Under the Health Insurance Portability and Accountability Act (HIPAA) minimum necessary standard, HIPAA-covered entities (such as health systems and insurers) are required to make reasonable efforts to ensure that access to Protected Health Information (PHI) is limited to the minimum necessary information to accomplish the intended purpose of particular use, disclosure, or request.
In this solution accelerator we show how to use databricks lakehouse platform and John Snow Lab's SparkOCR and NLP for Health Care pre-trained models to:
- Store clinical notes in pdf format in deltalake
- Use SparkOCR to improve image quality and extract text from pdfs
- Use SparkNLP pre-trained models for phi extraction and de-identification
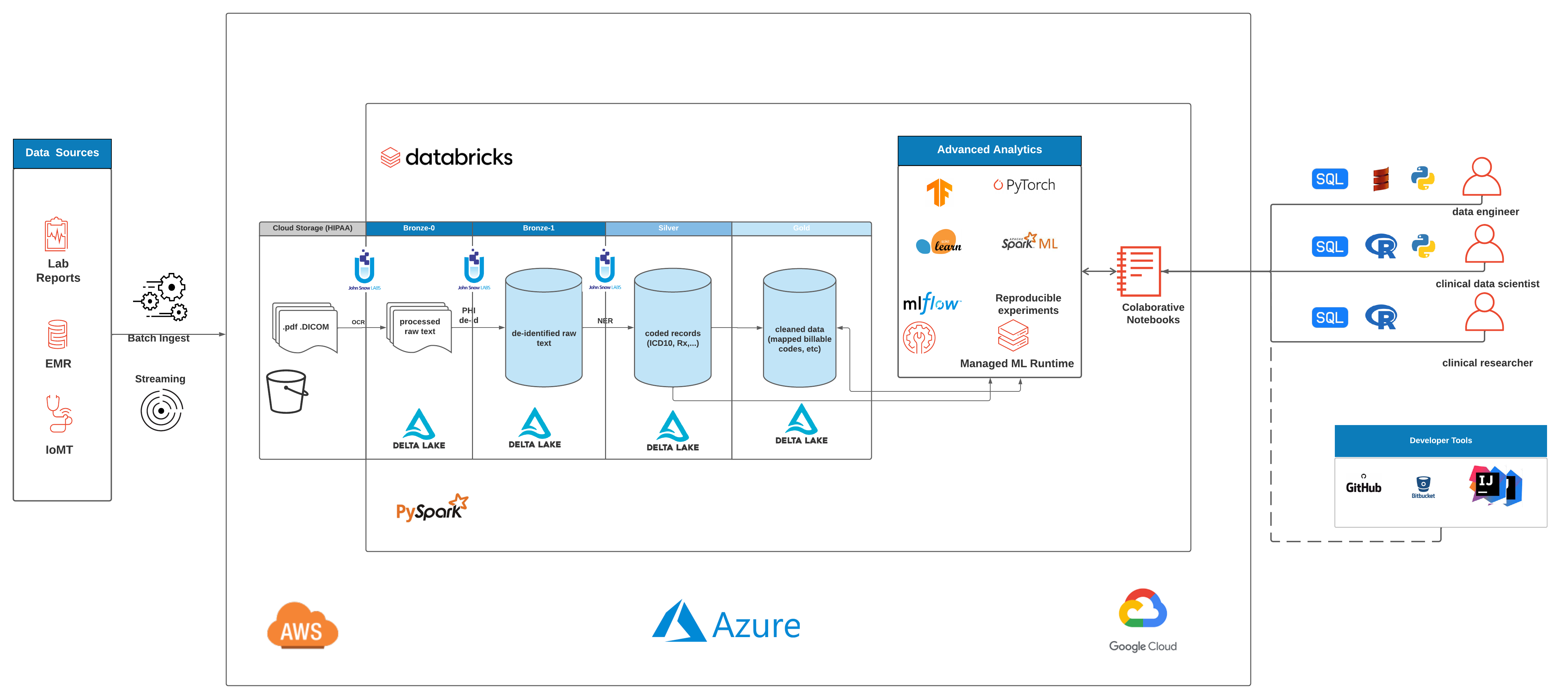
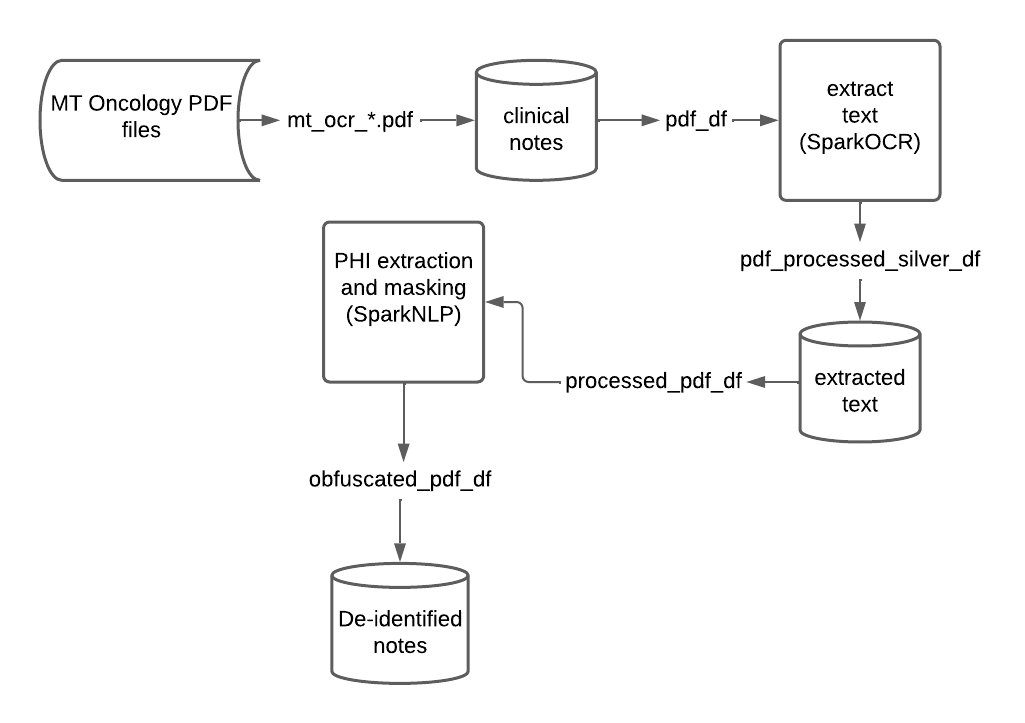
pdf-ocr: This notebook imports pdf files containing oncology reports and uses sparkOCR for image processing and text extraction. Resulting entities and text are stored in deltaphi-deidentification: In this notebook we use pre-trained models to extract phi and mask extracted phi. Resulting obfuscated clinical notes are stored in delta for downstream analysis.config: Utility notebook for setting up the environment
Copyright / License info of the notebook. Copyright [2021] the Notebook Authors. The source in this notebook is provided subject to the Apache 2.0 License. All included or referenced third party libraries are subject to the licenses set forth below.
| Library Name | Library License | Library License URL | Library Source URL |
|---|---|---|---|
| Pandas | BSD 3-Clause License | https://github.com/pandas-dev/pandas/blob/master/LICENSE | https://github.com/pandas-dev/pandas |
| Numpy | BSD 3-Clause License | https://github.com/numpy/numpy/blob/main/LICENSE.txt | https://github.com/numpy/numpy |
| Apache Spark | Apache License 2.0 | https://github.com/apache/spark/blob/master/LICENSE | https://github.com/apache/spark/tree/master/python/pyspark |
| Spark NLP | Apache-2.0 License | https://github.com/JohnSnowLabs/spark-nlp/blob/master/LICENSE | https://github.com/JohnSnowLabs/spark-nlp |
| MatPlotLib | https://github.com/matplotlib/matplotlib/blob/master/LICENSE/LICENSE | https://github.com/matplotlib/matplotlib | |
| Pillow (PIL) | HPND License | https://github.com/python-pillow/Pillow/blob/master/LICENSE | https://github.com/python-pillow/Pillow/ |
| Spark NLP for Healthcare | Proprietary license - John Snow Labs Inc. | NA | NA |
| Spark OCR | Proprietary license - John Snow Labs Inc. | NA | NA |
| Author |
|---|
| Databricks Inc. |
| John Snow Labs Inc. |
Databricks Inc. (“Databricks”) does not dispense medical, diagnosis, or treatment advice. This Solution Accelerator (“tool”) is for informational purposes only and may not be used as a substitute for professional medical advice, treatment, or diagnosis. This tool may not be used within Databricks to process Protected Health Information (“PHI”) as defined in the Health Insurance Portability and Accountability Act of 1996, unless you have executed with Databricks a contract that allows for processing PHI, an accompanying Business Associate Agreement (BAA), and are running this notebook within a HIPAA Account. Please note that if you run this notebook within Azure Databricks, your contract with Microsoft applies.
The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.
To run this accelerator, set up JSL Partner Connect AWS, Azure and navigate to My Subscriptions tab. Make sure you have a valid subscription for the workspace you clone this repo into, then install on cluster as shown in the screenshot below, with the default options. You will receive an email from JSL when the installation completes.

Once the JSL installation completes successfully, clone this repo into a Databricks workspace. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs.