Home
RDMA (Remote Direct Memory Access) is an emerging networking technology promising higher throughput and lower latency compared to traditional TCP/IP based networks. RDMA has been widely used in high performance computing (HPC), and now becomes more popular in today's datacenter environment. This tutorial explains some of the basic concepts of RDMA based programming, and it also covers some commonly applied optimization techniques.
This tutorial servers as a brief summary of the contents from the following links, which have more details and code examples:
-
- Gives great explanations of RDMA interfaces and code snippets on how to use them.
-
- Example code demonstrating the latest software/hardware features can be found within libibverbs*/examples and perftest*
-
Mellanox OFED manual
- Google search for the latest version
To draw an analogy from everyday mail service, queue pair (QP) defines the address of the communication endpoints, or equivalently, sockets in traditional socket based programming. Each communication endpoint needs to create a QP in order to talk to each other.
There are three different types of QP: RC (Reliable Connection), UC (Unreliable Connection) and UD (Unreliable Datagram). A more recent optimization from Mellanox introduces DCT (Dynamically Connected Transport) to solve the QP scalability problem.
If QP is connected (RC or UC), each QP can only talk to ONE other QP. Otherwise, if QP is created as UD or DCT, the QP is able to talk to ANY other QPs. A more detailed discussion on how to choose the type of QP can be found later in Choice of QP types.
In RDMA based programming, verb is a term that defines the types of communication operations. There are two different communication primitives: channel semantics (send/receive) and memory semantics (read/write). If we only consider how data is delivered to the other end, channel semantics involves both communication endpoints: the receiver needs to pre-post receives and the sender posts sends; while memory semantics only involves one side of the communication endpoint: the sender can write the data directly to the receiver's memory region, or the receiver can read from the target's memory region without notifying the target.
Generally speaking, memory semantics has less overhead compared to channel semantics and thus has higher raw performance; On the other hand, channel semantics involves less programming effort.
git checkout 65893ec
We start off with a simple example only involves two nodes: a server and a client. Messages are ping-ponged between the server and client, while the client initiates the sending of the messages. This simple example is used to demonstrate the common process of setting up connection using IB. (In this tutorial, we use RDMA and IB interchangeably since IB, short for Infiniband, is one of the most popular hardware implementation of RDMA technology). In this first example, we use RC QP and Send/Receive verbs.
Check the implementation of function setup_ib in "setup_ib.c" for more details.
-
Step 1: Get IB context
struct ibv_contextFirst, we need to get IB device list by calling
ibv_get_device_list; Then we can get IB context by calling:ibv_open_device -
Step 2: Allocate IB protection domain
struct ibv_pdProtection domain will later be used to register IB memory region and create Queue Pairs. Protection domain is allocated by calling:
ibv_alloc_pd -
Step 3: Register IB memory region
struct ibv_mrIB memory region is used to store messages exchanged among nodes. Older version of hardware requires these memory regions to be pinned (thus, cannot be swapped out by OS); however, newer hardware that supports on demand paging relaxes such restriction. Memory region is managed by the programmer. The programmer needs to make sure the old message that has not been processed, does not get overwritten by the newly incoming message. Memory region is registered by calling
ibv_reg_mr -
Step 4: Create Completion Queue
struct ibv_cqCompletion Queue (CQ) is commonly used along with channel semantics (send/receive). It provides a way to notify the programmer that the operation is complete. Completion queue can be created using
ibv_create_cq -
Step 5: Create Queue Pair
struct ibv_qpQueue Pair (QP) can be created by calling
ibv_create_qp -
Step 6: Query IB port attribute
struct ibv_port_attrIB port attribute can be obtained by calling
ibv_query_port. The fieldlidfrom port attribute will later be used to connect QPs -
Step 7: Connect QP
Now QPs are created, they need to know whom they are talking to. IB needs to use out-of-band communication to connect QP. Commonly, Sockets are used to exchange QP related information. In the case of channel semantics (send/recv), only two pieces of information need to be exchanged in order to connect QP:
lidfromstruct ibv_port_attrandqp_numfromstruct ibv_qp. Afterlidandqp_numhas been received, QP state can be changed from INIT to RTR (ready to receive) and then to RTS (ready to send) by callingibv_modify_qp
git checkout e1570c6
Default setup for Example 1 is to use 64B message and ping-pong one message a time. Now, we modify the command line arguments to introduce two more input parameters: msg_size and num_concurr_msgs. The meaning of msg_size is straightforward. The other parameter, num_concurr_msgs, defines how many messages can be sent at the same time.

As shown in figure above, generally speaking, by using small message size and large number of concurrent messages, it is more likely to saturate the NIC hardware (in terms of operations per second, NOT bytes per second. To have a higher bandwidth number (B/s), large message size should be used), and hence, has a higher throughput number. The downside of having a large number of concurrent messages is that it would potentially consumes more memory.
git checkout f73736e
In this example, we demonstrate how to implement the same echo benchmark as example 1 but using RDMA write. Now the sender needs to know where to write the message on the receiver's end. As a result, two more pieces of information need to be exchanged during QP connection: rkey and raddr. rkey is the key of the receiver's memory region, and raddr is the receiver's memory address the sender will write the message to.
In the previous example, the incoming messages are detected by polling the completion queue: a completed event for a posted receive indicates a newly incoming message. Since RDMA write is one-sided communication primitive, such that the receiver is not notified for the incoming messages. In this example, we demonstrate a different way of detecting incoming messages. We assume all messages are of the same content: "AA..A", whose length is determined by msg_size. For instance, to detect the first incoming message, one needs to poll two memory locations: raddr and raddr + msg_size - 1. As soon as the content of these two memory locations turn into 'A', the first incoming message is received. You will find the following code snippet in both "client.c" and "server.c", which is used to detect incoming messages.
while ((*msg_start != 'A') && (*msg_end != 'A')) {
}
One may notice that, within the post_send function implementation in "ib.c", we set the send_flags to be IBV_SEND_SIGNALED. As a result, each send operation also generates a completion event when it is finished (when the message has been delivered to the receiver and an acknowledgement is sent back to the sender). Although in example 1, we generally ignore such events, in both "client.c" and "server.c", only completion events of posted receives are polled to detect incoming message:
if (wc[i].opcode == IBV_WC_RECV) {
...
}
Since the completion events of the sends are not relevant, we can get ride of the notification of such events by not setting send_flags (the default behavior is not signaled), as shown in post_write_unsignaled in "ib.c". However, we can not use unsignaled sends all the time. Under the current libverbs implementation, a send operation is only considered to be completed when a completion event of this operation is generated and polled from the CQ. If one kept posting unsignaled sends, the send queue will eventually be full because none of these operations would be thought as completed and hence they remain in the send queue; and as a result, no more sends can be posted to the send queue. It also happens when one uses signaled sends but not polling any completion events from the CQ. As a result, a common practice is to use selective signaling, where a signaled send is posted once in a while, and then poll its completion event from the CQ. After the completion event of the signaled send is polled from CQ, all previous sends are considered to be completed and thus are removed from the send queue. Unsignaled sends have less overhead compared to signaled sends, therefore, selective signaling tends to have better performance. A more detailed discussion can be found here
As we have discussed earlier, the detection of a newly incoming message is by polling memory locations till they turn into the specific content ('A' in our example). In practice, the memory region will be reused once the message has been processed. As a result, as soon as the message has been processed, we need to reset the memory region such that it does not contain the old message.
In the previous example, we demonstrate one optimization technique: selective signaling. In the following, we will discuss two more: message inlining and batching.
git checkout 1b460c2
To post a send (or write), a work request (WR), ibv_send_wr, needs to be prepared before it is passed on to ibv_post_send. WR stores a pointer pointing to the memory region containing the message would be sent to the receiver. The successful return of a ibv_post_send function call only indicates that such work request has been passed down to the NIC and stored within the send queue. When the work request is later being pulled out from the send queue and processed, the NIC follows the pointer to find the memory region and copy out the message to be sent. Therefore, it involves two round trips between the NIC and the host memory: first WR to NIC, then message to NIC.
Most RDMA compatible NICs allow some small messages to be inlined with the WR, such that the message body is copied together with the WR to the NIC; and as a result, saves one round trip of following the pointer to copy out the actual message. Unfortunately, there is no way to determine the max inline message size supported by the hardware. It is normally done by using trial and error.
To enable inlined message. Two places need to be modified: first, add max_inline_data to ibv_qp_init_attr when create QP; second, set send_flags to IBV_SEND_INLINE.
git checkout d7dd63e
There are two different ways that CPU communicates with the NIC: MMIO and DMA. When calling ibv_post_send, the CPU uses MMIO to write WR to the NIC memory; and when the NIC starts to process the WR and needs to copy the message body by following the pointer, it uses DMA. Generally speaking, DMA is more efficient compared to MMIO.
If one needs to send out N messages, a common practice is call ibv_post_send N times, and each time CPU uses MMIO to write WR to NIC memory. A different approach is to use a link list of WRs where ibv_post_send is called only once to write the head of the WR list to the NIC using MMIO, and the NIC reads the rest of the WRs using DMA. This second approach is called batching which is more efficient than the first approach. In order to use message batching, a list of ibv_send_wr needs to be created manually by setting ibv_send_wr.next pointing to the next WR. Check the implementation of function setup_ib in "setup_ib.c" for more details.
However, if one needs to send out multiple messages to different destinations, thus involves more than one QPs, these messages cannot be batched. Under this constraint, messages can be batched must use the same QP. Therefore, there exists an alternative approach: if those outgoing messages are sent to the same QP, packing these messages into one big message at the sender and unpack them at the receiver. Sending one big message is even more efficient than batching. However, it involves packing and unpacking at both ends. We will not discuss this approach further in this tutorial.
A comparison of the throughput performance for different optimization techniques is shown in the following figure. Data are collected using 8B messages (for write batch, batch size is chosen to be 4). Write performs better than send/recv. Write inline and write are similar, while batching has better performance when the number of concurrent messages is small.

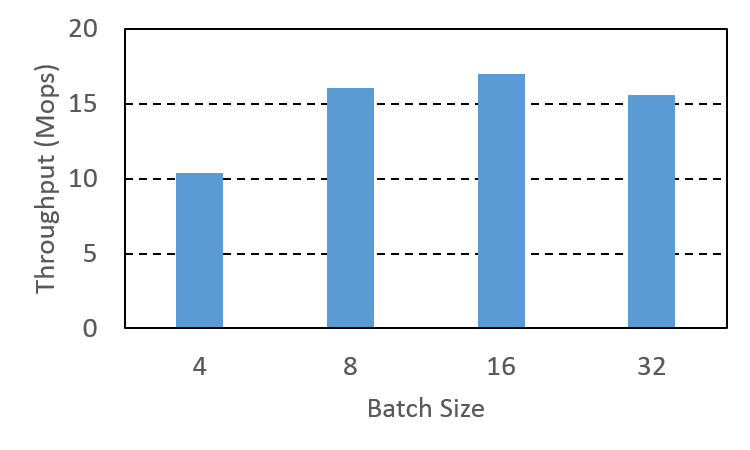
In the following figure, we show how the batch size affects throughput performance. The data are collected using 8B messages and maximum of 64 concurrent messages.
git checkout ec2a4db
Shared receive queue (SRQ) is introduced to improve memory efficiency by allowing one receive queue being shared among different QPs. Before SRQ is introduced, each QP needs to create its own receive queue. Imaging a case where 100s or even 1000s of QPs need to be created, which is not uncommon for real world applications, the same number of receive queues need to allocated that leads to potential huge memory wastage. The reason is that although one node may need to talk to 100s or 1000s other nodes, it is uncommon for it to talk to all the nodes at the same time, which means among those 100s or 1000s receive queues, only a few being used at a particular time. With the introduction of the SRQ, the number of receive queues no longer grows linearly with the number of QPs.
SRQ is created using ibv_create_srq. When QP is created, specify the SRQ that QP is intended to use under ibv_qp_init_attr.srq. Receives are posted by calling ibv_post_srq_recv
When SRQ is used, the source of the incoming message is implicit. There are multiple ways to determine the source of the incoming message, the solution adopted by this tutorial is by embedding the rank of the QP inside the imm_data, which is a 4B data sent along with the actual message. In order to send message along with a imm_data field, the ibv_send_wr.op_code needs to be set to IBV_WR_SEND_WITH_IMM.
One big limitation of SRQ is that a single SRQ only supports one message size, which is fundamental, because receives are served in FIFO order. To deal messages of variable sizes, either use one SRQ which accommodates the maximum message size or multiple SRQs each accommodates a different message size.
Due to lack of state of art IB hardware, we hope to include such example using DCT in the future. Meanwhile, reader of this tutorial can find code example for how to use DCT under libibverbs*/examples (with the latest libverbs distribution).
With no experience with DCT, we focus our discussion on choice between RC (Reliable Connection) and UD (Unreliable Datagram). Compared to RC, UD has less overhead hence has better raw performance. However, the performance improvement provided by using UD instead of RC is minimal compared to choose UDP over TCP. It is because the RDMA protocol processing is mostly in hardware, while TCP/UDP uses kernel software. The main advantage of using UD is that a single QP can used to talk to any other QPs, while using RC, one needs to create as many QPs as the number of communication peers. However, with the introduction of DCT, QP scalability problem can be well addressed.
There are a few constrains when using UD:
-
Maximum message size is limited by MTU. Modern RDMA compatible NICs supports MTU of size 2KB to 4KB, which means message of size larger than 4KB needs to be broken down into smaller pieces at the sender and re-assembled at the receiver. It simply requires more programming effort.
-
Each message sent using UD has a Global Routing Header (GRH) of 40B long. Even if your message is of size 8B, the total amount of data needs to be sent is at least 48B.
-
Out-of-order message delivery. Different from RC, the message order is not guaranteed. In case where message order is important, programmers need to keep track of the message order by themselves.
-
Unreliable message delivery. Although in today's datacenter environment, package drop is rare, unless applications allow message drops, tracking message delivery and re-transmission scheme all need to be implemented using software.
In my opinion, unless the application allows message drops, does not care about the order of message delivery and always has message size less than the MTU, using UD requires re-implement existing hardware logic (used for RC QP) in software, which leads to more programming effort and potentially worse performance.
Example 2 shows how to poll incoming messages when using RDMA write. However, example 2 only shows the case where only 1 communication peer is involved. If there are 100s of communication peers, which means we need to poll 100s of different memory locations for incoming messages. Straightforward solutions includes polling 100s of different memory locations in a round robin fashion, or spawning 100s of threads, each dedicates to one memory region. Neither seems to be efficient or scalable. Plus for these types of polling method, the application needs to reserve special characters for message termination and reset memory region manually after processing each message.
An alternative approach involves usage of CQ. Since RDMA write does not use pre-post receives, we cannot poll CQ for receive completion events to detect incoming messages. In order to generate a completion event for incoming RDMA write, we need to set use ibv_send_wr.op_code to IBV_WR_RDMA_WRITE_WITH_IMM . The extra immediate data field associated with the write operation generates a completion event which can be polled by the CQ. Plus, one can embed the message length information in imm_data so that application does not need to reserve special character for message termination or reset memory region after the message being processed.
For a small number of QPs, polling at memory locations directly could outperform using CQ. With a large number of QPs, in my opinion, the alternative approach using RDMA write with imm_data provides a single point polling (polling at CQ) which is more scalable.