```
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+classifier = keras_hub.models.Classifier.from_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb"
+)
+```
\ No newline at end of file
diff --git a/templates/guides/keras_nlp/getting_started.md b/templates/guides/keras_nlp/getting_started.md
new file mode 100644
index 0000000000..92da7dccd1
--- /dev/null
+++ b/templates/guides/keras_nlp/getting_started.md
@@ -0,0 +1,1065 @@
+# Getting Started with KerasNLP
+
+**Author:** [Jonathan Bischof](https://github.com/jbischof)
+**Date created:** 2022/12/15
+**Last modified:** 2023/07/01
+**Description:** An introduction to the KerasNLP API.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_nlp/getting_started.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_nlp/getting_started.py)
+
+
+
+---
+## Introduction
+
+KerasNLP is a natural language processing library that supports users through
+their entire development cycle. Our workflows are built from modular components
+that have state-of-the-art preset weights and architectures when used
+out-of-the-box and are easily customizable when more control is needed.
+
+This library is an extension of the core Keras API; all high-level modules are
+[`Layers`](/api/layers/) or [`Models`](/api/models/). If you are familiar with Keras,
+congratulations! You already understand most of KerasNLP.
+
+KerasNLP uses Keras 3 to work with any of TensorFlow, Pytorch and Jax. In the
+guide below, we will use the `jax` backend for training our models, and
+[tf.data](https://www.tensorflow.org/guide/data) for efficiently running our
+input preprocessing. But feel free to mix things up! This guide runs in
+TensorFlow or PyTorch backends with zero changes, simply update the
+`KERAS_BACKEND` below.
+
+This guide demonstrates our modular approach using a sentiment analysis example at six
+levels of complexity:
+
+* Inference with a pretrained classifier
+* Fine tuning a pretrained backbone
+* Fine tuning with user-controlled preprocessing
+* Fine tuning a custom model
+* Pretraining a backbone model
+* Build and train your own transformer from scratch
+
+Throughout our guide, we use Professor Keras, the official Keras mascot, as a visual
+reference for the complexity of the material:
+
+ +
+
+```python
+!pip install -q --upgrade keras-nlp
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+import keras_nlp
+import keras
+
+# Use mixed precision to speed up all training in this guide.
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+
+
+```python
+!pip install -q --upgrade keras-nlp
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+import keras_nlp
+import keras
+
+# Use mixed precision to speed up all training in this guide.
+keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+```
+
+
+```
+
+---
+## API quickstart
+
+Our highest level API is `keras_nlp.models`. These symbols cover the complete user
+journey of converting strings to tokens, tokens to dense features, and dense features to
+task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following
+modules:
+
+* **Tokenizer**: `keras_nlp.models.XXTokenizer`
+ * **What it does**: Converts strings to sequences of token ids.
+ * **Why it's important**: The raw bytes of a string are too high dimensional to be useful
+ features so we first map them to a small number of tokens, for example `"The quick brown
+ fox"` to `["the", "qu", "##ick", "br", "##own", "fox"]`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Preprocessor**: `keras_nlp.models.XXPreprocessor`
+ * **What it does**: Converts strings to a dictionary of preprocessed tensors consumed by
+ the backbone, starting with tokenization.
+ * **Why it's important**: Each model uses special tokens and extra tensors to understand
+ the input such as delimiting input segments and identifying padding tokens. Padding each
+ sequence to the same length improves computational efficiency.
+ * **Has a**: `XXTokenizer`.
+ * **Inherits from**: `keras.layers.Layer`.
+* **Backbone**: `keras_nlp.models.XXBackbone`
+ * **What it does**: Converts preprocessed tensors to dense features. *Does not handle
+ strings; call the preprocessor first.*
+ * **Why it's important**: The backbone distills the input tokens into dense features that
+ can be used in downstream tasks. It is generally pretrained on a language modeling task
+ using massive amounts of unlabeled data. Transferring this information to a new task is a
+ major breakthrough in modern NLP.
+ * **Inherits from**: `keras.Model`.
+* **Task**: e.g., `keras_nlp.models.XXClassifier`
+ * **What it does**: Converts strings to task-specific output (e.g., classification
+ probabilities).
+ * **Why it's important**: Task models combine string preprocessing and the backbone model
+ with task-specific `Layers` to solve a problem such as sentence classification, token
+ classification, or text generation. The additional `Layers` must be fine-tuned on labeled
+ data.
+ * **Has a**: `XXBackbone` and `XXPreprocessor`.
+ * **Inherits from**: `keras.Model`.
+
+Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):
+
+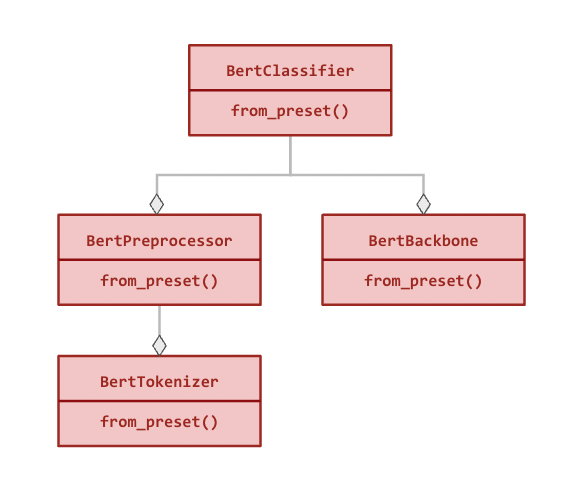 +
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+
+---
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+
+
+```python
+!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+!tar -xf aclImdb_v1.tar.gz
+!# Remove unsupervised examples
+!rm -r aclImdb/train/unsup
+```
+
+```python
+BATCH_SIZE = 16
+imdb_train = keras.utils.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = keras.utils.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+```
+
+
+All modules can be used independently and have a `from_preset()` method in addition to
+the standard constructor that instantiates the class with **preset** architecture and
+weights (see examples below).
+
+---
+## Data
+
+We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
+we use the text to predict whether the review was positive (`label = 1`) or negative
+(`label = 0`).
+
+We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the
+powerful `tf.data.Dataset` format for examples.
+
+
+```python
+!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
+!tar -xf aclImdb_v1.tar.gz
+!# Remove unsupervised examples
+!rm -r aclImdb/train/unsup
+```
+
+```python
+BATCH_SIZE = 16
+imdb_train = keras.utils.text_dataset_from_directory(
+ "aclImdb/train",
+ batch_size=BATCH_SIZE,
+)
+imdb_test = keras.utils.text_dataset_from_directory(
+ "aclImdb/test",
+ batch_size=BATCH_SIZE,
+)
+
+# Inspect first review
+# Format is (review text tensor, label tensor)
+print(imdb_train.unbatch().take(1).get_single_element())
+
+```
+
+```
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+100 80.2M 100 80.2M 0 0 88.0M 0 --:--:-- --:--:-- --:--:-- 87.9M
+
+Found 25000 files belonging to 2 classes.
+Found 25000 files belonging to 2 classes.
+(, )
+
+```
+
+---
+## Inference with a pretrained classifier
+
+ +
+The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_nlp.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is
+[negative, positive] for binary classification.
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-nlp!"])
+```
+
+
+
+The highest level module in KerasNLP is a **task**. A **task** is a `keras.Model`
+consisting of a (generally pretrained) **backbone** model and task-specific layers.
+Here's an example using `keras_nlp.models.BertClassifier`.
+
+**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is
+[negative, positive] for binary classification.
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
+# Note: batched inputs expected so must wrap string in iterable
+classifier.predict(["I love modular workflows in keras-nlp!"])
+```
+
+
+```
+ 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 689ms/step
+
+array([[-1.539, 1.543]], dtype=float16)
+
+```
+
+All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with
+preset preprocessing, architecture and weights. This means that we can pass raw strings
+in any format accepted by a `keras.Model` and get output specific to our task.
+
+This particular **preset** is a `"bert_tiny_uncased_en"` **backbone** fine-tuned on
+`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
+the `tiny` architecture for demo purposes, but larger models are recommended for SoTA
+performance. For all the task-specific presets available for `BertClassifier`, see
+our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+Let's evaluate our classifier on the IMDB dataset. You will note we don't need to
+call `keras.Model.compile` here. All **task** models like `BertClassifier` ship with
+compilation defaults, meaning we can just call `keras.Model.evaluate` directly. You
+can always call compile as normal to override these defaults (e.g. to add new metrics).
+
+The output below is [loss, accuracy],
+
+
+```python
+classifier.evaluate(imdb_test)
+```
+
+
+```
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - loss: 0.4610 - sparse_categorical_accuracy: 0.7882
+
+[0.4630218744277954, 0.783519983291626]
+
+```
+
+Our result is 78% accuracy without training anything. Not bad!
+
+---
+## Fine tuning a pretrained BERT backbone
+
+ +
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+To train your classifier, use `keras.Model.fit` as with any other
+`keras.Model`. As with our inference example, we can rely on the compilation
+defaults for the **task** and skip `keras.Model.compile`. As preprocessing is
+included, we again pass the raw data.
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+```
+
+
+
+When labeled text specific to our task is available, fine-tuning a custom classifier can
+improve performance. If we want to predict IMDB review sentiment, using IMDB data should
+perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model
+will be available (e.g., categorizing customer reviews).
+
+The workflow for fine-tuning is almost identical to above, except that we request a
+**preset** for the **backbone**-only model rather than the entire classifier. When passed
+a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific
+layers in preparation for training. For all the **backbone** presets available for
+`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+To train your classifier, use `keras.Model.fit` as with any other
+`keras.Model`. As with our inference example, we can rely on the compilation
+defaults for the **task** and skip `keras.Model.compile`. As preprocessing is
+included, we again pass the raw data.
+
+
+```python
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased",
+ num_classes=2,
+)
+classifier.fit(
+ imdb_train,
+ validation_data=imdb_test,
+ epochs=1,
+)
+```
+
+
+```
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 16s 9ms/step - loss: 0.5202 - sparse_categorical_accuracy: 0.7281 - val_loss: 0.3254 - val_sparse_categorical_accuracy: 0.8621
+
+
+
+```
+
+Here we see a significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
+training even though the IMDB dataset is much smaller than `sst2`.
+
+---
+## Fine tuning with user-controlled preprocessing
+ +
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** we can use `tf.data` for preprocessing while running on the
+Jax or PyTorch backend. The input dataset will automatically be converted to
+backend native tensor types during fit. In fact, given the efficiency of `tf.data`
+for running preprocessing, this is good practice on all backends.
+
+
+```python
+import tensorflow as tf
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+# Apply the preprocessor to every sample of train and test data using `map()`.
+# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see
+# https://www.tensorflow.org/guide/data_performance for details.
+
+# Note: only call `cache()` if you training data fits in CPU memory!
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased", preprocessor=None, num_classes=2
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+```
+
+
+
+For some advanced training scenarios, users might prefer direct control over
+preprocessing. For large datasets, examples can be preprocessed in advance and saved to
+disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In
+other cases, custom preprocessing is needed to handle the inputs.
+
+Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic
+preprocessing or pass a custom `BertPreprocessor` instead.
+
+### Separate preprocessing from the same preset
+
+Each model architecture has a parallel **preprocessor** `Layer` with its own
+`from_preset` constructor. Using the same **preset** for this `Layer` will return the
+matching **preprocessor** as the **task**.
+
+In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,
+which computes the preprocessing once and caches the result before fitting begins.
+
+**Note:** we can use `tf.data` for preprocessing while running on the
+Jax or PyTorch backend. The input dataset will automatically be converted to
+backend native tensor types during fit. In fact, given the efficiency of `tf.data`
+for running preprocessing, this is good practice on all backends.
+
+
+```python
+import tensorflow as tf
+
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=512,
+)
+
+# Apply the preprocessor to every sample of train and test data using `map()`.
+# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see
+# https://www.tensorflow.org/guide/data_performance for details.
+
+# Note: only call `cache()` if you training data fits in CPU memory!
+imdb_train_cached = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_cached = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+classifier = keras_nlp.models.BertClassifier.from_preset(
+ "bert_tiny_en_uncased", preprocessor=None, num_classes=2
+)
+classifier.fit(
+ imdb_train_cached,
+ validation_data=imdb_test_cached,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - loss: 0.5194 - sparse_categorical_accuracy: 0.7272 - val_loss: 0.3032 - val_sparse_categorical_accuracy: 0.8728
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2871 - sparse_categorical_accuracy: 0.8805 - val_loss: 0.2809 - val_sparse_categorical_accuracy: 0.8818
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2134 - sparse_categorical_accuracy: 0.9178 - val_loss: 0.3043 - val_sparse_categorical_accuracy: 0.8790
+
+
+
+```
+
+After three epochs, our validation accuracy has only increased to 0.88. This is both a
+function of the small size of our dataset and our model. To exceed 90% accuracy, try
+larger **presets** such as `"bert_base_en_uncased"`. For all the **backbone** presets
+available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_nlp/models/).
+
+### Custom preprocessing
+
+In cases where custom preprocessing is required, we offer direct access to the
+`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`
+constructor to get the vocabulary matching pretraining.
+
+**Note:** `BertTokenizer` does not pad sequences by default, so the output is
+ragged (each sequence has varying length). The `MultiSegmentPacker` below
+handles padding these ragged sequences to dense tensor types (e.g. `tf.Tensor`
+or `torch.Tensor`).
+
+
+```python
+tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
+tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
+
+# Write your own packer or use one of our `Layers`
+packer = keras_nlp.layers.MultiSegmentPacker(
+ start_value=tokenizer.cls_token_id,
+ end_value=tokenizer.sep_token_id,
+ # Note: This cannot be longer than the preset's `sequence_length`, and there
+ # is no check for a custom preprocessor!
+ sequence_length=64,
+)
+
+
+# This function that takes a text sample `x` and its
+# corresponding label `y` as input and converts the
+# text into a format suitable for input into a BERT model.
+def preprocessor(x, y):
+ token_ids, segment_ids = packer(tokenizer(x))
+ x = {
+ "token_ids": token_ids,
+ "segment_ids": segment_ids,
+ "padding_mask": token_ids != 0,
+ }
+ return x, y
+
+
+imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+
+# Preprocessed example
+print(imdb_train_preprocessed.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': }, )
+
+```
+
+---
+## Fine tuning with a custom model
+
+
+For more advanced applications, an appropriate **task** `Model` may not be available. In
+this case, we provide direct access to the **backbone** `Model`, which has its own
+`from_preset` constructor and can be composed with custom `Layer`s. Detailed examples can
+be found at our [transfer learning guide](https://keras.io/guides/transfer_learning/).
+
+A **backbone** `Model` does not include automatic preprocessing but can be paired with a
+matching **preprocessor** using the same **preset** as shown in the previous workflow.
+
+In this workflow, we experiment with freezing our backbone model and adding two trainable
+transformer layers to adapt to the new input.
+
+**Note**: We can ignore the warning about gradients for the `pooled_dense` layer because
+we are using BERT's sequence output.
+
+
+```python
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
+backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
+
+imdb_train_preprocessed = (
+ imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+imdb_test_preprocessed = (
+ imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
+)
+
+backbone.trainable = False
+inputs = backbone.input
+sequence = backbone(inputs)["sequence_output"]
+for _ in range(2):
+ sequence = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=512,
+ dropout=0.1,
+ )(sequence)
+# Use [CLS] token output to classify
+outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
+
+model = keras.Model(inputs, outputs)
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(5e-5),
+ metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+model.summary()
+model.fit(
+ imdb_train_preprocessed,
+ validation_data=imdb_test_preprocessed,
+ epochs=3,
+)
+```
+
+
+Model: "functional_1"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
+┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
+│ padding_mask │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ segment_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ token_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ bert_backbone_3 │ [(None, 128), │ 4,385,… │ padding_mask[0][0], │
+│ (BertBackbone) │ (None, None, │ │ segment_ids[0][0], │
+│ │ 128)] │ │ token_ids[0][0] │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ transformer_encoder │ (None, None, 128) │ 198,272 │ bert_backbone_3[0][… │
+│ (TransformerEncode… │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │
+│ (TransformerEncode… │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ get_item_4 │ (None, 128) │ 0 │ transformer_encoder… │
+│ (GetItem) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ dense (Dense) │ (None, 2) │ 258 │ get_item_4[0][0] │
+└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
+
+
+
+
+
+ Total params: 4,782,722 (18.24 MB)
+
+
+
+
+
+ Trainable params: 396,802 (1.51 MB)
+
+
+
+
+
+ Non-trainable params: 4,385,920 (16.73 MB)
+
+
+
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 17s 10ms/step - loss: 0.6208 - sparse_categorical_accuracy: 0.6612 - val_loss: 0.6119 - val_sparse_categorical_accuracy: 0.6758
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.5324 - sparse_categorical_accuracy: 0.7347 - val_loss: 0.5484 - val_sparse_categorical_accuracy: 0.7320
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.4735 - sparse_categorical_accuracy: 0.7723 - val_loss: 0.4874 - val_sparse_categorical_accuracy: 0.7742
+
+
+
+```
+
+This model achieves reasonable accuracy despite having only 10% of the trainable parameters
+of our `BertClassifier` model. Each training step takes about 1/3 of the time---even
+accounting for cached preprocessing.
+
+---
+## Pretraining a backbone model
+ +
+Do you have access to large unlabeled datasets in your domain? Are they around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e
+[Transformer pretraining](https://keras.io/guides/keras_nlp/transformer_pretraining/#pretraining)
+for step-by-step details on how to replicate the original paper.
+
+### Preprocessing
+
+
+```python
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+```
+
+
+
+Do you have access to large unlabeled datasets in your domain? Are they around the
+same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If
+so, you might benefit from domain-specific pretraining of your own backbone models.
+
+NLP models are generally pretrained on a language modeling task, predicting masked words
+given the visible words in an input sentence. For example, given the input
+`"The fox [MASK] over the [MASK] dog"`, the model might be asked to predict `["jumped", "lazy"]`.
+The lower layers of this model are then packaged as a **backbone** to be combined with
+layers relating to a new task.
+
+The KerasNLP library offers SoTA **backbones** and **tokenizers** to be trained from
+scratch without presets.
+
+In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the
+"next sentence prediction" (NSP) loss because it adds significant complexity to the data
+processing and was dropped by later models like RoBERTa. See our e2e
+[Transformer pretraining](https://keras.io/guides/keras_nlp/transformer_pretraining/#pretraining)
+for step-by-step details on how to replicate the original paper.
+
+### Preprocessing
+
+
+```python
+# All BERT `en` models have the same vocabulary, so reuse preprocessor from
+# "bert_tiny_en_uncased"
+preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
+ "bert_tiny_en_uncased",
+ sequence_length=256,
+)
+packer = preprocessor.packer
+tokenizer = preprocessor.tokenizer
+
+# keras.Layer to replace some input tokens with the "[MASK]" token
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=0.25,
+ mask_selection_length=64,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+ unselectable_token_ids=[
+ tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
+ ],
+)
+
+
+def preprocess(inputs, label):
+ inputs = preprocessor(inputs)
+ masked_inputs = masker(inputs["token_ids"])
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": masked_inputs["token_ids"],
+ "segment_ids": inputs["segment_ids"],
+ "padding_mask": inputs["padding_mask"],
+ "mask_positions": masked_inputs["mask_positions"],
+ }
+ labels = masked_inputs["mask_ids"]
+ weights = masked_inputs["mask_weights"]
+ return features, labels, weights
+
+
+pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
+ tf.data.AUTOTUNE
+)
+pretrain_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Tokens with ID 103 are "masked"
+print(pretrain_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'segment_ids': , 'padding_mask': , 'mask_positions': }, , )
+
+```
+
+### Pretraining model
+
+
+```python
+# BERT backbone
+backbone = keras_nlp.models.BertBackbone(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ num_layers=2,
+ num_heads=2,
+ hidden_dim=128,
+ intermediate_dim=512,
+)
+
+# Language modeling head
+mlm_head = keras_nlp.layers.MaskedLMHead(
+ token_embedding=backbone.token_embedding,
+)
+
+inputs = {
+ "token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
+ "segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
+ "padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
+ "mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
+}
+
+# Encoded token sequence
+sequence = backbone(inputs)["sequence_output"]
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.summary()
+pretraining_model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
+ weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+
+# Pretrain on IMDB dataset
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=3, # Increase to 6 for higher accuracy
+)
+```
+
+
+Model: "functional_3"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
+┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
+│ mask_positions │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ padding_mask │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ segment_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ token_ids │ (None, None) │ 0 │ - │
+│ (InputLayer) │ │ │ │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ bert_backbone_4 │ [(None, 128), │ 4,385,… │ mask_positions[0][0… │
+│ (BertBackbone) │ (None, None, │ │ padding_mask[0][0], │
+│ │ 128)] │ │ segment_ids[0][0], │
+│ │ │ │ token_ids[0][0] │
+├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
+│ masked_lm_head │ (None, None, │ 3,954,… │ bert_backbone_4[0][… │
+│ (MaskedLMHead) │ 30522) │ │ mask_positions[0][0] │
+└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
+
+
+
+
+
+ Total params: 4,433,210 (16.91 MB)
+
+
+
+
+
+ Trainable params: 4,433,210 (16.91 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - loss: 5.7032 - sparse_categorical_accuracy: 0.0566 - val_loss: 5.0685 - val_sparse_categorical_accuracy: 0.1044
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 5.0701 - sparse_categorical_accuracy: 0.1096 - val_loss: 4.9363 - val_sparse_categorical_accuracy: 0.1239
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 4.9607 - sparse_categorical_accuracy: 0.1240 - val_loss: 4.7913 - val_sparse_categorical_accuracy: 0.1417
+
+
+
+```
+
+After pretraining save your `backbone` submodel to use in a new task!
+
+---
+## Build and train your own transformer from scratch
+
+
+Want to implement a novel transformer architecture? The KerasNLP library offers all the
+low-level modules used to build SoTA architectures in our `models` API. This includes the
+`keras_nlp.tokenizers` API which allows you to train your own subword tokenizer using
+`WordPieceTokenizer`, `BytePairTokenizer`, or `SentencePieceTokenizer`.
+
+In this workflow, we train a custom tokenizer on the IMDB data and design a backbone with
+custom transformer architecture. For simplicity, we then train directly on the
+classification task. Interested in more details? We wrote an entire guide to pretraining
+and finetuning a custom transformer on
+[keras.io](https://keras.io/guides/keras_nlp/transformer_pretraining/),
+
+### Train custom vocabulary from IMDB data
+
+
+```python
+vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
+ imdb_train.map(lambda x, y: x),
+ vocabulary_size=20_000,
+ lowercase=True,
+ strip_accents=True,
+ reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
+)
+tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab,
+ lowercase=True,
+ strip_accents=True,
+ oov_token="[UNK]",
+)
+```
+
+### Preprocess data with a custom tokenizer
+
+
+```python
+packer = keras_nlp.layers.StartEndPacker(
+ start_value=tokenizer.token_to_id("[START]"),
+ end_value=tokenizer.token_to_id("[END]"),
+ pad_value=tokenizer.token_to_id("[PAD]"),
+ sequence_length=512,
+)
+
+
+def preprocess(x, y):
+ token_ids = packer(tokenizer(x))
+ return token_ids, y
+
+
+imdb_preproc_train_ds = imdb_train.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+imdb_preproc_val_ds = imdb_test.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+### Design a tiny transformer
+
+
+```python
+token_id_input = keras.Input(
+ shape=(None,),
+ dtype="int32",
+ name="token_ids",
+)
+outputs = keras_nlp.layers.TokenAndPositionEmbedding(
+ vocabulary_size=len(vocab),
+ sequence_length=packer.sequence_length,
+ embedding_dim=64,
+)(token_id_input)
+outputs = keras_nlp.layers.TransformerEncoder(
+ num_heads=2,
+ intermediate_dim=128,
+ dropout=0.1,
+)(outputs)
+# Use "[START]" token to classify
+outputs = keras.layers.Dense(2)(outputs[:, 0, :])
+model = keras.Model(
+ inputs=token_id_input,
+ outputs=outputs,
+)
+
+model.summary()
+```
+
+
+Model: "functional_5"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃
+┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
+│ token_ids (InputLayer) │ (None, None) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ token_and_position_embedding │ (None, None, 64) │ 1,259,648 │
+│ (TokenAndPositionEmbedding) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_2 │ (None, None, 64) │ 33,472 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ get_item_6 (GetItem) │ (None, 64) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ dense_1 (Dense) │ (None, 2) │ 130 │
+└─────────────────────────────────┴───────────────────────────┴────────────┘
+
+
+
+
+
+ Total params: 1,293,250 (4.93 MB)
+
+
+
+
+
+ Trainable params: 1,293,250 (4.93 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+### Train the transformer directly on the classification objective
+
+
+```python
+model.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.AdamW(5e-5),
+ metrics=[keras.metrics.SparseCategoricalAccuracy()],
+ jit_compile=True,
+)
+model.fit(
+ imdb_preproc_train_ds,
+ validation_data=imdb_preproc_val_ds,
+ epochs=3,
+)
+```
+
+
+```
+Epoch 1/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/step - loss: 0.7790 - sparse_categorical_accuracy: 0.5367 - val_loss: 0.4420 - val_sparse_categorical_accuracy: 0.8120
+Epoch 2/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.3654 - sparse_categorical_accuracy: 0.8443 - val_loss: 0.3046 - val_sparse_categorical_accuracy: 0.8752
+Epoch 3/3
+ 1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.2471 - sparse_categorical_accuracy: 0.9019 - val_loss: 0.3060 - val_sparse_categorical_accuracy: 0.8748
+
+
+
+```
+
+Excitingly, our custom classifier is similar to the performance of fine-tuning
+`"bert_tiny_en_uncased"`! To see the advantages of pretraining and exceed 90% accuracy we
+would need to use larger **presets** such as `"bert_base_en_uncased"`.
diff --git a/templates/guides/keras_nlp/transformer_pretraining.md b/templates/guides/keras_nlp/transformer_pretraining.md
new file mode 100644
index 0000000000..40397c881c
--- /dev/null
+++ b/templates/guides/keras_nlp/transformer_pretraining.md
@@ -0,0 +1,635 @@
+# Pretraining a Transformer from scratch with KerasNLP
+
+**Author:** [Matthew Watson](https://github.com/mattdangerw/)
+**Date created:** 2022/04/18
+**Last modified:** 2023/07/15
+**Description:** Use KerasNLP to train a Transformer model from scratch.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_nlp/transformer_pretraining.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_nlp/transformer_pretraining.py)
+
+
+
+KerasNLP aims to make it easy to build state-of-the-art text processing models. In this
+guide, we will show how library components simplify pretraining and fine-tuning a
+Transformer model from scratch.
+
+This guide is broken into three parts:
+
+1. *Setup*, task definition, and establishing a baseline.
+2. *Pretraining* a Transformer model.
+3. *Fine-tuning* the Transformer model on our classification task.
+
+---
+## Setup
+
+The following guide uses Keras 3 to work in any of `tensorflow`, `jax` or
+`torch`. We select the `jax` backend below, which will give us a particularly
+fast train step below, but feel free to mix it up.
+
+
+```python
+!pip install -q --upgrade keras-nlp
+!pip install -q --upgrade keras # Upgrade to Keras 3.
+```
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
+
+
+import keras_nlp
+import tensorflow as tf
+import keras
+```
+
+```
+
+```
+
+Next up, we can download two datasets.
+
+- [SST-2](https://paperswithcode.com/sota/sentiment-analysis-on-sst-2-binary) a text
+classification dataset and our "end goal". This dataset is often used to benchmark
+language models.
+- [WikiText-103](https://paperswithcode.com/dataset/wikitext-103): A medium sized
+collection of featured articles from English Wikipedia, which we will use for
+pretraining.
+
+Finally, we will download a WordPiece vocabulary, to do sub-word tokenization later on in
+this guide.
+
+
+```python
+# Download pretraining data.
+keras.utils.get_file(
+ origin="https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip",
+ extract=True,
+)
+wiki_dir = os.path.expanduser("~/.keras/datasets/wikitext-103-raw/")
+
+# Download finetuning data.
+keras.utils.get_file(
+ origin="https://dl.fbaipublicfiles.com/glue/data/SST-2.zip",
+ extract=True,
+)
+sst_dir = os.path.expanduser("~/.keras/datasets/SST-2/")
+
+# Download vocabulary data.
+vocab_file = keras.utils.get_file(
+ origin="https://storage.googleapis.com/tensorflow/keras-nlp/examples/bert/bert_vocab_uncased.txt",
+)
+```
+
+Next, we define some hyperparameters we will use during training.
+
+
+```python
+# Preprocessing params.
+PRETRAINING_BATCH_SIZE = 128
+FINETUNING_BATCH_SIZE = 32
+SEQ_LENGTH = 128
+MASK_RATE = 0.25
+PREDICTIONS_PER_SEQ = 32
+
+# Model params.
+NUM_LAYERS = 3
+MODEL_DIM = 256
+INTERMEDIATE_DIM = 512
+NUM_HEADS = 4
+DROPOUT = 0.1
+NORM_EPSILON = 1e-5
+
+# Training params.
+PRETRAINING_LEARNING_RATE = 5e-4
+PRETRAINING_EPOCHS = 8
+FINETUNING_LEARNING_RATE = 5e-5
+FINETUNING_EPOCHS = 3
+```
+
+### Load data
+
+We load our data with [tf.data](https://www.tensorflow.org/guide/data), which will allow
+us to define input pipelines for tokenizing and preprocessing text.
+
+
+```python
+# Load SST-2.
+sst_train_ds = tf.data.experimental.CsvDataset(
+ sst_dir + "train.tsv", [tf.string, tf.int32], header=True, field_delim="\t"
+).batch(FINETUNING_BATCH_SIZE)
+sst_val_ds = tf.data.experimental.CsvDataset(
+ sst_dir + "dev.tsv", [tf.string, tf.int32], header=True, field_delim="\t"
+).batch(FINETUNING_BATCH_SIZE)
+
+# Load wikitext-103 and filter out short lines.
+wiki_train_ds = (
+ tf.data.TextLineDataset(wiki_dir + "wiki.train.raw")
+ .filter(lambda x: tf.strings.length(x) > 100)
+ .batch(PRETRAINING_BATCH_SIZE)
+)
+wiki_val_ds = (
+ tf.data.TextLineDataset(wiki_dir + "wiki.valid.raw")
+ .filter(lambda x: tf.strings.length(x) > 100)
+ .batch(PRETRAINING_BATCH_SIZE)
+)
+
+# Take a peak at the sst-2 dataset.
+print(sst_train_ds.unbatch().batch(4).take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+You can see that our `SST-2` dataset contains relatively short snippets of movie review
+text. Our goal is to predict the sentiment of the snippet. A label of 1 indicates
+positive sentiment, and a label of 0 negative sentiment.
+
+### Establish a baseline
+
+As a first step, we will establish a baseline of good performance. We don't actually need
+KerasNLP for this, we can just use core Keras layers.
+
+We will train a simple bag-of-words model, where we learn a positive or negative weight
+for each word in our vocabulary. A sample's score is simply the sum of the weights of all
+words that are present in the sample.
+
+
+```python
+# This layer will turn our input sentence into a list of 1s and 0s the same size
+# our vocabulary, indicating whether a word is present in absent.
+multi_hot_layer = keras.layers.TextVectorization(
+ max_tokens=4000, output_mode="multi_hot"
+)
+multi_hot_layer.adapt(sst_train_ds.map(lambda x, y: x))
+multi_hot_ds = sst_train_ds.map(lambda x, y: (multi_hot_layer(x), y))
+multi_hot_val_ds = sst_val_ds.map(lambda x, y: (multi_hot_layer(x), y))
+
+# We then learn a linear regression over that layer, and that's our entire
+# baseline model!
+
+inputs = keras.Input(shape=(4000,), dtype="int32")
+outputs = keras.layers.Dense(1, activation="sigmoid")(inputs)
+baseline_model = keras.Model(inputs, outputs)
+baseline_model.compile(loss="binary_crossentropy", metrics=["accuracy"])
+baseline_model.fit(multi_hot_ds, validation_data=multi_hot_val_ds, epochs=5)
+```
+
+
+```
+Epoch 1/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 2s 698us/step - accuracy: 0.6421 - loss: 0.6469 - val_accuracy: 0.7567 - val_loss: 0.5391
+Epoch 2/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 493us/step - accuracy: 0.7524 - loss: 0.5392 - val_accuracy: 0.7868 - val_loss: 0.4891
+Epoch 3/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 513us/step - accuracy: 0.7832 - loss: 0.4871 - val_accuracy: 0.7991 - val_loss: 0.4671
+Epoch 4/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 475us/step - accuracy: 0.7991 - loss: 0.4543 - val_accuracy: 0.8069 - val_loss: 0.4569
+Epoch 5/5
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 1s 476us/step - accuracy: 0.8100 - loss: 0.4313 - val_accuracy: 0.8036 - val_loss: 0.4530
+
+
+
+```
+
+A bag-of-words approach can be a fast and surprisingly powerful, especially when input
+examples contain a large number of words. With shorter sequences, it can hit a
+performance ceiling.
+
+To do better, we would like to build a model that can evaluate words *in context*. Instead
+of evaluating each word in a void, we need to use the information contained in the
+*entire ordered sequence* of our input.
+
+This runs us into a problem. `SST-2` is very small dataset, and there's simply not enough
+example text to attempt to build a larger, more parameterized model that can learn on a
+sequence. We would quickly start to overfit and memorize our training set, without any
+increase in our ability to generalize to unseen examples.
+
+Enter **pretraining**, which will allow us to learn on a larger corpus, and transfer our
+knowledge to the `SST-2` task. And enter **KerasNLP**, which will allow us to pretrain a
+particularly powerful model, the Transformer, with ease.
+
+---
+## Pretraining
+
+To beat our baseline, we will leverage the `WikiText103` dataset, an unlabeled
+collection of Wikipedia articles that is much bigger than `SST-2`.
+
+We are going to train a *transformer*, a highly expressive model which will learn
+to embed each word in our input as a low dimensional vector. Our wikipedia dataset has no
+labels, so we will use an unsupervised training objective called the *Masked Language
+Modeling* (MaskedLM) objective.
+
+Essentially, we will be playing a big game of "guess the missing word". For each input
+sample we will obscure 25% of our input data, and train our model to predict the parts we
+covered up.
+
+### Preprocess data for the MaskedLM task
+
+Our text preprocessing for the MaskedLM task will occur in two stages.
+
+1. Tokenize input text into integer sequences of token ids.
+2. Mask certain positions in our input to predict on.
+
+To tokenize, we can use a `keras_nlp.tokenizers.Tokenizer` -- the KerasNLP building block
+for transforming text into sequences of integer token ids.
+
+In particular, we will use `keras_nlp.tokenizers.WordPieceTokenizer` which does
+*sub-word* tokenization. Sub-word tokenization is popular when training models on large
+text corpora. Essentially, it allows our model to learn from uncommon words, while not
+requiring a massive vocabulary of every word in our training set.
+
+The second thing we need to do is mask our input for the MaskedLM task. To do this, we can use
+`keras_nlp.layers.MaskedLMMaskGenerator`, which will randomly select a set of tokens in each
+input and mask them out.
+
+The tokenizer and the masking layer can both be used inside a call to
+[tf.data.Dataset.map](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map).
+We can use `tf.data` to efficiently pre-compute each batch on the CPU, while our GPU or TPU
+works on training with the batch that came before. Because our masking layer will
+choose new words to mask each time, each epoch over our dataset will give us a totally
+new set of labels to train on.
+
+
+```python
+# Setting sequence_length will trim or pad the token outputs to shape
+# (batch_size, SEQ_LENGTH).
+tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
+ vocabulary=vocab_file,
+ sequence_length=SEQ_LENGTH,
+ lowercase=True,
+ strip_accents=True,
+)
+# Setting mask_selection_length will trim or pad the mask outputs to shape
+# (batch_size, PREDICTIONS_PER_SEQ).
+masker = keras_nlp.layers.MaskedLMMaskGenerator(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ mask_selection_rate=MASK_RATE,
+ mask_selection_length=PREDICTIONS_PER_SEQ,
+ mask_token_id=tokenizer.token_to_id("[MASK]"),
+)
+
+
+def preprocess(inputs):
+ inputs = tokenizer(inputs)
+ outputs = masker(inputs)
+ # Split the masking layer outputs into a (features, labels, and weights)
+ # tuple that we can use with keras.Model.fit().
+ features = {
+ "token_ids": outputs["token_ids"],
+ "mask_positions": outputs["mask_positions"],
+ }
+ labels = outputs["mask_ids"]
+ weights = outputs["mask_weights"]
+ return features, labels, weights
+
+
+# We use prefetch() to pre-compute preprocessed batches on the fly on the CPU.
+pretrain_ds = wiki_train_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+pretrain_val_ds = wiki_val_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Preview a single input example.
+# The masks will change each time you run the cell.
+print(pretrain_val_ds.take(1).get_single_element())
+```
+
+
+```
+({'token_ids': , 'mask_positions': }, , )
+
+```
+
+The above block sorts our dataset into a `(features, labels, weights)` tuple, which can be
+passed directly to `keras.Model.fit()`.
+
+We have two features:
+
+1. `"token_ids"`, where some tokens have been replaced with our mask token id.
+2. `"mask_positions"`, which keeps track of which tokens we masked out.
+
+Our labels are simply the ids we masked out.
+
+Because not all sequences will have the same number of masks, we also keep a
+`sample_weight` tensor, which removes padded labels from our loss function by giving them
+zero weight.
+
+### Create the Transformer encoder
+
+KerasNLP provides all the building blocks to quickly build a Transformer encoder.
+
+We use `keras_nlp.layers.TokenAndPositionEmbedding` to first embed our input token ids.
+This layer simultaneously learns two embeddings -- one for words in a sentence and another
+for integer positions in a sentence. The output embedding is simply the sum of the two.
+
+Then we can add a series of `keras_nlp.layers.TransformerEncoder` layers. These are the
+bread and butter of the Transformer model, using an attention mechanism to attend to
+different parts of the input sentence, followed by a multi-layer perceptron block.
+
+The output of this model will be a encoded vector per input token id. Unlike the
+bag-of-words model we used as a baseline, this model will embed each token accounting for
+the context in which it appeared.
+
+
+```python
+inputs = keras.Input(shape=(SEQ_LENGTH,), dtype="int32")
+
+# Embed our tokens with a positional embedding.
+embedding_layer = keras_nlp.layers.TokenAndPositionEmbedding(
+ vocabulary_size=tokenizer.vocabulary_size(),
+ sequence_length=SEQ_LENGTH,
+ embedding_dim=MODEL_DIM,
+)
+outputs = embedding_layer(inputs)
+
+# Apply layer normalization and dropout to the embedding.
+outputs = keras.layers.LayerNormalization(epsilon=NORM_EPSILON)(outputs)
+outputs = keras.layers.Dropout(rate=DROPOUT)(outputs)
+
+# Add a number of encoder blocks
+for i in range(NUM_LAYERS):
+ outputs = keras_nlp.layers.TransformerEncoder(
+ intermediate_dim=INTERMEDIATE_DIM,
+ num_heads=NUM_HEADS,
+ dropout=DROPOUT,
+ layer_norm_epsilon=NORM_EPSILON,
+ )(outputs)
+
+encoder_model = keras.Model(inputs, outputs)
+encoder_model.summary()
+```
+
+
+Model: "functional_3"
+
+
+
+
+
+┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
+┃ Layer (type) ┃ Output Shape ┃ Param # ┃
+┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
+│ input_layer_1 (InputLayer) │ (None, 128) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ token_and_position_embedding │ (None, 128, 256) │ 7,846,400 │
+│ (TokenAndPositionEmbedding) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ layer_normalization │ (None, 128, 256) │ 512 │
+│ (LayerNormalization) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ dropout (Dropout) │ (None, 128, 256) │ 0 │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_1 │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+├─────────────────────────────────┼───────────────────────────┼────────────┤
+│ transformer_encoder_2 │ (None, 128, 256) │ 527,104 │
+│ (TransformerEncoder) │ │ │
+└─────────────────────────────────┴───────────────────────────┴────────────┘
+
+
+
+
+
+ Total params: 9,428,224 (287.73 MB)
+
+
+
+
+
+ Trainable params: 9,428,224 (287.73 MB)
+
+
+
+
+
+ Non-trainable params: 0 (0.00 B)
+
+
+
+
+### Pretrain the Transformer
+
+You can think of the `encoder_model` as it's own modular unit, it is the piece of our
+model that we are really interested in for our downstream task. However we still need to
+set up the encoder to train on the MaskedLM task; to do that we attach a
+`keras_nlp.layers.MaskedLMHead`.
+
+This layer will take as one input the token encodings, and as another the positions we
+masked out in the original input. It will gather the token encodings we masked, and
+transform them back in predictions over our entire vocabulary.
+
+With that, we are ready to compile and run pretraining. If you are running this in a
+Colab, note that this will take about an hour. Training Transformer is famously compute
+intensive, so even this relatively small Transformer will take some time.
+
+
+```python
+# Create the pretraining model by attaching a masked language model head.
+inputs = {
+ "token_ids": keras.Input(shape=(SEQ_LENGTH,), dtype="int32", name="token_ids"),
+ "mask_positions": keras.Input(
+ shape=(PREDICTIONS_PER_SEQ,), dtype="int32", name="mask_positions"
+ ),
+}
+
+# Encode the tokens.
+encoded_tokens = encoder_model(inputs["token_ids"])
+
+# Predict an output word for each masked input token.
+# We use the input token embedding to project from our encoded vectors to
+# vocabulary logits, which has been shown to improve training efficiency.
+outputs = keras_nlp.layers.MaskedLMHead(
+ token_embedding=embedding_layer.token_embedding,
+ activation="softmax",
+)(encoded_tokens, mask_positions=inputs["mask_positions"])
+
+# Define and compile our pretraining model.
+pretraining_model = keras.Model(inputs, outputs)
+pretraining_model.compile(
+ loss="sparse_categorical_crossentropy",
+ optimizer=keras.optimizers.AdamW(PRETRAINING_LEARNING_RATE),
+ weighted_metrics=["sparse_categorical_accuracy"],
+ jit_compile=True,
+)
+
+# Pretrain the model on our wiki text dataset.
+pretraining_model.fit(
+ pretrain_ds,
+ validation_data=pretrain_val_ds,
+ epochs=PRETRAINING_EPOCHS,
+)
+
+# Save this base model for further finetuning.
+encoder_model.save("encoder_model.keras")
+```
+
+
+```
+Epoch 1/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 242s 41ms/step - loss: 5.4679 - sparse_categorical_accuracy: 0.1353 - val_loss: 3.4570 - val_sparse_categorical_accuracy: 0.3522
+Epoch 2/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 234s 40ms/step - loss: 3.6031 - sparse_categorical_accuracy: 0.3396 - val_loss: 3.0514 - val_sparse_categorical_accuracy: 0.4032
+Epoch 3/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 232s 40ms/step - loss: 3.2609 - sparse_categorical_accuracy: 0.3802 - val_loss: 2.8858 - val_sparse_categorical_accuracy: 0.4240
+Epoch 4/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 233s 40ms/step - loss: 3.1099 - sparse_categorical_accuracy: 0.3978 - val_loss: 2.7897 - val_sparse_categorical_accuracy: 0.4375
+Epoch 5/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 235s 40ms/step - loss: 3.0145 - sparse_categorical_accuracy: 0.4090 - val_loss: 2.7504 - val_sparse_categorical_accuracy: 0.4419
+Epoch 6/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 252s 43ms/step - loss: 2.9530 - sparse_categorical_accuracy: 0.4157 - val_loss: 2.6925 - val_sparse_categorical_accuracy: 0.4474
+Epoch 7/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 232s 40ms/step - loss: 2.9088 - sparse_categorical_accuracy: 0.4210 - val_loss: 2.6554 - val_sparse_categorical_accuracy: 0.4513
+Epoch 8/8
+ 5857/5857 ━━━━━━━━━━━━━━━━━━━━ 236s 40ms/step - loss: 2.8721 - sparse_categorical_accuracy: 0.4250 - val_loss: 2.6389 - val_sparse_categorical_accuracy: 0.4548
+
+```
+
+---
+## Fine-tuning
+
+After pretraining, we can now fine-tune our model on the `SST-2` dataset. We can
+leverage the ability of the encoder we build to predict on words in context to boost
+our performance on the downstream task.
+
+### Preprocess data for classification
+
+Preprocessing for fine-tuning is much simpler than for our pretraining MaskedLM task. We just
+tokenize our input sentences and we are ready for training!
+
+
+```python
+
+def preprocess(sentences, labels):
+ return tokenizer(sentences), labels
+
+
+# We use prefetch() to pre-compute preprocessed batches on the fly on our CPU.
+finetune_ds = sst_train_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+finetune_val_ds = sst_val_ds.map(
+ preprocess, num_parallel_calls=tf.data.AUTOTUNE
+).prefetch(tf.data.AUTOTUNE)
+
+# Preview a single input example.
+print(finetune_val_ds.take(1).get_single_element())
+```
+
+
+```
+(, )
+
+```
+
+### Fine-tune the Transformer
+
+To go from our encoded token output to a classification prediction, we need to attach
+another "head" to our Transformer model. We can afford to be simple here. We pool
+the encoded tokens together, and use a single dense layer to make a prediction.
+
+
+```python
+# Reload the encoder model from disk so we can restart fine-tuning from scratch.
+encoder_model = keras.models.load_model("encoder_model.keras", compile=False)
+
+# Take as input the tokenized input.
+inputs = keras.Input(shape=(SEQ_LENGTH,), dtype="int32")
+
+# Encode and pool the tokens.
+encoded_tokens = encoder_model(inputs)
+pooled_tokens = keras.layers.GlobalAveragePooling1D()(encoded_tokens[0])
+
+# Predict an output label.
+outputs = keras.layers.Dense(1, activation="sigmoid")(pooled_tokens)
+
+# Define and compile our fine-tuning model.
+finetuning_model = keras.Model(inputs, outputs)
+finetuning_model.compile(
+ loss="binary_crossentropy",
+ optimizer=keras.optimizers.AdamW(FINETUNING_LEARNING_RATE),
+ metrics=["accuracy"],
+)
+
+# Finetune the model for the SST-2 task.
+finetuning_model.fit(
+ finetune_ds,
+ validation_data=finetune_val_ds,
+ epochs=FINETUNING_EPOCHS,
+)
+```
+
+
+```
+Epoch 1/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 21s 9ms/step - accuracy: 0.7500 - loss: 0.4891 - val_accuracy: 0.8036 - val_loss: 0.4099
+Epoch 2/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 16s 8ms/step - accuracy: 0.8826 - loss: 0.2779 - val_accuracy: 0.8482 - val_loss: 0.3964
+Epoch 3/3
+ 2105/2105 ━━━━━━━━━━━━━━━━━━━━ 16s 8ms/step - accuracy: 0.9176 - loss: 0.2066 - val_accuracy: 0.8549 - val_loss: 0.4142
+
+
+
+```
+
+Pretraining was enough to boost our performance to 84%, and this is hardly the ceiling
+for Transformer models. You may have noticed during pretraining that our validation
+performance was still steadily increasing. Our model is still significantly undertrained.
+Training for more epochs, training a large Transformer, and training on more unlabeled
+text would all continue to boost performance significantly.
+
+One of the key goals of KerasNLP is to provide a modular approach to NLP model building.
+We have shown one approach to building a Transformer here, but KerasNLP supports an ever
+growing array of components for preprocessing text and building models. We hope it makes
+it easier to experiment on solutions to your natural language problems.
diff --git a/templates/guides/keras_nlp/upload.md b/templates/guides/keras_nlp/upload.md
new file mode 100644
index 0000000000..76d3872fb0
--- /dev/null
+++ b/templates/guides/keras_nlp/upload.md
@@ -0,0 +1,308 @@
+# Uploading Models with KerasNLP
+
+**Author:** [Samaneh Saadat](https://github.com/SamanehSaadat/), [Matthew Watson](https://github.com/mattdangerw/)
+**Date created:** 2024/04/29
+**Last modified:** 2024/04/29
+**Description:** An introduction on how to upload a fine-tuned KerasNLP model to model hubs.
+
+
+ [**View in Colab**](https://colab.research.google.com/github/keras-team/keras-io/blob/master/guides/ipynb/keras_nlp/upload.ipynb) • [**GitHub source**](https://github.com/keras-team/keras-io/blob/master/guides/keras_nlp/upload.py)
+
+
+
+# Introduction
+
+Fine-tuning a machine learning model can yield impressive results for specific tasks.
+Uploading your fine-tuned model to a model hub allows you to share it with the broader community.
+By sharing your models, you'll enhance accessibility for other researchers and developers,
+making your contributions an integral part of the machine learning landscape.
+This can also streamline the integration of your model into real-world applications.
+
+This guide walks you through how to upload your fine-tuned models to popular model hubs such as
+[Kaggle Models](https://www.kaggle.com/models) and [Hugging Face Hub](https://huggingface.co/models).
+
+# Setup
+
+Let's start by installing and importing all the libraries we need. We use KerasNLP for this guide.
+
+
+```python
+!pip install -q --upgrade keras-nlp huggingface-hub kagglehub
+```
+
+
+```python
+import os
+
+os.environ["KERAS_BACKEND"] = "jax"
+
+import keras_nlp
+
+```
+
+# Data
+
+We can use the IMDB reviews dataset for this guide. Let's load the dataset from `tensorflow_dataset`.
+
+
+```python
+import tensorflow_datasets as tfds
+
+imdb_train, imdb_test = tfds.load(
+ "imdb_reviews",
+ split=["train", "test"],
+ as_supervised=True,
+ batch_size=4,
+)
+```
+
+We only use a small subset of the training samples to make the guide run faster.
+However, if you need a higher quality model, consider using a larger number of training samples.
+
+
+```python
+imdb_train = imdb_train.take(100)
+```
+
+# Task Upload
+
+A `keras_nlp.models.Task`, wraps a `keras_nlp.models.Backbone` and a `keras_nlp.models.Preprocessor` to create
+a model that can be directly used for training, fine-tuning, and prediction for a given text problem.
+In this section, we explain how to create a `Task`, fine-tune and upload it to a model hub.
+
+---
+## Load Model
+
+If you want to build a Causal LM based on a base model, simply call `keras_nlp.models.CausalLM.from_preset`
+and pass a built-in preset identifier.
+
+
+```python
+causal_lm = keras_nlp.models.CausalLM.from_preset("gpt2_base_en")
+
+```
+
+
+```
+Downloading from https://www.kaggle.com/api/v1/models/keras/gpt2/keras/gpt2_base_en/2/download/task.json...
+
+Downloading from https://www.kaggle.com/api/v1/models/keras/gpt2/keras/gpt2_base_en/2/download/preprocessor.json...
+
+```
+
+---
+## Fine-tune Model
+
+After loading the model, you can call `.fit()` on the model to fine-tune it.
+Here, we fine-tune the model on the IMDB reviews which makes the model movie domain-specific.
+
+
+```python
+# Drop labels and keep the review text only for the Causal LM.
+imdb_train_reviews = imdb_train.map(lambda x, y: x)
+
+# Fine-tune the Causal LM.
+causal_lm.fit(imdb_train_reviews)
+```
+ 100/100 ━━━━━━━━━━━━━━━━━━━━ 151s 1s/step - loss: 1.0198 - sparse_categorical_accuracy: 0.3271
+
+---
+## Save the Model Locally
+
+To upload a model, you need to first save the model locally using `save_to_preset`.
+
+
+```python
+preset_dir = "./gpt2_imdb"
+causal_lm.save_to_preset(preset_dir)
+```
+
+Let's see the saved files.
+
+
+```python
+os.listdir(preset_dir)
+```
+
+
+
+
+
+```
+['preprocessor.json',
+ 'tokenizer.json',
+ 'task.json',
+ 'model.weights.h5',
+ 'config.json',
+ 'metadata.json',
+ 'assets']
+
+```
+
+### Load a Locally Saved Model
+
+A model that is saved to a local preset can be loaded using `from_preset`.
+What you save in, is what you get back out.
+
+
+```python
+causal_lm = keras_nlp.models.CausalLM.from_preset(preset_dir)
+```
+
+You can also load the `keras_nlp.models.Backbone` and `keras_nlp.models.Tokenizer` objects from this preset directory.
+Note that these objects are equivalent to `causal_lm.backbone` and `causal_lm.preprocessor.tokenizer` above.
+
+
+```python
+backbone = keras_nlp.models.Backbone.from_preset(preset_dir)
+tokenizer = keras_nlp.models.Tokenizer.from_preset(preset_dir)
+```
+
+---
+## Upload the Model to a Model Hub
+
+After saving a preset to a directory, this directory can be uploaded to a model hub such as Kaggle or Hugging Face directly from the KerasNLP library.
+To upload the model to Kaggle, the URI must start with `kaggle://` and to upload to Hugging Face, it should start with `hf://`.
+
+### Upload to Kaggle
+
+To upload a model to Kaggle, first, we need to authenticate with Kaggle.
+This can in one of the following ways:
+1. Set environment variables `KAGGLE_USERNAME` and `KAGGLE_KEY`.
+2. Provide a local `~/.kaggle/kaggle.json`.
+3. Call `kagglehub.login()`.
+
+Let's make sure we are logged in before continuing.
+
+
+```python
+import kagglehub
+
+if "KAGGLE_USERNAME" not in os.environ or "KAGGLE_KEY" not in os.environ:
+ kagglehub.login()
+
+```
+
+To upload a model we can use `keras_nlp.upload_preset(uri, preset_dir)` API where `uri` has the format of
+`kaggle:////Keras/` for uploading to Kaggle and `preset_dir` is the directory that the model is saved in.
+
+Running the following uploads the model that is saved in `preset_dir` to Kaggle:
+
+
+```python
+kaggle_username = kagglehub.whoami()["username"]
+kaggle_uri = f"kaggle://{kaggle_username}/gpt2/keras/gpt2_imdb"
+keras_nlp.upload_preset(kaggle_uri, preset_dir)
+```
+
+
+```
+Upload successful: preprocessor.json (834B)
+Upload successful: tokenizer.json (322B)
+Upload successful: task.json (2KB)
+Upload successful: model.weights.h5 (475MB)
+Upload successful: config.json (431B)
+Upload successful: metadata.json (142B)
+Upload successful: merges.txt (446KB)
+Upload successful: vocabulary.json (1018KB)
+
+Your model instance version has been created.
+
+```
+
+### Upload to Hugging Face
+
+To upload a model to Hugging Face, first, we need to authenticate with Hugging Face.
+This can in one of the following ways:
+1. Set environment variables `HF_USERNAME` and `HF_TOKEN`.
+2. Call `huggingface_hub.notebook_login()`.
+
+Let's make sure we are logged in before coninuing.
+
+
+```python
+import huggingface_hub
+
+if "HF_USERNAME" not in os.environ or "HF_TOKEN" not in os.environ:
+ huggingface_hub.notebook_login()
+```
+
+`keras_nlp.upload_preset(uri, preset_dir)` can be used to upload a model to Hugging Face if `uri` has the format of
+`kaggle:///`.
+
+Running the following uploads the model that is saved in `preset_dir` to Hugging Face:
+
+
+```python
+hf_username = huggingface_hub.whoami()["name"]
+hf_uri = f"hf://{hf_username}/gpt2_imdb"
+keras_nlp.upload_preset(hf_uri, preset_dir)
+
+```
+
+---
+## Load a User Uploaded Model
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+causal_lm = keras_nlp.models.CausalLM.from_preset(
+ f"kaggle://{kaggle_username}/gpt2/keras/gpt2_imdb"
+)
+```
+
+We can also load the model uploaded to Hugging Face by calling `from_preset`.
+
+```python
+causal_lm = keras_nlp.models.CausalLM.from_preset(f"hf://{hf_username}/gpt2_imdb")
+```
+
+# Classifier Upload
+
+Uploading a classifier model is similar to Causal LM upload.
+To upload the fine-tuned model, first, the model should be saved to a local directory using `save_to_preset`
+API and then it can be uploaded via `keras_nlp.upload_preset`.
+
+
+```python
+# Load the base model.
+classifier = keras_nlp.models.Classifier.from_preset(
+ "bert_tiny_en_uncased", num_classes=2
+)
+
+# Fine-tune the classifier.
+classifier.fit(imdb_train)
+
+# Save the model to a local preset directory.
+preset_dir = "./bert_tiny_imdb"
+classifier.save_to_preset(preset_dir)
+
+# Upload to Kaggle.
+keras_nlp.upload_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb", preset_dir
+)
+```
+ 100/100 ━━━━━━━━━━━━━━━━━━━━ 7s 31ms/step - loss: 0.6975 - sparse_categorical_accuracy: 0.5164
+
+
+
+```
+Upload successful: preprocessor.json (947B)
+Upload successful: tokenizer.json (461B)
+Upload successful: task.json (2KB)
+Upload successful: task.weights.h5 (50MB)
+Upload successful: model.weights.h5 (17MB)
+Upload successful: config.json (454B)
+Upload successful: metadata.json (140B)
+Upload successful: vocabulary.txt (226KB)
+
+Your model instance version has been created.
+```
+
+After verifying that the model is uploaded to Kaggle, we can load the model by calling `from_preset`.
+
+```python
+classifier = keras_nlp.models.Classifier.from_preset(
+ f"kaggle://{kaggle_username}/bert/keras/bert_tiny_imdb"
+)
+```
\ No newline at end of file
diff --git a/templates/keras_3/keras_3_announcement.md b/templates/keras_3/keras_3_announcement.md
index b57d985d75..2be864b4a7 100644
--- a/templates/keras_3/keras_3_announcement.md
+++ b/templates/keras_3/keras_3_announcement.md
@@ -171,7 +171,7 @@ you can start using today with Keras 3.
All 40 Keras Applications models (the `keras.applications` namespace)
are available in all backends.
The vast array of pretrained models in [KerasCV](https://keras.io/api/keras_cv/)
-and [KerasNLP](https://keras.io/api/keras_nlp/) also work with all backends. This includes:
+and [KerasHub](https://keras.io/api/keras_hub/) also work with all backends. This includes:
- BERT
- OPT
diff --git a/templates/keras_cv/index.md b/templates/keras_cv/index.md
index 9b6287c348..1c3615f649 100644
--- a/templates/keras_cv/index.md
+++ b/templates/keras_cv/index.md
@@ -3,20 +3,20 @@
Star
KerasCV is a library of modular computer vision components that work natively
-with TensorFlow, JAX, or PyTorch. Built on Keras 3, these models, layers,
-metrics, callbacks, etc., can be trained and serialized in any framework and
+with TensorFlow, JAX, or PyTorch. Built on Keras 3, these models, layers,
+metrics, callbacks, etc., can be trained and serialized in any framework and
re-used in another without costly migrations.
-KerasCV can be understood as a horizontal extension of the Keras API: the
-components are new first-party Keras objects that are too specialized to be
-added to core Keras. They receive the same level of polish and backwards
-compatibility guarantees as the core Keras API, and they are maintained by the
+KerasCV can be understood as a horizontal extension of the Keras API: the
+components are new first-party Keras objects that are too specialized to be
+added to core Keras. They receive the same level of polish and backwards
+compatibility guarantees as the core Keras API, and they are maintained by the
Keras team.
-Our APIs assist in common computer vision tasks such as data augmentation,
+Our APIs assist in common computer vision tasks such as data augmentation,
classification, object detection, segmentation, image generation, and more.
-Applied computer vision engineers can leverage KerasCV to quickly assemble
-production-grade, state-of-the-art training and inference pipelines for all of
+Applied computer vision engineers can leverage KerasCV to quickly assemble
+production-grade, state-of-the-art training and inference pipelines for all of
these common tasks.
diff --git a/templates/keras_hub/index.md b/templates/keras_hub/index.md
new file mode 100644
index 0000000000..042d796c27
--- /dev/null
+++ b/templates/keras_hub/index.md
@@ -0,0 +1,136 @@
+# KerasHub
+
+Star
+
+**KerasHub** is a pretrained modeling library that aims to be simple, flexible,
+and fast. The library provides [Keras 3](https://keras.io/keras_3/)
+implementations of popular model archtictures, paired with a collection of
+pretrained checkpoints available on [Kaggle Models](https://kaggle.com/models/).
+Models can be use for both training and inference, on any of the TensorFlow,
+Jax, and Torch backends.
+
+KerasHub is an extension of the core Keras API; KerasHub components are provide
+as [`Layers`](/api/layers/) and [`Models`](/api/models/). If you are familiar
+with Keras, congratulations! You already understand most of KerasHub.
+
+See our [Getting Started guide](/guides/keras_hub/getting_started)
+to start learning our API. We welcome
+[contributions](https://github.com/keras-team/keras-hub/issues/1835).
+
+---
+## Quick links
+
+* [KerasHub API reference](/api/keras_hub/)
+* [KerasHub on GitHub](https://github.com/keras-team/keras-hub)
+* [KerasHub models on Kaggle](https://www.kaggle.com/organizations/keras/models)
+* [List of available pretrained models](/api/keras_hub/models/)
+
+## Guides
+
+* [Getting Started with KerasHub](/guides/keras_hub/getting_started/)
+* [Uploading Models with KerasHub](/guides/keras_hub/upload/)
+
+---
+## Installation
+
+To install the latest KerasHub release with Keras 3, simply run:
+
+```
+pip install --upgrade keras-hub
+```
+
+To install the latest nightly changes for both KerasHub and Keras, you can use
+our nightly package.
+
+```
+pip install --upgrade keras-hub-nightly
+```
+
+Note that currently, installing KerasHub will always pull in TensorFlow for use
+of the `tf.data` API for preprocessing. Even when pre-processing with `tf.data`,
+training can still happen on any backend.
+
+Read [Getting started with Keras](https://keras.io/getting_started/) for more
+information on installing Keras 3 and compatibility with different frameworks.
+
+**Note:** We recommend using KerasHub with TensorFlow 2.16 or later, as TF 2.16
+packages Keras 3 by default.
+
+---
+## Quickstart
+
+Below is a quick example using ResNet to predict an image, and BERT to train a
+classifier:
+
+```python
+import os
+os.environ["KERAS_BACKEND"] = "jax" # Or "tensorflow" or "torch"!
+
+import keras
+import keras_hub
+import numpy as np
+import tensorflow_datasets as tfds
+
+# Load a ResNet model.
+classifier = keras_hub.models.ImageClassifier.from_preset(
+ "resnet_50_imagenet",
+ activation="softmax",
+)
+# Predict a label for a single image.
+image_url = "https://upload.wikimedia.org/wikipedia/commons/a/aa/California_quail.jpg"
+image_path = keras.utils.get_file(origin=image_url)
+image = keras.utils.load_img(image_path)
+batch = np.array([image])
+preds = classifier.predict(batch)
+print(keras_hub.utils.decode_imagenet_predictions(preds))
+
+# Load a BERT model.
+classifier = keras_hub.models.BertClassifier.from_preset(
+ "bert_base_en_uncased",
+ activation="softmax",
+ num_classes=2,
+)
+
+# Fine-tune on IMDb movie reviews.
+imdb_train, imdb_test = tfds.load(
+ "imdb_reviews",
+ split=["train", "test"],
+ as_supervised=True,
+ batch_size=16,
+)
+classifier.fit(imdb_train, validation_data=imdb_test)
+# Predict two new examples.
+preds = classifier.predict(
+ ["What an amazing movie!", "A total waste of my time."]
+)
+print(preds)
+```
+
+---
+## Compatibility
+
+We follow [Semantic Versioning](https://semver.org/), and plan to
+provide backwards compatibility guarantees both for code and saved models built
+with our components. While we continue with pre-release `0.y.z` development, we
+may break compatibility at any time and APIs should not be consider stable.
+
+## Disclaimer
+
+KerasHub provides access to pre-trained models via the `keras_hub.models` API.
+These pre-trained models are provided on an "as is" basis, without warranties
+or conditions of any kind.
+
+## Citing KerasHub
+
+If KerasHub helps your research, we appreciate your citations.
+Here is the BibTeX entry:
+
+```bibtex
+@misc{kerashub2022,
+ title={KerasHub},
+ author={Watson, Matthew, and Qian, Chen, and Bischof, Jonathan and Chollet,
+ Fran\c{c}ois and others},
+ year={2022},
+ howpublished={\url{https://github.com/keras-team/keras-hub}},
+}
+```
 "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -q --upgrade keras-hub\n",
+ "!pip install -q --upgrade keras # Upgrade to Keras 3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "os.environ[\"KERAS_BACKEND\"] = \"jax\" # or \"tensorflow\" or \"torch\"\n",
+ "\n",
+ "import keras_hub\n",
+ "import keras\n",
+ "\n",
+ "# Use mixed precision to speed up all training in this guide.\n",
+ "keras.mixed_precision.set_global_policy(\"mixed_float16\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## API quickstart\n",
+ "\n",
+ "Our highest level API is `keras_hub.models`. These symbols cover the complete user\n",
+ "journey of converting strings to tokens, tokens to dense features, and dense features to\n",
+ "task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following\n",
+ "modules:\n",
+ "\n",
+ "* **Tokenizer**: `keras_hub.models.XXTokenizer`\n",
+ " * **What it does**: Converts strings to sequences of token ids.\n",
+ " * **Why it's important**: The raw bytes of a string are too high dimensional to be useful\n",
+ " features so we first map them to a small number of tokens, for example `\"The quick brown\n",
+ " fox\"` to `[\"the\", \"qu\", \"##ick\", \"br\", \"##own\", \"fox\"]`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Preprocessor**: `keras_hub.models.XXPreprocessor`\n",
+ " * **What it does**: Converts strings to a dictionary of preprocessed tensors consumed by\n",
+ " the backbone, starting with tokenization.\n",
+ " * **Why it's important**: Each model uses special tokens and extra tensors to understand\n",
+ " the input such as delimiting input segments and identifying padding tokens. Padding each\n",
+ " sequence to the same length improves computational efficiency.\n",
+ " * **Has a**: `XXTokenizer`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Backbone**: `keras_hub.models.XXBackbone`\n",
+ " * **What it does**: Converts preprocessed tensors to dense features. *Does not handle\n",
+ " strings; call the preprocessor first.*\n",
+ " * **Why it's important**: The backbone distills the input tokens into dense features that\n",
+ " can be used in downstream tasks. It is generally pretrained on a language modeling task\n",
+ " using massive amounts of unlabeled data. Transferring this information to a new task is a\n",
+ " major breakthrough in modern NLP.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "* **Task**: e.g., `keras_hub.models.XXClassifier`\n",
+ " * **What it does**: Converts strings to task-specific output (e.g., classification\n",
+ " probabilities).\n",
+ " * **Why it's important**: Task models combine string preprocessing and the backbone model\n",
+ " with task-specific `Layers` to solve a problem such as sentence classification, token\n",
+ " classification, or text generation. The additional `Layers` must be fine-tuned on labeled\n",
+ " data.\n",
+ " * **Has a**: `XXBackbone` and `XXPreprocessor`.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "\n",
+ "Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install -q --upgrade keras-hub\n",
+ "!pip install -q --upgrade keras # Upgrade to Keras 3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "os.environ[\"KERAS_BACKEND\"] = \"jax\" # or \"tensorflow\" or \"torch\"\n",
+ "\n",
+ "import keras_hub\n",
+ "import keras\n",
+ "\n",
+ "# Use mixed precision to speed up all training in this guide.\n",
+ "keras.mixed_precision.set_global_policy(\"mixed_float16\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## API quickstart\n",
+ "\n",
+ "Our highest level API is `keras_hub.models`. These symbols cover the complete user\n",
+ "journey of converting strings to tokens, tokens to dense features, and dense features to\n",
+ "task-specific output. For each `XX` architecture (e.g., `Bert`), we offer the following\n",
+ "modules:\n",
+ "\n",
+ "* **Tokenizer**: `keras_hub.models.XXTokenizer`\n",
+ " * **What it does**: Converts strings to sequences of token ids.\n",
+ " * **Why it's important**: The raw bytes of a string are too high dimensional to be useful\n",
+ " features so we first map them to a small number of tokens, for example `\"The quick brown\n",
+ " fox\"` to `[\"the\", \"qu\", \"##ick\", \"br\", \"##own\", \"fox\"]`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Preprocessor**: `keras_hub.models.XXPreprocessor`\n",
+ " * **What it does**: Converts strings to a dictionary of preprocessed tensors consumed by\n",
+ " the backbone, starting with tokenization.\n",
+ " * **Why it's important**: Each model uses special tokens and extra tensors to understand\n",
+ " the input such as delimiting input segments and identifying padding tokens. Padding each\n",
+ " sequence to the same length improves computational efficiency.\n",
+ " * **Has a**: `XXTokenizer`.\n",
+ " * **Inherits from**: `keras.layers.Layer`.\n",
+ "* **Backbone**: `keras_hub.models.XXBackbone`\n",
+ " * **What it does**: Converts preprocessed tensors to dense features. *Does not handle\n",
+ " strings; call the preprocessor first.*\n",
+ " * **Why it's important**: The backbone distills the input tokens into dense features that\n",
+ " can be used in downstream tasks. It is generally pretrained on a language modeling task\n",
+ " using massive amounts of unlabeled data. Transferring this information to a new task is a\n",
+ " major breakthrough in modern NLP.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "* **Task**: e.g., `keras_hub.models.XXClassifier`\n",
+ " * **What it does**: Converts strings to task-specific output (e.g., classification\n",
+ " probabilities).\n",
+ " * **Why it's important**: Task models combine string preprocessing and the backbone model\n",
+ " with task-specific `Layers` to solve a problem such as sentence classification, token\n",
+ " classification, or text generation. The additional `Layers` must be fine-tuned on labeled\n",
+ " data.\n",
+ " * **Has a**: `XXBackbone` and `XXPreprocessor`.\n",
+ " * **Inherits from**: `keras.Model`.\n",
+ "\n",
+ "Here is the modular hierarchy for `BertClassifier` (all relationships are compositional):\n",
+ "\n",
+ " \n",
+ "\n",
+ "All modules can be used independently and have a `from_preset()` method in addition to\n",
+ "the standard constructor that instantiates the class with **preset** architecture and\n",
+ "weights (see examples below)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Data\n",
+ "\n",
+ "We will use a running example of sentiment analysis of IMDB movie reviews. In this task,\n",
+ "we use the text to predict whether the review was positive (`label = 1`) or negative\n",
+ "(`label = 0`).\n",
+ "\n",
+ "We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the\n",
+ "powerful `tf.data.Dataset` format for examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n",
+ "!tar -xf aclImdb_v1.tar.gz\n",
+ "!# Remove unsupervised examples\n",
+ "!rm -r aclImdb/train/unsup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE = 16\n",
+ "imdb_train = keras.utils.text_dataset_from_directory(\n",
+ " \"aclImdb/train\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "imdb_test = keras.utils.text_dataset_from_directory(\n",
+ " \"aclImdb/test\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "\n",
+ "# Inspect first review\n",
+ "# Format is (review text tensor, label tensor)\n",
+ "print(imdb_train.unbatch().take(1).get_single_element())\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Inference with a pretrained classifier\n",
+ "\n",
+ "
\n",
+ "\n",
+ "All modules can be used independently and have a `from_preset()` method in addition to\n",
+ "the standard constructor that instantiates the class with **preset** architecture and\n",
+ "weights (see examples below)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Data\n",
+ "\n",
+ "We will use a running example of sentiment analysis of IMDB movie reviews. In this task,\n",
+ "we use the text to predict whether the review was positive (`label = 1`) or negative\n",
+ "(`label = 0`).\n",
+ "\n",
+ "We load the data using `keras.utils.text_dataset_from_directory`, which utilizes the\n",
+ "powerful `tf.data.Dataset` format for examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n",
+ "!tar -xf aclImdb_v1.tar.gz\n",
+ "!# Remove unsupervised examples\n",
+ "!rm -r aclImdb/train/unsup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "BATCH_SIZE = 16\n",
+ "imdb_train = keras.utils.text_dataset_from_directory(\n",
+ " \"aclImdb/train\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "imdb_test = keras.utils.text_dataset_from_directory(\n",
+ " \"aclImdb/test\",\n",
+ " batch_size=BATCH_SIZE,\n",
+ ")\n",
+ "\n",
+ "# Inspect first review\n",
+ "# Format is (review text tensor, label tensor)\n",
+ "print(imdb_train.unbatch().take(1).get_single_element())\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Inference with a pretrained classifier\n",
+ "\n",
+ " \n",
+ "\n",
+ "The highest level module in KerasHub is a **task**. A **task** is a `keras.Model`\n",
+ "consisting of a (generally pretrained) **backbone** model and task-specific layers.\n",
+ "Here's an example using `keras_hub.models.BertClassifier`.\n",
+ "\n",
+ "**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is\n",
+ "[negative, positive] for binary classification."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_hub.models.BertClassifier.from_preset(\"bert_tiny_en_uncased_sst2\")\n",
+ "# Note: batched inputs expected so must wrap string in iterable\n",
+ "classifier.predict([\"I love modular workflows in keras-hub!\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with\n",
+ "preset preprocessing, architecture and weights. This means that we can pass raw strings\n",
+ "in any format accepted by a `keras.Model` and get output specific to our task.\n",
+ "\n",
+ "This particular **preset** is a `\"bert_tiny_uncased_en\"` **backbone** fine-tuned on\n",
+ "`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use\n",
+ "the `tiny` architecture for demo purposes, but larger models are recommended for SoTA\n",
+ "performance. For all the task-specific presets available for `BertClassifier`, see\n",
+ "our keras.io [models page](https://keras.io/api/keras_hub/models/).\n",
+ "\n",
+ "Let's evaluate our classifier on the IMDB dataset. You will note we don't need to\n",
+ "call `keras.Model.compile` here. All **task** models like `BertClassifier` ship with\n",
+ "compilation defaults, meaning we can just call `keras.Model.evaluate` directly. You\n",
+ "can always call compile as normal to override these defaults (e.g. to add new metrics).\n",
+ "\n",
+ "The output below is [loss, accuracy],"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier.evaluate(imdb_test)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Our result is 78% accuracy without training anything. Not bad!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning a pretrained BERT backbone\n",
+ "\n",
+ "
\n",
+ "\n",
+ "The highest level module in KerasHub is a **task**. A **task** is a `keras.Model`\n",
+ "consisting of a (generally pretrained) **backbone** model and task-specific layers.\n",
+ "Here's an example using `keras_hub.models.BertClassifier`.\n",
+ "\n",
+ "**Note**: Outputs are the logits per class (e.g., `[0, 0]` is 50% chance of positive). The output is\n",
+ "[negative, positive] for binary classification."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_hub.models.BertClassifier.from_preset(\"bert_tiny_en_uncased_sst2\")\n",
+ "# Note: batched inputs expected so must wrap string in iterable\n",
+ "classifier.predict([\"I love modular workflows in keras-hub!\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "All **tasks** have a `from_preset` method that constructs a `keras.Model` instance with\n",
+ "preset preprocessing, architecture and weights. This means that we can pass raw strings\n",
+ "in any format accepted by a `keras.Model` and get output specific to our task.\n",
+ "\n",
+ "This particular **preset** is a `\"bert_tiny_uncased_en\"` **backbone** fine-tuned on\n",
+ "`sst2`, another movie review sentiment analysis (this time from Rotten Tomatoes). We use\n",
+ "the `tiny` architecture for demo purposes, but larger models are recommended for SoTA\n",
+ "performance. For all the task-specific presets available for `BertClassifier`, see\n",
+ "our keras.io [models page](https://keras.io/api/keras_hub/models/).\n",
+ "\n",
+ "Let's evaluate our classifier on the IMDB dataset. You will note we don't need to\n",
+ "call `keras.Model.compile` here. All **task** models like `BertClassifier` ship with\n",
+ "compilation defaults, meaning we can just call `keras.Model.evaluate` directly. You\n",
+ "can always call compile as normal to override these defaults (e.g. to add new metrics).\n",
+ "\n",
+ "The output below is [loss, accuracy],"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier.evaluate(imdb_test)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Our result is 78% accuracy without training anything. Not bad!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning a pretrained BERT backbone\n",
+ "\n",
+ " \n",
+ "\n",
+ "When labeled text specific to our task is available, fine-tuning a custom classifier can\n",
+ "improve performance. If we want to predict IMDB review sentiment, using IMDB data should\n",
+ "perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model\n",
+ "will be available (e.g., categorizing customer reviews).\n",
+ "\n",
+ "The workflow for fine-tuning is almost identical to above, except that we request a\n",
+ "**preset** for the **backbone**-only model rather than the entire classifier. When passed\n",
+ "a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific\n",
+ "layers in preparation for training. For all the **backbone** presets available for\n",
+ "`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/).\n",
+ "\n",
+ "To train your classifier, use `keras.Model.fit` as with any other\n",
+ "`keras.Model`. As with our inference example, we can rely on the compilation\n",
+ "defaults for the **task** and skip `keras.Model.compile`. As preprocessing is\n",
+ "included, we again pass the raw data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_hub.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " num_classes=2,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train,\n",
+ " validation_data=imdb_test,\n",
+ " epochs=1,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Here we see a significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of\n",
+ "training even though the IMDB dataset is much smaller than `sst2`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with user-controlled preprocessing\n",
+ "
\n",
+ "\n",
+ "When labeled text specific to our task is available, fine-tuning a custom classifier can\n",
+ "improve performance. If we want to predict IMDB review sentiment, using IMDB data should\n",
+ "perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model\n",
+ "will be available (e.g., categorizing customer reviews).\n",
+ "\n",
+ "The workflow for fine-tuning is almost identical to above, except that we request a\n",
+ "**preset** for the **backbone**-only model rather than the entire classifier. When passed\n",
+ "a **backbone** **preset**, a **task** `Model` will randomly initialize all task-specific\n",
+ "layers in preparation for training. For all the **backbone** presets available for\n",
+ "`BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/).\n",
+ "\n",
+ "To train your classifier, use `keras.Model.fit` as with any other\n",
+ "`keras.Model`. As with our inference example, we can rely on the compilation\n",
+ "defaults for the **task** and skip `keras.Model.compile`. As preprocessing is\n",
+ "included, we again pass the raw data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "classifier = keras_hub.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " num_classes=2,\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train,\n",
+ " validation_data=imdb_test,\n",
+ " epochs=1,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "Here we see a significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of\n",
+ "training even though the IMDB dataset is much smaller than `sst2`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with user-controlled preprocessing\n",
+ " \n",
+ "\n",
+ "For some advanced training scenarios, users might prefer direct control over\n",
+ "preprocessing. For large datasets, examples can be preprocessed in advance and saved to\n",
+ "disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In\n",
+ "other cases, custom preprocessing is needed to handle the inputs.\n",
+ "\n",
+ "Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic\n",
+ "preprocessing or pass a custom `BertPreprocessor` instead."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Separate preprocessing from the same preset\n",
+ "\n",
+ "Each model architecture has a parallel **preprocessor** `Layer` with its own\n",
+ "`from_preset` constructor. Using the same **preset** for this `Layer` will return the\n",
+ "matching **preprocessor** as the **task**.\n",
+ "\n",
+ "In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,\n",
+ "which computes the preprocessing once and caches the result before fitting begins.\n",
+ "\n",
+ "**Note:** we can use `tf.data` for preprocessing while running on the\n",
+ "Jax or PyTorch backend. The input dataset will automatically be converted to\n",
+ "backend native tensor types during fit. In fact, given the efficiency of `tf.data`\n",
+ "for running preprocessing, this is good practice on all backends."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "\n",
+ "preprocessor = keras_hub.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "# Apply the preprocessor to every sample of train and test data using `map()`.\n",
+ "# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see\n",
+ "# https://www.tensorflow.org/guide/data_performance for details.\n",
+ "\n",
+ "# Note: only call `cache()` if you training data fits in CPU memory!\n",
+ "imdb_train_cached = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_cached = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "classifier = keras_hub.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\", preprocessor=None, num_classes=2\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train_cached,\n",
+ " validation_data=imdb_test_cached,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After three epochs, our validation accuracy has only increased to 0.88. This is both a\n",
+ "function of the small size of our dataset and our model. To exceed 90% accuracy, try\n",
+ "larger **presets** such as `\"bert_base_en_uncased\"`. For all the **backbone** presets\n",
+ "available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Custom preprocessing\n",
+ "\n",
+ "In cases where custom preprocessing is required, we offer direct access to the\n",
+ "`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`\n",
+ "constructor to get the vocabulary matching pretraining.\n",
+ "\n",
+ "**Note:** `BertTokenizer` does not pad sequences by default, so the output is\n",
+ "ragged (each sequence has varying length). The `MultiSegmentPacker` below\n",
+ "handles padding these ragged sequences to dense tensor types (e.g. `tf.Tensor`\n",
+ "or `torch.Tensor`)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = keras_hub.models.BertTokenizer.from_preset(\"bert_tiny_en_uncased\")\n",
+ "tokenizer([\"I love modular workflows!\", \"Libraries over frameworks!\"])\n",
+ "\n",
+ "# Write your own packer or use one of our `Layers`\n",
+ "packer = keras_hub.layers.MultiSegmentPacker(\n",
+ " start_value=tokenizer.cls_token_id,\n",
+ " end_value=tokenizer.sep_token_id,\n",
+ " # Note: This cannot be longer than the preset's `sequence_length`, and there\n",
+ " # is no check for a custom preprocessor!\n",
+ " sequence_length=64,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "# This function that takes a text sample `x` and its\n",
+ "# corresponding label `y` as input and converts the\n",
+ "# text into a format suitable for input into a BERT model.\n",
+ "def preprocessor(x, y):\n",
+ " token_ids, segment_ids = packer(tokenizer(x))\n",
+ " x = {\n",
+ " \"token_ids\": token_ids,\n",
+ " \"segment_ids\": segment_ids,\n",
+ " \"padding_mask\": token_ids != 0,\n",
+ " }\n",
+ " return x, y\n",
+ "\n",
+ "\n",
+ "imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "\n",
+ "# Preprocessed example\n",
+ "print(imdb_train_preprocessed.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with a custom model\n",
+ "
\n",
+ "\n",
+ "For some advanced training scenarios, users might prefer direct control over\n",
+ "preprocessing. For large datasets, examples can be preprocessed in advance and saved to\n",
+ "disk or preprocessed by a separate worker pool using `tf.data.experimental.service`. In\n",
+ "other cases, custom preprocessing is needed to handle the inputs.\n",
+ "\n",
+ "Pass `preprocessor=None` to the constructor of a **task** `Model` to skip automatic\n",
+ "preprocessing or pass a custom `BertPreprocessor` instead."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Separate preprocessing from the same preset\n",
+ "\n",
+ "Each model architecture has a parallel **preprocessor** `Layer` with its own\n",
+ "`from_preset` constructor. Using the same **preset** for this `Layer` will return the\n",
+ "matching **preprocessor** as the **task**.\n",
+ "\n",
+ "In this workflow we train the model over three epochs using `tf.data.Dataset.cache()`,\n",
+ "which computes the preprocessing once and caches the result before fitting begins.\n",
+ "\n",
+ "**Note:** we can use `tf.data` for preprocessing while running on the\n",
+ "Jax or PyTorch backend. The input dataset will automatically be converted to\n",
+ "backend native tensor types during fit. In fact, given the efficiency of `tf.data`\n",
+ "for running preprocessing, this is good practice on all backends."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "\n",
+ "preprocessor = keras_hub.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=512,\n",
+ ")\n",
+ "\n",
+ "# Apply the preprocessor to every sample of train and test data using `map()`.\n",
+ "# `tf.data.AUTOTUNE` and `prefetch()` are options to tune performance, see\n",
+ "# https://www.tensorflow.org/guide/data_performance for details.\n",
+ "\n",
+ "# Note: only call `cache()` if you training data fits in CPU memory!\n",
+ "imdb_train_cached = (\n",
+ " imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "imdb_test_cached = (\n",
+ " imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)\n",
+ ")\n",
+ "\n",
+ "classifier = keras_hub.models.BertClassifier.from_preset(\n",
+ " \"bert_tiny_en_uncased\", preprocessor=None, num_classes=2\n",
+ ")\n",
+ "classifier.fit(\n",
+ " imdb_train_cached,\n",
+ " validation_data=imdb_test_cached,\n",
+ " epochs=3,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After three epochs, our validation accuracy has only increased to 0.88. This is both a\n",
+ "function of the small size of our dataset and our model. To exceed 90% accuracy, try\n",
+ "larger **presets** such as `\"bert_base_en_uncased\"`. For all the **backbone** presets\n",
+ "available for `BertClassifier`, see our keras.io [models page](https://keras.io/api/keras_hub/models/)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Custom preprocessing\n",
+ "\n",
+ "In cases where custom preprocessing is required, we offer direct access to the\n",
+ "`Tokenizer` class that maps raw strings to tokens. It also has a `from_preset()`\n",
+ "constructor to get the vocabulary matching pretraining.\n",
+ "\n",
+ "**Note:** `BertTokenizer` does not pad sequences by default, so the output is\n",
+ "ragged (each sequence has varying length). The `MultiSegmentPacker` below\n",
+ "handles padding these ragged sequences to dense tensor types (e.g. `tf.Tensor`\n",
+ "or `torch.Tensor`)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = keras_hub.models.BertTokenizer.from_preset(\"bert_tiny_en_uncased\")\n",
+ "tokenizer([\"I love modular workflows!\", \"Libraries over frameworks!\"])\n",
+ "\n",
+ "# Write your own packer or use one of our `Layers`\n",
+ "packer = keras_hub.layers.MultiSegmentPacker(\n",
+ " start_value=tokenizer.cls_token_id,\n",
+ " end_value=tokenizer.sep_token_id,\n",
+ " # Note: This cannot be longer than the preset's `sequence_length`, and there\n",
+ " # is no check for a custom preprocessor!\n",
+ " sequence_length=64,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "# This function that takes a text sample `x` and its\n",
+ "# corresponding label `y` as input and converts the\n",
+ "# text into a format suitable for input into a BERT model.\n",
+ "def preprocessor(x, y):\n",
+ " token_ids, segment_ids = packer(tokenizer(x))\n",
+ " x = {\n",
+ " \"token_ids\": token_ids,\n",
+ " \"segment_ids\": segment_ids,\n",
+ " \"padding_mask\": token_ids != 0,\n",
+ " }\n",
+ " return x, y\n",
+ "\n",
+ "\n",
+ "imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "\n",
+ "# Preprocessed example\n",
+ "print(imdb_train_preprocessed.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Fine tuning with a custom model\n",
+ " \n",
+ "\n",
+ "Do you have access to large unlabeled datasets in your domain? Are they around the\n",
+ "same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If\n",
+ "so, you might benefit from domain-specific pretraining of your own backbone models.\n",
+ "\n",
+ "NLP models are generally pretrained on a language modeling task, predicting masked words\n",
+ "given the visible words in an input sentence. For example, given the input\n",
+ "`\"The fox [MASK] over the [MASK] dog\"`, the model might be asked to predict `[\"jumped\", \"lazy\"]`.\n",
+ "The lower layers of this model are then packaged as a **backbone** to be combined with\n",
+ "layers relating to a new task.\n",
+ "\n",
+ "The KerasHub library offers SoTA **backbones** and **tokenizers** to be trained from\n",
+ "scratch without presets.\n",
+ "\n",
+ "In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the\n",
+ "\"next sentence prediction\" (NSP) loss because it adds significant complexity to the data\n",
+ "processing and was dropped by later models like RoBERTa. See our e2e\n",
+ "[Transformer pretraining](https://keras.io/guides/keras_hub/transformer_pretraining/#pretraining)\n",
+ "for step-by-step details on how to replicate the original paper."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# All BERT `en` models have the same vocabulary, so reuse preprocessor from\n",
+ "# \"bert_tiny_en_uncased\"\n",
+ "preprocessor = keras_hub.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=256,\n",
+ ")\n",
+ "packer = preprocessor.packer\n",
+ "tokenizer = preprocessor.tokenizer\n",
+ "\n",
+ "# keras.Layer to replace some input tokens with the \"[MASK]\" token\n",
+ "masker = keras_hub.layers.MaskedLMMaskGenerator(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " mask_selection_rate=0.25,\n",
+ " mask_selection_length=64,\n",
+ " mask_token_id=tokenizer.token_to_id(\"[MASK]\"),\n",
+ " unselectable_token_ids=[\n",
+ " tokenizer.token_to_id(x) for x in [\"[CLS]\", \"[PAD]\", \"[SEP]\"]\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(inputs, label):\n",
+ " inputs = preprocessor(inputs)\n",
+ " masked_inputs = masker(inputs[\"token_ids\"])\n",
+ " # Split the masking layer outputs into a (features, labels, and weights)\n",
+ " # tuple that we can use with keras.Model.fit().\n",
+ " features = {\n",
+ " \"token_ids\": masked_inputs[\"token_ids\"],\n",
+ " \"segment_ids\": inputs[\"segment_ids\"],\n",
+ " \"padding_mask\": inputs[\"padding_mask\"],\n",
+ " \"mask_positions\": masked_inputs[\"mask_positions\"],\n",
+ " }\n",
+ " labels = masked_inputs[\"mask_ids\"]\n",
+ " weights = masked_inputs[\"mask_weights\"]\n",
+ " return features, labels, weights\n",
+ "\n",
+ "\n",
+ "pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "pretrain_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "# Tokens with ID 103 are \"masked\"\n",
+ "print(pretrain_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Pretraining model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# BERT backbone\n",
+ "backbone = keras_hub.models.BertBackbone(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " num_layers=2,\n",
+ " num_heads=2,\n",
+ " hidden_dim=128,\n",
+ " intermediate_dim=512,\n",
+ ")\n",
+ "\n",
+ "# Language modeling head\n",
+ "mlm_head = keras_hub.layers.MaskedLMHead(\n",
+ " token_embedding=backbone.token_embedding,\n",
+ ")\n",
+ "\n",
+ "inputs = {\n",
+ " \"token_ids\": keras.Input(shape=(None,), dtype=tf.int32, name=\"token_ids\"),\n",
+ " \"segment_ids\": keras.Input(shape=(None,), dtype=tf.int32, name=\"segment_ids\"),\n",
+ " \"padding_mask\": keras.Input(shape=(None,), dtype=tf.int32, name=\"padding_mask\"),\n",
+ " \"mask_positions\": keras.Input(shape=(None,), dtype=tf.int32, name=\"mask_positions\"),\n",
+ "}\n",
+ "\n",
+ "# Encoded token sequence\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "\n",
+ "# Predict an output word for each masked input token.\n",
+ "# We use the input token embedding to project from our encoded vectors to\n",
+ "# vocabulary logits, which has been shown to improve training efficiency.\n",
+ "outputs = mlm_head(sequence, mask_positions=inputs[\"mask_positions\"])\n",
+ "\n",
+ "# Define and compile our pretraining model.\n",
+ "pretraining_model = keras.Model(inputs, outputs)\n",
+ "pretraining_model.summary()\n",
+ "pretraining_model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.AdamW(learning_rate=5e-4),\n",
+ " weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "# Pretrain on IMDB dataset\n",
+ "pretraining_model.fit(\n",
+ " pretrain_ds,\n",
+ " validation_data=pretrain_val_ds,\n",
+ " epochs=3, # Increase to 6 for higher accuracy\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After pretraining save your `backbone` submodel to use in a new task!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Build and train your own transformer from scratch\n",
+ "
\n",
+ "\n",
+ "Do you have access to large unlabeled datasets in your domain? Are they around the\n",
+ "same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If\n",
+ "so, you might benefit from domain-specific pretraining of your own backbone models.\n",
+ "\n",
+ "NLP models are generally pretrained on a language modeling task, predicting masked words\n",
+ "given the visible words in an input sentence. For example, given the input\n",
+ "`\"The fox [MASK] over the [MASK] dog\"`, the model might be asked to predict `[\"jumped\", \"lazy\"]`.\n",
+ "The lower layers of this model are then packaged as a **backbone** to be combined with\n",
+ "layers relating to a new task.\n",
+ "\n",
+ "The KerasHub library offers SoTA **backbones** and **tokenizers** to be trained from\n",
+ "scratch without presets.\n",
+ "\n",
+ "In this workflow, we pretrain a BERT **backbone** using our IMDB review text. We skip the\n",
+ "\"next sentence prediction\" (NSP) loss because it adds significant complexity to the data\n",
+ "processing and was dropped by later models like RoBERTa. See our e2e\n",
+ "[Transformer pretraining](https://keras.io/guides/keras_hub/transformer_pretraining/#pretraining)\n",
+ "for step-by-step details on how to replicate the original paper."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# All BERT `en` models have the same vocabulary, so reuse preprocessor from\n",
+ "# \"bert_tiny_en_uncased\"\n",
+ "preprocessor = keras_hub.models.BertPreprocessor.from_preset(\n",
+ " \"bert_tiny_en_uncased\",\n",
+ " sequence_length=256,\n",
+ ")\n",
+ "packer = preprocessor.packer\n",
+ "tokenizer = preprocessor.tokenizer\n",
+ "\n",
+ "# keras.Layer to replace some input tokens with the \"[MASK]\" token\n",
+ "masker = keras_hub.layers.MaskedLMMaskGenerator(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " mask_selection_rate=0.25,\n",
+ " mask_selection_length=64,\n",
+ " mask_token_id=tokenizer.token_to_id(\"[MASK]\"),\n",
+ " unselectable_token_ids=[\n",
+ " tokenizer.token_to_id(x) for x in [\"[CLS]\", \"[PAD]\", \"[SEP]\"]\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "\n",
+ "def preprocess(inputs, label):\n",
+ " inputs = preprocessor(inputs)\n",
+ " masked_inputs = masker(inputs[\"token_ids\"])\n",
+ " # Split the masking layer outputs into a (features, labels, and weights)\n",
+ " # tuple that we can use with keras.Model.fit().\n",
+ " features = {\n",
+ " \"token_ids\": masked_inputs[\"token_ids\"],\n",
+ " \"segment_ids\": inputs[\"segment_ids\"],\n",
+ " \"padding_mask\": inputs[\"padding_mask\"],\n",
+ " \"mask_positions\": masked_inputs[\"mask_positions\"],\n",
+ " }\n",
+ " labels = masked_inputs[\"mask_ids\"]\n",
+ " weights = masked_inputs[\"mask_weights\"]\n",
+ " return features, labels, weights\n",
+ "\n",
+ "\n",
+ "pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(\n",
+ " tf.data.AUTOTUNE\n",
+ ")\n",
+ "pretrain_val_ds = imdb_test.map(\n",
+ " preprocess, num_parallel_calls=tf.data.AUTOTUNE\n",
+ ").prefetch(tf.data.AUTOTUNE)\n",
+ "\n",
+ "# Tokens with ID 103 are \"masked\"\n",
+ "print(pretrain_ds.unbatch().take(1).get_single_element())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "### Pretraining model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab_type": "code"
+ },
+ "outputs": [],
+ "source": [
+ "# BERT backbone\n",
+ "backbone = keras_hub.models.BertBackbone(\n",
+ " vocabulary_size=tokenizer.vocabulary_size(),\n",
+ " num_layers=2,\n",
+ " num_heads=2,\n",
+ " hidden_dim=128,\n",
+ " intermediate_dim=512,\n",
+ ")\n",
+ "\n",
+ "# Language modeling head\n",
+ "mlm_head = keras_hub.layers.MaskedLMHead(\n",
+ " token_embedding=backbone.token_embedding,\n",
+ ")\n",
+ "\n",
+ "inputs = {\n",
+ " \"token_ids\": keras.Input(shape=(None,), dtype=tf.int32, name=\"token_ids\"),\n",
+ " \"segment_ids\": keras.Input(shape=(None,), dtype=tf.int32, name=\"segment_ids\"),\n",
+ " \"padding_mask\": keras.Input(shape=(None,), dtype=tf.int32, name=\"padding_mask\"),\n",
+ " \"mask_positions\": keras.Input(shape=(None,), dtype=tf.int32, name=\"mask_positions\"),\n",
+ "}\n",
+ "\n",
+ "# Encoded token sequence\n",
+ "sequence = backbone(inputs)[\"sequence_output\"]\n",
+ "\n",
+ "# Predict an output word for each masked input token.\n",
+ "# We use the input token embedding to project from our encoded vectors to\n",
+ "# vocabulary logits, which has been shown to improve training efficiency.\n",
+ "outputs = mlm_head(sequence, mask_positions=inputs[\"mask_positions\"])\n",
+ "\n",
+ "# Define and compile our pretraining model.\n",
+ "pretraining_model = keras.Model(inputs, outputs)\n",
+ "pretraining_model.summary()\n",
+ "pretraining_model.compile(\n",
+ " loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
+ " optimizer=keras.optimizers.AdamW(learning_rate=5e-4),\n",
+ " weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],\n",
+ " jit_compile=True,\n",
+ ")\n",
+ "\n",
+ "# Pretrain on IMDB dataset\n",
+ "pretraining_model.fit(\n",
+ " pretrain_ds,\n",
+ " validation_data=pretrain_val_ds,\n",
+ " epochs=3, # Increase to 6 for higher accuracy\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "After pretraining save your `backbone` submodel to use in a new task!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text"
+ },
+ "source": [
+ "## Build and train your own transformer from scratch\n",
+ "