- Title: Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning
- Authors: Siteng Huang, Biao Gong, Yutong Feng, Min Zhang, Yiliang Lv, Donglin Wang
- Institutes: Zhejiang University, Alibaba Group, Westlake University
- More details: [arXiv] | [code] | [homepage]
🎉The paper has been accepted by CVPR 2024! The code has been released.
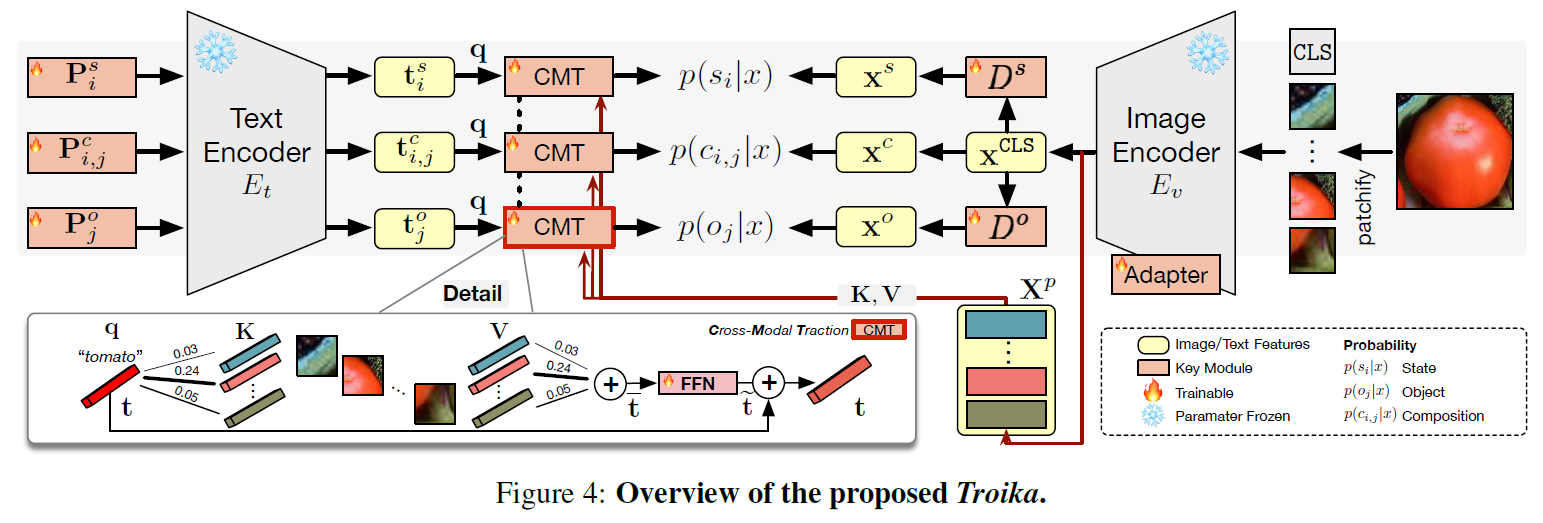
With a particular focus on the universality of the solution, in this work, we propose a novel Multi-Path paradigm for VLM-based CZSL models that establishes three identification branches to jointly model the state, object, and composition. The presented Troika is an outstanding implementation that aligns the branch-specific prompt representations with decomposed visual features. To calibrate the bias between semantically similar multi-modal representations, we further devise a Cross-Modal Traction module into Troika that shifts the prompt representation towards the current visual content. Experiments show that on the closed-world setting, Troika exceeds the current state-of-the-art methods by up to +7.4% HM and +5.7% AUC. And on the more challenging open-world setting, Troika still surpasses the best CLIP-based method by up to +3.8% HM and +2.7% AUC.
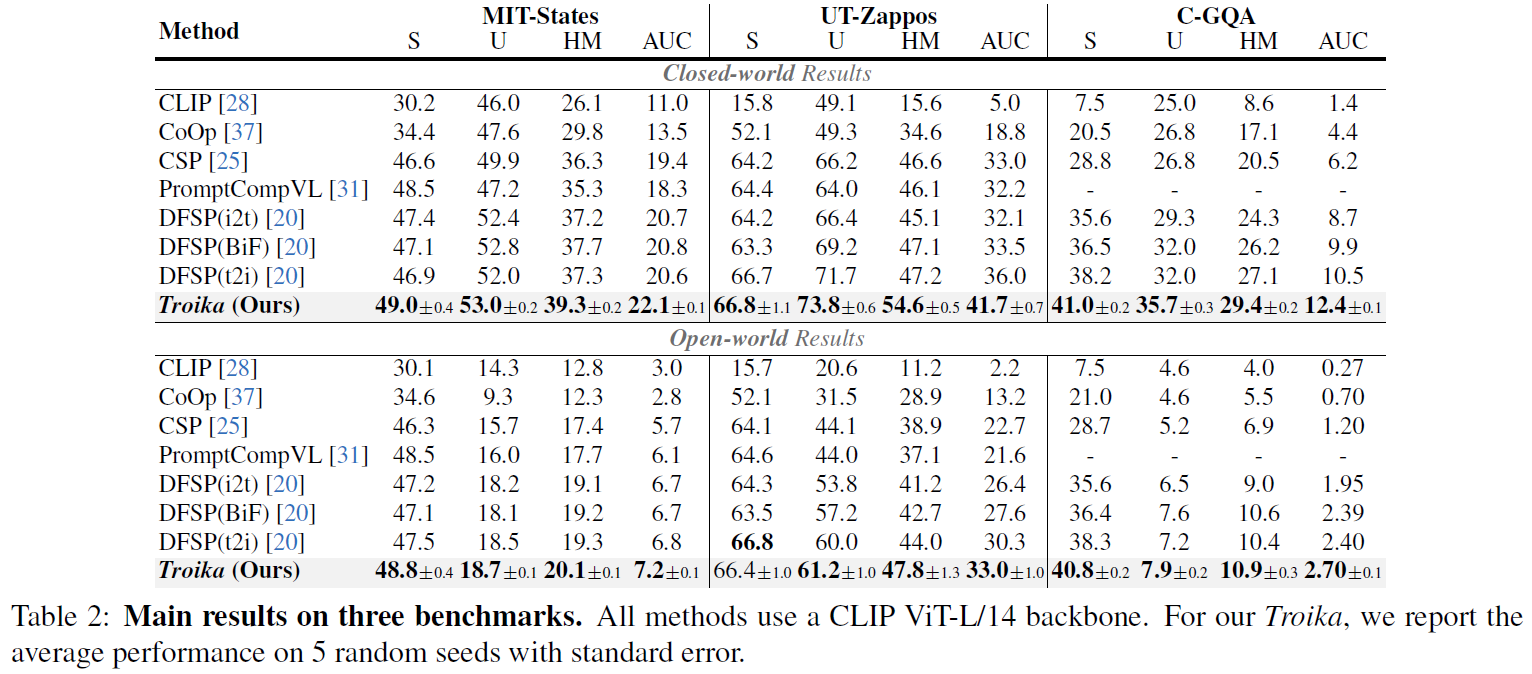
The following results are obtained with a pre-trained CLIP (ViT-L/14). More experimental results can be found in the paper.

If you find this work useful in your research, please cite our paper:
@inproceedings{Huang2024Troika,
title={Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning},
author={Siteng Huang and Biao Gong and Yutong Feng and Min Zhang and Yiliang Lv and Donglin Wang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
Our code references the following projects: