

CRSLab is an open-source toolkit for building Conversational Recommender System (CRS). It is developed based on Python and PyTorch. CRSLab has the following highlights:
- Comprehensive benchmark models and datasets: We have integrated commonly-used 6 datasets and 18 models, including graph neural network and pre-training models such as R-GCN, BERT and GPT-2. We have preprocessed these datasets to support these models, and release for downloading.
- Extensive and standard evaluation protocols: We support a series of widely-adopted evaluation protocols for testing and comparing different CRS.
- General and extensible structure: We design a general and extensible structure to unify various conversational recommendation datasets and models, in which we integrate various built-in interfaces and functions for quickly development.
- Easy to get started: We provide simple yet flexible configuration for new researchers to quickly start in our library.
- Human-machine interaction interfaces: We provide flexible human-machine interaction interfaces for researchers to conduct qualitative analysis.
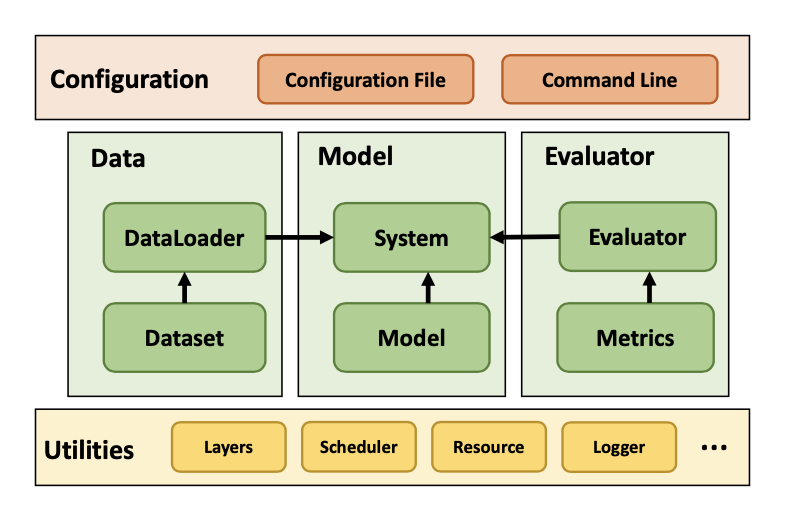
Figure 1: The overall framework of CRSLab
CRSLab works with the following operating systems:
- Linux
- Windows 10
- macOS X
CRSLab requires Python version 3.7 or later.
CRSLab requires torch version 1.8. If you want to use CRSLab with GPU, please ensure that CUDA or CUDAToolkit version is 10.2 or later. Please use the combinations shown in this Link to ensure the normal operation of PyTorch Geometric.
Use PyTorch Locally Installation or Previous Versions Installation commands to install PyTorch. For example, on Linux and Windows 10:
# CUDA 10.2
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
# CUDA 11.1
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
# CPU Only
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly -c pytorchIf you want to use CRSLab with GPU, make sure the following command prints True after installation:
$ python -c "import torch; print(torch.cuda.is_available())"
>>> TrueEnsure that at least PyTorch 1.8.0 is installed:
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0Find the CUDA version PyTorch was installed with:
$ python -c "import torch; print(torch.version.cuda)"
>>> 11.1For Linux:
Install the relevant packages:
conda install pyg -c pyg
For others:
Check PyG installation documents to install the relevant packages.
You can install from pip:
pip install crslabOR install from source:
git clone https://github.com/RUCAIBox/CRSLab && cd CRSLab
pip install -e .With the source code, you can use the provided script for initial usage of our library with cpu by default:
python run_crslab.py --config config/crs/kgsf/redial.yamlThe system will complete the data preprocessing, and training, validation, testing of each model in turn. Finally it will get the evaluation results of specified models.
If you want to save pre-processed datasets and training results of models, you can use the following command:
python run_crslab.py --config config/crs/kgsf/redial.yaml --save_data --save_systemIn summary, there are following arguments in run_crslab.py:
--configor-c: relative path for configuration file(yaml).--gpuor-g: specify GPU id(s) to use, we now support multiple GPUs. Defaults to CPU(-1).--save_dataor-sd: save pre-processed dataset.--restore_dataor-rd: restore pre-processed dataset from file.--save_systemor-ss: save trained system.--restore_systemor-rs: restore trained system from file.--debugor-d: use validation dataset to debug your system.--interactor-i: interact with your system instead of training.--tensorboardor-tb: enable tensorboard to monitor train performance.
In CRSLab, we unify the task description of conversational recommendation into three sub-tasks, namely recommendation (recommend user-preferred items), conversation (generate proper responses) and policy (select proper interactive action). The recommendation and conversation sub-tasks are the core of a CRS and have been studied in most of works. The policy sub-task is needed by recent works, by which the CRS can interact with users through purposeful strategy. As the first release version, we have implemented 18 models in the four categories of CRS model, Recommendation model, Conversation model and Policy model.
| Category | Model | Graph Neural Network? | Pre-training Model? |
|---|---|---|---|
| CRS Model | ReDial KBRD KGSF TG-ReDial INSPIRED |
× √ √ × × |
× × × √ √ |
| Recommendation model | Popularity GRU4Rec SASRec TextCNN R-GCN BERT |
× × × × √ × |
× × × × × √ |
| Conversation model | HERD Transformer GPT-2 |
× × × |
× × √ |
| Policy model | PMI MGCG Conv-BERT Topic-BERT Profile-BERT |
× × × × × |
× × √ √ √ |
Among them, the four CRS models integrate the recommendation model and the conversation model to improve each other, while others only specify an individual task.
For Recommendation model and Conversation model, we have respectively implemented the following commonly-used automatic evaluation metrics:
| Category | Metrics |
|---|---|
| Recommendation Metrics | Hit@{1, 10, 50}, MRR@{1, 10, 50}, NDCG@{1, 10, 50} |
| Conversation Metrics | PPL, BLEU-{1, 2, 3, 4}, Embedding Average/Extreme/Greedy, Distinct-{1, 2, 3, 4} |
| Policy Metrics | Accuracy, Hit@{1,3,5} |
We have collected and preprocessed 6 commonly-used human-annotated datasets, and each dataset was matched with proper KGs as shown below:
| Dataset | Dialogs | Utterances | Domains | Task Definition | Entity KG | Word KG |
|---|---|---|---|---|---|---|
| ReDial | 10,006 | 182,150 | Movie | -- | DBpedia | ConceptNet |
| TG-ReDial | 10,000 | 129,392 | Movie | Topic Guide | CN-DBpedia | HowNet |
| GoRecDial | 9,125 | 170,904 | Movie | Action Choice | DBpedia | ConceptNet |
| DuRecDial | 10,200 | 156,000 | Movie, Music | Goal Plan | CN-DBpedia | HowNet |
| INSPIRED | 1,001 | 35,811 | Movie | Social Strategy | DBpedia | ConceptNet |
| OpenDialKG | 13,802 | 91,209 | Movie, Book | Path Generate | DBpedia | ConceptNet |
We have trained and test the integrated models on the TG-Redial dataset, which is split into training, validation and test sets using a ratio of 8:1:1. For each conversation, we start from the first utterance, and generate reply utterances or recommendations in turn by our model. We perform the evaluation on the three sub-tasks.
| Model | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
|---|---|---|---|---|---|---|---|---|---|
| SASRec | 0.000446 | 0.00134 | 0.0160 | 0.000446 | 0.000576 | 0.00114 | 0.000445 | 0.00075 | 0.00380 |
| TextCNN | 0.00267 | 0.0103 | 0.0236 | 0.00267 | 0.00434 | 0.00493 | 0.00267 | 0.00570 | 0.00860 |
| BERT | 0.00722 | 0.00490 | 0.0281 | 0.00722 | 0.0106 | 0.0124 | 0.00490 | 0.0147 | 0.0239 |
| KBRD | 0.00401 | 0.0254 | 0.0588 | 0.00401 | 0.00891 | 0.0103 | 0.00401 | 0.0127 | 0.0198 |
| KGSF | 0.00535 | 0.0285 | 0.0771 | 0.00535 | 0.0114 | 0.0135 | 0.00535 | 0.0154 | 0.0259 |
| TG-ReDial | 0.00793 | 0.0251 | 0.0524 | 0.00793 | 0.0122 | 0.0134 | 0.00793 | 0.0152 | 0.0211 |
| Model | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | Dist@1 | Dist@2 | Dist@3 | Dist@4 | Average | Extreme | Greedy | PPL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HERD | 0.120 | 0.0141 | 0.00136 | 0.000350 | 0.181 | 0.369 | 0.847 | 1.30 | 0.697 | 0.382 | 0.639 | 472 |
| Transformer | 0.266 | 0.0440 | 0.0145 | 0.00651 | 0.324 | 0.837 | 2.02 | 3.06 | 0.879 | 0.438 | 0.680 | 30.9 |
| GPT2 | 0.0858 | 0.0119 | 0.00377 | 0.0110 | 2.35 | 4.62 | 8.84 | 12.5 | 0.763 | 0.297 | 0.583 | 9.26 |
| KBRD | 0.267 | 0.0458 | 0.0134 | 0.00579 | 0.469 | 1.50 | 3.40 | 4.90 | 0.863 | 0.398 | 0.710 | 52.5 |
| KGSF | 0.383 | 0.115 | 0.0444 | 0.0200 | 0.340 | 0.910 | 3.50 | 6.20 | 0.888 | 0.477 | 0.767 | 50.1 |
| TG-ReDial | 0.125 | 0.0204 | 0.00354 | 0.000803 | 0.881 | 1.75 | 7.00 | 12.0 | 0.810 | 0.332 | 0.598 | 7.41 |
| Model | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
|---|---|---|---|---|---|---|---|---|---|
| MGCG | 0.591 | 0.818 | 0.883 | 0.591 | 0.680 | 0.683 | 0.591 | 0.712 | 0.729 |
| Conv-BERT | 0.597 | 0.814 | 0.881 | 0.597 | 0.684 | 0.687 | 0.597 | 0.716 | 0.731 |
| Topic-BERT | 0.598 | 0.828 | 0.885 | 0.598 | 0.690 | 0.693 | 0.598 | 0.724 | 0.737 |
| TG-ReDial | 0.600 | 0.830 | 0.893 | 0.600 | 0.693 | 0.696 | 0.600 | 0.727 | 0.741 |
The above results were obtained from our CRSLab in preliminary experiments. However, these algorithms were implemented and tuned based on our understanding and experiences, which may not achieve their optimal performance. If you could yield a better result for some specific algorithm, please kindly let us know. We will update this table after the results are verified.
| Releases | Date | Features |
|---|---|---|
| v0.1.1 | 1 / 4 / 2021 | Basic CRSLab |
| v0.1.2 | 3 / 28 / 2021 | CRSLab |
Please let us know if you encounter a bug or have any suggestions by filing an issue.
We welcome all contributions from bug fixes to new features and extensions.
We expect all contributions discussed in the issue tracker and going through PRs.
We thank the nice contributions through PRs from @shubaoyu, @ToheartZhang.
If you find CRSLab useful for your research or development, please cite our Paper:
@article{crslab,
title={CRSLab: An Open-Source Toolkit for Building Conversational Recommender System},
author={Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng, Wayne Xin Zhao, Yaliang Li, Ji-Rong Wen},
year={2021},
journal={arXiv preprint arXiv:2101.00939}
}
CRSLab was developed and maintained by AI Box group in RUC.
CRSLab uses MIT License.