A repo showing important events, news, and community updates related to Karachi and areas around it.
We have implemented a simple harvester that pulls tweets from twitter for a particular topic at a schedule. We then perform Sentiment analysis of tweets using AWS Lake Formation/Glue.
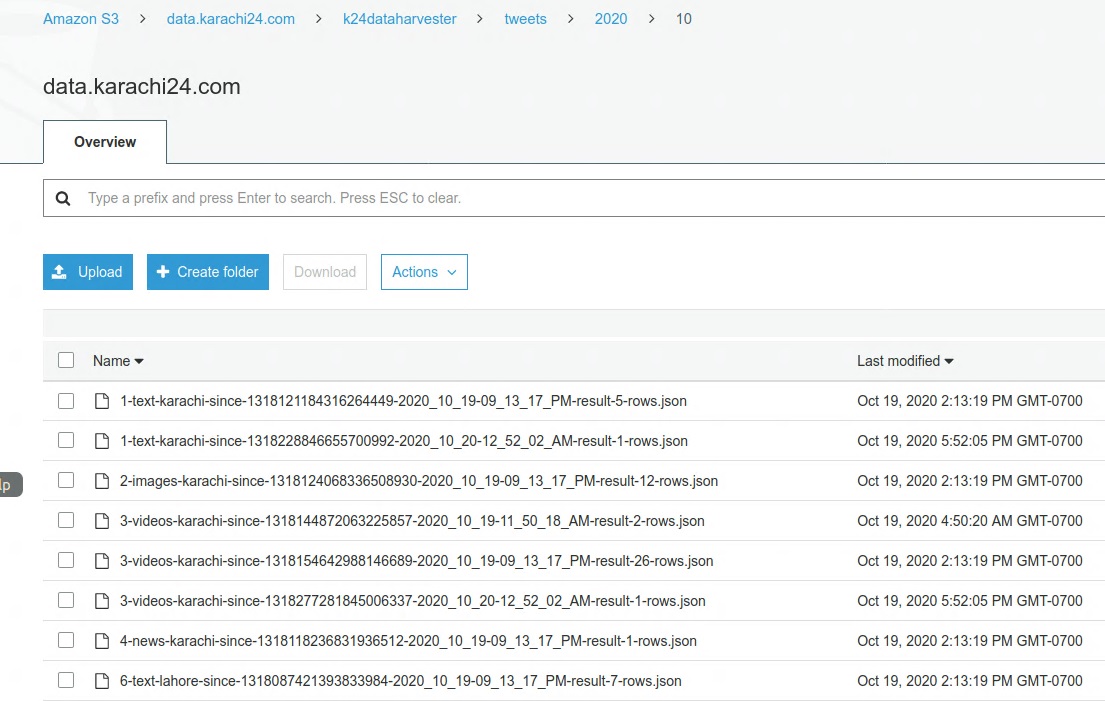
Results are saved to s3 and DynamoDb Table.
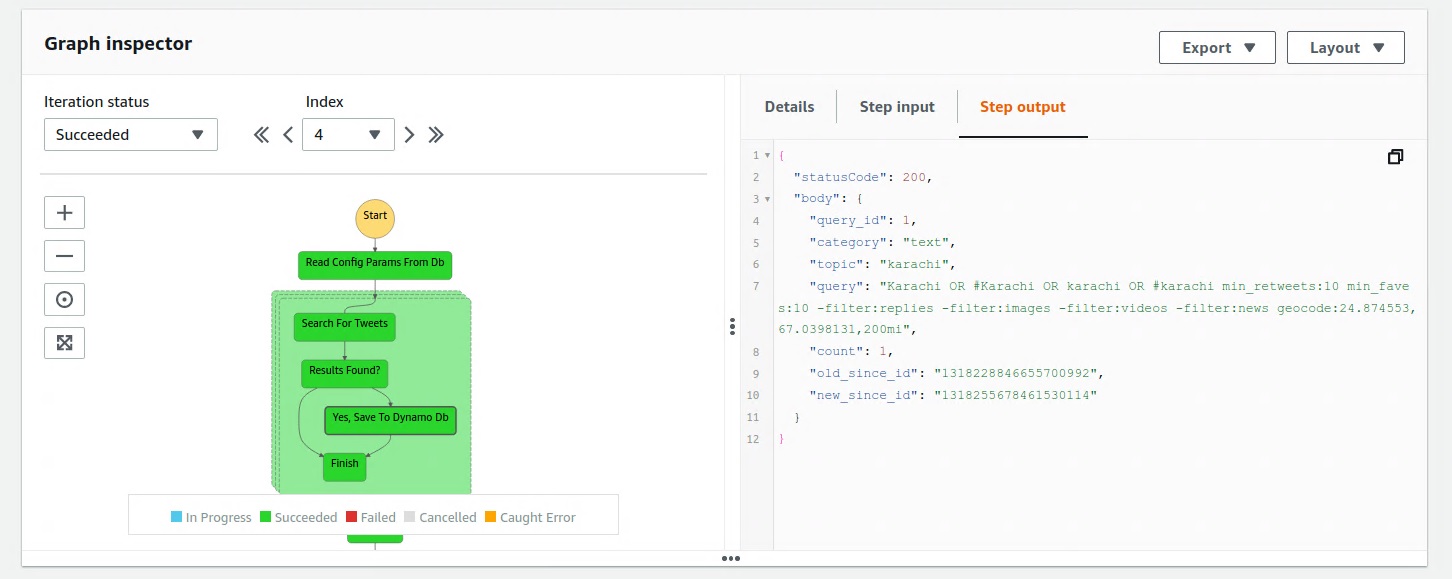
We save twitter queries to a DynamoDb Config table. During each run, active (enabled=1) queries are read from the Config table, and then supplied to the downstream MAP State function via a JSON input param.
{
"Id": 1,
"enabled": "1",
"description": "These tweets are related to Karachi",
"queries": [{
"Id": 1,
"category": "text",
"topic": "karachi",
"q": "Karachi OR #Karachi OR karachi OR #karachi min_retweets:10 min_faves:10 -filter:replies -filter:images -filter:videos -filter:news geocode:24.874553,67.0398131,200mi",
"count": 1500,
"since_id": "1312862399490220002",
"enabled": "1"
},
{
"Id": 2,
"category": "images",
"topic": "karachi",
"q": "Karachi OR #Karachi OR karachi OR #karachi min_retweets:10 min_faves:10 -filter:replies filter:images geocode:24.874553,67.0398131,200mi",
"count": 1500,
"since_id": "1312862399490220002",
"enabled": "1"
},
{
"Id": 3,
"category": "videos",
"topic": "karachi",
"q": "Karachi OR #Karachi OR karachi OR #karachi min_retweets:10 min_faves:10 -filter:replies filter:videos",
"count": 1500,
"since_id": "1312862399490220002",
"enabled": "1"
},
{
"Id": 4,
"category": "news",
"topic": "karachi",
"q": "Karachi OR #Karachi OR karachi OR #karachi min_retweets:10 min_faves:10 -filter:replies filter:news",
"count": 1500,
"since_id": "1312862399490220002",
"enabled": "0"
}
]
}JSON result is saved to S3 folder structure resembling Apache HIVE format.
<bucket root>/k24dataharvester/tweets/YYYY/MM/<file name>.json
<bucket root>/k24dataharvester/tweets/2020/10/1-text-karachi-since-1318121184316264449-2020_10_19-09_13_17_PM-result-5-rows.json