Note : Repo won't be updated in the near future and is probably broken, due to the UI changes. You can still update the selenium script to get it back on track!
A python command-line scrapper for Okcupid.
Since the last big UI update (2018 I guess), no working open-source Okcupid scraper was available. Fear not ! Here it comes again !
As Okcupid is javascript-heavy and uses anti-scraping patterns, the scrapper tends to be a little bit slow (around 3k profiles per 24h). I'd recommend using it over a very good connection (> 5 MBps download, > 1 MBps upload) as a slow loading of the page tends to break it.
Please note that altough it uses the pickle package, there is no .pkl file included. It's just for saving a loading your account's cookies in a simple and foolproof way.
Open an issue to share feedback or propose features. Star the repo if you like it! 🌟
As humans more and more absorbed in their smartphones and computers, they tend to use them predominantly for all sorts of things :
- Grocery shopping
- Dentist appointment
- Watching tv
- Reading books
- Discussing politics
And...
- Mating
Okcupid and similar apps/websites have indeed become the primary way of finding a mate in the US, as of 2017 :
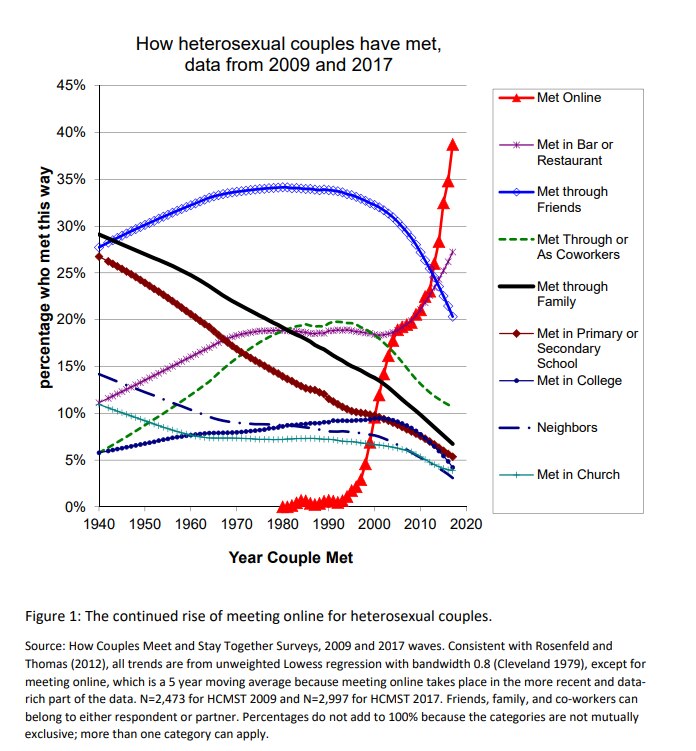
There is a lot to learn about how people present themselves in the online world, what they reflect on and so on. Hacking the process of finding a mate can be a part of it, as a Chris McKinlay did few years ago (Using data science for finding a girlfriend ! Eternal respect !)
Besides, Okcupid has been a great trove of data for aspiring Data Scientists looking for "real-world" datasets to analyse. A research paper was even written about it : OkCupid Data for Introductory Statistics and Data Science Courses, Kim, Albert Y.; Escobedo-Land, Adriana,Journal of Statistics Education, v23 n2 2015
- The dataset will contain personal information that have not been anonymised. As I used those sites before, I'm not sure I'd have liked to have my intro jokes recorded on the open web forever.
Please do not release the data you've gathered if you haven't aggregated the results before.
- Scraping it yourself gives you more flexibility for the kind of data you're looking for. For instance, currently, all "old" OkC datasets are about 'murica' but with this you can scrape the Old World or even Asia !
Ready to try ?
For now, you'll have to build it yourself (everything is explained below), but I'll send it to Pypi once I feel it's good enough™ for publication.
Fork the scrapper by clicking on the "Fork" button, in the up-right corner.
Once the forking process is complete, you should have a fork (essentially a copy) of my template in your own GitHub account. On the GitHub page for your repository, click on the green “Clone or download” button, and copy the URL: we’ll need it for the next step.
Next, we want to download the files from your GitHub repository onto your local machine.
-
Choose a directory on your local drive and in the command line,
cdto it. -
Replace in the command below with the URL you copied in the previous step, then execute this command:
git clone <YOUR_COPIED_URL_HERE> okcupidon-package
For this to work, you should have Python 3 installed on your computer. I'd advise to use a virtual environment, as always.
-
cd to the 'okcupidon-package' folder. if you use
ls, you should see asetup.pyfile in the directory. -
Type
python setup.py sdist- this command will tell python to look for the packages' files and build it nicely. -
Now you should have a new folder, called
dist, with aokcupidon-0.0.tar.gzfile inside - this is the package ! -
You can now install the package using
pip install \path\to\okcupidon-0.0.tar.gz
It should work. If it doesn't, please open a ticket and tell me !
-
You need to execute this package as a standalone program :
python -m okcupidon -
Help about the variables and the commands is available as such :
python -m okcupidon --help
usage: __main__.py [-h] [-i ID] [-p PWD] [-c COOKIES_FILE] [-s]
[--no-save-config] [--print-config]
[--max-query-attempts MAX_QUERY_ATTEMPTS]
[--outfile OUTFILE] [--num-profiles NUM_PROFILES]
{print_config,run} ...
positional arguments:
{print_config,run}
print_config Print contents of config file.
run Run the webscrapper.
optional arguments:
-h, --help show this help message and exit
-i ID, --id ID The email used to log in Okcupid
-p PWD, --pwd PWD The password used to log in Okcupid
-c COOKIES_FILE, --cookies_file COOKIES_FILE
Name or absolute path to the .json filecontaining the
OKC cookies (credentials)necessary to view user
profiles.
-s, --store_cookies Store session cookies as a .pkl file - useful if you
are logging for the first timeusing id and pwd
--no-save-config If used, any other cl-args provided are not saved to
the config.ini file. This arg does not require a
value.
--print-config Print contents of config file.
--max-query-attempts MAX_QUERY_ATTEMPTS
The number of attempts to make when requesting a
webpage, in case the first request is not successful.
--outfile OUTFILE Name or absolute path of the sql file in which to
store the collected usernames.
--num-profiles NUM_PROFILES
Integer specifying the number of profiles to
browse.Set by default to 3, for testing purposesYou should set an OkCupid profile by yourself. Phone numbers can be set for free with Twilio - "testing" bonus is quite generous. Keep in mind that the parameters (ex: Man/woman, Sexuality, etc.) will influence which profiles you'll see. I'd advise to set it the widest possible.
Configuration file can be seen with the print_config command :
python -m okcupidon print_config
Configuration is set in CLI and is memorized by the package :
- -i myemail@example.com <- this is your mail
- -p pa55word <- this is your password
- --num-profiles <- How many profiles would you like to scrape, sir ?
So we can configure the scrapper as such python -m okcupidon -i myemail@example.com -p pa55word --num-profiles 10000
Options can also be set. Check the help for more info.
From experience, I'd set a --max-query-attempts at 20 or above :
python -m okcupidon --max-query-attempts 20
You can get this way more than 1000 profiles per 'scrape round' of about 12 hours before the scraper gets in trouble.
Once your config is all set up, you can trigger the run command : python -m okcupidon run
Since Okcupid may ask you for 2-factor identification (text-message) the first time. Once it's done, the scraper saves a cookie which will enable it to log seamlessly. You just need to wait for 5 seconds and see if the program asks you for the code that was sent to you. You can also provide a cookie file name with the -c option.
The package will output an SQLite database for you to use. It has two tables :
- profile_id - gathers all the profile ids visited
- profile_info - gathers every bit of info on profiles visited (exc. questions and photos) in a "long" format.
The DB file is by default named okc_db. It will increment if you start again the scrapper (duplicates may appear however).