用于学习的TTS算法项目,推理速度比较慢,但diffusion是大趋势

 Grad-TTS-CFM Framework
Grad-TTS-CFM Framework
-
从 NVIDIA/BigVGAN 下载声码器模型 bigvgan_base_24khz_100band
将 g_05000000 放到 ./bigvgan_pretrain/g_05000000
-
从 Executedone/Chinese-FastSpeech2 下载BERT韵律模型 prosody_model
将 best_model.pt 改名为 prosody_model.pt,并放到 ./bert/prosody_model.pt
-
从Release页面下载TTS模型 grad_tts.pt from release page
将 grad_tts.pt 放到当前目录,或者任意地方
-
安装环境依赖
pip install -r requirements.txt
cd ./grad/monotonic_align
python setup.py build_ext --inplace
cd -
-
推理测试
python inference.py --file test.txt --checkpoint grad_tts.pt --timesteps 10 --temperature 1.015
生成音频在文件夹
./inference_outtimesteps越大效果越好、推理时间越久;当被设置为0, 将跳过diffusion、输出FrameEncoder生成的mel谱temperature决定diffusion推理添加的噪声量,需要调试出最佳值
-
下载 标贝数据 官方连接: https://www.data-baker.com/data/index/TNtts/
将
Waves放到 ./data/Waves将
000001-010000.txt放到 ./data/000001-010000.txt -
重采样到24KHz,因为采用BigVGAN 24K模型
python tools/preprocess_a.py -w ./data/Wave/ -o ./data/wavs -s
24000 -
提取mel谱,替换声码器需注意,mel参数写死在代码中
python tools/preprocess_m.py --wav data/wavs/ --out data/mels/
-
提取BERT韵律向量,同时生成训练索引文件
train.txt和valid.txtpython tools/preprocess_b.py
输出包括
data/berts/和data/files注意:打印信息,是在剔除
儿化音(项目为算法演示,不做生产) -
额外说明
原始标注为
000001 卡尔普#2陪外孙#1玩滑梯#4。 ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1 000002 假语村言#2别再#1拥抱我#4。 jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3
需要标注为,BERT需要汉字
卡尔普陪外孙玩滑梯。(包括标点),TTS需要声韵母sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil000001 卡尔普陪外孙玩滑梯。 ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1 sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil 000002 假语村言别再拥抱我。 jia2 yu3 cun1 yan2 bie2 zai4 yong1 bao4 wo3 sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil
训练标注为
./data/wavs/000001.wav|./data/mels/000001.pt|./data/berts/000001.npy|sil k a2 ^ er2 p u3 p ei2 ^ uai4 s uen1 ^ uan2 h ua2 t i1 sp sil ./data/wavs/000002.wav|./data/mels/000002.pt|./data/berts/000002.npy|sil j ia2 ^ v3 c uen1 ^ ian2 b ie2 z ai4 ^ iong1 b ao4 ^ uo3 sp sil遇到这句话会出错
002365 这图#2难不成#2是#1P过的#4? zhe4 tu2 nan2 bu4 cheng2 shi4 P IY1 guo4 de5
-
调试dataset
python tools/preprocess_d.py
-
启动训练
python train.py
-
恢复训练
python train.py -p logs/new_exp/grad_tts_***.pt
python inference.py --file test.txt --checkpoint ./logs/new_exp/grad_tts_***.pt --timesteps 20 --temperature 1.15

https://github.com/huawei-noah/Speech-Backbones/blob/main/Grad-TTS
https://github.com/shivammehta25/Matcha-TTS
https://github.com/thuhcsi/LightGrad
https://github.com/Executedone/Chinese-FastSpeech2
https://github.com/PlayVoice/vits_chinese
https://github.com/NVIDIA/BigVGAN
Official implementation of the Grad-TTS model based on Diffusion Probabilistic Modelling. For all details check out our paper accepted to ICML 2021 via this link.
Authors: Vadim Popov*, Ivan Vovk*, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov.
*Equal contribution.
Demo page with voiced abstract: link.
Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score.
- HiFi-GAN model is used as vocoder, official github repository: link.
- Monotonic Alignment Search algorithm is used for unsupervised duration modelling, official github repository: link.
- Phonemization utilizes CMUdict, official github repository: link.
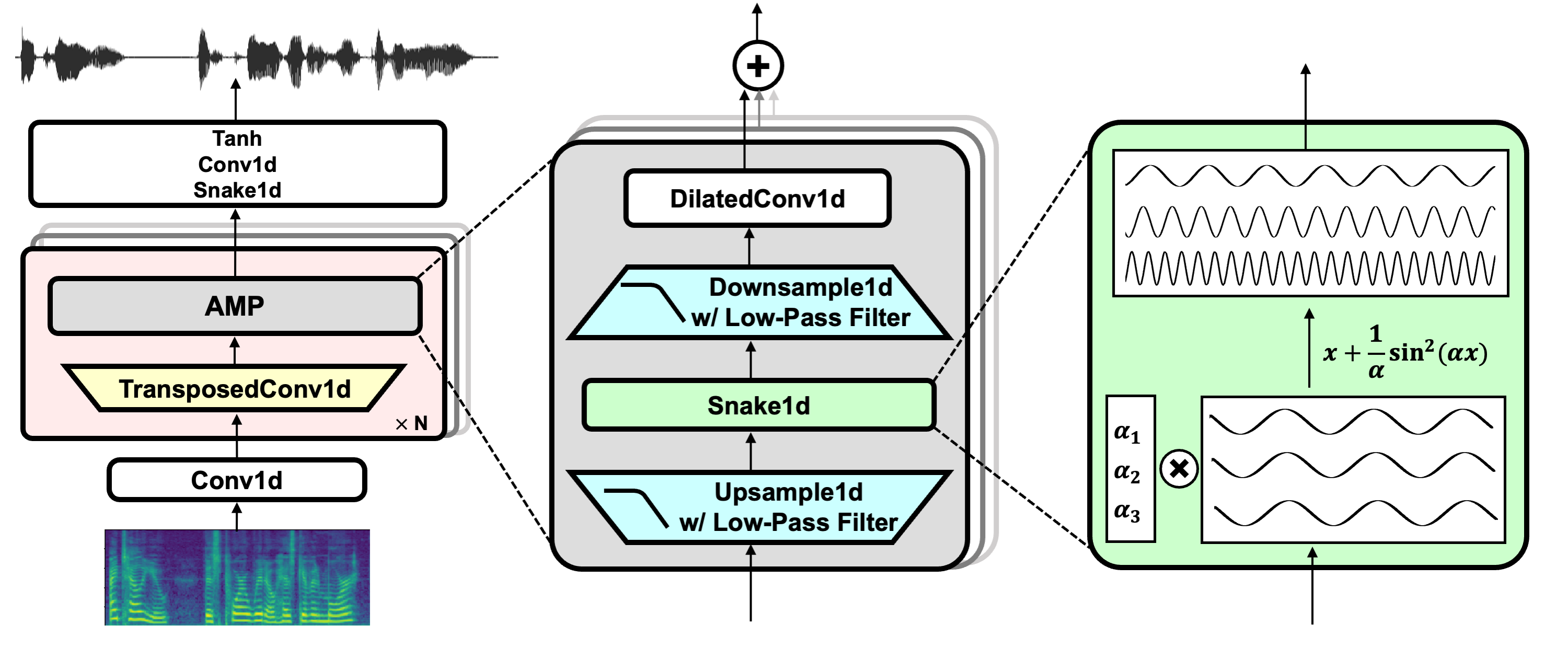
project link: https://github.com/NVIDIA/BigVGAN
dowdload pretrain model bigvgan_base_24khz_100band
python bigvgan/inference.py \
--input_wavs_dir bigvgan_debug \
--output_dir bigvgan_outpython bigvgan/train.py --config bigvgan_pretrain/config.json
-
HiFi-GAN (for generator and multi-period discriminator)
-
Snake (for periodic activation)
-
Alias-free-torch (for anti-aliasing)
-
Julius (for low-pass filter)
-
UnivNet (for multi-resolution discriminator)