Towards Reverse-Engineering Black-Box Neural Networks, ICLR'18
Many deployed learned models are black boxes: given input, returns output. Internal information about the model, such as the architecture, optimisation procedure, or training data, is not disclosed explicitly as it might contain proprietary information or make the system more vulnerable. This work shows that such attributes of neural networks can be exposed from a sequence of queries. This has multiple implications. On the one hand, our work exposes the vulnerability of black-box neural networks to different types of attacks -- we show that the revealed internal information helps generate more effective adversarial examples against the black box model. On the other hand, this technique can be used for better protection of private content from automatic recognition models using adversarial examples. Our paper suggests that it is actually hard to draw a line between white box and black box models.
We extract diverse types of information from a black-box neural network (which we call model attributes; examples include the non-linear activation type, optimisation algorithm, training dataset) by observing its output with respect to certain query inputs. This is achieved by learning the correlation between the network attributes and certain patterns in the network's output. The correlation is learned by training a classifier over outputs from multiple models to predict the model attributes - we call this a metamodel because it literally classifies classifiers. We introduce three novel metamodel methods in this project. They differ in the way they choose the query inputs and interpret the corresponding outputs.
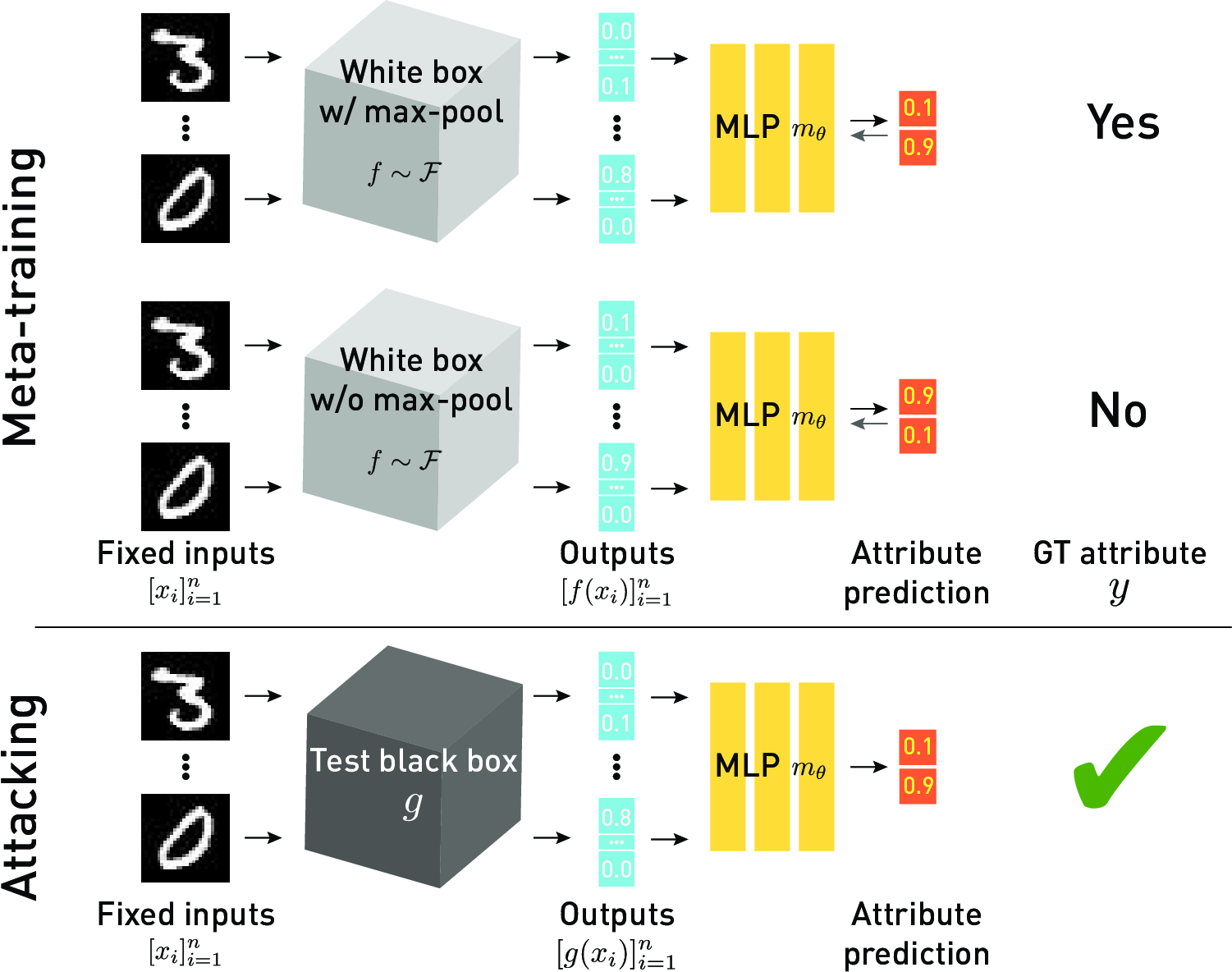
The simplest one - kennen-o - selects the query inputs at random from a dataset. An MLP classifier is trained over the outputs with respect to the selected inputs to predict network attributes. See the figure above.

Our second approach - kennen-i - approaches the problem from a completely different point of view. For the sake of clarity, we take an MNIST digit classifier as an example. Over multiple white-box models (training set models), we craft an input that is designed to expose inner secrets of the training set models. This crafted input turns out to generalise very well to unseen black-box models, in the sense that it also reveals the secrets of the unseen black box. More specifically, using gradient signals from a diverse set of white box models, we design a query input that forces an MNIST digit classifier to predict 0 if the classifier has the attribute A, and 1 if it doesn't. In other words, the crafted input re-purposes a digit classifier into a model attribute classifier. See the figure above for the training procedure. We also show below some learned query inputs which are designed to induce the prediction of label 0 if the victim black box has a max-pooling layer, train-time dropout layer, and kernel size 3, respectively, and 1 otherwise.
| Max-Pooling, yes or no? | Dropout, yes or no? | Kernel Size, 3 or 5? | |
|---|---|---|---|
| Crafted input |  |
 |
 |
| Reverse-engineering success rate (random chance) |
94.8% (50%) |
77.0% (50%) |
88.5% (50%) |
They share similarities to adversarial examples to neural networks (Explaining and Harnessing Adversarial Examples) that are also designed to alter the behaviour a neural network. The only difference is the goal. The goal of adversarial examples is to induce a specific output (e.g. wrong output, specific prediction for malicious purpose). The goal of the kennen-i inputs is to expose the model attributes. They both seem to generalise well to unseen models, enabling attacks on black boxes. (See Delving into Transferable Adversarial Examples and Black-Box Attacks for the transferability of adversarial examples.)
Our final metamodel - kennen-io - combines kennen-o and kennen-i.
The ICLR paper contains much more detailed experimental results on MNIST, including the prediction of 12 diverse model attributes, as well as extrapolation setups where the test black-box model is significantly different from the training models. We also show results on attacking black-box ImageNet classifiers with adversarial examples generated using the reverse-engineered information.
We support python versions 2.7 and 3.5 for this project. Conda environment with pytorch (with cuda8.0 or 10.0) has been used. Tested on pytorch versions 0.4.1 and 1.1.0.
VERY IMPORTANT Clone this repository recursively.
$ git clone https://github.com/coallaoh/WhitenBlackBox.git --recursiveRun the following commands to download and untar the necessary data (6.3MB).
$ mkdir cache && wget https://datasets.d2.mpi-inf.mpg.de/joon18iclr/mnist_val.pkl.tar.gz -P cache/ && cd cache && tar xvf mnist_val.pkl.tar.gz && cd ..MNIST-NET is a dataset of 11,282 diverse MNIST digit classifiers. The full pipeline for generating MNIST-NET is included in the repository (see below). The generation has taken about 40 GPU days with NVIDIA Tesla K80. Alternatively, the dataset can be downloaded from this link (19GB). Untar the downloaded file in the cache/ folder.
Follow the steps below:
wget https://datasets.d2.mpi-inf.mpg.de/joon18iclr/MNIST-NET.tar.gz
tar -xvzf MNIST-NET.tar.gz -C cache/
Running
$ ./run.pywill (1) generate the MNIST-NET dataset and (2) train and evaluate various metamodels (kennen variants - see paper) on the MNIST-NET. Read run.py in detail for more information on configuration etc.
For any problem with implementation or bug, please contact Seong Joon Oh (coallaoh at gmail).
@article{joon18iclr,
title = {Towards Reverse-Engineering Black-Box Neural Networks},
author = {Oh, Seong Joon and Augustin, Max and Schiele, Bernt and Fritz, Mario},
year = {2018},
journal = {International Conference on Learning Representations},
}