


LycheePy is a distributed processing server of geospatial data.
It allows you to:
- Publish pre-defined processing chains through a WPS interface. By doing so, users are abstracted about the chains complexity, because they do not have to build them each time they want to chain processes. From the consumer users perspective, a chain is just another process.
- Automatize geo-spatial data publication into repositories, such as GeoServer, FTP servers, or any other kind of repository. You can easily add integrations to new kinds of repositories besides the currently supported.
- Easily scale. LycheePy is a distributed system. Worker nodes provide processing capabilities and execute processes, and you can add or remove as many you require. Also, LycheePy will concurrently execute processes when possible, according to the chains topology.
- Architecture
- Implementation
- Deployment
- Static Configuration
- Publishing, Discovering, and Executing
- Setting Up Your Development Environment
- The Graphic User Interface
- Who Uses LycheePy?
- Ideas
The development architecture focuses on the software organization into modules. The software is divided into little packages or subsystems which can be developed by small development teams, and they are organized on a layers hierarchy, where each one of them provide a well-defined interface.
Each component responsibilities need to be very well delimited, so there is only one reason for them to change. This way, any change on the system will affect one component only. Having their responsibilities and interfaces well defined, any component may be replaced with another with different implementation, without affecting the others, and they may be reused for other developments.
When there is a dependency between a component and interfaces of another component, then the first should use a Gateway, which encapsulates the interaction with those interfaces. This way, any change on those interfaces will only affect the Gateway and, ideally, not the components which use that gateway.

On this view, we can distinguish 13 components, being 5 of them Gateways:
- WPS: An implementation of the OGC WPS standard, which exposes the WPS I interface, through which can retrieve discovery and execution requests of processes and chains. It depends on the Configuration Gateway component, through which it can access to the metadata of every available executables (processes and chains). Also depends on the Executor component, to which it delegates the execution requests it receives.
- Configuration Gateway: Encapsulates the interaction with the Configuration I interface, of the Configuration component.
- Configuration: Exposes the Configuration I interface, trough which it is possible to add, modify, and delete processes and chains. It requires some kind of persistence in order to store these settings. Uses the Processes Gateway to store and delete processes files.
- Executor: Encapsulates the execution of chains and processes. It can attend every execution request that may come from the WPS component, or some other component we may add in the future. Depends on the Broker Gateway to enqueue processes executions, and on the Executions Gateway in order to inform and update the executions statuses.
- Executions Gateway: Encapsulates the interaction with the Executions I interface, of the Executions component.
- Executions: Persists the status of all the chains executions that have finished (successfully or with errors) or are still running. It exposes the Executions I interface, through which it is possible to update or read those statuses.
- Broker Gateway: Encapsulates every possible interaction with the Messages Queue interface, of the Broker component. Trough this component, it is possible to enqueue tasks.
- Broker: Capable of receive tasks and store them on a queue. It ensures that those will be executed in the same order they where enqueued. Publishers and consumers may be distributed across different hosts.
- Worker: Consumes tasks from the Messages Queue interface and executes them. It depends on the Processes Gateway, to obtain the processes files, which will be later executed. Also depends on the Repository Gateway to perform geospatial data automatic publication.
- Processes Gateway: Encapsulates the interaction with the Processes I interface, of the Processes component.
- Processes: Stores the files of those processes available on the server.
- Repository Gateway: Encapsulates the interaction with repositories for products publishing. This component implements an strategy for each supported repository type.
The physical architecture is the mapping between the software and the hardware. It considers non-functional requirements, such as availability, fault tolerance, performance, and scalability. The software its executed on a computers (nodes) network.
The design of the development components has been carried out considering their capability to be distributed across different nodes on a network, searching for the maximum flexibility, and taking full advantage of the distributed processing, making the system horizontally scalable.
The deployment of the software can be carried out considering a maximum decomposition, and a minimum decomposition. Between these two extremes, exist many intermediate combinations.
The minimum decomposition, represented below, consists of deploying all the development components into the same node. This is a completely centralized schema, and it does not perform distributed processing, but there may be the possibility of performing parallel processing if the container's processor has multiple cores. It also carries with all the disadvantages of a centralized system.

On the maximum decomposition, represented below, all the development components, except gateways, are deployed on a dedicated node, plus a proxy, and the necessary persistence components. This schema carries with all the advantages of a distributed system:
- We can increase (or reduce) each nodes capabilities, according to our needs.
- We can horizontally scale the processing capabilities, adding more Worker nodes.
- Because of some nodes failure, it may not result on a complete system unavailability. Of course, it depends on which component fails: For example, if we had multiple Worker nodes, and one of them fails, the processing capability decreases and the chains execution may be slower, but all the system's functionalities will still work; while if the Broker component fails, then we have lost the capability of execute processes and chains, but the system will still be able to attend discovery operations, the products will still be accessible by the users, and so on. Whatever is the case, the recovery to any kind of failure should be faster, because the problem is isolated, and it is easier to identify and resolve, or to replace the node.

This is the section we all might consider the most important, or at least the most attractive. Of course, it is important, but if you scrolled to here without reading about the architecture then scroll up again :)
First, lets talk about the repository organization. At the root of it, we basically have three directories:
- lycheepy, which contains the source code.
- doc, which contains the documentation.
- tests, which contains functional, and (in the future) unitary tests.
Inside the lycheepy directory, we will find one folder per each development component, and everything we need to install and run the application. To ensure the proper distribution of these development components across different containers while we are developing, and even in production, we use Docker Compose, so on this directory we'll find:
- A install_host_dependencies.sh executable file, which can be used in order to install the host dependencies, such as docker-compose.
- The docker-compose.yml file. There are found all the containers definitions, their mutual dependencies, the ports they expose for mutual interaction, the ports they expose to the host, and so on.
- A start.sh executable file, which can be used to run all the containers for development purposes.
Inside each development component's directory, we will find a Dockerfile file, and the source code of the component itself. Let's see with an example: The Configuration development component is inside the lycheepy/configuration directory, and there we can see:
- The Dockerfile.
- A folder with the same name of the component, which contains the source code, in this case named configuration. Inside this folder you can organize your code just as you like.
- A requirements.txt file, because we are talking about a component which is implemented with Python, and on this level we should place all install-related files. We will only use this file while the component's installation.
- A wait-service.sh file, which is an utility to wait until a TCP port of another container starts listening. You can read more about this here.
If your component is implemented with Python and uses gateways, then they should be placed on a gateways package, inside the component's sources folder. Inside this package, you can place one folder per each component dependency. This way, we can quickly know which components the component depends on. For example: The WPS component depends on the Configuration component, so inside its sources folder we place a gateways package, and there we place a configuration package, which contains the gateway.
Just as we said before, the development components are placed inside the lycheepy directory.
Placed on the wps directory, it is an implementation of the OGC WPS standard. More precisely, it is a great Python implementation of that standard, named PyWPS.
PyWPS uses a configuration file, placed here, where you can:
- Specify metadata about the server instance.
- Configure the WPS server. For example, specifying how many processes can be running in parallel.
- Configure logging policies, such as the logging level.
To make the processes and chains of the Configuration component visible through the WPS interface, this component uses the ConfigurationGateway.
To delegate the execution requests to the Executor component, we use an adapter. This translates the metadata coming from the Configuration component, into special PyWPS Process instances. When those instances are executed, they simply delegate it to the Executor component.
The ServiceBuilder is the one that takes the metadata from the ConfigurationGateway, calls the adapter, and appends those special processes to a PyWPS Service instance.
This is a very simple component, which exposes a ReST API, through which we can publish processes and chains. Right now, we are going to talk about its implementation, rather than how to use its endpoints.
The interface is implemented with the Simply Restful framework, which uses Flask and SQLAlchemy.
It uses a PostgreSQL instance as persistence, but you could use another database supported by SQLAlchemy, such as SQLite.
It performs several validations over the chains topography, using NetworkX.
Finally, it publishes processes files on the Processes component, so it uses a gateway. This gateway is shared by the Configuration and Worker components, so it is on a separated repository, and referenced as a git-submodule by both components.
It encapsulates the complexity that relies behind the distributed execution of processes and chains, while it provides a very clear interface.
It also keeps the executions statuses updated on the Executions component, through the ExecutionsGateway. Also depends on the BrokerGateway to enqueue processes executions.
It basically provides two public operations: execute_process and execute_chain. When it comes to a process execution, it simply enqueues the process execution using the BrokerGateway. But the chains execution is a bit more complex.
On LycheePy, a chain is a directed acyclic graph, so they can be sliced into antichains by using the AntiChains algorithm. Let's see it with an example:

The algoritm produces a list of antichains, where an antichain is a list of processes. The particularity of each antichain is that there is no relationship between the processes it contains, so we could execute them in parallel (this means at the same time, using multiple processor cores, or in a distributed way).
We use NetworkX to obtain the antichains, and encapsulate it on the AntiChains class. To execute a chain, a Chain instance is built using the ChainBuilder class, starting from the metadata that comes from the Configuration component. The Chain class encapsulates all the execution logic, which basically consists of loop the antichains list, and send each antichain to the Broker, trough the BrokerGateway, to be concurrently executed.
This is a very simple component, which exposes a ReST API, through which we can read and update execution statuses. Right now, we are going to talk about its implementation, rather than how to use its endpoints.
The interface is implemented with the Simply Restful framework, which uses Flask and SQLAlchemy.
It uses a PostgreSQL instance as persistence, but you could use another database supported by SQLAlchemy, such as SQLite.
In the architecture description, we said that this component receives tasks from the Executor (the producer) trough the BrokerGateway. Then, these tasks are stored until the Workers consume and execute them. The communication protocol between all these parts must consider that all of them may be located on different hosts, because our goal is to perform distributed processing.
So, to carry out all these functional and not functional requirements, we chose Celery: "An asynchronous task queue/job queue based on distributed message passing". It just fits perfectly: "The execution units, called tasks, are executed concurrently on a single or more worker servers".
So, in Celery, the workers define which tasks they can execute, and then begin to listen to a broker, which is usually a RabbitMQ instance, and the producers simply enqueue tasks into the broker. Yes, the Broker component is a RabbitMQ instance.
The BrokerGateway uses a Celery application to "talk" with the Broker. It enqueues tasks with the same name and parameters that the Workers are expecting.
The Worker defines two tasks:
- A run_process task, which can execute a process, given its identifier and inputs values. Uses the ProcessesGateway to obtain the process file.
- A run_chain_process task, which first executes the process, using the run_process, and then performs the automatic products publication, making use of the RepositoryGateway, if any of the process outputs have been configured as automatically publishable.
This component responsibility is simple: It just stores the processes files. So, we have so many alternatives to implement it, some better than others: A FTP server, a database, a shared filesystem, and so on. We've chosen vsftpd, an FTP server.
The thing here is the gateway to this component, which completely abstracts the gateway's clients about the "complexity" behind this. You can simply obtain a process instance by specifying its identifier.
The Repository is an external System, capable to store geospatial data. Some repositories may make this data available to users, and they can do it trough different kinds of interfaces. Examples are GeoServer, an FTP repository, a File System, cloud services, and so on.
The Repository Gateway is the component which encapsulates the interaction with those external repositories, to perform products publication. The Worker component makes use of this gateway, so LycheePy can publish products on multiple instances of different kinds of repositories, at the same time. You are not limited to a single repository, or to a single repository type.
You can easily add integrations with new kinds of repositories: There is a Repository "interface" (in Python, the closest thing to an interface is an abstract class), which defines a single publish method. So, all you got to do is create a class that implements that interface and its "publish" method, which is the one to be invoked to perform products publication. Yes, it is a Strategy pattern.
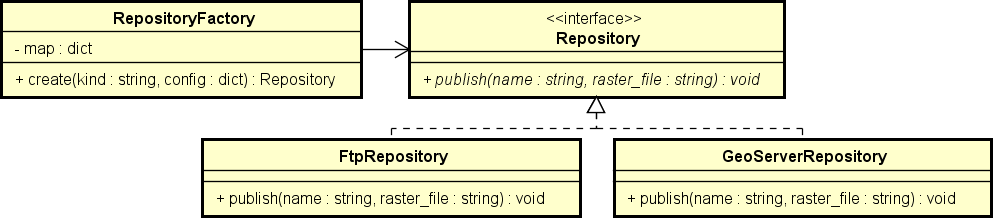
LycheePy already provides integrations with GeoServer and with FTP servers. So yes, there are two strategies:
- The GeoServerRepository can publish rasters into a GeoServer instance. It uses the gsconfig client to interact with a GeoServer instance through its ReST Configuration API.
- The FtpRepository can publish any output file into any FTP server.
For development purposes, all you need to run LycheePy is clone the repository and execute the start.sh script.
I still do not figure out the best way of deploying an application with docker-compose into production. I will require some more research.
You can configure the maximum amount of time that a process execution can take, on the lycheepy/wps/wps/settings.py file:
PROCESS_EXECUTION_TIMEOUT = 30The PyWPS configuration file can be found in lycheepy/wps/wps/pywps.cfg.
The Configuration component settings are placed on the lycheepy/configuration/configuration/settings.py file. There, you can:
- Configure its endpoints pagination. This takes effect on the chains list, the processes list, the supported formats list, and the supported data types list:
- DEFAULT_PAGE_SIZE specifies how many results will be returned when the user does not specify the limit query parameter.
- MAX_PAGE_SIZE specifies the maximum amount of results can be returned, independently of the limit query parameter.
- Configure on which form/data keys you expect the process metadata, and the process file, when a process is uploaded or updated:
- PROCESS_SPECIFICATION_FIELD specifies the key where you are expecting the process metadata.
- PROCESS_FILE_FIELD specifies the key where you are expecting the process file.
- Configure the supported process file extensions, trough the ALLOWED_PROCESSES_EXTENSIONS parameter. We are using PyWPS, though we only support .py files.
DEFAULT_PAGE_SIZE = 10
MAX_PAGE_SIZE = 100
PROCESS_SPECIFICATION_FIELD = 'specification'
PROCESS_FILE_FIELD = 'file'
ALLOWED_PROCESSES_EXTENSIONS = ['py']The Executions component settings are placed on the lycheepy/executions/executions/settings.py file. There, you can configure its endpoints pagination. This takes effect on the executions list:
- DEFAULT_PAGE_SIZE specifies how many results will be returned when the user does not specify the limit query parameter.
- MAX_PAGE_SIZE specifies the maximum amount of results can be returned, independently of the limit query parameter.
DEFAULT_PAGE_SIZE = 10
MAX_PAGE_SIZE = 100Here comes, I think, the best part. We will see how LycheePy works with an example.
The COSMO-Skymed mission, carried out by the Italian Space Agency (ASI), consists of a constellation of four satellites equipped with Synthetic Aperture Radar (SAR) operating at X-band.
The COSMO-SkyMed products are divided in the following major classes:

Taken from the COSMO-Skymed Products Handbook
We will focus on the SAR Standard products, which are the following:

Taken from the COSMO-Skymed Products Handbook
And are generated by this chain:

Taken from the COSMO-Skymed Products Handbook
Of course, we do not have access to those processors, so we will use dummy processes, which always return the same image.
The processes administration is done trough the Configuration component. Its configuration interface is available on the {host}/configuration URI, trough the HTTP protocol.
You can publish processes using the {host}/configuration/processes URI with the HTTP POST method. You have to send two things to the server, using the multipart/form-data HTTP header:
- The process metadata, in a key named "specification".
- The process file, in a key named "file".
Processes parameters (inputs and outputs) have dataType OR format, they cannot have both or none.
Here you can see a metadata example for the L0 process:
{
"identifier": "L0",
"title": "L0 Processor",
"abstract": "The L0 processor generates the RAW product",
"version": "0.1",
"metadata": ["Level 0", "Processor"],
"inputs": [
{
"identifier": "crude",
"title": "Crude data",
"abstract": "Downloaded from the satellite to the ground station",
"format": "GEOTIFF"
}
],
"outputs": [
{
"identifier": "RAW",
"title": "RAW product",
"abstract": "The single output generated by this processor",
"format": "GEOTIFF"
}
]
}That's it. Your process is now uploaded and published trough the WPS interface.
You can retrieve a list of the published processes, using the {host}/configuration/processes URI with the HTTP GET method.
{
"count": 1,
"results": [
{
"id": 1,
"identifier": "L0",
"version": "0.1",
"title": "L0 Processor",
"abstract": "The L0 processor generates the RAW product",
"metadata": ["Level 0", "Processor"],
"inputs": [
{
"format": "GEOTIFF",
"format": null,
"abstract": "Downloaded from the satellite to the ground station",
"identifier": "crude",
"title": "Crude data"
}
],
"outputs": [
{
"dataType": null,
"format": "GEOTIFF",
"abstract": "The single output generated by this processor",
"identifier": "RAW",
"title": "RAW product"
}
]
}
]
}You can update a process using the {host}/configuration/processes/{processId} URI, where processId is the id property of the process under edition, with the HTTP PUT method.
It works equally than the process upload. With multipart/form-data you'll send the process metadata in the same key, "specification", and optionally send the new process file in the same key, "file".
You can publish chains trough the {host}/configuration/chains URI, using the HTTP POST method, with "Content-type: application/json".
Remember that chains are also published trough the WPS interface, so they need to have identical metadata than a process.
You do not specify explicitly which are the inputs and outputs of a chain. Instead, you specify the "steps" of the chain, where a "step" is an edge of the directed acyclic graph. This edge goes from the "before" process to the "after" process.
Given the chain steps, LycheePy can build the graph and know which the inputs are, and which the outputs:
- The chain inputs are the inputs of all the processes (nodes) with indegree 0.
- The chain outputs are the outputs of all the processes (nodes) with outdegree 0.
LycheePy will automatically try to map the outputs of the "before" process with the inputs of the "after" process, using their identifiers. It is case sensitive. If they do not match by identifier, you can specify an explicit mapping, like this:
{
"before": "ProcessA",
"after": "ProcessB",
"match": {
"processAoutput": "processBinput"
}
}Here is an example of the SAR Standard Products chain:
{
"identifier": "Cosmo Skymed",
"title": "CSK Standard Processing Model",
"abstract": "An implementation of the SAR Standard Products chain",
"version": "0.1",
"metadata": ["Cosmo", "Skymed", "Mission", "Chain"],
"steps": [
{"before": "L0", "after": "L1A"},
{"before": "L1A", "after": "L1B"},
{"before": "L1B", "after": "L1C"},
{"before": "L1B", "after": "L1D"}
],
"publish": {
"L0": ["RAW"],
"L1A": ["SCS"],
"L1B": ["MDG"],
"L1C": ["GEC"],
"L1D": ["GTC"]
}
}You can specify which outputs of which processes of the chain will be automatically published. And you simply need to use the "publish" property of the chain, as you can see on the example above. That property is an object, where its keys are the processes identifiers, and each one of them have a list of which outputs we wish to publish. Just as simple as that.
You can retrieve a list of the published chains, using the {host}/configuration/chains URI with the HTTP GET method.
LycheePy will calculate and show you which are inputs and the outputs of the chains. You can see it on the "inputs", and "outputs" properties:
{
"count": 1,
"results": [
{
"id": 1,
"identifier": "Cosmo Skymed",
"version": "0.1",
"title": "CSK Standard Processing Model",
"abstract": "An implementation of the SAR Standard Products chain",
"publish": {
"L1D": ["GTC"],
"L1B": ["MDG"],
"L1A": ["SCS"],
"L0": ["RAW"],
"L1C": ["GEC"]
},
"steps": [
{"after": "L1A", "match": {}, "before": "L0"},
{"after": "L1B", "match": {}, "before": "L1A"},
{"after": "L1C", "match": {}, "before": "L1B"},
{"after": "L1D", "match": {}, "before": "L1B"}
],
"metadata": ["Cosmo", "Skymed", "Mission", "Chain"],
"inputs": [
{
"format": "GEOTIFF",
"format": null,
"abstract": "Downloaded from the satellite to the ground station",
"identifier": "crude",
"title": "Crude data"
}
],
"outputs": [
{
"dataType": null,
"format": "GEOTIFF",
"abstract": "GEC Product",
"identifier": "GEC",
"title": "GEC Product"
},
{
"dataType": null,
"format": "GEOTIFF",
"abstract": "GTC Product",
"identifier": "GTC",
"title": "GTC Product"
}
]
}
]
}You can update a process using the {host}/configuration/chains/{chainId} URI, where chainId is the id property of the chain under edition, with the HTTP PUT method and "Content-type: application-json".
You simply need to send the chain metadata again. This will update the chain, and immediately be reflected on the WPS interface.
That was it, you published your processes and the chain. They now they are available trough the WPS interface. If you perform a GetCapabilities operation, you'll see something like this:
{host}/wps?service=WPS&request=getcapabilities
<!-- PyWPS 4.0.0 -->
<wps:Capabilities xmlns:gml="http://www.opengis.net/gml" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" service="WPS" version="1.0.0" xml:lang="en-US" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 http://schemas.opengis.net/wps/1.0.0/wpsGetCapabilities_response.xsd" updateSequence="1">
<ows:ServiceIdentification>
<ows:Title>LycheePy Server</ows:Title>
<ows:Abstract>LycheePy is a geospatial data processing server that allows you to expose predeterminated chains, and executes them in a distributed way. Also, it can be directly integrated with geospatial repositories, so you can configure these chains to automaticly publish outputs into them</ows:Abstract>
<ows:Keywords>
<ows:Keyword>LycheePy</ows:Keyword>
<ows:Keyword>WPS</ows:Keyword>
<ows:Keyword>PyWPS</ows:Keyword>
<ows:Keyword>Processes</ows:Keyword>
<ows:Keyword>Geospatial</ows:Keyword>
<ows:Keyword>Distribution</ows:Keyword>
<ows:Keyword>Automatic</ows:Keyword>
<ows:Keyword>Products</ows:Keyword>
<ows:Keyword>Publication</ows:Keyword>
<ows:Keyword>Repositories</ows:Keyword>
<ows:Type codeSpace="ISOTC211/19115">theme</ows:Type>
</ows:Keywords>
<ows:ServiceType>WPS</ows:ServiceType>
<ows:ServiceTypeVersion>1.0.0</ows:ServiceTypeVersion>
<ows:Fees>None</ows:Fees>
<ows:AccessConstraints>None</ows:AccessConstraints>
</ows:ServiceIdentification>
<ows:ServiceProvider>
<ows:ProviderName>LycheePy Development Team</ows:ProviderName>
<ows:ProviderSite xlink:href="http://lycheepy.org/"/>
<ows:ServiceContact>
<ows:IndividualName>Gabriel Jose Bazan</ows:IndividualName>
<ows:PositionName>Developer</ows:PositionName>
<ows:ContactInfo>
<ows:Phone>
<ows:Voice>+54</ows:Voice>
</ows:Phone>
<ows:Address>
<ows:AdministrativeArea>Argentina</ows:AdministrativeArea>
<ows:PostalCode>0</ows:PostalCode>
<ows:Country>World, Internet</ows:Country>
<ows:ElectronicMailAddress>gbazan@outlook.com</ows:ElectronicMailAddress>
</ows:Address>
<ows:OnlineResource xlink:href="http://lycheepy.org"/>
<ows:HoursOfService>12:00-20:00UTC</ows:HoursOfService>
<ows:ContactInstructions>Knock on the heavens door</ows:ContactInstructions>
</ows:ContactInfo>
<ows:Role>hallo</ows:Role>
</ows:ServiceContact>
</ows:ServiceProvider>
<ows:OperationsMetadata>
<ows:Operation name="GetCapabilities">
<ows:DCP>
<ows:HTTP>
<ows:Get xlink:href="http://wps/wps"/>
<ows:Post xlink:href="http://wps/wps"/>
</ows:HTTP>
</ows:DCP>
</ows:Operation>
<ows:Operation name="DescribeProcess">
<ows:DCP>
<ows:HTTP>
<ows:Get xlink:href="http://wps/wps"/>
<ows:Post xlink:href="http://wps/wps"/>
</ows:HTTP>
</ows:DCP>
</ows:Operation>
<ows:Operation name="Execute">
<ows:DCP>
<ows:HTTP>
<ows:Get xlink:href="http://wps/wps"/>
<ows:Post xlink:href="http://wps/wps"/>
</ows:HTTP>
</ows:DCP>
</ows:Operation>
</ows:OperationsMetadata>
<wps:ProcessOfferings>
<wps:Process wps:processVersion="0.1">
<ows:Identifier>L0</ows:Identifier>
<ows:Title>L0 Processor</ows:Title>
<ows:Abstract>The L0 processor generates the RAW product</ows:Abstract>
</wps:Process>
<wps:Process wps:processVersion="0.1">
<ows:Identifier>L1D</ows:Identifier>
<ows:Title>L1D Processor</ows:Title>
<ows:Abstract>Level 1D Processor, which generates the GTC product</ows:Abstract>
</wps:Process>
<wps:Process wps:processVersion="0.1">
<ows:Identifier>Cosmo Skymed</ows:Identifier>
<ows:Title>CSK Standard Processing Model</ows:Title>
<ows:Abstract>An implementation of the SAR Standard Products chain</ows:Abstract>
</wps:Process>
<wps:Process wps:processVersion="0.1">
<ows:Identifier>L1A</ows:Identifier>
<ows:Title>Level 1A Process</ows:Title>
<ows:Abstract>Level 1A Processor, which generates the SCS product</ows:Abstract>
</wps:Process>
<wps:Process wps:processVersion="1.0">
<ows:Identifier>L1B</ows:Identifier>
<ows:Title>L1B Processor</ows:Title>
<ows:Abstract>Level 1B Processor, which generates the MDG product</ows:Abstract>
</wps:Process>
<wps:Process wps:processVersion="1.0">
<ows:Identifier>L1C</ows:Identifier>
<ows:Title>L1C Processor</ows:Title>
<ows:Abstract>Level 1C Processor, which generates the GEC product</ows:Abstract>
</wps:Process>
</wps:ProcessOfferings>
<wps:Languages>
<wps:Default>
<ows:Language>en-US</ows:Language>
</wps:Default>
<wps:Supported>
<ows:Language>en-US</ows:Language>
</wps:Supported>
</wps:Languages>
</wps:Capabilities>You can retrieve more specific details about a process with the DescribeProcess operation:
{host}/wps?service=WPS&request=describeprocess&version=1.0.0&identifier=L0
<!-- PyWPS 4.0.0 -->
<wps:ProcessDescriptions xmlns:gml="http://www.opengis.net/gml" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 http://schemas.opengis.net/wps/1.0.0/wpsDescribeProcess_response.xsd" service="WPS" version="1.0.0" xml:lang="en-US">
<ProcessDescription wps:processVersion="0.1" storeSupported="true" statusSupported="true">
<ows:Identifier>L0</ows:Identifier>
<ows:Title>L0 Processor</ows:Title>
<ows:Abstract>The L0 processor generates the RAW product</ows:Abstract>
<DataInputs>
<Input minOccurs="1" maxOccurs="1">
<ows:Identifier>crude</ows:Identifier>
<ows:Title>Crude data</ows:Title>
<ows:Abstract></ows:Abstract>
<ComplexData maximumMegabytes="10">
<Default>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Default>
<Supported>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Supported>
</ComplexData>
</Input>
</DataInputs>
<ProcessOutputs>
<Output>
<ows:Identifier>RAW</ows:Identifier>
<ows:Title>RAW product</ows:Title>
<ComplexOutput>
<Default>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Default>
<Supported>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Supported>
</ComplexOutput>
</Output>
</ProcessOutputs>
</ProcessDescription>
</wps:ProcessDescriptions>And about the chain, because it is just another process:
{host}/wps?service=WPS&request=describeprocess&version=1.0.0&identifier=Cosmo Skymed
<!-- PyWPS 4.0.0 -->
<wps:ProcessDescriptions xmlns:gml="http://www.opengis.net/gml" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 http://schemas.opengis.net/wps/1.0.0/wpsDescribeProcess_response.xsd" service="WPS" version="1.0.0" xml:lang="en-US">
<ProcessDescription wps:processVersion="0.1" storeSupported="true" statusSupported="true">
<ows:Identifier>Cosmo Skymed</ows:Identifier>
<ows:Title>CSK Standard Processing Model</ows:Title>
<ows:Abstract>An implementation of the SAR Standard Products chain</ows:Abstract>
<DataInputs>
<Input minOccurs="1" maxOccurs="1">
<ows:Identifier>crude</ows:Identifier>
<ows:Title>Crude data</ows:Title>
<ows:Abstract></ows:Abstract>
<ComplexData maximumMegabytes="10">
<Default>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Default>
<Supported>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Supported>
</ComplexData>
</Input>
</DataInputs>
<ProcessOutputs>
<Output>
<ows:Identifier>GEC</ows:Identifier>
<ows:Title>GEC Product</ows:Title>
<ComplexOutput>
<Default>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Default>
<Supported>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Supported>
</ComplexOutput>
</Output>
<Output>
<ows:Identifier>GTC</ows:Identifier>
<ows:Title>GTC Product</ows:Title>
<ComplexOutput>
<Default>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Default>
<Supported>
<Format>
<MimeType>image/tiff; subtype=geotiff</MimeType>
</Format>
</Supported>
</ComplexOutput>
</Output>
</ProcessOutputs>
</ProcessDescription>
</wps:ProcessDescriptions>So, you published and discovered your processes and the chain. Let's execute them trough WPS.
Processes can be executed with the Execute operation, where you specify the identifier of the process you wish to execute, and a list of values for its inputs.
The examples below use the HTTP POST method on the {host}/wps/ URI.
The following example will execute the L0 processor:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<wps:Execute service="WPS" version="1.0.0" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 ../wpsExecute_request.xsd">
<ows:Identifier>L0</ows:Identifier>
<wps:DataInputs>
<wps:Input>
<ows:Identifier>crude</ows:Identifier>
<wps:Reference xlink:href="http://repository:8080/geoserver/ows?service=WCS&version=2.0.0&request=GetCoverage&coverageId=nurc:Img_Sample&format=image/tiff">
</wps:Reference>
</wps:Input>
</wps:DataInputs>
</wps:Execute>As a response, you will receive something like this:
<!-- PyWPS 4.0.0 -->
<wps:ExecuteResponse xmlns:gml="http://www.opengis.net/gml" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 http://schemas.opengis.net/wps/1.0.0/wpsExecute_response.xsd" service="WPS" version="1.0.0" xml:lang="en-US" serviceInstance="http://wps/wps?service=WPS&request=GetCapabilities" statusLocation="http://wps/wps/outputs/f4a9ebf6-4d74-11e8-947e-0242ac12000a.xml">
<wps:Process wps:processVersion="0.1">
<ows:Identifier>L0</ows:Identifier>
<ows:Title>L0 Processor</ows:Title>
<ows:Abstract>The L0 processor generates the RAW product</ows:Abstract>
</wps:Process>
<wps:Status creationTime="2018-05-01T19:22:15Z">
<wps:ProcessSucceeded>PyWPS Process L0 Processor finished</wps:ProcessSucceeded>
</wps:Status>
<wps:ProcessOutputs>
<wps:Output>
<ows:Identifier>RAW</ows:Identifier>
<ows:Title>RAW product</ows:Title>
<ows:Abstract></ows:Abstract>
<wps:Reference href="http://{host_name_or_ip}/outputs/1f638322-9e9f-11e8-b5db-0242ac12000a/ows_yu78Ak" mimeType="image/tiff; subtype=geotiff" encoding="" schema=""/>
</wps:Output>
</wps:ProcessOutputs>
</wps:ExecuteResponse>The Cosmo Skymed process (our chain) takes only one input, the crude data, and produces two outputs, the GEC and GTC products, just as we explained before.
So, this request is identical to the previous, since the L0 processor is the only with indegree 0, so it occupies the first place on the execution order:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<wps:Execute service="WPS" version="1.0.0" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 ../wpsExecute_request.xsd">
<ows:Identifier>Cosmo Skymed</ows:Identifier>
<wps:DataInputs>
<wps:Input>
<ows:Identifier>crude</ows:Identifier>
<wps:Reference xlink:href="http://repository:8080/geoserver/ows?service=WCS&version=2.0.0&request=GetCoverage&coverageId=nurc:Img_Sample&format=image/tiff">
</wps:Reference>
</wps:Input>
</wps:DataInputs>
</wps:Execute>As a response, you will receive something like this:
<!-- PyWPS 4.0.0 -->
<wps:ExecuteResponse xmlns:gml="http://www.opengis.net/gml" xmlns:ows="http://www.opengis.net/ows/1.1" xmlns:wps="http://www.opengis.net/wps/1.0.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/wps/1.0.0 http://schemas.opengis.net/wps/1.0.0/wpsExecute_response.xsd" service="WPS" version="1.0.0" xml:lang="en-US" serviceInstance="http://wps/wps?service=WPS&request=GetCapabilities" statusLocation="http://wps/wps/outputs/1fa4685e-4d75-11e8-947e-0242ac12000a.xml">
<wps:Process wps:processVersion="0.1">
<ows:Identifier>Cosmo Skymed</ows:Identifier>
<ows:Title>CSK Standard Processing Model</ows:Title>
<ows:Abstract>An implementation of the SAR Standard Products chain</ows:Abstract>
</wps:Process>
<wps:Status creationTime="2018-05-01T19:23:29Z">
<wps:ProcessSucceeded>PyWPS Process CSK Standard Processing Model finished</wps:ProcessSucceeded>
</wps:Status>
<wps:ProcessOutputs>
<wps:Output>
<ows:Identifier>GEC</ows:Identifier>
<ows:Title>GEC Product</ows:Title>
<wps:Reference href="http://{host_name_or_ip}/outputs/1f638322-9e9f-11e8-b5db-0242ac12000a/ows_yu78Ak" mimeType="image/tiff; subtype=geotiff" encoding="" schema=""/>
</wps:Output>
<wps:Output>
<ows:Identifier>GTC</ows:Identifier>
<ows:Title>GTC Product</ows:Title>
<wps:Reference href="http://{host_name_or_ip}/outputs/1f638322-9e9f-11e8-b5db-0242ac12000a/ows_yu78Ak" mimeType="image/tiff; subtype=geotiff" encoding="" schema=""/>
</wps:Output>
</wps:ProcessOutputs>
</wps:ExecuteResponse>And all the processes outputs you made automatically publishable on the chain metadata, now are just published.
The WPS standard, on its 1.X and 2.X versions, implement a mechanism through which you can request execution statuses, which is specially useful when you are requesting asynchronous executions. This is done trough an identifier which the server will send you as a response for your execution request. But it is limited, because you can only request the status of a single execution ID.
With LycheePy you can still use the WPS mechanism, but it also gives you the possibility of requesting more sophisticated queries.
Everything is done with the HTTP GET method over the {host}/executions/executions URI.
Let's see. For example, you could request the status of all the executions of the server. Those will include the ones which are still running, and those which already finished (successfully, or with errors):
{host}/executions/executions
Or you could need the same, but you want to see it chronologically ordered:
{host}/executions/executions?order_by=start__desc
Or you want to see all the executions of one specific chain:
{host}/executions/executions?chain_identifier=Cosmo Skymed&order_by=start__asc
Or you want to see all the failed executions of one specific chain:
{host}/executions/executions?chain_identifier=Cosmo Skymed&status__name__eq=FAILURE
Or to see the executions still running, together with the successful ones:
{host}/executions/executions?chain_identifier=Cosmo Skymed&status__name__in=SUCCESS;RUNNING
Or simply request the status of a very specific execution ID:
{host}/executions/executions?execution_id=41838c1c-4847-11e8-9afe-0242ac12000a
Or the last execution sent to the server:
{host}/executions/executions?order_by=start__desc&limit=1
And so on. Just combine filters as you like.
In all those cases, you'll retrieve a list like this:
{
"count": 1,
"results": [
{
"status": {
"id": 2,
"name": "SUCCESS"
},
"end": "2018-04-25T05:13:05.713671Z",
"start": "2018-04-25T05:13:04.354559Z",
"reason": "",
"chain_identifier": "Cosmo Skymed",
"id": 1,
"execution_id": "551352d0-4847-11e8-9afe-0242ac12000a"
}
]
}You can dynamically configure the repositories where products will automatically published.
As we've seen, on a chain you can configure which processes outputs need to be published. And when you do that, those outputs will be automatically published onto all the registered and enabled repositories.
You can register a new repository using the {host}/configuration/repositories URI with the HTTP POST method.
For now, you can register Geo Server and FTP repositories.
For example, if you want to register a new Geo Server repository:
{
"name": "My GeoServer Repository",
"type": "GEO_SERVER",
"configurations": {
"host": "my_geoserver",
"port": 80,
"protocol": "http",
"username": "me",
"password": "123",
"workspace": "lycheepy"
}
}Where host, port and protocol are mandatory settings.
Or, if you want to register a new FTP repository:
{
"name": "My FTP Repository",
"type": "FTP",
"configurations": {
"host": "my_ftp",
"username": "me",
"password": "123",
"timeout": 60,
"path": "lycheepy"
}
}Where host, username, password, and timeout are mandatory settings.
When you register a new repository, by default it is enabled. This means that since it has been registered, publishable outputs will be automatically published onto it. If you want to register a new repository, but not enable it yet, then add the "enabled" property with false as value. Something like this:
{
"enabled": false,
"name": "My Disabled FTP Repository",
"type": "FTP",
"configurations": {
"host": "my_disabled_ftp",
"username": "me",
"password": "123",
"timeout": 40
}
}Using the HTTP GET method over the {host}/configuration/repositories URI, you'll retrieve a list of all the registered repositories. Something like this:
{
"count": 2,
"results": [
{
"id": 1,
"name": "My GeoServer Repository",
"type": "GEO_SERVER",
"enabled": true,
"configurations": {
"host": "my_geoserver",
"protocol": "http",
"port": "8080"
},
"created": "2018-10-30T04:37:41.198935Z",
"availableConfigurations": ["host", "username", "password", "protocol", "port", "path", "workspace"],
"mandatoryConfigurations": ["host", "protocol", "port"]
},
{
"id": 2,
"name": "My FTP Repository",
"type": "FTP",
"enabled": true,
"created": "2018-10-30T04:38:06.299574Z",
"configurations": {
"host": "my_ftp",
"username": "me",
"password": "",
"timeout": "5",
"path": "lycheepy"
},
"availableConfigurations": ["host", "username", "password", "timeout", "path"],
"mandatoryConfigurations": ["host", "username", "password", "timeout"]
}
]
}Using the HTTP GET method over the {host}/configuration/repositories/{id} URI, you can retrieve a specific repository by its identifier. Something like this:
{
"id": 1,
"name": "My GeoServer Repository",
"type": "GEO_SERVER",
"enabled": true,
"configurations": {
"host": "my_geoserver",
"protocol": "http",
"port": "8080"
},
"created": "2018-10-30T04:37:41.198935Z",
"availableConfigurations": ["host", "username", "password", "protocol", "port", "path", "workspace"],
"mandatoryConfigurations": ["host", "protocol", "port"]
}Using the HTTP PUT method over the {host}/configuration/repositories/{id} URI, you can update a specific repository by its identifier. You can send one or more of the representation keys. For example, you could only update its name by sending something like:
{
"name": "This is not my repository!"
}Or update its configurations, and its name:
{
"name": "It was my repository",
"configurations": {
"host": "my_geoserver",
"protocol": "http",
"port": "8080"
}
}The repository type cannot be updated once it is created.
You can enable or disable a repository by simply using the HTTP PUT method over the {host}/configuration/repositories/{id} URI, and sending the "enabled" key. The true value stands for enabled, and false for deisabled.
Enabling example:
{
"enabled": true
}Disabling example:
{
"enabled": false
}And finally, using the HTTP DELETE method over the {host}/configuration/repositories/{id} URI, you can delete a specific repository by its identifier.
So, you (finally!) configured your repositories, your processes, some chains, and began executing some chains. Now, you want to access the automatically published products on the resistered repositories.
Whatever is your repository, products are published using a naming convention, so you can quickly identify them:
{Chain Identifier}:{Execution ID}:{Process Identifier}:{Output Identifier}
If you're using a GeoServer instance, you could install the CSW Plugin to it. This exposes a new OGC service: The Catalog Service for the Web (CSW). This catalog is filled automatically as you publish data into the repository.
So, making use of the CSW catalog, its GetRecords operation, and the previously explained naming convention, we can request things like:
- All the products, by simply not specifying any filter.
- All the products of a chain, using only the chain identifier.
- All the products of a chain execution, using only the Execution ID.
- All the products of a process, using only the process identifier.
- All the products of a process within a specific chain, using the chain identifier, and the process identifier.
- All the products produced by a specific output of an specific process, using the process identifier, and the output identifier.
- All the published outputs of a specific process within an execution, using the Execution ID, and the process identifier.
- And so on.
For example, you could request all the products of an specific execution, using a filter like the following (replace your execution identifier):
<csw:GetRecords xmlns:csw="http://www.opengis.net/cat/csw/2.0.2" xmlns:ogc="http://www.opengis.net/ogc" service="CSW" version="2.0.2" resultType="results" startPosition="1" maxRecords="10" outputFormat="application/xml" outputSchema="http://www.opengis.net/cat/csw/2.0.2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.opengis.net/cat/csw/2.0.2 http://schemas.opengis.net/csw/2.0.2/CSW-discovery.xsd" xmlns:gmd="http://www.isotc211.org/2005/gmd" xmlns:apiso="http://www.opengis.net/cat/csw/apiso/1.0">
<csw:Query typeNames="csw:Record">
<csw:ElementSetName>full</csw:ElementSetName>
<csw:Constraint version="1.1.0">
<ogc:Filter>
<ogc:PropertyIsLike matchCase="false" wildCard="%" singleChar="_" escapeChar="\">
<ogc:PropertyName>dc:title</ogc:PropertyName>
<ogc:Literal>%2e389cae-2a2b-11e8-8048-0242ac12000a%</ogc:Literal>
</ogc:PropertyIsLike>
</ogc:Filter>
</csw:Constraint>
</csw:Query>
</csw:GetRecords>And as a result, you'll get something like the following, which contains all the RAW, SSC, DGM, GEC, and GTC products (in the case of our example):
<?xml version="1.0" encoding="UTF-8"?>
<csw:GetRecordsResponse xmlns:csw="http://www.opengis.net/cat/csw/2.0.2" xmlns:rim="urn:oasis:names:tc:ebxml-regrep:xsd:rim:3.0" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dct="http://purl.org/dc/terms/" xmlns:ows="http://www.opengis.net/ows" xmlns:ogc="http://www.opengis.net/ogc" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2.0.2" xsi:schemaLocation="http://www.opengis.net/cat/csw/2.0.2 http://repository:8080/geoserver/schemas/csw/2.0.2/record.xsd">
<csw:SearchStatus timestamp="2018-04-25T05:22:58.854Z"/>
<csw:SearchResults numberOfRecordsMatched="5" numberOfRecordsReturned="5" nextRecord="0" recordSchema="http://www.opengis.net/cat/csw/2.0.2" elementSet="full">
<csw:Record>
<dc:identifier>lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L0:RAW</dc:identifier>
<dc:creator>GeoServer Catalog</dc:creator>
<dct:references scheme="OGC:WMS">http://repository:8080/geoserver/wms?service=WMS&request=GetMap&layers=lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L0:RAW</dct:references>
<dc:subject>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L0:RAW</dc:subject>
<dc:subject>WCS</dc:subject>
<dc:subject>GeoTIFF</dc:subject>
<dc:description>Generated from GeoTIFF</dc:description>
<dc:title>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L0:RAW</dc:title>
<dc:type>http://purl.org/dc/dcmitype/Dataset</dc:type>
<ows:BoundingBox crs="urn:x-ogc:def:crs:EPSG:6.11:4326">
<ows:LowerCorner>40.61211948610636 14.007123867581605</ows:LowerCorner>
<ows:UpperCorner>41.06318200414095 14.555170176382685</ows:UpperCorner>
</ows:BoundingBox>
</csw:Record>
<csw:Record>
<dc:identifier>lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1A:SCS</dc:identifier>
<dc:creator>GeoServer Catalog</dc:creator>
<dct:references scheme="OGC:WMS">http://repository:8080/geoserver/wms?service=WMS&request=GetMap&layers=lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1A:SCS</dct:references>
<dc:subject>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1A:SCS</dc:subject>
<dc:subject>WCS</dc:subject>
<dc:subject>GeoTIFF</dc:subject>
<dc:description>Generated from GeoTIFF</dc:description>
<dc:title>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1A:SCS</dc:title>
<dc:type>http://purl.org/dc/dcmitype/Dataset</dc:type>
<ows:BoundingBox crs="urn:x-ogc:def:crs:EPSG:6.11:4326">
<ows:LowerCorner>40.61211948610636 14.007123867581605</ows:LowerCorner>
<ows:UpperCorner>41.06318200414095 14.555170176382685</ows:UpperCorner>
</ows:BoundingBox>
</csw:Record>
<csw:Record>
<dc:identifier>lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1B:MDG</dc:identifier>
<dc:creator>GeoServer Catalog</dc:creator>
<dct:references scheme="OGC:WMS">http://repository:8080/geoserver/wms?service=WMS&request=GetMap&layers=lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1B:MDG</dct:references>
<dc:subject>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1B:MDG</dc:subject>
<dc:subject>WCS</dc:subject>
<dc:subject>GeoTIFF</dc:subject>
<dc:description>Generated from GeoTIFF</dc:description>
<dc:title>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1B:MDG</dc:title>
<dc:type>http://purl.org/dc/dcmitype/Dataset</dc:type>
<ows:BoundingBox crs="urn:x-ogc:def:crs:EPSG:6.11:4326">
<ows:LowerCorner>40.61211948610636 14.007123867581605</ows:LowerCorner>
<ows:UpperCorner>41.06318200414095 14.555170176382685</ows:UpperCorner>
</ows:BoundingBox>
</csw:Record>
<csw:Record>
<dc:identifier>lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1C:GEC</dc:identifier>
<dc:creator>GeoServer Catalog</dc:creator>
<dct:references scheme="OGC:WMS">http://repository:8080/geoserver/wms?service=WMS&request=GetMap&layers=lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1C:GEC</dct:references>
<dc:subject>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1C:GEC</dc:subject>
<dc:subject>WCS</dc:subject>
<dc:subject>GeoTIFF</dc:subject>
<dc:description>Generated from GeoTIFF</dc:description>
<dc:title>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1C:GEC</dc:title>
<dc:type>http://purl.org/dc/dcmitype/Dataset</dc:type>
<ows:BoundingBox crs="urn:x-ogc:def:crs:EPSG:6.11:4326">
<ows:LowerCorner>40.61211948610636 14.007123867581605</ows:LowerCorner>
<ows:UpperCorner>41.06318200414095 14.555170176382685</ows:UpperCorner>
</ows:BoundingBox>
</csw:Record>
<csw:Record>
<dc:identifier>lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1D:GTC</dc:identifier>
<dc:creator>GeoServer Catalog</dc:creator>
<dct:references scheme="OGC:WMS">http://repository:8080/geoserver/wms?service=WMS&request=GetMap&layers=lycheepy:Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1D:GTC</dct:references>
<dc:subject>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1D:GTC</dc:subject>
<dc:subject>WCS</dc:subject>
<dc:subject>GeoTIFF</dc:subject>
<dc:description>Generated from GeoTIFF</dc:description>
<dc:title>Cosmo Skymed:41838c1c-4847-11e8-9afe-0242ac12000a:L1D:GTC</dc:title>
<dc:type>http://purl.org/dc/dcmitype/Dataset</dc:type>
<ows:BoundingBox crs="urn:x-ogc:def:crs:EPSG:6.11:4326">
<ows:LowerCorner>40.61211948610636 14.007123867581605</ows:LowerCorner>
<ows:UpperCorner>41.06318200414095 14.555170176382685</ows:UpperCorner>
</ows:BoundingBox>
</csw:Record>
</csw:SearchResults>
</csw:GetRecordsResponse>First of all, clone the repository. LycheePy uses git-submodules, so you should clone recursively:
git clone https://github.com/gabrielbazan/lycheepy.git --recursive
Then, install docker-ce, and docker-compose, by running:
cd lycheepy/lycheepy/
sudo ./install_host_dependencies.sh
Now everything we need is installed. To build an run, do the following:
sudo ./start.sh
And now you're able to use your LycheePy instance.
LycheePy also has a web client! You you can find here.
Do you use it? Add yourself! :)
Feel free to contribute, or come up with some ideas!