Releases: UKPLab/sentence-transformers
v3.1.1 - Patch hard negative mining & remove `numpy<2` restriction
This patch release fixes hard negatives mining for models that don't automatically normalize their embeddings and it lifts the numpy<2 restriction that was previously required.
Install this version with
# Full installation:
pip install sentence-transformers[train]==3.1.1
# Inference only:
pip install sentence-transformers==3.1.1Hard Negatives Mining Patch (#2944)
The mine_hard_negatives utility introduced in the previous release would fail if use_faiss=True & the model does not automatically normalize its embeddings. This release patches that, allowing the utility to work with all Sentence Transformer models:
from sentence_transformers.util import mine_hard_negatives
from sentence_transformers import SentenceTransformer
from datasets import load_dataset
# Load a Sentence Transformer model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1").bfloat16()
# Load a dataset to mine hard negatives from
dataset = load_dataset("sentence-transformers/natural-questions", split="train[:10000]")
print(dataset)
"""
Dataset({
features: ['query', 'answer'],
num_rows: 10000
})
"""
# Mine hard negatives
dataset = mine_hard_negatives(
dataset=dataset,
model=model,
range_min=10,
range_max=50,
max_score=0.8,
margin=0.1,
num_negatives=5,
sampling_strategy="random",
batch_size=128,
use_faiss=True,
)
'''
Batches: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 75/75 [00:21<00:00, 3.51it/s]
Batches: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 79/79 [00:03<00:00, 25.77it/s]
Querying FAISS index: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.98it/s]
Metric Positive Negative Difference
Count 10,000 47,711
Mean 0.7600 0.5376 0.2299
Median 0.7673 0.5379 0.2274
Std 0.0658 0.0387 0.0629
Min 0.3858 0.3732 0.1044
25% 0.7219 0.5129 0.1833
50% 0.7673 0.5379 0.2274
75% 0.8058 0.5617 0.2724
Max 0.9341 0.7024 0.4780
Skipped 48770 potential negatives (9.56%) due to the margin of 0.1.
Could not find enough negatives for 2289 samples (4.58%). Consider adjusting the range_max, range_min, margin and max_score parameters if you'd like to find more valid negatives.
'''
print(dataset)
'''
Dataset({
features: ['query', 'answer', 'negative'],
num_rows: 47711
})
'''
print(dataset[0])
'''
{
'query': 'where is the us navy base in japan located',
'answer': 'United States Fleet Activities Yokosuka The United States Fleet Activities Yokosuka (横須賀海 軍施設, Yokosuka kaigunshisetsu) or Commander Fleet Activities Yokosuka (司令官艦隊活動横須賀, Shirei-kan kantai katsudō Yokosuka) is a United States Navy base in Yokosuka, Japan. Its mission is to maintain and operate base facilities for the logistic, recreational, administrative support and service of the U.S. Naval Forces Japan, Seventh Fleet and other operating forces assigned in the Western Pacific. CFAY is the largest strategically important U.S. naval installation in the western Pacific.[1] As of August 2013[update], it was commanded by Captain David Glenister.',
'negative': "2011 Tōhoku earthquake and tsunami The earthquake took place at 14:46 JST (UTC 05:46) around 67\xa0km (42\xa0mi) from the nearest point on Japan's coastline, and initial estimates indicated the tsunami would have taken 10 to 30\xa0minutes to reach the areas first affected, and then areas farther north and south based on the geography of the coastline.[127][128] Just over an hour after the earthquake at 15:55 JST, a tsunami was observed flooding Sendai Airport, which is located near the coast of Miyagi Prefecture,[129][130] with waves sweeping away cars and planes and flooding various buildings as they traveled inland.[131][132] The impact of the tsunami in and around Sendai Airport was filmed by an NHK News helicopter, showing a number of vehicles on local roads trying to escape the approaching wave and being engulfed by it.[133] A 4-metre-high (13\xa0ft) tsunami hit Iwate Prefecture.[134] Wakabayashi Ward in Sendai was also particularly hard hit.[135] At least 101 designated tsunami evacuation sites were hit by the wave.[136]"
}
'''
dataset.push_to_hub("natural-questions-hard-negatives", "triplet")Thanks to @omarnj-lab for pointing out the bug to me.
Numpy restriction lifted (#2937)
The v3.1.0 Sentence Transformers release required numpy<2 to prevent crashes on Windows. However, various third-parties (e.g. scipy) have now been recompiled & released, allowing the Windows tests to pass again.
If you experience the following snippet:
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.0 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
If you are a user of the module, the easiest solution will be to downgrade to 'numpy<2' or try to upgrade the affected module. We expect that some modules will need time to support NumPy 2.
Then consider 1) upgrading the dependency from which the error occurred or 2) downgrading numpy to below v2:
pip install -U numpy<2
Thanks to @kozlek for pointing this out to me and helping getting it resolved.
All changes
- [
deps] Attempt to remove numpy restrictions by @tomaarsen in #2937 - [
metadata] Extend pyproject.toml metadata by @tomaarsen in #2943 - [
fix] Ensure that the embeddings from hard negative mining are normalized by @tomaarsen in #2944
Full Changelog: v3.1.0...v3.1.1
Contributors
Assets 2
v3.1.0 - Hard Negatives Mining utility; new loss function for symmetric tasks; streaming datasets; custom modules
This release introduces a hard negatives mining utility to get better models out of your data, a new strong loss function for symmetric tasks, training with streaming datasets to avoid having to store datasets fully on disk, custom modules to allow for more creativity from model authors, and many bug fixes, small additions and documentation improvements.
Install this version with
# Full installation:
pip install sentence-transformers[train]==3.1.0
# Inference only:
pip install sentence-transformers==3.1.0Warning
Due to incompatibilities with Windows, we have set numpy<2 in the Sentence Transformers requirements. If you're not on Windows, you can still install numpy>=2 and everything should work as expected.
Hard Negatives Mining utility (#2768, #2848)
Hard negatives are texts that are rather similar to some anchor text (e.g. a question), but are not the correct match. For example:
- Anchor: "are red pandas actually pandas?"
- Positive: "Red pandas, like giant pandas, are bamboo eaters native to Asia's high forests. Despite these similarities and their shared name, the two species are not closely related. Red pandas are much smaller than giant pandas and are the only living member of their taxonomic family."
- Hard negative: "The giant panda (Ailuropoda melanoleuca; Chinese: 大熊猫; pinyin: dàxióngmāo), also known as the panda bear or simply the panda, is a bear native to south central China."
These negatives are more difficult for a model to distinguish from the correct answer, leading to a stronger training signal and a stronger overall model when used with one of the Loss Functions that accepts (anchor, positive, negative) pairs such as the one above.
This release introduces a utility function called mine_hard_negatives that allows you to mine for these hard negatives given a (anchor, positive) dataset (and optionally a corpus of negative candidate texts).
It boasts the following features to give you fine-grained control over the similarity of the mined negatives relative to the anchor:
- CrossEncoder rescoring for higher quality negative selection.
- Skip the top
$n$ negative candidates as these might be true positives. - Consider only the top
$n$ negative candidates. - Skip negative candidates that are within some
marginof the true similarity between anchor and positive. - Skip negative candidates whose similarity is larger than some
max_score. - Two sampling strategies: pick the top negative candidates that satisfy the requirements, or pick them randomly.
- FAISS index for searching for negative candidates.
- Option to return data as triplets only, or as
2 + num_negatives-tuples.
from sentence_transformers.util import mine_hard_negatives
from sentence_transformers import SentenceTransformer
from datasets import load_dataset
# Load a Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# Load a dataset to mine hard negatives from
dataset = load_dataset("sentence-transformers/natural-questions", split="train")
print(dataset)
"""
Dataset({
features: ['query', 'answer'],
num_rows: 100231
})
"""
# Mine hard negatives
dataset = mine_hard_negatives(
dataset=dataset,
model=model,
range_min=10,
range_max=50,
max_score=0.8,
margin=0.1,
num_negatives=5,
sampling_strategy="random",
batch_size=128,
use_faiss=True,
)
'''
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 588/588 [00:33<00:00, 17.37it/s]
Batches: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 784/784 [00:07<00:00, 101.55it/s]
Querying FAISS index: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.06s/it]
Metric Positive Negative Difference
Count 100,231 460,725 460,725
Mean 0.6866 0.4133 0.2917
Median 0.7010 0.4059 0.2873
Std 0.1125 0.0673 0.1006
Min 0.0303 0.1638 0.1029
25% 0.6221 0.3649 0.2112
50% 0.7010 0.4059 0.2873
75% 0.7667 0.4561 0.3647
Max 0.9584 0.7362 0.7073
Skipped 882722 potential negatives (17.27%) due to the margin of 0.1.
Skipped 27 potential negatives (0.00%) due to the maximum score of 0.8.
Could not find enough negatives for 40430 samples (8.07%). Consider adjusting the range_max, range_min, margin and max_score parameters if you'd like to find more valid negatives.
'''
print(dataset)
'''
Dataset({
features: ['query', 'answer', 'negative'],
num_rows: 460725
})
'''
print(dataset[0])
'''
{
'query': 'the first person to use the word geography was',
'answer': 'History of geography The history of geography includes many histories of geography which have differed over time and between different cultural and political groups. In more recent developments, geography has become a distinct academic discipline. \'Geography\' derives from the Greek γεωγραφία – geographia,[1] a literal translation of which would be "to describe or write about the Earth". The first person to use the word "geography" was Eratosthenes (276–194 BC). However, there is evidence for recognizable practices of geography, such as cartography (or map-making) prior to the use of the term geography.',
'negative': 'Terminology of the British Isles The word "Great" means "larger", in comparison with Brittany in modern-day France. One historical term for the peninsula in France that largely corresponds to the modern French province is Lesser or Little Britain. That region was settled by many British immigrants during the period of Anglo-Saxon migration into Britain, and named "Little Britain" by them. The French term "Bretagne" now refers to the French "Little Britain", not to the British "Great Britain", which in French is called Grande-Bretagne. In classical times, the Graeco-Roman geographer Ptolemy in his Almagest also called the larger island megale Brettania (great Britain). At that time, it was in contrast to the smaller island of Ireland, which he called mikra Brettania (little Britain).[62] In his later work Geography, Ptolemy refers to Great Britain as Albion and to Ireland as Iwernia. These "new" names were likely to have been the native names for the islands at the time. The earlier names, in contrast, were likely to have been coined before direct contact with local peoples was made.[63]'
}
'''
dataset.push_to_hub("natural-questions-hard-negatives", "triplet")This dataset can immediately be used in conjunction with MultipleNegativesRankingLoss, likely resulting in a stronger model than if you had just used the natural-questions dataset outright.
Here are some example datasets that I created using this new function:
- https://huggingface.co/datasets/tomaarsen/gooaq-hard-negatives
- https://huggingface.co/datasets/tomaarsen/natural-questions-hard-negatives
Big thanks to @ChrisGeishauser and @ArthurCamara for assisting with this feature.
Add CachedMultipleNegativesSymmetricRankingLoss loss function (#2879)
Let's break this down:
- MultipleNegativesRankingLoss (MNRL): Given (anchor, positive) text pairs or (anchor, positive, negative) text triplets, this loss trains for "Given an anchor (e.g. a query), which text out of a big lineup (all positives and negatives in the batch) is the true positive (e.g. the answer)?".
- MultipleNegativesSymmetricRankingLoss (MNSRL): Adaptation of MNRL that adds a second loss term which means: "Given an positive (e.g. an summary), which text out of a big lineup (all anchors) is the true anchor (e.g. the full article)?". This is useful for symmetric tasks, such as clustering, classification, finding similar texts, and a bit less useful for asymmetric tasks such as question-answer retrieval.
- CachedMultipleNegativesRankingLoss (CMNRL): Adaptation of MNRL such that the batch size can be increased to an arbitrary size at a flat 10-20% training speed cost. A higher batch size means a larger lineup for the model to find the true positive in, often resulting in a better training signal and model.
The v3.1 Sentence Transformers release now introduces a new loss: CachedMultipleNegativesSymmetricRankingLoss (CMNSRL), which combines both of the previous adaptations. The result is a loss adept at symmetric training tasks for which you can pick an arbitrarily large batch size. It is likely the strongest loss for Semantic Textual Similarity (STS) tasks in Sentence Transformers now.
Big thanks to @madhavthaker1 for working to include it.
Str...
Contributors
Assets 2
v3.0.1 - Patch introducing new Trainer features, model card improvements and evaluator fixes
This patch release introduces some improvements for the SentenceTransformerTrainer, as well as some updates for the automatic model card generation. It also patches some minor evaluator bugs and a bug with MatryoshkaLoss. Lastly, every single Sentence Transformer model can now be saved and loaded with the safer model.safetensors files.
Install this version with
# Full installation:
pip install sentence-transformers[train]==3.0.1
# Inference only:
pip install sentence-transformers==3.0.1SentenceTransformerTrainer improvements
- Implement gradient checkpointing for lower memory usage during training (#2717)
- Implement support for
push_to_hub=TrueTraining Argument, also implementtrainer.push_to_hub(...)(#2718)
Model Cards
This patch release improves on the automatically generated model cards in several ways:
- Your training datasets are now automatically linked if they're on Hugging Face (#2711)
- A new
generated_from_trainertag is now also added (#2710) - The automatically included widget examples are now improved, especially for question-answering. Previously, the widget could give examples of comparing two questions with eachother (#2713)
- If you save a model locally, then load it again and upload it, it would previously still show
...
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
...This now gets replaced with your new model ID on Hugging Face (#2714)
- The exact training dataset size is now included in the model metadata, rather than as a bucket of e.g. 1K<n<10K (#2728)
Evaluators fixes
- The primary metric of evaluators in
SequentialEvaluatorwould be ignored in thescorescalculation (#2700) - Fix confusing print statement in TranslationEvaluator when using
print_wrong_matches=True(#1894) - Fix bug that prevents you from customizing the
primary_metricinInformationRetrievalEvaluator(#2701) - Allow passing a list of evaluators to the STTrainer rather than a
SequentialEvaluator(#2717)
Losses fixes
- Fix
MatryoshkaLosscrash if the first dimension is not the biggest (#2719)
Security
- Integrate safetensors with all modules, including Dense, LSTM, CNN, etc. to prevent needing pickled
pytorch_model.binanymore (#2722)
All changes
- updating to evaluation_strategy by @higorsilvaa in #2686
- fix loss link by @Samoed in #2690
- Fix bug that restricts users from specifying custom primary_function in InformationRetrievalEvaluator by @hetulvp in #2701
- Fix a bug in SequentialEvaluator to use primary_metric if defined in evaluator. by @hetulvp in #2700
- [
fix] Always override the originally saved version in the ST config by @tomaarsen in #2709 - [
model cards] Also include HF datasets in the model card metadata by @tomaarsen in #2711 - Add "generated_from_trainer" tag to auto-generated model cards by @tomaarsen in #2710
- Fix confusing print statement in TranslationEvaluator by @NathanS-Git in #1894
- [
model cards] Improve the widget example selection: not based on embeddings, better for QA by @tomaarsen in #2713 - [
model cards] Replace 'sentence_transformers_model_id' from reused model if possible by @tomaarsen in #2714 - [
feat] Allow passing a list of evaluators to the Trainer by @tomaarsen in #2716 - [
fix] Fix gradient checkpointing to allow for much lower memory usage by @tomaarsen in #2717 - [
fix] Implementcreate_model_cardon the Trainer, allowing args.push_to_hub=True by @tomaarsen in #2718 - [
fix] FixMatryoshkaLosscrash if the first dimension is not the biggest by @tomaarsen in #2719 - Update models_en_sentence_embeddings.html by @saikartheekb in #2720
- [
typing] Improve typing for many functions & addpy.typedto satisfymypyby @tomaarsen in #2724 - [
fix] Fix edge case with evaluator being None by @tomaarsen in #2726 - [
simplify] Set can_return_loss=True globally, instead of via the data collator by @tomaarsen in #2727 - [
feat] Integrate safetensors with Dense, etc. modules too. by @tomaarsen in #2722 - [
model cards] Specify the exact dataset size as a tag, will be bucketized by HF by @tomaarsen in #2728
New Contributors
- @higorsilvaa made their first contribution in #2686
- @hetulvp made their first contribution in #2701
- @NathanS-Git made their first contribution in #1894
- @saikartheekb made their first contribution in #2720
Full Changelog: v3.0.0...v3.0.1
Contributors
Assets 2
v3.0.0 - Sentence Transformer Training Refactor; new similarity methods; hyperparameter optimization; 50+ datasets release
This release consists of a major refactor that overhauls the training approach (introducing multi-gpu training, bf16, loss logging, callbacks, and much more), adds convenient similarity and similarity_pairwise methods, adds extra keyword arguments, introduces Hyperparameter Optimization, and includes a massive reformatting and release of 50+ datasets for training embedding models. In total, this is the largest Sentence Transformers update since the project was first created.
Install this version with
# Full installation:
pip install sentence-transformers[train]==3.0.0
# Inference only:
pip install sentence-transformers==3.0.0Sentence Transformer training refactor (#2449)
The v3.0 release centers around this huge modernization of the training approach for SentenceTransformer models. Whereas training before v3.0 used to be all about InputExample, DataLoader and model.fit, the new training approach relies on 5 new components. You can learn more about these components in our Training and Finetuning Embedding Models with Sentence Transformers v3 blogpost. Additionally, you can read the new Training Overview, check out the Training Examples, or read this summary:
- Dataset
A trainingDatasetorDatasetDict. This class is much more suited for sharing & efficient modifications than lists/DataLoaders ofInputExampleinstances. ADatasetcan contain multiple text columns that will be fed in order to the corresponding loss function. So, if the loss expects (anchor, positive, negative) triplets, then your dataset should also have 3 columns. The names of these columns are irrelevant. If there is a "label" or "score" column, it is treated separately, and used as the labels during training.
ADatasetDictcan be used to train with multiple datasets at once, e.g.:When aDatasetDict({ multi_nli: Dataset({ features: ['premise', 'hypothesis', 'label'], num_rows: 392702 }) snli: Dataset({ features: ['snli_premise', 'hypothesis', 'label'], num_rows: 549367 }) stsb: Dataset({ features: ['sentence1', 'sentence2', 'label'], num_rows: 5749 }) })
DatasetDictis used, thelossparameter to theSentenceTransformerTrainermust also be a dictionary with these dataset keys, e.g.:{ 'multi_nli': SoftmaxLoss(...), 'snli': SoftmaxLoss(...), 'stsb': CosineSimilarityLoss(...), } - Loss Function
A loss function, or a dictionary of loss functions like described above. These loss functions do not require changes compared to before this PR. - Training Arguments
A SentenceTransformerTrainingArguments instance, subclass of a TrainingArguments instance. This powerful class controls the specific details of the training. - Evaluator
An optionalSentenceEvaluatorinstance. Unlike before, models can now be evaluated both on an evaluation dataset with some loss function and/or aSentenceEvaluatorinstance. - Trainer
The newSentenceTransformersTrainerinstance based on thetransformersTrainer. This instance is provided with a SentenceTransformer model, a SentenceTransformerTrainingArguments class, a SentenceEvaluator, a training and evaluation Dataset/DatasetDict and a loss function/dict of loss functions. Most of these parameters are optional. Once provided, all you have to do is calltrainer.train().
Some of the major features that are now implemented include:
- MultiGPU Training (Data Parallelism (DP) and Distributed Data Parallelism (DDP))
- bf16 training support
- Loss logging
- Evaluation datasets + evaluation loss
- Improved callback support (built-in via Weights and Biases, TensorBoard, CodeCarbon, etc., as well as custom callbacks)
- Gradient checkpointing
- Gradient accumulation
- Improved model card generation
- Warmup ratio
- Pushing to the Hugging Face Hub on every model checkpoint
- Resuming from a training checkpoint
- Hyperparameter Optimization
This script is a minimal example (no evaluator, no training arguments) of training mpnet-base on a part of the all-nli dataset using MultipleNegativesRankingLoss:
from datasets import load_dataset
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer
from sentence_transformers.losses import MultipleNegativesRankingLoss
# 1. Load a model to finetune
model = SentenceTransformer("microsoft/mpnet-base")
# 2. Load a dataset to finetune on
dataset = load_dataset("sentence-transformers/all-nli", "triplet")
train_dataset = dataset["train"].select(range(10_000))
eval_dataset = dataset["dev"].select(range(1_000))
# 3. Define a loss function
loss = MultipleNegativesRankingLoss(model)
# 4. Create a trainer & train
trainer = SentenceTransformerTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
)
trainer.train()
# 5. Save the trained model
model.save_pretrained("models/mpnet-base-all-nli")Additionally, trained models now automatically produce extensive model cards. Each of the following models were trained using some script from the Training Examples, and the model cards were not edited manually whatsoever:
- tomaarsen/mpnet-base-all-nli-triplet
- tomaarsen/stsb-distilbert-base-mnrl-cl-multi
- tomaarsen/distilroberta-base-paraphrases-multi
Prior to the Sentence Transformer v3 release, all models would be trained using the SentenceTransformer.fit method. Rather than deprecating this method, starting from v3.0, this method will use the SentenceTransformerTrainer behind the scenes. This means that your old training code should still work, and should even be upgraded with the new features such as multi-gpu training, loss logging, etc. That said, the new training approach is much more powerful, so it is recommended to write new training scripts using the new approach.
Many of the old training scripts were updated to use the new Trainer-based approach, but not all have been updated yet. We accept help via Pull Requests to assist in updating the scripts.
Similarity Score (#2615, #2490)
Sentence Transformers v3.0 introduces two new useful methods:
and one property:
These can be used to calculate the similarity between embeddings, and to specify which similarity function should be used, for example:
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer("all-mpnet-base-v2")
>>> sentences = [
... "The weather is so nice!",
... "It's so sunny outside.",
... "He's driving to the movie theater.",
... "She's going to the cinema.",
... ]
>>> embeddings = model.encode(sentences, normalize_embeddings=True)
>>> model.similarity(embeddings, embeddings)
tensor([[1.0000, 0.7235, 0.0290, 0.1309],
[0.7235, 1.0000, 0.0613, 0.1129],
[0.0290, 0.0613, 1.0000, 0.5027],
[0.1309, 0.1129, 0.5027, 1.0000]])
>>> model.similarity_fn_name
"cosine"
>>> model.similarity_fn_name = "euclidean"
>>> model.similarity(embedd...Contributors
Assets 2
v2.7.0 - CachedGISTEmbedLoss, easy Matryoshka inference & evaluation, CrossEncoder, Intel Gaudi2
This release introduces a new promising loss function, easier inference for Matryoshka models, new functionality for CrossEncoders and Inference on Intel Gaudi2, along much more.
Install this version with
pip install sentence-transformers==2.7.0
New loss function: CachedGISTEmbedLoss (#2592)
For a number of years, MultipleNegativesRankingLoss (also known as SimCSE, InfoNCE, in-batch negatives loss) has been the state of the art in embedding model training. Notably, this loss function performs better with a larger batch size.
Recently, various improvements have been introduced:
CachedMultipleNegativesRankingLosswas introduced, which allows you to pick much higher batch sizes (e.g. 65536) with constant memory.GISTEmbedLosstakes a guide model to guide the in-batch negative sample selection. This prevents false negatives, resulting in a stronger training signal.
Now, @JacksonCakes has combined these two approaches to produce the best of both worlds: CachedGISTEmbedLoss. This loss function allows for high batch sizes with constant memory usage, while also using a guide model to assist with the in-batch negative sample selection.
As can be seen in our Loss Overview, this model should be used with (anchor, positive) pairs or (anchor, positive, negative) triplets, much like MultipleNegativesRankingLoss, CachedMultipleNegativesRankingLoss, and GISTEmbedLoss. In short, any example using those loss functions can be updated to use CachedGISTEmbedLoss! Feel free to experiment, e.g. with this training script.
Automatic Matryoshka model truncation (#2573)
Sentence Transformers v2.4.0 introduced Matryoshka models: models whose embeddings are still useful after truncation. Since then, many useful Matryoshka models have been trained.
As of this release, the truncation for these Matryoshka embedding models can be done automatically via a new truncate_dim constructor argument:
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
matryoshka_dim = 64
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True, truncate_dim=matryoshka_dim)
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
]
)
print(embeddings.shape)
# => [3, 64]
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])Extra information:
Model truncation in all evaluators (#2582)
Alongside easier inference with Matryoshka models, evaluating them is now also much easier. You can also pass truncate_dim to any Evaluator. This way you can easily check the performance of any Sentence Transformer model at various truncated dimensions (even if the model was not trained with MatryoshkaLoss!)
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
from sentence_transformers import SentenceTransformer
import datasets
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka")
stsb = datasets.load_dataset("mteb/stsbenchmark-sts", split="test")
for dim in [768, 512, 256, 128, 64, 32, 16, 8, 4]:
evaluator = EmbeddingSimilarityEvaluator(
stsb["sentence1"],
stsb["sentence2"],
[score / 5 for score in stsb["score"]],
name=f"sts-test-{dim}",
truncate_dim=dim,
)
print(f"dim={dim:<3}: {evaluator(model) * 100:.2f} Spearman Correlation")dim=768: 86.81 Spearman Correlation
dim=512: 86.76 Spearman Correlation
dim=256: 86.66 Spearman Correlation
dim=128: 86.20 Spearman Correlation
dim=64 : 85.40 Spearman Correlation
dim=32 : 82.42 Spearman Correlation
dim=16 : 79.31 Spearman Correlation
dim=8 : 72.82 Spearman Correlation
dim=4 : 63.44 Spearman Correlation
Here are some example training scripts that use this new truncate_dim option to assist with training Matryoshka models:
CrossEncoder improvements
This release improves the support for CrossEncoder reranker models.
push_to_hub (#2524)
You can now push trained CrossEncoder models to the 🤗 Hugging Face Hub!
from sentence_transformers import CrossEncoder
...
model = CrossEncoder("distilroberta-base")
# Train the model
model.fit(
train_dataloader=train_dataloader,
evaluator=evaluator,
epochs=num_epochs,
warmup_steps=warmup_steps,
)
model.push_to_hub("tomaarsen/distilroberta-base-stsb-cross-encoder")- Docs:
CrossEncoder.push_to_hub
trust_remote_code for custom models (#2595)
You can now load custom models from the Hugging Face Hub, i.e. models that have custom modelling code that require trust_remote_code to load.
from sentence_transformers import CrossEncoder
# Note: this model does not require `trust_remote_code=True` - there are currently no models that require it yet.
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2", trust_remote_code=True)
# We want to compute the similarity between the query sentence
query = "A man is eating pasta."
# With all sentences in the corpus
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# We rank all sentences in the corpus for the query
ranks = model.rank(query, corpus)
# Print the scores
print("Query:", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{corpus[rank['corpus_id']]}")- Docs:
CrossEncoder
Inference on Intel Gaudi2 (#2557)
From this release onwards, you will be able to perform inference on Intel Gaudi2 accelerators. No modifications are needed, as the library will automatically detect the hpu device and configure the model accordingly. Thanks to Intel Habana for the support here.
All changes
- [
docs] Add simple Makefile for building docs by @tomaarsen in #2566 - [
examples] Add Matryoshka evaluation plot by @kddubey in #2564 - Adding
push_to_hubto CrossEncoder by @imvladikon in #2524 - Fix semantic_search_usearch() for single query by @karmi in #2572
- [
requirements] Set minimum transformers version to 4.34.0 for is_nltk_available by @tomaarsen in #2574 - [
docs] Update link: retrieve_rerank_simple_wikipedia.py -> .ipynb by @tomaarsen in #2580 - Document dev reqs, add ruff pre-commit by @kddubey in #2576
- Enable Sentence Transformer Inference with Intel Gaudi2 GPU Supported ( 'hpu' ) by @ZhengHongming888 in #2557
- [
feat] Add truncation support by @kddubey in #2573 - [
examples] Add model upload for training_nli_v3 with GISTEmbedLoss by @tomaarsen in #2584 - Add truncation support in evaluators by @kddubey in #2582
- Add ST annotation to evaluators by @kddubey in #2586
- [
fix] Matryoshka training always patch original forward, and check matryoshka_dims by @kddubey in #2593 - corrected comment from kmeans to...
Contributors
Assets 2
v2.6.1 - Fix Quantized Semantic Search rescoring
This is a patch release to fix a bug in semantic_search_faiss and semantic_search_usearch that caused the scores to not correspond to the returned corpus indices. Additionally, you can now evaluate embedding models after quantizing their embeddings.
Precision support in EmbeddingSimilarityEvaluator
You can now pass precision to the EmbeddingSimilarityEvaluator to evaluate the performance after quantization:
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator, SimilarityFunction
import datasets
model = SentenceTransformer("all-mpnet-base-v2")
stsb = datasets.load_dataset("mteb/stsbenchmark-sts", split="test")
print("Spearman correlation based on Cosine Similarity on the STS Benchmark test set:")
for precision in ["float32", "uint8", "int8", "ubinary", "binary"]:
evaluator = EmbeddingSimilarityEvaluator(
stsb["sentence1"],
stsb["sentence2"],
[score / 5 for score in stsb["score"]],
main_similarity=SimilarityFunction.COSINE,
name="sts-test",
precision=precision,
)
print(precision, evaluator(model))Spearman correlation based on Cosine Similarity on the STS Benchmark test set:
float32 0.8342190421330611
uint8 0.8260094846238505
int8 0.8312754408857808
ubinary 0.8244338431442343
binary 0.8244338431442343
All changes
- Add 'precision' support to the EmbeddingSimilarityEvaluator by @tomaarsen in #2559
- [hotfix] Quantization patch; fix semantic_search_faiss/semantic_search_usearch rescoring by @tomaarsen in #2558
- Fix a typo in a docstring in CosineSimilarityLoss.py by @bryant1410 in #2553
Full Changelog: v2.6.0...v2.6.1
Contributors
Assets 2
v2.6.0 - Embedding Quantization, GISTEmbedLoss
This release brings embedding quantization: a way to heavily speed up retrieval & other tasks, and a new powerful loss function: GISTEmbedLoss.
Install this version with
pip install sentence-transformers==2.6.0
Embedding Quantization
Embeddings may be challenging to scale up, which leads to expensive solutions and high latencies. However, there is a new approach to counter this problem; it entails reducing the size of each of the individual values in the embedding: Quantization. Experiments on quantization have shown that we can maintain a large amount of performance while significantly speeding up computation and saving on memory, storage, and costs.
To be specific, using binary quantization may result in retaining 96% of the retrieval performance, while speeding up retrieval by 25x and saving on memory & disk space with 32x. Do not underestimate this approach! Read more about Embedding Quantization in our extensive blogpost.
Binary and Scalar Quantization
Two forms of quantization exist at this time: binary and scalar (int8). These quantize embedding values from float32 into binary and int8, respectively. For Binary quantization, you can use the following snippet:
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")References:
GISTEmbedLoss
GISTEmbedLoss, as introduced in Solatorio (2024), is a guided variant of the more standard in-batch negatives (MultipleNegativesRankingLoss) loss. Both loss functions are provided with a list of (anchor, positive) pairs, but while MultipleNegativesRankingLoss uses anchor_i and positive_i as positive pair and all positive_j with i != j as negative pairs, GISTEmbedLoss uses a second model to guide the in-batch negative sample selection.
This can be very useful, because it is plausible that anchor_i and positive_j are actually quite semantically similar. In this case, GISTEmbedLoss would not consider them a negative pair, while MultipleNegativesRankingLoss would. When finetuning MPNet-base on the AllNLI dataset, these are the Spearman correlation based on cosine similarity using the STS Benchmark dev set (higher is better):

The blue line is MultipleNegativesRankingLoss, whereas the grey line is GISTEmbedLoss with the small all-MiniLM-L6-v2 as the guide model. Note that all-MiniLM-L6-v2 by itself does not reach 88 Spearman correlation on this dataset, so this is really the effect of two models (mpnet-base and all-MiniLM-L6-v2) reaching a performance that they could not reach separately.
Soft save_to_hub Deprecation
Most codebases that allow for pushing models to the Hugging Face Hub adopt a push_to_hub method instead of a save_to_hub method, and now Sentence Transformers will follow that convention. The push_to_hub method will now be the recommended approach, although save_to_hub will continue to exist for the time being: it will simply call push_to_hub internally.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-mpnet-base-v2")
...
# Train the model
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=dev_evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=warmup_steps,
)
# Push the model to Hugging Face
model.push_to_hub("tomaarsen/mpnet-base-nli-stsb")All changes
- Add GISTEmbedLoss by @avsolatorio in #2535
- [
feat] Add 'get_config_dict' method to GISTEmbedLoss for better model cards by @tomaarsen in #2543 - Enable saving modules as pytorch_model.bin by @CKeibel in #2542
- [
deprecation] Deprecatesave_to_hubin favor ofpush_to_hub; add safe_serialization support topush_to_hubby @tomaarsen in #2544 - Fix SentenceTransformer encode documentation return type default (numpy vectors) by @CKeibel in #2546
- [
docs] Update return docstring of encode_multi_process by @tomaarsen in #2548 - [
feat] Add binary & scalar embedding quantization support to Sentence Transformers by @tomaarsen in #2549
New Contributors
- @avsolatorio made their first contribution in #2535
- @CKeibel made their first contribution in #2542
Full Changelog: v2.5.1...v2.6.0
Contributors
Assets 2
v2.5.1 - fix CrossEncoder.rank bug with default top_k
This is a patch release to fix a bug in CrossEncoder.rank that caused the last value to be discarded when using the default top_k=-1.
CrossEncoder.rank patch:
from sentence_transformers.cross_encoder import CrossEncoder
# Pre-trained cross encoder
model = CrossEncoder("cross-encoder/stsb-distilroberta-base")
# We want to compute the similarity between the query sentence
query = "A man is eating pasta."
# With all sentences in the corpus
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# We rank all sentences in the corpus for the query
ranks = model.rank(query, corpus)
# Print the scores
print("Query:", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{corpus[rank['corpus_id']]}")Query: A man is eating pasta.
0.67 A man is eating food.
0.34 A man is eating a piece of bread.
0.08 A man is riding a horse.
0.07 A man is riding a white horse on an enclosed ground.
0.01 The girl is carrying a baby.
0.01 Two men pushed carts through the woods.
0.01 A monkey is playing drums.
0.01 A woman is playing violin.
0.01 A cheetah is running behind its prey.
Previously, the lowest score document would be removed from the output.
All changes
- [
examples] Update model repo_id in 2dMatryoshka example by @tomaarsen in #2515 - [
feat] Add get_config_dict to new Matryoshka2dLoss & AdaptiveLayerLoss by @tomaarsen in #2516 - [
chore] Update to ruff 0.3.0; update ruff.toml by @tomaarsen in #2517 - [
example] Don't always normalize the embeddings in clustering example by @tomaarsen in #2520 - Fix CrossEncoder.rank default value for
top_kby @xenova in #2518
New Contributors
Full Changelog: v2.5.0...v2.5.1
Contributors
Assets 2
v2.5.0 - 2D Matryoshka & Adaptive Layer models, CrossEncoder (re)ranking
This release brings two new loss functions, a new way to (re)rank with CrossEncoder models, and more fixes
Install this version with
pip install sentence-transformers==2.5.0
2D Matryoshka & Adaptive Layer models (#2506)
Embedding models are often encoder models with numerous layers, such as 12 (e.g. all-mpnet-base-v2) or 6 (e.g. all-MiniLM-L6-v2). To get embeddings, every single one of these layers must be traversed. 2D Matryoshka Sentence Embeddings (2DMSE) revisits this concept by proposing an approach to train embedding models that will perform well when only using a selection of all layers. This results in faster inference speeds at relatively low performance costs.
For example, using Sentence Transformers, you can train an Adaptive Layer model that can be sped up by 2x at a 15% reduction in performance, or 5x on GPU & 10x on CPU for a 20% reduction in performance. The 2DMSE paper highlights scenarios where this is superior to using a smaller model.
Training
Training with Adaptive Layer support is quite elementary: rather than applying some loss function on only the last layer, we also apply that same loss function on the pooled embeddings from previous layers. Additionally, we employ a KL-divergence loss that aims to make the embeddings of the non-last layers match that of the last layer. This can be seen as a fascinating approach of knowledge distillation, but with the last layer as the teacher model and the prior layers as the student models.
For example, with the 12-layer microsoft/mpnet-base, it will now be trained such that the model produces meaningful embeddings after each of the 12 layers.
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, AdaptiveLayerLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = AdaptiveLayerLoss(model=model, loss=base_loss)- Reference:
AdaptiveLayerLoss
Additionally, this can be combined with the MatryoshkaLoss such that the resulting model can be reduced both in the number of layers, but also in the size of the output dimensions. See also the Matryoshka Embeddings for more information on reducing output dimensions. In Sentence Transformers, the combination of these two losses is called Matryoshka2dLoss, and a shorthand is provided for simpler training.
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, Matryoshka2dLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = Matryoshka2dLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])- Reference:
Matryoshka2dLoss
Performance Results
Results
Let's look at the performance that we may be able to expect from an Adaptive Layer embedding model versus a regular embedding model. For this experiment, I have trained two models:
- tomaarsen/mpnet-base-nli-adaptive-layer: Trained by running adaptive_layer_nli.py with microsoft/mpnet-base.
- tomaarsen/mpnet-base-nli: A near identical model as the former, but using only
MultipleNegativesRankingLossrather thanAdaptiveLayerLosson top ofMultipleNegativesRankingLoss. I also use microsoft/mpnet-base as the base model.
Both of these models were trained on the AllNLI dataset, which is a concatenation of the SNLI and MultiNLI datasets. I have evaluated these models on the STSBenchmark test set using multiple different embedding dimensions. The results are plotted in the following figure:
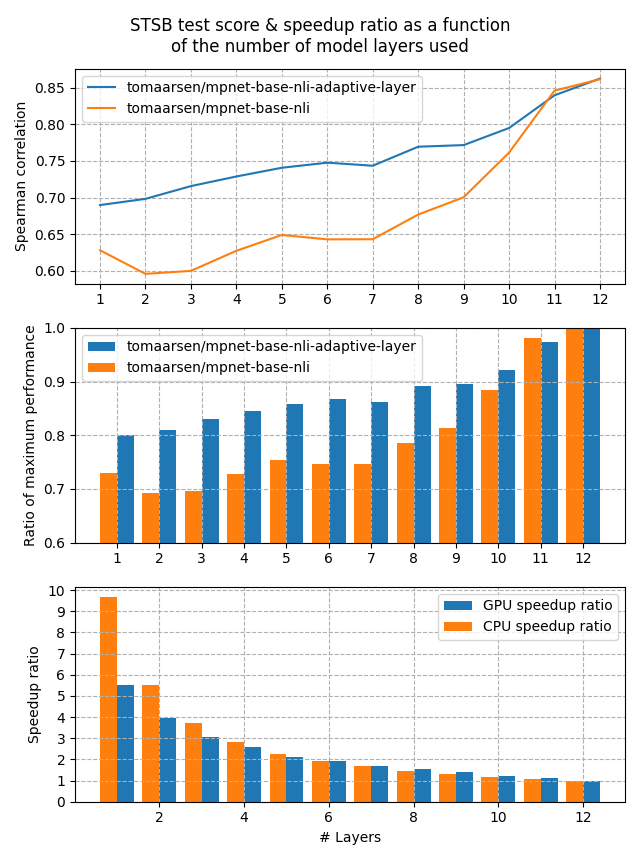
The first figure shows that the Adaptive Layer model stays much more performant when reducing the number of layers in the model. This is also clearly shown in the second figure, which displays that 80% of the performance is preserved when the number of layers is reduced all the way to 1.
Lastly, the third figure shows the expected speedup ratio for GPU & CPU devices in my tests. As you can see, removing half of the layers results in roughly a 2x speedup, at a cost of ~15% performance on STSB (~86 -> ~75 Spearman correlation). When removing even more layers, the performance benefit gets larger for CPUs, and between 5x and 10x speedups are very feasible with a 20% loss in performance.
Inference
Inference
After a model has been trained using the Adaptive Layer loss, you can then truncate the model layers to your desired layer count. Note that this requires doing a bit of surgery on the model itself, and each model is structured a bit differently, so the steps are slightly different depending on the model.
First of all, we will load the model & access the underlying transformers model like so:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("tomaarsen/mpnet-base-nli-adaptive-layer")
# We can access the underlying model with `model[0].auto_model`
print(model[0].auto_model)MPNetModel(
(embeddings): MPNetEmbeddings(
(word_embeddings): Embedding(30527, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): MPNetEncoder(
(layer): ModuleList(
(0-11): 12 x MPNetLayer(
(attention): MPNetAttention(
(attn): MPNetSelfAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(k): Linear(in_features=768, out_features=768, bias=True)
(v): Linear(in_features=768, out_features=768, bias=True)
(o): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(intermediate): MPNetIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): MPNetOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(relative_attention_bias): Embedding(32, 12)
)
(pooler): MPNetPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
This output will differ depending on the model. We will look for the repeated layers in the encoder. For this MPNet model, this is stored under model[0].auto_model.encoder.layer. Then we can slice the model to only keep the first few layers to speed up the model:
new_num_layers = 3
model[0].auto_model.encoder.layer = model[0].auto_model.encoder.layer[:new_num_layers]Then we can run inference with it using SentenceTransformers.encode.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("tomaarsen/mpnet-base-nli-adaptive-layer")
new_num_layers = 3
model[0].auto_model.encoder.layer = model[0].auto_model.encoder.layer[:new_num_layers]
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
# Similarity of the first sentence with the other two
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7761, 0.1655]])
# compared to tensor([[ 0.7547, -0.0162]]) for the full modelAs you can see, the similarity between the related sentences is much higher than the unrelated sentence, despite only using 3 layers. Feel free to copy this script locally, modify the new_num_layers, and observe the difference in similarities.
Extra information:
Example training scripts:
- adaptive_layer_nli.py
- adaptive_layer_sts.py
- 2d_matryoshka_nli.py
- [2d_matryoshka_sts.py](https://github.com/UKPLab/sentence-transfo...
Contributors
Assets 2
v2.4.0 - Matryoshka models, SOTA loss functions, prompt templates, INSTRUCTOR support
This release introduces numerous notable features that are well worth learning about!
Install this version with
pip install sentence-transformers==2.4.0
MatryoshkaLoss (#2485)
Dense embedding models typically produce embeddings with a fixed size, such as 768 or 1024. All further computations (clustering, classification, semantic search, retrieval, reranking, etc.) must then be done on these full embeddings. Matryoshka Representation Learning revisits this idea, and proposes a solution to train embedding models whose embeddings are still useful after truncation to much smaller sizes. This allows for considerably faster (bulk) processing.
Training
Training using Matryoshka Representation Learning (MRL) is quite elementary: rather than applying some loss function on only the full-size embeddings, we also apply that same loss function on truncated portions of the embeddings. For example, if a model has an embedding dimension of 768 by default, it can now be trained on 768, 512, 256, 128, 64 and 32. Each of these losses will be added together, optionally with some weight:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])- Reference:
MatryoshkaLoss
Inference
Inference
After a model has been trained using a Matryoshka loss, you can then run inference with it using SentenceTransformers.encode. You must then truncate the resulting embeddings, and it is recommended to renormalize the embeddings.
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
]
)
embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])As you can see, the similarity between the search query and the correct document is much higher than that of an unrelated document, despite the very small matryoshka dimension applied. Feel free to copy this script locally, modify the matryoshka_dim, and observe the difference in similarities.
Note: Despite the embeddings being smaller, training and inference of a Matryoshka model is not faster, not more memory-efficient, and not smaller. Only the processing and storage of the resulting embeddings will be faster and cheaper.
Extra information:
Example training scripts:
CoSENTLoss (#2454)
CoSENTLoss was introduced by Jianlin Su, 2022 as a drop-in replacement of CosineSimilarityLoss. Experiments have shown that it produces a stronger learning signal than CosineSimilarityLoss.
from sentence_transformers import SentenceTransformer, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('bert-base-uncased')
train_examples = [
InputExample(texts=['My first sentence', 'My second sentence'], label=1.0),
InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)
]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size)
train_loss = losses.CoSENTLoss(model=model)You can update training_stsbenchmark.py by replacing CosineSimilarityLoss with CoSENTLoss & you can observe the improved performance.
AnglELoss (#2471)
AnglELoss was introduced in Li and Li, 2023. It is an adaptation of the CoSENTLoss, and also acts as a strong drop-in replacement of CosineSimilarityLoss. Compared to CoSENTLoss, AnglELoss uses a different similarity function which aims to avoid vanishing gradients.
Like with CoSENTLoss, you can use it just like CosineSimilarityLoss.
from sentence_transformers import SentenceTransformer, losses
from sentence_transformers.readers import InputExample
model = SentenceTransformer('bert-base-uncased')
train_examples = [
InputExample(texts=['My first sentence', 'My second sentence'], label=1.0),
InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)
]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size)
train_loss = losses.AnglELoss(model=model)You can update training_stsbenchmark.py by replacing CosineSimilarityLoss with AnglELoss & you can observe the improved performance.
Prompt Templates (#2477)
Some models require using specific text prompts to achieve optimal performance. For example, with intfloat/multilingual-e5-large you should prefix all queries with query: and all passages with passage: . Another example is BAAI/bge-large-en-v1.5, which performs best for retrieval when the input texts are prefixed with Represent this sentence for searching relevant passages: .
Sentence Transformer models can now be initialized with prompts and default_prompt_name parameters:
promptsis an optional argument that accepts a dictionary of prompts with prompt names to prompt texts. The prompt will be prepended to the input text during inference. For example,model = SentenceTransformer( "intfloat/multilingual-e5-large", prompts={ "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }, ) # or model.prompts = { "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }
default_prompt_nameis an optional argument that determines the default prompt to be used. It has to correspond with a prompt name fromprompts. IfNone, then no prompt is used by default. For example,model = SentenceTransformer( "intfloat/multilingual-e5-large", prompts={ "classification": "Classify the following text: ", "retrieval": "Retrieve semantically similar text: ", "clustering": "Identify the topic or theme based on the text: ", }, default_prompt_name="retrieval", ) # or model.default_prompt_name="retrieval"
Both of these parameters can also be specified in the config_sentence_transformers.json file of a saved model. That way, you won't have to specify these options manually when loading. When you save a Sentence Transformer model, these options will be automatically saved as well.
During inference, prompts can be applied in a few different ways. All of these scenarios result in identical texts being embedded:
- Explicitly using the
promptoption inSentenceTransformer.encode:embeddings = model.encode("How to bake a strawberry cake", prompt="Retrieve semantically similar text: ")
- Explicitly using the
prompt_nameoption inSentenceTransformer.encodeby relying on the prompts loaded from a) initialization or b) the model config.embeddings = model.encode("How to bake a strawberry cake", prompt_name="retrieval")
- If
promptnorprompt_nameare specified inSentenceTransformer.encode, then the prompt specified bydefault_prompt_namewill be applied. If it isNone, then no prompt will be applied.embeddings = model.encode("How to bake a strawberry cake")
Instructor support (#2477)
Some INSTRUCTOR models, such as [hkunlp/instructor-large](ht...