- install and initialize the pipenv
pipenv install
- Compare two images with eachother using the lpips_2imgs.py script.
pipenv run python lpips_2imgs.py -p0 imgs/CT_scan_images/png_img/L506_40_target.png -p1 imgs/CT_scan_images/png_img/L506_40_input.png
Perceptual Similarity Metric and Dataset [Project Page]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang. In CVPR, 2018.
Run pip install lpips. The following Python code is all you need.
import lpips
loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores
loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization
import torch
img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1]
img1 = torch.zeros(1,3,64,64)
d = loss_fn_alex(img0, img1)More thorough information about variants is below. This repository contains our perceptual metric (LPIPS) and dataset (BAPPS). It can also be used as a "perceptual loss". This uses PyTorch; a Tensorflow alternative is here.
Table of Contents
- Learned Perceptual Image Patch Similarity (LPIPS) metric
a. Basic Usage If you just want to run the metric through command line, this is all you need.
b. "Perceptual Loss" usage
c. About the metric - Berkeley-Adobe Perceptual Patch Similarity (BAPPS) dataset
a. Download
b. Evaluation
c. About the dataset
d. Train the metric using the dataset
- Install PyTorch 1.0+ and torchvision fom http://pytorch.org
pip install -r requirements.txt- Clone this repo:
git clone https://github.com/richzhang/PerceptualSimilarity
cd PerceptualSimilarityEvaluate the distance between image patches. Higher means further/more different. Lower means more similar.
Example scripts to take the distance between 2 specific images, all corresponding pairs of images in 2 directories, or all pairs of images within a directory:
python lpips_2imgs.py -p0 imgs/ex_ref.png -p1 imgs/ex_p0.png --use_gpu
python lpips_2dirs.py -d0 imgs/ex_dir0 -d1 imgs/ex_dir1 -o imgs/example_dists.txt --use_gpu
python lpips_1dir_allpairs.py -d imgs/ex_dir_pair -o imgs/example_dists_pair.txt --use_gpu
File test_network.py shows example usage. This snippet is all you really need.
import lpips
loss_fn = lpips.LPIPS(net='alex')
d = loss_fn.forward(im0,im1)Variables im0, im1 is a PyTorch Tensor/Variable with shape Nx3xHxW (N patches of size HxW, RGB images scaled in [-1,+1]). This returns d, a length N Tensor/Variable.
Run python test_network.py to take the distance between example reference image ex_ref.png to distorted images ex_p0.png and ex_p1.png. Before running it - which do you think should be closer?
{kind=link}
{kind=link}
{kind=link}
Some Options By default in model.initialize:
- By default,
net='alex'. Networkalexis fastest, performs the best (as a forward metric), and is the default. For backpropping,net='vgg'loss is closer to the traditional "perceptual loss". - By default,
lpips=True. This adds a linear calibration on top of intermediate features in the net. Set this tolpips=Falseto equally weight all the features.
File lpips_loss.py shows how to iteratively optimize using the metric. Run python lpips_loss.py for a demo. The code can also be used to implement vanilla VGG loss, without our learned weights.
Higher means further/more different. Lower means more similar.
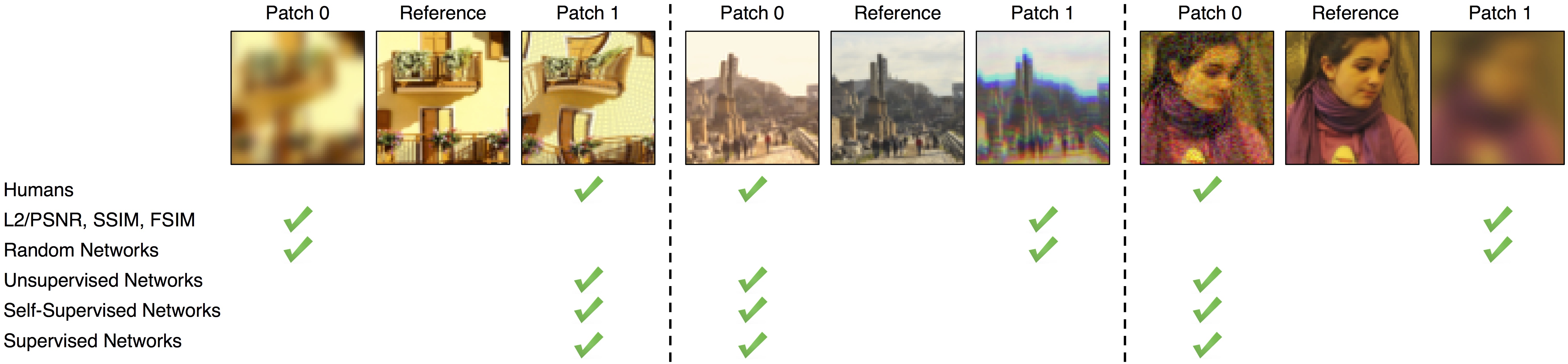
We found that deep network activations work surprisingly well as a perceptual similarity metric. This was true across network architectures (SqueezeNet [2.8 MB], AlexNet [9.1 MB], and VGG [58.9 MB] provided similar scores) and supervisory signals (unsupervised, self-supervised, and supervised all perform strongly). We slightly improved scores by linearly "calibrating" networks - adding a linear layer on top of off-the-shelf classification networks. We provide 3 variants, using linear layers on top of the SqueezeNet, AlexNet (default), and VGG networks.
If you use LPIPS in your publication, please specify which version you are using. The current version is 0.1. You can set version='0.0' for the initial release.
Run bash ./scripts/download_dataset.sh to download and unzip the dataset into directory ./dataset. It takes [6.6 GB] total. Alternatively, run bash ./scripts/download_dataset_valonly.sh to only download the validation set [1.3 GB].
- 2AFC train [5.3 GB]
- 2AFC val [1.1 GB]
- JND val [0.2 GB]
Script test_dataset_model.py evaluates a perceptual model on a subset of the dataset.
Dataset flags
--dataset_mode:2afcorjnd, which type of perceptual judgment to evaluate--datasets: list the datasets to evaluate- if
--dataset_mode 2afc: choices are [train/traditional,train/cnn,val/traditional,val/cnn,val/superres,val/deblur,val/color,val/frameinterp] - if
--dataset_mode jnd: choices are [val/traditional,val/cnn]
- if
Perceptual similarity model flags
--model: perceptual similarity model to uselpipsfor our LPIPS learned similarity model (linear network on top of internal activations of pretrained network)baselinefor a classification network (uncalibrated with all layers averaged)l2for Euclidean distancessimfor Structured Similarity Image Metric
--net: [squeeze,alex,vgg] for thenet-linandnetmodels; ignored forl2andssimmodels--colorspace: choices are [Lab,RGB], used for thel2andssimmodels; ignored fornet-linandnetmodels
Misc flags
--batch_size: evaluation batch size (will default to 1)--use_gpu: turn on this flag for GPU usage
An example usage is as follows: python ./test_dataset_model.py --dataset_mode 2afc --datasets val/traditional val/cnn --model lpips --net alex --use_gpu --batch_size 50. This would evaluate our model on the "traditional" and "cnn" validation datasets.
The dataset contains two types of perceptual judgements: Two Alternative Forced Choice (2AFC) and Just Noticeable Differences (JND).
(1) 2AFC Evaluators were given a patch triplet (1 reference + 2 distorted). They were asked to select which of the distorted was "closer" to the reference.
Training sets contain 2 judgments/triplet.
train/traditional[56.6k triplets]train/cnn[38.1k triplets]train/mix[56.6k triplets]
Validation sets contain 5 judgments/triplet.
val/traditional[4.7k triplets]val/cnn[4.7k triplets]val/superres[10.9k triplets]val/deblur[9.4k triplets]val/color[4.7k triplets]val/frameinterp[1.9k triplets]
Each 2AFC subdirectory contains the following folders:
ref: original reference patchesp0,p1: two distorted patchesjudge: human judgments - 0 if all preferred p0, 1 if all humans preferred p1
(2) JND Evaluators were presented with two patches - a reference and a distorted - for a limited time. They were asked if the patches were the same (identically) or different.
Each set contains 3 human evaluations/example.
val/traditional[4.8k pairs]val/cnn[4.8k pairs]
Each JND subdirectory contains the following folders:
p0,p1: two patchessame: human judgments: 0 if all humans thought patches were different, 1 if all humans thought patches were same
See script train_test_metric.sh for an example of training and testing the metric. The script will train a model on the full training set for 10 epochs, and then test the learned metric on all of the validation sets. The numbers should roughly match the Alex - lin row in Table 5 in the paper. The code supports training a linear layer on top of an existing representation. Training will add a subdirectory in the checkpoints directory.
You can also train "scratch" and "tune" versions by running train_test_metric_scratch.sh and train_test_metric_tune.sh, respectively.
If you find this repository useful for your research, please use the following.
@inproceedings{zhang2018perceptual,
title={The Unreasonable Effectiveness of Deep Features as a Perceptual Metric},
author={Zhang, Richard and Isola, Phillip and Efros, Alexei A and Shechtman, Eli and Wang, Oliver},
booktitle={CVPR},
year={2018}
}
This repository borrows partially from the pytorch-CycleGAN-and-pix2pix repository. The average precision (AP) code is borrowed from the py-faster-rcnn repository. Angjoo Kanazawa, Connelly Barnes, Gaurav Mittal, wilhelmhb, Filippo Mameli, SuperShinyEyes, Minyoung Huh helped to improve the codebase.