
Code and results accompanying the paper:
Kozodoi, N., Jacob, J., Lessmann, S. (2021).
Fairness in Credit Scoring: Assessment, Implementation and Profit Implications.
European Journal of Operational Research, 297, 1083-1094.
The paper is available at the publisher's website and on arXiv.
Note: the PDF on the publisher's website contains a typo in Equation 5 (the group subscripts in the last term should be swapped). Please refer to the arXiv preprint and/or the code in this repo for the correct version.
The rise of algorithmic decision-making has spawned much research on fair machine learning (ML). Financial institutions use ML for building risk scorecards that support a range of credit-related decisions. The project makes three contributions:
- Revisiting statistical fairness criteria and examine their adequacy for credit scoring.
- Cataloging algorithmic options for incorporating fairness goals in the ML model development pipeline.
- Empirically comparing multiple fairness processors in a profit-oriented credit scoring context using real-world data.
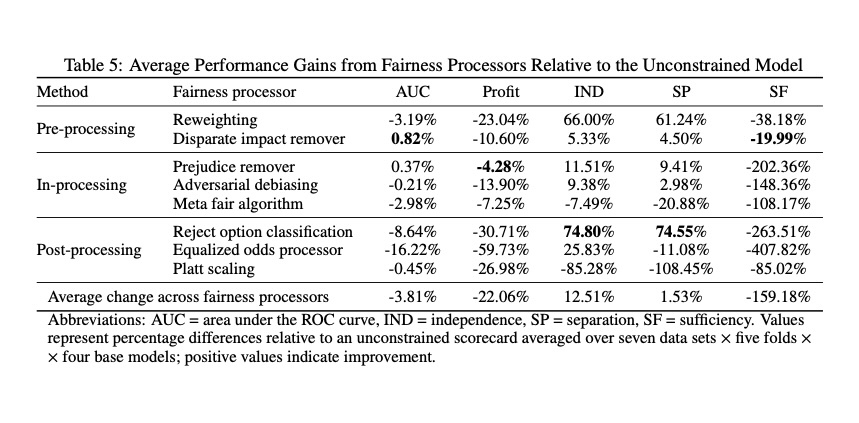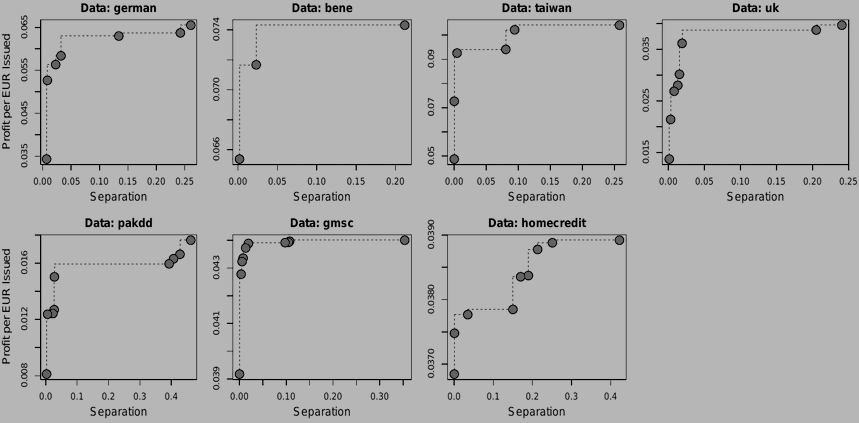
The empirical results substantiate the evaluation of fairness measures, identify suitable options to implement fair credit scoring, and clarify the profit-fairness trade-off in lending decisions. We find that multiple fairness criteria can be approximately satisfied at once and recommend separation as a proper criterion for measuring scorecard fairness. We also find fair in-processors to deliver a good profit-fairness balance and show that algorithmic discrimination can be reduced to a reasonable level at a relatively low cost.
This repo contains codes and files that allow reproducing the results presented in the paper, performing additional analyses and extending the experimental setup. It provides implementations of eight fairness processors used in the paper. Further details on the modeling pipeline are provided in the paper as well as in the codes.
The repo has the following structure:
codes/: Python notebooks and R codes implementing data processing and fair ML algorithmsdata/: raw data sets and processed data exported from the data processing scriptsfunctions/: helper functions accompanying the codes, including a customizedaif360Python moduleoutput/: figures and tables with results exported fromcode_14_results.Rand presented in the paperresults/: intermediate and final results files exported from the different modeling codes
Further details on the codes are provided in a separate README file in the codes folder.
The experiments are performed on seven credit scoring data sets obtained from different sources, including the UCI Machine Learning Repository, Kaggle and PAKDD platforms.
To respect the terms of use of the corresponding data sets and adhere to the file size limit, the raw data is not included in the repo. The full list of data sets with the download links and instructions is provided in a separate README file in the data folder.
The paper implements and banchmarks the folloeing fair ML algorithms:
- Pre-processors:
- Reweighting (Calders et al. 2009)
- Disparate Impact Remover (Feldman et al. 2015)
- In-processors:
- Prejudice Remover (Kamishima et al. 2012)
- Adersarial Debiasing (Zhang et al. 2018)
- Meta-Fairness Algorithm (Celis et al. 2019)
- Post-processors:
- Reject Option Classification (Kamiran et al. 2012)
- Equalized Odds Processor (Hardt et al. 2016)
- Platt Scaling (Platt 1999), (Barocas et al. 2019)
The codes require Python 3.7+ and R 4.0+. Relevant R packages are installed separately at the beginning of each R script. Packages required to implement each of the considered fairness processors are listed and imported in the corresponding Python scripts.
To work with the Python notebooks, we recommend to create a virtual Conda environment from the supplied environment.yml file:
conda env create --name fairness --file environment.yml
conda activate fairness
Reproducing results presented in the paper and carrying out additional analysis involves the following steps:
- Update working paths in
code_00_working_paths.R. - Execute
code_14_results.Rto perform analysis of the results and save outputs inoutput/.
Modifying the experimental setup requires the following:
- Place the raw data sets in the
data/raw/folder (see instructions). - Update working paths in
code_00_working_paths.R. - Execute
code_01_data_partitioning.ipynbto process and partition each data set. - Adjust experimental parameters specified in
functions/. - Execute the modeling codes according to their name order for each of the data sets.
- Execute
code_14_results.Rto perform analysis of the results and save outputs inoutput/.