-
Notifications
You must be signed in to change notification settings - Fork 6
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
🔧 fix small error, update project version
- Loading branch information
Showing
4 changed files
with
21 additions
and
5 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
7c6bda8There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Classification Report
Metrics
Confusion Matrix
Errorcases
Hyperparameters Tuning
Leaderboard
7c6bda8There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Tabular Classification Report
Metrics
SHAP train
SHAP val
Hyperparameters Tuning
Leaderboard
Figures
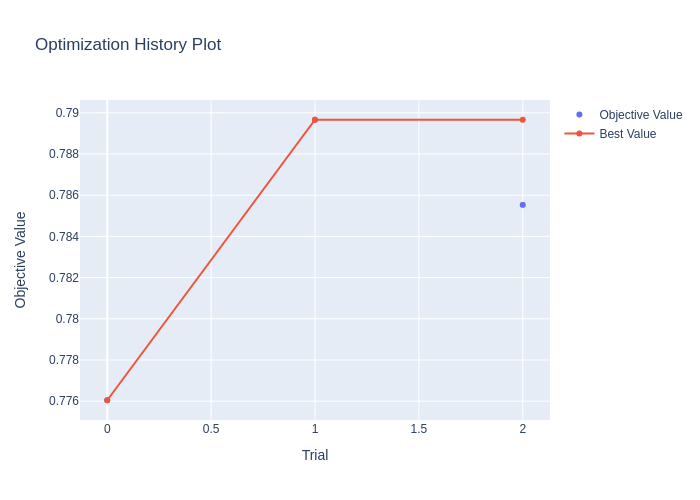
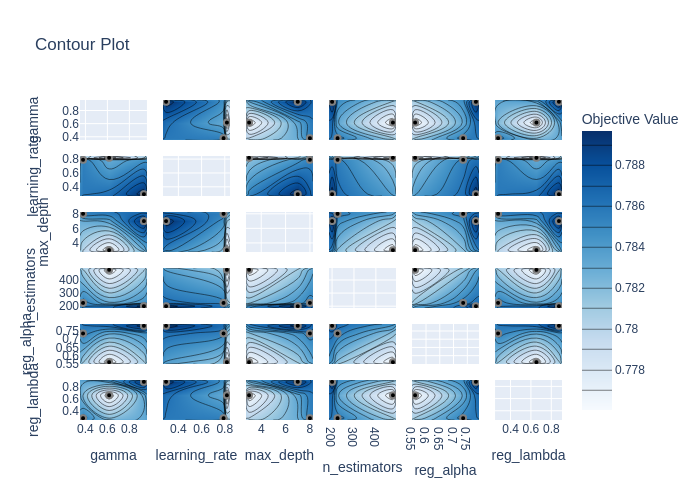
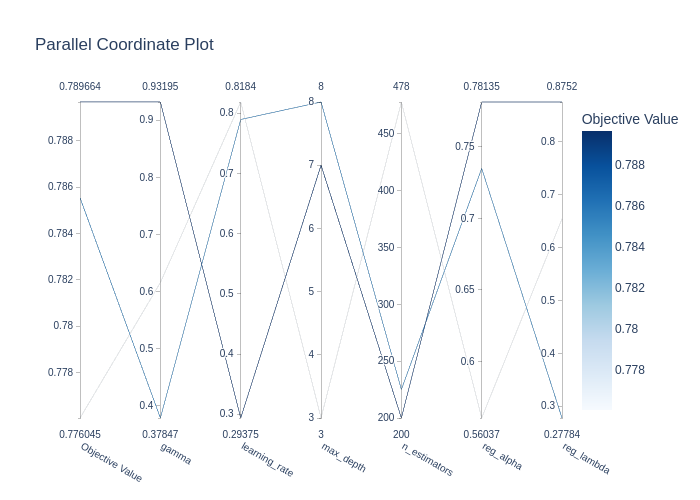
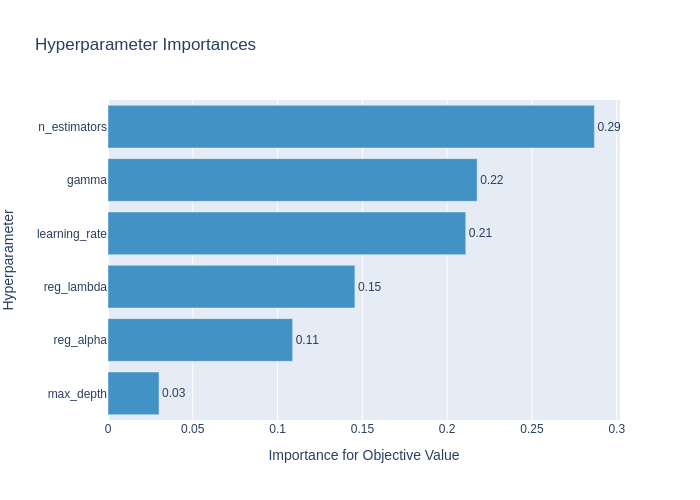
7c6bda8There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Semantic Report
Metrics
Prediction