Releases: facebook/zstd
Zstandard v1.5.6 - Chrome Edition
This release highlights the deployment of Google Chrome 123, introducing zstd-encoding for Web traffic, offered as a preferable option for compression of dynamic contents. With limited web server support for zstd-encoding due to its novelty, we are launching an updated Zstandard version to facilitate broader adoption.
Improved latency (time to first byte) for web pages
Using zstd compression for large documents over the Internet, data is segmented into smaller blocks of up to 128 KB, for incremental updates. This is crucial for applications like Chrome that process parts of documents as they arrive. However, on slow or congested networks, there can be some brief unresponsiveness in the middle of a block transmission, delaying update. To mitigate such scenarios, libzstd introduces the new parameter ZSTD_c_targetCBlockSize, enabling the division of blocks into even smaller segments to enhance initial byte delivery speed. Activating this feature incurs a cost, both runtime (equivalent to -2% speed at level 8) and a slight compression efficiency decrease (<0.1%), but offers some desirable latency reduction, notably beneficial in areas with more congested network infrastructure.
Improved compression ratio at high levels
Highest compression levels (typically 18+) receive some compression ratio improvement. The improvement is really noticeable for 32-bit structures, like arrays of int for example. A real-world example would the .debug_str_offsets section of DWARF debug info within ELF executables, mentioned in #2832, for which the compression effectiveness increases by +35%. It's not rare for many files or objects to contain sections of 32-bit structures, resulting in corresponding compression ratio improvements.
Granular binary size selection
libzstd provides build customization, including options to compile only the compression or decompression modules, minimizing binary size. Enhanced in v1.5.6 (source), it now allows for even finer control by enabling selective inclusion or exclusion of specific components within these modules. This advancement aids applications needing precise binary size management.
Miscellaneous Enhancements
This release includes various minor enhancements and bug fixes to enhance user experience. Key updates include an expanded list of recognized compressed file suffixes for the --exclude-compressed flag, improving efficiency by skipping presumed incompressible content. Furthermore, compatibility has been broadened to include additional chipsets (sparc64, ARM64EC, risc-v) and operating systems (QNX, AIX, Solaris, HP-UX).
Change Log
api: Promote ZSTD_c_targetCBlockSize to Stable API by @felixhandte
api: new experimental ZSTD_d_maxBlockSize parameter, to reduce streaming decompression memory, by @terrelln
perf: improve performance of param ZSTD_c_targetCBlockSize, by @Cyan4973
perf: improved compression of arrays of integers at high compression, by @Cyan4973
lib: reduce binary size with selective built-time exclusion, by @felixhandte
lib: improved huffman speed on small data and linux kernel, by @terrelln
lib: accept dictionaries with partial literal tables, by @terrelln
lib: fix CCtx size estimation with external sequence producer, by @embg
lib: fix corner case decoder behaviors, by @Cyan4973 and @aimuz
lib: fix zdict prototype mismatch in static_only mode, by @ldv-alt
lib: fix several bugs in magicless-format decoding, by @embg
cli: add common compressed file types to --exclude-compressed by @daniellerozenblit (requested by @dcog989)
cli: fix mixing -c and -o commands with --rm, by @Cyan4973
cli: fix erroneous exclusion of hidden files with --output-dir-mirror by @felixhandte
cli: improved time accuracy on BSD, by @felixhandte
cli: better errors on argument parsing, by @KapJI
tests: better compatibility with older versions of grep, by @Cyan4973
tests: lorem ipsum generator as default content generator, by @Cyan4973
build: cmake improvements by @terrelln, @sighingnow, @gjasny, @JohanMabille, @Saverio976, @gruenich, @teo-tsirpanis
build: bazel support, by @jondo2010
build: fix cross-compiling for AArch64 with lld by @jcelerier
build: fix Apple platform compatibility, by @nidhijaju
build: fix Visual 2012 and lower compatibility, by @Cyan4973
build: improve win32 support, by @DimitriPapadopoulos
build: better C90 compliance for zlibWrapper, by @emaste
port: make: fat binaries on macos, by @mredig
port: ARM64EC compatibility for Windows, by @dunhor
port: QNX support by @klausholstjacobsen
port: MSYS2 and Cygwin makefile installation and test support, by @QBos07
port: risc-v support validation in CI, by @Cyan4973
port: sparc64 support validation in CI, by @Cyan4973
port: AIX compatibility, by @likema
port: HP-UX compatibility, by @likema
doc: Improved specification accuracy, by @elasota
bug: Fix and deprecate ZSTD_generateSequences (#3981), by @terrelln
Full change list (auto-generated)
- Add win32 to windows-artifacts.yml by @Kim-SSi in #3600
- Fix mmap-dict help output by @daniellerozenblit in #3601
- [oss-fuzz] Fix simple_round_trip fuzzer with overlapping decompression by @terrelln in #3612
- Reduce streaming decompression memory by (128KB - blockSizeMax) by @terrelln in #3616
- removed travis & appveyor scripts by @Cyan4973 in #3621
- Add ZSTD_d_maxBlockSize parameter by @terrelln in #3617
- [doc] add decoder errata paragraph by @Cyan4973 in #3620
- add makefile entry to build fat binary on macos by @mredig in #3614
- Disable unused variable warning in msan configurations by @danlark1 in #3624
#3634 - Allow Build-Time Exclusion of Individual Compression Strategies by @felixhandte in #3623
- Get zstd working with ARM64EC on Windows by @dunhor in #3636
- minor : update streaming_compression example by @Cyan4973 in #3631
- Fix UBSAN issue (zero addition to NULL) by @terrelln in #3658
- Add options in Makefile to cmake by @sighingnow in #3657
- fix a minor inefficiency in compress_superblock by @Cyan4973 in #3668
- Fixed a bug in the educational decoder by @Cyan4973 in #3659
- changed LLU suffix into ULL for Visual 2012 and lower by @Cyan4973 in #3664
- fixed decoder behavior when nbSeqs==0 is encoded using 2 bytes by @Cyan4973 in #3669
- detect extraneous bytes in the Sequences section by @Cyan4973 in #3674
- Bitstream produces only zeroes after an overflow event by @Cyan4973 in #3676
- Update FreeBSD CI images to latest supported releases by @emaste in #3684
- Clean up a false error message in the LDM debug log by @embg in #3686
- Hide ASM symbols on Apple platforms by @nidhijaju in #3688
- Changed the decoding loop to detect more invalid cases of corruption sooner by @Cyan4973 in #3677
- Fix Intel Xcode builds with assembly by @gjasny in #3665
- Save one byte on the frame epilogue by @Coder-256 in #3700
- Update fileio.c: fix build failure with enabled LTO by @LocutusOfBorg in #3695
- fileio_asyncio: handle malloc fails in AIO_ReadPool_create by @void0red in #3704
- Fix typographical error in README.md by @nikohoffren in #3701
- Fixed typo by @alexsifivetw in #3712
- Improve dual license wording in README by @terrelln in #3718
- Unpoison Workspace Memory Before Custom-Free by @felixhandte in #3725
- added ZSTD_decompressDCtx() benchmark option to fullbench by @Cyan4973 in #3726
- No longer reject dictionaries with literals maxSymbolValue < 255 by @terrelln in #3731
- fix: ZSTD_BUILD_DECOMPRESSION message by @0o001 in #3728
- Updated Makefiles for full MSYS2 and Cygwin installation and testing … by @QBos07 in #3720
- Work around nullptr-with-nonzero-offset warning by @terrelln in #3738
- Fix & refactor Huffman repeat tables for dictionaries by @terrelln in #3737
- zdictlib: fix prototype mismatch by @ldv-alt in #3733
- Fixed zstd cmake shared build on windows by @JohanMabille in #3739
- Added qnx in the posix test section of platform.h by @klausholstjacobsen in #3745
- added some documentation on ZSTD_estimate*Size() variants by @Cyan4973 in #3755
- Improve macro guards for ZSTD_assertValidSequence by @terrelln in #3770
- Stop suppressing pointer-overflow U...
Contributors
Assets 10
Zstandard v1.5.5
This is a quick fix release. The primary focus is to correct a rare corruption bug in high compression mode, detected by @danlark1 . The probability to generate such a scenario by random chance is extremely low. It evaded months of continuous fuzzer tests, due to the number and complexity of simultaneous conditions required to trigger it. Nevertheless, @danlark1 from Google shepherds such a humongous amount of data that he managed to detect a reproduction case (corruptions are detected thanks to the checksum), making it possible for @terrelln to investigate and fix the bug. Thanks !
While the probability might be very small, corruption issues are nonetheless very serious, so an update to this version is highly recommended, especially if you employ high compression modes (levels 16+).
When the issue was detected, there were a number of other improvements and minor fixes already in the making, hence they are also present in this release. Let’s detail the main ones.
Improved memory usage and speed for the --patch-from mode
V1.5.5 introduces memory-mapped dictionaries, by @daniellerozenblit, for both posix #3486 and windows #3557.
This feature allows zstd to memory-map large dictionaries, rather than requiring to load them into memory. This can make a pretty big difference for memory-constrained environments operating patches for large data sets.
It's mostly visible under memory pressure, since mmap will be able to release less-used memory and continue working.
But even when memory is plentiful, there are still measurable memory benefits, as shown in the graph below, especially when the reference turns out to be not completely relevant for the patch.

This feature is automatically enabled for --patch-from compression/decompression when the dictionary is larger than the user-set memory limit. It can also be manually enabled/disabled using --mmap-dict or --no-mmap-dict respectively.
Additionally, @daniellerozenblit introduces significant speed improvements for --patch-from.
An I/O optimization in #3486 greatly improves --patch-from decompression speed on Linux, typically by +50% on large files (~1GB).

Compression speed is also taken care of, with a dictionary-indexing speed optimization introduced in #3545. It wildly accelerates --patch-from compression, typically doubling speed on large files (~1GB), sometimes even more depending on exact scenario.

This speed improvement comes at a slight regression in compression ratio, and is therefore enabled only on non-ultra compression strategies.
Speed improvements of middle-level compression for specific scenarios
The row-hash match finder introduced in version 1.5.0 for levels 5-12 has been improved in version 1.5.5, enhancing its speed in specific corner-case scenarios.
The first optimization (#3426) accelerates streaming compression using ZSTD_compressStream on small inputs by removing an expensive table initialization step. This results in remarkable speed increases for very small inputs.
The following scenario measures compression speed of ZSTD_compressStream at level 9 for different sample sizes on a linux platform running an i7-9700k cpu.
| sample size | v1.5.4 (MB/s) |
v1.5.5 (MB/s) |
improvement |
|---|---|---|---|
| 100 | 1.4 | 44.8 | x32 |
| 200 | 2.8 | 44.9 | x16 |
| 500 | 6.5 | 60.0 | x9.2 |
| 1K | 12.4 | 70.0 | x5.6 |
| 2K | 25.0 | 111.3 | x4.4 |
| 4K | 44.4 | 139.4 | x3.2 |
| ... | ... | ... | |
| 1M | 97.5 | 99.4 | +2% |
The second optimization (#3552) speeds up compression of incompressible data by a large multiplier. This is achieved by increasing the step size and reducing the frequency of matching when no matches are found, with negligible impact on the compression ratio. It makes mid-level compression essentially inexpensive when processing incompressible data, typically, already compressed data (note: this was already the case for fast compression levels).
The following scenario measures compression speed of ZSTD_compress compiled with gcc-9 for a ~10MB incompressible sample on a linux platform running an i7-9700k cpu.
| level | v1.5.4 (MB/s) |
v1.5.5 (MB/s) |
improvement |
|---|---|---|---|
| 3 | 3500 | 3500 | not a row-hash level (control) |
| 5 | 400 | 2500 | x6.2 |
| 7 | 380 | 2200 | x5.8 |
| 9 | 176 | 1880 | x10 |
| 11 | 67 | 1130 | x16 |
| 13 | 89 | 89 | not a row-hash level (control) |
Miscellaneous
There are other welcome speed improvements in this package.
For example, @felixhandte managed to increase processing speed of small files by carefully reducing the nb of system calls (#3479). This can easily translate into +10% speed when processing a lot of small files in batch.
The Seekable format received a bit of care. It's now much faster when splitting data into very small blocks (#3544). In an extreme scenario reported by @P-E-Meunier, it improves processing speed by x90. Even for more "common" settings, such as using 4KB blocks on some "normally" compressible data like enwik, it still provides a healthy x2 processing speed benefit. Moreover, @dloidolt merged an optimization that reduces the nb of I/O seek() events during reads (decompression), which is also beneficial for speed.
The release is not limited to speed improvements, several loose ends and corner cases were also fixed in this release. For a more detailed list of changes, please take a look at the changelog.
Change Log
- fix: fix rare corruption bug affecting the high compression mode, reported by @danlark1 (#3517, @terrelln)
- perf: improve mid-level compression speed (#3529, #3533, #3543, @yoniko and #3552, @terrelln)
- lib: deprecated bufferless block-level API (#3534) by @terrelln
- cli:
mmaplarge dictionaries to save memory, by @daniellerozenblit - cli: improve speed of
--patch-frommode (~+50%) (#3545) by @daniellerozenblit - cli: improve i/o speed (~+10%) when processing lots of small files (#3479) by @felixhandte
- cli:
zstdno longer crashes when requested to write into write-protected directory (#3541) by @felixhandte - cli: fix decompression into block device using
-o(#3584, @Cyan4973) reported by @georgmu - build: fix zstd CLI compiled with lzma support but not zlib support (#3494) by @Hello71
- build: fix
cmakedoes no longer require 3.18 as minimum version (#3510) by @kou - build: fix MSVC+ClangCL linking issue (#3569) by @tru
- build: fix zstd-dll, version of zstd CLI that links to the dynamic library (#3496) by @yoniko
- build: fix MSVC warnings (#3495) by @embg
- doc: updated zstd specification to clarify corner cases, by @Cyan4973
- doc: document how to create fat binaries for macos (#3568) by @rickmark
- misc: improve seekable format ingestion speed (~+100%) for very small chunk sizes (#3544) by @Cyan4973
- misc:
tests/fullbenchcan benchmark multiple files (#3516) by @dloidolt
Full change list (auto-generated)
- Fix all MSVC warnings by @embg in #3495
- Fix zstd-dll build missing dependencies by @yoniko in #3496
- Bump github/codeql-action from 2.2.1 to 2.2.4 by @dependabot in #3503
- Github Action to generate Win64 artifacts by @Cyan4973 in #3491
- Use correct types in LZMA comp/decomp by @Hello71 in #3497
- Make Github workflows permissions read-only by default by @yoniko in #3488
- CI Workflow for external compressors dependencies by @yoniko in #3505
- Fix cli-tests issues by @daniellerozenblit in #3509
- Fix Permissions on Publish Release Artifacts Job by @felixhandte in #3511
- Use
f-variants ofchmod()andchown()by @felixhandte in #3479 - Don't require CMake 3.18 or later by @kou in #3510
- meson: always build the zstd binary when tests are enabled by @eli-schwartz in #3490
- [bug-fix] Fix rare corruption bug affecting the block splitter by @terrelln in #3517
- Clarify zstd specification for Huffman blocks by @Cyan4973 in #3514
- Fix typos found by codespell by @DimitriPapadopoulos in #3513
- Bump github/codeql-action from 2.2.4 to 2.2.5 by @dependabot in #3518
- fullbench with two files by @dloidolt in #3516
- Add initialization of clevel to static cdict (#3525) by @yoniko in #3527
- [linux-kernel] Fix assert definition by @terrelln in #3532
- Add ZSTD_set{C,F,}Params() helper functions by @terrelln in #3530
- Clarify dstCapacity requirements by @terrelln in #3531
- Mmap large dictionaries in patch-from mode by @daniellerozenblit in #3486
- added...
Contributors
Assets 10
Zstandard v1.5.4
Zstandard v1.5.4 is a pretty big release benefiting from one year of work, spread over > 650 commits. It offers significant performance improvements across multiple scenarios, as well as new features (detailed below). There is a crop of little bug fixes too, a few ones targeting the 32-bit mode are important enough to make this release a recommended upgrade.
Various Speed improvements
This release has accumulated a number of scenario-specific improvements, that cumulatively benefit a good portion of installed base in one way or another.
Among the easier ones to describe, the repository has received several contributions for arm optimizations, notably from @JunHe77 and @danlark1. And @terrelln has improved decompression speed for non-x64 systems, including arm. The combination of this work is visible in the following example, using an M1-Pro (aarch64 architecture) :
| cpu | function | corpus | v1.5.2 |
v1.5.4 |
Improvement |
|---|---|---|---|---|---|
| M1 Pro | decompress | silesia.tar |
1370 MB/s | 1480 MB/s | + 8% |
| Galaxy S22 | decompress | silesia.tar |
1150 MB/s | 1200 MB/s | + 4% |
Middle compression levels (5-12) receive some care too, with @terrelln improving the dispatch engine, and @danlark1 offering NEON optimizations. Exact speed up vary depending on platform, cpu, compiler, and compression level, though one can expect gains ranging from +1 to +10% depending on scenarios.
| cpu | function | corpus | v1.5.2 |
v1.5.4 |
Improvement |
|---|---|---|---|---|---|
| i7-9700k | compress -6 | silesia.tar |
110 MB/s | 121 MB/s | +10% |
| Galaxy S22 | compress -6 | silesia.tar |
98 MB/s | 103 MB/s | +5% |
| M1 Pro | compress -6 | silesia.tar |
122 MB/s | 130 MB/s | +6.5% |
| i7-9700k | compress -9 | silesia.tar |
64 MB/s | 70 MB/s | +9.5% |
| Galaxy S22 | compress -9 | silesia.tar |
51 MB/s | 52 MB/s | +1% |
| M1 Pro | compress -9 | silesia.tar |
77 MB/s | 86 MB/s | +11.5% |
| i7-9700k | compress -12 | silesia.tar |
31.6 MB/s | 31.8 MB/s | +0.5% |
| Galaxy S22 | compress -12 | silesia.tar |
20.9 MB/s | 22.1 MB/s | +5% |
| M1 Pro | compress -12 | silesia.tar |
36.1 MB/s | 39.7 MB/s | +10% |
Speed of the streaming compression interface has been improved by @embg in scenarios involving large files (where size is a multiple of the windowSize parameter). The improvement is mostly perceptible at high speeds (i.e. ~level 1). In the following sample, the measurement is taken directly at ZSTD_compressStream() function call, using a dedicated benchmark tool tests/fullbench.
| cpu | function | corpus | v1.5.2 |
v1.5.4 |
Improvement |
|---|---|---|---|---|---|
| i7-9700k | ZSTD_compressStream() -1 |
silesia.tar |
392 MB/s | 429 MB/s | +9.5% |
| Galaxy S22 | ZSTD_compressStream() -1 |
silesia.tar |
380 MB/s | 430 MB/s | +13% |
| M1 Pro | ZSTD_compressStream() -1 |
silesia.tar |
476 MB/s | 539 MB/s | +13% |
Finally, dictionary compression speed has received a good boost by @embg. Exact outcome varies depending on system and corpus. The following result is achieved by cutting the enwik8 compression corpus into 1KB blocks, generating a dictionary from these blocks, and then benchmarking the compression speed at level 1.
| cpu | function | corpus | v1.5.2 |
v1.5.4 |
Improvement |
|---|---|---|---|---|---|
| i7-9700k | dictionary compress | enwik8 -B1K |
125 MB/s | 165 MB/s | +32% |
| Galaxy S22 | dictionary compress | enwik8 -B1K |
138 MB/s | 166 MB/s | +20% |
| M1 Pro | dictionary compress | enwik8 -B1K |
155 MB/s | 195 MB/s | +25 % |
There are a few more scenario-specifics improvements listed in the changelog section below.
I/O Performance improvements
The 1.5.4 release improves IO performance of zstd CLI, by using system buffers (macos) and adding a new asynchronous I/O capability, enabled by default on large files (when threading is available). The user can also explicitly control this capability with the --[no-]asyncio flag . These new threads remove the need to block on IO operations. The impact is mostly noticeable when decompressing large files (>= a few MBs), though exact outcome depends on environment and run conditions.
Decompression speed gets significant gains due to its single-threaded serial nature and the high speeds involved. In some cases we observe up to double performance improvement (local Mac machines) and a wide +15-45% benefit on Intel Linux servers (see table for details).
On the compression side of things, we’ve measured up to 5% improvements. The impact is lower because compression is already partially asynchronous via the internal MT mode (see release v1.3.4).
The following table shows the elapsed run time for decompressions of silesia and enwik8 on several platforms - some Skylake-era Linux servers and an M1 MacbookPro. It compares the time it takes for version v1.5.2 to version v1.5.4 with asyncio on and off.
| platform | corpus | v1.5.2 |
v1.5.4-no-asyncio |
v1.5.4 |
Improvement |
|---|---|---|---|---|---|
| Xeon D-2191A CentOS8 | enwik8 |
280 MB/s | 280 MB/s | 324 MB/s | +16% |
| Xeon D-2191A CentOS8 | silesia.tar |
303 MB/s | 302 MB/s | 386 MB/s | +27% |
| i7-1165g7 win10 | enwik8 |
270 MB/s | 280 MB/s | 350 MB/s | +27% |
| i7-1165g7 win10 | silesia.tar |
450 MB/s | 440 MB/s | 580 MB/s | +28% |
| i7-9700K Ubuntu20 | enwik8 |
600 MB/s | 604 MB/s | 829 MB/s | +38% |
| i7-9700K Ubuntu20 | silesia.tar |
683 MB/s | 678 MB/s | 991 MB/s | +45% |
| Galaxy S22 | enwik8 |
360 MB/s | 420 MB/s | 515 MB/s | +70% |
| Galaxy S22 | silesia.tar |
310 MB/s | 320 MB/s | 580 MB/s | +85% |
| MBP M1 | enwik8 |
428 MB/s | 734 MB/s | 815 MB/s | +90% |
| MBP M1 | silesia.tar |
465 MB/s | 875 MB/s | 1001 MB/s | +115% |
Support of externally-defined sequence producers
libzstd can now support external sequence producers via a new advanced registration function ZSTD_registerSequenceProducer() (#3333).
This API allows users to provide their own custom sequence producer which libzstd invokes to process each block. The produced list of sequences (literals and matches) is then post-processed by libzstd to produce valid compressed blocks.
This block-level offload API is a more granular complement of the existing frame-level offload API compressSequences() (introduced in v1.5.1). It offers an easier migration story for applications already integrated with libzstd: the user application continues to invoke the same compression functions ZSTD_compress2() or ZSTD_compressStream2() as usual, and transparently benefits from the specific properties of the external sequence producer. For example, the sequence producer could be tuned to take advantage of known characteristics of the input, to offer better speed / ratio.
One scenario that becomes possible is to combine this capability with hardware-accelerated matchfinders, such as the Intel® QuickAssist accelerator (Intel® QAT) provided in server CPUs such as the 4th Gen Intel® Xeon® Scalable processors (previously codenamed Sapphire Rapids). More details to be provided in future communications.
Change Log
perf: +20% faster huffman decompression for targets that can't compile x64 assembly (#3449, @terrelln)
perf: up to +10% faster streaming compression at levels 1-2 (#3114, @embg)
perf: +4-13% for levels 5-12 by optimizing function generation (#3295, @terrelln)
pref: +3-11% compression speed for arm target (#3199, #3164, #3145, #3141, #3138, @JunHe77 and #3139, #3160, @danlark1)
perf: +5-30% faster dictionary compression at levels 1-4 (#3086, #3114, #3152, @embg)
perf: +10-20% cold dict compression speed by prefetching CDict tables (#3177, @embg)
perf: +1% faster compression by removing a branch in ZSTD_fast_noDict (#3129, @felixhandte)
perf: Small compression ratio improvements in high compression mode (#2983, #3391, @Cyan4973 and #3285, #3302, @daniellerozenblit)
perf: small speed improvement by better detecting STATIC_BMI2 for clang (#3080, @TocarIP)
perf: Improved streaming performance when ZSTD_c_stableInBuffer is set (#2974, @Cyan4973)
cli: Asynchronous I/O for improved cli speed (#2975, #2985, #3021, #3022, @yoniko)
cli: Change zstdless behavior to align with zless (#2909, @binhdvo)
cli: Keep original file if -c or --stdout is given (#3052, @dirkmueller)
cli: Keep original files when result is concatenated into a single output with -o (#3450, @Cyan4973)
cli: Preserve Permissions and Ownership of regular files (#3432, @felixhandte)
cli: Print zlib/lz4/lzma library versions with -vv (#3030, @terrelln)
cli: Print checksum value for single frame files with -lv (#3332, @Cyan4973)
cli: Print dictID when present with -lv (#3184, @htnhan)
cli: when stderr is not the console, disable status updates, but preserve final summary (#3458, @Cyan4973)
cli: support --best and --no-name in gzip compatibility mode (#3059, @dirkmueller)
cli: support for posix high resolution timer clock_gettime(), for improved benchmark accuracy (#3423, @Cyan4973)
cli: improved help/usage (-h, -H) formatting (#3094, @dirkmueller and #3385, @jonpalmisc)
cli: Fix better handling of bogus numeric values (#3268, @ctkhanhly)
cli: Fix input consists of multiple files and stdin (#3222, @yoniko)
cli: Fix tiny files passthrough (#3215, @cgbur)
cli: Fix for -r on empty directory (#3027, @brailovich)
cli: Fix empty string as argument for --output-dir-* (#3220, @embg)
cli: Fix decompression memory usage reported by -vv --long (#3042, @u1f35c, and #3232, @zengyijing)
cli: Fix infinite loop when empty input is passed to trainer (#3081, @terrelln)
cli: Fix --adapt doesn't work when --no-progress is also set (#3354, @terrelln)
api: Support for External Sequence Producer (#3333, @embg)
api: Support for in-place decompression (#3432, @te...
Contributors
Assets 9
Zstandard v1.5.2
Zstandard v1.5.2 is a bug-fix release, addressing issues that were raised with the v1.5.1 release.
In particular, as a side-effect of the inclusion of assembly code in our source tree, binary artifacts were being marked as needing an executable stack on non-amd64 architectures. This release corrects that issue. More context is available in #2963.
This release also corrects a performance regression that was introduced in v1.5.0 that slows down compression of very small data when using the streaming API. Issue #2966 tracks that topic.
In addition there are a number of smaller improvements and fixes.
Full Changelist
- Fix zstd-static output name with MINGW/Clang by @MehdiChinoune in #2947
- storeSeq & mlBase : clarity refactoring by @Cyan4973 in #2954
- Fix mini typo by @fwessels in #2960
- Refactor offset+repcode sumtype by @Cyan4973 in #2962
- meson: fix MSVC support by @eli-schwartz in #2951
- fix performance issue in scenario #2966 (part 1) by @Cyan4973 in #2969
- [meson] Explicitly disable assembly for non clang/gcc copmilers by @terrelln in #2972
- Mark Huffman Decoder Assembly
noexecstackon All Architectures by @felixhandte in #2964 - Improve Module Map File by @felixhandte in #2953
- Remove Dependencies to Allow the Zstd Binary to Dynamically Link to the Library by @felixhandte in #2977
- [opt] Fix oss-fuzz bug in optimal parser by @terrelln in #2980
- [license] Fix license header of huf_decompress_amd64.S by @terrelln in #2981
- Fix
stderrprogress logging for decompression by @terrelln in #2982 - Fix tar test cases by @sunwire in #2956
- Fixup MSVC source file inclusion for cmake builds by @hmaarrfk in #2957
- x86-64: Hide internal assembly functions by @hjl-tools in #2993
- Prepare v1.5.2 by @felixhandte in #2987
- Documentation and minor refactor to clarify MT memory management by @embg in #3000
- Avoid updating timestamps when the destination is
stdoutby @floppym in #2998 - [build][asm] Pass ASFLAGS to the assembler instead of CFLAGS by @terrelln in #3009
- Update CI documentation by @embg in #2999
New Contributors
- @MehdiChinoune made their first contribution in #2947
- @fwessels made their first contribution in #2960
- @sunwire made their first contribution in #2956
- @hmaarrfk made their first contribution in #2957
- @floppym made their first contribution in #2998
Full Changelog: v1.5.1...v1.5.2
Contributors
Assets 10
Zstandard v1.5.1
Notice : it has been brought to our attention that the v1.5.1 library might be built with an executable stack on non-x64 architectures, which could end up being flagged as problematic by some systems with thorough security settings which disallow executable stack. We are currently reviewing the issue. Be aware of it if you build libzstd for non-x64 architecture.
Zstandard v1.5.1 is a maintenance release, bringing a good number of small refinements to the project. It also offers a welcome crop of performance improvements, as detailed below.
Performance Improvements
Speed improvements for fast compression (levels 1–4)
PRs #2749, #2774, and #2921 refactor single-segment compression for ZSTD_fast and ZSTD_dfast, which back compression levels 1 through 4 (as well as the negative compression levels). Speedups in the ~3-5% range are observed. In addition, the compression ratio of ZSTD_dfast (levels 3 and 4) is slightly improved.
Rebalanced middle compression levels
v1.5.0 introduced major speed improvements for mid-level compression (from 5 to 12), while preserving roughly similar compression ratio. As a consequence, the speed scale became tilted towards faster speed. Unfortunately, the difference between successive levels was no longer regular, and there is a large performance gap just after the impacted range, between levels 12 and 13.
v1.5.1 tries to rebalance parameters so that compression levels can be roughly associated to their former speed budget. Consequently, v1.5.1 mid compression levels feature speeds closer to former v1.4.9 (though still sensibly faster) and receive in exchange an improved compression ratio, as shown in below graph.


Note that, since middle levels only experience a rebalancing, save some special cases, no significant performance differences between versions v1.5.0 and v1.5.1 should be expected: levels merely occupy different positions on the same curve. The situation is a bit different for fast levels (1-4), for which v1.5.1 delivers a small but consistent performance benefit on all platforms, as described in previous paragraph.
Huffman Improvements
Our Huffman code was significantly revamped in this release. Both encoding and decoding speed were improved. Additionally, encoding speed for small inputs was improved even further. Speed is measured on the Silesia corpus by compressing with level 1 and extracting the literals left over after compression. Then compressing and decompressing the literals from each block. Measurements are done on an Intel i9-9900K @ 3.6 GHz.
| Compiler | Scenario | v1.5.0 Speed | v1.5.1 Speed | Delta |
|---|---|---|---|---|
| gcc-11 | Literal compression - 128KB block | 748 MB/s | 927 MB/s | +23.9% |
| clang-13 | Literal compression - 128KB block | 810 MB/s | 927 MB/s | +14.4% |
| gcc-11 | Literal compression - 4KB block | 223 MB/s | 321 MB/s | +44.0% |
| clang-13 | Literal compression - 4KB block | 224 MB/s | 310 MB/s | +38.2% |
| gcc-11 | Literal decompression - 128KB block | 1164 MB/s | 1500 MB/s | +28.8% |
| clang-13 | Literal decompression - 128KB block | 1006 MB/s | 1504 MB/s | +49.5% |
Overall impact on (de)compression speed depends on the compressibility of the data. Compression speed improves from 1-4%, and decompression speed improves from 5-15%.
PR #2722 implements the Huffman decoder in assembly for x86-64 with BMI2 enabled. We detect BMI2 support at runtime, so this speedup applies to all x86-64 builds running on CPUs that support BMI2. This improves Huffman decoding speed by about 40%, depending on the scenario. PR #2733 improves Huffman encoding speed by 10% for clang and 20% for gcc. PR #2732 drastically speeds up the HUF_sort() function, which speeds up Huffman tree building for compression. This is a significant speed boost for small inputs, measuring in at a 40% improvement for 4K inputs.
Binary Size and Build Speed
zstd binary size grew significantly in v1.5.0 due to the new code added for middle compression level speed optimizations. In this release we recover the binary size, and in the process also significantly speed up builds, especially with sanitizers enabled.
Measured on x86-64 compiled with -O3 we measure libzstd.a size. We regained 161 KB of binary size on gcc, and 293 KB of binary size on clang. Note that these binary sizes are listed for the whole library, optimized for speed over size. The decoder only, with size saving options enabled, and compiled with -Os or -Oz can be much smaller.
| Version | gcc-11 size | clang-13 size |
|---|---|---|
| v1.5.1 | 1177 KB | 1167 KB |
| v1.5.0 | 1338 KB | 1460 KB |
| v1.4.9 | 1137 KB | 1151 KB |
Change log
Featured user-visible changes
- perf: rebalanced compression levels, to better match intended speed/level curve, by @senhuang42 and @Cyan4973
- perf: faster huffman decoder, using
x64assembly, by @terrelln - perf: slightly faster high speed modes (strategies fast & dfast), by @felixhandte
- perf: smaller binary size and faster compilation times, by @terrelln and @nolange
- perf: new row64 mode, used notably at highest
lazy2levels 11-12, by @senhuang42 - perf: faster mid-level compression speed in presence of highly repetitive patterns, by @senhuang42
- perf: minor compression ratio improvements for small data at high levels, by @Cyan4973
- perf: reduced stack usage (mostly useful for Linux Kernel), by @terrelln
- perf: faster compression speed on incompressible data, by @bindhvo
- perf: on-demand reduced
ZSTD_DCtxstate size, using build macroZSTD_DECODER_INTERNAL_BUFFER, at a small cost of performance, by @bindhvo - build: allows hiding static symbols in the dynamic library, using build macro, by @skitt
- build: support for
m68k(Motorola 68000's), by @Cyan4973 - build: improved
AIXsupport, by @Helflym - build: improved meson unofficial build, by @eli-schwartz
- cli : fix : forward
mtimeto output file, by @felixhandte - cli : custom memory limit when training dictionary (#2925), by @embg
- cli : report advanced parameters information when compressing in very verbose mode (
-vv), by @Svetlitski-FB - cli : advanced commands in the form
--long-param=can accept negative value arguments, by @binhdvo
PR full list
- Add determinism fuzzers and fix rare determinism bugs by @terrelln in #2648
ZSTD_VecMask_next: fix incorrect variable name in fallback code path by @dnelson-1901 in #2657- improve tar compatibility by @Cyan4973 in #2660
- Enable SSE2 compression path to work on MSVC by @TrianglesPCT in #2653
- Fix CircleCI Config to Fully Remove
publish-github-releaseJob by @felixhandte in #2649 - [CI] Fix zlib-wrapper test by @senhuang42 in #2668
- [CI] Add ARM tests back into CI by @senhuang42 in #2667
- [trace] Refine the ZSTD_HAVE_WEAK_SYMBOLS detection by @terrelln in #2674
- [CI][1/2] Re-do the github actions workflows, migrate various travis and appveyor tests. by @senhuang42 in #2675
- Make GH Actions CI tests run apt-get update before apt-get install by @senhuang42 in #2682
- Add arm64 fuzz test to travis by @senhuang42 in #2686
- Add ldm and block splitter auto-enable to old api by @senhuang42 in #2684
- Add documentation for --patch-from by @binhdvo in #2693
- Make regression test run on every PR by @senhuang42 in #2691
- Initialize "potentially uninitialized" pointers. by @wolfpld in #2654
- Flatten
ZSTD_row_getMatchMaskby @aqrit in #2681 - Update
READMEfor Travis CI Badge by @gauthamkrishna9991 in #2700 - Fuzzer test with no intrinsics on
S390x(big endian) by @senhuang42 in #2678 - Fix
--progressflag to properly control progress display and default … by @binhdvo in #2698 - [bug] Fix entropy repeat mode bug by @senhuang42 in #2697
- Format File Sizes Human-Readable in the cli by @felixhandte in #2702
- Add support for negative values in advanced flags by @binhdvo in #2705
- [fix] Add missing bounds checks during compression by @terrelln in #2709
- Add API for fetching skippable frame content by @binhdvo in #2708
- Add option to use logical cores for default threads by @binhdvo in #2710
- lib/Makefile: Fix small typo in
ZSTD_FORCE_DECOMPRESS_*build macros by @luisdallos in #2714 - [RFC] Add internal API for converting
ZSTD_SequenceintoseqStoreby @senhuang42 in #2715 - Optimize zstd decompression by another x% by @danlark1 in https://github.com/facebook/z...
Contributors
Assets 12
Zstandard v1.5.0
v1.5.0 is a major release featuring large performance improvements as well as API changes.
Performance
Improved Middle-Level Compression Speed
1.5.0 introduces a new default match finder for the compression strategies greedy, lazy, and lazy2, (which map to levels 5-12 for inputs larger than 256K). The optimization brings a massive improvement in compression speed with slight perturbations in compression ratio (< 0.5%) and equal or decreased memory usage.
Benchmarked with gcc, on an i9-9900K:
| level | silesia.tar speed delta |
enwik7 speed delta |
|---|---|---|
| 5 | +25% | +25% |
| 6 | +50% | +50% |
| 7 | +40% | +40% |
| 8 | +40% | +50% |
| 9 | +50% | +65% |
| 10 | +65% | +80% |
| 11 | +85% | +105% |
| 12 | +110% | +140% |
On heavily loaded machines with significant cache contention, we have internally measured even larger gains: 2-3x+ speed at levels 5-7. 🚀
The biggest gains are achieved on files typically larger than 128KB. On files smaller than 16KB, by default we revert back to the legacy match finder which becomes the faster one. This default policy can be overriden manually: the new match finder can be forcibly enabled with the advanced parameter ZSTD_c_useRowMatchFinder, or through the CLI option --[no-]row-match-finder.
Note: only CPUs that support SSE2 realize the full extent of this improvement.
Improved High-Level Compression Ratio
Improving compression ratio via block splitting is now enabled by default for high compression levels (16+). The amount of benefit varies depending on the workload. Compressing archives comprised of heavily differing files will see more improvement than compression of single files that don’t vary much entropically (like text files/enwik). At levels 16+, we observe no measurable regression to compression speed.
level 22 compression
| file | ratio 1.4.9 | ratio 1.5.0 | ratio % delta |
|---|---|---|---|
| silesia.tar | 4.021 | 4.041 | +0.49% |
| calgary.tar | 3.646 | 3.672 | +0.71% |
| enwik7 | 3.579 | 3.579 | +0.0% |
The block splitter can be forcibly enabled on lower compression levels as well with the advanced parameter ZSTD_c_splitBlocks. When forcibly enabled at lower levels, speed regressions can become more notable. Additionally, since more compressed blocks may be produced, decompression speed on these blobs may also see small regressions.
Faster Decompression Speed
The decompression speed of data compressed with large window settings (such as --long or --ultra) has been significantly improved in this version. The gains vary depending on compiler brand and version, with clang generally benefiting the most.
The following benchmark was measured by compressing enwik9 at level --ultra -22 (with a 128 MB window size) on a core i7-9700K.
| Compiler version | D. Speed improvement |
|---|---|
| gcc-7 | +15% |
| gcc-8 | +10 % |
| gcc-9 | +5% |
| gcc-10 | +1% |
| clang-6 | +21% |
| clang-7 | +16% |
| clang-8 | +16% |
| clang-9 | +18% |
| clang-10 | +16% |
| clang-11 | +15% |
Average decompression speed for “normal” payload is slightly improved too, though the impact is less impressive. Once again, mileage varies depending on exact compiler version, payload, and even compression level. In general, a majority of scenarios see benefits ranging from +1 to +9%. There are also a few outliers here and there, from -4% to +13%. The average gain across all these scenarios stands at ~+4%.
Library Updates
Dynamic Library Supports Multithreading by Default
It was already possible to compile libzstd with multithreading support. But it was an active operation. By default, the make build script would build libzstd as a single-thread-only library.
This changes in v1.5.0.
Now the dynamic library (typically libzstd.so.1 on Linux) supports multi-threaded compression by default.
Note that this property is not extended to the static library (typically libzstd.a on Linux) because doing so would have impacted the build script of existing client applications (requiring them to add -pthread to their recipe), thus potentially breaking their build. In order to avoid this disruption, the static library remains single-threaded by default.
Luckily, this build disruption does not extend to the dynamic library, which can be built with multi-threading support while existing applications linking to libzstd.so and expecting only single-thread capabilities will be none the wiser, and remain completely unaffected.
The idea is that starting from v1.5.0, applications can expect the dynamic library to support multi-threading should they need it, which will progressively lead to increased adoption of this capability overtime.
That being said, since the locally deployed dynamic library may, or may not, support multi-threading compression, depending on local build configuration, it’s always better to check this capability at runtime. For this goal, it’s enough to check the return value when changing parameter ZSTD_c_nbWorkers , and if it results in an error, then multi-threading is not supported.
Q: What if I prefer to keep the libraries in single-thread mode only ?
The target make lib-nomt will ensure this outcome.
Q: Actually, I want both static and dynamic library versions to support multi-threading !
The target make lib-mt will generate this outcome.
Promotions to Stable
Moving up to the higher digit 1.5 signals an opportunity to extend the stable portion of zstd public API.
This update is relatively minor, featuring only a few non-controversial newcomers.
ZSTD_defaultCLevel() indicates which level is default (applied when selecting level 0). It completes existing
ZSTD_minCLevel() and ZSTD_maxCLevel().
Similarly, ZSTD_getDictID_fromCDict() is a straightforward equivalent to already promoted ZSTD_getDictID_fromDDict().
Deprecations
Zstd-1.4.0 stabilized a new advanced API which allows users to pass advanced parameters to zstd. We’re now deprecating all the old experimental APIs that are subsumed by the new advanced API. They will be considered for removal in the next Zstd major release zstd-1.6.0. Note that only experimental symbols are impacted. Stable functions, like ZSTD_initCStream(), remain fully supported.
The deprecated functions are listed below, together with the migration. All the suggested migrations are stable APIs, meaning that once you migrate, the API will be supported forever. See the documentation for the deprecated functions for more details on how to migrate.
- Functions that migrate to
ZSTD_compress2()with parameter setters:ZSTD_compress_advanced(): UseZSTD_CCtx_setParameter().ZSTD_compress_usingCDict_advanced(): UseZSTD_CCtx_setParameter()andZSTD_CCtx_refCDict().
- Functions that migrate to
ZSTD_compressStream()orZSTD_compressStream2()with parameter setters:ZSTD_initCStream_srcSize(): UseZSTD_CCtx_setPledgedSrcSize().ZSTD_initCStream_usingDict(): UseZSTD_CCtx_loadDictionary().ZSTD_initCStream_usingCDict(): UseZSTD_CCtx_refCDict().ZSTD_initCStream_advanced(): UseZSTD_CCtx_setParameter().ZSTD_initCStream_usingCDict_advanced(): UseZSTD_CCtx_setParameter()andZSTD_CCtx_refCDict().ZSTD_resetCStream(): UseZSTD_CCtx_reset()andZSTD_CCtx_setPledgedSrcSize().
- Functions that are deprecated without replacement. We don’t expect any users of these functions. Please open an issue if you use these and have questions about how to migrate.
ZSTD_compressBegin_advanced()ZSTD_compressBegin_usingCDict_advanced()
Header File Locations
Zstd has slightly re-organized the library layout to move all public headers to the top level lib/ directory. This is for consistency, so all public headers are in lib/ and all private headers are in a sub-directory. If you build zstd from source, this may affect your build system.
lib/common/zstd_errors.hhas moved tolib/zstd_errors.h.lib/dictBuilder/zdict.hhas moved tolib/zdict.h.
Single-File Library
We have moved the scripts in contrib/single_file_libs to build/single_file_libs. These scripts, originally contributed by @cwoffenden, produce a single compilation-unit amalgamation of the zstd library, which can be convenient for integrating Zstandard into other source trees. This move reflects a commitment on our part to support this tool and this pattern of using zstd going forward.
Windows Release Artifact Format
We are slightly c...
Zstandard v1.4.9
This is an incremental release which includes various improvements and bug-fixes.
>2x Faster Long Distance Mode
Long Distance Mode (LDM) --long just got a whole lot faster thanks to optimizations by @mpu in #2483! These optimizations preserve the compression ratio but drastically speed up compression. It is especially noticeable in multithreaded mode, because the long distance match finder is not parallelized. Benchmarking with zstd -T0 -1 --long=31 on an Intel I9-9900K at 3.2 GHz we see:
| File | v1.4.8 MB/s | v1.4.9 MB/s | Improvement |
|---|---|---|---|
| silesia.tar | 308 | 692 | 125% |
| linux-versions* | 312 | 667 | 114% |
| enwik9 | 294 | 747 | 154% |
* linux-versions is a concatenation of the linux 4.0, 5.0, and 5.10 git archives.
New Experimental Decompression Feature: ZSTD_d_refMultipleDDicts
If the advanced parameter ZSTD_d_refMultipleDDicts is enabled, then multiple calls to ZSTD_refDDict() will be honored in the corresponding DCtx. Example usage:
ZSTD_DCtx* dctx = ZSTD_createDCtx();
ZSTD_DCtx_setParameter(dctx, ZSTD_d_refMultipleDDicts, ZSTD_rmd_refMultipleDDicts);
ZSTD_DCtx_refDDict(dctx, ddict1);
ZSTD_DCtx_refDDict(dctx, ddict2);
ZSTD_DCtx_refDDict(dctx, ddict3);
...
ZSTD_decompress...
Decompression of multiple frames, each with their own dictID, is now possible with a single ZSTD_decompress call. As long as the dictID from each frame header references one of the dictIDs within the DCtx, then the corresponding dictionary will be used to decompress that particular frame. Note that this feature is disabled with a statically-allocated DCtx.
Changelog
- bug: Use
umask()to Constrain Created File Permissions (#2495, @felixhandte) - bug: Make Simple Single-Pass Functions Ignore Advanced Parameters (#2498, @terrelln)
- api: Add (De)Compression Tracing Functionality (#2482, @terrelln)
- api: Support References to Multiple DDicts (#2446, @senhuang42)
- api: Add Function to Generate Skippable Frame (#2439, @senhuang42)
- perf: New Algorithms for the Long Distance Matcher (#2483, @mpu)
- perf: Performance Improvements for Long Distance Matcher (#2464, @mpu)
- perf: Don't Shrink Window Log when Streaming with a Dictionary (#2451, @terrelln)
- cli: Fix
--output-dir-mirror's Rejection of..-Containing Paths (#2512, @felixhandte) - cli: Allow Input From Console When
-f/--forceis Passed (#2466, @felixhandte) - cli: Improve Help Message (#2500, @senhuang42)
- tests: Avoid Using
stat -con NetBSD (#2513, @felixhandte) - tests: Correctly Invoke md5 Utility on NetBSD (#2492, @Niacat)
- tests: Remove Flaky Tests (#2455, #2486, #2445, @Cyan4973)
- build: Zstd CLI Can Now be Linked to Dynamic
libzstd(#2457, #2454 @Cyan4973) - build: Avoid Using Static-Only Symbols (#2504, @skitt)
- build: Fix Fuzzer Compiler Detection & Update UBSAN Flags (#2503, @terrelln)
- build: Explicitly Hide Static Symbols (#2501, @skitt)
- build: CMake: Enable Only C for lib/ and programs/ Projects (#2498, @concatime)
- build: CMake: Use
configure_file()to Create the.pcFile (#2462, @lazka) - build: Add Guards for
_LARGEFILE_SOURCEand_LARGEFILE64_SOURCE(#2444, @indygreg) - build: Improve
zlibwrapperMakefile (#2437, @Cyan4973) - contrib: Add
recover_directoryProgram (#2473, @terrelln) - doc: Change License Year to 2021 (#2452 & #2465, @terrelln & @senhuang42)
- doc: Fix Typos (#2459, @ThomasWaldmann)
Zstandard v1.4.8 - hotfix
This is a minor hotfix for v1.4.7,
where an internal buffer unalignment bug was detected by @bmwiedemann .
The issue is of no consequence for x64 and arm64 targets,
but could become a problem for cpus relying on strict alignment, such as mips or older arm designs.
Additionally, some targets, like 32-bit x86 cpus, do not care much about alignment, but the code does, and will detect the misalignment and return an error code. Some other less common platforms, such as s390x, also seem to trigger the same issue.
While it's a minor fix, this update is nonetheless recommended.
Zstandard v1.4.7
Note : this version features a minor bug, which can be present on systems others than x64 and arm64. Update v1.4.8 is recommended for all other platforms.
v1.4.7 unleashes several months of improvements across many axis, from performance to various fixes, to new capabilities, of which a few are highlighted below. It’s a recommended upgrade.
(Note: if you ever wondered what happened to v1.4.6, it’s an internal release number reserved for synchronization with Linux Kernel)
Improved --long mode
--long mode makes it possible to analyze vast quantities of data in reasonable time and memory budget. The --long mode algorithm runs on top of the regular match finder, and both contribute to the final compressed outcome.
However, the fact that these 2 stages were working independently resulted in minor discrepancies at highest compression levels, where the cost of each decision must be carefully monitored. For this reason, in situations where the input is not a good fit for --long mode (no large repetition at long distance), enabling it could reduce compression performance, even if by very little, compared to not enabling it (at high compression levels). This situation made it more difficult to "just always enable" the --long mode by default.
This is fixed in this version. For compression levels 16 and up, usage of --long will now never regress compared to compression without --long. This property made it possible to ramp up --long mode contribution to the compression mix, improving its effectiveness.
The compression ratio improvements are most notable when --long mode is actually useful. In particular, --patch-from (which implicitly relies on --long) shows excellent gains from the improvements. We present some brief results here (tested on Macbook Pro 16“, i9).

Since --long mode is now always beneficial at high compression levels, it’s now automatically enabled for any window size >= 128MB and up.
Faster decompression of small blocks
This release includes optimizations that significantly speed up decompression of small blocks and small data. The decompression speed gains will vary based on the block size according to the table below:
| Block Size | Decompression Speed Improvement |
|---|---|
| 1 KB | ~+30% |
| 2 KB | ~+30% |
| 4 KB | ~+25% |
| 8 KB | ~+15% |
| 16 KB | ~+10% |
| 32 KB | ~+5% |
These optimizations come from improving the process of reading the block header, and building the Huffman and FSE decoding tables. zstd’s default block size is 128 KB, and at this block size the time spent decompressing the data dominates the time spent reading the block header and building the decoding tables. But, as blocks become smaller, the cost of reading the block header and building decoding tables becomes more prominent.
CLI improvements
The CLI received several noticeable upgrades with this version.
To begin with, zstd can accept a new parameter through environment variable, ZSTD_NBTHREADS . It’s useful when zstd is called behind an application (tar, or a python script for example). Also, users which prefer multithreaded compression by default can now set a desired nb of threads with their environment. This setting can still be overridden on demand via command line.
A new command --output-dir-mirror makes it possible to compress a directory containing subdirectories (typically with -r command) producing one compressed file per source file, and reproduce the arborescence into a selected destination directory.
There are other various improvements, such as more accurate warning and error messages, full equivalence between conventions --long-command=FILE and --long-command FILE, fixed confusion risks between stdin and user prompt, or between console output and status message, as well as a new short execution summary when processing multiple files, cumulatively contributing to a nicer command line experience.
New experimental features
Shared Thread Pool
By default, each compression context can be set to use a maximum nb of threads.
In complex scenarios, there might be multiple compression contexts, working in parallel, and each using some nb of threads. In such cases, it might be desirable to control the total nb of threads used by all these compression contexts altogether.
This is now possible, by making all these compression contexts share the same threadpool. This capability is expressed thanks to a new advanced compression parameter, ZSTD_CCtx_refThreadPool(), contributed by @marxin. See its documentation for more details.
Faster Dictionary Compression
This release introduces a new experimental dictionary compression algorithm, applicable to mid-range compression levels, employing strategies such as ZSTD_greedy, ZSTD_lazy, and ZSTD_lazy2. This new algorithm can be triggered by selecting the compression parameter ZSTD_c_enableDedicatedDictSearch during ZSTD_CDict creation (experimental section).
Benchmarks show the new algorithm providing significant compression speed gains :
| Level | Hot Dict | Cold Dict |
|---|---|---|
| 5 | ~+17% | ~+30% |
| 6 | ~+12% | ~+45% |
| 7 | ~+13% | ~+40% |
| 8 | ~+16% | ~+50% |
| 9 | ~+19% | ~+65% |
| 10 | ~+24% | ~+70% |
We hope it will help making mid-levels compression more attractive for dictionary scenarios. See the documentation for more details. Feedback is welcome!
New Sequence Ingestion API
We introduce a new entry point, ZSTD_compressSequences(), which makes it possible for users to define their own sequences, by whatever mechanism they prefer, and present them to this new entry point, which will generate a single zstd-compressed frame, based on provided sequences.
So for example, users can now feed to the function an array of externally generated ZSTD_Sequence:
[(offset: 5, matchLength: 4, litLength: 10), (offset: 7, matchLength: 6, litLength: 3), ...] and the function will output a zstd compressed frame based on these sequences.
This experimental API has currently several limitations (and its relevant params exist in the “experimental” section). Notably, this API currently ignores any repeat offsets provided, instead always recalculating them on the fly. Additionally, there is no way to forcibly specify existence of certain zstd features, such as RLE or raw blocks.
If you are interested in this new entry point, please refer to zstd.h for more detailed usage instructions.
Changelog
There are many other features and improvements in this release, and since we can’t highlight them all, they are listed below:
- perf: stronger
--longmode at high compression levels, by @senhuang42 - perf: stronger
--patch-fromat high compression levels, thanks to--longimprovements - perf: faster decompression speed for small blocks, by @terrelln
- perf: faster dictionary compression at medium compression levels, by @felixhandte
- perf: small speed & memory usage improvements for
ZSTD_compress2(), by @terrelln - perf: minor generic decompression speed improvements, by @helloguo
- perf: improved fast compression speeds with Visual Studio, by @animalize
- cli : Set nb of threads with environment variable
ZSTD_NBTHREADS, by @senhuang42 - cli : new
--output-dir-mirror DIRcommand, by @xxie24 (#2219) - cli : accept decompressing files with
*.zstdsuffix - cli :
--patch-fromcan compressstdinwhen used with--stream-size, by @bimbashrestha (#2206) - cli : provide a condensed summary by default when processing multiple files
- cli : fix :
stdininput can no longer be confused with user prompt - cli : fix : console output no longer mixes
stdoutand status messages - cli : improve accuracy of several error messages
- api : new sequence ingestion API, by @senhuang42
- api : shared thread pool: control total nb of threads used by multiple compression jobs, by @marxin
- api : new
ZSTD_getDictID_fromCDict(), by @LuAPi - api : zlibWrapper only uses public API, and is compatible with dynamic library, by @terrelln
- api : fix : multithreaded compression has predictable output even in special cases (see #2327) (issue not present on cli)
- api : fix : dictionary compression correctly respects dictionary compression level (see #2303) (issue not present on cli)
- api : fix : return
dstSize_tooSmallerror whenever appropriate - api : fix :
ZSTD_initCStream_advanced()with static allocation and no dictionary - build: fix cmake script when employing path including spaces, by @terrelln
- build: new
ZSTD_NO_INTRINSICSmacro to avoid explicit intrinsics - build: new
STATIC_BMI2macro for compile time detection of BMI2 on MSVC, by @Niadb (#2258) - build: improved compile-time detection of aarch64/neon platforms, by @bsdimp
- build: Fix building on AIX 5.1, by @likema
- build: compile paramgrill with cmake on Windows, requested by @mirh
- build: install pkg-config file with CMake and MinGW, by @tonytheodore (#2183)
- build: Install DLL with CMake on Windows, by @BioDataAnalysis (#2221)
- build: fix : cli compilation with uclibc
- misc: Improve single file library and include dictBuilder, by @cwoffenden
- misc: Fix single file library compilation with Emscripten, by @yoshihitoh (#2227)
- misc: Add freestanding translation script in
contrib/freestanding_lib, by @terrelln - doc : clarify repcode updates in format specification, by @felixhandte
Zstandard v1.4.5
Zstd v1.4.5 Release Notes
This is a fairly important release which includes performance improvements and new major CLI features. It also fixes a few corner cases, making it a recommended upgrade.
Faster Decompression Speed
Decompression speed has been improved again, thanks to great contributions from @terrelln.
As usual, exact mileage varies depending on files and compilers.
For x64 cpus, expect a speed bump of at least +5%, and up to +10% in favorable cases.
ARM cpus receive more benefit, with speed improvements ranging from +15% vicinity, and up to +50% for certain SoCs and scenarios (ARM‘s situation is more complex due to larger differences in SoC designs).
For illustration, some benchmarks run on a modern x64 platform using zstd -b compiled with gcc v9.3.0 :
| v1.4.4 | v1.4.5 | |
|---|---|---|
| silesia.tar | 1568 MB/s | 1653 MB/s |
| --- | --- | --- |
| enwik8 | 1374 MB/s | 1469 MB/s |
| calgary.tar | 1511 MB/s | 1610 MB/s |
Same platform, using clang v10.0.0 compiler :
| v1.4.4 | v1.4.5 | |
|---|---|---|
| silesia.tar | 1439 MB/s | 1496 MB/s |
| --- | --- | --- |
| enwik8 | 1232 MB/s | 1335 MB/s |
| calgary.tar | 1361 MB/s | 1457 MB/s |
Simplified integration
Presuming a project needs to integrate libzstd's source code (as opposed to linking a pre-compiled library), the /lib source directory can be copy/pasted into target project. Then the local build system must setup a few include directories. Some setups are automatically provided in prepared build scripts, such as Makefile, but any other 3rd party build system must do it on its own.
This integration is now simplified, thanks to @felixhandte, by making all dependencies within /lib relative, meaning it’s only necessary to setup include directories for the *.h header files that are directly included into target project (typically zstd.h). Even that task can be circumvented by copy/pasting the *.h into already established include directories.
Alternatively, if you are a fan of one-file integration strategy, @cwoffenden has extended his one-file decoder script into a full feature one-file compression library. The script create_single_file_library.sh will generate a file zstd.c, which contains all selected elements from the library (by default, compression and decompression). It’s then enough to import just zstd.h and the generated zstd.c into target project to access all included capabilities.
--patch-from
Zstandard CLI is introducing a new command line option --patch-from, which leverages existing compressors, dictionaries and long range match finder to deliver a high speed engine for producing and applying patches to files.
--patch-from is based on dictionary compression. It will consider a previous version of a file as a dictionary, to better compress a new version of same file. This operation preserves fast zstd speeds at lower compression levels. To this ends, it also increases the previous maximum limit for dictionaries from 32 MB to 2 GB, and automatically uses the long range match finder when needed (though it can also be manually overruled).
--patch-from can also be combined with multi-threading mode at a very minimal compression ratio loss.
Example usage:
# create the patch
zstd --patch-from=<oldfile> <newfile> -o <patchfile>
# apply the patch
zstd -d --patch-from=<oldfile> <patchfile> -o <newfile>`
Benchmarks:
We compared zstd to bsdiff, a popular industry grade diff engine. Our test corpus were tarballs of different versions of source code from popular GitHub repositories. Specifically:
`repos = {
# ~31mb (small file)
"zstd": {"url": "https://github.com/facebook/zstd", "dict-branch": "refs/tags/v1.4.2", "src-branch": "refs/tags/v1.4.3"},
# ~273mb (medium file)
"wordpress": {"url": "https://github.com/WordPress/WordPress", "dict-branch": "refs/tags/5.3.1", "src-branch": "refs/tags/5.3.2"},
# ~1.66gb (large file)
"llvm": {"url": "https://github.com/llvm/llvm-project", "dict-branch": "refs/tags/llvmorg-9.0.0", "src-branch": "refs/tags/llvmorg-9.0.1"}
}`
--patch-from on level 19 (with chainLog=30 and targetLength=4kb) is comparable with bsdiff when comparing patch sizes.
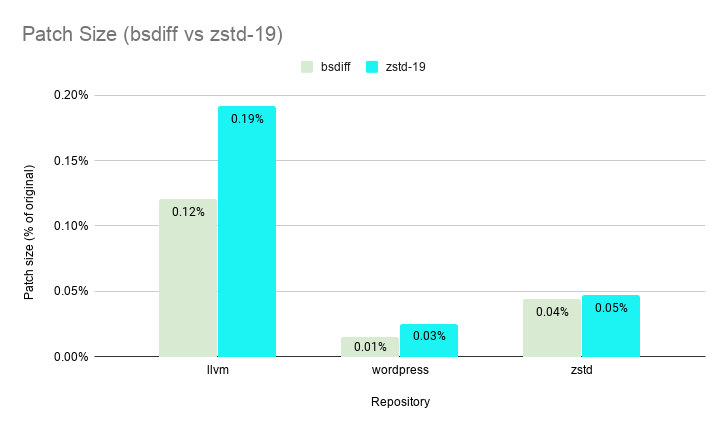
--patch-from greatly outperforms bsdiff in speed even on its slowest setting of level 19 boasting an average speedup of ~7X. --patch-from is >200X faster on level 1 and >100X faster (shown below) on level 3 vs bsdiff while still delivering patch sizes less than 0.5% of the original file size.
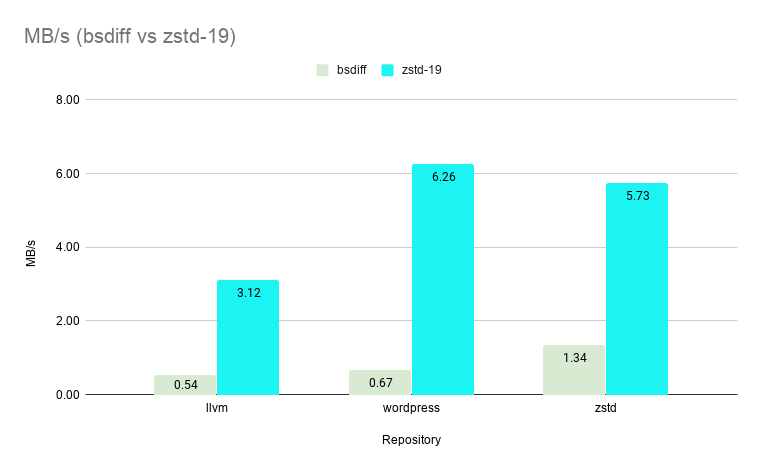
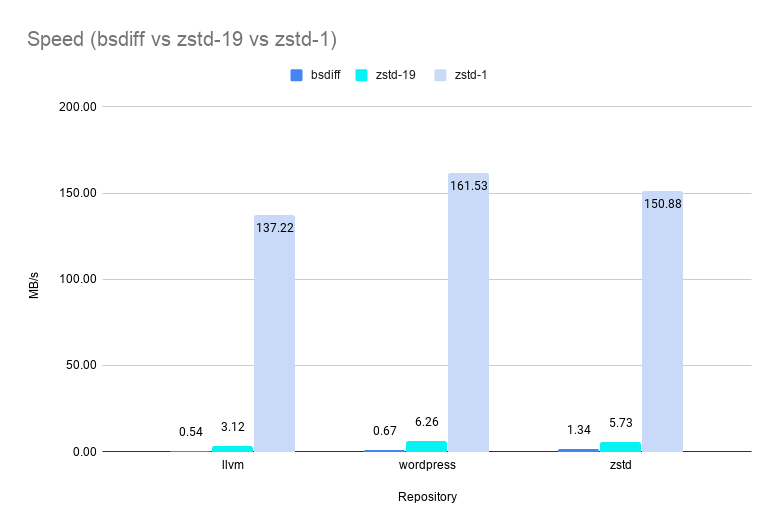
And of course, there is no change to the fast zstd decompression speed.
Addendum :
After releasing --patch-from, we were made aware of two other popular diff engines by the community: SmartVersion and Xdelta. We ran some additional benchmarks for them and here are our primary takeaways. All three tools are excellent diff engines with clear advantages (especially in speed) over the popular bsdiff. Patch sizes for both binary and text data produced by all three are pretty comparable with Xdelta underperforming Zstd and SmartVersion only slightly [1]. For patch creation speed, Xdelta is the clear winner for text data and Zstd is the clear winner for binary data [2]. And for Patch Extraction Speed (ie. decompression), Zstd is fastest in all scenarios [3]. See wiki for details.
--filelist=
Finally, --filelist= is a new CLI capability, which makes it possible to pass a list of files to operate upon from a file,
as opposed to listing all target files solely on the command line.
This makes it possible to prepare a list offline, save it into a file, and then provide the prepared list to zstd.
Another advantage is that this method circumvents command line size limitations, which can become a problem when operating on very large directories (such situation can typically happen with shell expansion).
In contrast, passing a very large list of filenames from within a file is free of such size limitation.
Full List
- perf: Improved decompression speed (x64 >+5%, ARM >+15%), by @terrelln
- perf: Automatically downsizes
ZSTD_DCtxwhen too large for too long (#2069, by @bimbashrestha) - perf: Improved fast compression speed on
aarch64(#2040, ~+3%, by @caoyzh) - perf: Small level 1 compression speed gains (depending on compiler)
- fix: Compression ratio regression on huge files (> 3 GB) using high levels (
--ultra) and multithreading, by @terrelln - api:
ZDICT_finalizeDictionary()is promoted to stable (#2111) - api: new experimental parameter
ZSTD_d_stableOutBuffer(#2094) - build: Generate a single-file
libzstdlibrary (#2065, by @cwoffenden) - build: Relative includes, no longer require
-Iflags forzstdlib subdirs (#2103, by @felixhandte) - build:
zstdnow compiles cleanly under-pedantic(#2099) - build:
zstdnow compiles with make-4.3 - build: Support
mingwcross-compilation from Linux, by @Ericson2314 - build: Meson multi-thread build fix on windows
- build: Some misc
iccfixes backed by new ci test on travis - cli: New
--patch-fromcommand, create and apply patches from files, by @bimbashrestha - cli:
--filelist=: Provide a list of files to operate upon from a file - cli:
-bcan now benchmark multiple files in decompression mode - cli: New
--no-content-sizecommand - cli: New
--show-default-cparamscommand - misc: new diagnosis tool,
checked_flipped_bits, incontrib/, by @felixhandte - misc: Extend largeNbDicts benchmark to compression
- misc: experimental edit-distance match finder in
contrib/ - doc: Improved beginner
CONTRIBUTING.mddocs - doc: New issue templates for zstd