Speech-to-Text-WaveNet : End-to-end sentence level English speech recognition using DeepMind's WaveNet
A tensorflow implementation of speech recognition based on DeepMind's WaveNet: A Generative Model for Raw Audio. (Hereafter the Paper)
Although ibab and tomlepaine have already implemented WaveNet with tensorflow, they did not implement speech recognition. That's why we decided to implement it ourselves.
Some of Deepmind's recent papers are tricky to reproduce. The Paper also omitted specific details about the implementation, and we had to fill the gaps in our own way.
Here are a few important notes.
First, while the Paper used the TIMIT dataset for the speech recognition experiment, we used the free VTCK dataset.
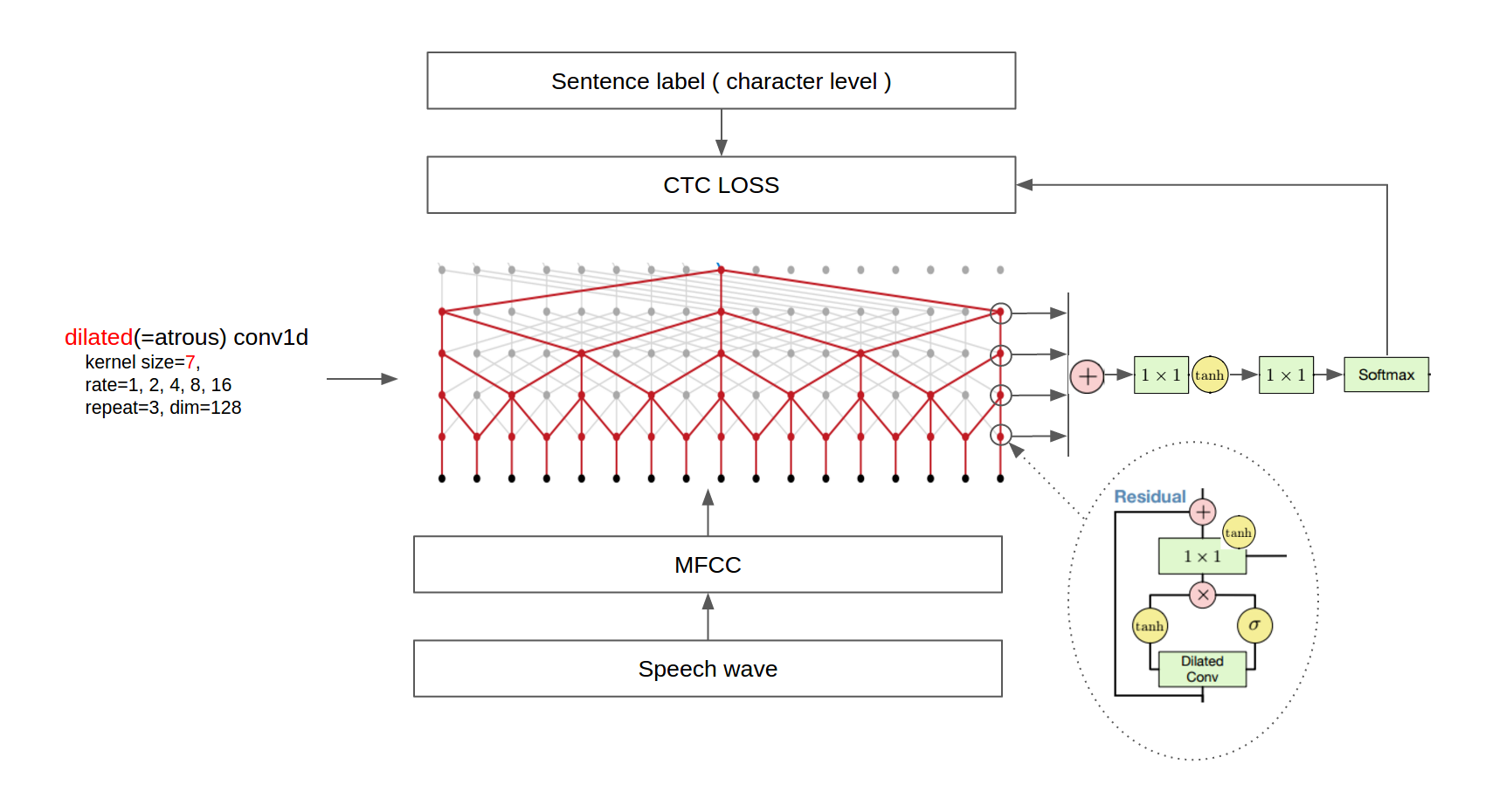
Second, the Paper added a mean-pooling layer after the dilated convolution layer for down-sampling. We extracted MFCC from wav files and removed the final mean-pooling layer because the original setting was impossible to run on our TitanX GPU.
Third, since the TIMIT dataset has phoneme labels, the Paper trained the model with two loss terms, phoneme classification and next phoneme prediction. We, instead, used a single CTC loss because VCTK provides sentence-level labels. As a result, we used only dilated conv1d layers without any causal conv1d layers.
Finally, we didn't do quantitative analyses such as WER/CER/PER and post-processing by combining a language model due to the time constraints.
The final architecture is shown in the following figure.
- tensorflow >= 0.11
- sugartensor >= 0.0.1.9
- pandas >= 0.19.1
- librosa >= 0.4.3
We used only 36,395 sentences in the VCTK corpus with a length of more than 5 seconds to prevent CTC loss errors. VCTK corpus can be downloaded from http://homepages.inf.ed.ac.uk/jyamagis/release/VCTK-Corpus.tar.gz. After downloading, extract the 'VCTK-Corpus.tar.gz' file to the 'asset/data/' directory.
Execute
python train.py
to train the network. You can see the result ckpt files and log files in the 'asset/train' directory. Launch tensorboard --logdir asset/train/log to monitor training process.
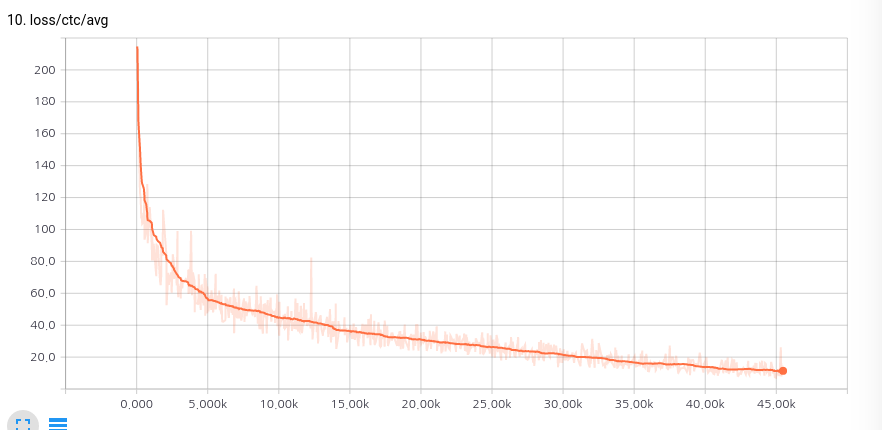
We've trained this model on a single Titan X GPU during 30 hours until 20 epochs and the model stopped at 13.4 ctc loss. If you don't have a Titan X GPU, reduce batch_size in the train.py file from 16 to 4.
Execute
python recognize.py --file
to transform a speech wave file to the English sentence. The result will be printed on the console.
For example, try the following command.
python recognize.py --file asset/data/wav48/p225/p225_003.wav
The result will be as follows:
six spoons of fresh now peas five thick slbs of blue cheese and maybe a snack for her brother bob
The ground truth is as follows:
Six spoons of fresh snow peas, five thick slabs of blue cheese, and maybe a snack for her brother Bob.
As mentioned earlier, there is no language model, so there are some cases where capital letters, punctuations, and words are misspelled.
You can transform a speech wave file to English text with the pre-trained model on the VCTK corpus. Extract the following zip file to the 'asset/train/ckpt/' directory.
- ibab's WaveNet(speech synthesis) tensorflow implementation
- tomlepaine's Fast WaveNet(speech synthesis) tensorflow implementation
- SugarTensor
- EBGAN tensorflow implementation
- Timeseries gan tensorflow implementation
- Supervised InfoGAN tensorflow implementation
- AC-GAN tensorflow implementation
- SRGAN tensorflow implementation
- ByteNet-Fast Neural Machine Translation
Namju Kim (buriburisuri@gmail.com) at Jamonglabs Co., Ltd. Kyubyong Park (kbpark@jamonglab.com) at Jamonglabs Co., Ltd.