A unique, multithreaded Low & Slow Denial-of-Service (Slow DoS) exploit against web servers that use vulnerable versions of thread-based web server software (Apache 1.x, Apache 2.x, httpd, etc.), that denies typical service to the web server’s legitimate clients by exhausting server resources at the cost of minimal bandwidth at the attacker's end — using a single system.
This unique approach uses staggering amounts of concurrently generated HTTP GET requests even while the other sockets are being created and established on-the-go, and is ironically effective against even some of its typical mitigation mechanisms such as poorly implemented reverse proxy servers.
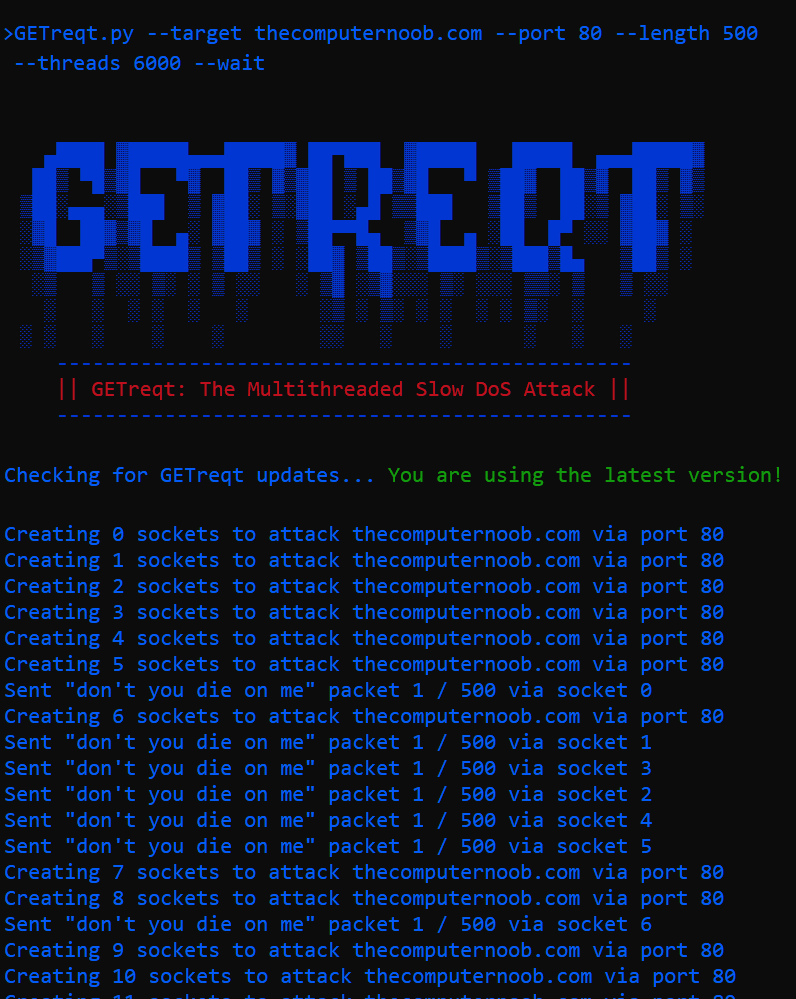
Example Execution
This project was created in Python, to supplement my Computer Science engineering degree's final-year research project titled "Low & Slow: The Evil Twin of DDoS Attacks", which was an awareness-based project. This project was honored with the title of "Project of the Year" by the university.
- Apache 1.x
- Apache 2.x
- BeeWare WAF
- DenyAll WAF
- dhttpd
- Flask
- GoAhead WebServer
- Trapeze Wireless Web Portal
- WebSense "block pages"
- Cherokee
- Cisco CSS
- IIS6.0
- IIS7.0
- lighttpd
- Netscaler
- nginx
- Squid
You may test these and report them as vulnerable / invulnerable to update this list in the future.
GETreqt.py --target example.com --port 80 --length 1024 --threads 6000 --wait
GETreqt.py -x example.com -p 80 -l 1024 -t 6000 -w
GETreqt.py --target example.com --port 80 --length 1024 --threads 10000 --end
GETreqt.py -x example.com -p 80 -l 1024 -t 10000 -e
| Option | Description |
|---|---|
| target (-x) | Target web server address (IP address or URL) |
| port (-p) | Target web server port (eg: 80) |
| length (-l) | Total packet length (eg: 1000) |
| threads (-t) | Threads (sockets) to attack with (eg: 6000) |
| wait (-w) | Do not terminate requests (relatively elegant slow DoS) |
| end (-e) | Terminate all requests correctly (blatant GET flood) |
-
The specified number of client-side software threads (--threads) are created — these would serve as the individual sockets established between the client and server
-
Unterminated (deliberately incomplete) GET request headers are created to be sent via all these created sockets
-
As this large number of sockets is being created and established, the unterminated GET requests are concurrently sent to the target web server using whatever sockets are already established presently
-
At randomized time intervals, a single byte is added to this unterminated GET request to keep the communication with the server alive. This time interval is a float value within the 0–5 range, and is randomized for each individual socket, for each individual iteration. This interval also aids in attempting to make the attack seem less automated or static, and more "human-like" to a potential monitoring mechanism at the server's end
Essentially, each created and established socket sends unterminated (deliberately incomplete) GET requests to the target server first. After this, every 0–5 seconds, a single arbitrary byte is added to each of these incomplete GET requests of each socket to give the target server an impression of an alive and still ongoing connection — like a drip feed. As the server is still "waiting" for all these concurrent requests to terminate (complete) correctly, this consumes a single software thread of the server per successfully connected GETreqt socket (eg: 1,000 server threads for 1,000 successfully connected sockets). Ergo, GETreqt with the
--waitoption attempts at occupying as many of the server-side threads—that are explicitly assigned to be serving clients—as possible in order to disrupt or hinder typical service to a legitimate client that is trying to access the web server. -
When a socket dies or a server-side thread is freed up (unoccupied), additional sockets are concurrently created and established to maximize the number of occupied server-side threads
-
Steps #4 and #5 remain active until either of the following occurs:
- The specified length of the request (--length) is reached
- The script is manually killed
- The target server crashes
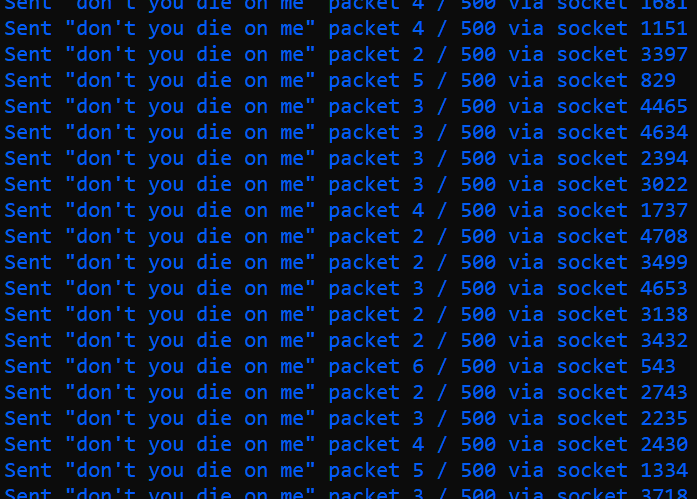
Sending Unterminated Requests
-
The specified number of client-side software threads (--threads) are created — these would serve as the individual sockets established between the client and server
-
Terminated (completed) GET request headers are created to be sent via all these created sockets
-
As this large number of sockets is being created and established, the terminated GET requests are concurrently sent to the target web server using whatever sockets are already established presently
Essentially, each created and established socket sends terminated (completed) GET requests to the target server, and goes on doing this repeatedly in an attempt at engaging as many server-side threads as possible momentarily. If a request is accepted and processed by the target server, even momentarily, it consumes a single software thread of the server per successfully connected GETreqt socket (eg: 500 server threads for 500 successfully connected sockets). Ergo, GETreqt with the
--endoption attempts at overwhelming the target server by blatantly spraying it with meaningless yet valid requests in order to occupy as many of the server-side threads—that are explicitly assigned to be serving clients—as possible in order to disrupt or hinder typical service to a legitimate client that is trying to access the web server. -
When a socket dies or a server-side thread is freed up (unoccupied), additional sockets are concurrently created and established to maximize the number of occupied server-side threads
-
Steps #3 and #4 remain active until either of the following occurs:
- The specified length of the request (--length) is reached
- The script is manually killed
- The target server crashes
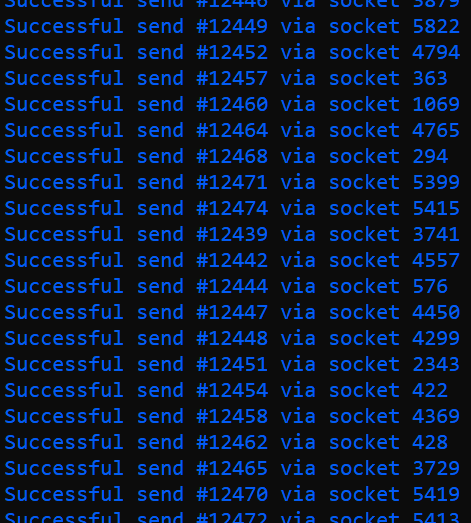
Sending Terminated Requests
When the server-side threads that are explicitly assigned to be serving clients are completely occupied by GETreqt's flood of terminated or unterminated GET requests, a legitimate client would fail to connect with the web server due to an insufficient amount of available threads on the server-side to be serving this client. This will result in the "Waiting for <target host>" message as the web browser anticipates a connection but never establishes one:

Waiting...
Further, upon waiting for a long enough amount of time, the web browser gives up as the server-side threads are completely occupied serving the attacker's requests. This is when the "ERR_CONNECTION_TIMED_OUT" error message is displayed to a legitimate client attempting to access the web page::
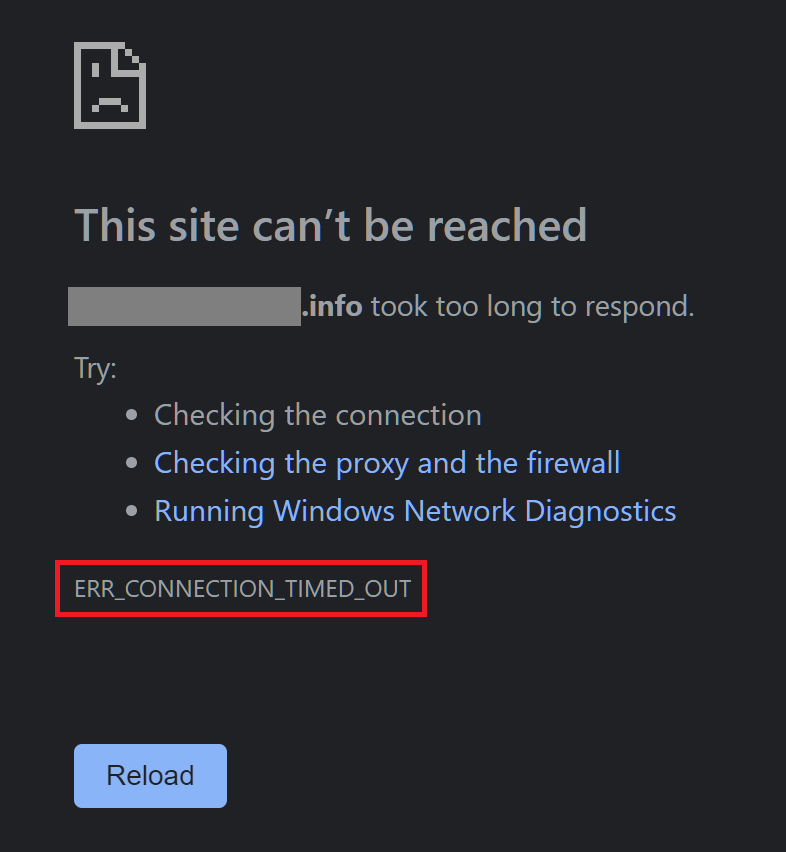
ERR_CONNECTION_TIMED_OUT
A reverse proxy server serves as an additional, protective layer to the destination server by obscuring the destination server's direct specifications (such as its IP address). Hence, say, if a ping command were to be executed using the primary web page domain using ping webpage.com, then the IP address being pinged would be that of the reverse proxy server instead of the destination web server where the web page exists.
That stated, if a reverse proxy server is poorly implemented or configured, then it would be vulnerable to GETreqt first. This means that if the reverse proxy server itself is vulnerable to GETreqt and is crippled by the attack, then since it serves as the only route through which a user could access the intended destination web server, the destination web server would also be inaccessible — technically also being a denial of typical service.
Upon a reverse proxy server failure such as this, a page resembling the following context / nature would display to a legitimate client attempting to access the web page:
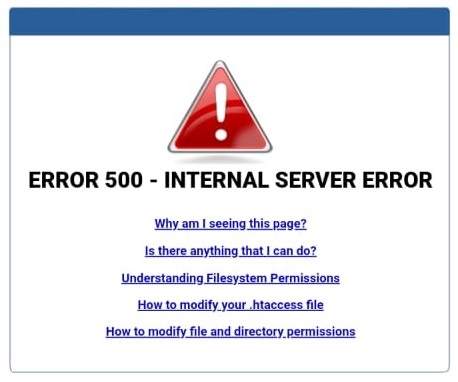
Reverse Proxy Server Failure
GETreqt was created for the purposes of education, research, and inspiring awareness surrounding the fact that organizations are still using vulnerable web server software versions in the current iteration of the digital world. I neither endorse nor shall be held responsible for any potential unethical or malicious activity that is a result of your usage of GETreqt.
Use your superpowers for good, not evil.
- colorama (for colors)
- termcolor (for colors)
My website: https://TheComputerNoob.com