Features • Download • Usage • Motivation • Contributing • Upcoming
StatsAssume automates the assumption checks of regression models (e.g., linear and logistic regression) on your data and displays the results in an elegant dashboard.
-
Automatically detects regression task (and relevant assumption checks) based on the target variable of dataset.
-
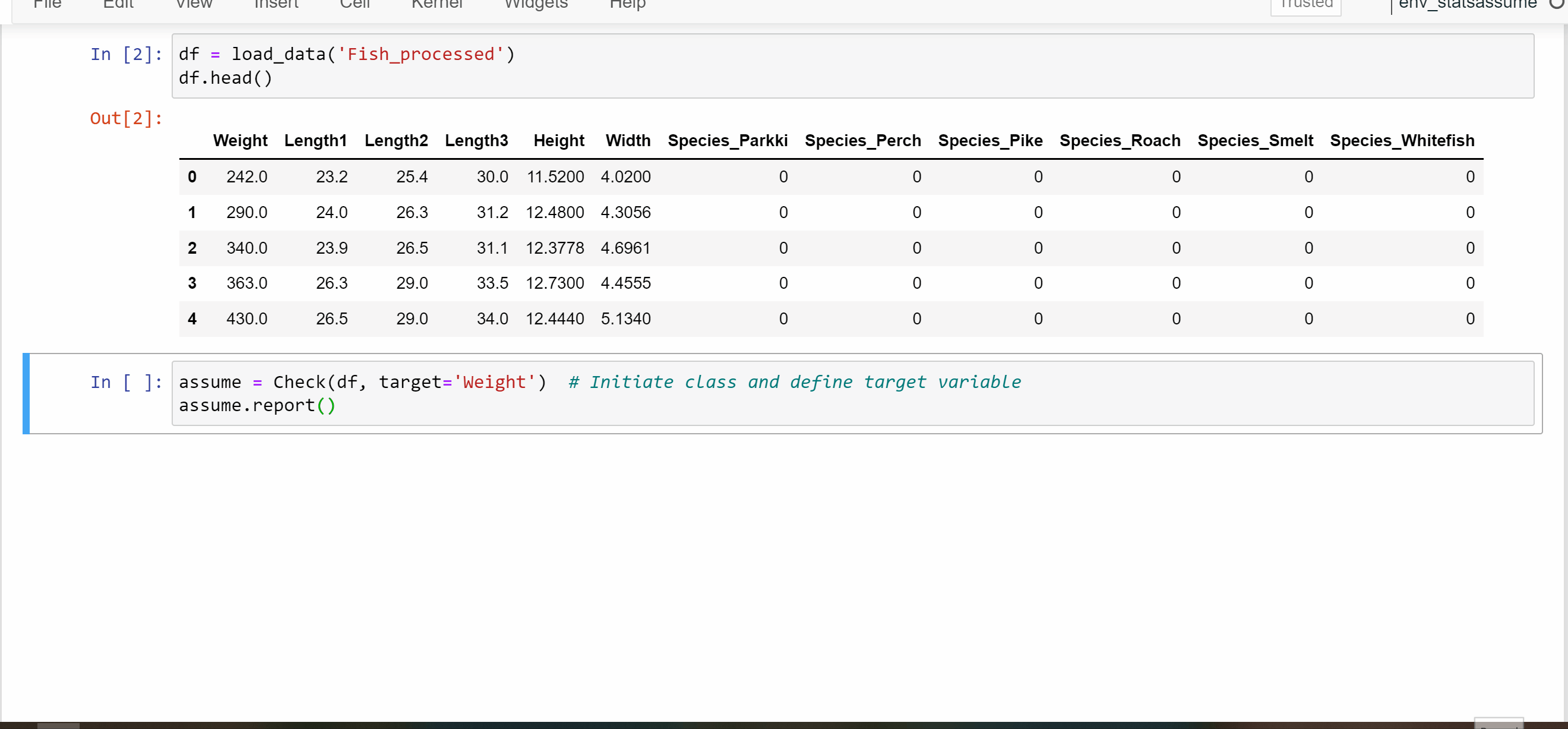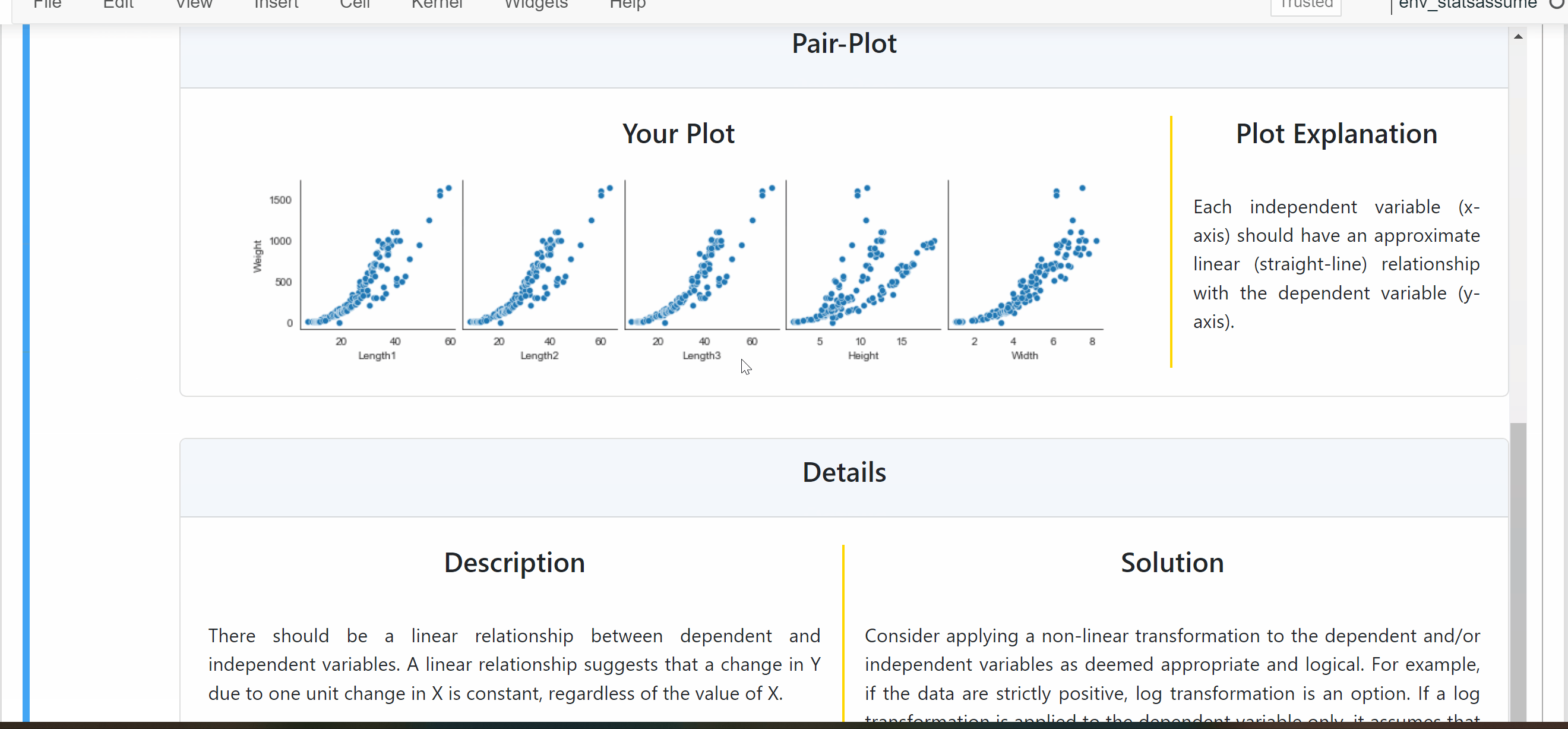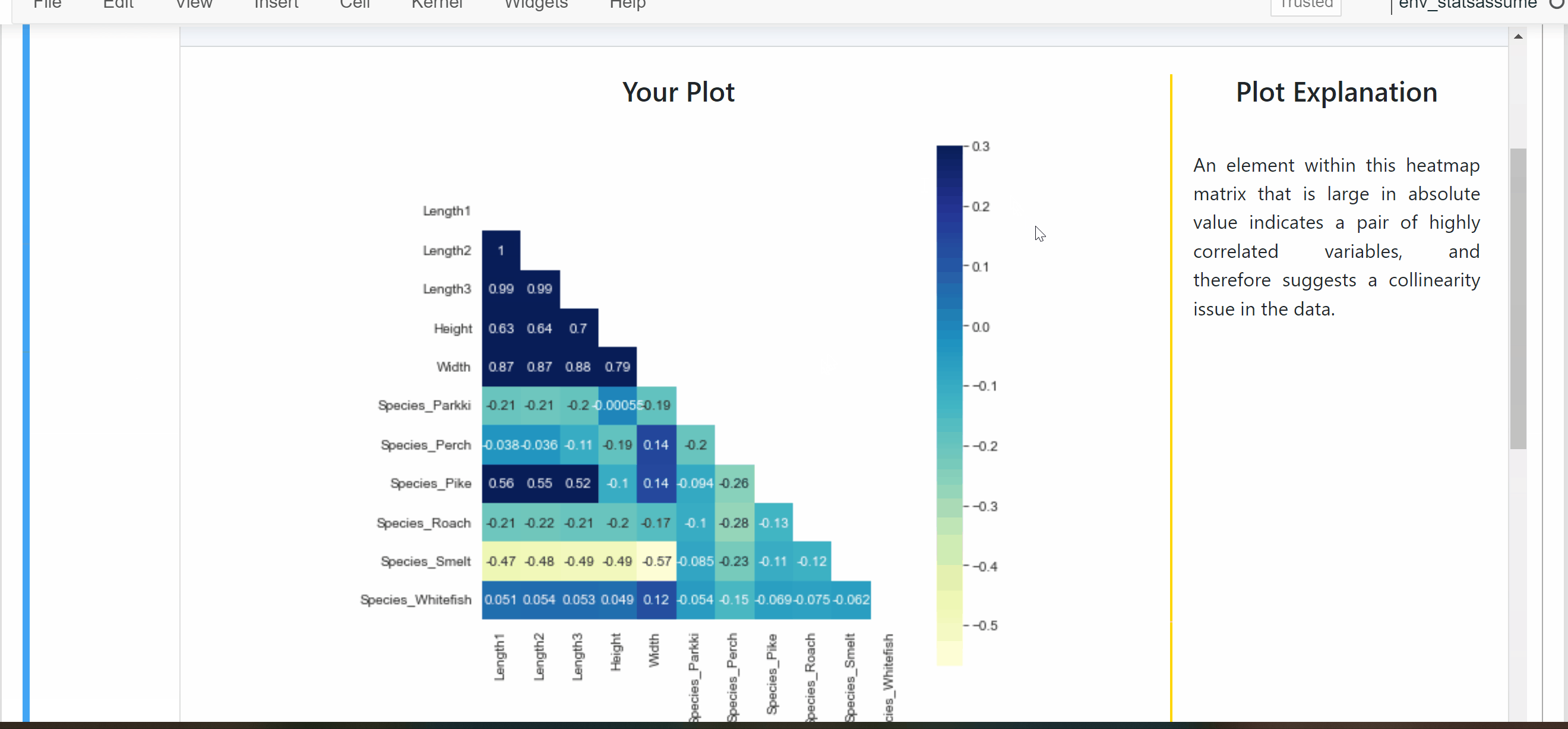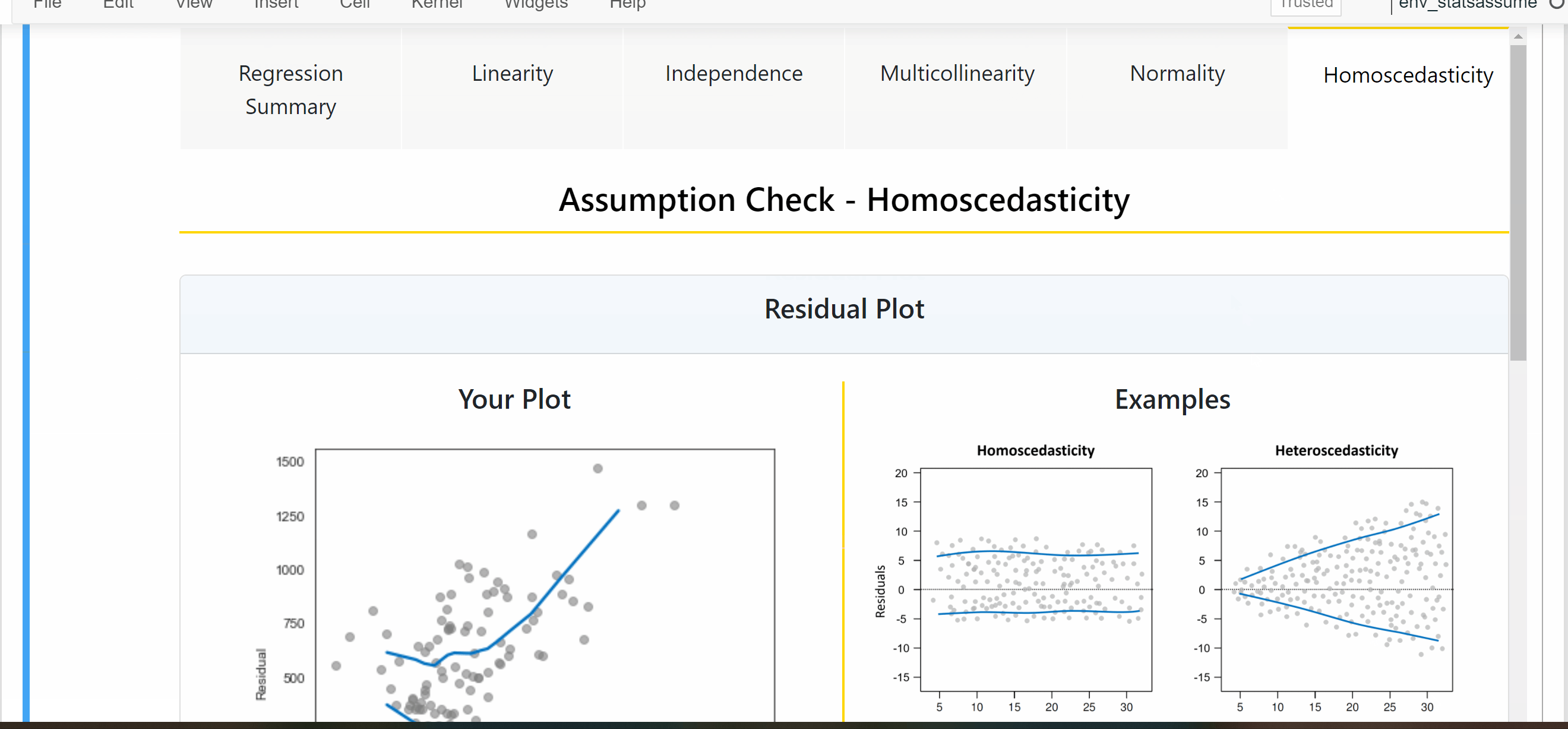
Automatically executes statistical tests and visual plots of assumption checks relevant to the regression task.
-
Generates clear visual output of results in a beautiful dashboard (built on Jupyter-Dash).
-
Displays insightful information on assumption concepts and possible fixes for assumption violations.
-
Able to automatically encode categorical variables to create dataset suitable for regression modelling (unless specified otherwise).
pip install statsassumefrom statsassume import Check
from statsassume.datasets import load_data
df = load_data('Fish_processed') # Get toy dataset (pre-processed)
assume = Check(df, target='Weight') # Initiate Check class and define target variable
assume.report() # Run assumption checks and generate dashboard reportNOTE: Data should ideally be pre-processed before running StatsAssume assumption checks.
Toy datasets available in StatsAssume can be found HERE
- While pre-processing should ideally be performed prior, StatsAssume comes with automatic encoding of categorical variables so that we can quickly commence model runs and assumption checks
- Here's how to put the
Checkclass (core object of StatsAssume) to its best use:
df = load_data('Fish') # Get toy dataset (raw)
assume = Check(df=df,
target='Weight',
task='linear regression',
predictors=['Height', 'Width', 'Length1', 'Species'],
keep=True,
categorical_features=['Species'],
categorical_encoder='ohe',
mode='inline')-
df: pd.DataFrame
Dataset (in pandas DataFrame format) -
target: str
Column name of target (dependent) variable -
task: str
Type of regression task to be performed. Options include: 'linear regression'(More tasks to come soon). If None specified, task will be automatically determined based ontargetvariable. -
predictors: list
List of column names of predictor (independent) features. If None specified, all columns other thantargetwill be regarded as predictors -
keep: bool
If True, variables inpredictorslist will be kept as predictor variables, and other non-target variables will be dropped. If False, variables inpredictorslist will be dropped, and other non-target variables will be retained. Default is True. -
categorical_features: list
List of column names deemed categorical, so that appropriate encoding can be performed. If None specified, the categorical variables will be automatically detected and encoded into numerical format for regression modelling. Default is None. -
categorical_encoding: str
Type of encoding technique to be performed on categorical variables. Options include: ohe (i.e. one-hot encoding) and ord (i.e. ordinal encoding). Default is ohe. -
mode: str
Type of display for dashboard report. Options include inline (displayed as output directly in Jupyter notebook), external (displayed in a new full-screen browser tab), or jupyterlab (displayed in separate tab right inside JupyterLab). Default is inline.
- Only
dfandtargetattributes are compulsory
- Tedious to perform assumption checks manually
- Lack of rigour and consistency in references and notebooks online
- Have a look at the existing Issues and Pull Requests that you would like to help with.
- Clone repo and create a new branch:
$ git checkout https://github.com/kennethleungty/statsassume -b name_of_new_branch. - Make changes and test
- Submit Pull Request with comprehensive description of changes
If you would like to request a feature or report a bug, please create a GitHub Issue.
- Assumption checks for Logistic Regression (meanwhile, take a look at this article on logistic regression assumptions)