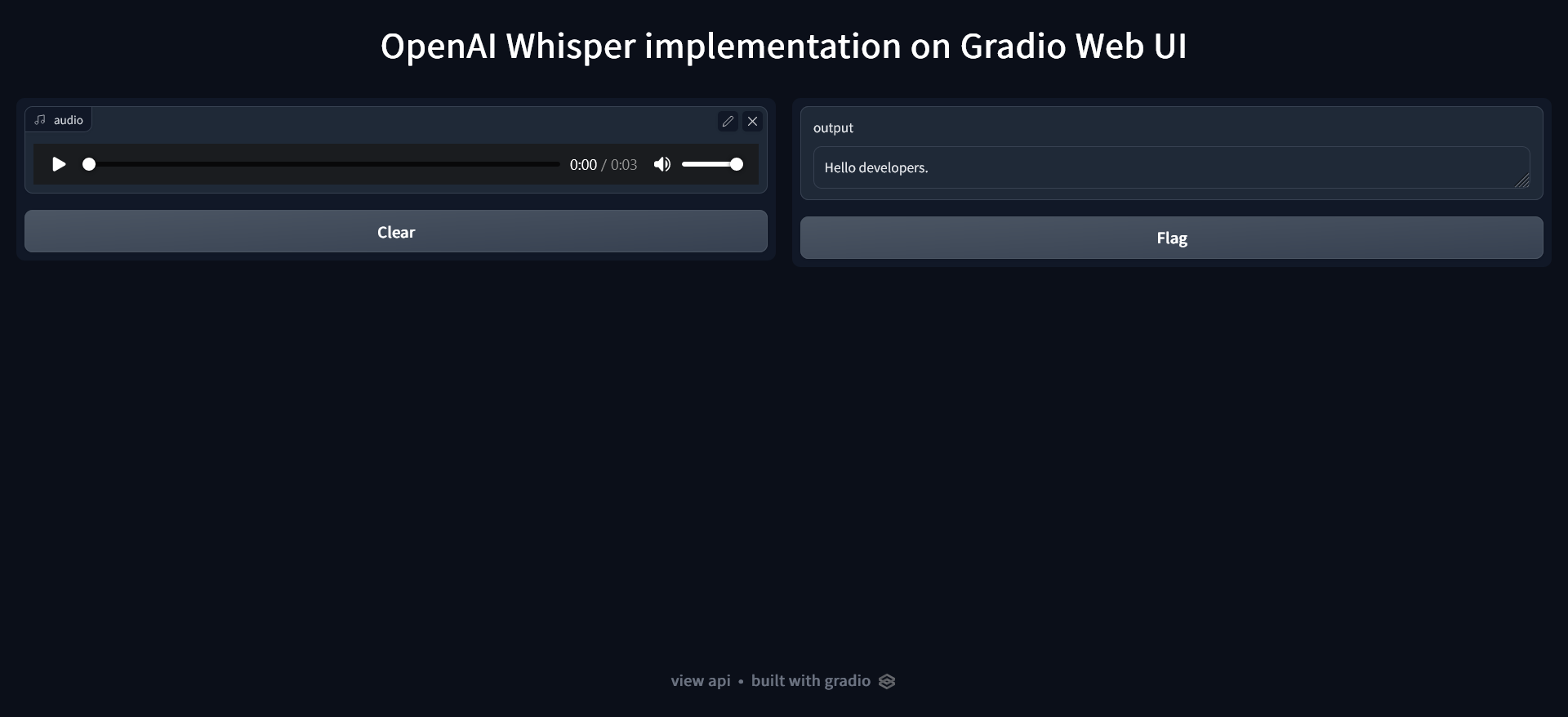
Whisper is an automatic speech recognition (ASR) system Gradio Web UI Implementation
Install ffmeg on Your Device
# on Ubuntu or Debian
sudo apt update
sudo apt install ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpegDownload Program
mkdir whisper-sppech2txt
cd whisper-sppech2txt
git clone https://github.com/innovatorved/whisper-openai-gradio-implementation.git .
pip install -r requirements.txtRun Program
python app.py
Available models and languages (Credit)
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and relative speed.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
For English-only applications, the .en models tend to perform better, especially for the tiny.en and base.en models. We observed that the difference becomes less significant for the small.en and medium.en models.
I'm a Developer i will feel the code then write .
For support, email vedgupta@protonmail.com