A library primarily for procedurally generating visual poems

Conceptual writing handled by code is a fairly recent emergent field, so I would like to thank and acknowledge the following fellow travelers:
- Thanks to Allison Parrish, whose pronouncing package I used. Parrish's poetic computation projects and poetry, such as Articulations, have also been highly inspiring.
- Leonard Richardson's olipy is another generative text software library with similar (Oulipian) concerns to my own which experiments with Markov chains, Queneau assembly, and has other fun miscellaneous functions like swapping letters in a text with corrupt ASCII versions.
- Riley Wong's poetry theremin transforms light sensor values into visual poems composed from words sampled from the poetry of the great modernist Mina Loy as well as Allen Ginsberg and William Carlos Williams, among others.
You can install this software and launch the interactive menu for creating visual poems from the following link to a Jupyter notebook hosted on Google Colab.
Note: this will only work on desktop and tablet effectively because of screen-size issues. Keep this readme open to consult for reference.
Alternatively, if you install this on your own machine (see below), you can initalize the interactive menu by running the following command from a terminal/shell: generative-poetry-cli
This software library contains various constraint-based procedures for stochastically generating concrete poetry (a.k.a. visual poetry) as a PDF or to the terminal. Most of these procedures are interactive and designed to be used and re-used once you learn to "play the game" by exploiting the rules of the procedure. All these procedures rely on common building blocks, after all. When you provide a list of input words, hidden algorithms find words related to those: phonetically or by way of meaning or context (more on this below). The words are then joined with various connectors depending on the procedure: random conjunctions and punctuation, related words (often creating stochastically generated puns and prosody as well as aberrations of syntax), mathematical symbols, uniform space, variable space.
The visual poems this produces are interesting for two reasons. As readers, we are trained to read horizontally and sometimes vertically, so we draw connections based on the spatial proximity of words on a page or on a screen. We also draw connections between words with similar meanings or similar sounds to one another. When reading many of these procedurally generated poems, it is easy to suspend one's disbelief and invent a context or reading for what is happening, or try to find a meaning or intention in a seemingly enigmatic or ambiguous word choice or phrasing when the execution of the code, which is not a human author, had no ascribed intents. In this sense, these poems are similar to abstract paintings in which paint is thrown onto the canvas, or to a Rorschach test. They are, for the most part, suggestive optical illusions, engineered by chance and a choice palette of words rather than paints. Nonetheless, the way some lines weave between prosody, pun, meaning, syntax and all these elements' destruction in pure nonsense creates an amusing and unique 21st century voice that reflects the chaotic nature of the Internet itself, home to literary gems and templated spam alike, and the questionable faith of many in the eventual emergence of a sentient artificial intelligence capable of thought and writing which adopts human concerns, style, and syntax.
This project was heavily inspired by Oulipo, the literary movement founded in 1960 short for a phrase best translated as "workshop of potential literature" whose ranks included Raymond Queneau, Italo Calvino, and Georges Perec. According to Marjorie Perloff, whose work on concrete poetry and copying Unoriginal Genius was also a great inspiration for this project, "the Oulipo constraint is a generative device: it creates a formal structure whose rules of composition are internalized so that the constraint in question is not only a rule but a thematic property of the poem." Due respect also must be given to Alastair Brotchie's Book Of Surrealist Games, which has taught me to keep experimenting and combining procedures, just as the Surrealist Groups have done in practice. The conceptual artist is often stereotyped as too wedded to the pure product of the procedure, but I find this attitude unhelpful; sometimes algorithmic output needs an edit, a remix, or some other medium touched by human hands to shine.
By way of example, here are five concrete poems from the same recipe I digitally collaged together using the same procedure: the words paranoid, marinate, hysteria, radio, waves, and reverie.
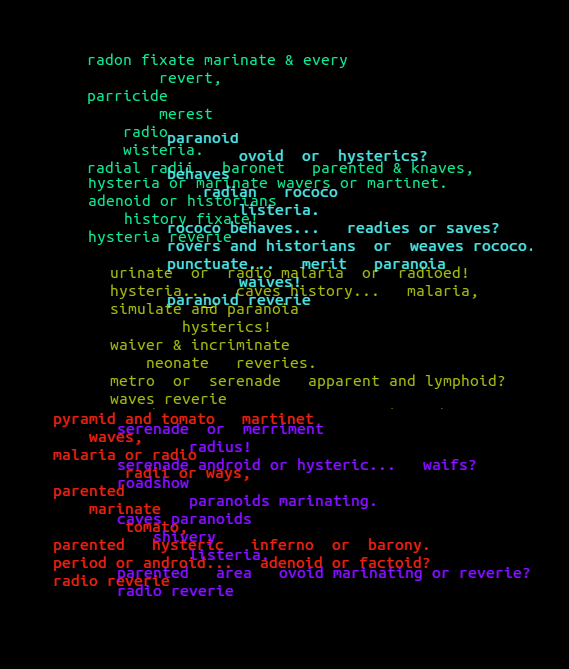
How do these procedures find related words, utilize random sampling, and filter out stuff like acronyms?
This project uses the CMU rhyming dictionary along with Datamuse API, which can find similar sounding words, similar meaning words, frequently following words, or contextually linked words for a given word. (A contextually linked word is a word that appears frequently on the Internet in the same document as another word: metamorphosis is contextually linked to the word Kafka, for example. However, CMU and Datamuse return many extremely archaic words (e.g. medieval English variants of words) as well as abbreviations, extremely uncommon words and abbreviations are mostly filtered out when the words are fetched.
This all occurs in the package's lexigen submodule, where, if you decide to import this to make your own generative text project, you can also tweak function parameters to have more or less Datamuse API results returned. Since Project Datamuse always orders their API results by relevancy (e.g. most to least similar sounding), it is possible to tweak the number of API results returned before this package randomly samples one of those words or a subset of those words in order to adjust the level of dynamism/chaos and structure/repetition in generated output.
In F.T. Marinetti's 1912 Technical Manifesto of Futurist Literature, he proposes replacing conjunctions in language with mathematical operators and eliminating most parts of speech to make a poetry of becoming and shifting velocities. In many ways this manifesto anticipates the syntax of programming languages. This method of poem generation connects random phonetically related words together with mathematical operators.
Marinetti took himself far too seriously, however. This project is more in the spirit of pataphysics which Alfred Jarry defined as "the science of imaginary solutions, which symbolically attributes the properties of objects, described by their virtuality, to their lineaments" (c.f. Exploits and Opinions of Doctor Faustroll, Pataphysician). This original 1894 meaning of 'virtuality' did not carry connotations of computation but instead those of the philosophy of his professor Henri Bergson, who attempted to rethink the metaphysics of space and time in terms of "matter and memory," e.g. the matter of the world as we perceive it vs. the layers of connotations and relationships of meaning we inevitably bring into any act of perception, linguistic creatures that we are. Nonetheless today virtuality comprises the digital world as well, and it is fitting that Jarry also wrote: "'Pataphysics will be, above all, the science of the particular, despite the common opinion that the only science is that of the general. 'Pataphysics will examine the laws governing exceptions, and will explain the universe supplementary to this one." I assure you this project implements exception handling. For more on the relationship between pataphysics and computation, see Andrew Hugill's Pataphysics And Computing.
Below is an example "Futurist poem" concerning pataphysics and surrealism. The following words were given as input: logic, dialectic, critical, surreal, and pataphysics.

This is the most complex generative method--it takes user-provided words and first gets phonetically related words to those words. It then randomly selects one of these phonetically related words, finds all the phonetically related words to that word, and picks one of those twice-removed results to begin a poem line. As the algorithms continue writing the line, they apply word transformations to previous words in the poem line (e.g. randomly selected similar meaning word, similar sounding word, contextually linked word, or frequently following word--see below) and there is also a 25% chance that another one of these operations is applied to the intermediate result. This means that there are often tens of thousands of results for the next word in a poem. The poem generator also forces line endings to rhyme in couplets.
The resultant stochastic emergence of puns and plays on words and cycle between sense and nonsense along with syntactic structure and anarchy remind me of James Joyce's Finnegan's Wake but were moreso inspired by another less known manifesto by Joyce's publisher and defender, Eugene Jolas, whose short and moving 1929 Revolution of the Word argued the poet "has the right to use words of his own fashioning and to disregard existing grammatical and syntactical laws." The generative implementation this Python package employs also occasionally switches world languages and makes cultural allusions (usually triggered by the frequently following word and contextually linked word functionality) which reminds me of Jolas' aspirations towards a Translatlantic multilingual poetry (for more on this, check out this piece by Marjorie Perloff). Right now this occurs somewhat by accident--by errors in Project Datamuse's English vocabulary--but in the future this package will incorporate more world languages as Project Datamuse incorporates them, starting with Spanish, which was recently added to Project Datamuse.
This example poem was produced from the following input words: anxious, spectacular, life, death, ascent, peace, tragedy, and love.

This one's more abstract but also more concrete, and by that I mean concrete poetry, which deals more with spatial arrangement and usually lacked syntax. The following words were given as input: chaos, dissolve, fire, morph, devolve, shapeshifter, transient, and cluster.
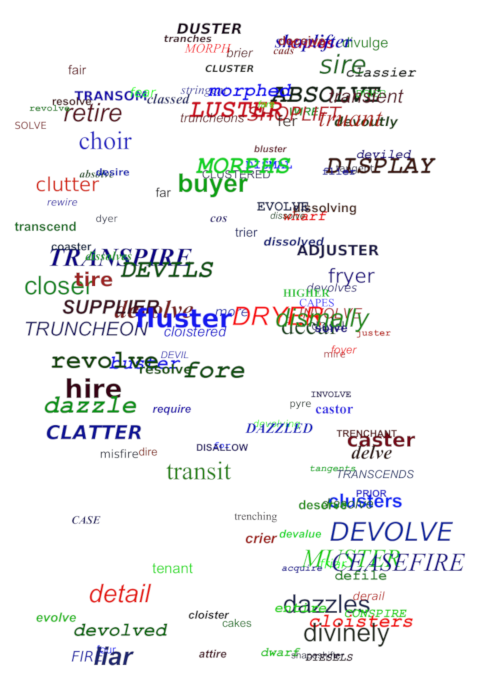
But not as chaotic as this method of making "character soup". (This method of generation does not take input words.)

And this last one does the same thing but using stop words from NLTK along with "verbal stop words" like "um" and "ahem." (This method of generation does not take input words.)

The submodule lexigen is likely useful outside of this application, as it controls random sampling of rhymes, similar sounding words, phonetically related words, similarly meaning words, contextually linked words, and rare related words.
Import the relevant submodule first.
from generativepoetry.lexigen import *
rhymes('cool') # all words that rhyme with cool
rhymes('cool', sample_size=6) # 6 random words that rhyme with cool
rhyme('cool') # 1 at random
A similar sounding word is a word that does not rhyme with a word but sounds similar.
# To get all of the similar sounding words according to Project Datamuse:
similar_sounding_word('cool', sample_size=None, datamuse_api_max=None)
# To get the top 10 similar sounding words and then randomly select 5 from that:
similar_sounding_words('cool', sample_size=5, datamuse_api_max=10)
# When not provided, sample_size defaults to 6, and datamuse_api_max defaults to 20.
# The same arguments can be optionally supplied to similar_sounding_word, which draws one word at random:
similar_sounding_word('cool', sample_size=3, datamuse_api_max=15)
similar_sounding_word('cool')
Phonetically related words are all of the rhymes and similar sounding words for a word or for a list of words
# It optionally accepts sample_size and datamuse_api_max to help the user control random sampling.
# Note that datamuse_api_max will only be used to control the number of similar meaning words
# initially fetched by the Datamuse API, however.
phonetically_related_words('slimy')
phonetically_related_words('slimy', sample_size=5, datamuse_api_max=15)
phonetically_related_words(['word', 'list'])
phonetically_related_words(['word', 'list'], sample_size=5, datamuse_api_max=15)
These include but aren't limited to synonyms; for example, spatula counts for spoon.
# To get all of the similar sounding words according to Project Datamuse:
similar_meaning_words('vampire', sample_size=None, datamuse_api_max=None)
# To get the top 10 similar sounding words and then randomly select 5 from that:
similar_meaning_words('vampire', sample_size=5, datamuse_api_max=10)
# When not provided, sample_size defaults to 6, and datamuse_api_max defaults to 20.
# The same arguments can be optionally supplied to similar_meaning_word, which draws one word at random:
similar_meaning_word('vampire', sample_size=8, datamuse_api_max=12)
similar_meaning_word('vampire')
These are words that are often found in the same documents as a given word but don't necessarily have a related meaning. For example, metamorphosis and Kafka.
# To get all of the contextually linked words according to Project Datamuse:
contextually_linked_words('metamorphosis', sample_size=None, datamuse_api_max=None)
# To get the top 10 contextually linked words and then randomly select 5 from that:
contextually_linked_words('metamorphosis', sample_size=5, datamuse_api_max=10)
# When not provided, sample_size defaults to 6, and datamuse_api_max defaults to 20.
# The same arguments can be optionally supplied to contextually_linked_word, which draws one word at random:
contextually_linked_word('metamorphosis', sample_size=8, datamuse_api_max=12)
contextually_linked_word('metamorphosis')
Finds a random sample of the rarest words that are related to a given input word, either phonetically, contextually, or by meaning.
# To get all of the related words to a given word:
related_rare_words('spherical', sample_size=None, rare_word_population_max=None)
# To get the top 10 rarest words and then randomly select 5 from that:
related_rare_words('spherical', sample_size=5, rare_word_population_max=16)
# When not provided, sample_size defaults to 8, and rare_word_population_max defaults to 20.
# The same arguments can be optionally supplied to related_rare_word, which draws one word at random:
related_rare_word('spherical', sample_size=8, rare_word_population_max=12)
related_rare_word('spherical')
These are words that frequently follow a given word in Project Datamuse's corpora.
# To get all of the frequently following words according to Project Datamuse:
frequently_following_words('metamorphosis', sample_size=None, datamuse_api_max=None)
# To get the top 10 frequently following words and then randomly select 5 from that:
frequently_following_words('metamorphosis', sample_size=5, datamuse_api_max=10)
# When not provided, sample_size defaults to 6, and datamuse_api_max defaults to 20.
# The same arguments can be optionally supplied to frequently_following_word, which draws one word at random:
frequently_following_word('metamorphosis', sample_size=8, datamuse_api_max=12)
frequently_following_word('metamorphosis')
There are many ways to write. In Unoriginal Genius, Marjorie Perloff contrasts the notion of 'original genius'--the mythic author of old who realizes works from the depths of their intellectual solitude--to a counter-tradition of 'unoriginal genius' including acts of plagiaristic parody (also known as détournement) and patchwriting. T.S. Eliot, James Joyce, and Thomas Pynchon are all exemplars of this style, having written their seminal works with encyclopedias, magazine, newspaper clippings, and world literature open face, according to Uncreative Writing by Kenneth Goldsmith.
Today there are countless ways to transform texts with software: Markov chains, cut-ups, substituting words for related words, swapping out verbs between books, GPT-2, BERT, etc. Today's cybernetic author can harness these as decomposing agents, destroying original texts to create messy new mélange that can be further edited, expanded upon, or synthesised into an original, meaningful work.
This submodule This project elaborates on these ideas, allowing the user to:
sample random sentences and paragraphs from publicly available works of literature on Project Gutenberg and Archive.org or any text you give it.
swap words that share the same part of speech between two texts--for instance, swapping all of one text's adjectives with another's and one text's nouns with another's, preserving the structure of a narrative or discursive formation while wildly changing the content. Take, for example, this passage from Charles Dickens' Great Expectations, which transforms into surrealist horror when you replace the nouns and adjectives with those from a paragraph in H.P. Lovecraft's story The Shunned House:
"It was then I began to understand that chimney in the eye had stopped, like the enveloping and the head, a human fungus ago. I noticed that Miss Havisham put down the height exactly on the time from which she had taken it up. As Estella dealt the streams, I glanced at the corpse-abhorrent again, and saw that the outline upon it, once few, now diseased, had never been worn. I glanced down at the sight from which the outline was insectoid, and saw that the half stocking on it, once few, now diseased, had been trodden ragged. Without this cosmos of thing, this standing still of all the worse monstrous attentions, not even the withered phosphorescent mist on the collapsed dissolving could have looked so like horror-mockings, or the human hideousness so like a horror."
run individual texts or list of texts through a Markov chain, semi-intelligently recombining the words in a more or less chaotic manner depending on n-gram size (which defaults to 1, the most chaotic).
Markov chain based generative algorithms like this one can create prose whose repetitions and permutations lend it a strange rhythm and which appears syntactically and semantically valid at first but eventually turns into nonsense. The Markov chain's formulaic yet sassy and subversive sstyle is quite similar Gertrude Stein's in The Making Of Americans, which she explains in details in the essay Composition as Explanation.
perform a virtual simulation of the cut-up method pioneered by William S. Burroughs and Brion Gysin by breaking texts down into components of random length (where the minimum and and maximum length in words is preserved) and then randomly rearranging them.
First, populate the Project Gutenberg cache if you are not using the pre-built Docker image:
python3 populate_cache.py
Next, import the library:
from prosedecomposer import *
To extract and clean the text from Project Gutenberg or Archive.org:
# From an Archive.org URL:
calvino_text = get_internet_archive_document('https://archive.org/stream/CalvinoItaloCosmicomics/Calvino-Italo-Cosmicomics_djvu.txt')
# From a Project Gutenberg URL:
alice_in_wonderland = get_gutenberg_document('https://www.gutenberg.org/ebooks/11')
# Select a random document from Project Gutenberg
random_gutenberg_text = random_gutenberg_document
The ParsedText class offers some functions for randomly sampling one or more sentences or paragraphs of a certain length:
parsed_calvino = ParsedText(calvino_text) parsed_calvino.random_sentence() # Returns a random sentence parsed_calvino.random_sentence(minimum_tokens=25) # Returns a random sentence of a guaranteed length in tokens parsed_calvino.random_sentences() # Returns 5 random sentences parsed_calvino.random_sentences(num=7, minimum_tokens=25) # Returns 7 random sentences of a guaranteed length parsed_calvino.random_paragraph() # Returns a random paragraph (of at least 3 sentence by default) parsed_calvino.random_paragraph(minimum_sentences=5) # Returns a paragraph with at least 5 sentences
To swap words with the same part(s) of speech between texts:
# Swap out adjectives and nouns between two random paragraphs of two random Gutenberg documents doc1 = ParsedText(random_gutenberg_document()) doc2 = ParsedText(random_gutenberg_document()) swap_parts_of_speech(doc1.random_paragraph(), doc2.random_paragraph()) # Any of Spacy's part of speech tag values should work, though: https://spacy.io/api/annotation#pos-tagging swap_parts_of_speech(doc1.random_paragraph(), doc2.random_paragraph(), parts_of_speech=["VERB", "CONJ"]) # Since NLG has not yet been implemented, expect syntax errors like subject-verb agreement.
To run text(s) through Markov chain text processing algorithms, see below. You may want a bigger n-gram size (2 or 3) if you are processing a lot of text, i.e. one or several books/stories/etc at once.
output = markov(text) # Just one text (defaults to n-gram size of 1 and 5 output sentences) output = markov(text, ngram_size=3, num_output_sentence=7) # Bigger n-gram size, more output sentences output = markov([text1, text2, text3]) # List of text (defaults to n-gram size of 1 and 5 output sentences) output = markov([text1, text2, text3], ngram_size=3, num_output_sentences=7) # Bigger n-gram size, more outputs
To virtually cut up and rearrange the text:
# Cuts up a text into cutouts between 3 and 7 words and rearrange them randomly (returns a list of cutout strings) cutouts = cutup(text) # Cuts up a text into cutouts between 2 an 10 words and rearrange them randomly (returns a list of cutout strings)
If you just want to try the notebook, I recommend using Google Colab. However, if you wish to modify the code or use some of the above functions in a live Python console or your own project, you can install the package on your local machine following the instructions listed below.
Because this library currently relies on the Python package hunspell, which does not support Windows, use Docker to launch a Linux-based container, then use pip to install, and enter the Python interactive shell within:
docker run -t -d python python3 -m pip install generativepoetry && python3
OSX users must install hunspell beforehand:
brew install hunspell
Then download the en_US dictionary from http://wordlist.aspell.net/dicts/ and unzip it to /Library/Spelling/ and install using pip:
python3 -m pip install generativepoetry
You will also need Microsoft's core font TTF files in /Library/Fonts/.
Ubuntu/Debian users should install hunspell-en-us and libhunspell-dev beforehand and then install with pip:
sudo apt-get install hunspell-en-us libhunspell-dev python3 -m pip install generativepoetry
Read documentation of library's classes & functions here .