We are building a Python library PyOE for data stream machine learning with a few lines. Researchers are welcome to use and give feedbacks!
This is the code for our paper OEBench: Investigating Open Environment Challenges in Real-World Relational Data Streams.
Relational datasets are widespread in real-world scenarios and are usually delivered in a streaming fashion. This type of data stream can present unique challenges, such as distribution drifts, outliers, emerging classes, and changing features, which have recently been described as open environment challenges for machine learning.
We develop an Open Environment Benchmark named OEBench to evaluate open environment challenges in relational data streams. Specifically, we investigate 55 real-world streaming datasets and establish that open environment scenarios are indeed widespread in real-world datasets, which presents significant challenges for stream learning algorithms.

This data processing pipeline is specifically designed for open environment learning, providing a comprehensive analysis of datasets, including missing values statistics, anomaly detection, multi-dimensional and one-dimensional drift detection, and concept drift detection. The pipeline is designed to process multiple datasets and provide a detailed report on various metrics.
The whole datasets can be downloaded from https://drive.google.com/file/d/1m7eKbycaEh38OxB7gJibUZ2kNqzVzYMf/view?usp=sharing.
This project requires the following Python packages:
- numpy
- pandas
- scikit-learn
- scikit-multiflow
- scipy
- pyod
- Keras
- tensorflow-gpu
- torch
- rtdl
- delu
- lightgbm
- xgboost
- catboost
- copulas
- menelaus (need Python >= 3.9)
- pytorch-tabnet
If import keras reports error in ADBench, please replace it with import tensorflow.keras.
-
Prepare
info.jsonandschema.jsonfor your datasets and place them in a folder nameddataset_experiment_infoin the same directory as this script. For each dataset, create a subfolder with the dataset's name. -
If only the statistics for selected datasets are desired, in the script, update the
dataset_prefix_listvariable to include the desired dataset subfolders' names from thedataset_experiment_infofolder. statistics for all datasets are desired, current code can remain unchanged as all dataset subfolders under thedataset_experiment_infofolder will be iterated. -
Run the script, and the pipeline will process each dataset in the specified list, generating various statistics and saving the results in separate CSV files within each dataset's subfolder. An
overall_stats.csvfile will also be generated, containing aggregated statistics for all datasets.
python pipeline.py
To add a new dataset to the pipeline, follow these steps:
-
Create a new subfolder within the
dataset_experiment_infofolder, named after the dataset. -
Place the dataset file (e.g., CSV or Excel) in the
datasetfolder. -
Create a schema file
schema.jsonand an dataset information fileinfo.jsonfor the dataset and place it in the same subfolder. -
If needed, add the dataset subfolder's name to the
dataset_prefix_listvariable in the script.
For example, to add a dataset called my_new_dataset, you should:
- Create a subfolder named
my_new_datasetinside thedataset_experiment_infofolder. - Place the
my_new_dataset.csvfile (or any other supported format) inside thedatasetsubfolder. - Create a schema file
schema.jsonand a information fileinfo.jsonand place them inside themy_new_datasetsubfolder. - If needed, manually add 'my_new_dataset' to the
dataset_prefix_listvariable in the script.
Template of schema.json of a dataset is as follows:
{
"numerical": ["num1", "num2"],
"categorical": ["cat1", "cat2"],
"target": ["target"],
"timestamp": ["date", "time"],
"replace_with_null": ["column_to_be_replaced_by_null"],
"window size": 0,
"unnecessary": ["unnecessary1", "unnecessary2"]
}Template of info.json of a dataset is as follows:
{
"schema": "schema.json",
"data": "dataset/my_new_.csv",
"task": "classification"
}dataset_prefix_list: A list of dataset path prefixes to process.done: A list of already processed datasets.
The run_pipeline function iterates through each dataset path prefix in the dataset_prefix_list and processes the dataset. For each dataset, the function performs the following steps:
- Pre-processes the dataset and extracts its schema.
- Processes missing values and calculates various missing value statistics.
- Detect outliers using IForest and ECOD methods.
- Detect multi-dimensional data drift using HDDDM, kdqTree and KS Statistics.
- Detect one-dimensional data drift using KS Statistics, HDDDM, kdsTree, CBDB, and PCA-CD methods.
- Detect concept drift using the PERM, ADWIN, DDM and EDDM method.
After processing each dataset, the function saves the calculated statistics in separate CSV files within each dataset's subfolder. Additionally, the overall_stats.csv file is generated, containing aggregated statistics for all datasets.
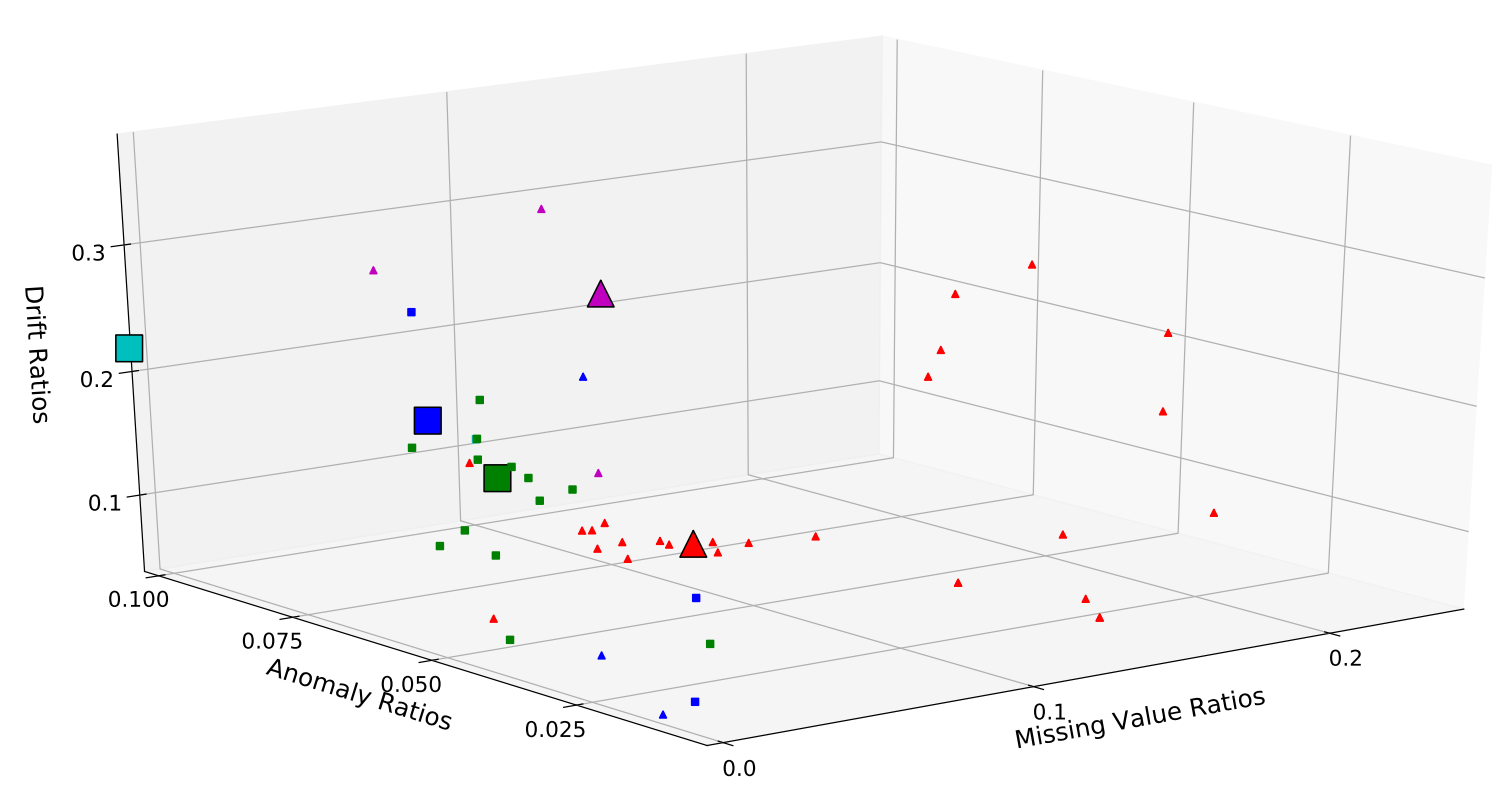
cluster.py visualizes the clusters of datasets according to our calculated statistics for three open environment problems (missing values, drifts, outliers). The purpose is to select representative datasets for further experiments on 10 stream learning algorithms.
Please refer to run.sh as an example.
| Parameter | Description |
|---|---|
model |
The model architecture. Options: mlp, tree. Default = mlp. |
gbdt |
Whether to use gbdt for tree model. Options: 0, 1. Default = 0. |
dataset |
Dataset to use. Options: selected or others from the pipeline.py (like dataset_experiment_info/airlines, etc). Default = selected. |
alg |
The training algorithm. Options: naive, ewc, lwf, icarl, sea, arf. Default = naive. |
lr |
Learning rate for MLP models, default = 0.01. |
batch-size |
Batch size for MLP models, default = 64. |
epochs |
Number of training epochs in local window for MLP models, default = 10. |
layers |
The number of layers in MLP models, default = 3. |
reg |
The regularization factor, default = 1. |
buffer |
The number of examplars allowed to store, default = 100. |
ensemble |
The ensemble size for GBDT and SEA, default = 1. |
window-factor |
The factor to multiply the default window size, default = 1. |
missing-fill |
The method to fill missing value. Options: knn_ (_ is the number of K in KNN), regression, avg, zero. Default = knn2. |
logdir |
The path to store the logs, default = ./logs/. |
device |
Specify the device to run the program, default = cpu. |
init_seed |
The initial seed, default = 0. |
- https://github.com/Minqi824/ADBench
- https://github.com/messaoudia/AdaptiveRandomForest
- https://github.com/moskomule/ewc.pytorch
If you find this repository useful, please cite our paper:
@article{diao2024oebench,
title={OEBench: Investigating Open Environment Challenges in Real-World Relational Data Streams},
author={Diao, Yiqun and Yang, Yutong and Li, Qinbin and He, Bingsheng and Lu, Mian},
journal={Proceedings of the VLDB Endowment},
volume={17},
number={6},
pages={1283--1296},
year={2024},
publisher={VLDB Endowment}
}