MaskDepthGenerator takes an image and its background as input to generate depth and mask for the image.
Custom Dataset was made and used for training the network. Details about it can be found here.
BG image - 100 images of 160x160x3 dimension
FG with BG - 400000 images of 160x160x3 dimension
GT Mask - 400000 images of 160x160x1 dimension
GT depth - 400000 images of 160x160x1 dimension
Data augmentation used: Random flipping

{kind=link}
This model is based on Encoder-Decoder architectural style. Pre-trained ResNet18 with first and last layer removed is taken as the backbone for the encoder. The Decoder consist of two branches - one for generating the mask, and the other for generating the depth. Each branch of the Decoder consist of [2, 2, 2, 2] block similar to ResNet18 backbone and each block in the decoder has a skip connection to the corresponding block in the encoder, where each unit performs 2 convolution and bilineear interpolation. Link to model

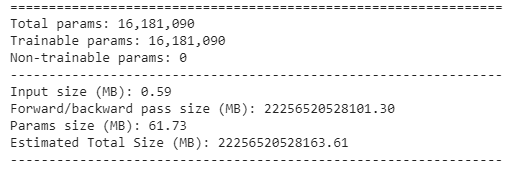
Total number of parameters: 16 million
Link to API used for MaskDepthGenerator
Below is the GPU and memory usage of training code.
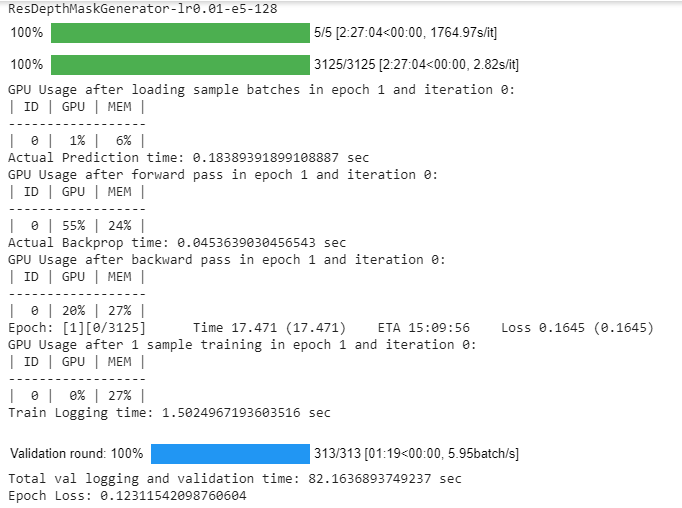
This is the link to training code profiling
From this, we can see that 78% of the time is spent on loss calculation and batch sampling.
I started with training two separate models. One for mask prediction and the other for depth. For mask, since it was a simple prediction, I used a 2 layer encoder-decoder structure. For encoding, I used 2 Convolution block consisting of 3x3 convolution followed by ReLU and then BatchNorm. For decoding, 2 3x3 convolution and then convtranspose2d. For depth, I used the model architecture mentioned above. Once I observed both were working properly, I merged mask prediction in this depth prediction structure.
For training, I used SGD optimizer with 0.01 learning rate.
Initially, I trained the network with image size of 80x80. During this, I used L1 loss for depth prediction and BCELossWithLogits for mask prediction.
For below input images:
- Background image

- FG_BG Image

Outputs were:
- Depth Prediction

- Mask Prediction

True Images:
- Depth

- Mask

Then, I trained the network with image size of 160x160. After the first epoch, the resulting predictions were good enough to start. But after this, the depth predictions were just gray images. So, I changed the loss function. For depth prediction, I changed it to a combination of pixel intensity loss(L1), loss in edges(calculated using Sobel filters) and structural similarity(SSIM). For mask, results were coming fine but fine structures were not captured properly. So, I changed it to be a combination of BCELossWithLogits and SSIM(to maintain structural similarity).
I used RMSE to evaluate depth prediction which turned out to be 0.18 and mean IoU for mask prediction which turned out to be around 0.2.
This low value is due to abnormal weightage of losses and the model needs more training.
-
Time constraint of colab
-
Large size of data.
-
Data was read as bytes rather than extracting since extracting files exploded RAM. Resizing images to smaller size helped in reducing image size. For original size, data splitting and training helped.
-
For overcoming time constraint in colab, created million of accounts :p. Switching between runtime type. This did not help much.
-
Using data which was read as bytes impacts efficiency of increasing batch size and number of workers. For 64 batch size and 128 batch size, it took nearly the same time for single epoch training. With 128 batch size, I was able to handle all data for training for 80x80 image size. For 160x160 image size, I was able to handle only 70% of data with batch size of 64 during training.
-
Even though the images used as background were quite simple but the complexity of foreground increased model complexity.