


My crude (and slightly terrifying) rendition of Renee French's Go Gopher writing what's on his mind.
Sum-Product Networks (SPNs) are deep probabilistic graphical models (PGMs) that compactly represent tractable probability distributions. Exact inference in SPNs is computed in time linear in the number of edges, an attractive feature that distinguishes SPNs from other PGMs. However, learning SPNs is a tough task. There have been many advances in learning the structure and parameters of SPNs in the past few years. One interesting feature is the fact that we can make use of SPNs' deep architecture and perform deep learning on these models. Since the number of hidden layers not only doesn't negatively impact the tractability of inference of SPNs but also augments the representability of this model, it is very much desirable to continue research on deep learning of SPNs.
This project aims to provide a simple framework for Sum-Product Networks. Our objective is to provide inference tools and implement various learning algorithms present in literature.
- Unit tests
- Support for continuos variables
- Soft inference (marginal probabilities)
- Hard inference (MAP) through max-product algorithm
- Gens-Domingos learning schema (LearnSPN) [1]
- Dennis-Ventura clustering structural learning algorithm [2]
- Poon-Domingos dense architecture [3]
- Computation of SPN derivatives
- Soft generative gradient descent
- Hard generative gradient descent
- Soft discriminative gradient descent
- Hard discriminative gradient descent
- Support for
.npyfiles - Support for
.arffdataset format (discrete variables only) - Support for
.csvdataset file format - Support for our own
.datadataset format - Serialization of SPNs
- [1] Learning the Structure of Sum-Product Networks, R. Gens & P. Domingos, ICML 2013
- [2] Learning the Architecture of Sum-Product Networks Using Clustering on Variables, A. Dennis & D. Ventura, NIPS 25 (2012)
- [3] Sum-Product Networks: A New Deep Architecture, H. Poon & P. Domingos, UAI 2011
See the Contribution Guidelines.
devcontains the development version of GoSPN.stablecontains a stable version of GoSPN.nlpcontains deprecated NLP model.
GoDocs: https://godoc.org/github.com/RenatoGeh/gospn
Learning algorithms are inside the github.com/RenatoGeh/gospn/learn
package, with each algorithm as a subpackage of learn (e.g.
learn/gens, learn/dennis, learn/poon).
To parse an ARFF format dataset and perform learning with the Gens-Domingos structure learning algorithm:
First import the relevant packages (e.g. learn/gens for Gens' structural
learning algorithm, io for ParseArff and spn for inference
methods):
import (
"github.com/RenatoGeh/gospn/learn/gens"
"github.com/RenatoGeh/gospn/io"
"github.com/RenatoGeh/gospn/spn"
)
Extract contents from an ARFF file (for now only discrete variables):
name, scope, values, labels := io.ParseArff("filename.arff")
Send the relevant information to the learning algorithm:
S := gens.Learn(scope, values, -1, 0.0001, 4.0, 4)
S is the resulting SPN. We can now compute the marginal probabilities
given a spn.VarSet:
evidence := make(spn.VarSet)
evidence[0] = 1 // Variable 0 = 1
// Summing out variable 1
evidence[2] = 0 // Variable 2 = 0
// Summing out all other variables.
p := S.Value(evidence)
// p is the marginal Pr(evidence), since S is already valid and normalized.
The method S.Value may repeat calculations if the SPN's graph is not a
tree. To use dynamic programming and avoid recomputations, either use
spn.Inference or spn.Storer:
// This only returns the desired probability (in logspace).
p := spn.Inference(S, evidence)
// A Storer stores values for all nodes.
T := spn.NewStorer()
t := T.NewTicket() // Creates a new DP table.
spn.StoreInference(S, evidence, t, T) // Stores inference values from each node to T(t).
p = T.Single(t, S) // Returns the first value inside node S: T(t, S).
Finding the approximate MPE works the same way. Let evidence be some
evidence, the MPE is given by:
args, mpe := S.ArgMax(evidence) // mpe is the probability and args is the argmax valuation.
Similarly to S.Value, S.ArgMax may recompute values if the graph is
not a tree. Use StoreMAP if the graph is a general DAG instead.
_, args := spn.StoreMAP(S, evidence, t, T)
mpe := T.Single(t, S)
GoSPN is written in Go. Go is an open source language originally developed at Google. It's a simple yet powerful and fast language built with efficiency in mind. Installing Go is easy. Pre-compiled packages are available for FreeBSD, Linux, Mac OS X and Windows for both 32 and 64-bit processors. For more information see https://golang.org/doc/install.
We have deprecated GNU GSL in favor of GoNum (https://github.com/gonum/). GoNum is written in Go, meaning when installing GoSPN, the Go package manager should automatically install all dependencies (including GoNum).
In case this does not occur and something like this comes up on the screen:
cannot find package "[...]/gonum/stat" in any of
Enter the following commands:
go get -u gonum.org/v1/gonum/stat
go get -u gonum.org/v1/gonum/mathext
We have deprecated functions that made GoSPN independent of GoNum or GNU GSL, so we recommend installing GoNum.
GoSPN supports .npy NumPy array dataset. We use
NpyIO to read the file and reformat
into GoSPN dataset format. Go's go get should automatically install
NpyIO.
Graph-tool is a Python module for graph manipulation and drawing. Since the SPNs we'll generate with most learning algorithms may have hundreads of thousands of nodes and hundreds of layers, we need a fast and efficient graph drawing tool for displaying our graphs. Since graph-tool uses C++ metaprogramming extensively, its performance is comparable to a C++ library.
Graph-tool uses the C++ Boost Library and can be compiled with OpenMP, a library for parallel programming on multiple cores architecture that may decrease graph compilation time significantly.
Compiling graph-tool can take up to 80 minutes and 3GB of RAM. If you do not plan on compiling the graphs GoSPN outputs, it is highly recommended that you do not install graph-tool.
Subdependencies and installation instructions are listed at https://graph-tool.skewed.de/download.
GoSPN also supports graph drawing with Graphviz. See io/output.go.
To get the source code through Go's go get command, run the following
command:
$ go get -u github.com/RenatoGeh/gospn
Then ensure all dependencies are pulled:
cd gospn && go build
To update GoSPN, run:
go get -u github.com/RenatoGeh/gospn
For a list of all available datasets in .data format, see:
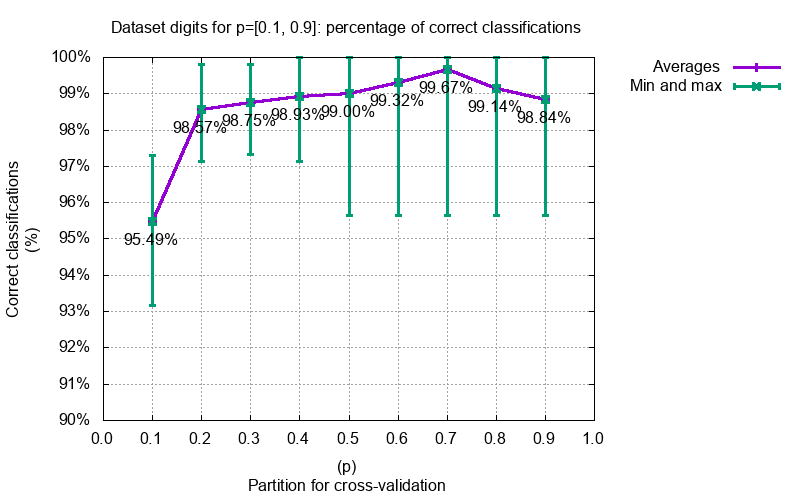
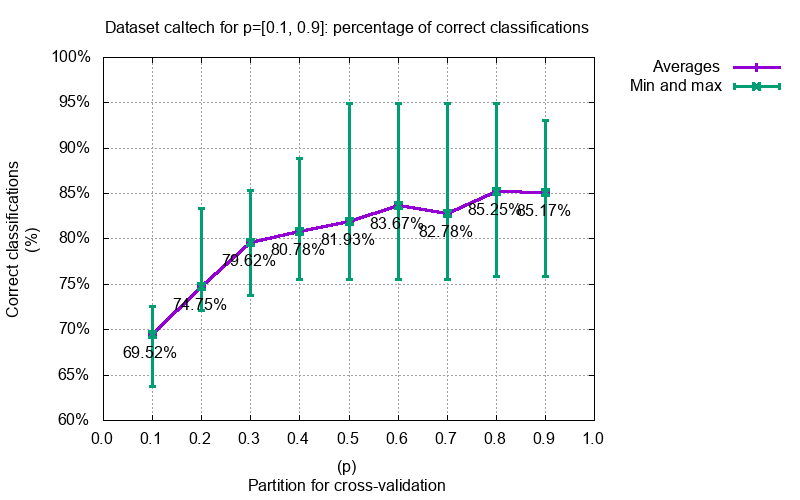
Some benchmarking and experiments we did with GoSPN. More can be found at https://github.com/renatogeh/benchmarks.




The following articles used GoSPN!
- Credal Sum-Product Networks, D. Mauá & F. Cozman & D. Conaty & C. Campos, PMLR 2017
- Approximation Complexity of Maximum A Posteriori Inference in Sum-Product Networks, D. Conaty & D. Mauá & C. Campos, UAI 2017
This project is part of my undergraduate research project supervised by Prof. Denis Deratani Mauá at the Institute of Mathematics and Statistics - University of São Paulo. We had financial support from CNPq grant #800585/2016-0.
We would like to greatly thank Diarmaid Conaty and Cassio P. de Campos, both from Queen's University Belfast, for finding and correcting several bugs.