Koby Bibas, Yaniv Fogel and Meir Feder
https://arxiv.org/abs/1905.04708
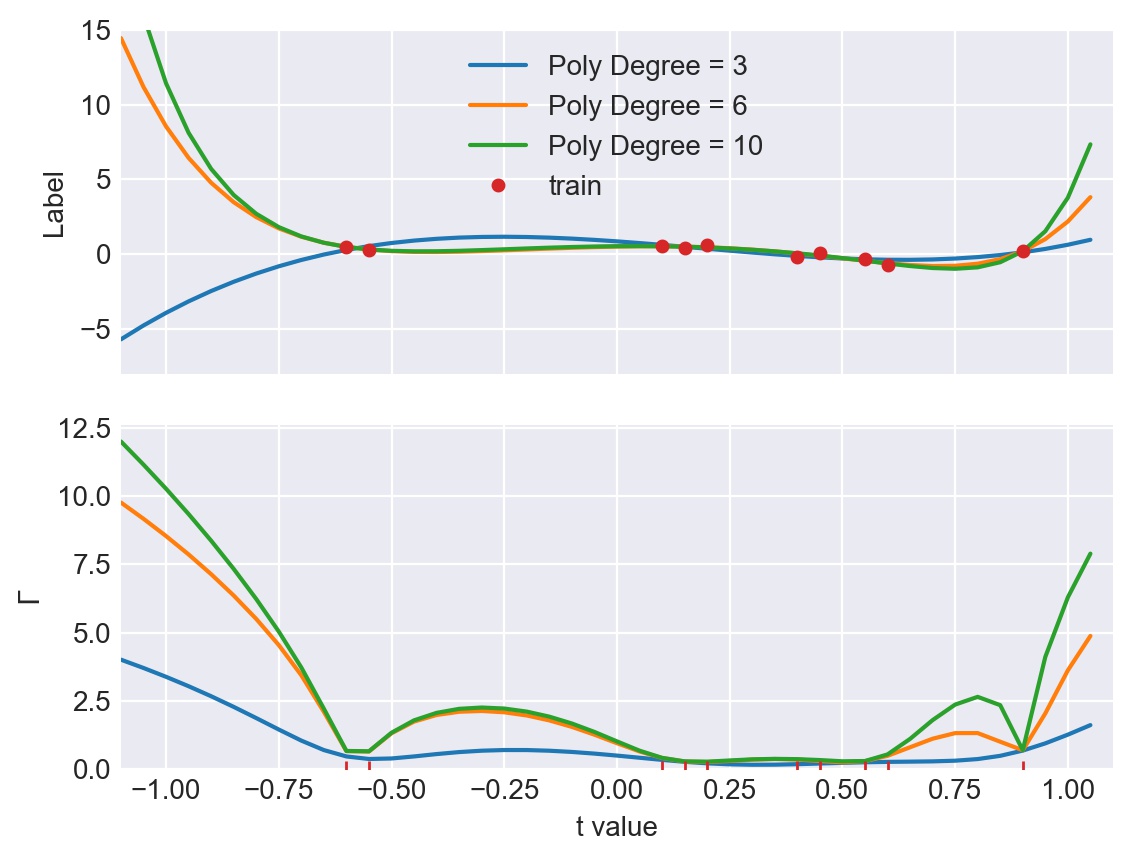
Linear regression is a classical paradigm in statistics. A new look at it is provided via the lens of universal learning. In applying universal learning to linear regression the hypotheses class represents the label y as a linear combination of the feature vector x^Tθ, within a Gaussian error. The Predictive Normalized Maximum Likelihood (pNML) solution for universal learning of individual data can be expressed analytically in this case, as well as its associated learnability measure. Interestingly, the situation where the number of parameters M may even be larger than the number of training samples N can be examined. As expected, in this case learnability cannot be attained in every situation; nevertheless, if the test vector resides mostly in a subspace spanned by the eigenvectors associated with the large eigenvalues of the empirical correlation matrix of the training data, linear regression can generalize despite the fact that it uses an over-parametrized model. We demonstrate the results with a simulation of fitting a polynomial to data with a possibly large polynomial degree.
Install requirement
# Add channels. Last added is with the highest priorety
conda config --add channels pytorch
conda config --add channels conda-forge
conda config --add channels anaconda
# Install pip for fallback
conda install --yes pip
# Install with conda. If package installation fails, install with pip.
while read requirement; do conda install --yes $requirement || pip install $requirement; done < requirements.txt Execute experiment:
cd src
python main_synthetic_data.py --config-name pnml_polynomial model_degree=4; \
python main_synthetic_data.py --config-name pnml_polynomial model_degree=6; \
python main_synthetic_data.py --config-name pnml_polynomial model_degree=7; Visualize:
cd notebook
jupyter-notebook pnml_syntetic.ipynbExecute experiment:
cd src
python main_synthetic_data.py --config-name pnml_fourier model_degree=3; \
python main_synthetic_data.py --config-name pnml_fourier model_degree=6; \
python main_synthetic_data.py --config-name pnml_fourier model_degree=8; \
python main_synthetic_data.py --config-name pnml_fourier model_degree=10; \
python main_synthetic_data.py --config-name pnml_fourier model_degree=20; \
python main_synthetic_data.py --config-name pnml_fourier model_degree=50; Visualize:
cd notebook
jupyter-notebook pnml_syntetic.ipynbThe data is taken from: https://github.com/yaringal/DropoutUncertaintyExps/tree/master/UCI_Datasets
Put it under ./data folder such that the project stracture is as follows
.
├── README.md
├── configs
├── data
│ └── UCI_Datasets
│ ├── bostonHousing
│ ├── concrete
│ ├── energy
│ ├── kin8nm
│ ├── naval-propulsion-plant
│ ├── power-plant
│ ├── protein-tertiary-structure
│ ├── wine-quality-red
│ └── yacht
├── notebooks
├── output
├── requirements.txt
└── src
Then, execute the experimnet:
cd src
python main_real_data.py --config-name real_data dataset_name=bostonHousing; \
python main_real_data.py --config-name real_data dataset_name=concrete; \
python main_real_data.py --config-name real_data dataset_name=energy; \
python main_real_data.py --config-name real_data dataset_name=kin8nm; \
python main_real_data.py --config-name real_data dataset_name=naval-propulsion-plant; \
python main_real_data.py --config-name real_data dataset_name=power-plant; \
python main_real_data.py --config-name real_data dataset_name=protein-tertiary-structure; \
python main_real_data.py --config-name real_data dataset_name=wine-quality-red; \
python main_real_data.py --config-name real_data dataset_name=yacht; Visualize:
cd notebook
jupyter-notebook real_data.ipynb@inproceedings{bibas2019new,
title={A new look at an old problem: A universal learning approach to linear regression},
author={Bibas, Koby and Fogel, Yaniv and Feder, Meir},
booktitle={2019 IEEE International Symposium on Information Theory (ISIT)},
pages={2304--2308},
year={2019},
organization={IEEE}
}