Learn data engineering fundamentals by constructing a modern data stack for analytics and machine learning applications. We'll also learn how to orchestrate our data workflows and programmatically execute tasks to prepare our high quality data for downstream consumers (analytics, ML, etc.)


👉 This repository contains the code that complements the data stack and orchestration lessons which is a part of the MLOps course. If you haven't already, be sure to check out the lessons because all the concepts are covered extensively and tied to data engineering best practices for building the data stack for ML systems.

At a high level, we're going to:
- Extract and Load data from sources to destinations.
- Transform for downstream applications.
This process is more commonly known as ELT, but there are variants such as ETL and reverse ETL, etc. They are all essentially the same underlying workflows but have slight differences in the order of data flow and where data is processed and stored.
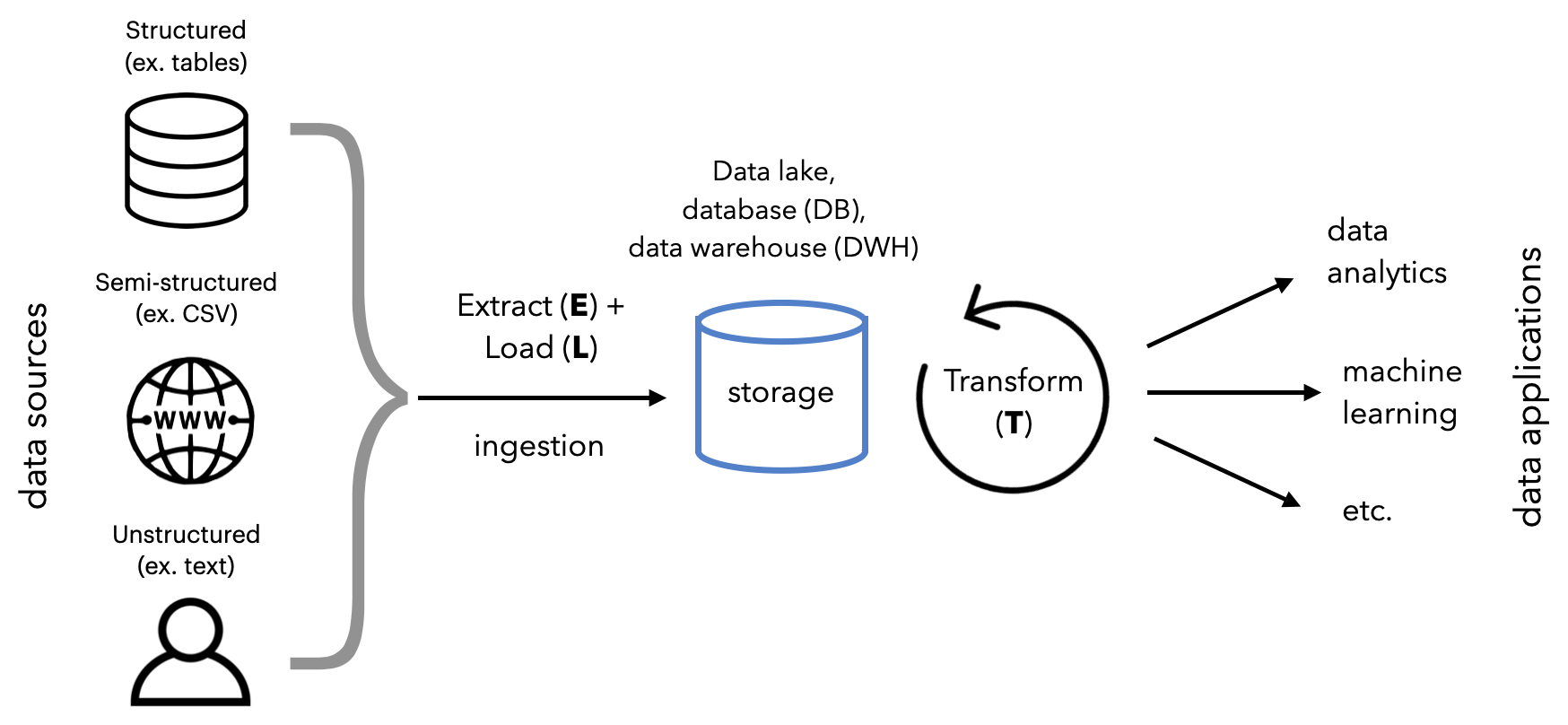
The first step in our data pipeline is to extract data from a source and load it into the appropriate destination. While we could construct custom scripts to do this manually or on a schedule, an ecosystem of data ingestion tools have already standardized the entire process. They all come equipped with connectors that allow for extraction, normalization, cleaning and loading between sources and destinations. And these pipelines can be scaled, monitored, etc. all with very little to no code.
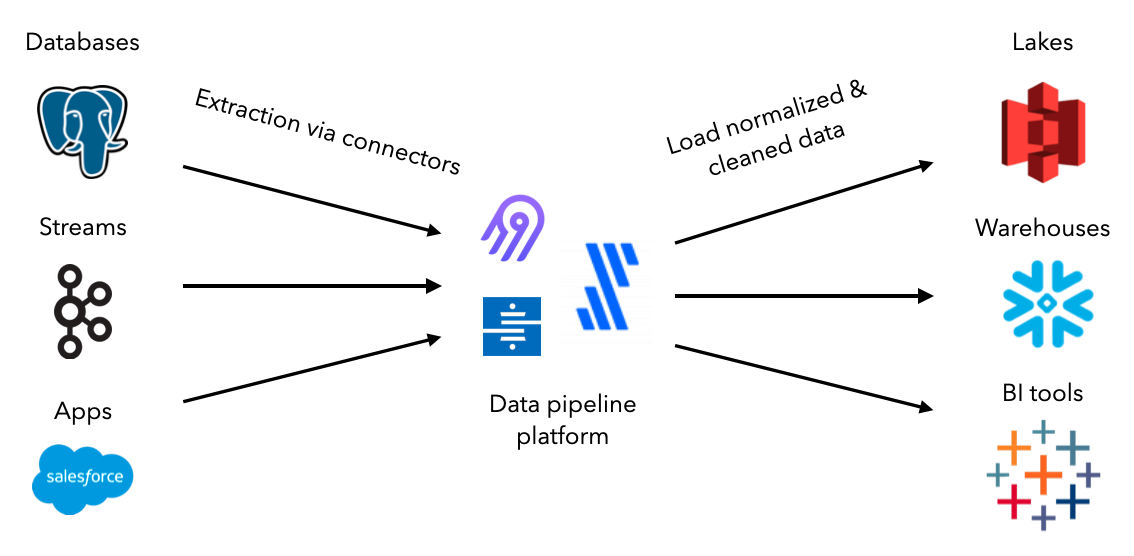
We're going to use the open-source tool Airbyte to create connections between our data sources and destinations. Let's set up Airbyte and define our data sources. As we progress in this lesson, we'll set up our destinations and create connections to extract and load data.
- Ensure that we still have Docker installed from our Docker lesson but if not, download it here. For Windows users, be sure to have these configurations enabled.
- In a parent directory, outside our project directory for the MLOps course, execute the following commands to load the Airbyte repository locally and launch the service.
git clone https://github.com/airbytehq/airbyte.git
cd airbyte
docker-compose up- After a few minutes, visit http://localhost:8000/ to view the launched Airbyte service.
We'll start our ELT process by defining the data source in Airbyte:
- On our Airbyte UI, click on
Sourceson the left menu. Then click the+ New sourcebutton on the top right corner. - Click on the
Source typedropdown and chooseFile. This will open a view to define our file data source.
Name: Projects
URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv
File Format: csv
Storage Provider: HTTPS: Public Web
Dataset Name: projects- Click the
Set up sourcebutton and our data source will be tested and saved. - Repeat steps 1-3 for our tags data source as well:
Name: Tags
URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv
File Format: csv
Storage Provider: HTTPS: Public Web
Dataset Name: tags
Once we know the source we want to extract data from, we need to decide the destination to load it. The choice depends on what our downstream applications want to be able to do with the data. And it's also common to store data in one location (ex. data lake) and move it somewhere else (ex. data warehouse) for specific processing.
Our destination will be a data warehouse since we'll want to use the data for downstream analytical and machine learning applications. We're going to use Google BigQuery which is free under Google Cloud's free tier for up to 10 GB storage and 1TB of queries (which is significantly more than we'll ever need for our purpose).
- Log into your Google account{:target="_blank} and then head over to Google CLoud. If you haven't already used Google Cloud's free trial, you'll have to sign up. It's free and you won't be autocharged unless you manually upgrade your account. Once the trial ends, we'll still have the free tier which is more than plenty for us.
- Go to the Google BigQuery page{:target="_blank} and click on the
Go to consolebutton. - We can create a new project by following these instructions which will lead us to the create project page.
Project name: made-with-ml # Google will append a unique ID to the end of it
Location: No organization- Once the project has been created, refresh the page and we should see it (along with few other default projects from Google).
# Google BigQuery projects
├── made-with-ml-XXXXXX 👈 our project
├── bigquery-publicdata
├── imjasonh-storage
└── nyc-tlcNext, we need to establish the connection between Airbyte and BigQuery so that we can load the extracted data to the destination. In order to authenticate our access to BigQuery with Airbyte, we'll need to create a service account and generate a secret key. This is basically creating an identity with certain access that we can use for verification. Follow these instructions to create a service and generate the key file (JSON). Note down the location of this file because we'll be using it throughout this lesson. For example ours is /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json.
- On our Airbyte UI, click on
Destinationson the left menu. Then click the+ New destinationbutton on the top right corner. - Click on the
Destination typedropdown and chooseBigQuery. This will open a view to define our file data source.
Name: BigQuery
Default Dataset ID: mlops_course # where our data will go inside our BigQuery project
Project ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID
Credentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location
Dataset location: US # select US or EU, all other options will not be compatible with dbt later- Click the
Set up destinationbutton and our data destination will be tested and saved.

Now we're ready to create the connection between our sources and destination:
- On our Airbyte UI, click on
Connectionson the left menu. Then click the+ New connectionbutton on the top right corner. - Under
Select a existing source, click on theSourcedropdown and chooseProjectsand clickUse existing source. - Under
Select a existing destination, click on theDestinationdropdown and chooseBigQueryand clickUse existing destination.
Connection name: Projects <> BigQuery
Replication frequency: Manual
Destination Namespace: Mirror source structure
Normalized tabular data: True # leave this selected- Click the
Set up connectionbutton and our connection will be tested and saved. - Repeat the same for our
Tagssource with the sameBigQuerydestination.
Notice that our sync mode is
Full refresh | Overwritewhich means that every time we sync data from our source, it'll overwrite the existing data in our destination. As opposed toFull refresh | Appendwhich will add entries from the source to bottom of the previous syncs.
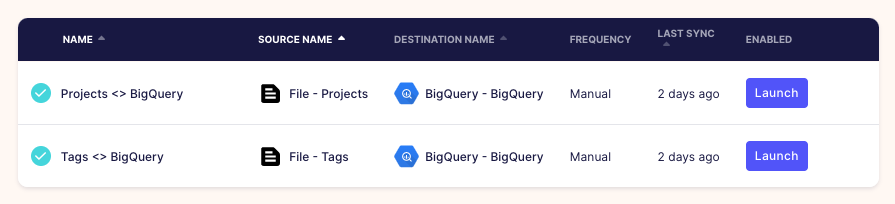
Our replication frequency is Manual because we'll trigger the data syncs ourselves:
- On our Airbyte UI, click on
Connectionson the left menu. Then click theProjects <> BigQueryconnection we set up earlier. - Press the
🔄 Sync nowbutton and once it's completed we'll see that the projects are now in our BigQuery data warehouse. - Repeat the same with our
Tags <> BigQueryconnection.
# Inside our data warehouse
made-with-ml-XXXXXX - Project
└── mlops_course - Dataset
│ ├── _airbyte_raw_projects - table
│ ├── _airbyte_raw_tags - table
│ ├── projects - table
│ └── tags - tableIn our orchestration lesson, we'll use Airflow to programmatically execute the data sync.
We can easily explore and query this data using SQL directly inside our warehouse:
- On our BigQuery project page, click on the
🔍 QUERYbutton and selectIn new tab. - Run the following SQL statement and view the data:
SELECT *
FROM `made-with-ml-XXXXXX.mlops_course.projects`
LIMIT 1000| id | created_on | title | description | |
|---|---|---|---|---|
| 0 | 6 | 2020-02-20 06:43:18 | Comparison between YOLO and RCNN on real world... | Bringing theory to experiment is cool. We can ... |
| 1 | 7 | 2020-02-20 06:47:21 | Show, Infer & Tell: Contextual Inference for C... | The beauty of the work lies in the way it arch... |
| 2 | 9 | 2020-02-24 16:24:45 | Awesome Graph Classification | A collection of important graph embedding, cla... |
| 3 | 15 | 2020-02-28 23:55:26 | Awesome Monte Carlo Tree Search | A curated list of Monte Carlo tree search papers... |
| 4 | 19 | 2020-03-03 13:54:31 | Diffusion to Vector | Reference implementation of Diffusion2Vec (Com... |
Once we've extracted and loaded our data, we need to transform the data so that it's ready for downstream applications. These transformations are different from the preprocessing we've seen before but are instead reflective of business logic that's agnostic to downstream applications. Common transformations include defining schemas, filtering, cleaning and joining data across tables, etc. While we could do all of these things with SQL in our data warehouse (save queries as tables or views), dbt delivers production functionality around version control, testing, documentation, packaging, etc. out of the box. This becomes crucial for maintaining observability and high quality data workflows.
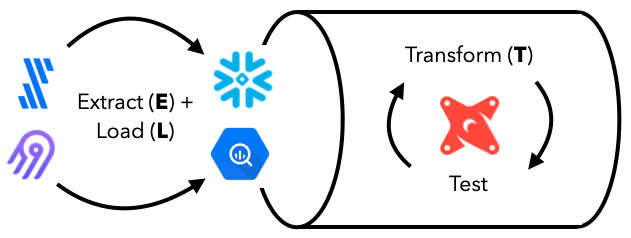
In addition to data transformations, we can also process the data using large-scale analytics engines like Spark, Flink, etc. We'll learn more about batch and stream processing in our systems design lesson.
Now we're ready to transform our data in our data warehouse using dbt. We'll be using a developer account on dbt Cloud (free), which provides us with an IDE, unlimited runs, etc.
We'll learn how to use the dbt-core in our orchestration lesson. Unlike dbt Cloud, dbt core is completely open-source and we can programmatically connect to our data warehouse and perform transformations.
- Create a free account and verify it.
- Go to https://cloud.getdbt.com/ to get set up.
- Click
continueand chooseBigQueryas the database. - Click
Upload a Service Account JSON fileand upload our file to autopopulate everything. - Click the
Test>Continue. - Click
Managedrepository and name itdbt-transforms(or anything else you want). - Click
Create>Continue>Skip and complete. - This will open the project page and click
>_ Start Developingbutton. - This will open the IDE where we can click
🗂 initialize your project.
Now we're ready to start developing our models:
- Click the
···next to themodelsdirectory on the left menu. - Click
New foldercalledmodels/labeled_projects. - Create a
New fileundermodels/labeled_projectscalledlabeled_projects.sql. - Repeat for another file under
models/labeled_projectscalledschema.yml.
dbt-cloud-XXXXX-dbt-transforms
├── ...
├── models
│ ├── example
│ └── labeled_projects
│ │ ├── labeled_projects.sql
│ │ └── schema.yml
├── ...
└── README.mdInside our models/labeled_projects/labeled_projects.sql file we'll create a view that joins our project data with the appropriate tags. This will create the labeled data necessary for downstream applications such as machine learning models. Here we're joining based on the matching id between the projects and tags:
-- models/labeled_projects/labeled_projects.sql
SELECT p.id, created_on, title, description, tag
FROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE
LEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE
ON p.id = t.idWe can view the queried results by clicking the Preview button and view the data lineage as well.
Inside our models/labeled_projects/schema.yml file we'll define the schemas for each of the features in our transformed data. We also define several tests that each feature should pass. View the full list of dbt tests but note that we'll use Great Expectations for more comprehensive tests when we orchestrate all these data workflows in our orchestration lesson.
# models/labeled_projects/schema.yml
version: 2
models:
- name: labeled_projects
description: "Tags for all projects"
columns:
- name: id
description: "Unique ID of the project."
tests:
- unique
- not_null
- name: title
description: "Title of the project."
tests:
- not_null
- name: description
description: "Description of the project."
tests:
- not_null
- name: tag
description: "Labeled tag for the project."
tests:
- not_null
At the bottom of the IDE, we can execute runs based on the transformations we've defined. We'll run each of the following commands and once they finish, we can see the transformed data inside our data warehouse.
dbt run
dbt testOnce these commands run successfully, we're ready to move our transformations to a production environment where we can insert this view in our data warehouse.
In order to apply these transformations to the data in our data warehouse, it's best practice to create an Environment and then define Jobs:
- Click
Environmentson the left menu >New Environmentbutton (top right corner) and fill out the details:
Name: Production
Type: Deployment
...
Dataset: mlops_course- Click
New Jobwith the following details and then clickSave(top right corner).
Name: Transform
Environment: Production
Commands: dbt run
dbt test
Schedule: uncheck "RUN ON SCHEDULE"- Click
Run Nowand view the transformed data in our data warehouse under a view calledlabeled_projects.
# Inside our data warehouse
made-with-ml-XXXXXX - Project
└── mlops_course - Dataset
│ ├── _airbyte_raw_projects - table
│ ├── _airbyte_raw_tags - table
│ ├── labeled_projects - view
│ ├── projects - table
│ └── tags - table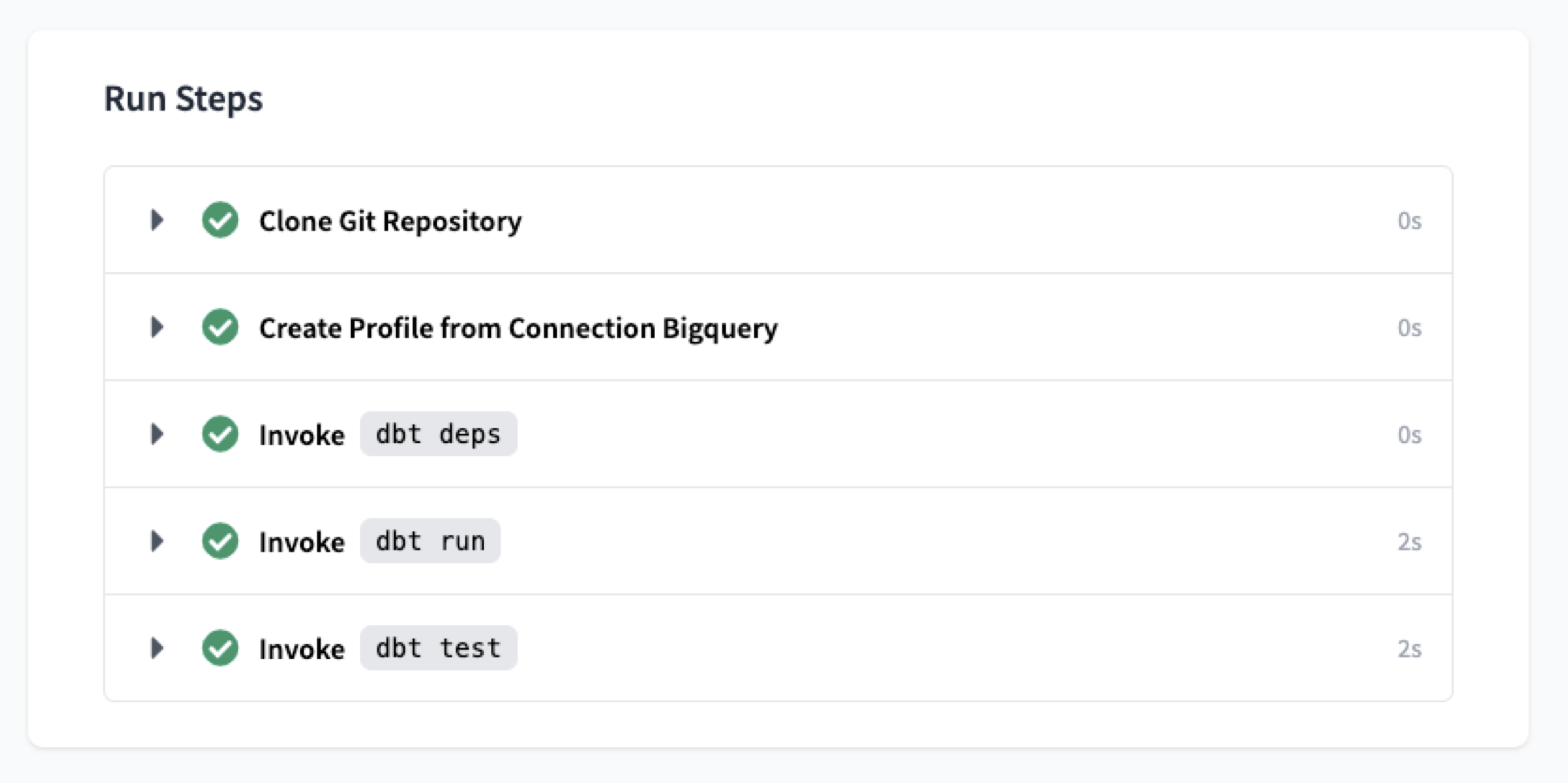
There is so much more to dbt so be sure to check out their official documentation to really customize any workflows. And be sure to check out our orchestration lesson where we'll programmatically create and execute our dbt transformations.
Hopefully we created our data stack for the purpose of gaining some actionable insight about our business, users, etc. Because it's these use cases that dictate which sources of data we extract from, how often and how that data is stored and transformed. Downstream applications of our data typically fall into one of these categories:
data analytics: use cases focused on reporting trends, aggregate views, etc. via charts, dashboards, etc.for the purpose of providing operational insight for business stakeholders.machine learning: use cases centered around using the transformed data to construct predictive models (forecasting, personalization, etc.).
!pip install google-cloud-bigquery==1.21.0 -qfrom google.cloud import bigquery
from google.oauth2 import service_account
# Replace these with your own values
project_id = "made-with-ml-XXXXXX"
SERVICE_ACCOUNT_KEY_JSON = "/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json"
# Establish connection
credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)
client = bigquery.Client(credentials= credentials, project=project_id)
# Query data
query_job = client.query("""
SELECT *
FROM mlops_course.labeled_projects""")
results = query_job.result()
results.to_dataframe().head()| id | created_on | title | description | tag | |
|---|---|---|---|---|---|
| 0 | 1994.0 | 2020-07-29 04:51:30 | Understanding the Effectivity of Ensembles in ... | The report explores the ideas presented in Dee... | computer-vision |
| 1 | 1506.0 | 2020-06-19 06:26:17 | Using GitHub Actions for MLOps & Data Science | A collection of resources on how to facilitate... | mlops |
| 2 | 807.0 | 2020-05-11 02:25:51 | Introduction to Machine Learning Problem Framing | This course helps you frame machine learning (... | mlops |
| 3 | 1204.0 | 2020-06-05 22:56:38 | Snaked: Classifying Snake Species using Images | Proof of concept that it is possible to identi... | computer-vision |
| 4 | 1706.0 | 2020-07-04 11:05:28 | PokeZoo | A deep learning based web-app developed using ... | computer-vision |
Now it's time to programmatically execute the workflows we set up above. We'll be using Airflow to author, schedule, and monitor our workflows. If you're not familiar with orchestration, be sure to check out the lesson first.
To install and run Airflow, we can either do so locally or with Docker. If using docker-compose to run Airflow inside Docker containers, we'll want to allocate at least 4 GB in memory.
# Configurations
export AIRFLOW_HOME=${PWD}/airflow
AIRFLOW_VERSION=2.3.3
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# Install Airflow (may need to upgrade pip)
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
# Initialize DB (SQLite by default)
airflow db initThis will create an airflow directory with the following components:
airflow/
├── logs/
├── airflow.cfg
├── airflow.db
├── unittests.cfg
└── webserver_config.pyWe're going to edit the airflow.cfg file to best fit our needs:
# Inside airflow.cfg
enable_xcom_pickling = True # needed for Great Expectations airflow provider
load_examples = False # don't clutter webserver with examplesAnd we'll perform a reset to implement these configuration changes.
airflow db reset -yNow we're ready to initialize our database with an admin user, which we'll use to login to access our workflows in the webserver.
# We'll be prompted to enter a password
airflow users create \
--username admin \
--firstname FIRSTNAME \
--lastname LASTNAME \
--role Admin \
--email EMAILOnce we've created a user, we're ready to launch the webserver and log in using our credentials.
# Launch webserver
source venv/bin/activate
export AIRFLOW_HOME=${PWD}/airflow
airflow webserver --port 8080 # http://localhost:8080The webserver allows us to run and inspect workflows, establish connections to external data storage, manager users, etc. through a UI. Similarly, we could also use Airflow's REST API or Command-line interface (CLI) to perform the same operations. However, we'll be using the webserver because it's convenient to visually inspect our workflows.
We'll explore the different components of the webserver as we learn about Airflow and implement our workflows.
Next, we need to launch our scheduler, which will execute and monitor the tasks in our workflows. The schedule executes tasks by reading from the metadata database and ensures the task has what it needs to finish running. We'll go ahead and execute the following commands on the separate terminal window:
# Launch scheduler (in separate terminal)
source venv/bin/activate
export AIRFLOW_HOME=${PWD}/airflow
export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
airflow schedulerWe're going to use the Airbyte connections we set up above but this time we're going to programmatically trigger the data syncs with Airflow. First, let's ensure that Airbyte is running on a separate terminal in it's repository:
git clone https://github.com/airbytehq/airbyte.git # skip if already create in data-stack lesson
cd airbyte
docker-compose upNext, let's install the required packages and establish the connection between Airbyte and Airflow:
pip install apache-airflow-providers-airbyte==3.1.0- Go to the Airflow webserver and click
Admin>Connections> ➕ - Add the connection with the following details:
Connection ID: airbyte
Connection Type: HTTP
Host: localhost
Port: 8000We could also establish connections programmatically{:target=“_blank”} but it’s good to use the UI to understand what’s happening under the hood.
In order to execute our extract and load data syncs, we can use the AirbyteTriggerSyncOperator:
# airflow/dags/workflows.py
@dag(...)
def dataops():
"""Production DataOps workflows."""
# Extract + Load
extract_and_load_projects = AirbyteTriggerSyncOperator(
task_id="extract_and_load_projects",
airbyte_conn_id="airbyte",
connection_id="XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", # REPLACE
asynchronous=False,
timeout=3600,
wait_seconds=3,
)
extract_and_load_tags = AirbyteTriggerSyncOperator(
task_id="extract_and_load_tags",
airbyte_conn_id="airbyte",
connection_id="XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", # REPLACE
asynchronous=False,
timeout=3600,
wait_seconds=3,
)
# Define DAG
extract_and_load_projects
extract_and_load_tagsWe can find the connection_id for each Airbyte connection by:
- Go to our Airbyte webserver and click
Connectionson the left menu. - Click on the specific connection we want to use and the URL should be like this:
https://demo.airbyte.io/workspaces/<WORKSPACE_ID>/connections/<CONNECTION_ID>/status- The string in the
CONNECTION_IDposition is the connection's id.
We can trigger our DAG right now and view the extracted data be loaded into our BigQuery data warehouse but we'll continue developing and execute our DAG once the entire DataOps workflow has been defined.
The specific process of where and how we extract our data can be bespoke but what's important is that we have validation at every step of the way. We'll once again use Great Expectations, as we did in our testing lesson, to validate our extracted and loaded data before transforming it.
With the Airflow concepts we've learned so far, there are many ways to use our data validation library to validate our data. Regardless of what data validation tool we use (ex. Great Expectations, TFX, AWS Deequ, etc.) we could use the BashOperator, PythonOperator, etc. to run our tests. However, Great Expectations has a Airflow Provider package to make it even easier to validate our data. This package contains a GreatExpectationsOperator which we can use to execute specific checkpoints as tasks.
pip install airflow-provider-great-expectations==0.1.1 great-expectations==0.15.19
great_expectations initThis will create the following directory within our data-engineering repository:
tests/great_expectations/
├── checkpoints/
├── expectations/
├── plugins/
├── uncommitted/
├── .gitignore
└── great_expectations.ymlBut first, before we can create our tests, we need to define a new datasource within Great Expectations for our Google BigQuery data warehouse. This will require several packages and exports:
pip install pybigquery==0.10.2 sqlalchemy_bigquery==1.4.4
export GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACEgreat_expectations datasource newWhat data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL) 👈What are you processing your files with?
1. MySQL
2. Postgres
3. Redshift
4. Snowflake
5. BigQuery 👈
6. other - Do you have a working SQLAlchemy connection string?This will open up an interactive notebook where we can fill in the following details:
datasource_name = “dwh"
connection_string = “bigquery://made-with-ml-359923/mlops_course”Next, we can create a suite of expectations for our data assets:
great_expectations suite newHow would you like to create your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data 👈
3. Automatically, using a profilerSelect a datasource
1. dwh 👈Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
1. mlops_course.projects 👈
2. mlops_course.tagsName the new Expectation Suite [mlops.projects.warning]: projectsThis will open up an interactive notebook where we can define our expectations. Repeat the same for creating a suite for our tags data asset as well.
Expectations for mlops_course.projects:
# data leak
validator.expect_compound_columns_to_be_unique(column_list=["title", "description"])# id
validator.expect_column_values_to_be_unique(column="id")
# create_on
validator.expect_column_values_to_not_be_null(column="created_on")
# title
validator.expect_column_values_to_not_be_null(column="title")
validator.expect_column_values_to_be_of_type(column="title", type_="STRING")
# description
validator.expect_column_values_to_not_be_null(column="description")
validator.expect_column_values_to_be_of_type(column="description", type_="STRING")Expectations for mlops_course.tags:
# id
validator.expect_column_values_to_be_unique(column="id")
# tag
validator.expect_column_values_to_not_be_null(column="tag")
validator.expect_column_values_to_be_of_type(column="tag", type_="STRING")Once we have our suite of expectations, we're ready to check checkpoints to execute these expectations:
great_expectations checkpoint new projectsThis will, of course, open up an interactive notebook. Just ensure that the following information is correct (the default values may not be):
datasource_name: dwh
data_asset_name: mlops_course.projects
expectation_suite_name: projectsAnd repeat the same for creating a checkpoint for our tags suite.
With our checkpoints defined, we're ready to apply them to our data assets in our warehouse.
GE_ROOT_DIR = Path(BASE_DIR, "great_expectations")
@dag(...)
def dataops():
...
validate_projects = GreatExpectationsOperator(
task_id="validate_projects",
checkpoint_name="projects",
data_context_root_dir=GE_ROOT_DIR,
fail_task_on_validation_failure=True,
)
validate_tags = GreatExpectationsOperator(
task_id="validate_tags",
checkpoint_name="tags",
data_context_root_dir=GE_ROOT_DIR,
fail_task_on_validation_failure=True,
)
# Define DAG
extract_and_load_projects >> validate_projects
extract_and_load_tags >> validate_tagsOnce we've validated our extracted and loaded data, we're ready to transform it. Our DataOps workflows are not specific to any particular downstream application so the transformation must be globally relevant (ex. cleaning missing data, aggregation, etc.). Just like in our data stack lesson, we're going to use dbt to transform our data. However, this time, we're going to do everything programmatically using the open-source dbt-core package.
In the root of our data-engineering repository, initialize our dbt directory with the following command:
dbt init dbf_transformsWhich database would you like to use?
[1] bigquery 👈Desired authentication method option:
[1] oauth
[2] service_account 👈keyfile: /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
project (GCP project id): made-with-ml-XXXXXX # REPLACE
dataset: mlops_course
threads: 1
job_execution_timeout_seconds: 300Desired location option:
[1] US 👈 # or what you picked when defining your dataset in Airbyte DWH destination setup
[2] EUWe'll prepare our dbt models as we did using the dbt Cloud IDE in the previous lesson.
cd dbt_transforms
rm -rf models/example
mkdir models/labeled_projects
touch models/labeled_projects/labeled_projects.sql
touch models/labeled_projects/schema.ymland add the following code to our model files:
-- models/labeled_projects/labeled_projects.sql
SELECT p.id, created_on, title, description, tag
FROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE
LEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE
ON p.id = t.id# models/labeled_projects/schema.yml
version: 2
models:
- name: labeled_projects
description: "Tags for all projects"
columns:
- name: id
description: "Unique ID of the project."
tests:
- unique
- not_null
- name: title
description: "Title of the project."
tests:
- not_null
- name: description
description: "Description of the project."
tests:
- not_null
- name: tag
description: "Labeled tag for the project."
tests:
- not_null
And we can use the BashOperator to execute our dbt commands like so:
DBT_ROOT_DIR = Path(BASE_DIR, "dbt_transforms")
@dag(...)
def dataops():
...
# Transform
transform = BashOperator(task_id="transform", bash_command=f"cd {DBT_ROOT_DIR} && dbt run && dbt test")
# Define DAG
extract_and_load_projects >> validate_projects
extract_and_load_tags >> validate_tags
[validate_projects, validate_tags] >> transformAnd of course, we'll want to validate our transformations beyond dbt's built-in methods, using great expectations. We'll create a suite and checkpoint as we did above for our projects and tags data assets.
great_expectations suite new # for mlops_course.labeled_projectsExpectations for mlops_course.labeled_projects:
# data leak
validator.expect_compound_columns_to_be_unique(column_list=["title", "description"])# id
validator.expect_column_values_to_be_unique(column="id")
# create_on
validator.expect_column_values_to_not_be_null(column="created_on")
# title
validator.expect_column_values_to_not_be_null(column="title")
validator.expect_column_values_to_be_of_type(column="title", type_="STRING")
# description
validator.expect_column_values_to_not_be_null(column="description")
validator.expect_column_values_to_be_of_type(column="description", type_="STRING")
# tag
validator.expect_column_values_to_not_be_null(column="tag")
validator.expect_column_values_to_be_of_type(column="tag", type_="STRING")great_expectations checkpoint new labeled_projectsdatasource_name: dwh
data_asset_name: mlops_course.labeled_projects
expectation_suite_name: labeled_projectsand just like how we added the validation task for our extracted and loaded data, we can do the same for our transformed data in Airflow:
@dag(...)
def dataops():
...
# Transform
transform = BashOperator(task_id="transform", bash_command=f"cd {DBT_ROOT_DIR} && dbt run && dbt test")
validate_transforms = GreatExpectationsOperator(
task_id="validate_transforms",
checkpoint_name="labeled_projects",
data_context_root_dir=GE_ROOT_DIR,
fail_task_on_validation_failure=True,
)
# Define DAG
extract_and_load_projects >> validate_projects
extract_and_load_tags >> validate_tags
[validate_projects, validate_tags] >> transform >> validate_transformsNow we have our entire DataOps DAG define and executing it will prepare our data from extraction to loading to transformation (and with validation at every step of the way) for downstream applications.
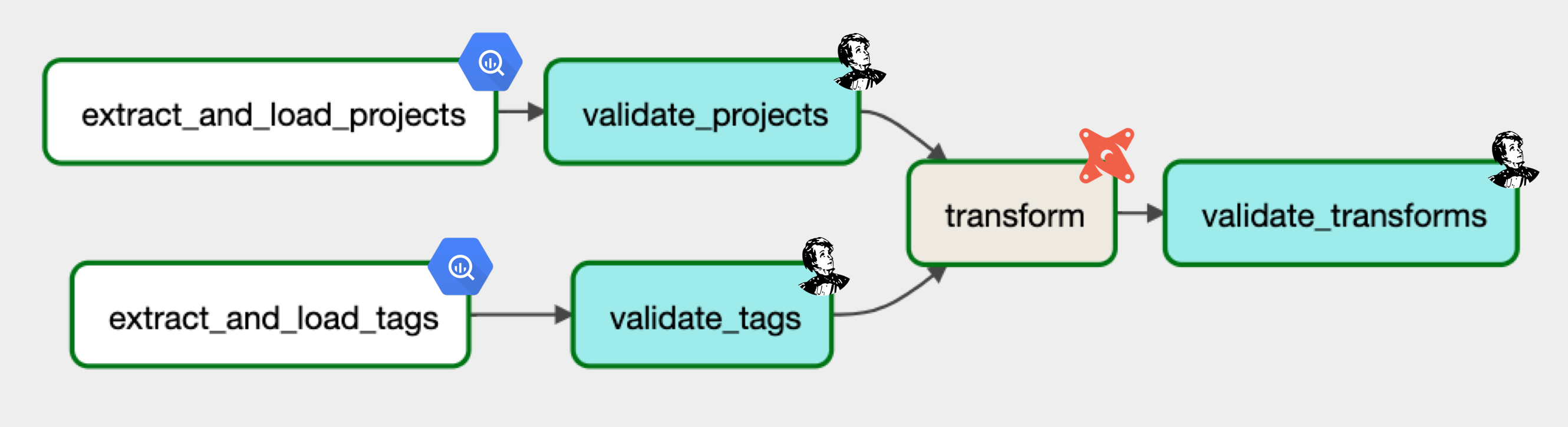
Learn a lot more about data engineering, including infrastructure that we haven't covered in code here and how it's poised for downstream analytics and machine learning applications in our data stack, orchestration and feature store lessons.