Processing Big Data with Titanoboa
Thanks to its distributed nature, titanoboa is well predisposed for Big Data processing.
You can also fine-tune how performant and robust your Big Data processing will be - based on your job channel configuration - if you are using a job channel that is robust and highly-available so will be your big data processing.
If on the other hand you are using a job channel that does not persist messages you will probably have more performant set up (but less robust). ...And of course you can combine these two approaches (it is perfectly possible to use multiple job channels and core systems in one titanoboa server.
Ultimately, if you use SQS queue as a job channel, your processing can have unlimited scalability while being most robust - your titanoboa servers can be located across multiple regions and availability zones!
But lets not get ahead of ourselves and start from the beginning:
There are two workflow step supertypes that are designed exactly for purpose of processing large(r) datasets:
-
:map - based on a sequence returned by this step's workload function, many separate atomic jobs are created
-
:reduce - performs reduce function over results returned by jobs triggered by a map step
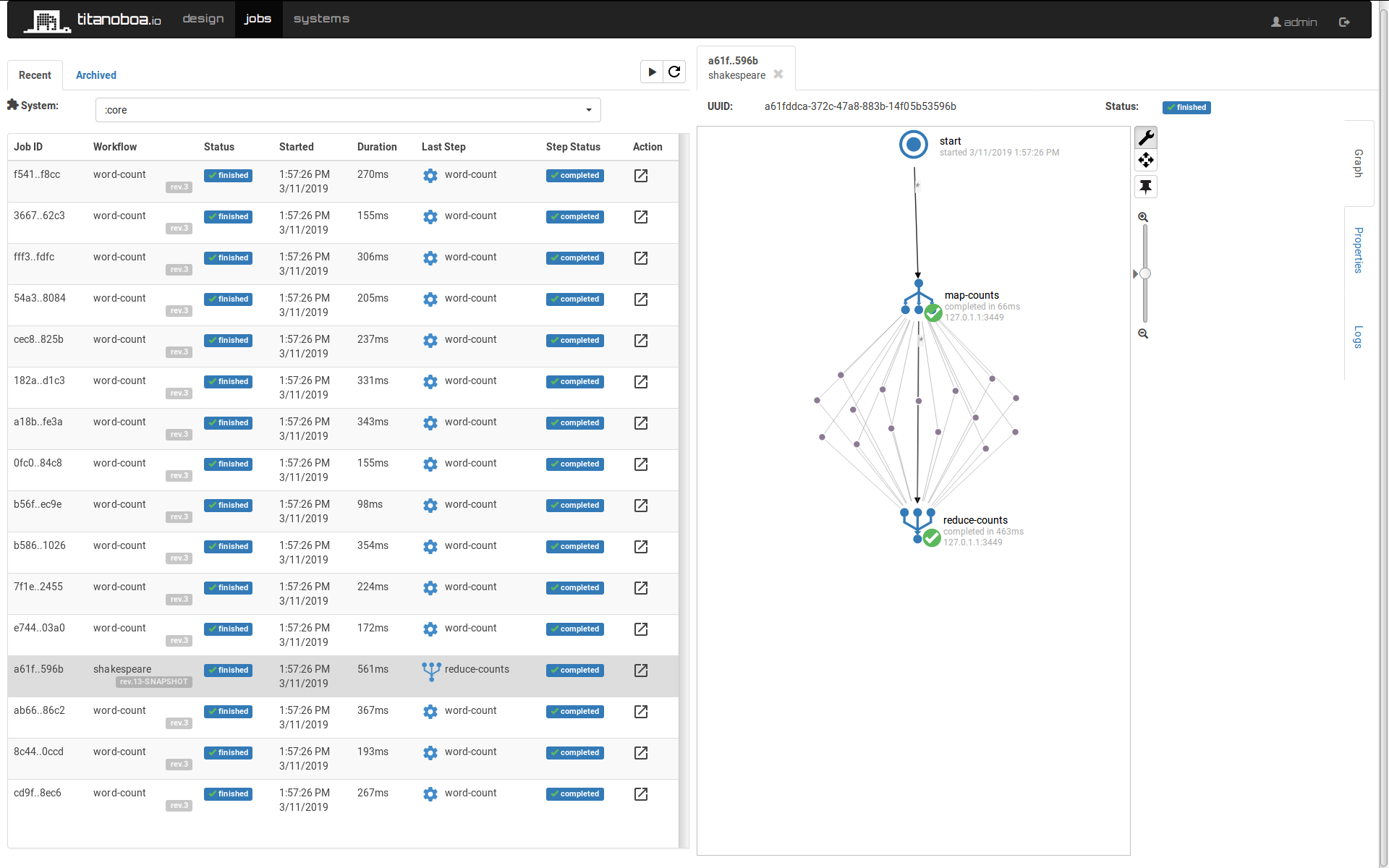
Here we can create a simple workflow that will count each word's occurrence in works of William Shakespeare.
First map step will simply return a list of files to process - and will trigger a separate workflow "count-words" for each of them. If we wanted to be more elaborate, we could further break down each play into smaller pieces, but for now this will do.
Note the :jobdef-name step property that defines which workflow to run.
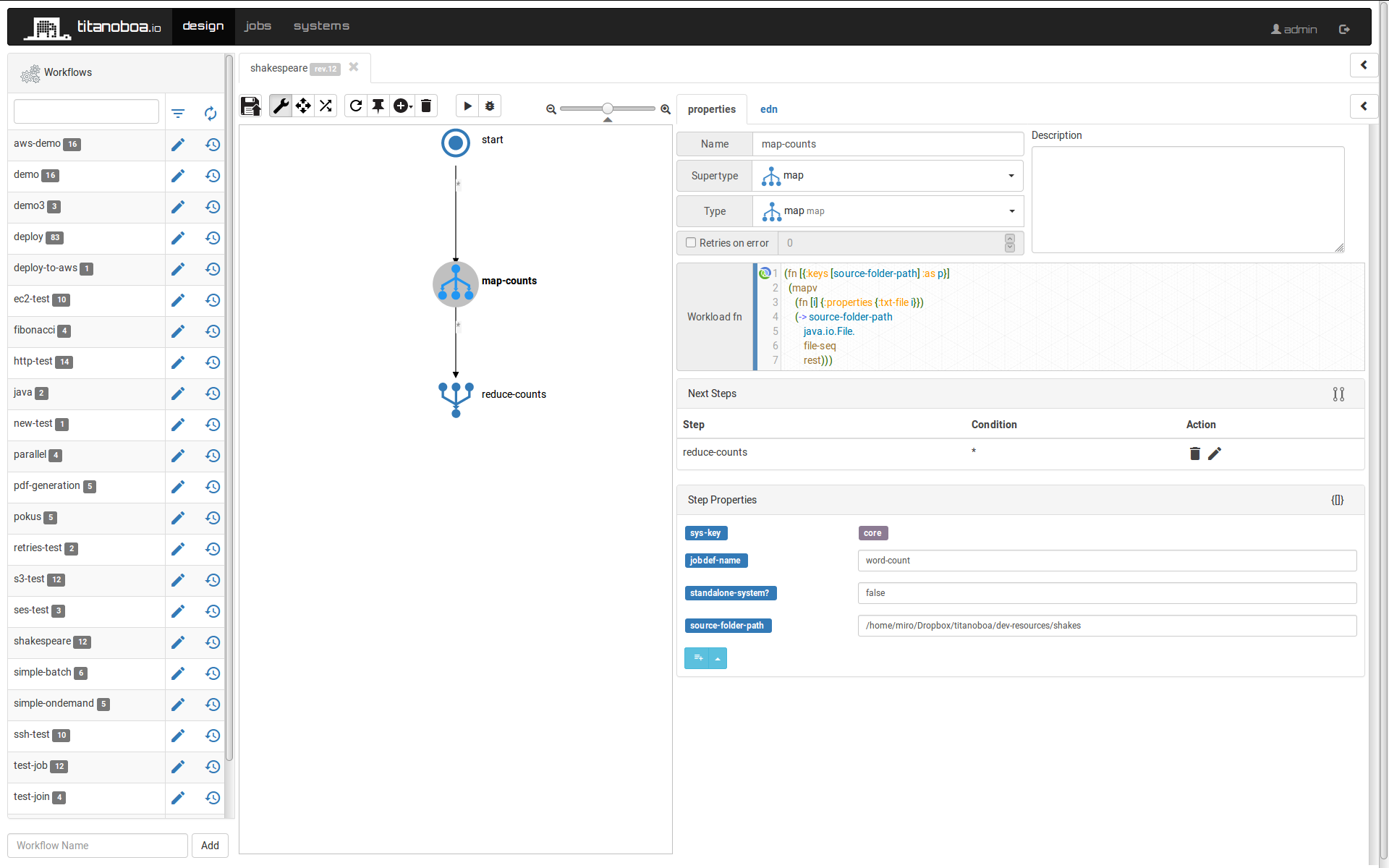
The workload function is as follows:
(fn [{:keys [source-folder-path] :as p}]
(mapv
(fn [i] {:properties {:txt-file i}})
(-> source-folder-path
java.io.File.
file-seq
rest)))In general, the "map" workload function is expected to return a sequence of maps. Each of these maps is then used as initial properties when instantiating the "count-words" child workflows.
Then there is the "word-count" workflow: it is a simple workflow with a single step, it will parse a file passed onto it and count word's frequencies in it and return it as a map.
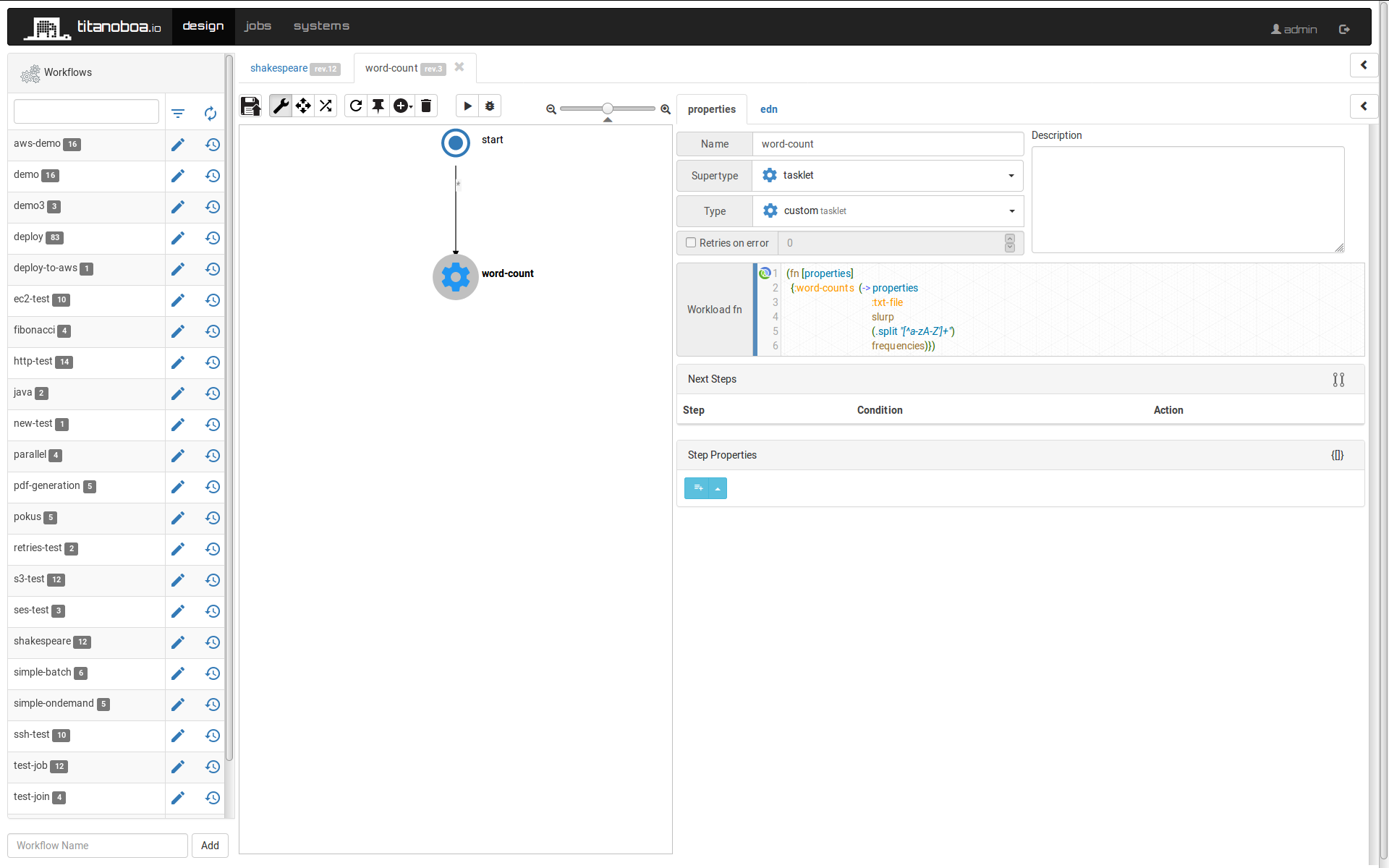
The workload function for the count step is as follows:
(fn [properties]
{:word-counts (-> properties
:txt-file
slurp
(.split "[^a-zA-Z']+")
frequencies)})The last step is a reduce step:
It takes all the results for "word-count" workflow and performs the reduce function over it - in this case it simply uses addition to sum all the counts together.
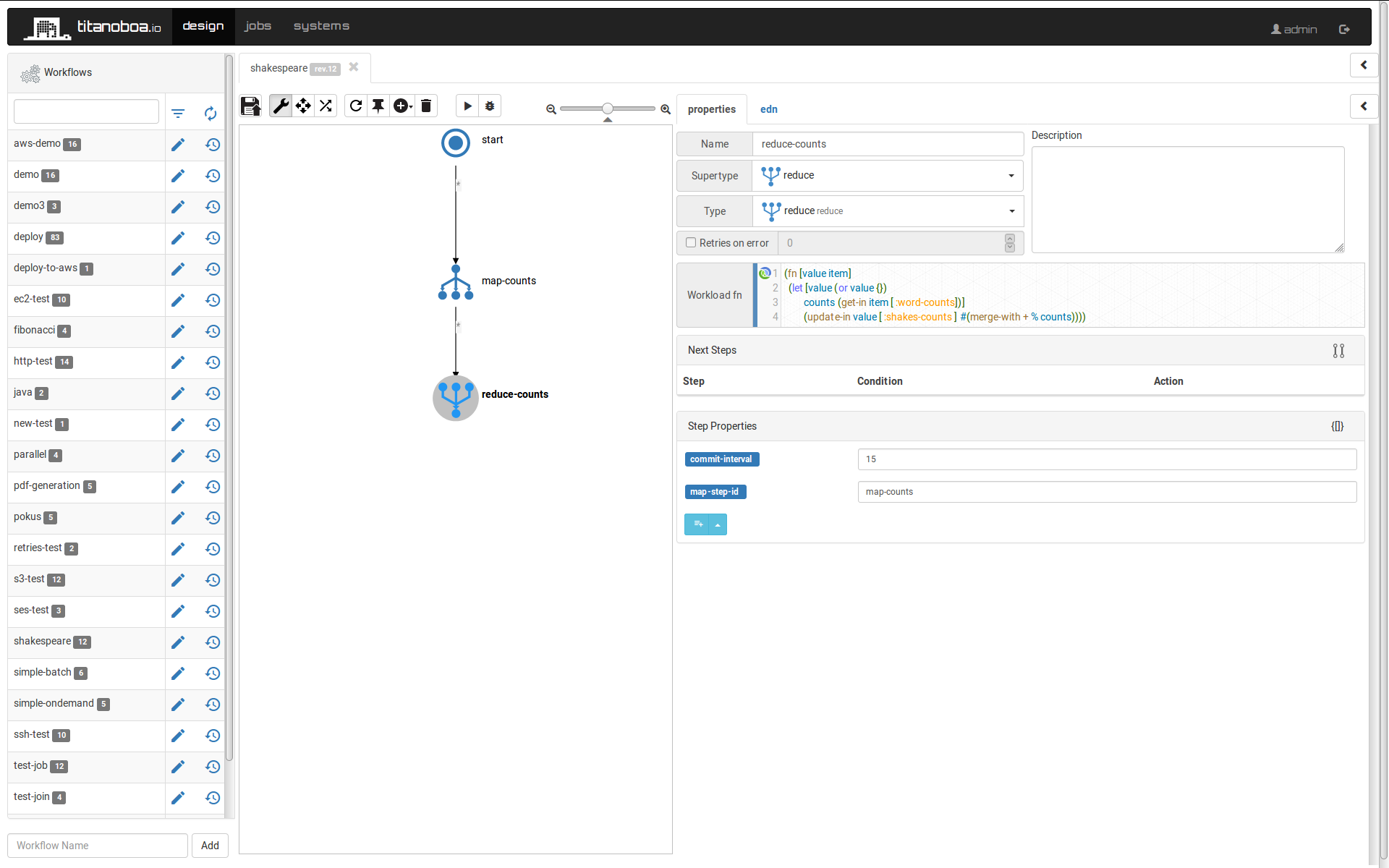
The reduce function expects two arguments current aggregate value and an item to aggregate - in this case properties from each step:
(fn [value item]
(let [value (or value {})
counts (:word-counts item)]
(update value :shakes-counts #(merge-with + % counts))))To maintain high availability, reduce steps can define commit interval after which an intermediary result is committed into a log on a file system. This way even in a case of a failover, a new node that will resume processing of the reduce step will not have to start from the beginning, but just from the latest commit.
As a result we get an (unordered) map of words' frequencies as a part of the job's properties:
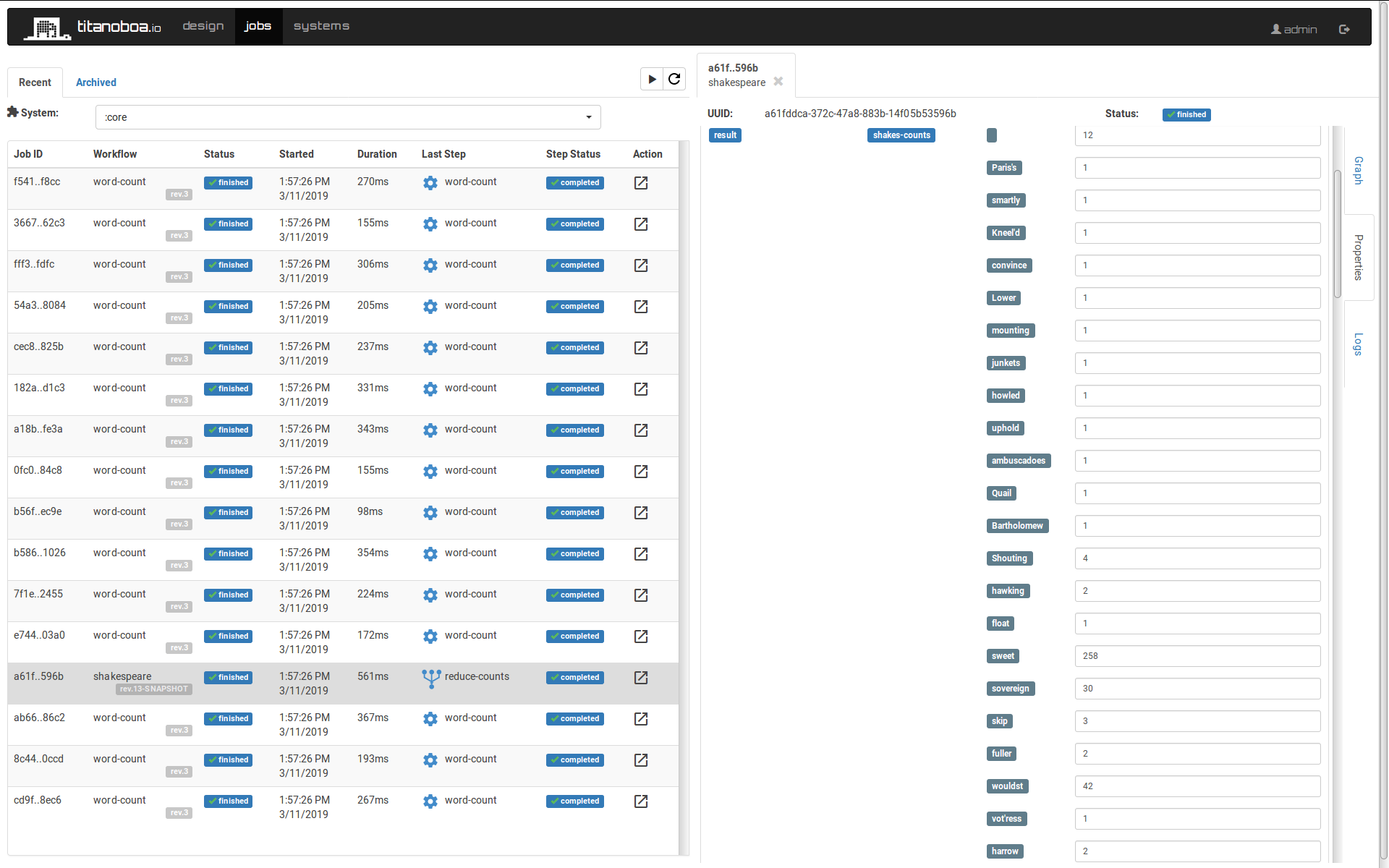
By default, the GUI shows only limited number of records (first 100 items by default), but if you would run the workflow directly via titanoboa's REST API, you could see all the words' counts in the response:
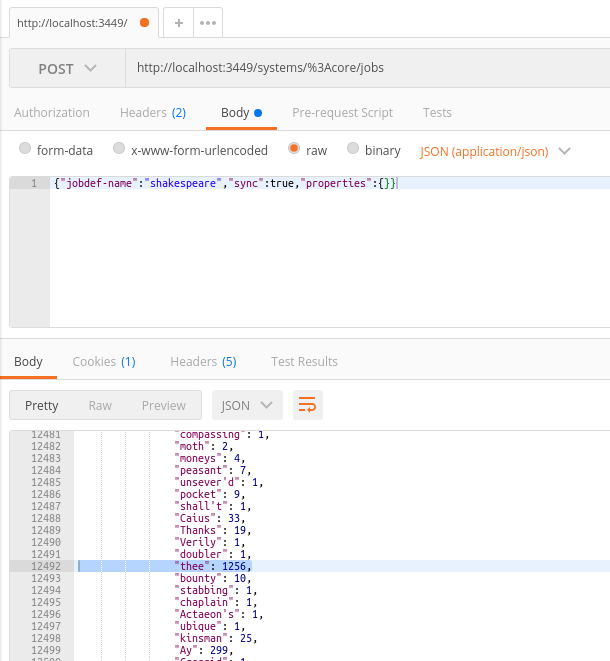
The whole example can be found here.
Read more about titanoboa on our wiki