
A GPT model as a language channel to build representations for a Non-Axiomatic Reasoning System (OpenNARS for Applications). This is the first system implementation which uses GPT together with NARS for reasoning on natural language input. This system can learn in a long-term manner while being able to learn and apply new knowledge effectively.
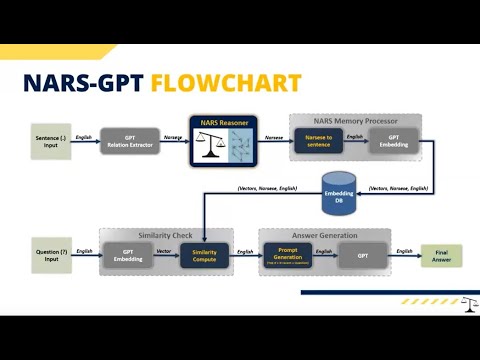
Features:
- Interactive NARS-style declarative inference and question answering with long-term memory storage
- System can point out which memory items support a specific conclusion, and how certain it is
- Seamless interfacing with Narsese input and sensorimotor capabilities of NARS.
- The system is able to build and maintain long-term, a useful and evidentally supported set of beliefs through reasoning.
- NARS-GPT supports various types of reasoning, truth maintenance and automated memory management, which can be beneficial for adaptive autonomous agents.
- It applies decades of knowledge about reasoning under uncertainty, evidence tracking and resource allocation in Non-Axiomatic Reasoning Systems.
Architecture:

Technical aspects:
- OpenNARS for Applications was chosen as the NARS implementation as the project seems to be the most mature implementation of NARS for large-scale experiments.
- GPT-4 was chosen for NARS-GPT since it is the most capable LLM by OpenAI that is usable through the public API.
- Sentences are stored in logical/structural form in the memory of NARS whereby introduction of new similar terms is avoided through the usage of embedding similarity of terms.
- Accurate reasoning with Non-Axiomatic Logic truth calculations are carried out with NARS.
- The long-term memory of NARS-GPT does not have a context window size limitation.
- The memory of NARS-GPT can nevertheless be bounded if users desire so, whereby a maximum amount of items is kept (the others evicted) by a usefulness ranking (how often an item was accessed and how recently).
- The attention buffer is a view of up to k relevant items in NARS's memory decided based on recency and relevance to other items in the attention buffer, whereby recency is based on the time stamp of when the knowledge item was created, and relevance is decided by cosine similarity of the sentence embedding to the questions's embedding.
- By NARS-GPT mentioned certainty values are NAL confidence values, whereby if frequency value is smaller than
$0.5$ the belief appears in negated formulation in the prompt.
Installation:
Run build.sh (which compiles & runs the ONA implementation of NARS with Clang or GCC) and also install the depencencies via install_python_dependencies.sh which will install the OpenAI API and other relevant Python packages.
How to run:
python3 NarsGPT.py API_KEY=YOUR_OPENAI_API_KEY
Evaluation:
Relevant folders:
./NARS-GPT/Evaluation_babI_qa16/
./NARS-GPT/Evaluation_INT_inf/
Side note: As different prompts can lead to different results which would make comparisons less fair, these scripts ensure the prompts to GPT-4 and NARS-GPT for the task are compatible. To run vanilla GPT-4 for evaluation on babI for comparison purposes, use the baseline branch.
In each of these folders, run:
python3 1_GenerateTestOutput.py API_KEY=YOUR_OPENAI_API_KEY
(which runs the model on the QA16 part of babI specified in line 11 of the script and generates TestOutput.json including input, actual and expected output for each example)
python3 2_EvaluateTestOutput.py API_KEY=YOUR_OPENAI_API_KEY
(which judges output correctness and generates Scores.json, and in addition Correct.json and Incorrect.json with the examples determined as correct and incorrect)
Scores.json then contains the relevant numbers, in terms of Correct amount, Incorrect amount, and the correctness ratio.
Please note that both scripts can be interrupted, with the resulting .json files reflecting the current state. That way one can also choose to use part of the dataset (say 100-200 examples) for replication.