Train CNN with different regularization and optimization methods
#!/usr/bin/env python
from __future__ import print_function
import numpy as np
import argparse
import time
import random
import chainer
from chainer import cuda, Function, gradient_check, Variable, optimizers, serializers, utils
from chainer import Link, Chain, ChainList,iterators,training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
import h5py
# my models
import models
def main():
parser = argparse.ArgumentParser(description='Train CIFAR10 with Chainer')
parser.add_argument('--batchsize', '-b', type=int, default=500 , help='Number of images in each mini-batch')
parser.add_argument('--epoch' , '-e', type=int, default=10 , help='Number of sweeps over the dataset to train')
parser.add_argument('--model' , '-u', type=str, default='CNN_N_P_D', help='Model used')
parser.add_argument('--method' , '-m', type=str, default='SGD' , help='Optimization methods')
parser.add_argument('--device' , '-d', type=int, default='0' , help='Device used')
parser.add_argument('--flip' , '-f', type=int, default='0' , help='Data augmentation')
args = parser.parse_args()
print('')
print('PS2 BY Shuyue Fu')
print('----------------------------')
print('# Minibatch-size: {}'.format(args.batchsize))
print('# epoch: {}'.format(args.epoch))
print('Optimization method: {}'.format(args.method))
temp = {
'CNN_N_P' : 'Convolution Neural Network with max pooling and batch normalization',
'CNN_Drop' : 'Convolution Neural Network with max pooling and dropout',
'CNN_Pooling' : 'Convolution Neural Network with max pooling',
'CNN_N_P_D' : 'Convolution Neural Network with max pooling, batch normalization and dropout',
'CNN_avePooling': 'Convolution Neural Network with average pooling'
}[args.model]
print('Model used: {}'.format(temp))
temp1 = ['No data augmentation','Data Augmentation: flip'][args.flip]
print(temp1)
print('----------------------------')
print('')
# load data
CIFAR10_data = h5py.File('CIFAR10.hdf5', 'r')
x_train = np.float32(CIFAR10_data['X_train'][:])
x_test = np.float32(CIFAR10_data['X_test'][:] )
y_train = np.int32(np.array(CIFAR10_data['Y_train'][:]))
y_test = np.int32(np.array(CIFAR10_data['Y_test'][:] ))
CIFAR10_data.close()
train = tuple((x_train[i],y_train[i]) for i in range(len(x_train)))
test = tuple((x_test[i] ,y_test[i] ) for i in range(len(x_test )))
n = len(train)
if args.flip == 1:
# flip the picture
temp = tuple((x_train[i][:][:,::-1,:],y_train[i]) for i in range(len(x_train)))
temp = train + temp
train = tuple(random.sample(temp,n))
# Set up a neural network model
model = {
'CNN_N_P' : L.Classifier(models.CNN_N_P()),
'CNN_N_P_D' : L.Classifier(models.CNN_N_P_D()),
'CNN_Drop' : L.Classifier(models.CNN_Drop()),
'CNN_Pooling' : L.Classifier(models.CNN_Pooling()),
'CNN_avePooling': L.Classifier(models.CNN_avePooling())
}[args.model]
# copy the model to gpu
model.to_gpu(args.device)
# four types of optimization:
# 1.normal SGD, 2.ADAM, 3.RMSPROP, 4.MomentumSGD
optimizer = {
'SGD' : chainer.optimizers.SGD(),
'Adam' : chainer.optimizers.Adam(),
'MomentumSGD': chainer.optimizers.MomentumSGD(momentum = .99),
'RMSprop' : chainer.optimizers.RMSprop(lr=0.001, alpha=0.99, eps=1e-08),
}[args.method]
optimizer.setup(model)
# shuffle the training set and test
train_iter = iterators.SerialIterator(train, batch_size=args.batchsize, shuffle=True)
test_iter = iterators.SerialIterator(test , batch_size=args.batchsize, repeat =False, shuffle=False)
# set update method
updater = training.StandardUpdater(train_iter, optimizer, device=args.device)
# train the multi-layer perceptron by iterating over the training set 20 times.
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out=(args.model+args.method))
# Evaluates the current model on the test dataset at the end of every epoch.
trainer.extend(extensions.Evaluator(test_iter, model, device=args.device))
# Accumulates the reported values and emits them to the log file in the output directory.
trainer.extend(extensions.LogReport())
# Prints the selected items in the LogReport.
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy']))
time1 = time.time()
trainer.run()
time2 = time.time()
training_time = time2 - time1
print("Training time: %f" % training_time)
if __name__ == '__main__':
main()1. First, train a deep neural network with 7 layers for CIFAR10 by using the training file above and model file below:
class MLP(chainer.Chain):
def __init__(self):
super(MLP, self).__init__(
# the size of the inputs to each layer will be inferred
l1=L.Linear(None, 1600), # n_in -> n_units
l2=L.Linear(None, 1600), # n_units -> n_units
l3=L.Linear(None,400),
l4=L.Linear(None,400),
l5=L.Linear(None,100),
l6=L.Linear(None,100),
l7=L.Linear(None, 10), # n_units -> n_out
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.relu(self.l5(h4))
h6 = F.relu(self.l6(h5))
y = self.l7(h6)
return yclass Conv_NN(Chain):
def __init__(self):
super(Conv_NN, self).__init__(
# input 3 channel of 32*32
conv1_1=L.Convolution2D(3, 12, 3, pad=1),
conv1_2=L.Convolution2D(12, 12, 3, pad=1),
conv2_1=L.Convolution2D(12, 36, 3, pad=1),
conv2_2=L.Convolution2D(36, 36, 3, pad=1),
conv3_1=L.Convolution2D(36, 64, 3, pad=1),
conv3_2=L.Convolution2D(64, 64, 3, pad=1),
conv3_3=L.Convolution2D(64, 64, 3, pad=1),
fc4 = L.Linear(64*32*32, 5000),
fc5 = L.Linear(5000, 500),
fc6 = L.Linear(500,10),
)
def __call__(self, x):
h = F.relu(self.conv1_1(x))
h = F.relu(self.conv1_2(h))
h = F.relu(self.conv2_1(h))
h = F.relu(self.conv2_2(h))
h = F.relu(self.conv3_1(h))
h = F.relu(self.conv3_2(h))
h = F.relu(self.conv3_3(h))
h = F.relu(self.fc4(h))
h = F.relu(self.fc5(h))
h = self.fc6(h)
L_out = h
return L_outCompare Normal deep neural network with convolution neural network:

Summary from the plot:
- CNN is much better than deep Neural network for this case.
- Adam and momentumSGD can greatly improve the performance
- Adam is better than momentumSGD
Since training CNN takes a lot of time due to the number of parameters. I inserted three Pooling layers in-between successive Conv layers in order to reduce computational time. Although the accuracy of the model might be reduced, but the efficiency boost and this method can control overfitting since the method progressively reduce the spatial size of the representation. There are two types of pooling method, I tested each method with different optimization methods using the following code
- max pooling with Adam
python train_CIFAR10.py -e 5 -m Adam -u CNN_pooling - max pooling with RMSprop
python train_CIFAR10.py -e 5 -m RMSprop -u CNN_pooling - max pooling with momentumSGD
python train_CIFAR10.py -e 5 -m MomentumSGD -u CNN_pooling - same with average pooling
python train_CIFAR10.py -e 5 -m Adam -u CNN_avePooling

{kind=link}
Summary of the two plots: three optimization methods using different pooling layer
- Average pooling works better than max pooling for Adam
- Max pooling works better for RMSprop and Momentum SGD
- Adam is better than MomentumSGD and RMSprop, MomentumSGD is slightly better than RMSprop
Code of models:
class CNN_avePooling(Chain):
# convolution neural network with average pooling
def __init__(self):
super(CNN_avePooling, self).__init__(
# input 3 channel of 32*32
conv1_1=L.Convolution2D(3, 64, 3, pad=1 ),
conv1_2=L.Convolution2D(64, 64, 3, pad=1),
conv2_1=L.Convolution2D(64, 128, 3, pad=1 ),
conv2_2=L.Convolution2D(128, 128, 3, pad=1),
conv3_1=L.Convolution2D(128, 256, 3, pad=1),
conv3_2=L.Convolution2D(256, 256, 3, pad=1),
conv3_3=L.Convolution2D(256, 256, 3, pad=1),
conv3_4=L.Convolution2D(256, 256, 3, pad=1),
fc4 = L.Linear(256*4*4, 500),
fc5 = L.Linear(500, 500),
fc6 = L.Linear(500,10),
)
def __call__(self, x):
h = F.relu(self.conv1_1(x))
h = F.relu(self.conv1_2(h))
h = F.average_pooling_2d(h, 2, 2)
h = F.relu(self.conv2_1(h))
h = F.relu(self.conv2_2(h))
h = F.average_pooling_2d(h, 2, 2)
h = F.relu(self.conv3_1(h))
h = F.relu(self.conv3_2(h))
h = F.relu(self.conv3_3(h))
h = F.relu(self.conv3_4(h))
h = F.average_pooling_2d(h, 2, 2)
h = F.relu(self.fc4(h))
h = F.relu(self.fc5(h))
h = self.fc6(h)
L_out = h
return L_outInterlayer Batch normalization is also a very popular optimization method, I explored the effect of batch normalization combining with other optimization methods. Since RMSprop is slightly poorer than MomentumSGD for training, I only explored the effect of Adam and MomentumSGD here.
- test Adam methods:
python train_CIFAR10.py -e 5 -m Adam -u CNN_N_P - test Momentum methods
python train_CIFAR10.py -e 5 -m MomentumSGD -u CNN_N_P
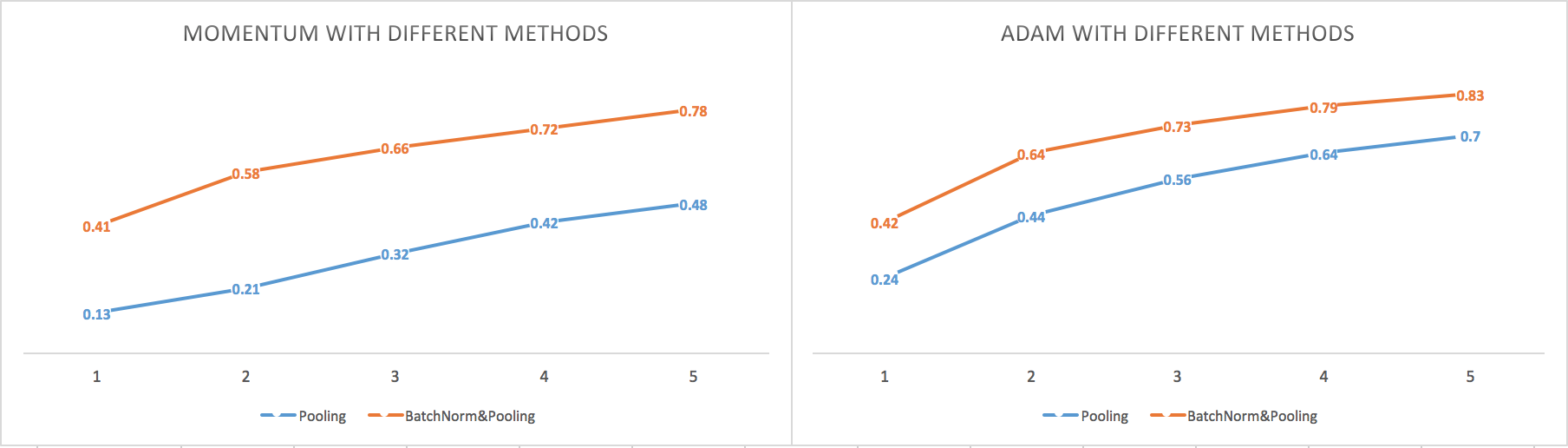
{kind=link}
The bottom two plots: compare Adam/Momentum normalization/pooling thoroughly
- Batch normalization greatly improve the performance of the model with pooling
- Adam with average pooling is better than Momentum with max pooling
class CNN_N_P(Chain):
# convolution neural network with batch normalization and max pooling
def __init__(self):
super(CNN_N_P, self).__init__(
# input 3 channel of 32*32
conv1_1 = L.Convolution2D(3 , 64 , 3, pad=1),
bn1_1 = L.BatchNormalization(64),
conv1_2 = L.Convolution2D(64, 64 , 3, pad=1),
bn1_2 = L.BatchNormalization(64),
conv2_1 = L.Convolution2D(64, 128, 3, pad=1),
bn2_1 = L.BatchNormalization(128),
conv2_2 = L.Convolution2D(128, 128, 3, pad=1),
bn2_2 = L.BatchNormalization(128),
conv3_1 = L.Convolution2D(128, 256, 3, pad=1),
bn3_1 = L.BatchNormalization(256),
conv3_2 = L.Convolution2D(256, 256, 3, pad=1),
bn3_2 = L.BatchNormalization(256),
conv3_3 = L.Convolution2D(256, 256, 3, pad=1),
bn3_3 = L.BatchNormalization(256),
conv3_4 = L.Convolution2D(256, 256, 3, pad=1),
bn3_4 = L.BatchNormalization(256),
fc4 = L.Linear(256*4*4, 500),
fc5 = L.Linear(500 , 500),
fc6 = L.Linear(500 , 10 ),
)
def __call__(self, x):
p = 0.25
dropout_bool = False
bn_bool = True
h = F.relu(self.bn1_1(self.conv1_1(x), bn_bool))
h = F.relu(self.bn1_2(self.conv1_2(h), bn_bool))
h = F.average_pooling_2d(h, 2, 2)
h = F.dropout(h, p, dropout_bool)
h = F.relu(self.bn2_1(self.conv2_1(h), bn_bool))
h = F.relu(self.bn2_2(self.conv2_2(h), bn_bool))
h = F.average_pooling_2d(h, 2, 2)
h = F.dropout(h, p, dropout_bool)
h = F.relu(self.bn3_1(self.conv3_1(h), bn_bool))
h = F.relu(self.bn3_2(self.conv3_2(h), bn_bool))
h = F.relu(self.bn3_3(self.conv3_3(h), bn_bool))
h = F.relu(self.bn3_4(self.conv3_4(h), bn_bool))
h = F.average_pooling_2d(h, 2, 2)
h = F.dropout(h, p, dropout_bool)
h = F.dropout(F.relu(self.fc4(h)), p, dropout_bool)
h = F.dropout(F.relu(self.fc5(h)), p, dropout_bool)
h = self.fc6(h)
L_out = h
return L_outNext I tested two regularization methods
-
add dropout:
python train_CIFAR10.py -e 5 -m Adam -u CNN_N_P -f 1 -
add data augmentation:
python train_CIFAR10.py -e 5 -m Adam -u CNN_N_P -f 1
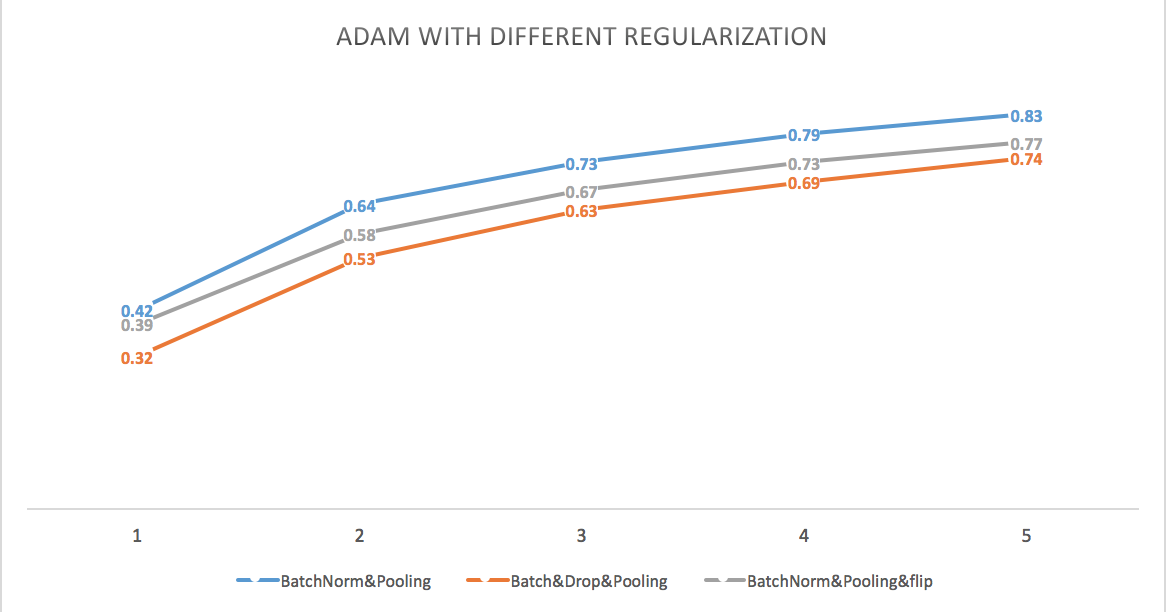
Summary from the plot: Regularization did reduce the accuracy, but it might help control overfitting in the long run.
Based on the analysis above, I chose CNN model with average pooling layer for CIFAR10. I used batch normalization and Adam as optimization methods, dropout / data augmentation as regularization method. I trained the model with 20 epoches.

Summary:
- Model with no regularization and model with data augmentation give an accuracy of 98%.
- Model with dropout gives an lower accuracy of 94% but the test for validation set is the steadiest.
| Method | Accuracy |
|---|---|
| No regularization | 0.98 |
| With dropout | 0.94 |
| With flip | 0.98 |
| With dropout and flip | 0.91 |