PaddleNLP提供多个开源的预训练词向量模型,用户仅需在使用paddlenlp.embeddings.TokenEmbedding时,指定预训练模型的名称,即可加载相对应的预训练模型。以下将介绍TokenEmbeddign详细用法,并列出PaddleNLP所支持的预训练Embedding模型。
| 参数 | 类型 | 属性 |
|---|---|---|
| embedding_name | string | 预训练embedding名称,可通过paddlenlp.embeddings.list_embedding_name()或Embedding 模型汇总查询。 |
| unknown_token | string | unknown token。 |
| unknown_token_vector | list 或者 np.array | 用来初始化unknown token对应的vector。默认为None(以正态分布方式初始化vector) |
| extended_vocab_path | string | 扩展词表的文件名路径。词表格式为一行一个词。 |
| trainable | bool | 是否可训练。True表示Embedding可以更新参数,False为不可更新。 |
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
paddle.set_device("cpu")
# 查看预训练embedding名称:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']
# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
print(token_embedding)
Object type: <paddlenlp.embeddings.token_embedding.TokenEmbedding object at 0x7fda7eb5f290>
Unknown index: 635963
Unknown token: [UNK]
Padding index: 635964
Padding token: [PAD]
Parameter containing:
Tensor(shape=[635965, 300], dtype=float32, place=CPUPlace, stop_gradient=False,
[[-0.24200200, 0.13931701, 0.07378800, ..., 0.14103900, 0.05592300, -0.08004800],
[-0.08671700, 0.07770800, 0.09515300, ..., 0.11196400, 0.03082200, -0.12893000],
[-0.11436500, 0.12201900, 0.02833000, ..., 0.11068700, 0.03607300, -0.13763499],
...,
[ 0.02628800, -0.00008300, -0.00393500, ..., 0.00654000, 0.00024600, -0.00662600],
[-0.00924490, 0.00652097, 0.01049327, ..., -0.01796000, 0.03498908, -0.02209341],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ]])test_token_embedding = token_embedding.search("中国")
print(test_token_embedding)
[[ 0.260801 0.1047 0.129453 -0.257317 -0.16152 0.19567 -0.074868
0.361168 0.245882 -0.219141 -0.388083 0.235189 0.029316 0.154215
-0.354343 0.017746 0.009028 0.01197 -0.121429 0.096542 0.009255
...,
-0.260592 -0.019668 -0.063312 -0.094939 0.657352 0.247547 -0.161621
0.289043 -0.284084 0.205076 0.059885 0.055871 0.159309 0.062181
0.123634 0.282932 0.140399 -0.076253 -0.087103 0.07262 ]]使用深度学习可视化工具VisualDL的High Dimensional组件可以对embedding结果进行可视化展示,便于对其直观分析,步骤如下:
# 获取词表中前1000个单词
labels = token_embedding.vocab.to_tokens(list(range(0,1000)))
test_token_embedding = token_embedding.search(labels)
# 引入VisualDL的LogWriter记录日志
from visualdl import LogWriter
with LogWriter(logdir='./visualize') as writer:
writer.add_embeddings(tag='test', mat=test_token_embedding, metadata=labels)执行完毕后会在当前路径下生成一个visualize目录,并将日志存放在其中,我们在命令行启动VisualDL即可进行查看,启动命令为:
visualdl logdir ./visualize启动后打开浏览器即可看到可视化结果
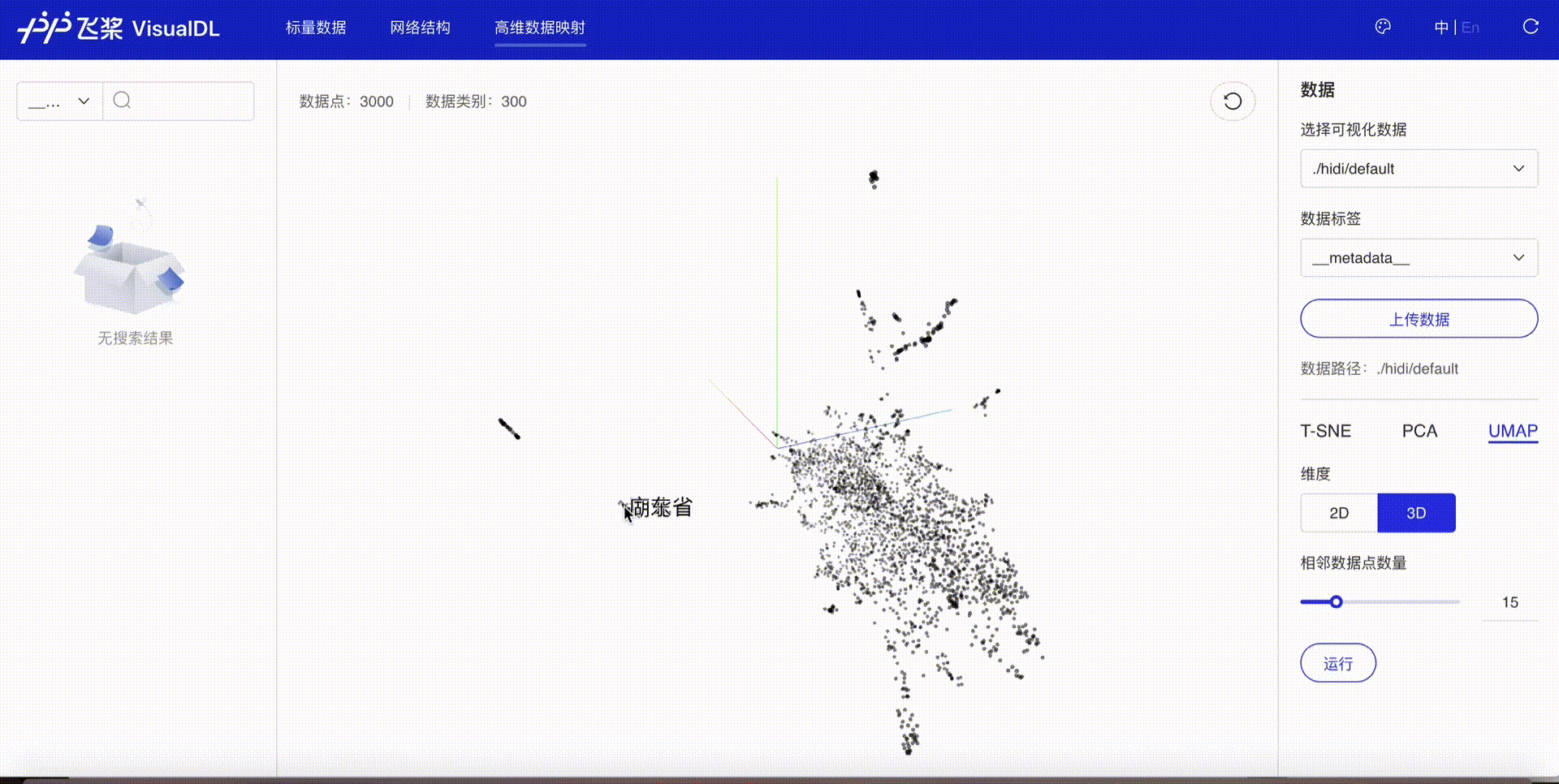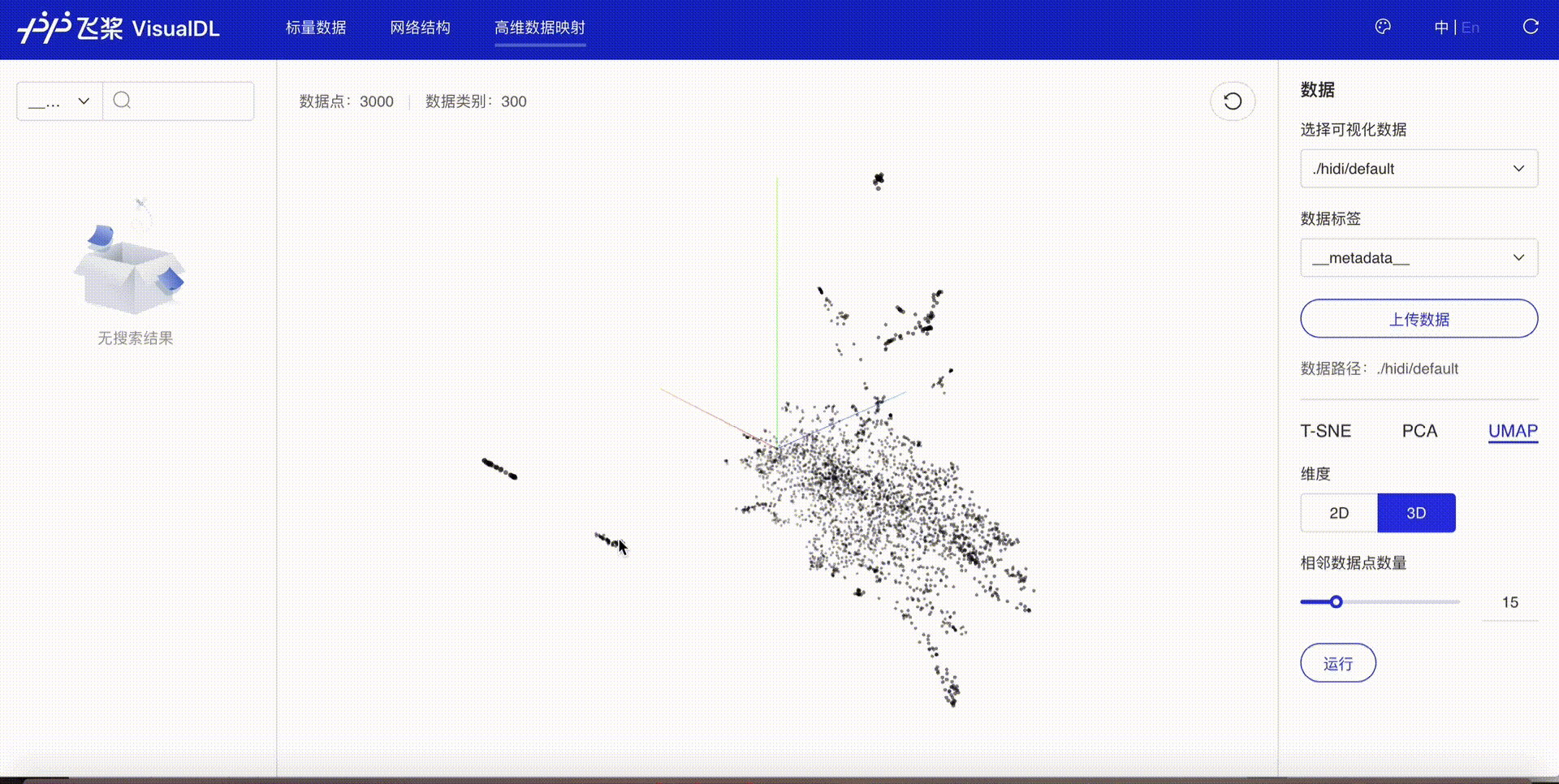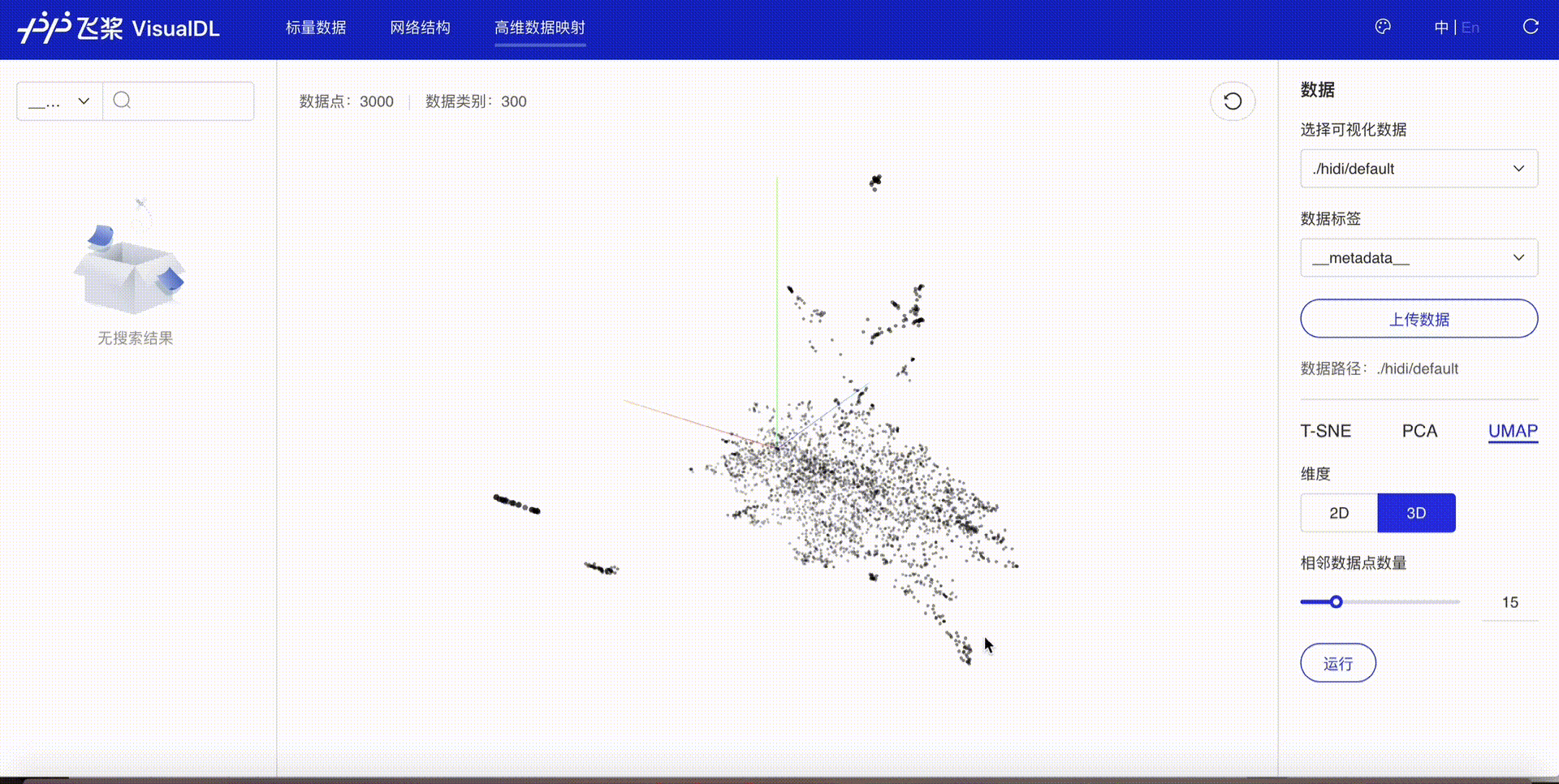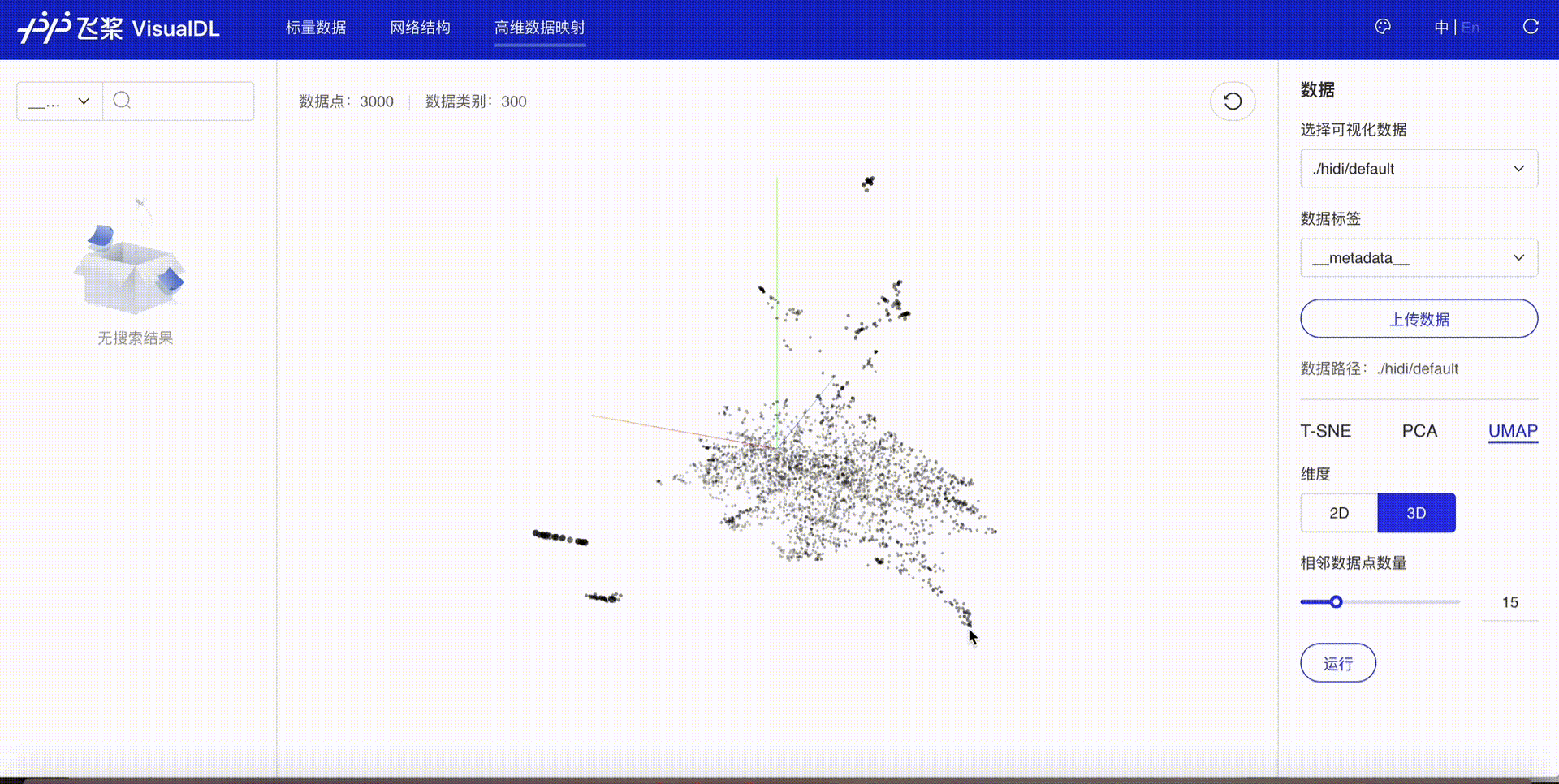
使用VisualDL除可视化embedding结果外,还可以对标量、图片、音频等进行可视化,有效提升训练调参效率。关于VisualDL更多功能和详细介绍,可参考VisualDL使用文档。
score = token_embedding.cosine_sim("中国", "美国")
print(score) # 0.49586025score = token_embedding.dot("中国", "美国")
print(score) # 8.611071以下为TokenEmbedding简单的组网使用方法。有关更多TokenEmbedding训练流程相关的使用方法,请参考Word Embedding with PaddleNLP。
in_words = paddle.to_tensor([0, 2, 3])
input_embeddings = token_embedding(in_words)
linear = paddle.nn.Linear(token_embedding.embedding_dim, 20)
input_fc = linear(input_embeddings)
print(input_fc)
Tensor(shape=[3, 20], dtype=float32, place=CPUPlace, stop_gradient=False,
[[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[-0.23473957, 0.17878169, 0.07215232, ..., 0.03698236, 0.14291850, 0.05136518],
[-0.42466098, 0.15017235, -0.04780108, ..., -0.04995505, 0.15847842, 0.00025209]])from paddlenlp.data import JiebaTokenizer
tokenizer = JiebaTokenizer(vocab=token_embedding.vocab)
words = tokenizer.cut("中国人民")
print(words) # ['中国人', '民']
tokens = tokenizer.encode("中国人民")
print(tokens) # [12530, 1334]以下将列举PaddleNLP支持的Embedding预训练模型。
- 模型命名方式为:${训练模型}.${语料}.${词向量类型}.${co-occurrence type}.dim${维度}。
- 模型有三种,分别是Word2Vec(w2v, skip-gram), GloVe(glove)和FastText(fasttext)。
以下预训练词向量由Chinese-Word-Vectors提供。
根据不同类型的上下文为每个语料训练多个目标词向量,第二列开始表示不同类型的上下文。以下为上下文类别:
- Word表示训练时目标词预测的上下文是一个Word。
- Word + N-gram表示训练时目标词预测的上下文是一个Word或者Ngram,其中bigram表示2-grams,ngram.1-2表示1-gram或者2-grams。
- Word + Character表示训练时目标词预测的上下文是一个Word或者Character,其中word-character.char1-2表示上下文是1个或2个Character。
- Word + Character + Ngram表示训练时目标词预测的上下文是一个Word、Character或者Ngram。bigram-char表示上下文是2-grams或者1个Character。
| 语料 | Word | Word + N-gram | Word + Character | Word + Character + N-gram |
|---|---|---|---|---|
| Baidu Encyclopedia 百度百科 | w2v.baidu_encyclopedia.target.word-word.dim300 | w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | w2v.baidu_encyclopedia.target.bigram-char.dim300 |
| Wikipedia_zh 中文维基百科 | w2v.wiki.target.word-word.dim300 | w2v.wiki.target.word-bigram.dim300 | w2v.wiki.target.word-char.dim300 | w2v.wiki.target.bigram-char.dim300 |
| People's Daily News 人民日报 | w2v.people_daily.target.word-word.dim300 | w2v.people_daily.target.word-bigram.dim300 | w2v.people_daily.target.word-char.dim300 | w2v.people_daily.target.bigram-char.dim300 |
| Sogou News 搜狗新闻 | w2v.sogou.target.word-word.dim300 | w2v.sogou.target.word-bigram.dim300 | w2v.sogou.target.word-char.dim300 | w2v.sogou.target.bigram-char.dim300 |
| Financial News 金融新闻 | w2v.financial.target.word-word.dim300 | w2v.financial.target.word-bigram.dim300 | w2v.financial.target.word-char.dim300 | w2v.financial.target.bigram-char.dim300 |
| Zhihu_QA 知乎问答 | w2v.zhihu.target.word-word.dim300 | w2v.zhihu.target.word-bigram.dim300 | w2v.zhihu.target.word-char.dim300 | w2v.zhihu.target.bigram-char.dim300 |
| Weibo 微博 | w2v.weibo.target.word-word.dim300 | w2v.weibo.target.word-bigram.dim300 | w2v.weibo.target.word-char.dim300 | w2v.weibo.target.bigram-char.dim300 |
| Literature 文学作品 | w2v.literature.target.word-word.dim300 | w2v.literature.target.word-bigram.dim300 | w2v.literature.target.word-char.dim300 | w2v.literature.target.bigram-char.dim300 |
| Complete Library in Four Sections 四库全书 | w2v.sikuquanshu.target.word-word.dim300 | w2v.sikuquanshu.target.word-bigram.dim300 | 无 | 无 |
| Mixed-large 综合 | w2v.mixed-large.target.word-word.dim300 | 暂无 | w2v.mixed-large.target.word-word.dim300 | 暂无 |
特别地,对于百度百科语料,在不同的 Co-occurrence类型下分别提供了目标词与上下文向量:
| Co-occurrence 类型 | 目标词向量 | 上下文词向量 |
|---|---|---|
| Word → Word | w2v.baidu_encyclopedia.target.word-word.dim300 | w2v.baidu_encyclopedia.context.word-word.dim300 |
| Word → Ngram (1-2) | w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | w2v.baidu_encyclopedia.context.word-ngram.1-2.dim300 |
| Word → Ngram (1-3) | w2v.baidu_encyclopedia.target.word-ngram.1-3.dim300 | w2v.baidu_encyclopedia.context.word-ngram.1-3.dim300 |
| Ngram (1-2) → Ngram (1-2) | w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 | w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 |
| Word → Character (1) | w2v.baidu_encyclopedia.target.word-character.char1-1.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-1.dim300 |
| Word → Character (1-2) | w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-2.dim300 |
| Word → Character (1-4) | w2v.baidu_encyclopedia.target.word-character.char1-4.dim300 | w2v.baidu_encyclopedia.context.word-character.char1-4.dim300 |
| Word → Word (left/right) | w2v.baidu_encyclopedia.target.word-wordLR.dim300 | w2v.baidu_encyclopedia.context.word-wordLR.dim300 |
| Word → Word (distance) | w2v.baidu_encyclopedia.target.word-wordPosition.dim300 | w2v.baidu_encyclopedia.context.word-wordPosition.dim300 |
| 语料 | 名称 |
|---|---|
| Google News | w2v.google_news.target.word-word.dim300.en |
| 语料 | 25维 | 50维 | 100维 | 200维 | 300 维 |
|---|---|---|---|---|---|
| Wiki2014 + GigaWord | 无 | glove.wiki2014-gigaword.target.word-word.dim50.en | glove.wiki2014-gigaword.target.word-word.dim100.en | glove.wiki2014-gigaword.target.word-word.dim200.en | glove.wiki2014-gigaword.target.word-word.dim300.en |
| glove.twitter.target.word-word.dim25.en | glove.twitter.target.word-word.dim50.en | glove.twitter.target.word-word.dim100.en | glove.twitter.target.word-word.dim200.en | 无 |
| 语料 | 名称 |
|---|---|
| Wiki2017 | fasttext.wiki-news.target.word-word.dim300.en |
| Crawl | fasttext.crawl.target.word-word.dim300.en |
以上所述的模型名称可直接以参数形式传入padddlenlp.embeddings.TokenEmbedding,加载相对应的模型。比如要加载语料为Wiki2017,通过FastText训练的预训练模型(fasttext.wiki-news.target.word-word.dim300.en),只需执行以下代码:
import paddle
from paddlenlp.embeddings import TokenEmbedding
token_embedding = TokenEmbedding(embedding_name="fasttext.wiki-news.target.word-word.dim300.en")| 模型 | 文件大小 | 词表大小 |
|---|---|---|
| w2v.baidu_encyclopedia.target.word-word.dim300 | 678.21 MB | 635965 |
| w2v.baidu_encyclopedia.target.word-character.char1-1.dim300 | 679.15 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-character.char1-2.dim300 | 679.30 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-character.char1-4.dim300 | 679.51 MB | 636038 |
| w2v.baidu_encyclopedia.target.word-ngram.1-2.dim300 | 679.48 MB | 635977 |
| w2v.baidu_encyclopedia.target.word-ngram.1-3.dim300 | 671.27 MB | 628669 |
| w2v.baidu_encyclopedia.target.word-ngram.2-2.dim300 | 7.28 GB | 6969069 |
| w2v.baidu_encyclopedia.target.word-wordLR.dim300 | 678.22 MB | 635958 |
| w2v.baidu_encyclopedia.target.word-wordPosition.dim300 | 679.32 MB | 636038 |
| w2v.baidu_encyclopedia.target.bigram-char.dim300 | 679.29 MB | 635976 |
| w2v.baidu_encyclopedia.context.word-word.dim300 | 677.74 MB | 635952 |
| w2v.baidu_encyclopedia.context.word-character.char1-1.dim300 | 678.65 MB | 636200 |
| w2v.baidu_encyclopedia.context.word-character.char1-2.dim300 | 844.23 MB | 792631 |
| w2v.baidu_encyclopedia.context.word-character.char1-4.dim300 | 1.16 GB | 1117461 |
| w2v.baidu_encyclopedia.context.word-ngram.1-2.dim300 | 7.25 GB | 6967598 |
| w2v.baidu_encyclopedia.context.word-ngram.1-3.dim300 | 5.21 GB | 5000001 |
| w2v.baidu_encyclopedia.context.word-ngram.2-2.dim300 | 7.26 GB | 6968998 |
| w2v.baidu_encyclopedia.context.word-wordLR.dim300 | 1.32 GB | 1271031 |
| w2v.baidu_encyclopedia.context.word-wordPosition.dim300 | 6.47 GB | 6293920 |
| w2v.wiki.target.bigram-char.dim300 | 375.98 MB | 352274 |
| w2v.wiki.target.word-char.dim300 | 375.52 MB | 352223 |
| w2v.wiki.target.word-word.dim300 | 374.95 MB | 352219 |
| w2v.wiki.target.word-bigram.dim300 | 375.72 MB | 352219 |
| w2v.people_daily.target.bigram-char.dim300 | 379.96 MB | 356055 |
| w2v.people_daily.target.word-char.dim300 | 379.45 MB | 355998 |
| w2v.people_daily.target.word-word.dim300 | 378.93 MB | 355989 |
| w2v.people_daily.target.word-bigram.dim300 | 379.68 MB | 355991 |
| w2v.weibo.target.bigram-char.dim300 | 208.24 MB | 195199 |
| w2v.weibo.target.word-char.dim300 | 208.03 MB | 195204 |
| w2v.weibo.target.word-word.dim300 | 207.94 MB | 195204 |
| w2v.weibo.target.word-bigram.dim300 | 208.19 MB | 195204 |
| w2v.sogou.target.bigram-char.dim300 | 389.81 MB | 365112 |
| w2v.sogou.target.word-char.dim300 | 389.89 MB | 365078 |
| w2v.sogou.target.word-word.dim300 | 388.66 MB | 364992 |
| w2v.sogou.target.word-bigram.dim300 | 388.66 MB | 364994 |
| w2v.zhihu.target.bigram-char.dim300 | 277.35 MB | 259755 |
| w2v.zhihu.target.word-char.dim300 | 277.40 MB | 259940 |
| w2v.zhihu.target.word-word.dim300 | 276.98 MB | 259871 |
| w2v.zhihu.target.word-bigram.dim300 | 277.53 MB | 259885 |
| w2v.financial.target.bigram-char.dim300 | 499.52 MB | 467163 |
| w2v.financial.target.word-char.dim300 | 499.17 MB | 467343 |
| w2v.financial.target.word-word.dim300 | 498.94 MB | 467324 |
| w2v.financial.target.word-bigram.dim300 | 499.54 MB | 467331 |
| w2v.literature.target.bigram-char.dim300 | 200.69 MB | 187975 |
| w2v.literature.target.word-char.dim300 | 200.44 MB | 187980 |
| w2v.literature.target.word-word.dim300 | 200.28 MB | 187961 |
| w2v.literature.target.word-bigram.dim300 | 200.59 MB | 187962 |
| w2v.sikuquanshu.target.word-word.dim300 | 20.70 MB | 19529 |
| w2v.sikuquanshu.target.word-bigram.dim300 | 20.77 MB | 19529 |
| w2v.mixed-large.target.word-char.dim300 | 1.35 GB | 1292552 |
| w2v.mixed-large.target.word-word.dim300 | 1.35 GB | 1292483 |
| w2v.google_news.target.word-word.dim300.en | 1.61 GB | 3000000 |
| glove.wiki2014-gigaword.target.word-word.dim50.en | 73.45 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim100.en | 143.30 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim200.en | 282.97 MB | 400002 |
| glove.wiki2014-gigaword.target.word-word.dim300.en | 422.83 MB | 400002 |
| glove.twitter.target.word-word.dim25.en | 116.92 MB | 1193516 |
| glove.twitter.target.word-word.dim50.en | 221.64 MB | 1193516 |
| glove.twitter.target.word-word.dim100.en | 431.08 MB | 1193516 |
| glove.twitter.target.word-word.dim200.en | 848.56 MB | 1193516 |
| fasttext.wiki-news.target.word-word.dim300.en | 541.63 MB | 999996 |
| fasttext.crawl.target.word-word.dim300.en | 1.19 GB | 2000002 |
- 感谢 Chinese-Word-Vectors提供Word2Vec中文预训练词向量。
- 感谢 GloVe Project提供的GloVe英文预训练词向量。
- 感谢 FastText Project提供的英文预训练词向量。
- Li, Shen, et al. "Analogical reasoning on chinese morphological and semantic relations." arXiv preprint arXiv:1805.06504 (2018).
- Qiu, Yuanyuan, et al. "Revisiting correlations between intrinsic and extrinsic evaluations of word embeddings." Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data. Springer, Cham, 2018. 209-221.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.
- T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, A. Joulin. Advances in Pre-Training Distributed Word Representations.