This repo contains the website materials to learn R aimed for beginners. The framework is build on Ines' framework developer for her spaCy course. The front-end is powered by Gatsby and Reveal.js and the back-end code execution uses Binder.
This section was contributed by @laderast. Thanks! ✨
The course repository works with two components: Gatsby (front-end), and Binder (back-end). We'll go over both of these to understand how it works as a whole.
Gatsby is a JavaScript/react.js based web page building framework, like Hugo, or Jekyll. The nice thing about it being JavaScript is that JavaScript widgets that you build are tightly integrated.
You can think of Gatsby as being the client side of the lesson framework. All code, solutions, tests, and chapter.md files are handled by Gatsby.
Binder is a way of building Docker containers from repositories that can be launched on a remote server/cluster (such as mybinder.org). This Docker container can be based on a Dockerfile, or R image. The thing about Binder is that the containers are ephemeral - if they're not used, they're deleted off the Binder servers. The main applications of Binder are:
- Reproducible Research (shareable notebooks) and
- Education (shareable notebooks)
You can think of Binder as being the server side of the lesson framework. It
needs the instructions on how to build the docker container (which is in the
binder/ folder), and the data you want to use for the lessons (in the data/
folder).
The only thing you need to get started with R and Binder is a repo that has a
runtime.txt file, or a Dockerfile. The rest, such as datafiles, are optional,
but are usually contained in a Binder repository.

Ines was super clever and designed a JavaScript plugin for Gatsby called Juniper to handle communication to and from the Binder container using Jupyter kernels. That's how code gets executed on the Binder container, and how code output (such as terminal messages, images, etc) are received from the Binder container.

There are two branches of this repo, which are used for different tasks:
- master - this is what the course is served out of via netlify: http://r-bootcamp.netlify.com - any changes to exercises in this branch will show up on the netlify page. The netlify page uses a JavaScript framework called Gatsby to build the pages. Gatsby submits code to binder and receives the output. It also handles the code checking. The parts of the repo that are handled by Gatsby include:
- exercises/solutions/tests
- chapter.md files
- slides (using reveal.js)
- binder - this is what the Binder image is built from. The reason they're
different is that binder forces a Docker container rebuild when a branch is
updated. So, if we served our container out of master, it would rebuild
everytime we modified a
chapter.mdor an exercise. If you need to add packages, you will add them to thebinder/install.Rfor this branch, and if you need to add datasets, you can add them to thedata/folder. The parts of the repo handled by Binder include:
- datasets in data/ folder (the container needs access to these to load data from submitted code)
- installation instructions in the binder/ folder for installing dependencies
I would say that the easiest thing to do is to occasionally merge master into
binder when you need to update the data:
Note that rebuilding the binder container can take a little bit of time (usually
on the order of 5 or 10 minutes or so), since it is installing/compiling
tidyverse for the container. You can always check the build status of the
container by clicking the badge below and looking at the log.
You can view the binder container here:
or at: https://mybinder.org/v2/gh/ines/course-starter-r/binder
- you can launch an Rstudio instance to test the container by using the "new" tab in the top right corner, and selecting 'Rstudio'. This is super helpful if you want to test if code will work in the binder container.
If you need to add packages, add the appropriate install.packages() statement
into binder/install.R. When you do, check that the container was built
properly by clicking the binder link above.
Currently, tidyverse is installed in the binder container.
If you want to access datasets in the data folder, you can always refer to this
folder as data/. For example, to use data/pets.csv:
pets <- read.csv("data/pets.csv")
Remember, if you need to add a dataset to the repo, it needs to be done in the
binder branch into the data/ folder.
If you would like to transfer your courses from DataCamp, there is a package
made for that: decampr. It will scan
your repository and attempt to extract exercise instructions, quizzes, exercise
code, and solutions and write them to the appropriate directory for your
project. For more info, please check out the decampr repo:
http://github.com/laderast/decampr
The app separates its source and content – so you usually shouldn't have to dig into the JavaScript source to change things. The following points of customization are available:
| Location | Description |
|---|---|
meta.json |
General config settings, title, description etc. |
theme.sass |
Color theme. |
binder/install.R |
Packages to install. |
binder/runtime.txt |
YYYY-MM-DD snapshot at MRAN that will be used for installing libraries. See here for details. |
chapters |
The chapters, one Markdown file per chapter. |
slides |
The slides, one Markdown file per slide deck. |
static |
Static assets like images, will be copied to the root. |
The following meta settings are available. Note that you have to re-start Gatsby to see the changes if you're editing it while the server is running.
| Setting | Description |
|---|---|
courseId |
Unique ID of the course. Will be used when saving completed exercises to the browser's local storage. |
title |
The title of the course. |
slogan |
Course slogan, displayed in the page title on the front page. |
description |
Course description. Used for site meta and in footer. |
bio |
Author bio. Used in the footer. |
siteUrl |
URL of the deployed site (without trailing slash). |
twitter |
Author twitter handle, used in Twitter cards meta. |
fonts |
Google Fonts to load. Should be the font part of the URL in the embed string, e.g. Lato:400,400i,700,700i. |
testTemplate |
Template used to validate the answers. ${solution} will be replaced with the user code and ${test} with the contents of the test file. |
juniper.repo |
Repo to build on Binder in user/repo format. Usually the same as this repo. |
juniper.branch |
Branch to build. Ideally not master, so the image is not rebuilt every time you push. |
juniper.lang |
Code language for syntax highlighting. |
juniper.kernelType |
The name of the kernel to use. |
juniper.debug |
Logs additional debugging info to the console. |
showProfileImage |
Whether to show the profile image in the footer. If true, a file static/profile.jpg needs to be available. |
footerLinks |
List of objects with "text" and "url" to display as links in the footer. |
theme |
Currently only used for the progressive web app, e.g. as the theme color on mobile. For the UI theme, edit theme.sass. |
All files added to /static will become available at the root of the deployed
site. So /static/image.jpg can be referenced in your course as /image.jpg.
The following assets need to be available and can be customized:
| File | Description |
|---|---|
icon.png |
Custom favicon. |
logo.svg |
The course logo. |
profile.png |
Photo or profile image. |
social.png |
Social image, displayed in Twitter and Facebook cards. |
icon_check.svg |
"Check" icon displayed on "Mark as completed" button. |
icon_slides.svg |
Icon displayed in the corner of a slides exercise. |
Chapters are placed in /chapters and are Markdown files
consisting of <exercise> components. They'll be turned into pages, e.g.
/chapter1. In their frontmatter block at the top of the file, they need to
specify type: chapter, as well as the following meta:
---
title: The chapter title
description: The chapter description
prev: /chapter1 # exact path to previous chapter or null to not show a link
next: /chapter3 # exact path to next chapter or null to not show a link
id: 2 # unique identifier for chapter
type: chapter # important: this creates a standalone page from the chapter
---
Slides are placed in /slides and are markdown files consisting of
slide content, separated by ---. They need to specify the following
frontmatter block at the top of the file:
---
type: slides
---
The first and last slide use a special layout and will display the headline
in the center of the slide. Speaker notes (in this case, the script) can be
added at the end of a slide, prefixed by Notes:. They'll then be shown on the
right next to the slides. Here's an example slides file:
---
type: slides
---
# Processing pipelines
Notes: This is a slide deck about processing pipelines.
---
# Next slide
- Some bullet points here
- And another bullet point
<img src="/image.jpg" alt="An image located in /static" />When using custom elements, make sure to place a newline between the opening/closing tags and the children. Otherwise, Markdown content may not render correctly.
Container of a single exercise.
| Argument | Type | Description |
|---|---|---|
id |
number / string | Unique exercise ID within chapter. |
title |
string | Exercise title. |
type |
string | Optional type. "slides" makes container wider and adds icon. |
| children | - | The contents of the exercise. |
<exercise id="1" title="Introduction to spaCy">
Content goes here...
</exercise>| Argument | Type | Description |
|---|---|---|
id |
number / string | Unique identifier of the code exercise. |
source |
string | Name of the source file (without file extension). Defaults to exc_${id} if not set. |
solution |
string | Name of the solution file (without file extension). Defaults to solution_${id} if not set. |
test |
string | Name of the test file (without file extension). Defaults to test_${id} if not set. |
| children | string | Optional hints displayed when the user clicks "Show hints". |
<codeblock id="02_03">
This is a hint!
</codeblock>Container to display slides interactively using Reveal.js and a Markdown file.
| Argument | Type | Description |
|---|---|---|
source |
string | Name of slides file (without file extension). |
<slides source="chapter1_01_introduction-to-spacy">
</slides>Container for multiple-choice question.
| Argument | Type | Description |
|---|---|---|
id |
string / number | Optional unique ID. Can be used if more than one choice question is present in one exercise. |
| children | nodes | Only <opt> components for the options. |
<choice>
<opt text="Option one">You have selected option one! This is not good.</opt>
<opt text="Option two" correct="true">Yay! </opt>
</choice>A multiple-choice option.
| Argument | Type | Description |
|---|---|---|
text |
string | The option text to be displayed. Supports inline HTML. |
correct |
string | "true" if the option is the correct answer. |
| children | string | The text to be displayed if the option is selected (explaining why it's correct or incorrect). |
The install.R in the repository defines the packages that
are installed when building it with Binder. You can specify the binder settings
like repo, branch and kernel type in the "juniper" section of the meta.json.
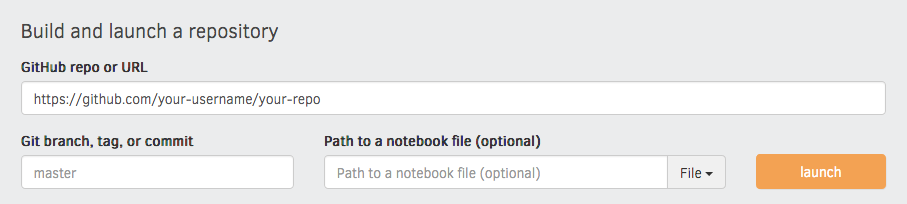
I'd recommend running the very first build via the interface on the
Binder website, as this gives you a detailed build log
and feedback on whether everything worked as expected. Enter your repository
URL, click "launch" and wait for it to install the dependencies and build the
image.
To validate the code when the user hits "Submit", we're currently using a
slightly hacky trick. Since the R code is sent back to the kernel as a string,
we can manipulate it and add tests – for example, exercise exc_01_02_01.R will
be validated using test_01_02_01.R (if available). The user code and test are
combined using a string template. At the moment, the testTemplate in the
meta.json looks like this:
success <- function(text) {
cat(paste("\033[32m", text, "\033[0m", sep = ""))
}
.solution <- "${solutionEscaped}"
${solution}
${test}
tryCatch({
test()
}, error = function(e) {
cat(paste("\033[31m", e[1], "\033[0m", sep = ""))
})If present, ${solution} will be replaced with the string value of the
submitted user code, and ${solutionEscaped} with the code but with all "
replaced by \", so we can assign it to a variable as a string and check
whether the submission includes something. We also insert the regular solution,
so we can actually run it and check the objects it creates. ${test} is
replaced by the contents of the test file. The template also defines a success
function, which prints a formatted green message and can be used in the tests.
Finally, the tryCatch expression checks if the test function raises a stop
and if so, it outputs the formatted error message. This also hides the full
error traceback (which can easily leak the correct answers).
A test file could then look like this:
test <- function() {
if (some_var != length(mtcars)) {
stop("Are you getting the correct length?")
}
if (!grepl("print(mtcars$gear)", .solution, fixed = TRUE)) {
stop("Are you printing the correct variable?")
}
success("Well done!")
}The string answer is available as .solution, and the test also has access to
the solution code.
For more details on how it all works behind the scenes, see the original course repo.
- You need to install the
teachrpackage
devtools::install_github("numbats/teachr")- For adding a new chapter, add the chapter Rmd in the
chaptersfolder. See for examplechapters/chapter1.Rmd. - For adding new slides to be referred to in the chapter Rmd, add the slides Rmd in
slidesfolder. Name your slides so the prefix ischapterXwhereXis the chapter number. See for exampleslides/chapter1_01_windows.Rmd.
- Navigate to the local repo folder
- Install brew (if not already available) https://brew.sh/
- Install node v14 (https://formulae.brew.sh/formula/node@14)
- Install gatsby with
npm install -g gatsby-cli - Install website dependencies with
npm install - Install lottie web
npm install lottie-web(https://www.npmjs.com/package/lottie-web) - Install google analytics plugin for Gatsby
npm install gatsby-plugin-google-gtag - Serve the website with
npm run dev
NOTE: the reference to image is relative to the chapter for local view but on the deployed website, it is the base url. This means that if your image reference is myfolder/myimage.png within chapterx then you need to refer to as like chapterx/myfolder/myimage.png. This will not show up on the local preview which needs the reference to be myfolder/myimage.png. How very annoying.