Description: Use Google BERT on fake_or_real news dataset with best f1 score: 0.986
- Google-BERT-on-fake_or_real-news-dataset
- Showcase
- Implementation
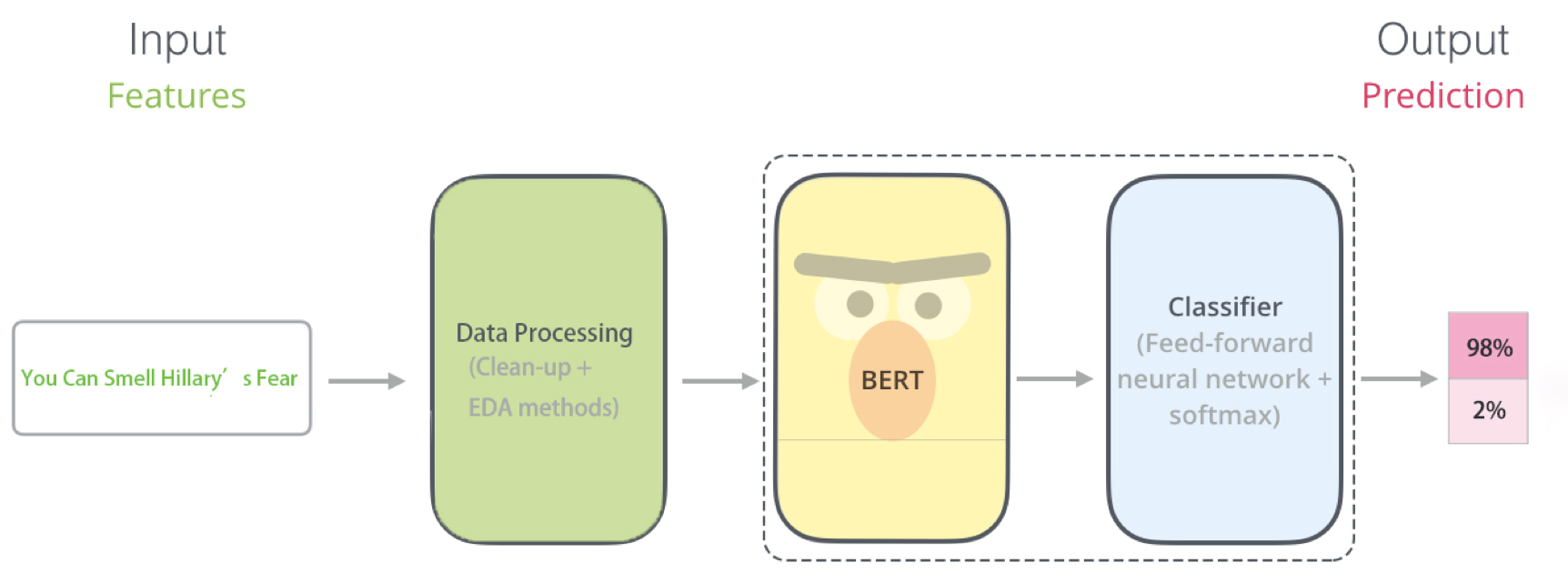
First, we got the raw text with title, text and label. Then we use some methods of data processing to operate the text. After the data processing, we put them into the Bert model to train the data, which includes the Bert itself and the Classifier, here I used the feed-forward neural network and add a softmax layer to normalize the output. In the end, we got the predication and other details.
(1) Drop non-sentence
• Type1: http[s]://www.claritypress.com/LendmanIII.html
• Type2: [email protected]
• Type3: @EP_President #EP_President
• Type4: **Want FOX News First * in your inbox every day? Sign up here.**
• Type5: ☮️ 💚 🌍 etc
(2) EDA methods
• Insert word by BERT similarity (Random Insertion)
• Substitute word by BERT similarity (Synonym Replacement)
AS for the first part, I use two methods: drop non-sentence and some EDA methods. I read some text within the fake_or_real news and I find that it contains various type of non-sentence, so I use the regular expression to drop them. And then, I use random insertion and synonym replacement to augment the text.
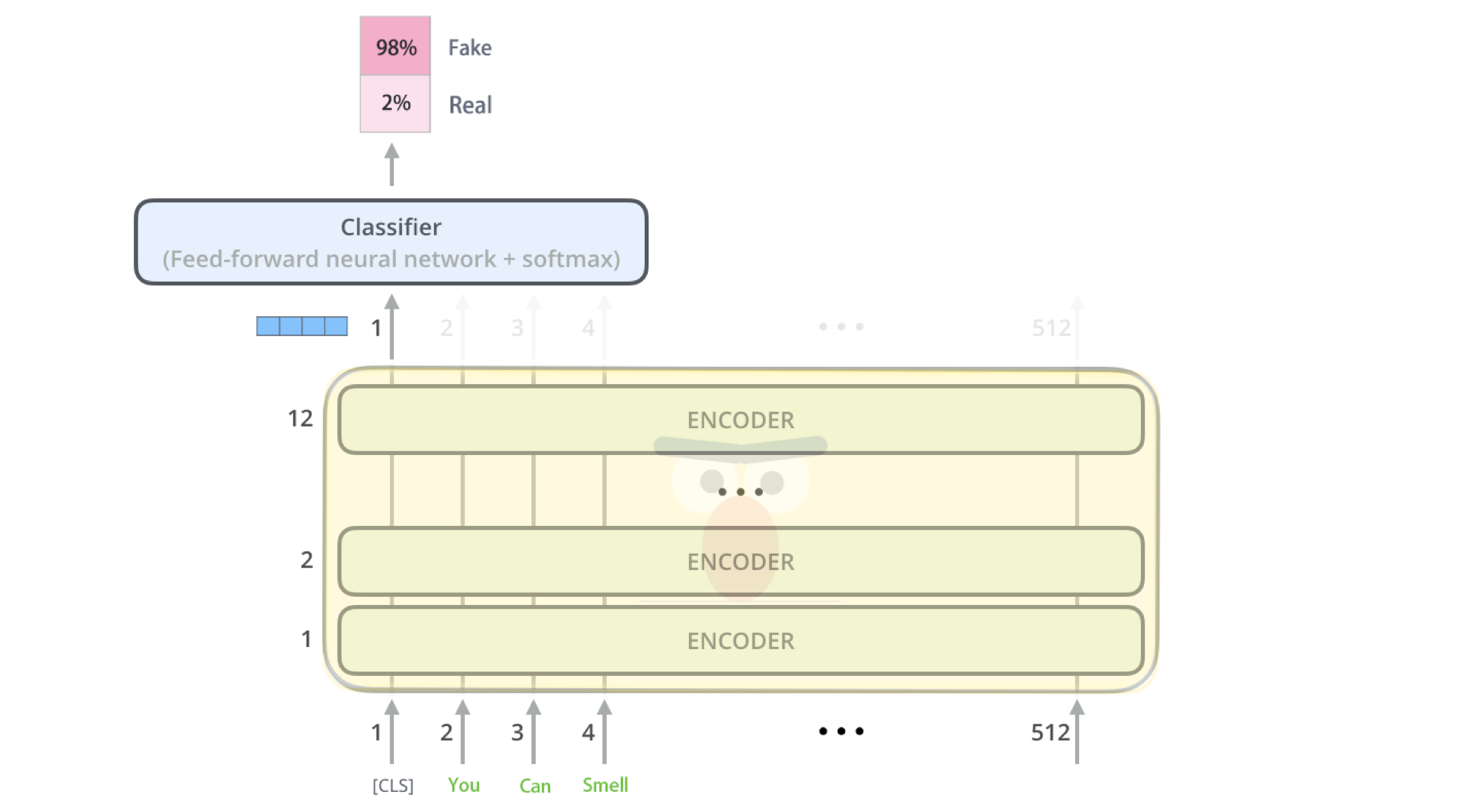
As for the second part, we put the text which we got from the first part into the bert model. The Bert model uses 12 encode layers and finally classifier to get the output.
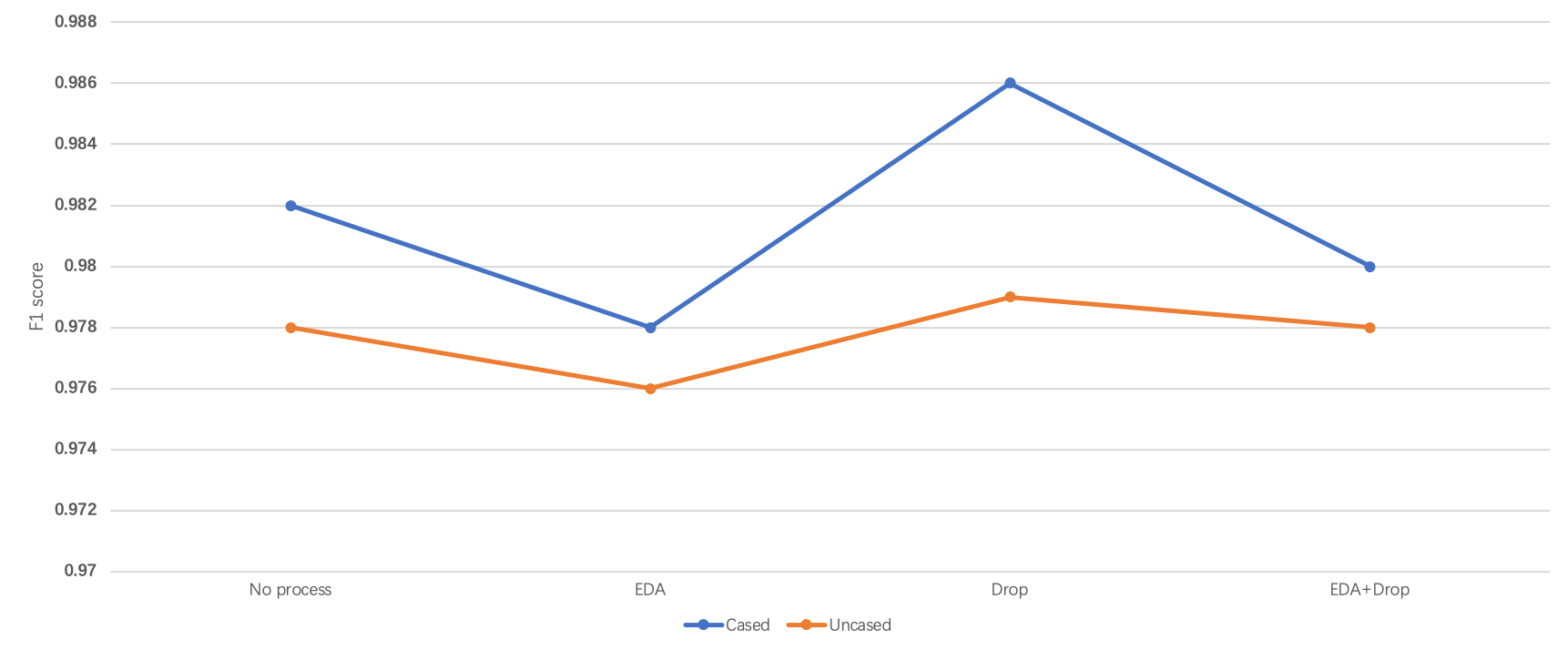
In the end, we combine different methods of data processing and u can see the f1 score from the chart. We get the best f1 score(0.986) from Cased text + drop sentence.
(1) EDA:
•Knowledge: https://towardsdatascience.com/these-are-the-easiest-data-augmentation-techniques-in-natural-language-processing-you-can-think-of-88e393fd610
•Implemenation: https://github.com/makcedward/nlpaug
(2) Can’t remove stopwords:
•Deeper Text Understanding for IR with Contextual NeuralLanguage Modeling: https://arxiv.org/pdf/1905.09217
•Understanding the Behaviors of BERT in Ranking : https://arxiv.org/pdf/1904.07531
(3) Bert by Pytorch:
•https://pytorch.org/hub/huggingface_pytorch-pretrained-bert_bert/
(4) Bert Demo:
https://github.com/sugi-chan/custom_bert_pipeline
(5) Dataset:
https://cbmm.mit.edu/sites/default/files/publications/fake-news-paper-NIPS.pdf
I learn the EDA from the two web site and through two articles, I learn that we shouldn’t remove Stopwords which otherwise will destroy the context of sentence. The end is implementation of BERT with Pytorch and the Bert model I learned.
## parameters Setting
par_cased = 0 # default cased, 0 means uncased
par_cleanup = 1 # default cleanup, 0 means non-cleanup
par_eda = 0 # default eda, 0 means non-eda
pip install pytorch_pretrained_bert nlpaug bert matplotlib sklearn librosa SoundFile nltk pandas
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from random import randrange
import torch.nn.functional as F
from sklearn.metrics import roc_curve, auc
import nlpaug.augmenter.char as nac
#import nlpaug.augmenter.word as naw
import nlpaug.flow as naf
from nlpaug.util import Actionimport torch
from pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM
# OPTIONAL: if you want to have more information on what's happening, activate the logger as follows
import logging
logging.basicConfig(level=logging.INFO)
# Load pre-trained model tokenizer (vocabulary)
if par_cased ==1:
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
else:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')class BertLayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
"""Construct a layernorm module in the TF style (epsilon inside the square root).
"""
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
class BertForSequenceClassification(nn.Module):
"""BERT model for classification.
This module is composed of the BERT model with a linear layer on top of
the pooled output.
Params:
`config`: a BertConfig class instance with the configuration to build a new model.
`num_labels`: the number of classes for the classifier. Default = 2.
Inputs:
`input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
with the word token indices in the vocabulary. Items in the batch should begin with the special "CLS" token. (see the tokens preprocessing logic in the scripts
`extract_features.py`, `run_classifier.py` and `run_squad.py`)
`token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
a `sentence B` token (see BERT paper for more details).
`attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
input sequence length in the current batch. It's the mask that we typically use for attention when
a batch has varying length sentences.
`labels`: labels for the classification output: torch.LongTensor of shape [batch_size]
with indices selected in [0, ..., num_labels].
Outputs:
if `labels` is not `None`:
Outputs the CrossEntropy classification loss of the output with the labels.
if `labels` is `None`:
Outputs the classification logits of shape [batch_size, num_labels].
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
token_type_ids = torch.LongTensor([[0, 0, 1], [0, 1, 0]])
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
num_labels = 2
model = BertForSequenceClassification(config, num_labels)
logits = model(input_ids, token_type_ids, input_mask)
```
"""
def __init__(self, num_labels=2):
super(BertForSequenceClassification, self).__init__()
self.num_labels = num_labels
if par_cased ==1:
self.bert = BertModel.from_pretrained('bert-base-cased')
else:
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, num_labels)
nn.init.xavier_normal_(self.classifier.weight)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None):
_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
def freeze_bert_encoder(self):
for param in self.bert.parameters():
param.requires_grad = False
def unfreeze_bert_encoder(self):
for param in self.bert.parameters():
param.requires_grad = True
from pytorch_pretrained_bert import BertConfig
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072)
num_labels = 2
model = BertForSequenceClassification(num_labels)
# Convert inputs to PyTorch tensors
#tokens_tensor = torch.tensor([tokenizer.convert_tokens_to_ids(zz)])
#logits = model(tokens_tensor)import pandas as pd
dat = pd.read_csv('/data/fake_or_real_news.csv')
dat.head()
dat = dat.drop(columns=['Unnamed: 0', 'title_vectors'])
for i in range(len(dat)):
if dat.loc[i, 'label'] == "REAL": #REAL equal 0
dat.loc[i, 'label'] = 0
elif dat.loc[i, 'label'] == "FAKE": #FAKE equal 1
dat.loc[i, 'label'] = 1
if dat.loc[i, 'text'] == "":
dat = dat.drop([i])
dat.head()dat_plus = dat.copy()
dat_plus['title_text']=dat['title']+'. '+dat['text']
dat_plus = dat_plus.drop(columns=['title', 'text'])
dat_plus['title_text']import re
def cleanup(text):
if par_cased == 0: # transfer into lower text if par_cased is false
text = text.lower()
text = re.sub(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+','',text) # drop http[s]://*
text = re.sub(u"\\{.*?}|\\[.*?]",'',text) # drop [*]
text = re.sub(u"\(\@.*?\s", '', text) # drop something like (@EP_President)
text = re.sub(u"\@.*?\s", '', text) # drop soething liek @EP_President
text = re.sub(u"\#.*?\s", '', text) # drop something like #EP_President (maybe hashtag)
text = re.sub(u"\© .*?\s", '', text) # drop something like © EP_President
text = re.sub(r'pic.tw(?:[a-zA-Z]|[0-9]|[$-_@.&+#]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+','',text) # drop pic.twitter.com/*
text = re.sub(u"\*\*", '', text) # drop something like **Want FOX News First * in your inbox every day? Sign up here.**
text = re.sub(u"|•|☮️|💚|🌍|😍|♦|☢", '', text) # drop something like and • etc
return(text)import nlpaug.augmenter.char as nac
import nlpaug.augmenter.word as naw
import nlpaug.flow as nafc
from nlpaug.util import Action
import nltk
nltk.download('punkt')
if par_cased ==1:
aug = naf.Sequential([
naw.BertAug(action="substitute", aug_p=0.8, aug_n=20,model_path='bert-base-cased',tokenizer_path='bert-base-cased'),
naw.BertAug(action="insert", aug_p=0.1)
])
else:
aug = naf.Sequential([
naw.BertAug(action="substitute", aug_p=0.8, aug_n=20,model_path='bert-base-uncased',tokenizer_path='bert-base-uncased'),
naw.BertAug(action="insert", aug_p=0.1)
])
def aug_text(text):
text = aug.augment(text)
return(text)
from nltk.tokenize import sent_tokenize
def sentence_token_nltk(text):
sent_tokenize_list = sent_tokenize(text)
return sent_tokenize_list
def eda_text(text):
if len(text) < 2:
return(text)
# split text into sentences
text = sentence_token_nltk(text)
if len(text) <= 1:
return(text)
if len(text) == 2:
for i in range(len(text)):
if i == 0:
tmp_text = text[i]
else:
tmp_text += text[i]
return(tmp_text)
# operate prior 3 sentences
for i in range(3):
if i == 0:
tmp_text = text[i]
else:
tmp_text += text[i]
zz = tokenizer.tokenize(tmp_text)
# operate proper sentences
if len(zz) <= 500:
#print(len(zz))
tmp_text = aug_text(tmp_text)
# conbine prior 3 sentences and rest sentences
for j in range(len(text)-3):
tmp_text += text[j+3]
return(tmp_text)
if par_eda == 1: # use eda to operate sentences when par_eda is true
for i in range(len(dat_plus['title_text'])):
if i%6 == 1:
#print(i)
dat_plus['title_text'][i] = copy.deepcopy(eda_text(dat_plus['title_text'][i]))
dat_plus['title_text'][i] = "".join(dat_plus['title_text'][i])import torch.nn.functional as F
#F.softmax(logits,dim=1)
from sklearn.model_selection import train_test_split
if par_cleanup == 1:
X = dat_plus['title_text'].apply(cleanup)
else:
X = dat_plus['title_text']
y = dat_plus['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
X_train = X_train.values.tolist()
X_test = X_test.values.tolist()
y_train = pd.get_dummies(y_train).values.tolist() # convert to one-hot encoding
y_test = pd.get_dummies(y_test).values.tolist()
max_seq_length = 256
class text_dataset(Dataset):
def __init__(self,x_y_list, transform=None):
self.x_y_list = x_y_list
self.transform = transform
def __getitem__(self,index):
tokenized_title_text = tokenizer.tokenize(self.x_y_list[0][index])
if len(tokenized_title_text) > max_seq_length:
tokenized_title_text = tokenized_title_text[:max_seq_length]
ids_title_text = tokenizer.convert_tokens_to_ids(tokenized_title_text) #tokens->input_ids
padding = [0] * (max_seq_length - len(ids_title_text))
ids_title_text += padding # use padding to make the same ids
assert len(ids_title_text) == max_seq_length
#print(ids_title_text)
ids_title_text = torch.tensor(ids_title_text)
label = self.x_y_list[1][index] # color
list_of_labels = [torch.from_numpy(np.array(label))]
return ids_title_text, list_of_labels[0]
def __len__(self):
return len(self.x_y_list[0])batch_size = 16 # divide into 16 batches
train_lists = [X_train, y_train]
test_lists = [X_test, y_test]
training_dataset = text_dataset(x_y_list = train_lists )
test_dataset = text_dataset(x_y_list = test_lists )
dataloaders_dict = {'train': torch.utils.data.DataLoader(training_dataset, batch_size=batch_size, shuffle=True, num_workers=0),
'val':torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
}
dataset_sizes = {'train':len(train_lists[0]),
'val':len(test_lists[0])}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device) def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
print('starting')
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 100
best_f1 = 0.978
best_acc_test = 0.96
best_acc_train = 0.96
best_auc = 0.96
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
label_corrects = 0
TP = 0
TN = 0
FN = 0
FP = 0
total_scores = []
total_tar = []
# Iterate over data.
for inputs, label in dataloaders_dict[phase]:
#inputs = inputs
#print(len(inputs),type(inputs),inputs)
#inputs = torch.from_numpy(np.array(inputs)).to(device)
inputs = inputs.to(device)
label = label.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# acquire output
outputs = model(inputs)
outputs = F.softmax(outputs,dim=1)
loss = criterion(outputs, torch.max(label.float(), 1)[1])
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
label_corrects += torch.sum(torch.max(outputs, 1)[1] == torch.max(label, 1)[1]) #返回每一行中最大值的那个元素,且返回其索引(返回最大元素在这一行的列索引)
pred_choice = torch.max(outputs, 1)[1]
target = torch.max(label, 1)[1]
scores = pred_choice.cpu().tolist()
tar = target.cpu().tolist()
total_scores = total_scores + scores
total_tar = total_tar + tar
tmp_tp = 0
tmp_tn = 0
tmp_fn = 0
tmp_fp = 0
if pred_choice.numel()!= target.numel():
print("error")
for i in range(pred_choice.numel()):
if pred_choice[i] == 1 and target[i] == 1 :
tmp_tp = tmp_tp + 1
elif pred_choice[i] == 0 and target[i] == 0 :
tmp_tn = tmp_tn + 1
elif pred_choice[i] == 0 and target[i] == 1 :
tmp_fn = tmp_fn + 1
elif pred_choice[i] == 1 and target[i] == 0 :
tmp_fp = tmp_fp + 1
# TP both predict and label are 1
TP += tmp_tp
# TN both predict and label are 0
TN += tmp_tn
# FN predict 0 label 1
FN += tmp_fn
# FP predict 1 label 0
FP += tmp_fp
epoch_loss = running_loss / dataset_sizes[phase]
p = TP / (TP + FP)
r = TP / (TP + FN)
F1 = 2 * r * p / (r + p)
acc = (TP + TN) / (TP + TN + FP + FN)
### draw ROC curce
tpr = TP/(TP+FN)
fpr = FP/(FP+TN)
tnr = TN/(FP+TN)
total_scores = np.array(total_scores)
total_tar = np.array(total_tar)
fpr, tpr, thresholds = roc_curve(total_tar, total_scores)
roc_auc = auc(fpr, tpr)
plt.title('ROC')
if roc_auc > best_auc:
best_auc = roc_auc
if epoch < num_epochs -1:
plt.plot(fpr, tpr,'b',label='AUC = %0.4f'% roc_auc)
if epoch == num_epochs -1:
plt.plot(fpr, tpr, color='darkorange', label='MAX AUC = %0.4f'% best_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
plt.show()
#print('{} p: {:.4f} '.format(phase,p ))
#print('{} r: {:.4f} '.format(phase,r ))
print('{} F1: {:.4f} '.format(phase,F1 ))
print('{} accuracy: {:.4f} '.format(phase,acc ))
if phase == 'val' and epoch_loss < best_loss:
print('saving with loss of {}'.format(epoch_loss),
'improved over previous {}'.format(best_loss))
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
#torch.save(model.state_dict(), '/content/drive/My Drive/Colab Notebooks/bert_model_test_loss.pth')
if F1 > best_f1:
best_f1 = F1
if phase == 'val' and acc > best_acc_test:
best_acc_test = acc
if phase == 'train' and acc > best_acc_train:
best_acc_train = acc
#best_model_wts = copy.deepcopy(model.state_dict())
#torch.save(model.state_dict(), '/content/drive/My Drive/Colab Notebooks/bert_model_test_f1.pth')
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print("Parament setting: ")
print("cased: ",par_cased)
print("cleanup: ",par_cleanup)
print("eda: ",par_eda)
print('Best train Acc: {:4f}'.format(float(best_acc_train)))
print('Best test Acc: {:4f}'.format(float(best_acc_test)))
print('Best f1 score: {:4f}'.format(float(best_f1)))
# load best model weights
model.load_state_dict(best_model_wts)
return modelprint(model)
model.to(device)model_ft1 = train_model(model, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=10)