This repository includes a procedure for extracting articulatory features with the corresponding acoustic features from the electromagnetic articulography (EMA) dataset. Currenetly, this procedure is only optimized for the Haskins IEEE EMA dataset (Link). Support for different datasets will be considered if necessary.
- Features
- Articulatory features: pellet sensor coordinates (horizontal, vertical)
- Acoustic features: formant frequencies (F1, F2, F3) and f0
- meta: speaker, utterance, word, phone etc.
- Data input-output
- Input: EMA data (
*.mator*.pkl) - Output: articulatory and acoustic data features (
*.pklor*.csv)
- Input: EMA data (
To use this procedure, you have to meet the following requirements:
- EMA data collected using AG501 or NDI WAVE system
- Simultaneous acoustic recording
- Data compatible to MVIEW (developed by Mark Tiede @Haskins labs) in Matlab (Check out the python conversion procedure: link)
- (1) Prepare data
- (2) Extract features (articulation, acoustics) (
extractor.py) - (3) Check features (
validate.py)
An example of using this procedure:
-
(1) Prepare data
# Prepare data as in the example folder # example # - F01_B01_S01_R01_F.pkl # - F01_B01_S01_R01_N.pkl # - ... # # See: https://github.com/jaekookang/Python-EMA-Viewer
-
(2) Extract features
# For a single file with 5 points given a vowel python extractor.py example/F01_B01_S01_R01_N.pkl result/result.csv \ --vowel IY1,IH1,EH1,AO1,AH1,AA1,AE1,UH1,UW1 \ --artic tr,td,tt,ja,ul,ll \ --acous f0,f1,f2,f3 \ --n_points 5 \ --ref example/reference_formants.xlsx \ --skip_nans False \ --write_log True # For multiple files, you can specify the directory name instead of file name at DATAFILE # usage: extractor.py [-h] --vowel VOWEL --artic ARTIC --acous ACOUS --n_points # N_POINTS [--ref REF] [--skip_nans SKIP_NANS] # DATAFILE OUTFILE # Extract articulatory and acoustic features from the EMA data # positional arguments: # DATAFILE Specify filename or directory # OUTFILE Specify output file name (eg. result.csv) # optional arguments: # -h, --help show this help message and exit # --vowel VOWEL Specify vowels (eg. # IY1,IH1,EH1,AO1,AH1,AA1,AE1,UH1,UW1 # --artic ARTIC Specify articulatory features (eg. tr,td,tt,ja,ul,ll) # --acous ACOUS Specify acoustic features (eg. f0,f1,f2,f3 or # f0,f1,f2) # --n_points N_POINTS Specify the number of data points to extract given a # vowel (<10) # --ref REF Specify a formant reference file for accurate tracking # --skip_nans SKIP_NANS # If False (default), it will throw errors on NaNs # --write_log WRITE_LOG # if True (default: False), it will write a log file # {OUTFILE}.log only if there are errors
-
(3) Check features
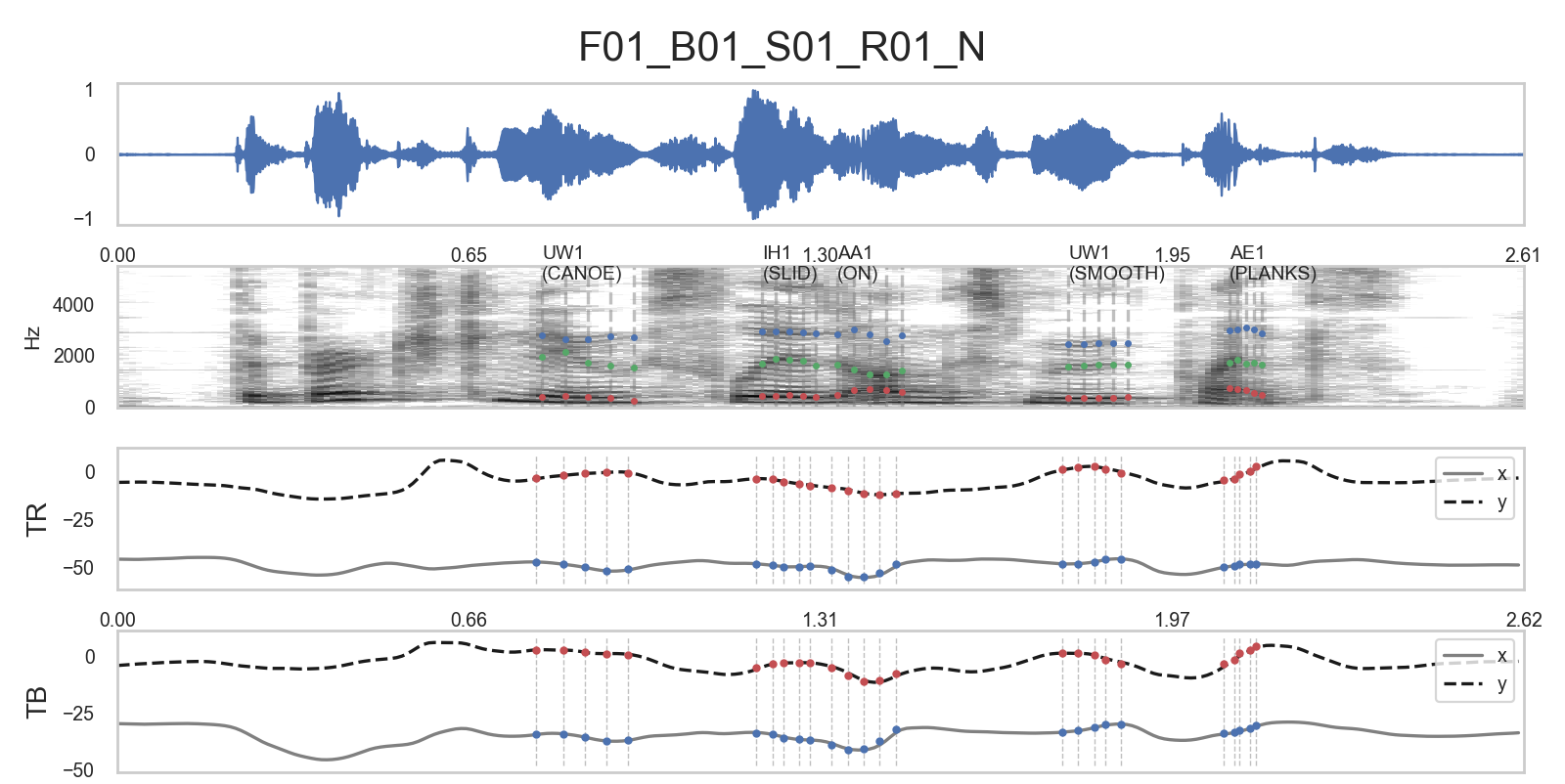
python validate.py result/result.csv \ example/F01_B01_S01_R01_N.pkl \ result/F01_B01_S01_R01_N.png \ --fileid F01_B01_S01_R01_N #usage: validate.py [-h] --fileid FILEID RESULTFILE DATAFILE PNGFILE # #Validate the result file from extractor.py # #positional arguments: #RESULTFILE Specify the result file created from extractor.py (*.csv) #DATAFILE Specify the data file (*.pkl) #PNGFILE Specify the output png file w/ path; "out.png" # #optional arguments: #-h, --help show this help message and exit #--fileid FILEID Specify fileid; eg. F01_B01_S01_R01_N # #See https://github.com/jaekookang/Articulatory-Data-Extractor
- For example
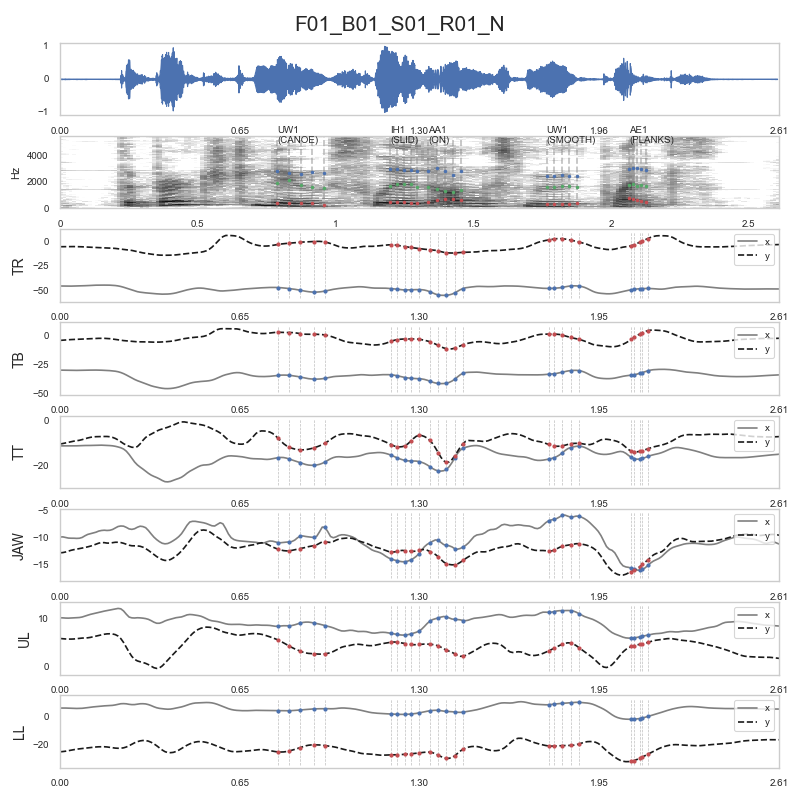
- For example
- Python-EMA-Viewer: https://github.com/jaekookang/Python-EMA-Viewer