- WARNING: currently NOT compatible with
keras 3.x, if usingtensorflow>=2.16.0, needs to installpip install tf-keras~=$(pip show tensorflow | awk -F ': ' '/Version/{print $2}')manually. While importing, import this package ahead of Tensorflow, or setexport TF_USE_LEGACY_KERAS=1. - It's not recommended downloading and loading model from h5 file directly, better building model and loading weights like
import kecam; mm = kecam.models.LCNet050(). - coco_train_script.py for TF is still under testing...
- >>>> Roadmap and todo list <<<<
- General Usage
- Recognition Models
- AotNet
- BEiT
- BEiTV2
- BotNet
- CAFormer
- CMT
- CoaT
- CoAtNet
- ConvNeXt
- ConvNeXtV2
- CoTNet
- CSPNeXt
- DaViT
- DiNAT
- DINOv2
- EdgeNeXt
- EfficientFormer
- EfficientFormerV2
- EfficientNet
- EfficientNetEdgeTPU
- EfficientNetV2
- EfficientViT_B
- EfficientViT_M
- EVA
- EVA02
- FasterNet
- FasterViT
- FastViT
- FBNetV3
- FlexiViT
- GCViT
- GhostNet
- GhostNetV2
- GMLP
- GPViT
- HaloNet
- Hiera
- HorNet
- IFormer
- InceptionNeXt
- LCNet
- LeViT
- MaxViT
- MetaTransFormer
- MLP mixer
- MobileNetV3
- MobileViT
- MobileViT_V2
- MogaNet
- NAT
- NFNets
- PVT_V2
- RegNetY
- RegNetZ
- RepViT
- ResMLP
- ResNeSt
- ResNetD
- ResNetQ
- ResNeXt
- SwinTransformerV2
- TinyNet
- TinyViT
- UniFormer
- VanillaNet
- VOLO
- WaveMLP
- Detection Models
- Language Models
- Stable Diffusion
- Segmentation Models
- Licenses
- Citing
- Default import will not specific these while using them in READMEs.
import os import sys import tensorflow as tf import numpy as np import pandas as pd import matplotlib.pyplot as plt from tensorflow import keras
- Install as pip package.
kecamis a short alias name of this package. Note: the pip packagekecamdoesn't set any backend requirement, make sure either Tensorflow or PyTorch installed before hand. For PyTorch backend usage, refer Keras PyTorch Backend.Refer to each sub directory for detail usage.pip install -U kecam # Or pip install -U keras-cv-attention-models # Or pip install -U git+https://github.com/leondgarse/keras_cv_attention_models
- Basic model prediction
Or just use model preset
from keras_cv_attention_models import volo mm = volo.VOLO_d1(pretrained="imagenet") """ Run predict """ import tensorflow as tf from tensorflow import keras from keras_cv_attention_models.test_images import cat img = cat() imm = keras.applications.imagenet_utils.preprocess_input(img, mode='torch') pred = mm(tf.expand_dims(tf.image.resize(imm, mm.input_shape[1:3]), 0)).numpy() pred = tf.nn.softmax(pred).numpy() # If classifier activation is not softmax print(keras.applications.imagenet_utils.decode_predictions(pred)[0]) # [('n02124075', 'Egyptian_cat', 0.99664897), # ('n02123045', 'tabby', 0.0007249644), # ('n02123159', 'tiger_cat', 0.00020345), # ('n02127052', 'lynx', 5.4973923e-05), # ('n02123597', 'Siamese_cat', 2.675306e-05)]
preprocess_inputanddecode_predictionsThe presetfrom keras_cv_attention_models import coatnet mm = coatnet.CoAtNet0() from keras_cv_attention_models.test_images import cat preds = mm(mm.preprocess_input(cat())) print(mm.decode_predictions(preds)) # [[('n02124075', 'Egyptian_cat', 0.9999875), ('n02123045', 'tabby', 5.194884e-06), ...]]
preprocess_inputanddecode_predictionsalso compatible with PyTorch backend.os.environ['KECAM_BACKEND'] = 'torch' from keras_cv_attention_models import caformer mm = caformer.CAFormerS18() # >>>> Using PyTorch backend # >>>> Aligned input_shape: [3, 224, 224] # >>>> Load pretrained from: ~/.keras/models/caformer_s18_224_imagenet.h5 from keras_cv_attention_models.test_images import cat preds = mm(mm.preprocess_input(cat())) print(preds.shape) # torch.Size([1, 1000]) print(mm.decode_predictions(preds)) # [[('n02124075', 'Egyptian_cat', 0.8817097), ('n02123045', 'tabby', 0.009335292), ...]]
num_classes=0set for excluding model topGlobalAveragePooling2D + Denselayers.from keras_cv_attention_models import resnest mm = resnest.ResNest50(num_classes=0) print(mm.output_shape) # (None, 7, 7, 2048)
num_classes={custom output classes}others than1000or0will just skip loading the header Dense layer weights. Asmodel.load_weights(weight_file, by_name=True, skip_mismatch=True)is used for loading weights.from keras_cv_attention_models import swin_transformer_v2 mm = swin_transformer_v2.SwinTransformerV2Tiny_window8(num_classes=64) # >>>> Load pretrained from: ~/.keras/models/swin_transformer_v2_tiny_window8_256_imagenet.h5 # WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/kernel:0. Weight expects shape (768, 64). Received saved weight with shape (768, 1000) # WARNING:tensorflow:Skipping loading weights for layer #601 (named predictions) due to mismatch in shape for weight predictions/bias:0. Weight expects shape (64,). Received saved weight with shape (1000,)
- Reload own model weights by set
pretrained="xxx.h5". Better than callingmodel.load_weightsdirectly, if reloading model with differentinput_shapeand with weights shape not matching.import os from keras_cv_attention_models import coatnet pretrained = os.path.expanduser('~/.keras/models/coatnet0_224_imagenet.h5') mm = coatnet.CoAtNet1(input_shape=(384, 384, 3), pretrained=pretrained) # No sense, just showing usage
- Alias name
kecamcan be used instead ofkeras_cv_attention_models. It's__init__.pyonly withfrom keras_cv_attention_models import *.import kecam mm = kecam.yolor.YOLOR_CSP() imm = kecam.test_images.dog_cat() preds = mm(mm.preprocess_input(imm)) bboxs, lables, confidences = mm.decode_predictions(preds)[0] kecam.coco.show_image_with_bboxes(imm, bboxs, lables, confidences)
- Calculate flops method from TF 2.0 Feature: Flops calculation #32809. For PyTorch backend, needs
thoppip install thop.from keras_cv_attention_models import coatnet, resnest, model_surgery model_surgery.get_flops(coatnet.CoAtNet0()) # >>>> FLOPs: 4,221,908,559, GFLOPs: 4.2219G model_surgery.get_flops(resnest.ResNest50()) # >>>> FLOPs: 5,378,399,992, GFLOPs: 5.3784G
- [Deprecated]
tensorflow_addonsis not imported by default. While reloading model depending onGroupNormalizationlikeMobileViTV2fromh5directly, needs to importtensorflow_addonsmanually first.import tensorflow_addons as tfa model_path = os.path.expanduser('~/.keras/models/mobilevit_v2_050_256_imagenet.h5') mm = keras.models.load_model(model_path)
- Export TF model to onnx. Needs
tf2onnxfor TF,pip install onnx tf2onnx onnxsim onnxruntime. For using PyTorch backend, exporting onnx is supported by PyTorch.from keras_cv_attention_models import volo, nat, model_surgery mm = nat.DiNAT_Small(pretrained=True) model_surgery.export_onnx(mm, fuse_conv_bn=True, batch_size=1, simplify=True) # Exported simplified onnx: dinat_small.onnx # Run test from keras_cv_attention_models.imagenet import eval_func aa = eval_func.ONNXModelInterf(mm.name + '.onnx') inputs = np.random.uniform(size=[1, *mm.input_shape[1:]]).astype('float32') print(f"{np.allclose(aa(inputs), mm(inputs), atol=1e-5) = }") # np.allclose(aa(inputs), mm(inputs), atol=1e-5) = True
- Model summary
model_summary.csvcontains gathered model info.paramsfor model params count inMflopsfor FLOPs inGinputfor model input shapeacc_metricsmeansImagenet Top1 Accuracyfor recognition models,COCO val APfor detection modelsinference_qpsforT4 inference query per secondwithbatch_size=1 + trtexecextrameans if any extra training info.
from keras_cv_attention_models import plot_func plot_series = [ "efficientnetv2", 'tinynet', 'lcnet', 'mobilenetv3', 'fasternet', 'fastervit', 'ghostnet', 'inceptionnext', 'efficientvit_b', 'mobilevit', 'convnextv2', 'efficientvit_m', 'hiera', ] plot_func.plot_model_summary( plot_series, model_table="model_summary.csv", log_scale_x=True, allow_extras=['mae_in1k_ft1k'] )

- Code format is using
line-length=160:find ./* -name "*.py" | grep -v __init__ | xargs -I {} black -l 160 {}
- T4 Inference in the model tables are tested using
trtexeconTesla T4withCUDA=12.0.1-1, Driver=525.60.13. All models are exported as ONNX using PyTorch backend, usingbatch_szie=1only. Note: this data is for reference only, and vary in different batch sizes or benchmark tools or platforms or implementations. - All results are tested using colab trtexec.ipynb. Thus reproducible by any others.
os.environ["KECAM_BACKEND"] = "torch"
from keras_cv_attention_models import convnext, test_images, imagenet
# >>>> Using PyTorch backend
mm = convnext.ConvNeXtTiny()
mm.export_onnx(simplify=True)
# Exported onnx: convnext_tiny.onnx
# Running onnxsim.simplify...
# Exported simplified onnx: convnext_tiny.onnx
# Onnx run test
tt = imagenet.eval_func.ONNXModelInterf('convnext_tiny.onnx')
print(mm.decode_predictions(tt(mm.preprocess_input(test_images.cat()))))
# [[('n02124075', 'Egyptian_cat', 0.880507), ('n02123045', 'tabby', 0.0047998047), ...]]
""" Run trtexec benchmark """
!trtexec --onnx=convnext_tiny.onnx --fp16 --allowGPUFallback --useSpinWait --useCudaGraph- attention_layers is
__init__.pyonly, which imports core layers defined in model architectures. LikeRelativePositionalEmbeddingfrombotnet,outlook_attentionfromvolo, and many otherPositional Embedding Layers/Attention Blocks.
from keras_cv_attention_models import attention_layers
aa = attention_layers.RelativePositionalEmbedding()
print(f"{aa(tf.ones([1, 4, 14, 16, 256])).shape = }")
# aa(tf.ones([1, 4, 14, 16, 256])).shape = TensorShape([1, 4, 14, 16, 14, 16])- model_surgery including functions used to change model parameters after built.
from keras_cv_attention_models import model_surgery
mm = keras.applications.ResNet50() # Trainable params: 25,583,592
# Replace all ReLU with PReLU. Trainable params: 25,606,312
mm = model_surgery.replace_ReLU(mm, target_activation='PReLU')
# Fuse conv and batch_norm layers. Trainable params: 25,553,192
mm = model_surgery.convert_to_fused_conv_bn_model(mm)- ImageNet contains more detail usage and some comparing results.
- Init Imagenet dataset using tensorflow_datasets #9.
- For custom dataset,
custom_dataset_script.pycan be used creating ajsonformat file, which can be used as--data_name xxx.jsonfor training, detail usage can be found in Custom recognition dataset. - Another method creating custom dataset is using
tfds.load, refer Writing custom datasets and Creating private tensorflow_datasets from tfds #48 by @Medicmind. - Running an AWS Sagemaker estimator job using
keras_cv_attention_modelscan be found in AWS Sagemaker script example by @Medicmind. aotnet.AotNet50default parameters set is a typicalResNet50architecture withConv2D use_bias=FalseandpaddinglikePyTorch.- Default parameters for
train_script.pyis likeA3configuration from ResNet strikes back: An improved training procedure in timm withbatch_size=256, input_shape=(160, 160).# `antialias` is default enabled for resize, can be turned off be set `--disable_antialias`. CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 train_script.py --seed 0 -s aotnet50
# Evaluation using input_shape (224, 224). # `antialias` usage should be same with training. CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m aotnet50_epoch_103_val_acc_0.7674.h5 -i 224 --central_crop 0.95 # >>>> Accuracy top1: 0.78466 top5: 0.94088
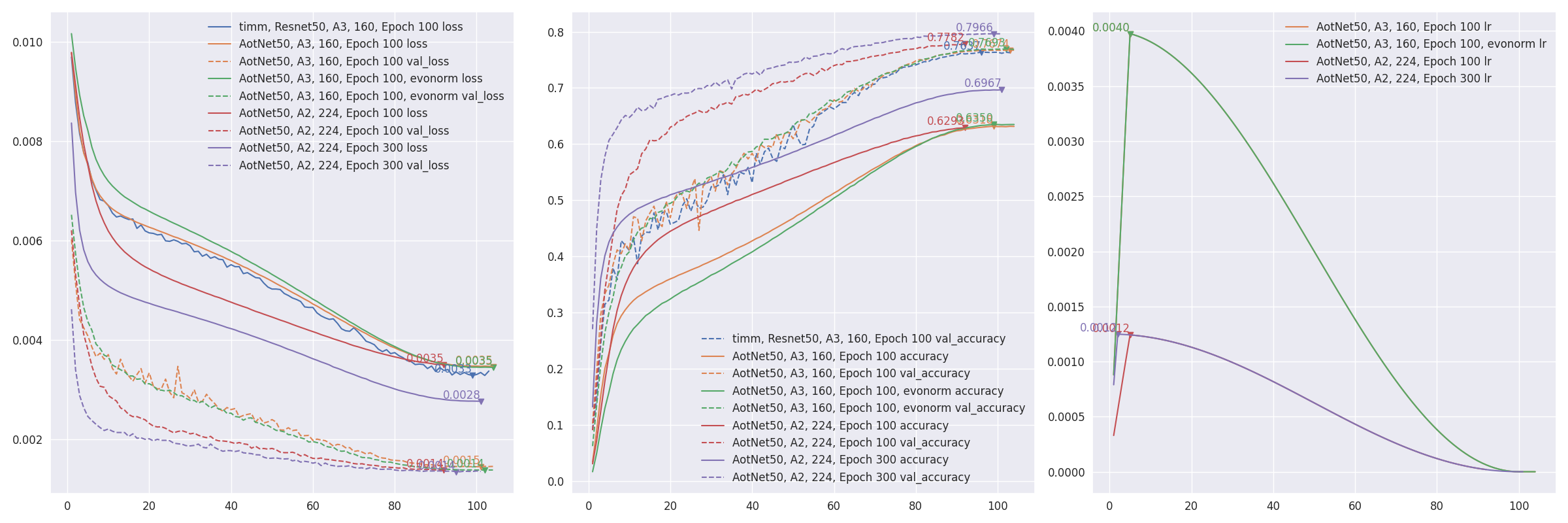
- Restore from break point by setting
--restore_pathand--initial_epoch, and keep other parameters same.restore_pathis higher priority thanmodelandadditional_model_kwargs, also restoreoptimizerandloss.initial_epochis mainly for learning rate scheduler. If not sure where it stopped, checkcheckpoints/{save_name}_hist.json.import json with open("checkpoints/aotnet50_hist.json", "r") as ff: aa = json.load(ff) len(aa['lr']) # 41 ==> 41 epochs are finished, initial_epoch is 41 then, restart from epoch 42
CUDA_VISIBLE_DEVICES='0' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 train_script.py --seed 0 -r checkpoints/aotnet50_latest.h5 -I 41 # >>>> Restore model from: checkpoints/aotnet50_latest.h5 # Epoch 42/105
eval_script.pyis used for evaluating model accuracy. EfficientNetV2 self tested imagenet accuracy #19 just showing how different parameters affecting model accuracy.# evaluating pretrained builtin model CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m regnet.RegNetZD8 # evaluating pretrained timm model CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m timm.models.resmlp_12_224 --input_shape 224 # evaluating specific h5 model CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m checkpoints/xxx.h5 # evaluating specific tflite model CUDA_VISIBLE_DEVICES='1' python3 eval_script.py -m xxx.tflite
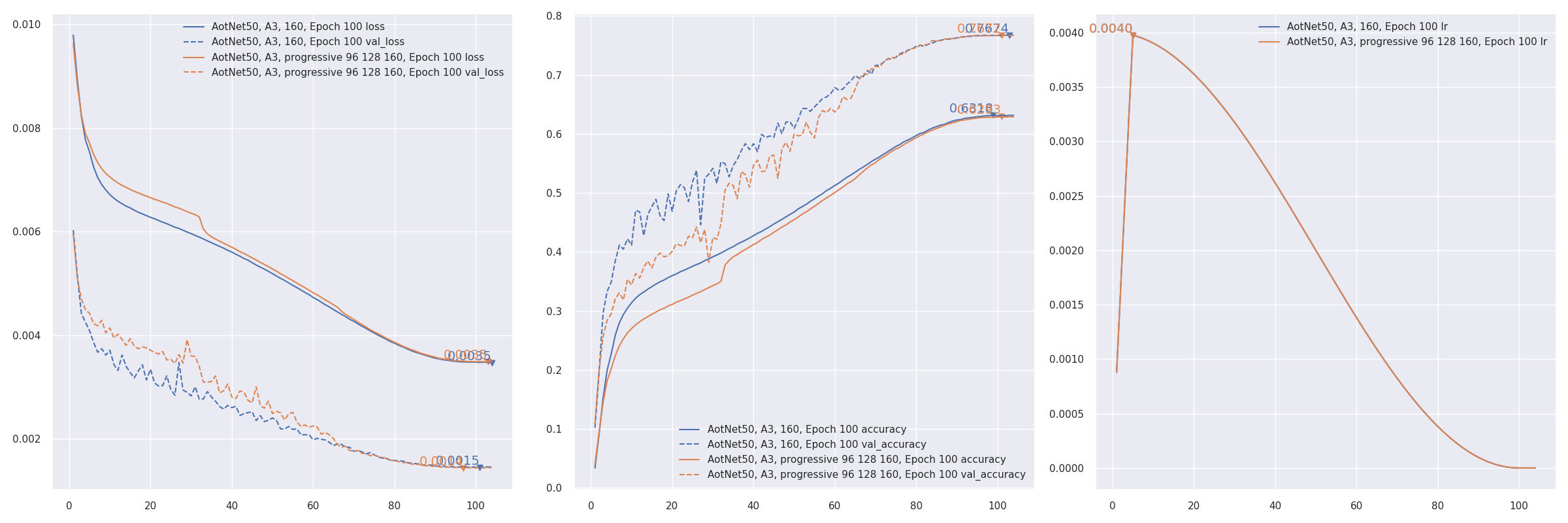
- Progressive training refer to PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training. AotNet50 A3 progressive input shapes
96 128 160:CUDA_VISIBLE_DEVICES='1' TF_XLA_FLAGS="--tf_xla_auto_jit=2" python3 progressive_train_script.py \ --progressive_epochs 33 66 -1 \ --progressive_input_shapes 96 128 160 \ --progressive_magnitudes 2 4 6 \ -s aotnet50_progressive_3_lr_steps_100 --seed 0
- Transfer learning with
freeze_backboneorfreeze_norm_layers: EfficientNetV2B0 transfer learning on cifar10 testing freezing backbone #55. - Token label train test on CIFAR10 #57. Currently not working as well as expected.
Token labelis implementation of Github zihangJiang/TokenLabeling, paper PDF 2104.10858 All Tokens Matter: Token Labeling for Training Better Vision Transformers.
-
Currently still under testing.
-
COCO contains more detail usage.
-
custom_dataset_script.pycan be used creating ajsonformat file, which can be used as--data_name xxx.jsonfor training, detail usage can be found in Custom detection dataset. -
Default parameters for
coco_train_script.pyisEfficientDetD0withinput_shape=(256, 256, 3), batch_size=64, mosaic_mix_prob=0.5, freeze_backbone_epochs=32, total_epochs=105. Technically, it's anypyramid structure backbone+EfficientDet / YOLOX header / YOLOR header+anchor_free / yolor / efficientdet anchorscombination supported. -
Currently 4 types anchors supported, parameter
anchors_modecontrols which anchor to use, value in["efficientdet", "anchor_free", "yolor", "yolov8"]. DefaultNonefordet_headerpresets. -
NOTE:
YOLOV8has a defaultregression_len=64for bbox output length. Typically it's4for other detection models, for yolov8 it'sreg_max=16 -> regression_len = 16 * 4 == 64.anchors_mode use_object_scores num_anchors anchor_scale aspect_ratios num_scales grid_zero_start efficientdet False 9 4 [1, 2, 0.5] 3 False anchor_free True 1 1 [1] 1 True yolor True 3 None presets None offset=0.5 yolov8 False 1 1 [1] 1 False # Default EfficientDetD0 CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py # Default EfficientDetD0 using input_shape 512, optimizer adamw, freezing backbone 16 epochs, total 50 + 5 epochs CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py -i 512 -p adamw --freeze_backbone_epochs 16 --lr_decay_steps 50 # EfficientNetV2B0 backbone + EfficientDetD0 detection header CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone efficientnet.EfficientNetV2B0 --det_header efficientdet.EfficientDetD0 # ResNest50 backbone + EfficientDetD0 header using yolox like anchor_free anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone resnest.ResNest50 --anchors_mode anchor_free # UniformerSmall32 backbone + EfficientDetD0 header using yolor anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone uniformer.UniformerSmall32 --anchors_mode yolor # Typical YOLOXS with anchor_free anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolox.YOLOXS --freeze_backbone_epochs 0 # YOLOXS with efficientdet anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolox.YOLOXS --anchors_mode efficientdet --freeze_backbone_epochs 0 # CoAtNet0 backbone + YOLOX header with yolor anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone coatnet.CoAtNet0 --det_header yolox.YOLOX --anchors_mode yolor # Typical YOLOR_P6 with yolor anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolor.YOLOR_P6 --freeze_backbone_epochs 0 # YOLOR_P6 with anchor_free anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --det_header yolor.YOLOR_P6 --anchors_mode anchor_free --freeze_backbone_epochs 0 # ConvNeXtTiny backbone + YOLOR header with efficientdet anchors CUDA_VISIBLE_DEVICES='0' python3 coco_train_script.py --backbone convnext.ConvNeXtTiny --det_header yolor.YOLOR --anchors_mode yolor
Note: COCO training still under testing, may change parameters and default behaviors. Take the risk if would like help developing.
-
coco_eval_script.pyis used for evaluating model AP / AR on COCO validation set. It has a dependencypip install pycocotoolswhich is not in package requirements. More usage can be found in COCO Evaluation.# EfficientDetD0 using resize method bilinear w/o antialias CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m efficientdet.EfficientDetD0 --resize_method bilinear --disable_antialias # >>>> [COCOEvalCallback] input_shape: (512, 512), pyramid_levels: [3, 7], anchors_mode: efficientdet # YOLOX using BGR input format CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m yolox.YOLOXTiny --use_bgr_input --nms_method hard --nms_iou_or_sigma 0.65 # >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: anchor_free # YOLOR / YOLOV7 using letterbox_pad and other tricks. CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m yolor.YOLOR_CSP --nms_method hard --nms_iou_or_sigma 0.65 \ --nms_max_output_size 300 --nms_topk -1 --letterbox_pad 64 --input_shape 704 # >>>> [COCOEvalCallback] input_shape: (704, 704), pyramid_levels: [3, 5], anchors_mode: yolor # Specify h5 model CUDA_VISIBLE_DEVICES='1' python3 coco_eval_script.py -m checkpoints/yoloxtiny_yolor_anchor.h5 # >>>> [COCOEvalCallback] input_shape: (416, 416), pyramid_levels: [3, 5], anchors_mode: yolor
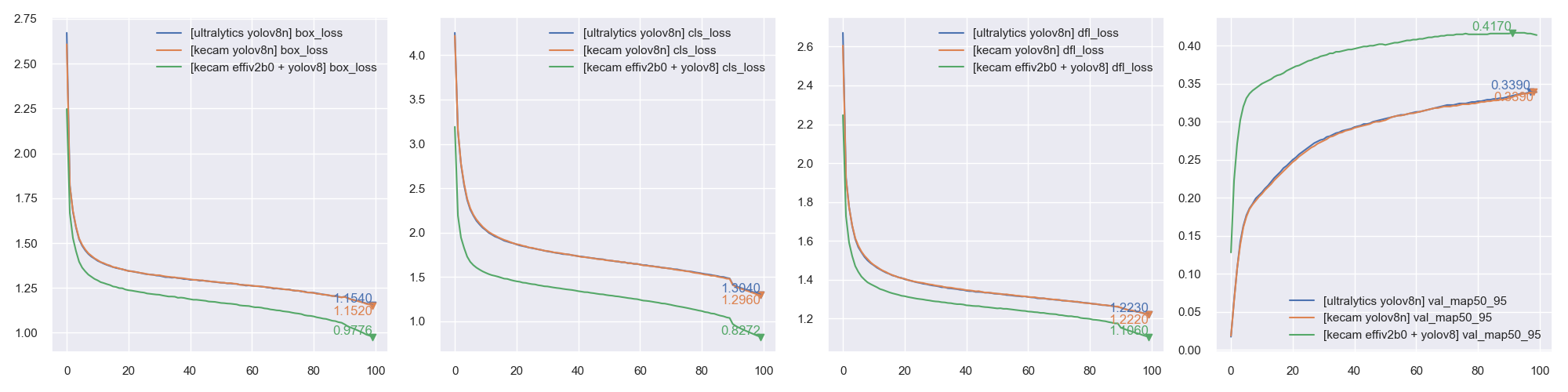
-
[Experimental] Training using PyTorch backend
import os, sys, torch os.environ["KECAM_BACKEND"] = "torch" from keras_cv_attention_models.yolov8 import train, yolov8 from keras_cv_attention_models import efficientnet global_device = torch.device("cuda:0") if torch.cuda.is_available() and int(os.environ.get("CUDA_VISIBLE_DEVICES", "0")) >= 0 else torch.device("cpu") # model Trainable params: 7,023,904, GFLOPs: 8.1815G bb = efficientnet.EfficientNetV2B0(input_shape=(3, 640, 640), num_classes=0) model = yolov8.YOLOV8_N(backbone=bb, classifier_activation=None, pretrained=None).to(global_device) # Note: classifier_activation=None # model = yolov8.YOLOV8_N(input_shape=(3, None, None), classifier_activation=None, pretrained=None).to(global_device) ema = train.train(model, dataset_path="coco.json", initial_epoch=0)
- CLIP contains more detail usage.
custom_dataset_script.pycan be used creating atsv/jsonformat file, which can be used as--data_name xxx.tsvfor training, detail usage can be found in Custom caption dataset.- Train using
clip_train_script.py on COCO captionsDefault--data_pathis a testing onedatasets/coco_dog_cat/captions.tsv.Train Using PyTorch backend by settingCUDA_VISIBLE_DEVICES=1 TF_XLA_FLAGS="--tf_xla_auto_jit=2" python clip_train_script.py -i 160 -b 128 \ --text_model_pretrained None --data_path coco_captions.tsvKECAM_BACKEND='torch'KECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python clip_train_script.py -i 160 -b 128 \ --text_model_pretrained None --data_path coco_captions.tsv
- Currently it's only a simple one modified from Github karpathy/nanoGPT.
- Train using
text_train_script.pyAs dataset is randomly sampled, needs to specifysteps_per_epochTrain Using PyTorch backend by settingCUDA_VISIBLE_DEVICES=1 TF_XLA_FLAGS="--tf_xla_auto_jit=2" python text_train_script.py -m LLaMA2_15M \ --steps_per_epoch 8000 --batch_size 8 --tokenizer SentencePieceTokenizerKECAM_BACKEND='torch'PlottingKECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python text_train_script.py -m LLaMA2_15M \ --steps_per_epoch 8000 --batch_size 8 --tokenizer SentencePieceTokenizerfrom keras_cv_attention_models import plot_func hists = ['checkpoints/text_llama2_15m_tensorflow_hist.json', 'checkpoints/text_llama2_15m_torch_hist.json'] plot_func.plot_hists(hists, addition_plots=['val_loss', 'lr'], skip_first=3)

- Stable Diffusion contains more detail usage.
- Note: Works better with PyTorch backend, Tensorflow one seems overfitted if training logger like
--epochs 200, and evaluation runs ~5 times slower. [???] - Dataset can be a directory containing images for basic DDPM training using images only, or a recognition json file created following Custom recognition dataset, which will train using labels as instruction.
python custom_dataset_script.py --train_images cifar10/train/ --test_images cifar10/test/ # >>>> total_train_samples: 50000, total_test_samples: 10000, num_classes: 10 # >>>> Saved to: cifar10.json
- Train using
ddpm_train_script.py on cifar10 with labelsDefault--data_pathis builtincifar10.Train Using PyTorch backend by setting# Set --eval_interval 50 as TF evaluation is rather slow [???] TF_XLA_FLAGS="--tf_xla_auto_jit=2" CUDA_VISIBLE_DEVICES=1 python ddpm_train_script.py --eval_interval 50
KECAM_BACKEND='torch'KECAM_BACKEND='torch' CUDA_VISIBLE_DEVICES=1 python ddpm_train_script.py

- Visualizing is for visualizing convnet filters or attention map scores.
- make_and_apply_gradcam_heatmap is for Grad-CAM class activation visualization.
from keras_cv_attention_models import visualizing, test_images, resnest mm = resnest.ResNest50() img = test_images.dog() superimposed_img, heatmap, preds = visualizing.make_and_apply_gradcam_heatmap(mm, img, layer_name="auto")

- plot_attention_score_maps is model attention score maps visualization.
from keras_cv_attention_models import visualizing, test_images, botnet img = test_images.dog() _ = visualizing.plot_attention_score_maps(botnet.BotNetSE33T(), img)

- Currently
TFLitenot supportingtf.image.extract_patches/tf.transpose with len(perm) > 4. Some operations could be supported in latest ortf-nightlyversion, like previously not supportedgelu/Conv2D with groups>1are working now. May try if encountering issue. - More discussion can be found Converting a trained keras CV attention model to TFLite #17. Some speed testing results can be found How to speed up inference on a quantized model #44.
- Functions like
model_surgery.convert_groups_conv2d_2_split_conv2dandmodel_surgery.convert_gelu_to_approximateare not needed using up-to-date TF version. - Not supporting
VOLO/HaloNetmodels converting, cause they need a longertf.transposeperm. - model_surgery.convert_dense_to_conv converts all
Denselayer with 3D / 4D inputs toConv1D/Conv2D, as currently TFLite xnnpack not supporting it.from keras_cv_attention_models import beit, model_surgery, efficientformer, mobilevit mm = efficientformer.EfficientFormerL1() mm = model_surgery.convert_dense_to_conv(mm) # Convert all Dense layers converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert())
Model Dense, use_xnnpack=false Conv, use_xnnpack=false Conv, use_xnnpack=true MobileViT_S Inference (avg) 215371 us Inference (avg) 163836 us Inference (avg) 163817 us EfficientFormerL1 Inference (avg) 126829 us Inference (avg) 107053 us Inference (avg) 107132 us - model_surgery.convert_extract_patches_to_conv converts
tf.image.extract_patchesto aConv2Dversion:from keras_cv_attention_models import cotnet, model_surgery from keras_cv_attention_models.imagenet import eval_func mm = cotnet.CotNetSE50D() mm = model_surgery.convert_groups_conv2d_2_split_conv2d(mm) # mm = model_surgery.convert_gelu_to_approximate(mm) # Not required if using up-to-date TFLite mm = model_surgery.convert_extract_patches_to_conv(mm) converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert()) test_inputs = np.random.uniform(size=[1, *mm.input_shape[1:]]) print(np.allclose(mm(test_inputs), eval_func.TFLiteModelInterf(mm.name + '.tflite')(test_inputs), atol=1e-7)) # True
- model_surgery.prepare_for_tflite is just a combination of above functions:
from keras_cv_attention_models import beit, model_surgery mm = beit.BeitBasePatch16() mm = model_surgery.prepare_for_tflite(mm) converter = tf.lite.TFLiteConverter.from_keras_model(mm) open(mm.name + ".tflite", "wb").write(converter.convert())
- Detection models including
efficinetdet/yolox/yolor, model can be converted a TFLite format directly. If need DecodePredictions also included in TFLite model, need to setuse_static_output=TrueforDecodePredictions, as TFLite requires a more static output shape. Model output shape will be fixed as[batch, max_output_size, 6]. The last dimension6means[bbox_top, bbox_left, bbox_bottom, bbox_right, label_index, confidence], and those valid ones are whereconfidence > 0.""" Init model """ from keras_cv_attention_models import efficientdet model = efficientdet.EfficientDetD0(pretrained="coco") """ Create a model with DecodePredictions using `use_static_output=True` """ model.decode_predictions.use_static_output = True # parameters like score_threshold / iou_or_sigma can be set another value if needed. nn = model.decode_predictions(model.outputs[0], score_threshold=0.5) bb = keras.models.Model(model.inputs[0], nn) """ Convert TFLite """ converter = tf.lite.TFLiteConverter.from_keras_model(bb) open(bb.name + ".tflite", "wb").write(converter.convert()) """ Inference test """ from keras_cv_attention_models.imagenet import eval_func from keras_cv_attention_models import test_images dd = eval_func.TFLiteModelInterf(bb.name + ".tflite") imm = test_images.cat() inputs = tf.expand_dims(tf.image.resize(imm, dd.input_shape[1:-1]), 0) inputs = keras.applications.imagenet_utils.preprocess_input(inputs, mode='torch') preds = dd(inputs)[0] print(f"{preds.shape = }") # preds.shape = (100, 6) pred = preds[preds[:, -1] > 0] bboxes, labels, confidences = pred[:, :4], pred[:, 4], pred[:, -1] print(f"{bboxes = }, {labels = }, {confidences = }") # bboxes = array([[0.22825494, 0.47238672, 0.816262 , 0.8700745 ]], dtype=float32), # labels = array([16.], dtype=float32), # confidences = array([0.8309707], dtype=float32) """ Show result """ from keras_cv_attention_models.coco import data data.show_image_with_bboxes(imm, bboxes, labels, confidences, num_classes=90)
- Experimental Keras PyTorch Backend.
- Set os environment
export KECAM_BACKEND='torch'to enable this PyTorch backend. - Currently supports most recognition and detection models except hornet*gf / nfnets / volo. For detection models, using
torchvision.ops.nmswhile running prediction. - Basic model build and prediction.
- Will load same
h5weights as TF one if available. - Note:
input_shapewill auto fit image data format. Giveninput_shape=(224, 224, 3)orinput_shape=(3, 224, 224), will both set to(3, 224, 224)ifchannels_first. - Note: model is default set to
evalmode.
os.environ['KECAM_BACKEND'] = 'torch' from keras_cv_attention_models import res_mlp mm = res_mlp.ResMLP12() # >>>> Load pretrained from: ~/.keras/models/resmlp12_imagenet.h5 print(f"{mm.input_shape = }") # mm.input_shape = [None, 3, 224, 224] import torch print(f"{isinstance(mm, torch.nn.Module) = }") # isinstance(mm, torch.nn.Module) = True # Run prediction from keras_cv_attention_models.test_images import cat print(mm.decode_predictions(mm(mm.preprocess_input(cat())))[0]) # [('n02124075', 'Egyptian_cat', 0.9597896), ('n02123045', 'tabby', 0.012809471), ...]
- Will load same
- Export typical PyTorch onnx / pth.
import torch torch.onnx.export(mm, torch.randn(1, 3, *mm.input_shape[2:]), mm.name + ".onnx") # Or by export_onnx mm.export_onnx() # Exported onnx: resmlp12.onnx mm.export_pth() # Exported pth: resmlp12.pth
- Save weights as h5. This
h5can also be loaded in typical TF backend model. Currently it's only weights without model structure supported.mm.save_weights("foo.h5")
- Training with compile and fit Note: loss function arguments should be
y_true, y_pred, while typical torch loss functions usingy_pred, y_true.import torch from keras_cv_attention_models.backend import models, layers mm = models.Sequential([layers.Input([3, 32, 32]), layers.Conv2D(32, 3), layers.GlobalAveragePooling2D(), layers.Dense(10)]) if torch.cuda.is_available(): _ = mm.to("cuda") xx = torch.rand([64, *mm.input_shape[1:]]) yy = torch.functional.F.one_hot(torch.randint(0, mm.output_shape[-1], size=[64]), mm.output_shape[-1]).float() loss = lambda y_true, y_pred: (y_true - y_pred.float()).abs().mean() # Will check kwargs for calling `self.train_compile` or `torch.nn.Module.compile` mm.compile(optimizer="AdamW", loss=loss, metrics='acc', grad_accumulate=4) mm.fit(xx, yy, epochs=2, batch_size=4)
- [Experimental] Set os environment
export KECAM_BACKEND='keras_core'to enable thiskeras_corebackend. Not usingkeras>3.0, as still not compiling with TensorFlow==2.15.0 keras-corehas its own backends, supporting tensorflow / torch / jax, by editting~/.keras/keras.json"backend"value.- Currently most recognition models except
HaloNet/BotNetsupported, alsoGPT2/LLaMA2supported. - Basic model build and prediction.
!pip install sentencepiece # required for llama2 tokenizer os.environ['KECAM_BACKEND'] = 'keras_core' os.environ['KERAS_BACKEND'] = 'jax' import kecam print(f"{kecam.backend.backend() = }") # kecam.backend.backend() = 'jax' mm = kecam.llama2.LLaMA2_42M() # >>>> Load pretrained from: ~/.keras/models/llama2_42m_tiny_stories.h5 mm.run_prediction('As evening fell, a maiden stood at the edge of a wood. In her hands,') # >>>> Load tokenizer from file: ~/.keras/datasets/llama_tokenizer.model # <s> # As evening fell, a maiden stood at the edge of a wood. In her hands, she held a beautiful diamond. Everyone was surprised to see it. # "What is it?" one of the kids asked. # "It's a diamond," the maiden said. # ...
- Keras AotNet is just a
ResNet/ResNetV2like framework, that set parameters likeattn_typesandse_ratioand others, which is used to apply different types attention layer. Works likebyoanet/byobnetfromtimm. - Default parameters set is a typical
ResNetarchitecture withConv2D use_bias=FalseandpaddinglikePyTorch.
from keras_cv_attention_models import aotnet
# Mixing se and outlook and halo and mhsa and cot_attention, 21M parameters.
# 50 is just a picked number that larger than the relative `num_block`.
attn_types = [None, "outlook", ["bot", "halo"] * 50, "cot"],
se_ratio = [0.25, 0, 0, 0],
model = aotnet.AotNet50V2(attn_types=attn_types, se_ratio=se_ratio, stem_type="deep", strides=1)
model.summary()- Keras BEiT includes models from PDF 2106.08254 BEiT: BERT Pre-Training of Image Transformers.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| BeitBasePatch16, 21k_ft1k | 86.53M | 17.61G | 224 | 85.240 | 321.226 qps |
| - 21k_ft1k, 384 | 86.74M | 55.70G | 384 | 86.808 | 164.705 qps |
| BeitLargePatch16, 21k_ft1k | 304.43M | 61.68G | 224 | 87.476 | 105.998 qps |
| - 21k_ft1k, 384 | 305.00M | 191.65G | 384 | 88.382 | 45.7307 qps |
| - 21k_ft1k, 512 | 305.67M | 363.46G | 512 | 88.584 | 21.3097 qps |
- Keras BEiT includes models from BeitV2 Paper PDF 2208.06366 BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| BeitV2BasePatch16 | 86.53M | 17.61G | 224 | 85.5 | 322.52 qps |
| - 21k_ft1k | 86.53M | 17.61G | 224 | 86.5 | 322.52 qps |
| BeitV2LargePatch16 | 304.43M | 61.68G | 224 | 87.3 | 105.734 qps |
| - 21k_ft1k | 304.43M | 61.68G | 224 | 88.4 | 105.734 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| BotNet50 | 21M | 5.42G | 224 | 746.454 qps | |
| BotNet101 | 41M | 9.13G | 224 | 448.102 qps | |
| BotNet152 | 56M | 12.84G | 224 | 316.671 qps | |
| BotNet26T | 12.5M | 3.30G | 256 | 79.246 | 1188.84 qps |
| BotNextECA26T | 10.59M | 2.45G | 256 | 79.270 | 1038.19 qps |
| BotNetSE33T | 13.7M | 3.89G | 256 | 81.2 | 610.429 qps |
- Keras CAFormer is for PDF 2210.13452 MetaFormer Baselines for Vision.
CAFormeris using 2 transformer stacks, whileConvFormeris all conv blocks.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CAFormerS18 | 26M | 4.1G | 224 | 83.6 | 399.127 qps |
| - 384 | 26M | 13.4G | 384 | 85.0 | 181.993 qps |
| - 21k_ft1k | 26M | 4.1G | 224 | 84.1 | 399.127 qps |
| - 21k_ft1k, 384 | 26M | 13.4G | 384 | 85.4 | 181.993 qps |
| CAFormerS36 | 39M | 8.0G | 224 | 84.5 | 204.328 qps |
| - 384 | 39M | 26.0G | 384 | 85.7 | 102.04 qps |
| - 21k_ft1k | 39M | 8.0G | 224 | 85.8 | 204.328 qps |
| - 21k_ft1k, 384 | 39M | 26.0G | 384 | 86.9 | 102.04 qps |
| CAFormerM36 | 56M | 13.2G | 224 | 85.2 | 162.257 qps |
| - 384 | 56M | 42.0G | 384 | 86.2 | 65.6188 qps |
| - 21k_ft1k | 56M | 13.2G | 224 | 86.6 | 162.257 qps |
| - 21k_ft1k, 384 | 56M | 42.0G | 384 | 87.5 | 65.6188 qps |
| CAFormerB36 | 99M | 23.2G | 224 | 85.5 | 116.865 qps |
| - 384 | 99M | 72.2G | 384 | 86.4 | 50.0244 qps |
| - 21k_ft1k | 99M | 23.2G | 224 | 87.4 | 116.865 qps |
| - 21k_ft1k, 384 | 99M | 72.2G | 384 | 88.1 | 50.0244 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ConvFormerS18 | 27M | 3.9G | 224 | 83.0 | 295.114 qps |
| - 384 | 27M | 11.6G | 384 | 84.4 | 145.923 qps |
| - 21k_ft1k | 27M | 3.9G | 224 | 83.7 | 295.114 qps |
| - 21k_ft1k, 384 | 27M | 11.6G | 384 | 85.0 | 145.923 qps |
| ConvFormerS36 | 40M | 7.6G | 224 | 84.1 | 161.609 qps |
| - 384 | 40M | 22.4G | 384 | 85.4 | 80.2101 qps |
| - 21k_ft1k | 40M | 7.6G | 224 | 85.4 | 161.609 qps |
| - 21k_ft1k, 384 | 40M | 22.4G | 384 | 86.4 | 80.2101 qps |
| ConvFormerM36 | 57M | 12.8G | 224 | 84.5 | 130.161 qps |
| - 384 | 57M | 37.7G | 384 | 85.6 | 63.9712 qps |
| - 21k_ft1k | 57M | 12.8G | 224 | 86.1 | 130.161 qps |
| - 21k_ft1k, 384 | 57M | 37.7G | 384 | 86.9 | 63.9712 qps |
| ConvFormerB36 | 100M | 22.6G | 224 | 84.8 | 98.0751 qps |
| - 384 | 100M | 66.5G | 384 | 85.7 | 48.5897 qps |
| - 21k_ft1k | 100M | 22.6G | 224 | 87.0 | 98.0751 qps |
| - 21k_ft1k, 384 | 100M | 66.5G | 384 | 87.6 | 48.5897 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CMTTiny, (Self trained 105 epochs) | 9.5M | 0.65G | 160 | 77.4 | 315.566 qps |
| - (305 epochs) | 9.5M | 0.65G | 160 | 78.94 | 315.566 qps |
| - 224, (fine-tuned 69 epochs) | 9.5M | 1.32G | 224 | 80.73 | 254.87 qps |
| CMTTiny_torch, (1000 epochs) | 9.5M | 0.65G | 160 | 79.2 | 338.207 qps |
| CMTXS_torch | 15.2M | 1.58G | 192 | 81.8 | 241.288 qps |
| CMTSmall_torch | 25.1M | 4.09G | 224 | 83.5 | 171.109 qps |
| CMTBase_torch | 45.7M | 9.42G | 256 | 84.5 | 103.34 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CoaTLiteTiny | 5.7M | 1.60G | 224 | 77.5 | 450.27 qps |
| CoaTLiteMini | 11M | 2.00G | 224 | 79.1 | 452.884 qps |
| CoaTLiteSmall | 20M | 3.97G | 224 | 81.9 | 248.846 qps |
| CoaTTiny | 5.5M | 4.33G | 224 | 78.3 | 152.495 qps |
| CoaTMini | 10M | 6.78G | 224 | 81.0 | 124.845 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CoAtNet0, 160, (105 epochs) | 23.3M | 2.09G | 160 | 80.48 | 584.059 qps |
| CoAtNet0, (305 epochs) | 23.8M | 4.22G | 224 | 82.79 | 400.333 qps |
| CoAtNet0 | 25M | 4.6G | 224 | 82.0 | 400.333 qps |
| - use_dw_strides=False | 25M | 4.2G | 224 | 81.6 | 461.197 qps |
| CoAtNet1 | 42M | 8.8G | 224 | 83.5 | 206.954 qps |
| - use_dw_strides=False | 42M | 8.4G | 224 | 83.3 | 228.938 qps |
| CoAtNet2 | 75M | 16.6G | 224 | 84.1 | 156.359 qps |
| - use_dw_strides=False | 75M | 15.7G | 224 | 84.1 | 165.846 qps |
| CoAtNet2, 21k_ft1k | 75M | 16.6G | 224 | 87.1 | 156.359 qps |
| CoAtNet3 | 168M | 34.7G | 224 | 84.5 | 95.0703 qps |
| CoAtNet3, 21k_ft1k | 168M | 34.7G | 224 | 87.6 | 95.0703 qps |
| CoAtNet3, 21k_ft1k | 168M | 203.1G | 512 | 87.9 | 95.0703 qps |
| CoAtNet4, 21k_ft1k | 275M | 360.9G | 512 | 88.1 | 74.6022 qps |
| CoAtNet4, 21k_ft1k, PT-RA-E150 | 275M | 360.9G | 512 | 88.56 | 74.6022 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ConvNeXtTiny | 28M | 4.49G | 224 | 82.1 | 361.58 qps |
| - 21k_ft1k | 28M | 4.49G | 224 | 82.9 | 361.58 qps |
| - 21k_ft1k, 384 | 28M | 13.19G | 384 | 84.1 | 182.134 qps |
| ConvNeXtSmall | 50M | 8.73G | 224 | 83.1 | 202.007 qps |
| - 21k_ft1k | 50M | 8.73G | 224 | 84.6 | 202.007 qps |
| - 21k_ft1k, 384 | 50M | 25.67G | 384 | 85.8 | 108.125 qps |
| ConvNeXtBase | 89M | 15.42G | 224 | 83.8 | 160.036 qps |
| - 384 | 89M | 45.32G | 384 | 85.1 | 83.3095 qps |
| - 21k_ft1k | 89M | 15.42G | 224 | 85.8 | 160.036 qps |
| - 21k_ft1k, 384 | 89M | 45.32G | 384 | 86.8 | 83.3095 qps |
| ConvNeXtLarge | 198M | 34.46G | 224 | 84.3 | 102.27 qps |
| - 384 | 198M | 101.28G | 384 | 85.5 | 47.2086 qps |
| - 21k_ft1k | 198M | 34.46G | 224 | 86.6 | 102.27 qps |
| - 21k_ft1k, 384 | 198M | 101.28G | 384 | 87.5 | 47.2086 qps |
| ConvNeXtXlarge, 21k_ft1k | 350M | 61.06G | 224 | 87.0 | 40.5776 qps |
| - 21k_ft1k, 384 | 350M | 179.43G | 384 | 87.8 | 21.797 qps |
| ConvNeXtXXLarge, clip | 846M | 198.09G | 256 | 88.6 |
- Keras ConvNeXt includes implementation of PDF 2301.00808 ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ConvNeXtV2Atto | 3.7M | 0.55G | 224 | 76.7 | 705.822 qps |
| ConvNeXtV2Femto | 5.2M | 0.78G | 224 | 78.5 | 728.02 qps |
| ConvNeXtV2Pico | 9.1M | 1.37G | 224 | 80.3 | 591.502 qps |
| ConvNeXtV2Nano | 15.6M | 2.45G | 224 | 81.9 | 471.918 qps |
| - 21k_ft1k | 15.6M | 2.45G | 224 | 82.1 | 471.918 qps |
| - 21k_ft1k, 384 | 15.6M | 7.21G | 384 | 83.4 | 213.802 qps |
| ConvNeXtV2Tiny | 28.6M | 4.47G | 224 | 83.0 | 301.982 qps |
| - 21k_ft1k | 28.6M | 4.47G | 224 | 83.9 | 301.982 qps |
| - 21k_ft1k, 384 | 28.6M | 13.1G | 384 | 85.1 | 139.578 qps |
| ConvNeXtV2Base | 89M | 15.4G | 224 | 84.9 | 132.575 qps |
| - 21k_ft1k | 89M | 15.4G | 224 | 86.8 | 132.575 qps |
| - 21k_ft1k, 384 | 89M | 45.2G | 384 | 87.7 | 66.5729 qps |
| ConvNeXtV2Large | 198M | 34.4G | 224 | 85.8 | 86.8846 qps |
| - 21k_ft1k | 198M | 34.4G | 224 | 87.3 | 86.8846 qps |
| - 21k_ft1k, 384 | 198M | 101.1G | 384 | 88.2 | 24.4542 qps |
| ConvNeXtV2Huge | 660M | 115G | 224 | 86.3 | |
| - 21k_ft1k | 660M | 337.9G | 384 | 88.7 | |
| - 21k_ft1k, 384 | 660M | 600.8G | 512 | 88.9 |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CotNet50 | 22.2M | 3.25G | 224 | 81.3 | 324.913 qps |
| CotNetSE50D | 23.1M | 4.05G | 224 | 81.6 | 513.077 qps |
| CotNet101 | 38.3M | 6.07G | 224 | 82.8 | 183.824 qps |
| CotNetSE101D | 40.9M | 8.44G | 224 | 83.2 | 251.487 qps |
| CotNetSE152D | 55.8M | 12.22G | 224 | 84.0 | 175.469 qps |
| CotNetSE152D | 55.8M | 24.92G | 320 | 84.6 | 175.469 qps |
- Keras CSPNeXt is for backbone of PDF 2212.07784 RTMDet: An Empirical Study of Designing Real-Time Object Detectors.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| CSPNeXtTiny | 2.73M | 0.34G | 224 | 69.44 | |
| CSPNeXtSmall | 4.89M | 0.66G | 224 | 74.41 | |
| CSPNeXtMedium | 13.05M | 1.92G | 224 | 79.27 | |
| CSPNeXtLarge | 27.16M | 4.19G | 224 | 81.30 | |
| CSPNeXtXLarge | 48.85M | 7.75G | 224 | 82.10 |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| DaViT_T | 28.36M | 4.56G | 224 | 82.8 | 224.563 qps |
| DaViT_S | 49.75M | 8.83G | 224 | 84.2 | 145.838 qps |
| DaViT_B | 87.95M | 15.55G | 224 | 84.6 | 114.527 qps |
| DaViT_L, 21k_ft1k | 196.8M | 103.2G | 384 | 87.5 | 34.7015 qps |
| DaViT_H, 1.5B | 348.9M | 327.3G | 512 | 90.2 | 12.363 qps |
| DaViT_G, 1.5B | 1.406B | 1.022T | 512 | 90.4 |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| DiNAT_Mini | 20.0M | 2.73G | 224 | 81.8 | 83.9943 qps |
| DiNAT_Tiny | 27.9M | 4.34G | 224 | 82.7 | 61.1902 qps |
| DiNAT_Small | 50.7M | 7.84G | 224 | 83.8 | 41.0343 qps |
| DiNAT_Base | 89.8M | 13.76G | 224 | 84.4 | 30.1332 qps |
| DiNAT_Large, 21k_ft1k | 200.9M | 30.58G | 224 | 86.6 | 18.4936 qps |
| - 21k, (num_classes=21841) | 200.9M | 30.58G | 224 | ||
| - 21k_ft1k, 384 | 200.9M | 89.86G | 384 | 87.4 | |
| DiNAT_Large_K11, 21k_ft1k | 201.1M | 92.57G | 384 | 87.5 |
- Keras DINOv2 includes models from PDF 2304.07193 DINOv2: Learning Robust Visual Features without Supervision.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| DINOv2_ViT_Small14 | 22.83M | 47.23G | 518 | 81.1 | 165.271 qps |
| DINOv2_ViT_Base14 | 88.12M | 152.6G | 518 | 84.5 | 54.9769 qps |
| DINOv2_ViT_Large14 | 306.4M | 509.6G | 518 | 86.3 | 17.4108 qps |
| DINOv2_ViT_Giant14 | 1139.6M | 1790.3G | 518 | 86.5 |
- Keras EdgeNeXt is for PDF 2206.10589 EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EdgeNeXt_XX_Small | 1.33M | 266M | 256 | 71.23 | 902.957 qps |
| EdgeNeXt_X_Small | 2.34M | 547M | 256 | 74.96 | 638.346 qps |
| EdgeNeXt_Small | 5.59M | 1.27G | 256 | 79.41 | 536.762 qps |
| - usi | 5.59M | 1.27G | 256 | 81.07 | 536.762 qps |
| EdgeNeXt_Base | 18.5M | 3.86G | 256 | 82.47 | 383.461 qps |
| - usi | 18.5M | 3.86G | 256 | 83.31 | 383.461 qps |
| - 21k_ft1k | 18.5M | 3.86G | 256 | 83.68 | 383.461 qps |
- Keras EfficientFormer is for PDF 2206.01191 EfficientFormer: Vision Transformers at MobileNet Speed.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientFormerL1, distill | 12.3M | 1.31G | 224 | 79.2 | 1214.22 qps |
| EfficientFormerL3, distill | 31.4M | 3.95G | 224 | 82.4 | 596.705 qps |
| EfficientFormerL7, distill | 74.4M | 9.79G | 224 | 83.3 | 298.434 qps |
- Keras EfficientFormer includes implementation of PDF 2212.08059 Rethinking Vision Transformers for MobileNet Size and Speed.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientFormerV2S0, distill | 3.60M | 405.2M | 224 | 76.2 | 1114.38 qps |
| EfficientFormerV2S1, distill | 6.19M | 665.6M | 224 | 79.7 | 841.186 qps |
| EfficientFormerV2S2, distill | 12.7M | 1.27G | 224 | 82.0 | 573.9 qps |
| EfficientFormerV2L, distill | 26.3M | 2.59G | 224 | 83.5 | 377.224 qps |
- Keras EfficientNet includes implementation of PDF 1911.04252 Self-training with Noisy Student improves ImageNet classification.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientNetV1B0 | 5.3M | 0.39G | 224 | 77.6 | 1129.93 qps |
| - NoisyStudent | 5.3M | 0.39G | 224 | 78.8 | 1129.93 qps |
| EfficientNetV1B1 | 7.8M | 0.70G | 240 | 79.6 | 758.639 qps |
| - NoisyStudent | 7.8M | 0.70G | 240 | 81.5 | 758.639 qps |
| EfficientNetV1B2 | 9.1M | 1.01G | 260 | 80.5 | 668.959 qps |
| - NoisyStudent | 9.1M | 1.01G | 260 | 82.4 | 668.959 qps |
| EfficientNetV1B3 | 12.2M | 1.86G | 300 | 81.9 | 473.607 qps |
| - NoisyStudent | 12.2M | 1.86G | 300 | 84.1 | 473.607 qps |
| EfficientNetV1B4 | 19.3M | 4.46G | 380 | 83.3 | 265.244 qps |
| - NoisyStudent | 19.3M | 4.46G | 380 | 85.3 | 265.244 qps |
| EfficientNetV1B5 | 30.4M | 10.40G | 456 | 84.3 | 146.758 qps |
| - NoisyStudent | 30.4M | 10.40G | 456 | 86.1 | 146.758 qps |
| EfficientNetV1B6 | 43.0M | 19.29G | 528 | 84.8 | 88.0369 qps |
| - NoisyStudent | 43.0M | 19.29G | 528 | 86.4 | 88.0369 qps |
| EfficientNetV1B7 | 66.3M | 38.13G | 600 | 85.2 | 52.6616 qps |
| - NoisyStudent | 66.3M | 38.13G | 600 | 86.9 | 52.6616 qps |
| EfficientNetV1L2, NoisyStudent | 480.3M | 477.98G | 800 | 88.4 |
- Keras EfficientNetEdgeTPU includes implementation of PDF 1911.04252 Self-training with Noisy Student improves ImageNet classification.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientNetEdgeTPUSmall | 5.49M | 1.79G | 224 | 78.07 | 1459.38 qps |
| EfficientNetEdgeTPUMedium | 6.90M | 3.01G | 240 | 79.25 | 1028.95 qps |
| EfficientNetEdgeTPULarge | 10.59M | 7.94G | 300 | 81.32 | 527.034 qps |
- Keras EfficientNet includes implementation of PDF 2104.00298 EfficientNetV2: Smaller Models and Faster Training.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientNetV2B0 | 7.1M | 0.72G | 224 | 78.7 | 1109.84 qps |
| - 21k_ft1k | 7.1M | 0.72G | 224 | 77.55? | 1109.84 qps |
| EfficientNetV2B1 | 8.1M | 1.21G | 240 | 79.8 | 842.372 qps |
| - 21k_ft1k | 8.1M | 1.21G | 240 | 79.03? | 842.372 qps |
| EfficientNetV2B2 | 10.1M | 1.71G | 260 | 80.5 | 762.865 qps |
| - 21k_ft1k | 10.1M | 1.71G | 260 | 79.48? | 762.865 qps |
| EfficientNetV2B3 | 14.4M | 3.03G | 300 | 82.1 | 548.501 qps |
| - 21k_ft1k | 14.4M | 3.03G | 300 | 82.46? | 548.501 qps |
| EfficientNetV2T | 13.6M | 3.18G | 288 | 82.34 | 496.483 qps |
| EfficientNetV2T_GC | 13.7M | 3.19G | 288 | 82.46 | 368.763 qps |
| EfficientNetV2S | 21.5M | 8.41G | 384 | 83.9 | 344.109 qps |
| - 21k_ft1k | 21.5M | 8.41G | 384 | 84.9 | 344.109 qps |
| EfficientNetV2M | 54.1M | 24.69G | 480 | 85.2 | 145.346 qps |
| - 21k_ft1k | 54.1M | 24.69G | 480 | 86.2 | 145.346 qps |
| EfficientNetV2L | 119.5M | 56.27G | 480 | 85.7 | 85.6514 qps |
| - 21k_ft1k | 119.5M | 56.27G | 480 | 86.9 | 85.6514 qps |
| EfficientNetV2XL, 21k_ft1k | 206.8M | 93.66G | 512 | 87.2 | 55.141 qps |
- Keras EfficientViT_B is for Paper PDF 2205.14756 EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientViT_B0 | 3.41M | 0.12G | 224 | 71.6 ? | 1581.76 qps |
| EfficientViT_B1 | 9.10M | 0.58G | 224 | 79.4 | 943.587 qps |
| - 256 | 9.10M | 0.78G | 256 | 79.9 | 840.844 qps |
| - 288 | 9.10M | 1.03G | 288 | 80.4 | 680.088 qps |
| EfficientViT_B2 | 24.33M | 1.68G | 224 | 82.1 | 583.295 qps |
| - 256 | 24.33M | 2.25G | 256 | 82.7 | 507.187 qps |
| - 288 | 24.33M | 2.92G | 288 | 83.1 | 419.93 qps |
| EfficientViT_B3 | 48.65M | 4.14G | 224 | 83.5 | 329.764 qps |
| - 256 | 48.65M | 5.51G | 256 | 83.8 | 288.605 qps |
| - 288 | 48.65M | 7.14G | 288 | 84.2 | 229.992 qps |
| EfficientViT_L1 | 52.65M | 5.28G | 224 | 84.48 | 503.068 qps |
| EfficientViT_L2 | 63.71M | 6.98G | 224 | 85.05 | 396.255 qps |
| - 384 | 63.71M | 20.7G | 384 | 85.98 | 207.322 qps |
| EfficientViT_L3 | 246.0M | 27.6G | 224 | 85.814 | 174.926 qps |
| - 384 | 246.0M | 81.6G | 384 | 86.408 | 86.895 qps |
- Keras EfficientViT_M is for Paper PDF 2305.07027 EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EfficientViT_M0 | 2.35M | 79.4M | 224 | 63.2 | 814.522 qps |
| EfficientViT_M1 | 2.98M | 167M | 224 | 68.4 | 948.041 qps |
| EfficientViT_M2 | 4.19M | 201M | 224 | 70.8 | 906.286 qps |
| EfficientViT_M3 | 6.90M | 263M | 224 | 73.4 | 758.086 qps |
| EfficientViT_M4 | 8.80M | 299M | 224 | 74.3 | 672.891 qps |
| EfficientViT_M5 | 12.47M | 522M | 224 | 77.1 | 577.254 qps |
- Keras EVA includes models from PDF 2211.07636 EVA: Exploring the Limits of Masked Visual Representation Learning at Scale.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EvaLargePatch14, 21k_ft1k | 304.14M | 61.65G | 196 | 88.59 | 115.532 qps |
| - 21k_ft1k, 336 | 304.53M | 191.55G | 336 | 89.20 | 53.3467 qps |
| EvaGiantPatch14, clip | 1012.6M | 267.40G | 224 | 89.10 | |
| - m30m | 1013.0M | 621.45G | 336 | 89.57 | |
| - m30m | 1014.4M | 1911.61G | 560 | 89.80 |
- Keras EVA02 includes models from PDF 2303.11331 EVA: EVA-02: A Visual Representation for Neon Genesis.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| EVA02TinyPatch14, mim_in22k_ft1k | 5.76M | 4.72G | 336 | 80.658 | 320.123 qps |
| EVA02SmallPatch14, mim_in22k_ft1k | 22.13M | 15.57G | 336 | 85.74 | 161.774 qps |
| EVA02BasePatch14, mim_in22k_ft22k_ft1k | 87.12M | 107.6G | 448 | 88.692 | 34.3962 qps |
| EVA02LargePatch14, mim_m38m_ft22k_ft1k | 305.08M | 363.68G | 448 | 90.054 |
- Keras FasterNet includes implementation of PDF 2303.03667 Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks .
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| FasterNetT0 | 3.9M | 0.34G | 224 | 71.9 | 1890.83 qps |
| FasterNetT1 | 7.6M | 0.85G | 224 | 76.2 | 1788.16 qps |
| FasterNetT2 | 15.0M | 1.90G | 224 | 78.9 | 1353.12 qps |
| FasterNetS | 31.1M | 4.55G | 224 | 81.3 | 818.814 qps |
| FasterNetM | 53.5M | 8.72G | 224 | 83.0 | 436.383 qps |
| FasterNetL | 93.4M | 15.49G | 224 | 83.5 | 319.809 qps |
- Keras FasterViT includes implementation of PDF 2306.06189 FasterViT: Fast Vision Transformers with Hierarchical Attention.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| FasterViT0 | 31.40M | 3.51G | 224 | 82.1 | 716.809 qps |
| FasterViT1 | 53.37M | 5.52G | 224 | 83.2 | 491.971 qps |
| FasterViT2 | 75.92M | 9.00G | 224 | 84.2 | 377.006 qps |
| FasterViT3 | 159.55M | 18.75G | 224 | 84.9 | 216.481 qps |
| FasterViT4 | 351.12M | 41.57G | 224 | 85.4 | 71.6303 qps |
| FasterViT5 | 957.52M | 114.08G | 224 | 85.6 | |
| FasterViT6, +.2 | 1360.33M | 144.13G | 224 | 85.8 |
- Keras FastViT includes implementation of PDF 2303.14189 FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| FastViT_T8 | 4.03M | 0.65G | 256 | 76.2 | 1020.29 qps |
| - distill | 4.03M | 0.65G | 256 | 77.2 | 1020.29 qps |
| - deploy=True | 3.99M | 0.64G | 256 | 76.2 | 1323.14 qps |
| FastViT_T12 | 7.55M | 1.34G | 256 | 79.3 | 734.867 qps |
| - distill | 7.55M | 1.34G | 256 | 80.3 | 734.867 qps |
| - deploy=True | 7.50M | 1.33G | 256 | 79.3 | 956.332 qps |
| FastViT_S12 | 9.47M | 1.74G | 256 | 79.9 | 666.669 qps |
| - distill | 9.47M | 1.74G | 256 | 81.1 | 666.669 qps |
| - deploy=True | 9.42M | 1.74G | 256 | 79.9 | 881.429 qps |
| FastViT_SA12 | 11.58M | 1.88G | 256 | 80.9 | 656.95 qps |
| - distill | 11.58M | 1.88G | 256 | 81.9 | 656.95 qps |
| - deploy=True | 11.54M | 1.88G | 256 | 80.9 | 833.011 qps |
| FastViT_SA24 | 21.55M | 3.66G | 256 | 82.7 | 371.84 qps |
| - distill | 21.55M | 3.66G | 256 | 83.4 | 371.84 qps |
| - deploy=True | 21.49M | 3.66G | 256 | 82.7 | 444.055 qps |
| FastViT_SA36 | 31.53M | 5.44G | 256 | 83.6 | 267.986 qps |
| - distill | 31.53M | 5.44G | 256 | 84.2 | 267.986 qps |
| - deploy=True | 31.44M | 5.43G | 256 | 83.6 | 325.967 qps |
| FastViT_MA36 | 44.07M | 7.64G | 256 | 83.9 | 211.928 qps |
| - distill | 44.07M | 7.64G | 256 | 84.6 | 211.928 qps |
| - deploy=True | 43.96M | 7.63G | 256 | 83.9 | 274.559 qps |
- Keras FBNetV3 includes implementation of PDF 2006.02049 FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| FBNetV3B | 5.57M | 539.82M | 256 | 79.15 | 713.882 qps |
| FBNetV3D | 10.31M | 665.02M | 256 | 79.68 | 635.963 qps |
| FBNetV3G | 16.62M | 1379.30M | 256 | 82.05 | 478.835 qps |
- Keras FlexiViT includes models from PDF 2212.08013 FlexiViT: One Model for All Patch Sizes.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| FlexiViTSmall | 22.06M | 5.36G | 240 | 82.53 | 744.578 qps |
| FlexiViTBase | 86.59M | 20.33G | 240 | 84.66 | 301.948 qps |
| FlexiViTLarge | 304.47M | 71.09G | 240 | 85.64 | 105.187 qps |
- Keras GCViT includes implementation of PDF 2206.09959 Global Context Vision Transformers.
| Model | Params | FLOPs | Input | Top1 Acc | Download |
|---|---|---|---|---|---|
| GCViT_XXTiny | 12.0M | 2.15G | 224 | 79.9 | 337.7 qps |
| GCViT_XTiny | 20.0M | 2.96G | 224 | 82.0 | 255.625 qps |
| GCViT_Tiny | 28.2M | 4.83G | 224 | 83.5 | 174.553 qps |
| GCViT_Tiny2 | 34.5M | 6.28G | 224 | 83.7 | |
| GCViT_Small | 51.1M | 8.63G | 224 | 84.3 | 131.577 qps |
| GCViT_Small2 | 68.6M | 11.7G | 224 | 84.8 | |
| GCViT_Base | 90.3M | 14.9G | 224 | 85.0 | 105.845 qps |
| GCViT_Large | 202.1M | 32.8G | 224 | 85.7 | |
| - 21k_ft1k | 202.1M | 32.8G | 224 | 86.6 | |
| - 21k_ft1k, 384 | 202.9M | 105.1G | 384 | 87.4 | |
| - 21k_ft1k, 512 | 203.8M | 205.1G | 512 | 87.6 |
- Keras GhostNet includes implementation of PDF 1911.11907 GhostNet: More Features from Cheap Operations.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| GhostNet_050 | 2.59M | 42.6M | 224 | 66.88 | 1272.25 qps |
| GhostNet_100 | 5.18M | 141.7M | 224 | 74.16 | 1167.4 qps |
| GhostNet_130 | 7.36M | 227.7M | 224 | 75.79 | 1024.49 qps |
| - ssld | 7.36M | 227.7M | 224 | 79.38 | 1024.49 qps |
- Keras GhostNet includes implementation of PDF GhostNetV2: Enhance Cheap Operation with Long-Range Attention.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| GhostNetV2_100 | 6.12M | 168.5M | 224 | 75.3 | 797.088 qps |
| GhostNetV2_130 | 8.96M | 271.1M | 224 | 76.9 | 722.668 qps |
| GhostNetV2_160 | 12.39M | 400.9M | 224 | 77.8 | 572.268 qps |
- Keras GMLP includes implementation of PDF 2105.08050 Pay Attention to MLPs.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| GMLPTiny16 | 6M | 1.35G | 224 | 72.3 | 234.187 qps |
| GMLPS16 | 20M | 4.44G | 224 | 79.6 | 138.363 qps |
| GMLPB16 | 73M | 15.82G | 224 | 81.6 | 77.816 qps |
- Keras GPViT includes implementation of PDF 2212.06795 GPVIT: A HIGH RESOLUTION NON-HIERARCHICAL VISION TRANSFORMER WITH GROUP PROPAGATION.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| GPViT_L1 | 9.59M | 6.15G | 224 | 80.5 | 210.166 qps |
| GPViT_L2 | 24.2M | 15.74G | 224 | 83.4 | 139.656 qps |
| GPViT_L3 | 36.7M | 23.54G | 224 | 84.1 | 131.284 qps |
| GPViT_L4 | 75.5M | 48.29G | 224 | 84.3 | 94.1899 qps |
- Keras HaloNet is for PDF 2103.12731 Scaling Local Self-Attention for Parameter Efficient Visual Backbones.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| HaloNextECA26T | 10.7M | 2.43G | 256 | 79.50 | 1028.93 qps |
| HaloNet26T | 12.5M | 3.18G | 256 | 79.13 | 1096.79 qps |
| HaloNetSE33T | 13.7M | 3.55G | 256 | 80.99 | 582.008 qps |
| HaloRegNetZB | 11.68M | 1.97G | 224 | 81.042 | 575.961 qps |
| HaloNet50T | 22.7M | 5.29G | 256 | 81.70 | 512.677 qps |
| HaloBotNet50T | 22.6M | 5.02G | 256 | 82.0 | 431.616 qps |
- Keras Hiera is for PDF 2306.00989 Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| HieraTiny, mae_in1k_ft1k | 27.91M | 4.93G | 224 | 82.8 | 644.356 qps |
| HieraSmall, mae_in1k_ft1k | 35.01M | 6.44G | 224 | 83.8 | 491.669 qps |
| HieraBase, mae_in1k_ft1k | 51.52M | 9.43G | 224 | 84.5 | 351.542 qps |
| HieraBasePlus, mae_in1k_ft1k | 69.90M | 12.71G | 224 | 85.2 | 291.446 qps |
| HieraLarge, mae_in1k_ft1k | 213.74M | 40.43G | 224 | 86.1 | 111.042 qps |
| HieraHuge, mae_in1k_ft1k | 672.78M | 125.03G | 224 | 86.9 |
- Keras HorNet is for PDF 2207.14284 HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| HorNetTiny | 22.4M | 4.01G | 224 | 82.8 | 222.665 qps |
| HorNetTinyGF | 23.0M | 3.94G | 224 | 83.0 | |
| HorNetSmall | 49.5M | 8.87G | 224 | 83.8 | 166.998 qps |
| HorNetSmallGF | 50.4M | 8.77G | 224 | 84.0 | |
| HorNetBase | 87.3M | 15.65G | 224 | 84.2 | 133.842 qps |
| HorNetBaseGF | 88.4M | 15.51G | 224 | 84.3 | |
| HorNetLarge | 194.5M | 34.91G | 224 | 86.8 | 89.8254 qps |
| HorNetLargeGF | 196.3M | 34.72G | 224 | 87.0 | |
| HorNetLargeGF | 201.8M | 102.0G | 384 | 87.7 |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| IFormerSmall | 19.9M | 4.88G | 224 | 83.4 | 254.392 qps |
| - 384 | 20.9M | 16.29G | 384 | 84.6 | 128.98 qps |
| IFormerBase | 47.9M | 9.44G | 224 | 84.6 | 147.868 qps |
| - 384 | 48.9M | 30.86G | 384 | 85.7 | 77.8391 qps |
| IFormerLarge | 86.6M | 14.12G | 224 | 84.6 | 113.434 qps |
| - 384 | 87.7M | 45.74G | 384 | 85.8 | 60.0292 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| InceptionNeXtTiny | 28.05M | 4.21G | 224 | 82.3 | 606.527 qps |
| InceptionNeXtSmall | 49.37M | 8.39G | 224 | 83.5 | 329.01 qps |
| InceptionNeXtBase | 86.67M | 14.88G | 224 | 84.0 | 260.639 qps |
| - 384 | 86.67M | 43.73G | 384 | 85.2 | 142.888 qps |
- Keras LCNet includes implementation of PDF 2109.15099 PP-LCNet: A Lightweight CPU Convolutional Neural Network.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| LCNet050 | 1.88M | 46.02M | 224 | 63.10 | 3107.89 qps |
| - ssld | 1.88M | 46.02M | 224 | 66.10 | 3107.89 qps |
| LCNet075 | 2.36M | 96.82M | 224 | 68.82 | 3083.55 qps |
| LCNet100 | 2.95M | 158.28M | 224 | 72.10 | 2752.6 qps |
| - ssld | 2.95M | 158.28M | 224 | 74.39 | 2752.6 qps |
| LCNet150 | 4.52M | 338.05M | 224 | 73.71 | 2250.69 qps |
| LCNet200 | 6.54M | 585.35M | 224 | 75.18 | 2028.31 qps |
| LCNet250 | 9.04M | 900.16M | 224 | 76.60 | 1686.7 qps |
| - ssld | 9.04M | 900.16M | 224 | 80.82 | 1686.7 qps |
- Keras LeViT is for PDF 2104.01136 LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| LeViT128S, distill | 7.8M | 0.31G | 224 | 76.6 | 800.53 qps |
| LeViT128, distill | 9.2M | 0.41G | 224 | 78.6 | 628.714 qps |
| LeViT192, distill | 11M | 0.66G | 224 | 80.0 | 597.299 qps |
| LeViT256, distill | 19M | 1.13G | 224 | 81.6 | 538.885 qps |
| LeViT384, distill | 39M | 2.36G | 224 | 82.6 | 460.139 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MaxViT_Tiny | 31M | 5.6G | 224 | 83.62 | 195.283 qps |
| - 384 | 31M | 17.7G | 384 | 85.24 | 92.5725 qps |
| - 512 | 31M | 33.7G | 512 | 85.72 | 52.6485 qps |
| MaxViT_Small | 69M | 11.7G | 224 | 84.45 | 149.286 qps |
| - 384 | 69M | 36.1G | 384 | 85.74 | 61.5757 qps |
| - 512 | 69M | 67.6G | 512 | 86.19 | 34.7002 qps |
| MaxViT_Base | 119M | 24.2G | 224 | 84.95 | 74.7351 qps |
| - 384 | 119M | 74.2G | 384 | 86.34 | 31.9028 qps |
| - 512 | 119M | 138.5G | 512 | 86.66 | 17.8139 qps |
| - imagenet21k | 135M | 24.2G | 224 | 74.7351 qps | |
| - 21k_ft1k, 384 | 119M | 74.2G | 384 | 88.24 | 31.9028 qps |
| - 21k_ft1k, 512 | 119M | 138.5G | 512 | 88.38 | 17.8139 qps |
| MaxViT_Large | 212M | 43.9G | 224 | 85.17 | 58.0967 qps |
| - 384 | 212M | 133.1G | 384 | 86.40 | 24.1388 qps |
| - 512 | 212M | 245.4G | 512 | 86.70 | 13.063 qps |
| - imagenet21k | 233M | 43.9G | 224 | 58.0967 qps | |
| - 21k_ft1k, 384 | 212M | 133.1G | 384 | 88.32 | 24.1388 qps |
| - 21k_ft1k, 512 | 212M | 245.4G | 512 | 88.46 | 13.063 qps |
| MaxViT_XLarge, imagenet21k | 507M | 97.7G | 224 | ||
| - 21k_ft1k, 384 | 475M | 293.7G | 384 | 88.51 | |
| - 21k_ft1k, 512 | 475M | 535.2G | 512 | 88.70 |
- Keras MetaTransFormer includes models from PDF 2307.10802 Meta-Transformer: A Unified Framework for Multimodal Learning.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MetaTransformerBasePatch16, laion_2b | 86.86M | 55.73G | 384 | 85.4 | 150.731 qps |
| MetaTransformerLargePatch14, laion_2b | 304.53M | 191.6G | 336 | 88.1 | 50.1536 qps |
- Keras MLP mixer includes implementation of PDF 2105.01601 MLP-Mixer: An all-MLP Architecture for Vision.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MLPMixerS32, JFT | 19.1M | 1.01G | 224 | 68.70 | 488.839 qps |
| MLPMixerS16, JFT | 18.5M | 3.79G | 224 | 73.83 | 451.962 qps |
| MLPMixerB32, JFT | 60.3M | 3.25G | 224 | 75.53 | 247.629 qps |
| - sam | 60.3M | 3.25G | 224 | 72.47 | 247.629 qps |
| MLPMixerB16 | 59.9M | 12.64G | 224 | 76.44 | 207.423 qps |
| - 21k_ft1k | 59.9M | 12.64G | 224 | 80.64 | 207.423 qps |
| - sam | 59.9M | 12.64G | 224 | 77.36 | 207.423 qps |
| - JFT | 59.9M | 12.64G | 224 | 80.00 | 207.423 qps |
| MLPMixerL32, JFT | 206.9M | 11.30G | 224 | 80.67 | 95.1865 qps |
| MLPMixerL16 | 208.2M | 44.66G | 224 | 71.76 | 77.9928 qps |
| - 21k_ft1k | 208.2M | 44.66G | 224 | 82.89 | 77.9928 qps |
| - JFT | 208.2M | 44.66G | 224 | 84.82 | 77.9928 qps |
| - 448 | 208.2M | 178.54G | 448 | 83.91 | |
| - 448, JFT | 208.2M | 178.54G | 448 | 86.78 | |
| MLPMixerH14, JFT | 432.3M | 121.22G | 224 | 86.32 | |
| - 448, JFT | 432.3M | 484.73G | 448 | 87.94 |
- Keras MobileNetV3 includes implementation of PDF 1905.02244 Searching for MobileNetV3.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MobileNetV3Small050 | 1.29M | 24.92M | 224 | 57.89 | 2458.28 qps |
| MobileNetV3Small075 | 2.04M | 44.35M | 224 | 65.24 | 2286.44 qps |
| MobileNetV3Small100 | 2.54M | 57.62M | 224 | 67.66 | 2058.06 qps |
| MobileNetV3Large075 | 3.99M | 156.30M | 224 | 73.44 | 1643.78 qps |
| MobileNetV3Large100 | 5.48M | 218.73M | 224 | 75.77 | 1629.44 qps |
| - miil | 5.48M | 218.73M | 224 | 77.92 | 1629.44 qps |
- Keras MobileViT is for PDF 2110.02178 MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MobileViT_XXS | 1.3M | 0.42G | 256 | 69.0 | 1319.43 qps |
| MobileViT_XS | 2.3M | 1.05G | 256 | 74.7 | 1019.57 qps |
| MobileViT_S | 5.6M | 2.03G | 256 | 78.3 | 790.943 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MobileViT_V2_050 | 1.37M | 0.47G | 256 | 70.18 | 718.337 qps |
| MobileViT_V2_075 | 2.87M | 1.04G | 256 | 75.56 | 642.323 qps |
| MobileViT_V2_100 | 4.90M | 1.83G | 256 | 78.09 | 591.217 qps |
| MobileViT_V2_125 | 7.48M | 2.84G | 256 | 79.65 | 510.25 qps |
| MobileViT_V2_150 | 10.6M | 4.07G | 256 | 80.38 | 466.482 qps |
| - 21k_ft1k | 10.6M | 4.07G | 256 | 81.46 | 466.482 qps |
| - 21k_ft1k, 384 | 10.6M | 9.15G | 384 | 82.60 | 278.834 qps |
| MobileViT_V2_175 | 14.3M | 5.52G | 256 | 80.84 | 412.759 qps |
| - 21k_ft1k | 14.3M | 5.52G | 256 | 81.94 | 412.759 qps |
| - 21k_ft1k, 384 | 14.3M | 12.4G | 384 | 82.93 | 247.108 qps |
| MobileViT_V2_200 | 18.4M | 7.12G | 256 | 81.17 | 394.325 qps |
| - 21k_ft1k | 18.4M | 7.12G | 256 | 82.36 | 394.325 qps |
| - 21k_ft1k, 384 | 18.4M | 16.2G | 384 | 83.41 | 229.399 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| MogaNetXtiny | 2.96M | 806M | 224 | 76.5 | 398.488 qps |
| MogaNetTiny | 5.20M | 1.11G | 224 | 79.0 | 362.409 qps |
| - 256 | 5.20M | 1.45G | 256 | 79.6 | 335.372 qps |
| MogaNetSmall | 25.3M | 4.98G | 224 | 83.4 | 249.807 qps |
| MogaNetBase | 43.7M | 9.96G | 224 | 84.2 | 133.071 qps |
| MogaNetLarge | 82.5M | 15.96G | 224 | 84.6 | 84.2045 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| NAT_Mini | 20.0M | 2.73G | 224 | 81.8 | 85.2324 qps |
| NAT_Tiny | 27.9M | 4.34G | 224 | 83.2 | 62.6147 qps |
| NAT_Small | 50.7M | 7.84G | 224 | 83.7 | 41.1545 qps |
| NAT_Base | 89.8M | 13.76G | 224 | 84.3 | 30.8989 qps |
- Keras NFNets is for PDF 2102.06171 High-Performance Large-Scale Image Recognition Without Normalization.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| NFNetL0 | 35.07M | 7.13G | 288 | 82.75 | |
| NFNetF0 | 71.5M | 12.58G | 256 | 83.6 | |
| NFNetF1 | 132.6M | 35.95G | 320 | 84.7 | |
| NFNetF2 | 193.8M | 63.24G | 352 | 85.1 | |
| NFNetF3 | 254.9M | 115.75G | 416 | 85.7 | |
| NFNetF4 | 316.1M | 216.78G | 512 | 85.9 | |
| NFNetF5 | 377.2M | 291.73G | 544 | 86.0 | |
| NFNetF6, sam | 438.4M | 379.75G | 576 | 86.5 | |
| NFNetF7 | 499.5M | 481.80G | 608 | ||
| ECA_NFNetL0 | 24.14M | 7.12G | 288 | 82.58 | |
| ECA_NFNetL1 | 41.41M | 14.93G | 320 | 84.01 | |
| ECA_NFNetL2 | 56.72M | 30.12G | 384 | 84.70 | |
| ECA_NFNetL3 | 72.04M | 52.73G | 448 |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| PVT_V2B0 | 3.7M | 580.3M | 224 | 70.5 | 561.593 qps |
| PVT_V2B1 | 14.0M | 2.14G | 224 | 78.7 | 392.408 qps |
| PVT_V2B2 | 25.4M | 4.07G | 224 | 82.0 | 210.476 qps |
| PVT_V2B2_linear | 22.6M | 3.94G | 224 | 82.1 | 226.791 qps |
| PVT_V2B3 | 45.2M | 6.96G | 224 | 83.1 | 135.51 qps |
| PVT_V2B4 | 62.6M | 10.19G | 224 | 83.6 | 97.666 qps |
| PVT_V2B5 | 82.0M | 11.81G | 224 | 83.8 | 81.4798 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| RegNetY040 | 20.65M | 3.98G | 224 | 82.3 | 749.277 qps |
| RegNetY064 | 30.58M | 6.36G | 224 | 83.0 | 436.946 qps |
| RegNetY080 | 39.18M | 7.97G | 224 | 83.17 | 513.43 qps |
| RegNetY160 | 83.59M | 15.92G | 224 | 82.0 | 338.046 qps |
| RegNetY320 | 145.05M | 32.29G | 224 | 82.5 | 188.508 qps |
- Keras RegNetZ includes implementation of Github timm/models/byobnet.py.
- Related paper PDF 2004.02967 Evolving Normalization-Activation Layers
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| RegNetZB16 | 9.72M | 1.44G | 224 | 79.868 | 751.035 qps |
| RegNetZC16 | 13.46M | 2.50G | 256 | 82.164 | 636.549 qps |
| RegNetZC16_EVO | 13.49M | 2.55G | 256 | 81.9 | |
| RegNetZD32 | 27.58M | 5.96G | 256 | 83.422 | 459.204 qps |
| RegNetZD8 | 23.37M | 3.95G | 256 | 83.5 | 460.021 qps |
| RegNetZD8_EVO | 23.46M | 4.61G | 256 | 83.42 | |
| RegNetZE8 | 57.70M | 9.88G | 256 | 84.5 | 274.97 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| RepViT_M09, distillation | 5.10M | 0.82G | 224 | 79.1 | |
| - deploy=True | 5.07M | 0.82G | 224 | 79.1 | 966.72 qps |
| RepViT_M10, distillation | 6.85M | 1.12G | 224 | 80.3 | 1157.8 qps |
| - deploy=True | 6.81M | 1.12G | 224 | 80.3 | |
| RepViT_M11, distillation | 8.29M | 1.35G | 224 | 81.2 | 846.682 qps |
| - deploy=True | 8.24M | 1.35G | 224 | 81.2 | 1027.5 qps |
| RepViT_M15, distillation | 14.13M | 2.30G | 224 | 82.5 | |
| - deploy=True | 14.05M | 2.30G | 224 | 82.5 | |
| RepViT_M23, distillation | 23.01M | 4.55G | 224 | 83.7 | |
| - deploy=True | 22.93M | 4.55G | 224 | 83.7 |
- Keras ResMLP includes implementation of PDF 2105.03404 ResMLP: Feedforward networks for image classification with data-efficient training.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ResMLP12 | 15M | 3.02G | 224 | 77.8 | 928.402 qps |
| ResMLP24 | 30M | 5.98G | 224 | 80.8 | 420.709 qps |
| ResMLP36 | 116M | 8.94G | 224 | 81.1 | 309.513 qps |
| ResMLP_B24 | 129M | 100.39G | 224 | 83.6 | 78.3015 qps |
| - 21k_ft1k | 129M | 100.39G | 224 | 84.4 | 78.3015 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ResNest50 | 28M | 5.38G | 224 | 81.03 | 534.627 qps |
| ResNest101 | 49M | 13.33G | 256 | 82.83 | 257.074 qps |
| ResNest200 | 71M | 35.55G | 320 | 83.84 | 118.183 qps |
| ResNest269 | 111M | 77.42G | 416 | 84.54 | 61.167 qps |
- Keras ResNetD includes implementation of PDF 1812.01187 Bag of Tricks for Image Classification with Convolutional Neural Networks
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ResNet50D | 25.58M | 4.33G | 224 | 80.530 | 930.214 qps |
| ResNet101D | 44.57M | 8.04G | 224 | 83.022 | 502.268 qps |
| ResNet152D | 60.21M | 11.75G | 224 | 83.680 | 353.279 qps |
| ResNet200D | 64.69M | 15.25G | 224 | 83.962 | 287.73 qps |
- Keras ResNetQ includes implementation of Github timm/models/resnet.py
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ResNet51Q | 35.7M | 4.87G | 224 | 82.36 | 838.754 qps |
| ResNet61Q | 36.8M | 5.96G | 224 | 730.245 qps |
- Keras ResNeXt includes implementation of PDF 1611.05431 Aggregated Residual Transformations for Deep Neural Networks.
SWSLmeansSemi-Weakly Supervised ResNe*tfrom Github facebookresearch/semi-supervised-ImageNet1K-models. Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| ResNeXt50, (32x4d) | 25M | 4.23G | 224 | 79.768 | 1041.46 qps |
| - SWSL | 25M | 4.23G | 224 | 82.182 | 1041.46 qps |
| ResNeXt50D, (32x4d + deep) | 25M | 4.47G | 224 | 79.676 | 1010.94 qps |
| ResNeXt101, (32x4d) | 42M | 7.97G | 224 | 80.334 | 571.652 qps |
| - SWSL | 42M | 7.97G | 224 | 83.230 | 571.652 qps |
| ResNeXt101W, (32x8d) | 89M | 16.41G | 224 | 79.308 | 367.431 qps |
| - SWSL | 89M | 16.41G | 224 | 84.284 | 367.431 qps |
| ResNeXt101W_64, (64x4d) | 83.46M | 15.46G | 224 | 82.46 | 377.83 qps |
- Keras SwinTransformerV2 includes implementation of PDF 2111.09883 Swin Transformer V2: Scaling Up Capacity and Resolution.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| SwinTransformerV2Tiny_ns | 28.3M | 4.69G | 224 | 81.8 | 289.205 qps |
| SwinTransformerV2Small_ns | 49.7M | 9.12G | 224 | 83.5 | 169.645 qps |
| SwinTransformerV2Tiny_window8 | 28.3M | 5.99G | 256 | 81.8 | 275.547 qps |
| SwinTransformerV2Tiny_window16 | 28.3M | 6.75G | 256 | 82.8 | 217.207 qps |
| SwinTransformerV2Small_window8 | 49.7M | 11.63G | 256 | 83.7 | 157.559 qps |
| SwinTransformerV2Small_window16 | 49.7M | 12.93G | 256 | 84.1 | 129.953 qps |
| SwinTransformerV2Base_window8 | 87.9M | 20.44G | 256 | 84.2 | 126.294 qps |
| SwinTransformerV2Base_window16 | 87.9M | 22.17G | 256 | 84.6 | 99.634 qps |
| SwinTransformerV2Base_window16, 21k_ft1k | 87.9M | 22.17G | 256 | 86.2 | 99.634 qps |
| SwinTransformerV2Base_window24, 21k_ft1k | 87.9M | 55.89G | 384 | 87.1 | 35.0508 qps |
| SwinTransformerV2Large_window16, 21k_ft1k | 196.7M | 48.03G | 256 | 86.9 | |
| SwinTransformerV2Large_window24, 21k_ft1k | 196.7M | 117.1G | 384 | 87.6 |
- Keras TinyNet includes implementation of PDF 2010.14819 Model Rubik’s Cube: Twisting Resolution, Depth and Width for TinyNets.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| TinyNetE | 2.04M | 25.22M | 106 | 59.86 | 2152.36 qps |
| TinyNetD | 2.34M | 53.35M | 152 | 66.96 | 1905.56 qps |
| TinyNetC | 2.46M | 103.22M | 184 | 71.23 | 1353.44 qps |
| TinyNetB | 3.73M | 206.28M | 188 | 74.98 | 1196.06 qps |
| TinyNetA | 6.19M | 343.74M | 192 | 77.65 | 981.976 qps |
- Keras TinyViT includes implementation of PDF 2207.10666 TinyViT: Fast Pretraining Distillation for Small Vision Transformers.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| TinyViT_5M, distill | 5.4M | 1.3G | 224 | 79.1 | 631.414 qps |
| - 21k_ft1k | 5.4M | 1.3G | 224 | 80.7 | 631.414 qps |
| TinyViT_11M, distill | 11M | 2.0G | 224 | 81.5 | 509.818 qps |
| - 21k_ft1k | 11M | 2.0G | 224 | 83.2 | 509.818 qps |
| TinyViT_21M, distill | 21M | 4.3G | 224 | 83.1 | 410.676 qps |
| - 21k_ft1k | 21M | 4.3G | 224 | 84.8 | 410.676 qps |
| - 21k_ft1k, 384 | 21M | 13.8G | 384 | 86.2 | 199.458 qps |
| - 21k_ft1k, 512 | 21M | 27.0G | 512 | 86.5 | 122.846 qps |
- Keras UniFormer includes implementation of PDF 2201.09450 UniFormer: Unifying Convolution and Self-attention for Visual Recognition.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| UniformerSmall32, token_label | 22M | 3.66G | 224 | 83.4 | 577.334 qps |
| UniformerSmall64 | 22M | 3.66G | 224 | 82.9 | 562.794 qps |
| - token_label | 22M | 3.66G | 224 | 83.4 | 562.794 qps |
| UniformerSmallPlus32 | 24M | 4.24G | 224 | 83.4 | 546.82 qps |
| - token_label | 24M | 4.24G | 224 | 83.9 | 546.82 qps |
| UniformerSmallPlus64 | 24M | 4.23G | 224 | 83.4 | 538.193 qps |
| - token_label | 24M | 4.23G | 224 | 83.6 | 538.193 qps |
| UniformerBase32, token_label | 50M | 8.32G | 224 | 85.1 | 272.485 qps |
| UniformerBase64 | 50M | 8.31G | 224 | 83.8 | 286.963 qps |
| - token_label | 50M | 8.31G | 224 | 84.8 | 286.963 qps |
| UniformerLarge64, token_label | 100M | 19.79G | 224 | 85.6 | 154.761 qps |
| - token_label, 384 | 100M | 63.11G | 384 | 86.3 | 75.3487 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| VanillaNet5 | 22.33M | 8.46G | 224 | 72.49 | 598.964 qps |
| - deploy=True | 15.52M | 5.17G | 224 | 72.49 | 798.199 qps |
| VanillaNet6 | 56.12M | 10.11G | 224 | 76.36 | 465.031 qps |
| - deploy=True | 32.51M | 6.00G | 224 | 76.36 | 655.944 qps |
| VanillaNet7 | 56.67M | 11.84G | 224 | 77.98 | 375.479 qps |
| - deploy=True | 32.80M | 6.90G | 224 | 77.98 | 527.723 qps |
| VanillaNet8 | 65.18M | 13.50G | 224 | 79.13 | 341.157 qps |
| - deploy=True | 37.10M | 7.75G | 224 | 79.13 | 479.328 qps |
| VanillaNet9 | 73.68M | 15.17G | 224 | 79.87 | 312.815 qps |
| - deploy=True | 41.40M | 8.59G | 224 | 79.87 | 443.464 qps |
| VanillaNet10 | 82.19M | 16.83G | 224 | 80.57 | 277.871 qps |
| - deploy=True | 45.69M | 9.43G | 224 | 80.57 | 408.082 qps |
| VanillaNet11 | 90.69M | 18.49G | 224 | 81.08 | 267.026 qps |
| - deploy=True | 50.00M | 10.27G | 224 | 81.08 | 377.239 qps |
| VanillaNet12 | 99.20M | 20.16G | 224 | 81.55 | 229.987 qps |
| - deploy=True | 54.29M | 11.11G | 224 | 81.55 | 358.076 qps |
| VanillaNet13 | 107.7M | 21.82G | 224 | 82.05 | 218.256 qps |
| - deploy=True | 58.59M | 11.96G | 224 | 82.05 | 334.244 qps |
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| VOLO_d1 | 27M | 4.82G | 224 | 84.2 | |
| - 384 | 27M | 14.22G | 384 | 85.2 | |
| VOLO_d2 | 59M | 9.78G | 224 | 85.2 | |
| - 384 | 59M | 28.84G | 384 | 86.0 | |
| VOLO_d3 | 86M | 13.80G | 224 | 85.4 | |
| - 448 | 86M | 55.50G | 448 | 86.3 | |
| VOLO_d4 | 193M | 29.39G | 224 | 85.7 | |
| - 448 | 193M | 117.81G | 448 | 86.8 | |
| VOLO_d5 | 296M | 53.34G | 224 | 86.1 | |
| - 448 | 296M | 213.72G | 448 | 87.0 | |
| - 512 | 296M | 279.36G | 512 | 87.1 |
- Keras WaveMLP includes implementation of PDF 2111.12294 An Image Patch is a Wave: Quantum Inspired Vision MLP.
| Model | Params | FLOPs | Input | Top1 Acc | T4 Inference |
|---|---|---|---|---|---|
| WaveMLP_T | 17M | 2.47G | 224 | 80.9 | 523.4 qps |
| WaveMLP_S | 30M | 4.55G | 224 | 82.9 | 203.445 qps |
| WaveMLP_M | 44M | 7.92G | 224 | 83.3 | 147.155 qps |
| WaveMLP_B | 63M | 10.26G | 224 | 83.6 |
- Keras EfficientDet includes implementation of Paper 1911.09070 EfficientDet: Scalable and Efficient Object Detection.
Det-AdvProp + AutoAugmentPaper 2103.13886 Robust and Accurate Object Detection via Adversarial Learning.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| EfficientDetD0 | 3.9M | 2.55G | 512 | 34.3 | 34.6 | 248.009 qps |
| - Det-AdvProp | 3.9M | 2.55G | 512 | 35.1 | 35.3 | 248.009 qps |
| EfficientDetD1 | 6.6M | 6.13G | 640 | 40.2 | 40.5 | 133.139 qps |
| - Det-AdvProp | 6.6M | 6.13G | 640 | 40.8 | 40.9 | 133.139 qps |
| EfficientDetD2 | 8.1M | 11.03G | 768 | 43.5 | 43.9 | 89.0523 qps |
| - Det-AdvProp | 8.1M | 11.03G | 768 | 44.3 | 44.3 | 89.0523 qps |
| EfficientDetD3 | 12.0M | 24.95G | 896 | 46.8 | 47.2 | 50.0498 qps |
| - Det-AdvProp | 12.0M | 24.95G | 896 | 47.7 | 48.0 | 50.0498 qps |
| EfficientDetD4 | 20.7M | 55.29G | 1024 | 49.3 | 49.7 | 28.0086 qps |
| - Det-AdvProp | 20.7M | 55.29G | 1024 | 50.4 | 50.4 | 28.0086 qps |
| EfficientDetD5 | 33.7M | 135.62G | 1280 | 51.2 | 51.5 | |
| - Det-AdvProp | 33.7M | 135.62G | 1280 | 52.2 | 52.5 | |
| EfficientDetD6 | 51.9M | 225.93G | 1280 | 52.1 | 52.6 | |
| EfficientDetD7 | 51.9M | 325.34G | 1536 | 53.4 | 53.7 | |
| EfficientDetD7X | 77.0M | 410.87G | 1536 | 54.4 | 55.1 | |
| EfficientDetLite0 | 3.2M | 0.98G | 320 | 27.5 | 26.41 | 599.616 qps |
| EfficientDetLite1 | 4.2M | 1.97G | 384 | 32.6 | 31.50 | 369.273 qps |
| EfficientDetLite2 | 5.3M | 3.38G | 448 | 36.2 | 35.06 | 278.263 qps |
| EfficientDetLite3 | 8.4M | 7.50G | 512 | 39.9 | 38.77 | 180.871 qps |
| EfficientDetLite3X | 9.3M | 14.01G | 640 | 44.0 | 42.64 | 115.271 qps |
| EfficientDetLite4 | 15.1M | 20.20G | 640 | 44.4 | 43.18 | 95.4122 qps |
- Keras YOLO_NAS includes implementation of Github Deci-AI/super-gradients YOLO-NAS models.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| YOLO_NAS_S | 12.88M | 16.96G | 640 | 47.5 | 240.087 qps | |
| - use_reparam_conv=False | 12.18M | 15.92G | 640 | 47.5 | 345.595 qps | |
| YOLO_NAS_M | 33.86M | 47.12G | 640 | 51.55 | 128.96 qps | |
| - use_reparam_conv=False | 31.92M | 43.91G | 640 | 51.55 | 167.935 qps | |
| YOLO_NAS_L | 44.53M | 64.53G | 640 | 52.22 | 98.6069 qps | |
| - use_reparam_conv=False | 42.02M | 59.95G | 640 | 52.22 | 131.11 qps |
- Keras YOLOR includes implementation of Paper 2105.04206 You Only Learn One Representation: Unified Network for Multiple Tasks.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| YOLOR_CSP | 52.9M | 60.25G | 640 | 50.0 | 52.8 | 118.746 qps |
| YOLOR_CSPX | 99.8M | 111.11G | 640 | 51.5 | 54.8 | 67.9444 qps |
| YOLOR_P6 | 37.3M | 162.87G | 1280 | 52.5 | 55.7 | 49.3128 qps |
| YOLOR_W6 | 79.9M | 226.67G | 1280 | 53.6 ? | 56.9 | 40.2355 qps |
| YOLOR_E6 | 115.9M | 341.62G | 1280 | 50.3 ? | 57.6 | 21.5719 qps |
| YOLOR_D6 | 151.8M | 467.88G | 1280 | 50.8 ? | 58.2 | 16.6061 qps |
- Keras YOLOV7 includes implementation of Paper 2207.02696 YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| YOLOV7_Tiny | 6.23M | 2.90G | 416 | 33.3 | 845.903 qps | |
| YOLOV7_CSP | 37.67M | 53.0G | 640 | 51.4 | 137.441 qps | |
| YOLOV7_X | 71.41M | 95.0G | 640 | 53.1 | 82.0534 qps | |
| YOLOV7_W6 | 70.49M | 180.1G | 1280 | 54.9 | 49.9841 qps | |
| YOLOV7_E6 | 97.33M | 257.6G | 1280 | 56.0 | 31.3852 qps | |
| YOLOV7_D6 | 133.9M | 351.4G | 1280 | 56.6 | 26.1346 qps | |
| YOLOV7_E6E | 151.9M | 421.7G | 1280 | 56.8 | 20.1331 qps |
- Keras YOLOV8 includes implementation of Github ultralytics/ultralytics detection and classification models.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| YOLOV8_N | 3.16M | 4.39G | 640 | 37.3 | 614.042 qps | |
| YOLOV8_S | 11.17M | 14.33G | 640 | 44.9 | 349.528 qps | |
| YOLOV8_M | 25.90M | 39.52G | 640 | 50.2 | 160.212 qps | |
| YOLOV8_L | 43.69M | 82.65G | 640 | 52.9 | 104.452 qps | |
| YOLOV8_X | 68.23M | 129.0G | 640 | 53.9 | 66.0428 qps | |
| YOLOV8_X6 | 97.42M | 522.6G | 1280 | 56.7 ? | 17.4368 qps |
- Keras YOLOX includes implementation of Paper 2107.08430 YOLOX: Exceeding YOLO Series in 2021.
| Model | Params | FLOPs | Input | COCO val AP | test AP | T4 Inference |
|---|---|---|---|---|---|---|
| YOLOXNano | 0.91M | 0.53G | 416 | 25.8 | 930.57 qps | |
| YOLOXTiny | 5.06M | 3.22G | 416 | 32.8 | 745.2 qps | |
| YOLOXS | 9.0M | 13.39G | 640 | 40.5 | 40.5 | 380.38 qps |
| YOLOXM | 25.3M | 36.84G | 640 | 46.9 | 47.2 | 181.084 qps |
| YOLOXL | 54.2M | 77.76G | 640 | 49.7 | 50.1 | 111.517 qps |
| YOLOXX | 99.1M | 140.87G | 640 | 51.5 | 51.5 | 62.3189 qps |
- Keras GPT2 includes implementation of Language Models are Unsupervised Multitask Learners.
T4 Inferenceis tested usinginput_shape=[1, 1024].
| Model | Params | FLOPs | vocab_size | LAMBADA PPL | T4 Inference |
|---|---|---|---|---|---|
| GPT2_Base | 163.04M | 146.42G | 50257 | 35.13 | 51.4483 qps |
| GPT2_Medium | 406.29M | 415.07G | 50257 | 15.60 | 21.756 qps |
| GPT2_Large | 838.36M | 890.28G | 50257 | 10.87 | |
| GPT2_XLarge, +.2 | 1.638B | 1758.3G | 50257 | 8.63 |
- Keras LLaMA2 includes implementation of PDF 2307.09288 Llama 2: Open Foundation and Fine-Tuned Chat Models.
tiny_storiesweights ported from Github karpathy/llama2.c, andLLaMA2_1Bmodel weights ported from Github jzhang38/TinyLlamaTinyLlama-1.1B-Chat-V0.4one.
| Model | Params | FLOPs | vocab_size | Val loss | T4 Inference |
|---|---|---|---|---|---|
| LLaMA2_15M | 24.41M | 4.06G | 32000 | 1.072 | |
| LLaMA2_42M | 58.17M | 50.7G | 32000 | 0.847 | |
| LLaMA2_110M | 134.1M | 130.2G | 32000 | 0.760 | |
| LLaMA2_1B | 1.10B | 2.50T | 32003 | ||
| LLaMA2_7B | 6.74B | 14.54T | 32000 |
- Keras Stable Diffusion includes implementation of PDF 2112.10752 High-Resolution Image Synthesis with Latent Diffusion Models. Weights ported from Github runwayml/stable-diffusion
sd-v1-5.ckpt.
| Model | Params | FLOPs | Input | Download |
|---|---|---|---|---|
| ViTTextLargePatch14 | 123.1M | 6.67G | [None, 77] | vit_text_large_patch14_clip.h5 |
| Encoder | 34.16M | 559.6G | [None, 512, 512, 3] | encoder_v1_5.h5 |
| UNet | 859.5M | 404.4G | [None, 64, 64, 4] | unet_v1_5.h5 |
| Decoder | 49.49M | 1259.5G | [None, 64, 64, 4] | decoder_v1_5.h5 |
- Keras YOLOV8 includes implementation of Github ultralytics/ultralytics segmentation models.
| Model | Params | FLOPs | Input | COCO val mask AP | T4 Inference |
|---|---|---|---|---|---|
| YOLOV8_N_SEG | 3.41M | 6.02G | 640 | 30.5 | |
| YOLOV8_S_SEG | 11.82M | 20.08G | 640 | 36.8 | |
| YOLOV8_M_SEG | 27.29M | 52.33G | 640 | 40.8 | |
| YOLOV8_L_SEG | 46.00M | 105.29G | 640 | 42.6 | |
| YOLOV8_X_SEG | 71.83M | 164.30G | 640 | 43.4 |
- Keras Segment Anything includes implementation of PDF 2304.02643 Segment Anything.
| Model | Params | FLOPs | Input | COCO val mask AP | T4 Inference |
|---|---|---|---|---|---|
| MobileSAM | 5.74M | 39.4G | 1024 | 41.0 | |
| TinySAM | 5.74M | 39.4G | 1024 | 41.9 | |
| EfficientViT_SAM_L0 | 30.73M | 35.4G | 512 | 45.7 |
- This part is copied and modified according to Github rwightman/pytorch-image-models.
- Code. The code here is licensed MIT. It is your responsibility to ensure you comply with licenses here and conditions of any dependent licenses. Where applicable, I've linked the sources/references for various components in docstrings. If you think I've missed anything please create an issue. So far all of the pretrained weights available here are pretrained on ImageNet and COCO with a select few that have some additional pretraining.
- ImageNet Pretrained Weights. ImageNet was released for non-commercial research purposes only (https://image-net.org/download). It's not clear what the implications of that are for the use of pretrained weights from that dataset. Any models I have trained with ImageNet are done for research purposes and one should assume that the original dataset license applies to the weights. It's best to seek legal advice if you intend to use the pretrained weights in a commercial product.
- COCO Pretrained Weights. Should follow cocodataset termsofuse. The annotations in COCO dataset belong to the COCO Consortium and are licensed under a Creative Commons Attribution 4.0 License. The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
- Pretrained on more than ImageNet and COCO. Several weights included or references here were pretrained with proprietary datasets that I do not have access to. These include the Facebook WSL, SSL, SWSL ResNe(Xt) and the Google Noisy Student EfficientNet models. The Facebook models have an explicit non-commercial license (CC-BY-NC 4.0, https://github.com/facebookresearch/semi-supervised-ImageNet1K-models, https://github.com/facebookresearch/WSL-Images). The Google models do not appear to have any restriction beyond the Apache 2.0 license (and ImageNet concerns). In either case, you should contact Facebook or Google with any questions.
- BibTeX
@misc{leondgarse, author = {Leondgarse}, title = {Keras CV Attention Models}, year = {2022}, publisher = {GitHub}, journal = {GitHub repository}, doi = {10.5281/zenodo.6506947}, howpublished = {\url{https://github.com/leondgarse/keras_cv_attention_models}} }
- Latest DOI: