We well know GANs for success in the realistic image generation. However, they can be applied in tabular data generation. We will review and examine some recent papers about tabular GANs in action.
Medium post: GANs for tabular data
Task formalization
Let say we have T_train and T_test (train and test set respectively). We need to train the model on T_train and make predictions on T_test. However, we will increase the train by generating new data by GAN, somehow similar to T_test, without using ground truth labels of it.
Experiment design
Let say we have T_train and T_test (train and test set respectively). The size of T_train is smaller and might have different data distribution. First of all, we train CTGAN on T_train with ground truth labels (step 1), then generate additional data T_synth (step 2). Secondly, we train boosting in an adversarial way on concatenated T_train and T_synth (target set to 0) with T_test (target set to 1) (steps 3 & 4). The goal is to apply newly trained adversarial boosting to obtain rows more like T_test. Note - initial ground truth labels aren't used for adversarial training. As a result, we take top rows from T_train and T_synth sorted by correspondence to T_test (steps 5 & 6), and train new boosting on them and check results on T_test.
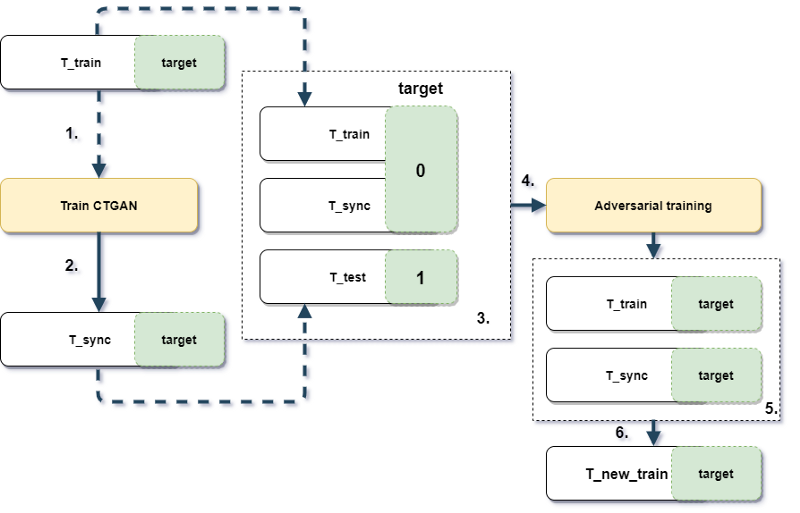
Picture 1.1 Experiment design and workflow
Of course for the benchmark purposes we will test ordinal training without these tricks and another original pipeline but without CTGAN (in step 3 we won't use T_sync).
Datasets
All datasets came from different domains. They have a different number of observations, number of categorical and numerical features. The objective for all datasets - binary classification. Preprocessing of datasets were simple: removed all time-based columns from datasets. Remaining columns were either categorical or numerical.
Table 1.1 Used datasets
| Name | Total points | Train points | Test points | Number of features | Number of categorical features | Short description |
|---|---|---|---|---|---|---|
| Telecom | 7.0k | 4.2k | 2.8k | 20 | 16 | Churn prediction for telecom data |
| Adult | 48.8k | 29.3k | 19.5k | 15 | 8 | Predict if persons' income is bigger 50k |
| Employee | 32.7k | 19.6k | 13.1k | 10 | 9 | Predict an employee's access needs, given his/her job role |
| Credit | 307.5k | 184.5k | 123k | 121 | 18 | Loan repayment |
| Mortgages | 45.6k | 27.4k | 18.2k | 20 | 9 | Predict if house mortgage is founded |
| Taxi | 892.5k | 535.5k | 357k | 8 | 5 | Predict the probability of an offer being accepted by a certain driver |
| Poverty_A | 37.6k | 22.5k | 15.0k | 41 | 38 | Predict whether or not a given household for a given country is poor or not |
To determine the best encoderthe ROC AUC scores of each dataset were scaled (min-max scale) and then averaged results among the dataset. To determine the best validation strategy, I compared the top score of each dataset for each type of validation.
Table 1.2 Different sampling results across the dataset, higher is better (100% - maximum per dataset ROC AUC)
| dataset_name | None | gan | sample_original |
|---|---|---|---|
| credit | 0.997 | 0.998 | 0.997 |
| employee | 0.986 | 0.966 | 0.972 |
| mortgages | 0.984 | 0.964 | 0.988 |
| poverty_A | 0.937 | 0.950 | 0.933 |
| taxi | 0.966 | 0.938 | 0.987 |
| adult | 0.995 | 0.967 | 0.998 |
| telecom | 0.995 | 0.868 | 0.992 |
Table 1.3 Different sampling results, higher is better for a mean (ROC AUC), lower is better for std (100% - maximum per dataset ROC AUC)
| sample_type | mean | std |
|---|---|---|
| None | 0.980 | 0.036 |
| gan | 0.969 | 0.06 |
| sample_original | 0.981 | 0.032 |
Table 1.4 same_target_prop is equal 1 then the target rate for train and test are different no more than 5%. Higher is better.
| sample_type | same_target_prop | prop_test_score |
|---|---|---|
| None | 0 | 0.964 |
| None | 1 | 0.985 |
| gan | 0 | 0.966 |
| gan | 1 | 0.945 |
| sample_original | 0 | 0.973 |
| sample_original | 1 | 0.984 |
[1] Jonathan Hui. GAN — What is Generative Adversarial Networks GAN? (2018), medium article
[2]Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generative Adversarial Networks (2014). arXiv:1406.2661
[3] Lei Xu LIDS, Kalyan Veeramachaneni. Synthesizing Tabular Data using Generative Adversarial Networks (2018). arXiv:1811.11264v1 [cs.LG]
[4] Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni. Modeling Tabular Data using Conditional GAN (2019). arXiv:1907.00503v2 [cs.LG]
[5] Denis Vorotyntsev. Benchmarking Categorical Encoders (2019). Medium post
[6] Insaf Ashrapov. GAN-for-tabular-data (2020). Github repository.
[7] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila. Analyzing and Improving the Image Quality of StyleGAN (2019) arXiv:1912.04958v2 [cs.CV]