This folder contains examples and best practices, written in Jupyter notebooks, for building recommendation systems.
The diagram below depicts how the best-practice examples help researchers / developers in the recommendation system development workflow.
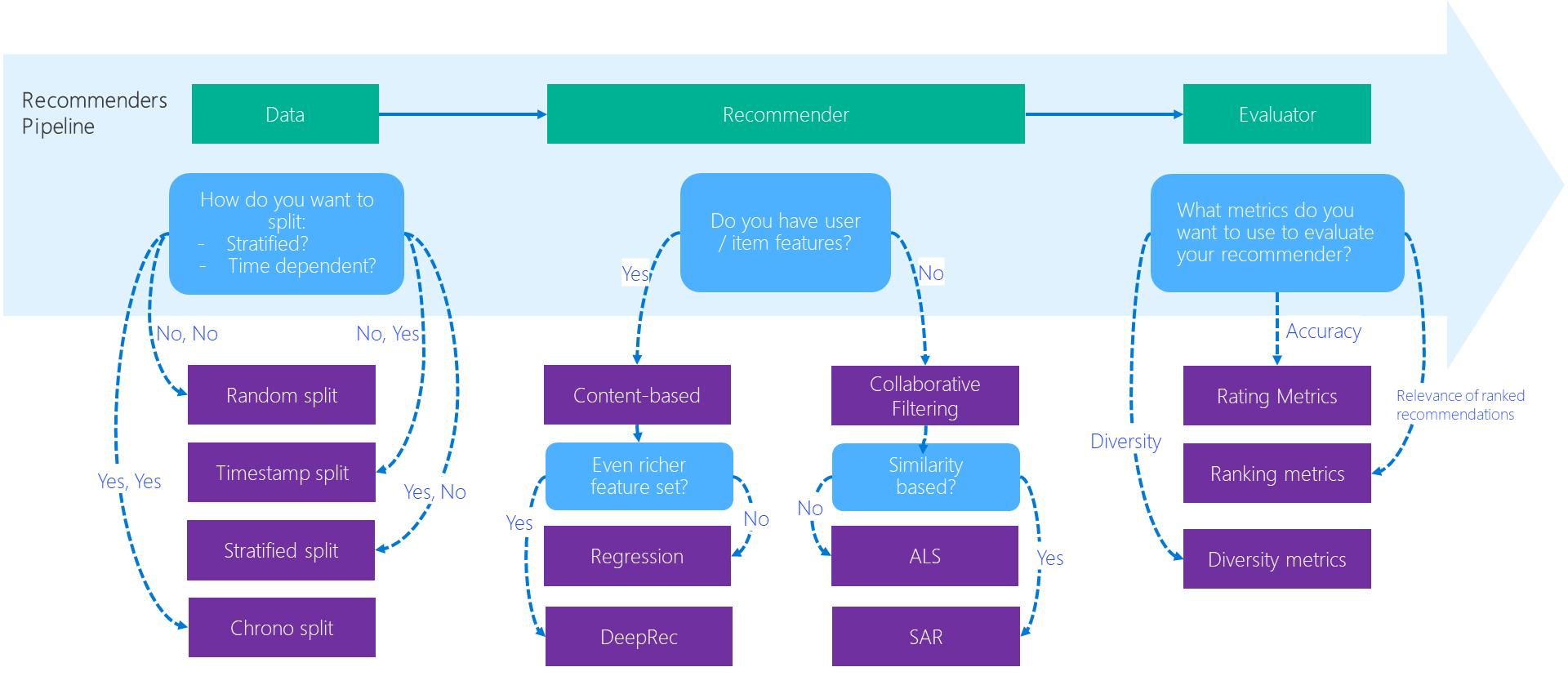
The following summarizes each directory of the best practice notebooks.
| Directory | Runs Local | Description |
|---|---|---|
| 00_quick_start | Yes | Quick start notebooks that demonstrate workflow of developing a recommender by using an algorithm in local environment |
| 01_prepare_data | Yes | Data preparation notebooks for each recommender algorithm |
| 02_model_collaborative_filtering | Yes | Deep dive notebooks about model training and evaluation using collaborative filtering algorithms |
| 02_model_content_based_filtering | Yes | Deep dive notebooks about model training and evaluation using content-based filtering algorithms |
| 03_evaluate | Yes | Notebooks that introduce different evaluation methods for recommenders |
| 04_model_select_and_optimize | Some local, some on Azure | Best practice notebooks for model tuning and selecting by using Azure Machine Learning Service and/or open source technologies |
| 05_operationalize | No, Run on Azure | Operationalization notebooks that illustrate an end-to-end pipeline by using a recommender algorithm for a certain real-world use case scenario |
| 06_benchmarks | Yes | Benchmark comparison of several recommender algorithms |
| 07_tutorials | Yes | Tutorials for using the Recommenders library |
The notebooks that do not require Azure can be run out-of-the-box on any Linux machine, where an environment is properly set up by following the instructions.
NOTE Some of the notebooks may rely on heterogeneous computing instances like a cluster of CPU machines with Spark framework installed or machines with GPU devices incorporated. It is therefore recommended to run these notebooks on a Data Science Virtual Machine for Linux (Ubuntu), where a single-node Spark and/or GPU device are pre-configured.
Azure products and services are used in certain notebooks to enhance the efficiency of developing recommender systems in scale.
To successfully run these notebooks, the users need an Azure subscription or can use Azure for free. The Azure products featured in the notebooks include:
- Azure Machine Learning service - Azure Machine Learning service is a cloud service used to train, deploy, automate, and manage machine learning models, all at the broad scale that the cloud provides. It is used intensively across various notebooks for the AI model development related tasks like:
- Hyperparameter tuning
- Tracking and monitoring metrics to enhance the model creation process
- Scaling up and out on Compute like DSVM and Azure Machine Learning Compute
- Deploying a web service to Azure Kubernetes Service
- Submitting pipelines
- Azure Data Science Virtual Machine - Azure Data Science Virtual Machine is mainly used for a remote server where user can easily configure the local as well as the cloud environment for running the example notebooks.
- Azure Cosmos DB - Cosmos DB is used for preserving data. This is demonstrated in the operationalization example where recommendation results generated from a model are preserved in Cosmos DB for real-time serving purpose.
- Azure Databricks - Azure Databricks is mainly used for developing Spark based recommenders such as Spark ALS algorithm, in a distributed computing environment.
- Azure Kubernetes Service - Azure Kubernetes Service is used for serving a recommender model or consuming the results generated from a recommender for a application service.
There may be other Azure service or products used in the notebooks. Introduction and/or reference of those will be provided in the notebooks.
The run_notebook_on_azureml notebook provides a scaffold to directly submit an existing notebook to AzureML compute targets. After setting up a compute target and creating a run configuration, simply replace the notebook file name and submit the notebook directly.
cfg = NotebookRunConfig(source_directory='../',
notebook='examples/00_quick_start/' + NOTEBOOK_NAME,
output_notebook='outputs/out.ipynb',
parameters={"MOVIELENS_DATA_SIZE": "100k", "TOP_K": 10},
run_config=run_config)All metrics and parameters logged with store_metadata will be stored on the run as tracked metrics. The initial notebook that was submitted, will be stored as an output notebook out.ipynb in the outputs tab of the Azure Portal.