


this is another yolov7 implementation based on detectron2, YOLOX, YOLOv6, YOLOv5, DETR, Anchor-DETR, DINO and some other SOTA detection models also supported. The ultimate goal of yolov7-d2 is to build a powerful weapon for anyone who wants a SOTA detector and train it without pain. It's extremly easy for users to build any Multi-Head models on yolov7-d2, for example, our E2E pose estimation is build on yolov7-d2 and works very well.
Thanks for Aarohi's youtube vlog for guaidance of yolov7: https://www.youtube.com/watch?v=ag88beS_fvM , if you want a quick start, take a look at this nice introduction on yolov7 and detectron2.
YOLOv7 v2.0 will be released soon! We will release our Convext-tiny YOLO arch model achieves mAP 43.9 with very low latency! Feature will be included in next version:
- Support EfficientFormer backbone;
- Support new YOLO2Go model, more lighter, much more faster and much more accurate;
- Support MobileOne backbone;
For more details, refer to read the doc.
Just fork and star!, you will be noticed once we release the new version!
🔥🔥🔥 Just another yolo variant implemented based on detectron2. But note that YOLOv7 isn't meant to be a successor of yolo family, 7 is just a magic and lucky number. Instead, YOLOv7 extends yolo into many other vision tasks, such as instance segmentation, one-stage keypoints detection etc..
The supported matrix in YOLOv7 are:
- YOLOv4 contained with CSP-Darknet53;
- YOLOv7 arch with resnets backbone;
- YOLOv7 arch with resnet-vd backbone (likely as PP-YOLO), deformable conv, Mish etc;
- GridMask augmentation from PP-YOLO included;
- Mosiac transform supported with a custom datasetmapper;
- YOLOv7 arch Swin-Transformer support (higher accuracy but lower speed);
- YOLOv7 arch Efficientnet + BiFPN;
- YOLOv5 style positive samples selection, new coordinates coding style;
- RandomColorDistortion, RandomExpand, RandomCrop, RandomFlip;
- CIoU loss (DIoU, GIoU) and label smoothing (from YOLOv5 & YOLOv4);
- YOLOF also included;
- YOLOv7 Res2net + FPN supported;
- Pyramid Vision Transformer v2 (PVTv2) supported;
- WBF (Weighted Box Fusion), this works better than NMS, link;
- YOLOX like head design and anchor design, also training support;
- YOLOX s,m,l backbone and PAFPN added, we have a new combination of YOLOX backbone and pafpn;
- YOLOv7 with Res2Net-v1d backbone, we found res2net-v1d have a better accuracy then darknet53;
- Added PPYOLOv2 PAN neck with SPP and dropblock;
- YOLOX arch added, now you can train YOLOX model (anchor free yolo) as well;
- DETR: transformer based detection model and onnx export supported, as well as TensorRT acceleration;
- AnchorDETR: Faster converge version of detr, now supported!
- Almost all models can export to onnx;
- Supports TensorRT deployment for DETR and other transformer models;
- It will integrate with wanwu, a torch-free deploy framework run fastest on your target platform.
⚠️ Important note: YOLOv7 on Github not the latest version, many features are closed-source but you can get it from https://manaai.cn
Features are ready but not opensource yet:
- Convnext training on YOLOX, higher accuracy than original YOLOX;
- GFL loss support;
- MobileVit-V2 backbone available;
- CSPRep-Resnet: a repvgg style resnet used in PP-YOLOE but in pytorch rather than paddle;
- VitDet support;
- Simple-FPN support from VitDet;
- PP-YOLOE head supported;
If you want get full version YOLOv7, either become a contributor or get from https://manaai.cn .
- 2022.08.20: Our new lightweighted model MobileOne-S0-YOLOX-Lite achieves mAP 30! surpressed yolox-nano or other lightweighted CPU models!
- 2022.07.26: Now we are preparing release new pose model;
- 2022.06.25: Meituan's YOLOv6 training has been supported in YOLOv7!
- 2022.06.13: New model YOLOX-Convnext-tiny got a
41.343 mAP beats yolox-s, AP-small even higher!; - 2022.06.09: GFL, general focal loss supported;
- 2022.05.26: Added YOLOX-ConvNext config;
- 2022.05.18: DINO, DNDetr and DABDetr are about added, new records on coco up to 63.3 AP!
- 2022.05.09: Big new function added! We adopt YOLOX with Keypoints Head!, model still under train, but you can check at code already;
- 2022.04.23: We finished the int8 quantization on SparseInst! It works perfect! Download the onnx try it our by your self.
- 2022.04.15: Now, we support the
SparseInstonnx expport! - 2022.03.25: New instance seg supported! 40 FPS @ 37 mAP!! Which is fast;
- 2021.09.16: First transformer based DETR model added, will explore more DETR series models;
- 2021.08.02: YOLOX arch added, you can train YOLOX as well in this repo;
- 2021.07.25: We found YOLOv7-Res2net50 beat res50 and darknet53 at same speed level! 5% AP boost on custom dataset;
- 2021.07.04: Added YOLOF and we can have a anchor free support as well, YOLOF achieves a better trade off on speed and accuracy;
- 2021.06.25: this project first started.
- more
If you have spare time or if you have GPU card, then help YOLOv7 become more stronger! Here is the guidance of contribute:
Claim task: I have some ideas but do not have enough time to do it, if you want to implement it, claim the task, I will give u detailed advise on how to do, and you can learn a lot from it;Test mAP: When you finished new idea implementation, create a thread to report experiment mAP, if it work, then merge into our main master branch;Pull request: YOLOv7 is open and always tracking on SOTA and light models, if a model is useful, we will merge it and deploy it, distribute to all users want to try.
Here are some tasks need to be claimed:
- VAN: Visual Attention Network, paper, VAN-Segmentation, it was better than Swin and PVT and DeiT:
- D2 VAN backbone integration;
- Test with YOLOv7 arch;
- ViDet: code, this provides a realtime detector based on transformer, Swin-Nano mAP: 40, while 20 FPS, it can be integrated into YOLOv7;
- Integrate into D2 backbone, remove MSAtten deps;
- Test with YOLOv7 or DETR arch;
- DINO: 63.3mAP highest in 2022 on coco.
- ConvNext: https://github.com/facebookresearch/ConvNeXt, combined convolution and transformer.
- NASVit: https://github.com/facebookresearch/NASViT
- MobileVIT: https://github.com/apple/ml-cvnets/blob/main/cvnets/models/classification/mobilevit.py
- DAB-DETR: https://github.com/IDEA-opensource/DAB-DETR, WIP
- DN-DETR: https://github.com/IDEA-opensource/DN-DETR
- EfficientNetV2: https://github.com/jahongir7174/EfficientNetV2
Just join our in-house contributor plan, you can share our newest code with your contribution!
Before running yolov7-d2, make sure you have detectron2 installed, for it's installation, please refer to original facebookresearch repo.
Simple pip install -e . you can have detectron2 installed from source.
Then, just clone this repo:
git clone https://github.com/jinfagang/yolov7_d2
cd yolov7_d2
pip install -e .
Or, you can pip install yolov7-d2 for quick install from pypi.
Then following docs for first training && inference usage.
| YOLOv7 Instance | Face & Detection |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
- See docs/install.md
Special requirements (other version may also work, but these are tested, with best performance, including ONNX export best support):
- torch 1.11 (stable version)
- onnx
- onnx-simplifier 0.3.7
- alfred-py latest
- detectron2 latest
If you using lower version torch, onnx exportation might not work as our expected.
Some highlights of YOLOv7 are:
- A simple and standard training framework for any detection && instance segmentation tasks, based on detectron2;
- Supports DETR and many transformer based detection framework out-of-box;
- Supports easy to deploy pipeline thought onnx.
- This is the only framework support YOLOv4 + InstanceSegmentation in single stage style;
- Easily plugin into transformers based detector;
We are strongly recommend you send PR if you have any further development on this project, the only reason for opensource it is just for using community power to make it stronger and further. It's very welcome for anyone contribute on any features!
| model | backbone | input | aug | APval | AP | FPS | weights |
|---|---|---|---|---|---|---|---|
| SparseInst | R-50 | 640 | ✘ | 32.8 | - | 44.3 | model |
| SparseInst | R-50-vd | 640 | ✘ | 34.1 | - | 42.6 | model |
| SparseInst (G-IAM) | R-50 | 608 | ✘ | 33.4 | - | 44.6 | model |
| SparseInst (G-IAM) | R-50 | 608 | ✓ | 34.2 | 34.7 | 44.6 | model |
| SparseInst (G-IAM) | R-50-DCN | 608 | ✓ | 36.4 | 36.8 | 41.6 | model |
| SparseInst (G-IAM) | R-50-vd | 608 | ✓ | 35.6 | 36.1 | 42.8 | model |
| SparseInst (G-IAM) | R-50-vd-DCN | 608 | ✓ | 37.4 | 37.9 | 40.0 | model |
| SparseInst (G-IAM) | R-50-vd-DCN | 640 | ✓ | 37.7 | 38.1 | 39.3 | model |
| SparseInst Int8 onnx | google drive |
| model | backbone | input | aug | AP | AP50 | APs | FPS | weights |
|---|---|---|---|---|---|---|---|---|
| YoloFormer-Convnext-tiny | Convnext-tiny | 800 | ✓ | 43 | 63.7 | 26.5 | 39.3 | model |
| YOLOX-s | - | 800 | ✓ | 40.5 | - | - | 39.3 | model |
note: We post AP-s here because we want to know how does small object performance in related model, it was notablely higher small-APs for transformer backbone based model! Some of above model might not opensourced but we provide weights.
Run a quick demo would be like:
python3 demo.py --config-file configs/wearmask/darknet53.yaml --input ./datasets/wearmask/images/val2017 --opts MODEL.WEIGHTS output/model_0009999.pth
Run a quick demo to upload and explore your YOLOv7 prediction with Weights & Biases . See here for an example
python3 demo.py --config-file configs/wearmask/darknet53.yaml --input ./datasets/wearmask/images/val2017 --wandb-entity <your-username/team> --wandb-project <project-name> --opts MODEL.WEIGHTS output/model_0009999.pth
Run SparseInst:
python demo.py --config-file configs/coco/sparseinst/sparse_inst_r50vd_giam_aug.yaml --video-input ~/Movies/Videos/86277963_nb2-1-80.flv -c 0.4 --opts MODEL.WEIGHTS weights/sparse_inst_r50vd_giam_aug_8bc5b3.pth
an update based on detectron2 newly introduced LazyConfig system, run with a LazyConfig model using:
python3 demo_lazyconfig.py --config-file configs/new_baselines/panoptic_fpn_regnetx_0.4g.py --opts train.init_checkpoint=output/model_0004999.pth
For training, quite simple, same as detectron2:
python train_net.py --config-file configs/coco/darknet53.yaml --num-gpus 8
If you want train YOLOX, you can using config file configs/coco/yolox_s.yaml. All support arch are:
- YOLOX: anchor free yolo;
- YOLOv7: traditional yolo with some explorations, mainly focus on loss experiments;
- YOLOv7P: traditional yolo merged with decent arch from YOLOX;
- YOLOMask: arch do detection and segmentation at the same time (tbd);
- YOLOInsSeg: instance segmentation based on YOLO detection (tbd);
There are some rules you must follow to if you want train on your own dataset:
- Rule No.1: Always set your own anchors on your dataset, using
tools/compute_anchors.py, this applys to any other anchor-based detection methods as well (EfficientDet etc.); - Rule No.2: Keep a faith on your loss will goes down eventually, if not, dig deeper to find out why (but do not post issues repeated caused I might don't know either.).
- Rule No.3: No one will tells u but it's real: do not change backbone easily, whole params coupled with your backbone, dont think its simple as you think it should be, also a Deeplearning engineer is not an easy work as you think, the whole knowledge like an ocean, and your knowledge is just a tiny drop of water...
- Rule No.4: must using pretrain weights for transoformer based backbone, otherwise your loss will bump;
Make sure you have read rules before ask me any questions.
detr:
python export.py --config-file detr/config/file
this works has been done, inference script included inside tools.
AnchorDETR:
anchorDETR also supported training and exporting to ONNX.
SparseInst: Sparsinst already supported exporting to onnx!!
python export.py --config-file configs/coco/sparseinst/sparse_inst_r50_giam_aug.yaml --video-input ~/Videos/a.flv --opts MODEL.WEIGHTS weights/sparse_inst_r50_giam_aug_2b7d68.pth INPUT.MIN_SIZE_TEST 512
If you are on a CPU device, please using:
python export.py --config-file configs/coco/sparseinst/sparse_inst_r50_giam_aug.yaml --input images/COCO_val2014_000000002153.jpg --verbose --opts MODEL.WEIGHTS weights/sparse_inst_r50_giam_aug_2b7d68.pth MODEL.DEVICE 'cpu'
Then you can have weights/sparse_inst_r50_giam_aug_2b7d68_sim.onnx generated, this onnx can be inference using ORT without any unsupported ops.
Here is a dedicated performance compare with other packages.
tbd.
- Wearmask:
support VOC, Yolo, coco 3 format. You can using coco format here. Download from: 链接: https://pan.baidu.com/s/1ozAgUFLqfTXLp-iOecddqQ 提取码: xgep . Using
configs/wearmaskto train this dataset. - more: to go.
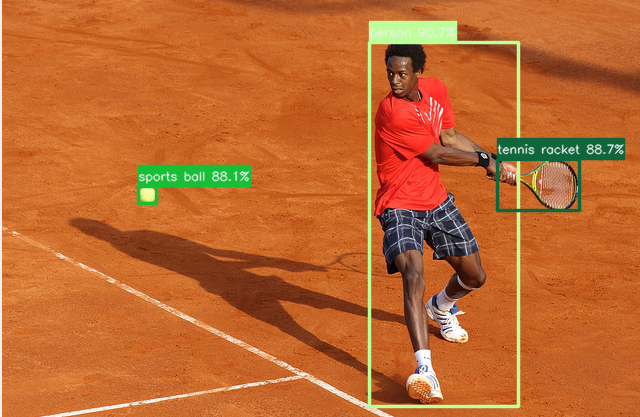
| Image | Detections |
|---|---|
 |
|
|
 |
 |
 |
 |
 |
- if wechat expired, please contact me update via github issue. group for general discussion, not only for yolov7.
- QQ群如果满了请加二群:419548605
| GridMask | Mosaic |
|---|---|
 |
 |
 |
 |
 |
 |
Code released under GPL license. Please pull request to this source repo before you make your changes public or commercial usage. All rights reserved by Lucas Jin.